Algoritmos de Series Temporales
El pronóstico de series temporales es una tarea de analítica predictiva que implica predecir puntos de datos futuros utilizando los datos históricos recopilados a lo largo del tiempo. Profundicemos en cómo funciona el pronóstico en series temporales y exploremos los diferentes algoritmos que se utilizan para generar modelos de pronóstico.
Pronóstico
El pronóstico implica el uso de métodos estadísticos para predecir valores futuros examinando las tendencias y patrones en datos pasados. Este análisis ayuda a los propietarios de negocios a tomar decisiones bien informadas sobre el curso de acción futuro basándose en las predicciones generadas por el modelo.
Los algoritmos de pronóstico de series temporales pueden clasificarse en dos categorías: univariados y multivariados, cada uno conduciendo a la creación de tipos correspondientes de modelos.
1. Pronóstico Univariado
Los modelos de pronóstico univariados se construyen utilizando conjuntos de datos univariados, que contienen solo una única característica o variable que se registra a lo largo del tiempo. Estos modelos se centran exclusivamente en los patrones temporales, tendencias y estacionalidad de esa única variable para pronósticos futuros, sin incorporar la influencia de otros factores.
Los algoritmos utilizados para construir los modelos de pronóstico univariados incluyen:
- Moving Average - MA
- Exponential Smoothing
- Holt Winter’s Method
- Auto Autoregressive Integrated Moving Average - Auto ARIMA
- Seasonal Autoregressive Integrated Moving Average - SARIMA
- Autoregressive Moving Average - ARMA
- Auto Regressor Entendamos cómo funciona cada uno de los algoritmos en detalle.
a. Moving Average
El modelo Moving Average (MA) es una técnica estadística comúnmente utilizada para pronósticos en el análisis de series temporales. En lugar de calcular el promedio de puntos de datos pasados, predice valores futuros basándose en una combinación lineal de errores de pronóstico pasados (o residuos) durante un número fijo de períodos, conocido como el “tamaño de ventana”. Este método suaviza las fluctuaciones aleatorias, haciéndolo útil para identificar tendencias y patrones a corto plazo en los datos.
Aunque el modelo MA es fácil de aplicar y puede ser útil para varios tipos de datos de series temporales, se basa únicamente en errores pasados y no tiene en cuenta directamente los valores pasados u otros factores externos que puedan afectar los datos. Como resultado, a menudo se recomienda combinar el modelo Moving Average con otros métodos de pronóstico, como los modelos AutoRegressive, para mejorar la precisión y capturar dinámicas más complejas en los datos.
El número de errores de pronóstico pasados utilizados en un modelo Moving Average (MA) está definido por el orden o retardo MA (q). El orden MA indica cuántos términos de error anteriores (retardos de los residuos) se incluyen en el modelo para predecir el valor actual.
Por ejemplo, en un modelo MA(q):
- Si q = 1, el modelo utiliza el término de error anterior (el primer retardo del residuo).
- Si q = 2, utiliza los dos términos de error anteriores (el primer y segundo retardo), y así sucesivamente. La elección del orden MA puede impactar significativamente en el rendimiento del modelo.
Ventajas
- Este algoritmo Moving Average es adecuado para pronósticos a corto plazo, como predecir ventas para los próximos períodos.
- Puede ayudar a eliminar el ruido de los datos de series temporales, facilitando la identificación de patrones o tendencias subyacentes al suavizar las fluctuaciones aleatorias.
Desventajas
- El modelo Moving Average (MA) no es adecuado para pronósticos a largo plazo ya que solo se basa en residuos (errores) de pronóstico pasados y no tiene en cuenta directamente los valores pasados u otros factores externos que puedan afectar los datos a largo plazo.
- Puede reaccionar lentamente a cambios o tendencias repentinas en los datos según el tamaño de ventana de residuos utilizados para las predicciones.
- Los modelos MA se utilizan principalmente para pronósticos de series temporales univariadas, donde el enfoque está en una sola variable a lo largo del tiempo y sus errores pasados. Sin embargo, en pronósticos de series temporales multivariadas, donde están involucradas múltiples variables, las medias móviles no funcionan bien.
- En el análisis de series temporales multivariadas, el objetivo es a menudo comprender las relaciones entre múltiples variables y aprovechar estas correlaciones para un mejor pronóstico.
- La aplicación directa de un modelo simple de media móvil a variables individuales de forma independiente en datos multivariados no logra capturar las interdependencias potenciales entre las variables.
b. Auto Regressive Model
Los modelos AutoRegressive (AR) son una clase de modelos estadísticos comúnmente utilizados en el análisis de series temporales para pronosticar valores futuros utilizando valores pasados en la serie temporal como entrada. Son particularmente útiles para capturar dependencias temporales en los datos evaluando la correlación entre valores precedentes y subsiguientes en la serie. El modelo predice valores futuros como una combinación lineal de observaciones pasadas, basándose en la suposición de que los valores pasados tienen una influencia directa en el comportamiento futuro.
