Código Personalizado
Operaciones de Custom Code
Las operaciones de Custom Code en el pipeline de QuickML permiten a los desarrolladores insertar su propia lógica en el proceso de entrenamiento del modelo. Al implementar clases de Python proporcionadas en plantillas, los usuarios pueden personalizar cómo se transforman los datos, cómo se procesan las características e incluso definir el algoritmo de aprendizaje automático utilizado.
Esta capacidad se divide en tres componentes distintos:
- Custom Data Transformation
- Custom ML Transformation
- Custom Algorithm
Cada componente desempeña un papel único en el ciclo de vida del aprendizaje automático y viene con firmas de métodos predefinidas que deben ser implementadas por el usuario.
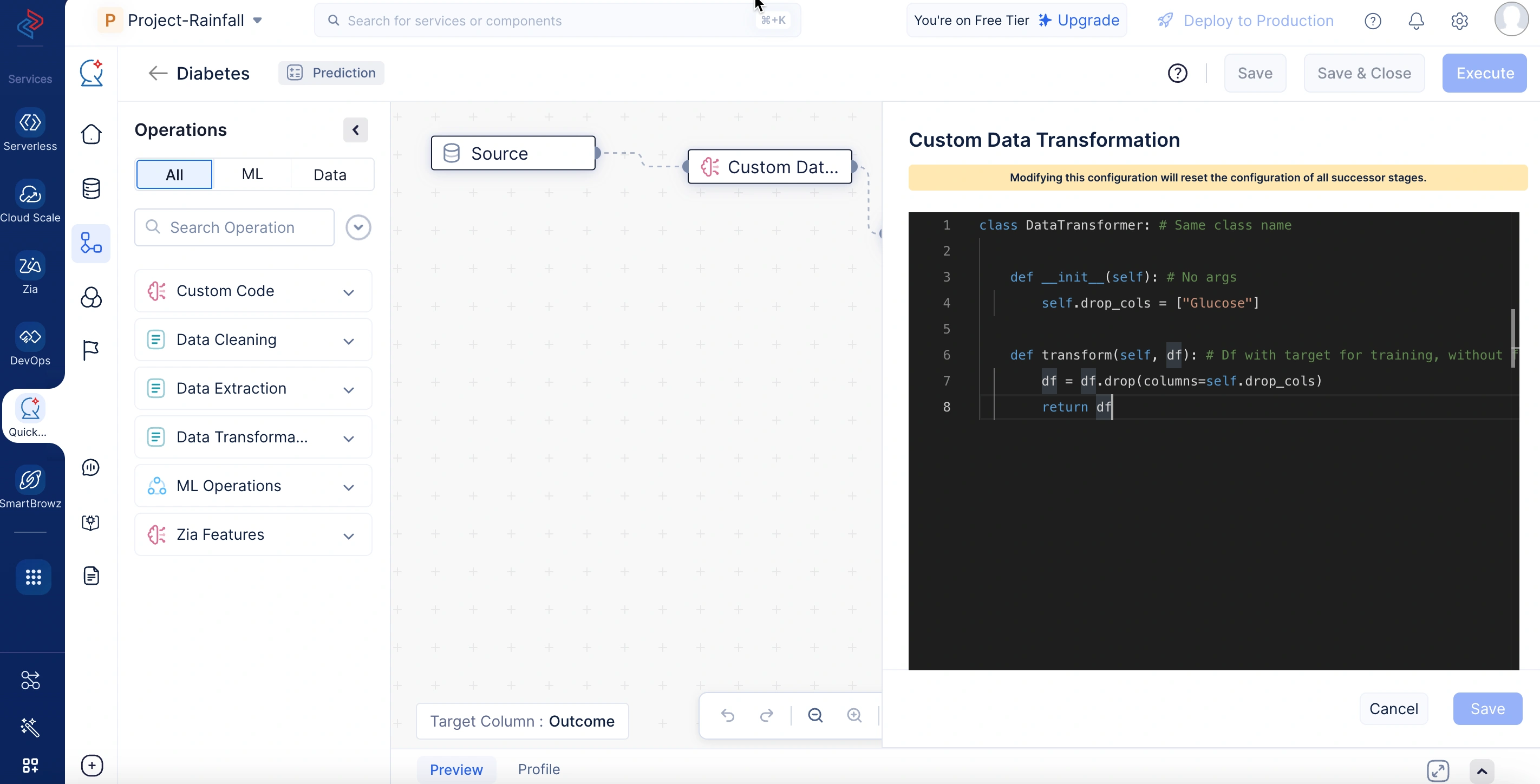
Custom Data Transformation
Custom Data Transformation se utiliza para optimizar los datos realizando operaciones como limpieza de datos, transformación y extracción de datos sin procesar utilizando lógica personalizada. Es particularmente útil para pasos de preprocesamiento como la eliminación de columnas, conversiones de formato y escalado que deben permanecer consistentes tanto en las etapas de entrenamiento del modelo como de predicción. El código personalizado maneja requisitos complejos durante el preprocesamiento de datos y se implementa en el método transform(), que acepta y devuelve un objeto DataFrame y se ejecuta tanto durante el entrenamiento como durante la inferencia.
