Data Transformation
Data Transformation es el proceso de convertir datos de un formato o estructura a otro formato o estructura.
-
Date Time Transformation
Se utiliza para extraer características de fecha-hora, como fecha, año y mes, de una columna que contiene fechas.
Caso de uso 1: Una empresa minorista quiere rastrear las ventas de sus productos a lo largo del tiempo. DateTime Transformation les ayuda a extraer la fecha, mes y año de la lista de transacciones de ventas.
Caso de uso 2: Una empresa de transporte puede usar DateTime Transformation para extraer la fecha, hora y ubicación de una lista de entregas pasadas para optimizar sus rutas de entrega.
Entrada de ejemplo:
dt 2021-11-29 11:52:59 Salida de ejemplo:
dt_day_of_week 1 dt_date_no 29 dt_year_no 2021 dt_month_no 11 dt_business_day 1 dt_week_no_year 48 dt_day_of_year 333 dt_AM_PM AM dt_quarter_year 4 -
Email Transformation
Se utiliza para extraer características como nombre de usuario, dominio y sufijo de una columna que contiene correos electrónicos.
Caso de uso 1: Un equipo de ventas puede usar Email Transformation para extraer el nombre de usuario y el nombre de dominio de una lista de direcciones de correo electrónico para personalizar su alcance por correo electrónico a clientes potenciales.
Caso de uso 2: Para identificar correos electrónicos de phishing, un equipo de seguridad necesita características como el nombre de dominio y el sufijo de una lista de direcciones de correo electrónico que han sido marcadas como sospechosas.
Entrada de ejemplo:
mail abc@zylker.com Salida de ejemplo:
mail_first mail_middle mail_last abc zylker com -
Extract Data
El componente Extract Data utiliza patrones regex para recuperar información de columnas de texto. Estos patrones pueden abarcar varios formatos de fecha, correos electrónicos o valores numéricos incrustados dentro de las columnas de texto.
Ejemplo:
En el dataset de predicción de precios de automóviles, para extraer el año de fabricación del automóvil de la columna name, usamos el patrón regex POSIX /d{4} aplicado en la misma columna.Patrones Regex POSIX de ejemplo:
- Formato de fecha: \d{4}-\d{2}-\d{2}
- Email: [a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+
- Número: \d+
-
Format
Se utiliza para modificar los valores de columna en el dataset basándose en la función elegida por el usuario. La función se mostrará según los tipos de datos de la columna.
Ejemplo:
En un dataset de pacientes, formateando la columna de edad usando la función de valor absoluto. La columna de edad ya no tendrá valores negativos. -
Group By
Se utiliza para particionar filas en grupos basándose en sus valores en una o más columnas. Es obligatorio proporcionar al menos una función de aggregate para una columna. Los usuarios también pueden establecer los criterios de HAVING para filtrar el dataset agrupado.
Ejemplo:
Ejemplo: En un dataset de salarios de empleados, los usuarios pueden sumar los salarios asignados a cada departamento agrupando los datos por departamento. Esto permite a los usuarios ver el gasto total en salarios de cada departamento. En la sección HAVING se pueden filtrar estos grupos para incluir solo los departamentos donde el salario total exceda 50,000.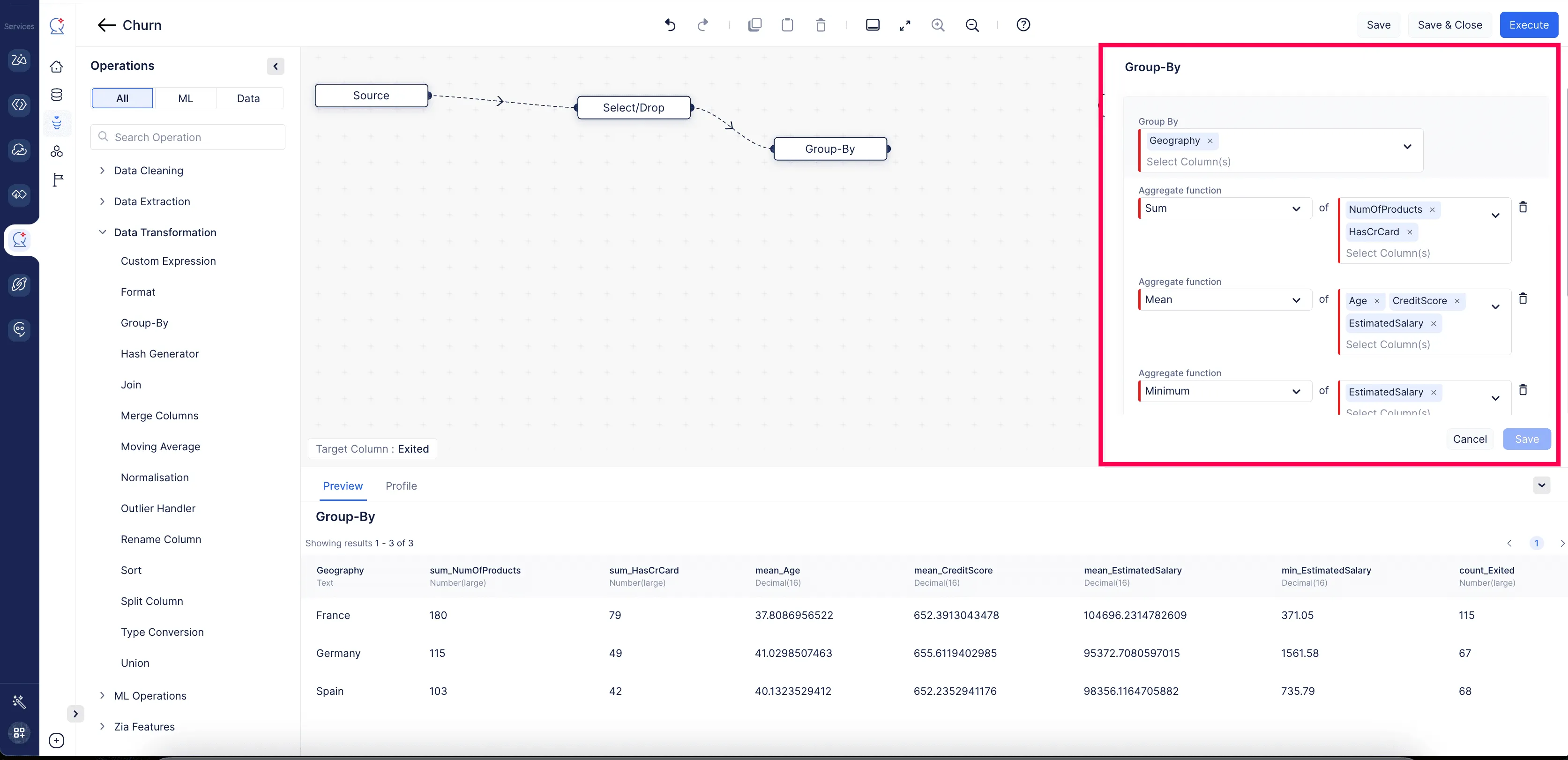
-
Hash Generator
Se utiliza para aplicar hash a una o varias columnas en el dataset. Los usuarios también pueden eliminar la columna de origen una vez que se genera el hash.
-
Join
Se utiliza para unir dos datasets en un solo dataset basándose en la columna primaria en ambas tablas. El usuario puede realizar joins de tipo Left, Right, Inner y Outer.
Nota: Esta etapa requiere seleccionar un nodo de dataset.
Ejemplo: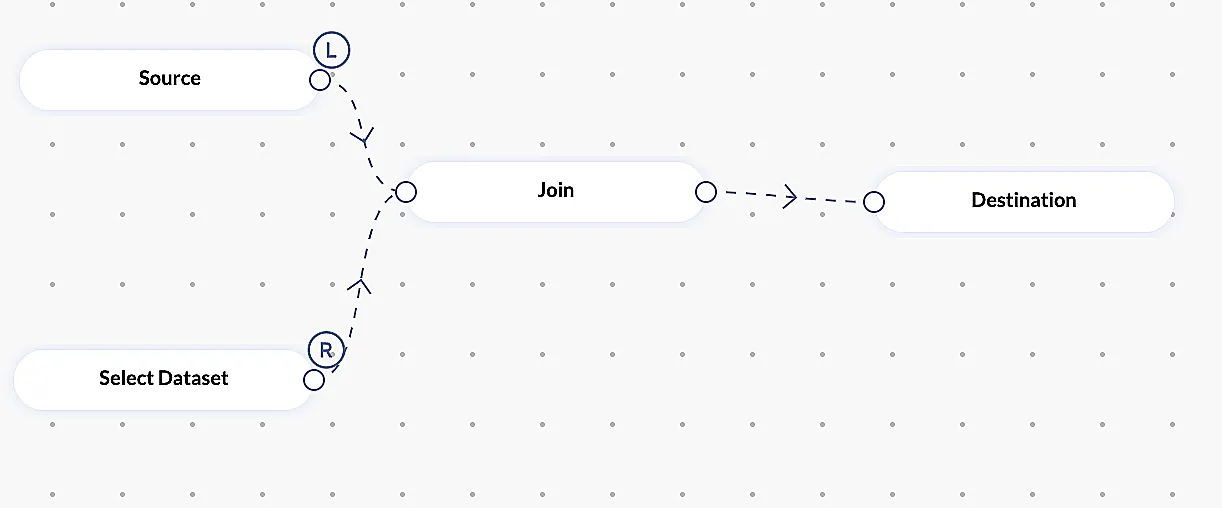
-
Merge Column
Se utiliza para fusionar dos o más columnas en una sola columna usando un separador especificado por el usuario. El usuario también puede eliminar la columna de origen después de realizar la operación de fusión.