El orden AR (p), puede definirse como el número de observaciones pasadas utilizadas en un modelo AutoRegressive (AR). Indica cuántos valores anteriores (retardos) de la serie temporal se incluyen en el modelo para predecir el valor actual.
Por ejemplo, en un modelo AR(p):
- Si p = 1, el modelo utiliza el valor anterior (el primer retardo).
- Si p = 2, utiliza los dos valores anteriores (el primer y segundo retardo), y así sucesivamente. La elección del orden AR puede impactar significativamente en el rendimiento del modelo.
Ventajas
- Los modelos AR son efectivos para capturar las dependencias temporales presentes en los datos de series temporales. Al regresar el valor actual sobre sus propios valores pasados, pueden capturar patrones y tendencias en los datos.
- Los parámetros de los modelos AR tienen interpretaciones claras. Cada parámetro autorregresivo representa la influencia de un valor retrasado específico sobre el valor actual, lo que facilita la comprensión de la relación entre observaciones pasadas y presentes.
- Los modelos AR son robustos frente a valores atípicos y manejan bien los datos ruidosos. Pueden filtrar eficazmente las fluctuaciones a corto plazo y centrarse en capturar tendencias a largo plazo en los datos.
- Los modelos AR son computacionalmente eficientes, particularmente para conjuntos de datos de tamaño pequeño a moderado. Requieren relativamente menos parámetros en comparación con otros modelos de series temporales, lo que los hace adecuados para análisis y pronósticos rápidos.
Desventajas
- Los modelos AR asumen una relación lineal entre observaciones pasadas y presentes. Esta suposición puede no cumplirse para todos los datos de series temporales, particularmente para relaciones no lineales o patrones complejos.
- Los modelos AR asumen que la serie temporal subyacente es estacionaria, lo que significa que sus propiedades estadísticas no cambian a lo largo del tiempo. Sin embargo, muchas series temporales del mundo real exhiben comportamiento no estacionario, lo que puede limitar la aplicabilidad de los modelos AR.
- Elegir el orden apropiado (AR lag(p)) para el modelo AR puede ser desafiante y puede requerir experimentación iterativa o diagnósticos estadísticos. Seleccionar un orden incorrecto puede llevar a un rendimiento deficiente del modelo y pronósticos inexactos.
- Los modelos AR pueden tener dificultades para proporcionar pronósticos precisos a largo plazo, especialmente cuando los datos subyacentes son altamente volátiles o están sujetos a cambios estructurales.
c. ARMA Model
ARMA (AutoRegressive Moving Average) es un método de pronóstico de series temporales que combina tanto componentes AutoRegressive como Moving Average. Construye un modelo estadístico utilizando los valores pasados del componente AutoRegressive y los residuos (errores) pasados del componente Moving Average para predecir valores futuros. Este modelo se utiliza particularmente para capturar dependencias y patrones a corto plazo en datos de series temporales estacionarias.
- Componente Autoregressive (AR): En el componente autorregresivo, el valor actual de la serie temporal se modela como una combinación lineal de sus valores anteriores. El “auto” en autorregresivo indica que el valor actual se regresa sobre sus propios valores pasados. Valores más altos de p capturan dependencias más complejas.
- Componente Moving Average (MA): En el componente de media móvil, el valor actual de la serie temporal se modela como una combinación lineal de los errores de pronóstico pasados. Los parámetros de la media móvil determinan los pesos asignados a los errores de pronóstico pasados para predecir el valor actual. Similar a los modelos autorregresivos, valores más altos de q capturan dependencias más complejas.
Los modelos ARMA combinan tanto componentes autorregresivos como de media móvil para capturar las dependencias temporales y las fluctuaciones aleatorias presentes en los datos.
Un modelo ARMA(p, q) se representa como la suma de los componentes AR (p) y MA (q).
Ventajas
- Los modelos ARMA pueden capturar una amplia gama de patrones y dinámicas presentes en los datos de series temporales, haciéndolos versátiles para diversas aplicaciones.
- Los parámetros de los modelos ARMA tienen interpretaciones claras, permitiendo a los analistas comprender las relaciones subyacentes entre observaciones pasadas y predicciones futuras.
- Los modelos ARMA son robustos frente a valores atípicos y pueden manejar bien los datos ruidosos, haciéndolos adecuados para conjuntos de datos del mundo real con irregularidades.
- Los modelos ARMA son computacionalmente eficientes, particularmente para conjuntos de datos de tamaño pequeño a moderado, permitiendo una estimación rápida del modelo y pronósticos.
Desventajas
- Los modelos ARMA asumen que la serie temporal subyacente es estacionaria, lo que significa que sus propiedades estadísticas no cambian a lo largo del tiempo. Sin embargo, muchas series temporales del mundo real exhiben comportamiento no estacionario, lo que puede limitar la aplicabilidad de los modelos ARMA.
- Los modelos ARMA pueden tener dificultades para proporcionar pronósticos precisos a largo plazo, especialmente cuando los datos subyacentes son altamente volátiles o están sujetos a cambios estructurales.