En el código de ejemplo a continuación, el nodo de Custom Data Transformation preprocesa los datos antes de que se utilicen para el entrenamiento o la predicción del modelo. Elimina la columna “Glucose” del conjunto de datos para asegurar que las características irrelevantes o potencialmente sesgadas no influyan en el aprendizaje o las predicciones del modelo.
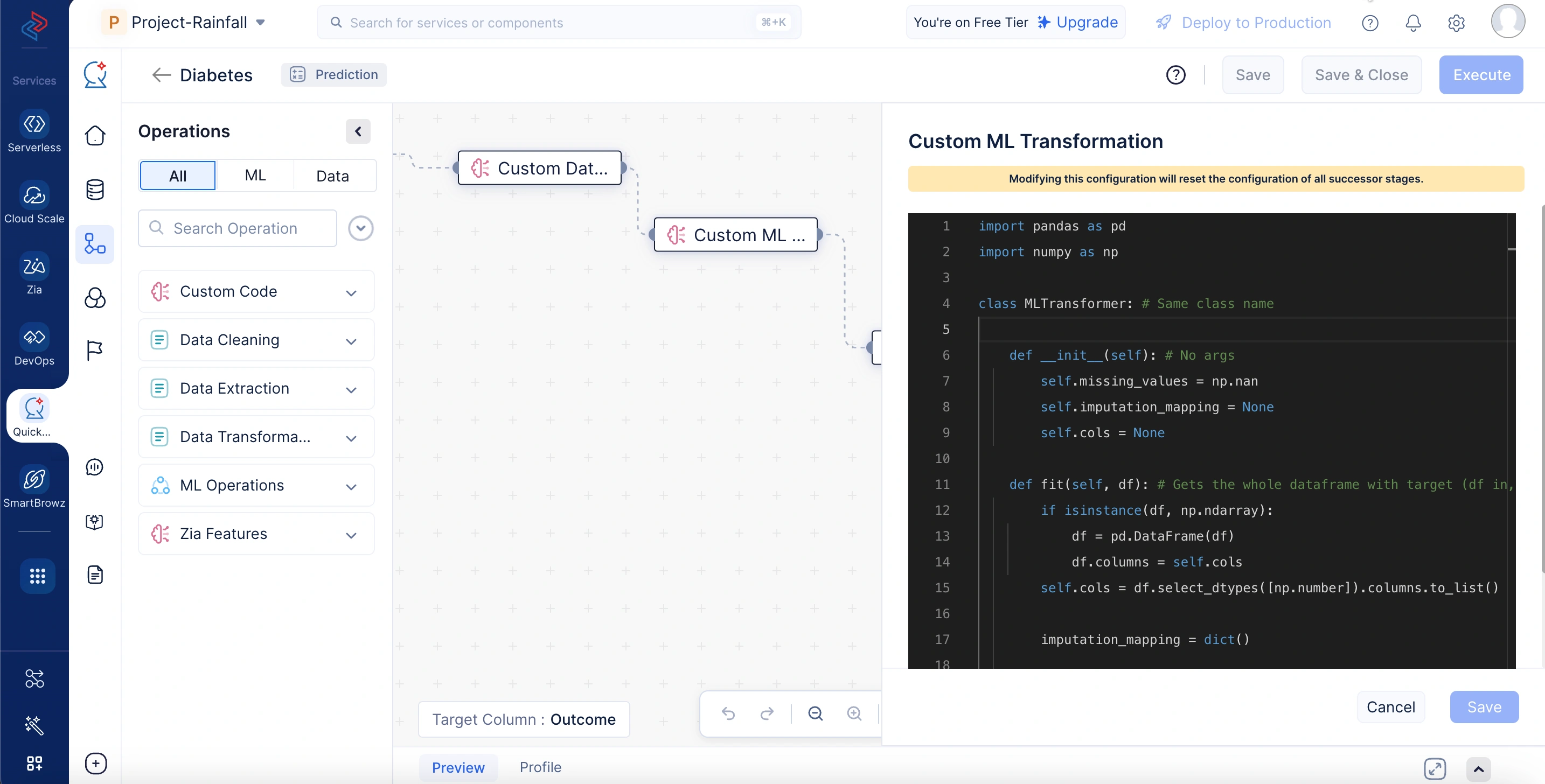
Custom ML Transformation
En el ciclo de vida del desarrollo de modelos de ML, las operaciones de Custom ML Transformation se utilizan durante el paso de preprocesamiento realizando tareas de ingeniería de características específicamente adaptadas al caso de uso utilizando lógica personalizada. Estas transformaciones son ideales para manejar operaciones como la imputación de valores faltantes, la codificación de características y la normalización, donde la lógica debe aprender de los datos de entrenamiento y aplicar consistentemente la misma transformación durante la predicción. Esto se logra a través de un método fit(), que aprende los parámetros necesarios de los datos de entrenamiento, y un método transform(), que aplica esos parámetros aprendidos para preprocesar nuevos datos. Ambos métodos aceptan y devuelven un objeto DataFrame.
