Importación de Data Store
La sintaxis general del comando de importación de Data Store es:
Antes de discutir la ejecución del comando, veamos las operaciones y configuraciones disponibles para este comando en detalle.
Operaciones
Hay tres operaciones que se pueden realizar usando el comando de importación de Data Store:
- Insert: Inserta nuevas filas de datos en la tabla desde el archivo CSV
- Update: Actualiza filas de datos existentes en la tabla
- Upsert: Habilita las operaciones de inserción y actualización al mismo tiempo. Si el registro ya existe, la fila se actualiza. Si el registro no existe, se inserta una nueva fila con los datos.
Puedes especificar la operación a ejecutar en el archivo JSON de configuración de entrada.
Archivo CSV de entrada
Como se mencionó anteriormente, la operación de importación escribe registros de forma masiva desde un archivo CSV a una tabla. Puedes proporcionar el archivo CSV de dos maneras:
- Puedes subir el archivo CSV que contiene los registros a un Bucket en Stratus antes de comenzar a ejecutar esta operación. En este caso, debes especificar la Object URL única generada para el archivo en Stratus, en el archivo JSON de configuración que pasas durante la ejecución del comando.
- Si no pasas ningún archivo JSON de configuración con el comando, debes especificar la ruta del archivo CSV en tu sistema durante la ejecución del comando, como se muestra en la sintaxis general anterior. Catalyst entonces subirá el archivo CSV que proporcionas al Bucket de tu proyecto y obtendrá automáticamente su Object URL para la ejecución. Puedes seleccionar la ruta para guardar el archivo en Stratus.
Catalyst considerará el archivo CSV especificado con el comando como la prioridad más alta, sobre la Object URL especificada en el archivo JSON. Si el archivo CSV no se especifica en ninguno de los dos lugares, el CLI mostrará un mensaje de error durante la ejecución del comando.
-
La primera fila del archivo CSV debe ser la fila de encabezado. En otras palabras, los nombres de las columnas deben estar presentes como fila de encabezado.
-
El archivo CSV debe contener datos en el formato que cumple con los estándares de archivos CSV. Si el archivo no está en el formato estándar, los datos escritos en la tabla pueden corromperse.
-
Podrás insertar 5000 registros en cada tabla por proyecto en el entorno de desarrollo. Si el archivo CSV contiene más registros que eso, los primeros 5000 registros se escribirán en la tabla. Los demás se omitirán en el entorno de desarrollo. No hay límites superiores para la inserción de datos en el entorno de producción.
Estructura del archivo JSON de configuración
A continuación se muestra un archivo JSON de configuración de ejemplo que especifica los requisitos de la operación de importación, que puedes pasar opcionalmente durante la ejecución del comando:
{
"table_identifier" : "ZylkerEmpDatabase",
"operation" : "upsert",
"object_url" : "https://bucket-name-development.zohostratus.com/object-name",
"callback" : {
"url" : "https://hr.zylker.com/es/EmpRecords/_callback.php.com",
"headers" : {
"src" : "ZCatalyst",
"operation" : "bulkwriteAPI"
}
},
"find_by" : "EmpID",
"fk_mapping" : [
{
"local_column" : "EmpID",
"reference_column" : "EmployeeID"
},
{
"local_column" : "DeptID",
"reference_column" : "DepartmentID"
}
]
}
Los parámetros admitidos por el archivo JSON de configuración se definen a continuación:
| Atributos | Descripción |
|---|---|
| table_identifier (String, Obligatorio) |
El ID único de la tabla o el nombre de la tabla donde se deben importar los datos. También puedes pasar el identificador de tabla usando la opción –table. |
| operation (String, Opcional) |
Especifica la operación a ejecutar. Valores permitidos:insert, update, upsert Operación predeterminada: insert |
| object_url (String, Obligatorio) |
La Object URL única del archivo CSV en Stratus. También puedes especificar la ruta del archivo CSV con el comando. |
| find_by (String, Obligatorio para operaciones update y upsert. No obligatorio para la operación insert) |