- Elegir el orden apropiado (p y q) para los componentes AR y MA de un modelo ARMA puede ser desafiante y puede requerir experimentación iterativa o diagnósticos estadísticos.
- El rendimiento de los modelos ARMA puede ser sensible a las estimaciones iniciales de los parámetros, lo que lleva a posibles problemas de convergencia o soluciones subóptimas, particularmente en espacios de parámetros de alta dimensionalidad.
d. ARIMA Model
El modelo ARIMA (AutoRegressive Integrated Moving Average) es un método estadístico popular diseñado para pronósticos de series temporales para manejar datos no estacionarios incorporando un componente de diferenciación además de los componentes AR y MA como en el modelo ARMA. Es un método versátil y potente, ya que puede aplicarse tanto a datos de series temporales estacionarias como no estacionarias.
Aquí hay un desglose de sus componentes:
- Término AutoRegressive (AR): Representa la relación entre una observación y un cierto número de observaciones retrasadas (pasos temporales anteriores). En un modelo AR (p), el valor de la serie en el tiempo ’t’ depende linealmente de los valores en los tiempos ’t-1’, ’t-2’, …, ’t-p'.
- Término Integrated (I): Se refiere a la diferenciación de las observaciones brutas para hacer la serie temporal estacionaria. La estacionariedad implica que las propiedades estadísticas de una serie temporal, como la media y la varianza, no cambian a lo largo del tiempo. El orden de diferenciación, denotado como ’d’, indica cuántas diferencias se requieren para lograr la estacionariedad.
- Término Moving Average (MA): Tiene en cuenta la relación entre una observación y un error residual de un modelo de media móvil aplicado a las observaciones retrasadas. En un modelo MA(q), el valor de la serie en el tiempo ’t’ depende linealmente de los términos de error en los tiempos ’t-1’, ’t-2’, …, ’t-q'.
El modelo ARIMA se denota como ARIMA(p, d, q), donde:
- ‘p’ es el orden de la parte autorregresiva.
- ’d’ es el grado de diferenciación.
- ‘q’ es el orden de la parte de media móvil. El modelo ARIMA realiza predicciones basándose en la combinación lineal de observaciones pasadas, diferenciación para estabilizar la serie, y un término de error que captura fluctuaciones inesperadas no explicadas por el modelo.
Auto ARIMA
Auto ARIMA busca automáticamente a través de un rango de posibles modelos ARIMA, incluyendo diferentes combinaciones de componentes autorregresivos (AR), integrados (I) y de media móvil (MA), para identificar el modelo que mejor se ajusta a los datos. Evalúa cada modelo basándose en criterios estadísticos como AIC (Criterio de Información de Akaike) o BIC (Criterio de Información Bayesiano) para determinar el modelo óptimo.
Ventajas
- ARIMA puede manejar una amplia gama de datos de series temporales, incluyendo datos económicos, financieros y sociales, haciéndolo aplicable en diversos campos.
- Los parámetros del modelo (p, d, q) pueden proporcionar información sobre las dinámicas subyacentes de la serie temporal, como el efecto de retardo y el impacto de la diferenciación.
- ARIMA se basa en principios estadísticos sólidos, convirtiéndolo en un método confiable para el análisis de series temporales.
- ARIMA puede generar pronósticos para períodos temporales futuros, proporcionando información valiosa para la toma de decisiones y la planificación.
- Los modelos ARIMA no requieren factores externos adicionales o covariables, lo que los hace relativamente sencillos de implementar e interpretar.
Desventajas
- ARIMA asume que la serie temporal es estacionaria o puede hacerse estacionaria mediante diferenciación. En la práctica, lograr la estacionariedad puede ser desafiante para algunos conjuntos de datos.
- Los modelos ARIMA tradicionales no son adecuados para capturar patrones estacionales en los datos. Se necesita ARIMA estacional (SARIMA) u otros métodos para datos estacionales.
- Son lineales y pueden no capturar eficazmente relaciones no lineales complejas presentes en algunos datos de series temporales.
- Los modelos ARIMA requieren una cantidad suficiente de datos históricos para estimar con precisión los parámetros del modelo. En casos de datos cortos o escasos, ARIMA puede no funcionar bien.
- ARIMA asume que las observaciones son independientes entre sí, lo cual puede no ser cierto para todos los datos de series temporales, particularmente en casos de autocorrelación o correlación serial.
e. SARIMA Model
Seasonal Autoregressive Integrated Moving Average (SARIMA) es una extensión del modelo ARIMA que incorpora estacionalidad en el análisis y pronóstico de datos de series temporales. Los modelos SARIMA son particularmente útiles para datos que exhiben tanto patrones no estacionales como estacionales:
- Diferenciación Estacional: SARIMA implica diferenciar la serie temporal no solo para eliminar tendencias sino también para eliminar patrones estacionales. Esto se hace restando la observación en el tiempo ’t’ de la observación en el tiempo ’t-s’, donde ’s’ representa el período estacional.
- Término Seasonal Autoregressive (SAR): El componente de retardo AR estacional tiene en cuenta la relación entre la observación actual y las observaciones pasadas en intervalos estacionales. Captura los patrones estacionales en los datos.
