Data Store Import
The general syntax of the Data Store import command is:
Before we discuss the command execution, let us look at the operations and configurations available for this command in detail.
Operations
There are three operations that can be performed using the Data Store import command:
- Insert: Inserts new rows of data into the table from the CSV file
- Update: Updates existing rows of data in the table
- Upsert: Enables both insert and update operations at the same time. If the record already exists, the row is updated. If the record does not exist, a new row with the data is inserted.
You can specify the operation to be executed in the input JSON configuration file.
Input CSV File
As mentioned earlier, the import operation bulk writes records from a CSV file to a table. You can provide the CSV file in two ways:
- You can upload the CSV file containing the records to a Bucket in Stratus before you begin executing this operation. In this case, you must specify the unique Object URL generated for the file in Stratus, in the JSON configuration file that you pass during the command execution.
- If you do not pass any JSON configuration file with the command, you must specify the path of the CSV file in your system in your command execution, as shown in the general syntax above. Catalyst will then upload the CSV file you provide to your project’s Bucket and automatically obtain it’s Object URL for execution. You can select the path to save the file in Stratus.
Catalyst will consider the CSV file specified with the command as the higher priority, over the Object URL specified in the JSON file. If the CSV file is not specified in either places, the CLI will display an error message during command execution.
-
The CSV file’s first row must be the header row. In other words, the column names must be present as the header row.
-
The CSV file must contain data in the format that adheres to CSV file standards. If the file is not in the standard format, the data written to the table may be corrupted.
-
You will be able to insert 5000 records in each table per project in the development environment . If the CSV file contains records more than that, the first 5000 records will be written to the table. The others will be skipped in the development environment. There are no upper limits for data insertion in the production environment.
JSON Configuration File Structure
A sample JSON configuration file specifying the requirements of the import operation, that you can optionally pass during the command execution, is shown below:
{
"table_identifier" : "ZylkerEmpDatabase",
"operation" : "upsert",
"object_url" : "https://bucket-name-development.zohostratus.com/object-name",
"callback" : {
"url" : "https://hr.zylker.com/en/EmpRecords/_callback.php.com",
"headers" : {
"src" : "ZCatalyst",
"operation" : "bulkwriteAPI"
}
},
"find_by" : "EmpID",
"fk_mapping" : [
{
"local_column" : "EmpID",
"reference_column" : "EmployeeID"
},
{
"local_column" : "DeptID",
"reference_column" : "DepartmentID"
}
]
}
The parameters supported by the JSON configuration file are defined below:
| Attributes | Description |
|---|---|
| table_identifier (String, Mandatory) |
The unique ID of the table or the table name where data must be imported to. You can also pass the table identifier using the –table option. |
| operation (String, Optional) |
Specifies the operation to be executed. Allowed values:insert, update, upsert Default operation: insert |
| object_url (String, Mandatory) |
The unique ID of the CSV file in Stratus. You can also specify the CSV file path with the command. |
| find_by (String, Mandatory for update and upsert operations. Not mandatory for insert operation) |
The unique column using which the records are identified. For example, if you specify a unique column called 'EmployeeID' as the find_by value, Catalyst will search the records in the Data Store table using the EmployeeID value. For the update operation, Catalyst will update the rows that match the EmployeeID value from the CSV file. For the upsert operation, Catalyst will update existing rows, and insert new rows if there are no records with matching EmployeeID values. Update: This can be a column with unique values as configured in the Data Store, or the ROWID generated by Catalyst for the records. Upsert: You can only specify a column with unique values as configured in the Data Store. You will not be able to specify the ROWID as the find_by value. This is because, upsert will insert new rows if matching ones are not found, and the ROWID values will not be available for rows not existing in the Data Store. Insert: If you specify a find_by column for an insert operation, any records matching the column values from the CSV file will be skipped and not inserted into the Data Store table. This is because, insert cannot update if a given record already exists. |
| fk_mapping (JSON, Optional) |
Foreign key mapping for the columns that are primary keys in other tables. This is specified if any columns imported from the CSV file should be configured as foreign keys. You must map foreign keys in the following format: { “local_column” : “local_column_name_1”, “reference_column” : “reference_column_name_1” } where local_column is the name of the column in the table where the bulk write operation is processed, and reference_column is the name of the column in the table in which it is a primary key. |
| callback (JSON, Optional) |
The section where you can define the properties of the callback URL, where automatic JSON responses of the job statuses will be sent to. The properties to be included in this section are given in the table below. |
Callback Properties
| Attribute | Description |
|---|---|
| url (String, Mandatory if you want to specify the callback URL) |
The URL where the automatic responses will be sent to using the HTTP POST method, each time the job status changes. Information about the job details will be contained in the body of the JSON response. The CLI will also display a live stream of the execution, and the final job status. |
| headers (String, Optional) | Headers that you require to be passed in the JSON response to the callback URL You must specify the headers as: { “{header_name_1}” : “{header_value_1}”, “{header_name_2}” : “{header_value_2}" } and so on. |
| params (String, Optional) |
Parameters that you require to be appended to the callback URL You must specify the parameters as: { “{param_name_1}” : “{param_value_1}”, “{param_name_2}” : “{param_value_2}" } and so on. |
Import Job Processing States
There are three job processing states for the import operation:
- In-Progress: The job enters this state as soon as you execute the import command. The CLI will
display a job_id parameter that you can use to
check the status of the job execution for subsequent responses manually, if
you have not configured a callback URL in the JSON.
If you have configured a callback URL, a state response with the job_id will also be posted to the URL in the format you defined. - Success: If the import operation is successful, Catalyst will provide a download URL where you can download a CSV report file that contains the details of the job execution. Catalyst also enables you to download the report file directly to your system through the CLI. If you have configured a callback URL, this response will be posted to it as well.
- Failed: If the import operation fails, the CLI will display the details of the errors that occurred. If you have configured a callback URL, this response will be posted to it as well.
Import Options
The import command execution process is described in detail in this section, for each option. The Data Store import command supports the following options:
--config <path>
The config option enables you to define the path of the JSON configuration file in your system.
For example, you can execute the import operation and pass the JSON file path as shown below:

The CLI will then automatically schedule the job execution and mark it as “in-progress”. It will display a live stream of the execution process, along with the job_id .
If the job executes successfully, the CLI will prompt you to download the report file to your system. Type ‘y ‘, then press Enter to download.
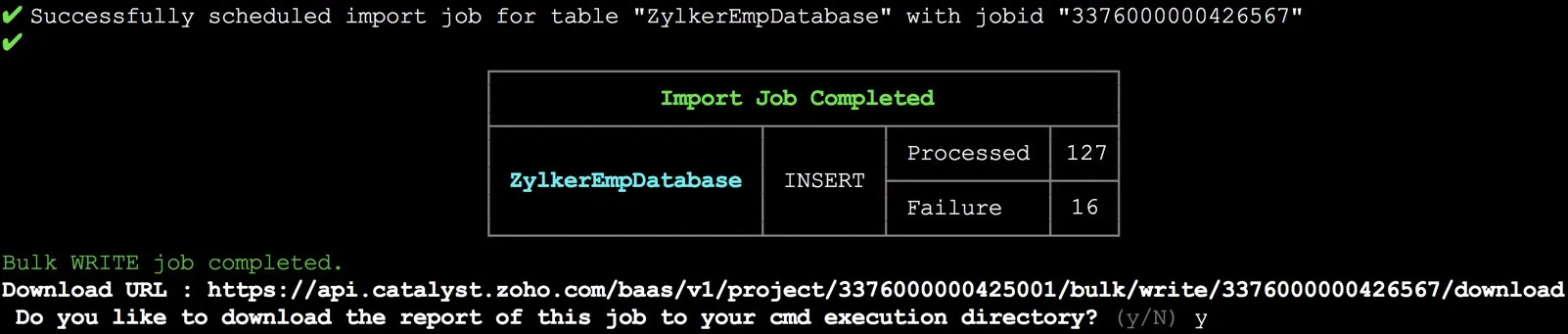
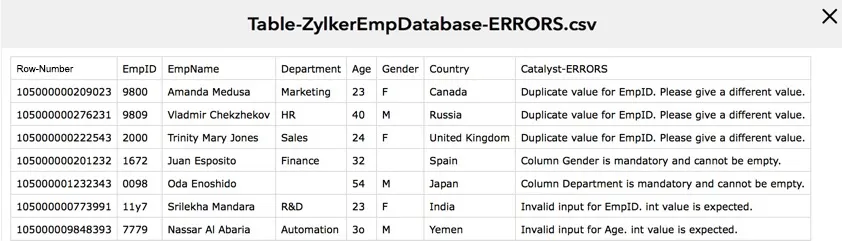
The ZIP file containing the report file will be downloaded to your project directory.

You can use the download URL provided by Catalyst to download the report even when you are not working in your CLI. You must execute it as an API command .
--table <name|id>
The --table option enables you to specify the table name or Table ID of the table, to which the records must be written.
As mentioned earlier, if you don’t specify the table identifier in the JSON file, or if you don’t pass a JSON file during the command execution, you must specify it using this option.
Catalyst will consider the table specified in the option as the higher priority, over the one specified in the JSON file. If the table is not specified in either places, the CLI will display an error message during command execution.
For example, you can specify the table identifier along with the CSV file path in the following way:

If you specify the CSV file path, the CLI will then execute the import operation, bulk write the records to the specified table, and provide the report file in the same way.

--production
The –production option enables you to directly execute the import operation in the production environment of your Catalyst project. If you use this option, the records from the input CSV file will be bulk written to the specified table directly in production.
Last Updated 2025-10-09 19:46:12 +0530 IST
Yes
No
Send your feedback to us