En el código de ejemplo a continuación, el nodo de Custom ML Transformation maneja la imputación de valores faltantes como parte del paso de preprocesamiento de datos. Durante el entrenamiento, calcula la media de cada columna numérica y la almacena. Posteriormente, durante la predicción o inferencia, rellena los valores faltantes en esas columnas usando los valores de media almacenados, asegurando consistencia entre las fases de entrenamiento y predicción.
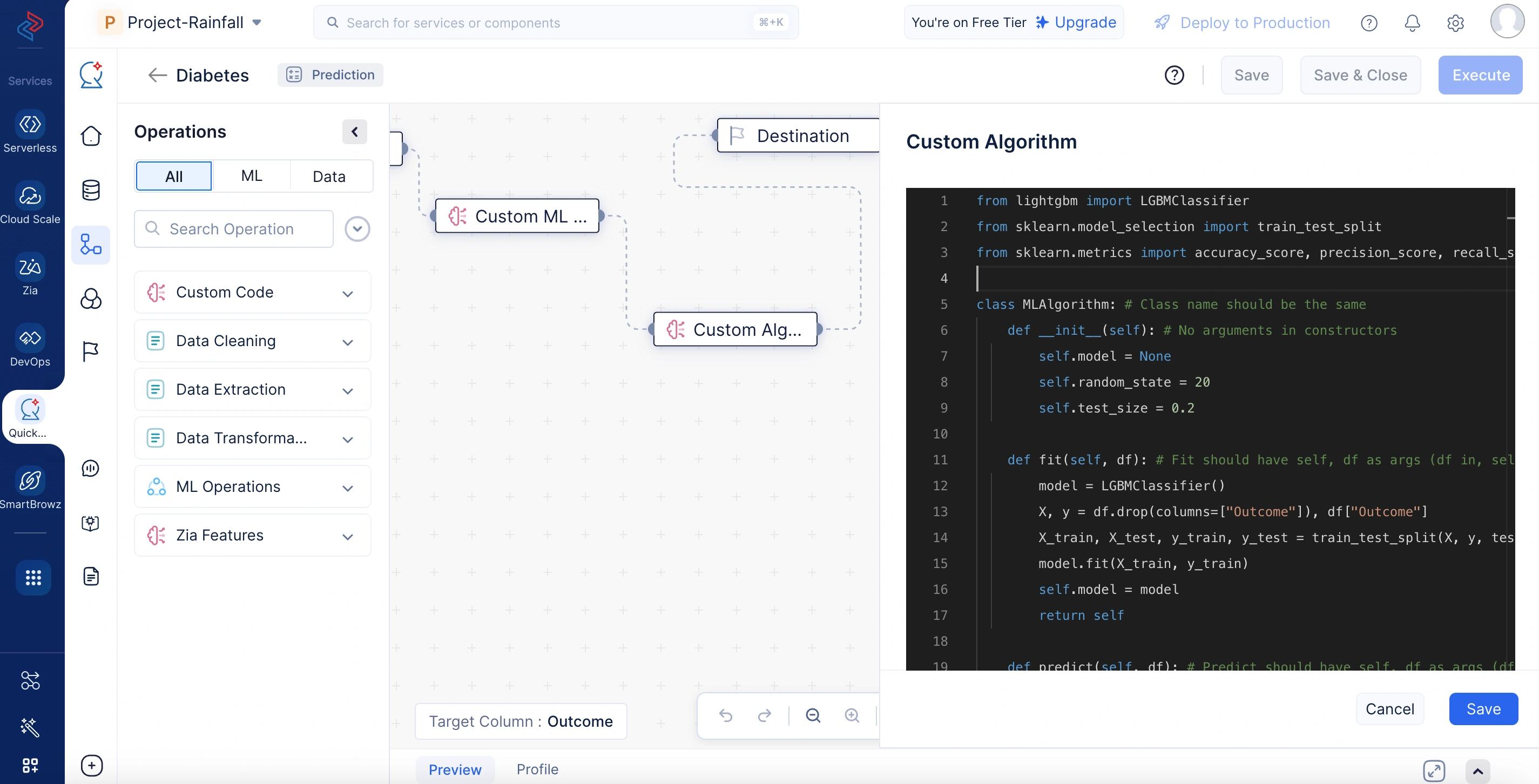
Custom Algorithm
Te permite integrar un modelo de ML personalizado y definir su lógica de entrenamiento, predicción y evaluación. Esto ofrece control total sobre qué algoritmo se utiliza y cómo se evalúa su rendimiento. Tiene funciones fit, predict y get_evaluation_metrics. Fit se ejecuta durante el entrenamiento del modelo, predict se ejecuta durante la predicción y get_evaluation_metrics se ejecuta después del entrenamiento del modelo para generar las métricas de evaluación. Las métricas devueltas por el método get_evaluation_metrics() se mostrarán en la sección de métricas de evaluación de la página de detalles del modelo.
La operación de Custom Algorithm se refiere a la aplicación de algoritmos personalizados adaptados a casos de uso empresariales específicos. Permite a los usuarios integrar un modelo de ML personalizado y definir lógica de entrenamiento, predicción y evaluación a medida. Este enfoque ofrece control total sobre qué algoritmo se utiliza y cómo se evalúa su rendimiento. Puede verse como una mejora de los algoritmos predefinidos estándar, permitiendo la resolución de problemas de modelado únicos utilizando reglas específicas del dominio.
La operación incluye tres métodos clave:
- fit() — se ejecuta durante el entrenamiento del modelo para aprender de los datos,
- predict() — se ejecuta durante la predicción para generar resultados, y
- get_evaluation_metrics() — se ejecuta después del entrenamiento para calcular y devolver métricas de evaluación.
En el código de ejemplo a continuación, el nodo de Custom Algorithm construye un modelo de ML utilizando el clasificador LightGBM. Divide el conjunto de datos de entrada en conjuntos de entrenamiento y prueba, entrena el modelo con los datos de entrenamiento y almacena la instancia del modelo entrenado. Durante la predicción, utiliza el modelo entrenado para generar resultados para datos no vistos. Después del entrenamiento, evalúa el modelo utilizando métricas de accuracy, precision, recall y F1-score, que se calculan sobre los datos de prueba y se devuelven como un diccionario para el análisis de rendimiento.
Lista de bibliotecas de Python desde las cuales se admite la importación:
numpy, scipy, pandas, xgboost, catboost, lightgbm, sklearn, tld, patsy, tensorflow, statsmodels, tldextract, huggingface_hub, sentence_transformers, imbalanced_learn, hyperopt, shap, lime, transformers, pmdarima, lightfm, LibRecommender, subseq
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us