Data Storeインポート
Data Storeインポートコマンドの一般的な構文は以下の通りです。
コマンドの実行について説明する前に、このコマンドで利用可能な操作と設定について詳しく見ていきましょう。
操作
Data Storeインポートコマンドを使用して実行できる操作は3つあります。
- Insert: CSVファイルからテーブルにデータの新しい行を挿入します
- Update: テーブル内の既存のデータ行を更新します
- Upsert: 挿入と更新の両方の操作を同時に実行できます。レコードが既に存在する場合、行が更新されます。レコードが存在しない場合、データを含む新しい行が挿入されます。
入力JSON設定ファイルで実行する操作を指定できます。
入力CSVファイル
前述の通り、インポート操作はCSVファイルからテーブルにレコードを一括書き込みします。CSVファイルは2つの方法で提供できます。
- この操作の実行を開始する前に、レコードを含むCSVファイルをStratusのバケットにアップロードできます。この場合、コマンド実行時に渡すJSON設定ファイルに、Stratusでファイルに生成された一意のオブジェクトURLを指定する必要があります。
- コマンドにJSON設定ファイルを渡さない場合は、上記の一般構文に示されているように、コマンド実行でシステム内のCSVファイルのパスを指定する必要があります。Catalystは指定されたCSVファイルをプロジェクトのバケットにアップロードし、実行用のオブジェクトURLを自動的に取得します。Stratusにファイルを保存するパスを選択できます。
Catalystは、JSONファイルで指定されたオブジェクトURLよりも、コマンドで指定されたCSVファイルを優先します。どちらにもCSVファイルが指定されていない場合、CLIはコマンド実行中にエラーメッセージを表示します。
-
CSVファイルの最初の行はヘッダー行でなければなりません。つまり、カラム名がヘッダー行として存在する必要があります。
-
CSVファイルはCSVファイル標準に準拠した形式でデータを含む必要があります。ファイルが標準形式でない場合、テーブルに書き込まれたデータが破損する可能性があります。
-
開発環境では、プロジェクトごとに各テーブルに5000件のレコードを挿入できます。CSVファイルにそれ以上のレコードが含まれている場合、最初の5000件のレコードがテーブルに書き込まれます。開発環境ではその他のレコードはスキップされます。本番環境ではデータ挿入の上限はありません。
JSON設定ファイルの構造
インポート操作の要件を指定するサンプルJSON設定ファイルは、コマンド実行時にオプションで渡すことができ、以下に示されています。
{
"table_identifier" : "ZylkerEmpDatabase",
"operation" : "upsert",
"object_url" : "https://bucket-name-development.zohostratus.com/object-name",
"callback" : {
"url" : "https://hr.zylker.com/ja/EmpRecords/_callback.php.com",
"headers" : {
"src" : "ZCatalyst",
"operation" : "bulkwriteAPI"
}
},
"find_by" : "EmpID",
"fk_mapping" : [
{
"local_column" : "EmpID",
"reference_column" : "EmployeeID"
},
{
"local_column" : "DeptID",
"reference_column" : "DepartmentID"
}
]
}
JSON設定ファイルでサポートされているパラメータは以下のように定義されています。
| 属性 | 説明 |
|---|---|
