Introducción a los Datos de Series Temporales
Las series temporales se refieren a una secuencia de puntos de datos que representan cómo una o más características cambian a lo largo del tiempo. Estos puntos de datos se registran a intervalos regulares, permitiendo el análisis de tendencias, cambios de estacionalidad, patrones y anomalías a lo largo del tiempo.
Los datos de series temporales se pueden categorizar en dos tipos: univariados, donde solo se registra una característica, y multivariados, donde se rastrean múltiples características en el tiempo simultáneamente.
El objetivo principal del análisis de series temporales es a menudo predecir valores futuros de una característica, que sirve como la variable objetivo en tareas como pronóstico o detección de anomalías.
Componentes de las Series Temporales
Los componentes de las series temporales caracterizan los patrones o comportamientos subyacentes de la serie de datos a lo largo del tiempo. Estos son simplemente los factores que afectan los valores de los puntos de datos observados. Comprender estos componentes ayudará a crear modelos mejores y más precisos. Los cuatro componentes de los datos de series temporales son:
- Tendencia
- Estacionalidad
- Cíclico
- Ruido
1. Tendencia
El componente de tendencia representa la dirección o movimiento a largo plazo en la serie temporal. Indica si los datos generalmente están aumentando, disminuyendo o permaneciendo constantes a lo largo del tiempo.
Características
- Refleja la tendencia subyacente de la serie durante un período más largo.
- Las tendencias pueden ser lineales o no lineales.
- Las tendencias no se ven afectadas por fluctuaciones o irregularidades a corto plazo.
Ejemplo
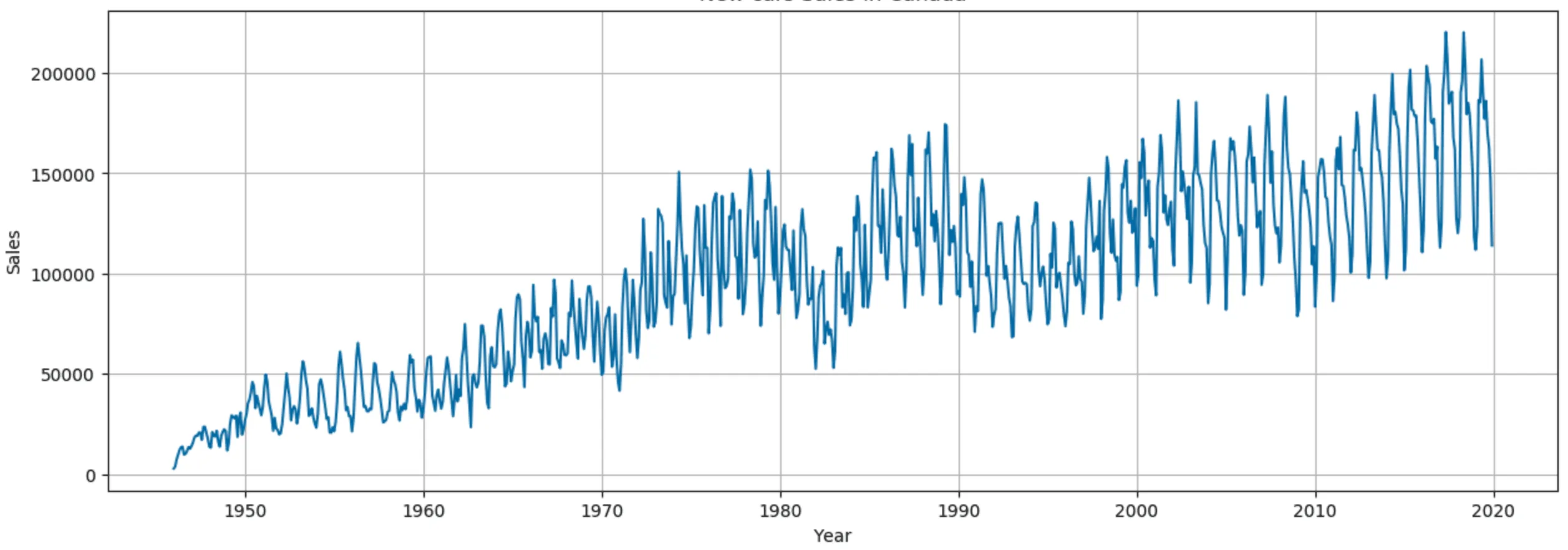
En los datos de ventas de una empresa, un aumento constante en las ventas durante varios años indica una tendencia positiva.