- Término Seasonal Moving Average (SMA): El componente de retardo MA estacional modela la dependencia entre la observación actual y los errores de pronóstico pasados en intervalos estacionales.
- Integración: Como en ARIMA, la integración se utiliza para hacer la serie temporal estacionaria mediante diferenciación. El orden de integración (denotado por ’d’) representa el número de diferencias no estacionales necesarias para lograr la estacionariedad.
- Términos Autoregressive (AR) y Moving Average (MA): Estos componentes, similares a ARIMA, capturan las dinámicas no estacionales de la serie temporal.
Ventajas
- SARIMA modela explícitamente los patrones estacionales en los datos, permitiendo pronósticos más precisos de series temporales con fluctuaciones periódicas, como datos de ventas mensuales o indicadores económicos trimestrales.
- Los modelos SARIMA pueden manejar una amplia gama de patrones estacionales, incluyendo estacionalidad multiplicativa y aditiva, así como patrones estacionales irregulares.
- Como ARIMA, los modelos SARIMA proporcionan parámetros interpretables (por ejemplo, AR, MA, AR estacional, MA estacional) que pueden ofrecer información sobre las dinámicas subyacentes de la serie temporal.
- Los modelos SARIMA pueden ser robustos a cambios en los patrones de datos subyacentes, siempre que se seleccionen el período estacional y los parámetros del modelo apropiados.
Desventajas
- Los modelos SARIMA son más complejos que los modelos ARIMA no estacionales, requiriendo parámetros adicionales para capturar las dinámicas estacionales. Esta complejidad puede hacer que la estimación e interpretación del modelo sean más desafiantes.
- Seleccionar el período estacional apropiado y determinar los órdenes de los términos AR, MA, AR estacional y MA estacional puede ser difícil y puede requerir diagnósticos y pruebas extensivas del modelo.
- Estimar modelos SARIMA, especialmente para grandes conjuntos de datos o modelos con muchos parámetros, puede ser computacionalmente intensivo y consumir mucho tiempo.
- SARIMA asume que la serie temporal es estacionaria después de la diferenciación. Asegurar la estacionariedad puede requerir un examen cuidadoso de los datos y un ajuste iterativo del modelo.
A pesar de estos desafíos, SARIMA sigue siendo una herramienta potente para el pronóstico de series temporales, para datos que exhiben tanto patrones no estacionales como estacionales. Con una especificación cuidadosa del modelo y selección de parámetros, los modelos SARIMA pueden proporcionar pronósticos precisos e información valiosa sobre los datos de series temporales.
f. Exponential Smoothing Model
El suavizado exponencial es un método de pronóstico de series temporales para datos univariados que puede extenderse para soportar datos con un componente de tendencia sistemática o estacional.
También realiza predicciones basadas en observaciones pasadas como ARIMA pero con una diferencia clave en cómo ponderan estas observaciones:
- Pesos Exponencialmente Decrecientes
- A diferencia de ARIMA, donde los pesos pueden ser arbitrarios, el Suavizado Exponencial asigna pesos exponencialmente decrecientes a las observaciones pasadas. Esto significa que las observaciones recientes tienen una influencia mucho mayor en el pronóstico que las más antiguas.
- Ejemplo: Si está prediciendo las ventas de hoy, las ventas de ayer tendrán un mayor impacto en el pronóstico que las ventas de hace una semana.
- Tipos de Suavizado Exponencial
- Simple Exponential Smoothing (SES): Adecuado para datos sin tendencia ni estacionalidad. Solo utiliza observaciones pasadas.
- Holt’s Linear Trend Model: Extiende SES para capturar tendencias en los datos.
- Holt-Winters Seasonal Model: Se extiende aún más para capturar la estacionalidad (patrones repetitivos como picos de ventas mensuales).
Ventajas
- Maneja diferentes patrones, lo que implica que puede adaptarse para manejar diferentes tipos de datos de series temporales, incluyendo aquellos con:
- Sin tendencia (Simple Exponential Smoothing)
- Tendencias lineales (Holt’s Linear Trend Model), y
- Patrones estacionales (Holt-Winters Seasonal Model)
- Requiere relativamente menos datos históricos en comparación con otros métodos de pronóstico más complejos como ARIMA o modelos de aprendizaje automático.
- Receptivo a los cambios porque las observaciones recientes reciben más peso, el método puede adaptarse rápidamente a cambios o desplazamientos en los datos.
Desventajas
- El suavizado exponencial puede tener dificultades para capturar relaciones complejas o fluctuaciones irregulares presentes en los datos.
- El rendimiento de los modelos de suavizado exponencial puede ser sensible a la elección de los parámetros de suavizado, como el factor de suavizado (alpha).
- El suavizado exponencial asume que la serie temporal subyacente es estacionaria, lo que significa que sus propiedades estadísticas permanecen constantes a lo largo del tiempo. Sin embargo, muchas series temporales del mundo real exhiben comportamiento no estacionario.