| table_identifier (String、必須) |
データをインポートするテーブルの一意のIDまたはテーブル名。–tableオプションを使用してテーブル識別子を渡すこともできます。 |
| operation (String、任意) |
実行する操作を指定します。 使用可能な値:insert、update、upsert デフォルト操作: insert |
| object_url (String、必須) |
Stratus内のCSVファイルの一意のID。 コマンドでCSVファイルパスを指定することもできます。 |
| find_by (String、updateおよびupsert操作では必須。insert操作では不要) |
レコードを識別するために使用される一意のカラム。 たとえば、「EmployeeID」という一意のカラムをfind_by値として指定した場合、CatalystはData Storeテーブル内のレコードをEmployeeID値を使用して検索します。更新操作では、CSVファイルのEmployeeID値に一致する行を更新します。Upsert操作では、既存の行を更新し、一致するEmployeeID値のレコードがない場合は新しい行を挿入します。 Update: Data Storeで設定された一意の値を持つカラム、またはCatalystがレコードに生成したROWIDを使用できます。 Upsert: Data Storeで設定された一意の値を持つカラムのみ指定できます。ROWIDをfind_by値として指定することはできません。これは、Upsertは一致するものが見つからない場合に新しい行を挿入しますが、Data Storeに存在しない行にはROWID値が利用できないためです。 Insert: Insert操作にfind_byカラムを指定した場合、CSVファイルのカラム値に一致するレコードはスキップされ、Data Storeテーブルに挿入されません。これは、Insertは指定されたレコードが既に存在する場合に更新できないためです。 |
| fk_mapping (JSON、任意) |
他のテーブルで主キーであるカラムの外部キーマッピング。CSVファイルからインポートされたカラムを外部キーとして設定する必要がある場合に指定します。 外部キーは以下の形式でマッピングする必要があります: { “local_column” : “local_column_name_1”, “reference_column” : “reference_column_name_1” } ここで、local_columnは一括書き込み操作が処理されるテーブルのカラム名、reference_columnは主キーであるテーブルのカラム名です。 |
| callback (JSON、任意) |
ジョブステータスの自動JSONレスポンスが送信されるコールバックURLのプロパティを定義するセクション。このセクションに含めるプロパティは以下の表に記載されています。 |
コールバックプロパティ
| 属性 | 説明 |
|---|---|
| url (String、コールバックURLを指定する場合は必須) |
ジョブステータスが変更されるたびに、HTTP POSTメソッドを使用して自動レスポンスが送信されるURL。ジョブの詳細情報はJSONレスポンスの本文に含まれます。 CLIは実行のライブストリームと最終的なジョブステータスも表示します。 |
| headers (String、任意) | コールバックURLへのJSONレスポンスで渡す必要があるヘッダー ヘッダーは以下のように指定する必要があります: { “{header_name_1}” : “{header_value_1}”, “{header_name_2}” : “{header_value_2}" } 以下同様です。 |
| params (String、任意) |
