Exportación de Data Store
Introducción
La sintaxis general del comando de exportación de Data Store es:
Estructura del archivo JSON de configuración
El comando de exportación de Data Store obtendrá los registros de la tabla que especifiques, que coincidan con los criterios que definas en el archivo JSON de configuración de entrada. Si no pasas el archivo JSON con el comando, o si no especificas ningún criterio, todos los registros de la tabla se leerán por defecto.
A continuación se muestra un archivo JSON de configuración de ejemplo que especifica los requisitos de la operación de exportación, que puedes pasar opcionalmente durante la ejecución del comando:
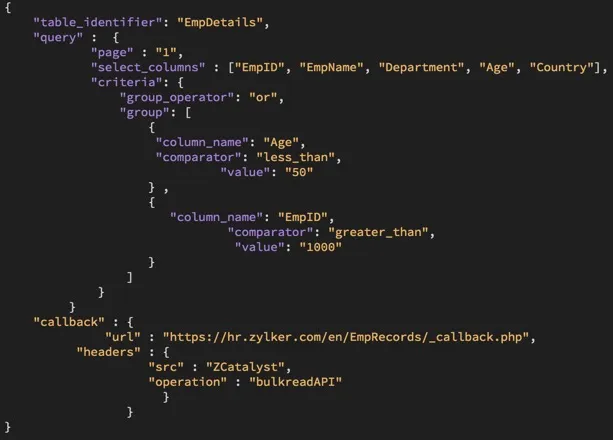
Los parámetros admitidos por el archivo JSON de configuración se definen a continuación:
| Atributos | Descripción |
|---|---|
| table_identifier (String, Obligatorio) |
El ID único de la tabla o el nombre de la tabla de donde se deben exportar los datos. También puedes pasar el identificador de tabla usando la opción –table. |
| query (JSON, Opcional) |
La sección donde puedes definir las condiciones y criterios para el trabajo de exportación |
| page (Numérico, Opcional) |
El archivo CSV generado como resultado del proceso de lectura masiva contiene doscientos mil registros en una página. El valor de página '1' indica que se exportarán los primeros doscientos mil registros que coincidan con tu consulta. Puedes obtener registros posteriores aumentando el valor de página. Por ejemplo, si deseas obtener registros del rango 200,001 a 400,000, debes especificar el valor de página como '2'. Valor predeterminado: 1 También puedes especificar el valor de página usando la opción –page. |
| select_columns (Array, Opcional) |
Columnas específicas en los registros que necesitan obtenerse de la tabla. Si no especificas las columnas, se seleccionarán y obtendrán todas las columnas. Puedes incluir múltiples columnas en un array. |
| callback (JSON, Opcional) |
La sección donde puedes definir las propiedades de la URL de callback, donde se enviarán las respuestas JSON automáticas de los estados del trabajo |
| url (String, Obligatorio si deseas especificar la URL de callback |
La URL donde se enviarán las respuestas automáticas usando el método HTTP POST, cada vez que cambie el estado del trabajo. La información sobre los detalles del trabajo estará contenida en el cuerpo de la respuesta JSON. El CLI también mostrará una transmisión en tiempo real de la ejecución y el estado final del trabajo. |
| headers (String, Opcional) |
Encabezados que necesitas que se pasen en la respuesta JSON a la URL de callback Debes especificar los encabezados como: { “{header_name_1}” : “{header_value_1}”, “{header_name_2}” : “{header_value_2}" } y así sucesivamente. |
| params (String, Opcional) |
Parámetros que necesitas que se agreguen a la URL de callback Debes especificar los parámetros como: { “{param_name_1}” : “{param_value_1}”, “{param_name_2}” : “{param_value_2}" } y así sucesivamente. |
| criteria (JSON, Opcional) |
Un conjunto de condiciones basadas en las cuales se obtendrán los registros. Las propiedades que se deben incluir en esta sección se indican en la tabla a continuación. |
Propiedades de criterios
| Atributos | Descripción |
|---|---|
| group_operator (String, Obligatorio si deseas especificar los criterios |
El operador que vinculará los grupos de criterios entre sí. Operadores admitidos: AND, OR Si defines dos o más grupos de criterios, puedes usar el operador AND o OR. Por ejemplo, puedes especificar un criterio como "column1 equal value 1 AND column2 contains value 2" en el formato especificado en la sección anterior. Nota: No podrás usar combinaciones de ambos operadores. Puedes usar AND o OR en una sola ejecución de comando. |
| group (JSON, Obligatorio si deseas especificar los criterios) |
Puedes incluir hasta 25 conjuntos de criterios en esta sección. El archivo JSON de ejemplo muestra 2 conjuntos de criterios. Nota: Solo puedes incluir un grupo general con un operador de grupo en una sola ejecución. |
| column_name (String, Obligatorio si deseas especificar los criterios) |
Nombre de la columna específica de la tabla para la cual se deben definir los criterios |
| comparator (String, Obligatorio si deseas especificar los criterios) |
El operador de comparación que coincide el nombre de la columna con el valor del criterio Comparadores admitidos: equal, not_equal, greater_than, greater_equal, less_than, less_equal, starts_with, ends_with, contains, not_contains, in, not_in, between, not_between Nota:
|
| value (String, Obligatorio si deseas especificar los criterios) |
El valor para la columna específica en el registro que deseas definir como criterio |
Estados de procesamiento del trabajo de exportación
Hay tres estados de procesamiento del trabajo para la operación de exportación:
- In-Progress: El trabajo entra en este estado tan pronto como ejecutas el comando de importación. El CLI mostrará un parámetro job_id que puedes usar para verificar el estado de la ejecución del trabajo para respuestas posteriores de forma manual, si no has configurado una URL de callback en el JSON.
Si has configurado una URL de callback, también se publicará una respuesta de estado con el job_id en la URL en el formato que definiste. - Success: Si la operación de exportación es exitosa, Catalyst proporcionará una URL de descarga donde puedes descargar el archivo CSV que contiene los registros que coinciden con tu consulta. Catalyst también te permite descargar el archivo de resultados directamente a tu sistema a través del CLI. Si has configurado una URL de callback, esta respuesta también se publicará en ella.
- Failed: Si la operación de exportación falla, el CLI mostrará los detalles de los errores que ocurrieron. Si has configurado una URL de callback, esta respuesta también se publicará en ella.
Opciones de exportación
El proceso de ejecución del comando de exportación se describe en detalle en esta sección, para cada opción. El comando de exportación de Data Store admite las siguientes opciones:
--config <path>
La opción –config te permite definir la ruta del archivo JSON de configuración en tu sistema.
Por ejemplo, puedes ejecutar la operación de exportación y pasar la ruta del archivo JSON como se muestra a continuación:

El CLI entonces programará automáticamente la ejecución del trabajo y lo marcará como “in-progress”. Mostrará una transmisión en tiempo real del proceso de ejecución, junto con el job_id.
Si el trabajo se ejecuta exitosamente, el CLI te solicitará que descargues el archivo de resultados a tu sistema. Escribe ‘y’, luego presiona Enter para descargar.

El archivo ZIP que contiene el archivo de resultados se descargará en tu directorio de proyecto.

Puedes usar la URL de descarga proporcionada por Catalyst para descargar el archivo de resultados incluso cuando no estés trabajando en tu CLI. Debes ejecutarlo como un comando de API.
El archivo CSV de resultados contendrá una lista de todos los registros que coinciden con tu consulta del trabajo de exportación.
--table <name|id>
La opción --table te permite especificar el nombre de la tabla o el Table ID de la tabla, de donde se deben leer los registros.
Como se mencionó anteriormente, si no especificas el identificador de tabla en el archivo JSON, o si no pasas un archivo JSON durante la ejecución del comando, debes especificarlo usando esta opción.
Catalyst considerará la tabla especificada en la opción como la prioridad más alta, sobre la especificada en el archivo JSON. Si la tabla no se especifica en ninguno de los dos lugares, el CLI mostrará un mensaje de error durante la ejecución del comando.
Por ejemplo, puedes especificar el identificador de tabla de la siguiente manera:
El CLI entonces ejecutará la operación de exportación, leerá de forma masiva los registros de la tabla especificada y proporcionará los resultados de la misma manera.
--page <page>
Como se discutió en la sección de parámetros JSON, puedes especificar un valor de página para indicar el rango de registros a obtener de la tabla.
Por ejemplo, puedes obtener registros del rango 200,001 a 400,000 ejecutando el siguiente comando:
--production
La opción --production te permite ejecutar directamente la operación de exportación en el entorno de producción de tu proyecto de Catalyst. Si usas esta opción, los registros de la tabla en el entorno de producción se leerán de forma masiva.
Última actualización 2026-03-20 21:51:56 +0530 IST
Yes
No
Send your feedback to us