- Los modelos de suavizado exponencial son sensibles a los valores atípicos o valores extremos en los datos.
g. Holt Winter’s Seasonal Model
El método de Holt-Winters, también conocido como triple exponential smoothing, es una técnica ampliamente utilizada para pronosticar datos de series temporales, especialmente cuando se trata de datos que exhiben tendencia y estacionalidad. Extiende el suavizado exponencial simple para manejar estos componentes de manera más efectiva.
- Componente de Nivel (lt): Representa el valor promedio de la serie a lo largo del tiempo. Se actualiza en cada paso temporal basándose en el valor observado y el nivel anterior. El nivel actualizado en el tiempo ’t’ es una combinación del valor observado ‘yt’, el nivel anterior ’lt-1’ y la tendencia anterior ‘bt-1’. Se calcula usando un parámetro de suavizado alpha.
- Componente de Tendencia (bt): Captura la dirección y la tasa de cambio en la serie a lo largo del tiempo. Se actualiza para reflejar la tendencia observada en los datos recientes. La tendencia actualizada en el tiempo ’t’ es una combinación de la diferencia entre el nivel actual y el nivel anterior, y la tendencia anterior. Se calcula usando un parámetro de suavizado beta.
- Componente Estacional (st): Tiene en cuenta las variaciones estacionales o patrones que se repiten a intervalos fijos (por ejemplo, diarios, semanales, mensuales). Se actualiza para reflejar el comportamiento estacional observado en los datos. El componente estacional actualizado en el tiempo ’t’ es una combinación del valor observado y el componente estacional correspondiente observado en el mismo momento en temporadas anteriores. Se calcula usando un parámetro de suavizado gamma.
Hay dos tipos principales de modelos Holt-Winters
Modelo aditivo: El modelo Aditivo se utiliza cuando las variaciones estacionales son aproximadamente constantes a lo largo de la serie. Es adecuado cuando la magnitud del efecto estacional no depende del nivel de la serie temporal.
Level : Lt=α(Yt−St−m)+(1−α)(Lt−1+Tt−1)
Trend: Tt=β(Lt−Lt−1)+(1−β)Tt−1
Season: St=γ(Yt−Lt)+(1−γ)St−m
Forecast: Yt+h=L t+hTt+St−m+h
Modelo multiplicativo: El modelo Multiplicativo se utiliza cuando las variaciones estacionales cambian proporcionalmente con el nivel de la serie. Es adecuado cuando la magnitud del efecto estacional varía con el nivel de la serie temporal.
Level : Lt=α(Yt/St−m)+(1−α)(Lt−1+Tt−1)
Trend: Tt=β(Lt−Lt−1)+(1−β)Tt−1
Season: St=γ(Yt/Lt)+(1−γ)St−m
Forecast: Yt+h=(Lt+hTt)St−m+h
Ventajas
- Está específicamente diseñado para capturar y pronosticar datos de series temporales con tendencia y estacionalidad, haciéndolo adecuado para una amplia gama de aplicaciones del mundo real.
- El método se adapta a los cambios en los patrones de datos subyacentes a lo largo del tiempo, haciéndolo robusto en entornos dinámicos donde los datos pueden exhibir tendencias o patrones estacionales en evolución.
- Los pronósticos resultantes pueden interpretarse fácilmente ya que se basan en los componentes de nivel, tendencia y estacionalidad, proporcionando información sobre el comportamiento futuro de la serie temporal.
- Aunque el método involucra múltiples componentes y parámetros, es relativamente sencillo de implementar en comparación con técnicas de pronóstico más complejas.
Desventajas
- Seleccionar valores apropiados para los parámetros de suavizado alpha, beta y gamma puede ser desafiante y puede requerir experiencia o experimentación extensiva, especialmente para conjuntos de datos con características variables.
- Sensible a valores atípicos o cambios repentinos en los datos, lo que puede impactar la precisión de los pronósticos, particularmente si estas anomalías no se abordan adecuadamente.
- Como otros métodos de suavizado exponencial, el método de Holt-Winters asume relaciones lineales entre los componentes, lo que puede no capturar adecuadamente patrones no lineales complejos presentes en algunos datos de series temporales.
- Estimar y actualizar los componentes del método de Holt-Winters para grandes conjuntos de datos o datos de alta frecuencia puede ser computacionalmente intensivo, especialmente si se implementa sin técnicas de optimización.
2. Algoritmos de Pronóstico Multivariado
a. Vector Auto Regressor (VAR)
El modelo Vector Auto Regression (VAR) es un algoritmo de series temporales multivariado utilizado para capturar las interdependencias lineales entre múltiples series temporales. Generaliza el modelo autorregresivo (AR) univariado a datos de series temporales multivariados. Cada variable en un modelo VAR es una función lineal de los retardos pasados de sí misma y los retardos pasados de todas las demás variables en el sistema.
Ventajas
- Los modelos VAR son adecuados para capturar las relaciones dinámicas entre múltiples series temporales sin requerir la especificación de variables dependientes e independientes. Esto los hace flexibles para modelar interdependencias complejas entre variables.