2. Estacionalidad
El componente estacional representa patrones regulares y repetitivos en la serie temporal que ocurren dentro de un período fijo, como diario, mensual o anual.
Características
- La estacionalidad ocurre a intervalos regulares y tiene un período fijo.
- A menudo impulsada por factores externos como el clima, las vacaciones o eventos culturales.
- Los efectos estacionales son predecibles y se repiten al mismo tiempo cada año, mes, semana o día.
Ejemplo
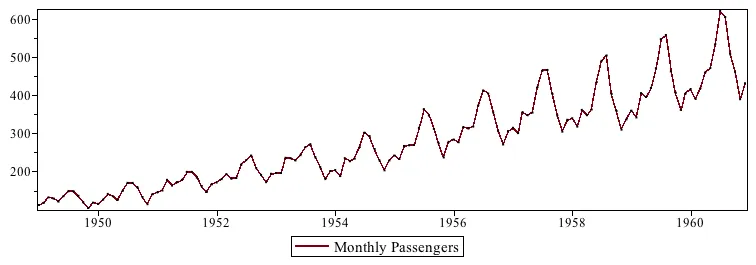
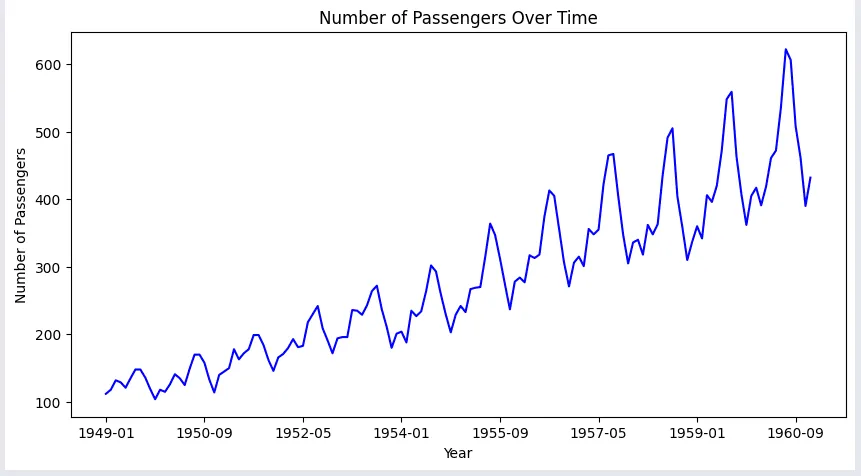
El ejemplo aquí muestra los pasajeros mensuales con respecto a cada mes desde 1949 hasta 1960, donde podemos ver la distribución estacional de los pasajeros en el gráfico.
3. Cíclico
El componente cíclico se refiere a las fluctuaciones en la serie temporal que ocurren durante períodos más largos, generalmente influenciadas por ciclos económicos o empresariales.
Características
- Los ciclos son generalmente irregulares en período y amplitud.
- Pueden durar más de un año, a menudo varios años.
- A diferencia de la estacionalidad, los patrones cíclicos son menos predecibles en su frecuencia y duración pero están influenciados por factores económicos más amplios.