コールバックURLに追加する必要があるパラメータ パラメータは以下のように指定する必要があります: { “{param_name_1}” : “{param_value_1}”, “{param_name_2}” : “{param_value_2}" } 以下同様です。 |
インポートジョブの処理状態
インポート操作には3つのジョブ処理状態があります。
- 進行中: インポートコマンドを実行するとすぐにジョブがこの状態に入ります。CLIはjob_idパラメータを表示し、JSONにコールバックURLを設定していない場合は、これを使用して後続のレスポンスのジョブ実行ステータスを手動で確認できます。
コールバックURLを設定している場合、定義した形式でjob_idを含む状態レスポンスがURLにも送信されます。 - 成功: インポート操作が成功した場合、Catalystはジョブ実行の詳細を含むCSVレポートファイルをダウンロードできるダウンロードURLを提供します。Catalystでは、CLIを通じてレポートファイルをシステムに直接ダウンロードすることもできます。コールバックURLを設定している場合、このレスポンスもURLに送信されます。
- 失敗: インポート操作が失敗した場合、CLIは発生したエラーの詳細を表示します。コールバックURLを設定している場合、このレスポンスもURLに送信されます。
インポートオプション
インポートコマンドの実行プロセスは、各オプションについてこのセクションで詳しく説明されています。Data Storeインポートコマンドは以下のオプションをサポートしています。
--config <path>
configオプションを使用すると、システム内のJSON設定ファイルのパスを定義できます。
たとえば、以下のようにインポート操作を実行してJSONファイルパスを渡すことができます。

CLIは自動的にジョブの実行をスケジュールし、「進行中」としてマークします。job_idとともに実行プロセスのライブストリームを表示します。
ジョブが正常に実行された場合、CLIはレポートファイルをシステムにダウンロードするよう求めます。「y」と入力し、Enterを押してダウンロードします。
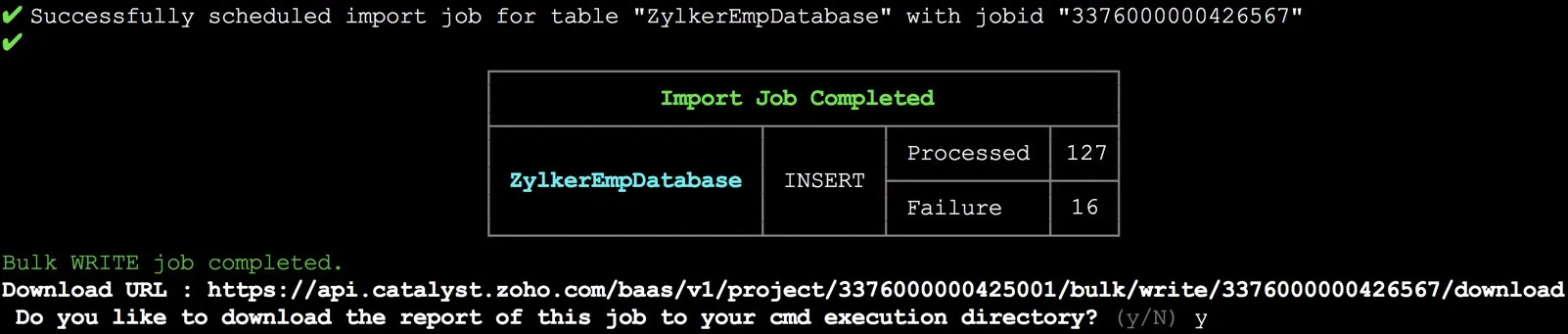
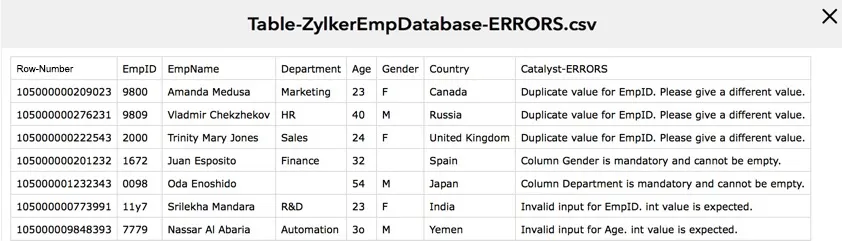
レポートファイルを含むZIPファイルがプロジェクトディレクトリにダウンロードされます。

Catalystが提供するダウンロードURLを使用して、CLIで作業していないときでもレポートをダウンロードできます。APIコマンドとして実行する必要があります。
--table <name|id>
--tableオプションを使用すると、レコードを書き込むテーブルのテーブル名またはテーブルIDを指定できます。
前述の通り、JSONファイルでテーブル識別子を指定しない場合、またはコマンド実行時にJSONファイルを渡さない場合は、このオプションを使用して指定する必要があります。
Catalystは、JSONファイルで指定されたテーブルよりも、オプションで指定されたテーブルを優先します。どちらにもテーブルが指定されていない場合、CLIはコマンド実行中にエラーメッセージを表示します。
たとえば、以下の方法でCSVファイルパスとともにテーブル識別子を指定できます。

CSVファイルパスを指定した場合、CLIはインポート操作を実行し、指定されたテーブルにレコードを一括書き込みし、同じ方法でレポートファイルを提供します。

--production
–productionオプションを使用すると、Catalystプロジェクトの本番環境でインポート操作を直接実行できます。このオプションを使用すると、入力CSVファイルのレコードが本番環境の指定されたテーブルに直接一括書き込みされます。
最終更新日 2026-02-23 18:09:41 +0530 IST
Yes
No
Send your feedback to us