- Todas las variables en un modelo VAR se tratan como endógenas, lo que significa que no es necesario categorizarlas como dependientes o independientes. Esta simetría permite una comprensión más completa de cómo las variables interactúan entre sí a lo largo del tiempo.
- Los modelos VAR tienen en cuenta explícitamente los efectos retardados de cada variable sobre sí misma y sobre las demás, permitiendo un análisis detallado de las dependencias temporales.
- El marco VAR permite pruebas de causalidad de Granger, que pueden identificar si una serie temporal puede predecir otra, proporcionando información sobre las relaciones causales entre variables.
- Los modelos VAR facilitan el análisis de respuesta al impulso, que ayuda a comprender el efecto de un shock en una variable sobre las otras variables del sistema a lo largo del tiempo. Esto es particularmente útil en el análisis de políticas y pronósticos económicos.
Desventajas
- Los modelos VAR requieren la estimación de un gran número de parámetros, especialmente cuando se trata de muchas variables y retardos. Esto puede llevar al sobreajuste, haciendo que el modelo sea sensible al ruido y reduciendo su capacidad de generalización.
- El gran número de parámetros a estimar significa que los modelos VAR requieren una cantidad significativa de datos para lograr resultados estables y confiables. Esto puede ser una limitación cuando se trabaja con series temporales cortas o datos escasos.
- Aunque los modelos VAR son potentes, interpretar las relaciones entre variables puede ser desafiante, especialmente cuando el modelo incluye muchas variables y retardos. La salida del modelo puede ser compleja y puede requerir conocimiento estadístico avanzado para interpretarse correctamente.
- Los modelos VAR asumen relaciones lineales entre variables. En la realidad, las relaciones entre variables de series temporales pueden ser no lineales, lo que puede limitar la efectividad del modelo para capturar las dinámicas verdaderas.
- La elección de la longitud de retardo p es crucial en el modelado VAR. Muy pocos retardos pueden llevar a una especificación incorrecta del modelo, mientras que demasiados pueden causar sobreajuste. Seleccionar la longitud de retardo óptima no siempre es sencillo y a menudo requiere pruebas y validación cuidadosas.
- A diferencia de los modelos Structural VAR (SVAR), los modelos VAR estándar no proporcionan una interpretación estructural de las relaciones entre variables. Esto puede ser una limitación en el análisis económico y de políticas, donde comprender los mecanismos subyacentes es importante.
- Cuando las variables en el modelo VAR están altamente correlacionadas, la multicolinealidad puede convertirse en un problema, llevando a estimaciones poco confiables de los coeficientes. Esto puede dificultar discernir el verdadero impacto de cada variable sobre las demás.
- A medida que aumenta el número de variables y retardos, la carga computacional de estimar los parámetros del modelo crece. Esto puede hacer que los modelos VAR sean computacionalmente intensivos, especialmente para grandes conjuntos de datos.
Validación Cruzada
La validación cruzada en series temporales es una técnica utilizada para evaluar el rendimiento de un modelo en un conjunto de datos de series temporales. A diferencia de la validación cruzada k-fold típica utilizada en el aprendizaje automático estándar, los datos de series temporales tienen un orden temporal que debe preservarse. Por lo tanto, se utilizan métodos específicos para manejar esta dependencia temporal.
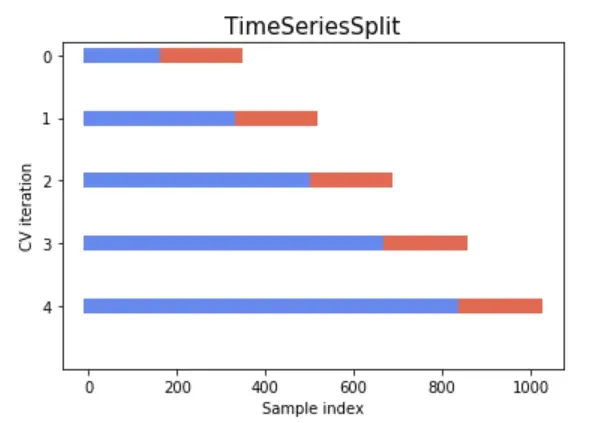
i. Rolling Time Series Split
- Este método implica dividir los datos de series temporales en conjuntos de entrenamiento y validación múltiples veces de tal manera que el conjunto de entrenamiento siempre precede al conjunto de validación.
- Simula la forma en que los nuevos datos están disponibles a lo largo del tiempo y asegura que el modelo siempre se pruebe con datos futuros, en relación con el conjunto de entrenamiento.