Ejemplo
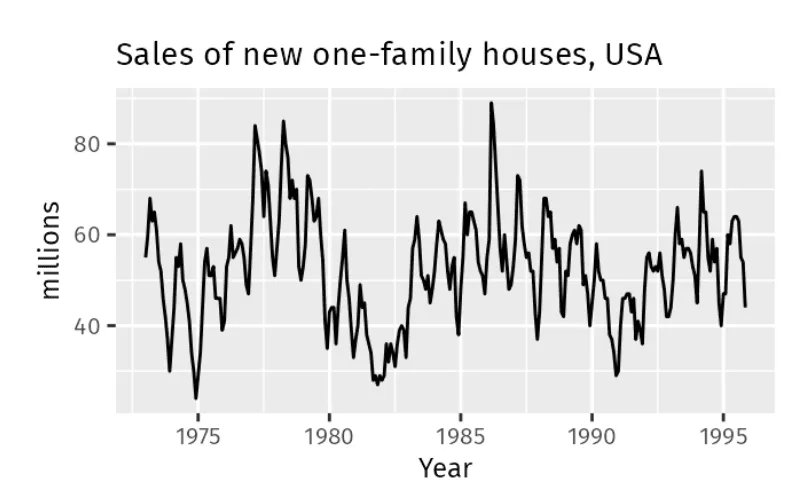
Las ventas de casas familiares nuevas fluctúan durante ciertos períodos, pero estos cambios no son estacionales, como se ve en el gráfico. Estas fluctuaciones podrían estar influenciadas por períodos de expansión y recesión económica, que son menos predecibles que los patrones estacionales.
4. Ruido
El componente de ruido captura la variación aleatoria en la serie temporal que no puede atribuirse a patrones de tendencia, cíclicos o estacionales. Representa las fluctuaciones impredecibles e irregulares en los datos.
Características
- El ruido es la parte residual de la serie temporal después de eliminar los componentes de tendencia, cíclicos y estacionales.
- Aleatorio e impredecible.
- El ruido no sigue ningún patrón específico y puede ser causado por factores aleatorios o errores de medición.
Ejemplo
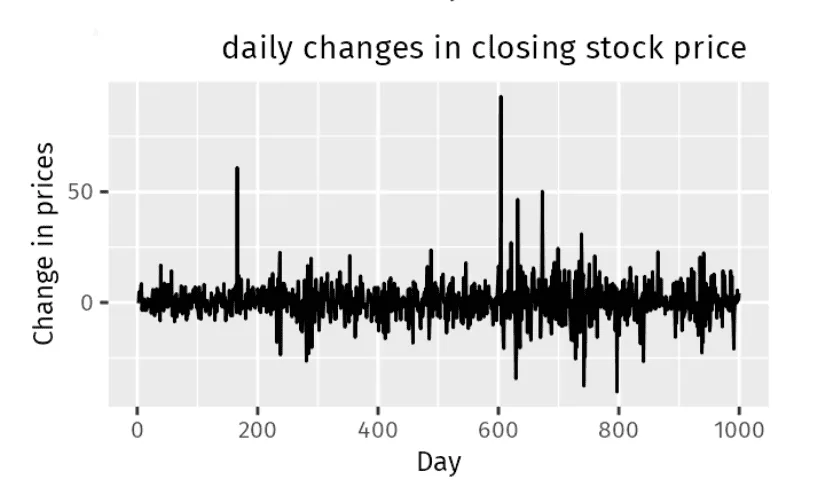
Como podemos concluir del gráfico, no hay una tendencia específica, estacionalidad o patrón cíclico en los cambios del precio de las acciones de la empresa. Las fluctuaciones de precio aparecen como subidas y bajadas aleatorias sin un patrón predecible.
Estacionariedad
La estacionariedad se refiere a una característica de los datos de series temporales donde las propiedades estadísticas, como la media, la varianza y la autocorrelación, permanecen constantes a lo largo del tiempo.
- La media es el valor promedio de las observaciones durante un cierto período de tiempo;
- La varianza es la medida de la dispersión o extensión del valor alrededor de la media,
- La autocorrelación es la correlación de la serie con sus valores anteriores.
