Data Store Export
Introduction
The general syntax of the Data Store export command is:
JSON Configuration File Structure
The Data Store Export command will obtain records from the table you specify, which match the criteria you define in the input JSON configuration file. If you don’t pass the JSON file with the command, or if you don’t specify any criteria, all records from the table will be read by default.
A sample JSON configuration file specifying the requirements of the export operation, that you can optionally pass during the command execution, is shown below:
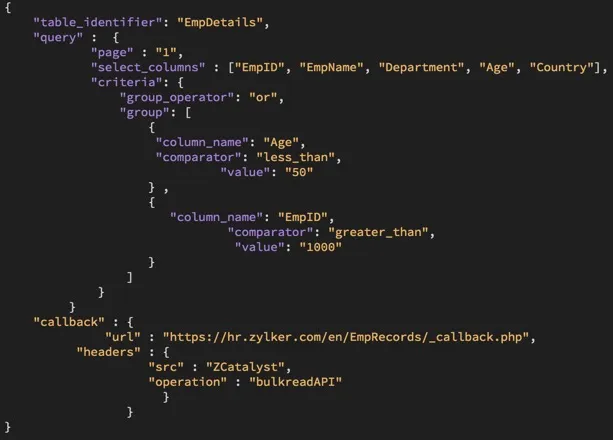
The parameters supported by the JSON configuration file are defined below:
| Attributes | Description |
|---|---|
| table_identifier (String, Mandatory) |
The unique ID of the table or the table name where data must be exported from. You can also pass the table identifier using the –table option . |
| query (JSON, Optional) |
The section where you can define the conditions and criteria for the export job |
| page (Numerical, Optional) |
The CSV file generated as the result of the bulk read process contains two hundred thousand/two lakh records in one page. Page value '1' indicates that the first two hundred thousand records matching your query will get exported. You can fetch subsequent records by increasing the page value. For example, if you want to fetch records from the range 200,001 to 400,000, then you must specify the page value as '2'. Default value: 1 You can also specify the page value using the –page option. |
| select_columns (Array, Optional) |
Specific columns in the records that need to be fetched from the table. If you do not specify the columns, all columns will be selected and fetched. You can include multiple columns in an array. |
| callback (JSON, Optional) |
The section where you can define the properties of the callback URL, where automatic JSON responses of the job statuses will be sent to |
| url (String, Mandatory if you want to specify the callback URL |
The URL where the automatic responses will be sent to using the HTTP POST method, each time the job status changes. Information about the job details will be contained in the body of the JSON response. The CLI will also display a live stream of the execution, and the final job status. |
| headers (String, Optional) |
Headers that you require to be passed in the JSON response to the callback URL You must specify the headers as: { “{header_name_1}” : “{header_value_1}”, “{header_name_2}” : “{header_value_2}" } and so on. |
| params (String, Optional) |
Parameters that you require to be appended to the callback URL You must specify the parameters as: { “{param_name_1}” : “{param_value_1}”, “{param_name_2}” : “{param_value_2}" } and so on. |
| criteria (JSON, Optional) |
A set of conditions based on which the records will be fetched. The properties to be included in this section are given in the table below. |
Criteria Properties
| Attributes | Description |
|---|---|
| group_operator (String, Mandatory if you want to specify the criteria |
The operator that will bind the criteria groups together. Supported Operators: AND, OR If you define two or more criteria groups, you can use the AND or the OR operator. For example, you can specify a criteria like "column1 equal value 1 AND column2 contains value 2" in the format specified in the previous section. Note: You will not be able to use combinations of both the operators. You can either use AND or OR in a single command execution. |
| group (JSON, Mandatory if you want to specify the criteria) |
You can include upto 25 criteria sets in this section. The sample JSON file shows 2 criteria sets. Note: You can include only one overall group with one group operator in a single execution. |
| column_name (String, Mandatory if you want to specify the criteria) |
Name of the specific column from the table that the criteria should be defined for |
| comparator (String, Mandatory if you want to specify the criteria) |
The comparison operator that matches the column name with the criteria value Supported Comparators: equal, not_equal, greater_than, greater_equal, less_than, less_equal, starts_with, ends_with, contains, not_contains, in, not_in, between, not_between Note:
|
| value (String, Mandatory if you want to specify the criteria) |
The value for the specific column in the record that you require to be defined as a criteria |
Export Job Processing States
There are three job processing states for the export operation:
- In-Progress: The job enters this state as soon as you execute the import command. The CLI will display a job_id parameter which you can use to check the status of the job execution for subsequent responses manually, if you have not configured a callback URL in the JSON.
If you have configured a callback URL, a state response with the job_id will also be posted to the URL in the format you defined. - Success: If the export operation is successful, Catalyst will provide a download URL where you can download the CSV file that contains the records matching your query. Catalyst also enables you to download the result file directly to your system through the CLI. If you have configured a callback URL, this response will be posted to it as well.
- Failed: If the export operation fails, the CLI will display the details of the errors that occurred. If you have configured a callback URL, this response will be posted to it as well.
Export Options
The export command execution process is described in detail in this section, for each option. The Data Store export command supports the following options:
--config <path>
The –config option enables you to define the path of the JSON configuration file in your system.
For example, you can execute the export operation and pass the JSON file path as shown below:

The CLI will then automatically schedule the job execution and mark it as “in-progress”. It will display a live stream of the execution process, along with the job_id.
If the job executes successfully, the CLI will prompt you to download the result file to your system. Type ‘y ‘, then press Enter to download.

The ZIP file containing the result file will be downloaded to your project directory.

You can use the download URL provided by Catalyst to download the result file even when you are not working in your CLI. You must execute it as an API command.
The CSV result file will contain a list of all the records matching your export job query.
--table <name|id>
The --table option enables you to specify the table name or Table ID of the table, where the records must be read from.
As mentioned earlier, if you don’t specify the table identifier in the JSON file, or if you don’t pass a JSON file during the command execution, you must specify it using this option.
Catalyst will consider the table specified in the option as the higher priority, over the one specified in the JSON file. If the table is not specified in either places, the CLI will display an error message during command execution.
For example, you can specify the table identifier in the following way:
The CLI will then execute the export operation, bulk read the records from the specified table, and provide the results in the same way.
--page <page>
As discussed in the JSON parameters section, you can specify a page value to indicate the range of records to fetch from the table.
For example, you can fetch records from the range 200,001 to 400,000 by executing the following command:
--production
The --production option enables you to directly execute the export operation in the production environment of your Catalyst project. If you use this option, If you use this option, the records from the table in the production environment will be bulk read.
Last Updated 2025-02-19 15:51:40 +0530 IST
Yes
No
Send your feedback to us