- Consulte la imagen a continuación para comprender la división de datos
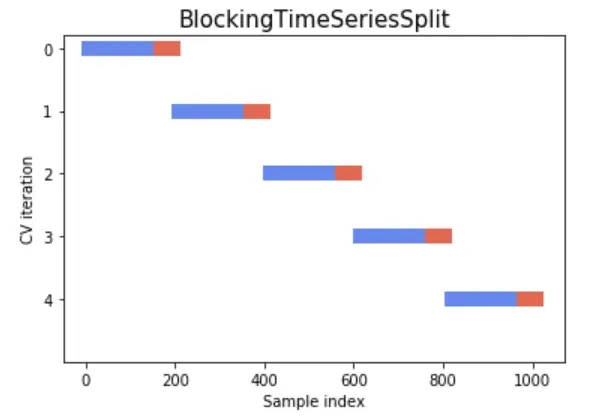
ii. Blocking Time Series Split
- Implica dividir los datos en bloques o pliegues contiguos, mientras se asegura que no haya superposición entre los conjuntos de entrenamiento y prueba y se mantiene el orden temporal de los datos.
- Previene que el modelo vea datos futuros durante el entrenamiento, lo que llevaría al sobreajuste.
- Asegura que el conjunto de entrenamiento siempre preceda al conjunto de validación, respetando el orden temporal.
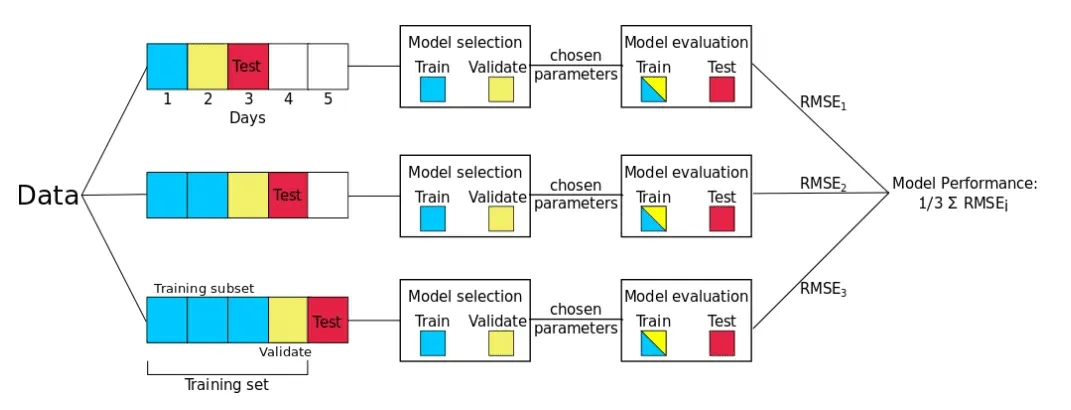
iii. Day Forward Chaining
- Day Forward-Chaining se basa en un método llamado forward-chaining y evaluación de recalibración de origen continuo. Usando este método, consideramos sucesivamente cada día como el conjunto de prueba y asignamos todos los datos anteriores al conjunto de entrenamiento.
- Este método produce muchas divisiones diferentes de entrenamiento/prueba. El error en cada división se promedia para calcular una estimación robusta del error del modelo.
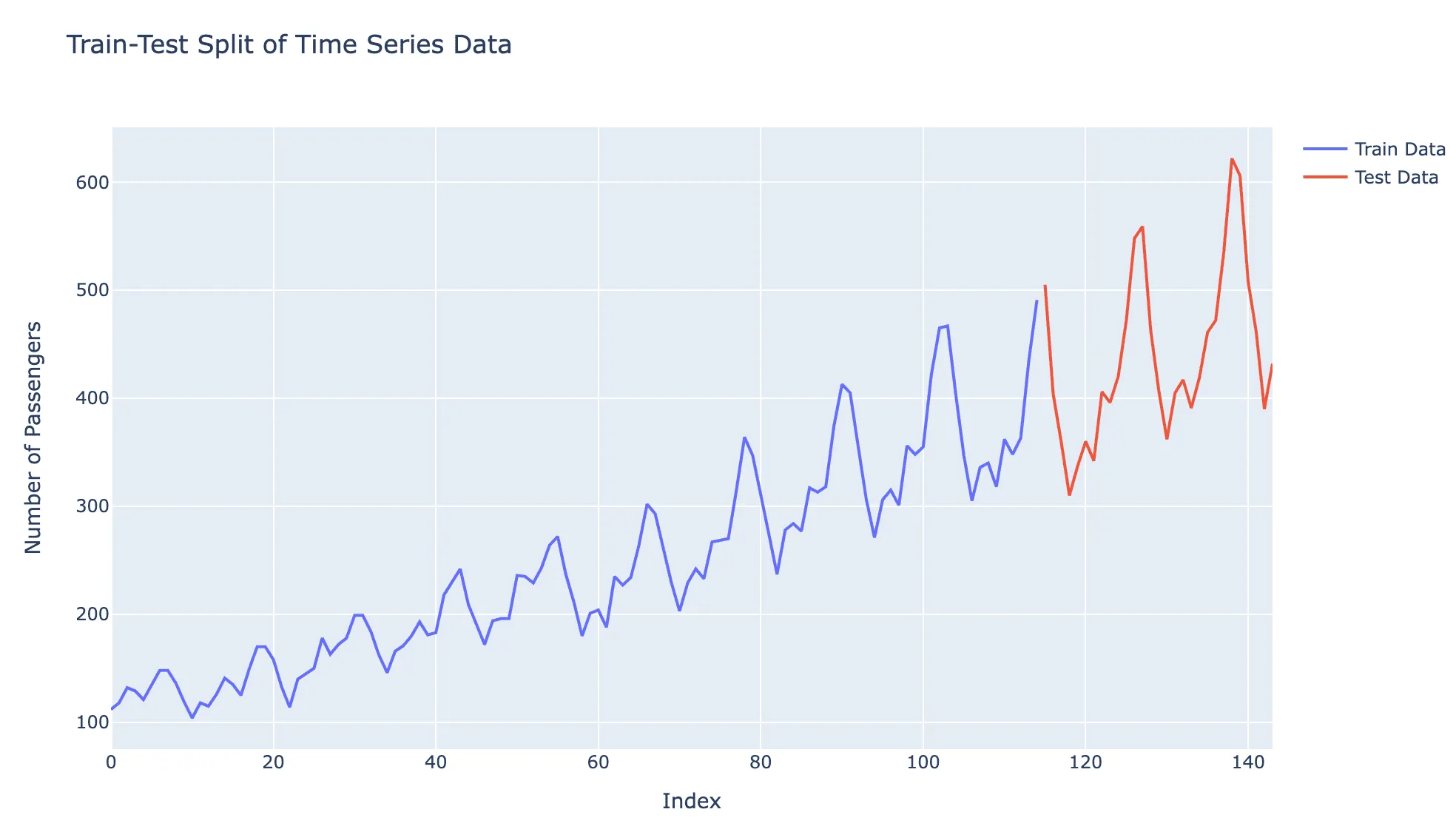
iv. Regular Train Test Split - Predeterminado En un escenario estándar de división entrenamiento-prueba, un conjunto de datos de series temporales se divide en dos subconjuntos: un conjunto de entrenamiento y un conjunto de prueba. El conjunto de entrenamiento se utiliza para entrenar el modelo, que contiene datos históricos, y luego se prueba en el conjunto de prueba, que incluye datos futuros no vistos. Esto permite evaluar el rendimiento del modelo y sus capacidades de generalización probando su capacidad para predecir valores futuros basados en datos pasados.