Las tres propiedades estadísticas de los datos de series temporales deben permanecer constantes a lo largo del tiempo para concluir que la serie es estacionaria. Entender si la serie es estacionaria o no es importante, ya que informa el tipo de preprocesamiento necesario para construir un modelo de series temporales efectivo. Cuando una serie es estacionaria, los valores registrados no cambian o permanecen dentro del mismo rango a lo largo del tiempo.
Veamos ejemplos de casos de uso donde la serie registrada se considera como serie estacionaria o no estacionaria.
a. Serie no estacionaria
Un dato de serie temporal se considera no estacionario si los valores registrados fueron afectados en diferentes momentos debido a la presencia de tendencia, estacionalidad, cíclico o ruido en los datos.
Ejemplo:
Los pasajeros de una aerolínea estarán en tendencia creciente con fluctuaciones estacionales cada año, como se muestra en el gráfico. Por lo tanto, esta serie se considera como serie no estacionaria.
El resultado de la prueba ADF para evaluar la presencia de estacionariedad
ADF Statistic: 0.81
p-value: 0.99
Critical Values: {'1%': -3.48, '5%':-2.88, '10%': -2.57}
Fail to reject the null hypothesis: The series is not stationary.
b. Serie estacionaria
Cuando una serie es estacionaria, los valores registrados no cambian o permanecen dentro del mismo rango a lo largo del tiempo.
Ejemplo:
Después de aplicar la técnica de transformación diferencial de lag 2, la serie no estacionaria se convierte en serie estacionaria. Si graficamos los valores transformados en un gráfico, aparecerá como se muestra a continuación:
Resultados de la prueba ADF para evaluar la presencia de estacionariedad después de la transformación de datos
ADF Statistic: -2.96
p-value: 0.03
Critical Values: {
'1%': -3.48,
'5%': -2.88,
'10%':-2.57
}
Reject the null hypothesis: The series is stationary.
Los modelos de series temporales se construyen típicamente usando datos estacionarios. Si una serie es no estacionaria, debe transformarse en una serie estacionaria antes de entrenar el modelo para asegurar predicciones futuras precisas. Se realizan dos pruebas estadísticas, conocidas como las pruebas ADF y KPSS, en los datos de series temporales para determinar si la estacionariedad está presente en la serie.
Pruebas de Estacionariedad
Estacionariedad en una serie temporal significa que las propiedades estadísticas de la serie no cambian a lo largo del tiempo. En otras palabras, si observa diferentes partes de la serie, deberían verse estadísticamente similares. Para que una serie sea estacionaria, debe tener una media constante, varianza constante y autocorrelación constante.
Hay dos tipos de métodos estadísticos que se pueden realizar en los datos de series temporales para verificar la presencia de estacionariedad. Son la prueba ADF y la prueba KPSS. Sin embargo, antes de ir a las pruebas de estacionariedad, entendamos un concepto en las pruebas estadísticas llamado hipótesis.
Hipótesis: La prueba de hipótesis es un método estadístico utilizado para hacer inferencias o sacar conclusiones sobre un conjunto de datos usando datos de muestra extraídos de todos los datos disponibles. Nos ayuda a decidir si hay suficiente evidencia en nuestra muestra para apoyar o rechazar una afirmación o hipótesis particular sobre todo el conjunto de datos.
- Hipótesis Nula (H₀): Esta es la suposición de que no hay efectos o diferencias. Representa el statu quo.
- Hipótesis Alternativa (H₁): Esta es lo opuesto a la hipótesis nula, y representa una nueva afirmación o efecto. Esto es lo que necesitaría probar.
Ahora que entendemos qué significan las hipótesis, veamos las pruebas de estacionariedad:
-
Prueba ADF
La prueba Augmented Dickey-Fuller (ADF) es una prueba estadística utilizada para determinar si una serie temporal tiene raíz unitaria o no. La presencia de raíz unitaria indica que los valores son altamente dependientes de valores anteriores, lo que indica que la serie es no estacionaria.
Objetivo: La prueba ADF se usa para verificar si la serie contiene raíz unitaria.