Ejemplo:
En un dataset de pasajeros, podemos combinar first_name, middle_name y last_name como columna Name usando un separador de espacio. -
Normalization
La normalización es un método estadístico que ayuda a escalar y comparar variables en diferentes escalas o unidades. Este nodo se utiliza para normalizar dos o más columnas.
-
Outlier Handler
Los outliers son puntos de datos que caen fuera de la distribución normal de los datos, lo que puede distorsionar los resultados del análisis de datos y llevar a conclusiones incorrectas. Outlier Handler se puede utilizar para eliminar outliers de un dataset o reemplazarlos con valores más razonables, como los valores de cap, mean o median de las columnas respectivas en los datos.
-
Sort
Se utiliza para ordenar el dataset por un conjunto de columnas. Los usuarios también pueden elegir el orden de clasificación.
-
Split Column
Se utiliza para dividir una sola columna en dos o más columnas basándose en el separador especificado por el usuario. El número de columnas de salida se determinará según los nombres de salida proporcionados por el usuario.
Ejemplo:
En un dataset de pasajeros, el usuario puede dividir la columna Name en tres columnas especificando first_name, middle_name y last_name en el cuadro de texto de la columna de salida. -
String Transformation
Se utiliza para producir word embeddings a partir de columnas que contienen texto.
Caso de uso 1: Para proporcionar contenido recomendado a sus usuarios, una empresa de redes sociales puede utilizar String Transformation para obtener los word embeddings del texto de las publicaciones que los usuarios han dado like y compartido.
Caso de uso 2: A partir del texto de los tickets, un equipo de soporte al cliente necesita clasificar los tickets de soporte identificando problemas comunes que sus clientes están experimentando usando word embeddings producidos por string transformation.
-
Type Conversion
Se utiliza para convertir el tipo de columna al tipo de dato especificado por el usuario. Los usuarios pueden manejar el dataset resultante si ocurre un error usando la opción On Error en la configuración. Throw lanzará una excepción si ocurre un error y detendrá la ejecución, mientras que Nullify devolverá el registro original si ocurre un error para ese registro en particular.
-
URL Transformation
Se utiliza para extraer características como sub_domain, domain y suffix de una columna que contiene URLs.
Caso de uso 1: Un equipo de marketing necesita determinar qué sitios web son visitados con más frecuencia por su mercado objetivo. Pueden utilizar URL Transformation para extraer los nombres de dominio de una lista de URLs en las que los usuarios de su sitio web han hecho clic.
Caso de uso 2: Un equipo de detección de fraude puede usar URL Transformation para descubrir la lista de dominios, subdominios y sufijos de sitios web maliciosos de una lista de URLs que han sido marcadas como sospechosas.
Entrada de ejemplo:
link https://www.google.in/library?fetch=query#fragment_part Salida de ejemplo:
link_url_protocol https link_url_domain www.google.in link_url_path /library link_url_query fetch=query link_url_fragment fragment_part link_domain_tld in link_domain_country IN subdomain www -
Union
Se utiliza para combinar dos datasets en un solo dataset. Los usuarios pueden eliminar filas duplicadas después de combinar dos datasets.
Nota: Esta etapa requiere seleccionar un nodo de dataset. -
Windowing
Se utiliza para realizar la operación de promedio de ventana en columnas numéricas. El usuario debe especificar el rango de ventana que debe ser mayor que 0. Los promedios móviles son un tipo simple y común de suavizado utilizado en el análisis de series temporales y la previsión de series temporales. Esto se puede utilizar para datasets de series temporales.
-
Fill Columns
Se utiliza para cambiar los valores de una columna específica basándose en los criterios establecidos por el usuario. Si los criterios no se especifican en la configuración, entonces todos los valores en esa columna serán reemplazados por el valor o método especificado por el usuario.
Ejemplo:
Para un dataset de población de un país que contiene detalles del paciente como nombre, edad, dirección y elegibilidad para votar, podemos actualizar la columna “eligible for vote” a “yes” para todas las personas cuya edad sea mayor de 18. -
Rename
Se utiliza para renombrar cualquier nombre de columna particular del dataset.
Ejemplo:
Para un dataset que contiene columnas como name, age, address y eligible_for_vote, podemos renombrar la columna eligible_for_vote a voter_eligibility. -
Custom Expression
Esto permite a los usuarios crear expresiones personalizadas para manipular o calcular valores en un dataset. Las expresiones personalizadas se pueden utilizar para derivar nuevas columnas, transformar datos existentes o aplicar cálculos complejos basados en los datos.
Ejemplo:
Para un dataset que contiene columnas como name, age, address y salary, podemos crear una expresión personalizada para calcular el salario anual a partir del salario mensual.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us