Representación visual de la división Entrenamiento-prueba de los datos de la siguiente manera:
Construir un pipeline
QuickML utiliza el constructor de pipeline en modo inteligente para crear modelos de series temporales. El Smart Builder proporciona una plantilla preconstruida para modelos de series temporales, diseñada para simplificar el proceso de desarrollo del modelo desde el preprocesamiento de datos hasta la selección del modelo. Con estas plantillas preconstruidas, las operaciones están predefinidas y se presentan a los usuarios varios parámetros para configurar cada etapa. Esta plantilla elimina la ambigüedad de qué etapa usar para construir un modelo de series temporales y agiliza el proceso de construcción del modelo.
Visualizaciones
Gráfico de Descomposición
Un gráfico de descomposición desglosa los datos de series temporales en sus componentes clave: tendencia, estacional y residual (o ruido). Ayuda a validar la presencia de estos componentes y comprender sus contribuciones al patrón general de los datos. La descomposición es particularmente útil para analizar datos de series temporales registrados a intervalos regulares durante diferentes períodos.
En QuickML, el gráfico de descomposición utiliza la técnica aditiva, donde la serie temporal original se representa como la suma de sus componentes:
Original Series = Trend + Seasonality + Residual
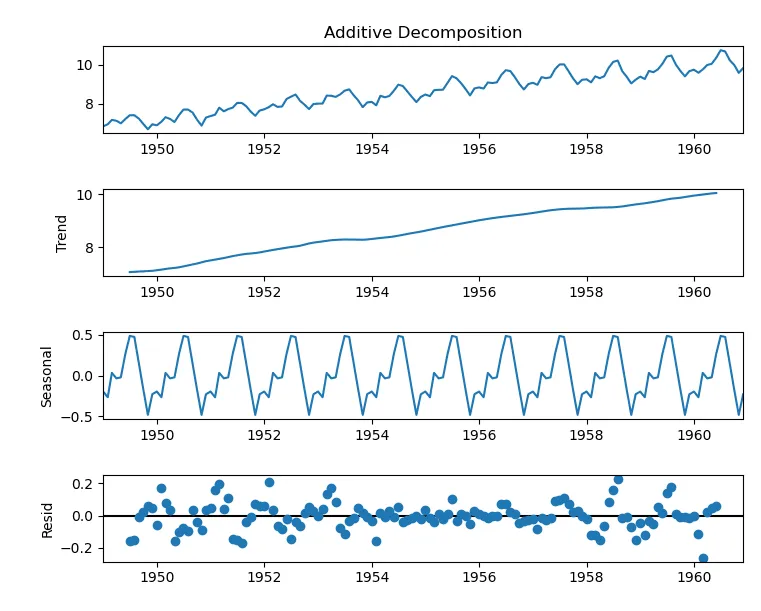
Esta técnica asume que la magnitud de las variaciones estacionales y residuales permanece constante a lo largo de la serie.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us