La columna única mediante la cual se identifican los registros. Por ejemplo, si especificas una columna única llamada 'EmployeeID' como el valor de find_by, Catalyst buscará los registros en la tabla de Data Store usando el valor de EmployeeID. Para la operación de actualización, Catalyst actualizará las filas que coincidan con el valor de EmployeeID del archivo CSV. Para la operación upsert, Catalyst actualizará las filas existentes e insertará nuevas filas si no hay registros con valores de EmployeeID coincidentes. Update: Puede ser una columna con valores únicos configurados en el Data Store, o el ROWID generado por Catalyst para los registros. Upsert: Solo puedes especificar una columna con valores únicos configurados en el Data Store. No podrás especificar el ROWID como valor de find_by. Esto se debe a que upsert insertará nuevas filas si no se encuentran coincidencias, y los valores de ROWID no estarán disponibles para filas que no existan en el Data Store. Insert: Si especificas una columna find_by para una operación de inserción, los registros que coincidan con los valores de la columna del archivo CSV se omitirán y no se insertarán en la tabla de Data Store. Esto se debe a que insert no puede actualizar si un registro dado ya existe. |
| fk_mapping (JSON, Opcional) |
Mapeo de claves foráneas para las columnas que son claves primarias en otras tablas. Se especifica si alguna columna importada del archivo CSV debe configurarse como clave foránea. Debes mapear las claves foráneas en el siguiente formato: { “local_column” : “local_column_name_1”, “reference_column” : “reference_column_name_1” } donde local_column es el nombre de la columna en la tabla donde se procesa la operación de escritura masiva, y reference_column es el nombre de la columna en la tabla en la que es clave primaria. |
| callback (JSON, Opcional) |
La sección donde puedes definir las propiedades de la URL de callback, donde se enviarán las respuestas JSON automáticas de los estados del trabajo. Las propiedades que se deben incluir en esta sección se indican en la tabla a continuación. |
Propiedades del callback
| Atributo | Descripción |
|---|---|
| url (String, Obligatorio si deseas especificar la URL de callback) |
La URL donde se enviarán las respuestas automáticas usando el método HTTP POST, cada vez que cambie el estado del trabajo. La información sobre los detalles del trabajo estará contenida en el cuerpo de la respuesta JSON. El CLI también mostrará una transmisión en tiempo real de la ejecución y el estado final del trabajo. |
| headers (String, Opcional) | Encabezados que necesitas que se pasen en la respuesta JSON a la URL de callback Debes especificar los encabezados como: { “{header_name_1}” : “{header_value_1}”, “{header_name_2}” : “{header_value_2}" } y así sucesivamente. |
| params (String, Opcional) |
Parámetros que necesitas que se agreguen a la URL de callback Debes especificar los parámetros como: { “{param_name_1}” : “{param_value_1}”, “{param_name_2}” : “{param_value_2}" } y así sucesivamente. |
Estados de procesamiento del trabajo de importación
Hay tres estados de procesamiento del trabajo para la operación de importación:
- In-Progress: El trabajo entra en este estado tan pronto como ejecutas el comando de importación. El CLI
mostrará un parámetro job_id que puedes usar para
verificar el estado de la ejecución del trabajo para respuestas posteriores de forma manual, si
no has configurado una URL de callback en el JSON.
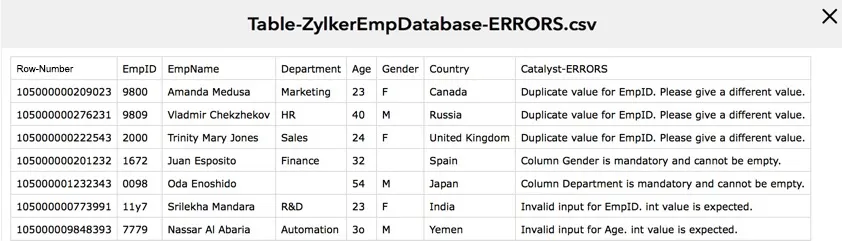
Si has configurado una URL de callback, también se publicará una respuesta de estado con el job_id en la URL en el formato que definiste. - Success: Si la operación de importación es exitosa, Catalyst proporcionará una URL de descarga donde puedes descargar un archivo CSV de reporte que contiene los detalles de la ejecución del trabajo. Catalyst también te permite descargar el archivo de reporte directamente a tu sistema a través del CLI. Si has configurado una URL de callback, esta respuesta también se publicará en ella.
- Failed: Si la operación de importación falla, el CLI mostrará los detalles de los errores que ocurrieron. Si has configurado una URL de callback, esta respuesta también se publicará en ella.
Opciones de importación
El proceso de ejecución del comando de importación se describe en detalle en esta sección, para cada opción. El comando de importación de Data Store admite las siguientes opciones:
--config <path>
La opción config te permite definir la ruta del archivo JSON de configuración en tu sistema.
Por ejemplo, puedes ejecutar la operación de importación y pasar la ruta del archivo JSON como se muestra a continuación:

El CLI entonces programará automáticamente la ejecución del trabajo y lo marcará como “in-progress”. Mostrará una transmisión en tiempo real del proceso de ejecución, junto con el job_id.
Si el trabajo se ejecuta exitosamente, el CLI te solicitará que descargues el archivo de reporte a tu sistema. Escribe ‘y’, luego presiona Enter para descargar.
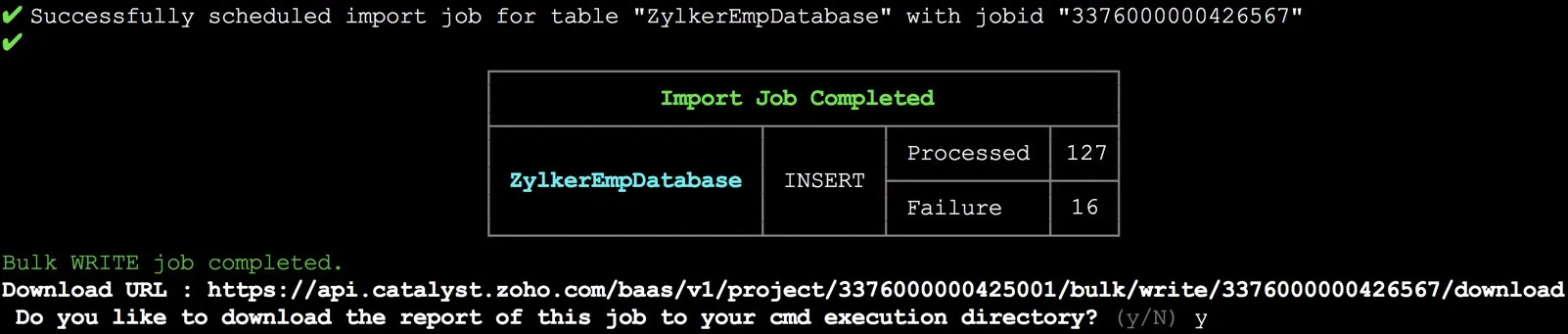
El archivo ZIP que contiene el archivo de reporte se descargará en tu directorio de proyecto.

Puedes usar la URL de descarga proporcionada por Catalyst para descargar el reporte incluso cuando no estés trabajando en tu CLI. Debes ejecutarlo como un comando de API.
--table <name|id>
La opción --table te permite especificar el nombre de la tabla o el Table ID de la tabla, en la cual se deben escribir los registros.
Como se mencionó anteriormente, si no especificas el identificador de tabla en el archivo JSON, o si no pasas un archivo JSON durante la ejecución del comando, debes especificarlo usando esta opción.
Catalyst considerará la tabla especificada en la opción como la prioridad más alta, sobre la especificada en el archivo JSON. Si la tabla no se especifica en ninguno de los dos lugares, el CLI mostrará un mensaje de error durante la ejecución del comando.
Por ejemplo, puedes especificar el identificador de tabla junto con la ruta del archivo CSV de la siguiente manera:

Si especificas la ruta del archivo CSV, el CLI entonces ejecutará la operación de importación, escribirá los registros de forma masiva en la tabla especificada y proporcionará el archivo de reporte de la misma manera.

--production
La opción –production te permite ejecutar directamente la operación de importación en el entorno de producción de tu proyecto de Catalyst. Si usas esta opción, los registros del archivo CSV de entrada se escribirán de forma masiva en la tabla especificada directamente en producción.
Última actualización 2026-03-20 21:51:56 +0530 IST
Yes
No
Send your feedback to us