Hipótesis nula: La serie temporal tiene raíz unitaria, por lo tanto es no estacionaria.
Interpretación: Si el estadístico de la prueba ADF es menor que el valor crítico, entonces la hipótesis nula se rechaza concluyendo que la serie temporal es Estacionaria.
Proceso de prueba: La prueba ADF funciona probando la hipótesis nula para verificar la presencia de una raíz unitaria en la serie temporal indica que la serie es no estacionaria.
-
Prueba KPSS
La prueba Kwiatkowski-Phillips-Schmidt-Shin (KPSS) es otra prueba estadística utilizada para verificar la estacionariedad de una serie temporal. Difiere de la prueba ADF en que prueba la hipótesis nula de que la serie temporal es estacionaria alrededor de una media o una tendencia determinística.
Objetivo: La prueba KPSS se usa para verificar si la serie es estacionaria.
Hipótesis nula: La serie temporal es estacionaria alrededor de una media constante o tendencia determinística.
Interpretación: Si el estadístico de la prueba KPSS es mayor que el valor crítico, la hipótesis nula se rechaza, indicando que la serie es no estacionaria.
Proceso de prueba: La prueba KPSS examina si la serie temporal es estacionaria probando una tendencia determinística o media alrededor de la cual fluctúa.
Cómo inferir los resultados de las pruebas
Las pruebas ADF y KPSS generan algunos valores estadísticos que nos ayudan a clasificar si la serie es estacionaria o no. Estos valores son:
- Estadístico de prueba
- P-Value
- Valores Críticos al 1%, 5% y 10% de Intervalos de Confianza
Estadístico de Prueba
El estadístico de prueba es el valor calculado en las pruebas para determinar cuán probable sería el valor si la hipótesis nula fuera verdadera.
Calcule el estadístico de prueba basándose en sus datos de muestra.
- Para una prueba z: el estadístico de prueba es z = (X̄ - μ) / ( σ/ √n) (Valor estadístico para datos completos)
- Para una prueba t: el estadístico de prueba es t = (X̄ - μ) / (s / √n) (Valor estadístico para datos de muestra)
Aquí, X̄ es la media de la muestra, μ es la media de la población, s es la desviación estándar de la Muestra o σ es la desviación estándar para todos los datos, n es el tamaño de la muestra.
En QuickML, los estadísticos de las pruebas ADF y KPSS se calculan a partir de sus respectivas pruebas sobre todos los datos de entrada. Ambos valores del estadístico de prueba proporcionan una medida de la evidencia contra la hipótesis nula.
La fortaleza de la evidencia se evalúa en tres niveles—fuerte, moderada y débil—comparando el valor del estadístico de prueba con los valores críticos en los niveles de significancia del 1%, 5% y 10%.
P-Value
¿Qué es el p-Value? El p-value en ambas pruebas indica la probabilidad de obtener un valor del estadístico de prueba tan extremo como el observado, asumiendo que la hipótesis nula es verdadera. El p-value se puede obtener de las tablas estadísticas para determinar si la hipótesis nula debe ser rechazada.
¿Cómo se deriva?
- Formulando y estimando el modelo de regresión ADF / KPSS
- Calculando el estadístico de prueba t𝛄 como se mencionó anteriormente.
- Comparando t𝛄 contra los valores críticos derivados de la simulación.
- Interpolando para obtener un p-value aproximado basado en cómo el estadístico de prueba se compara con los valores críticos bajo la hipótesis nula.
En la prueba ADF
Hipótesis nula: La serie temporal tiene raíz unitaria, lo que significa que es no estacionaria.
Interpretación: Asumiendo que el intervalo de significancia se establece en 5%.
- P-value bajo ( ≤ 0.05): Un p-value bajo indica que puede rechazar la hipótesis nula de raíz unitaria, sugiriendo que la serie es estacionaria.
- P-value alto ( > 0.05): Un p-value alto indica que no pudo rechazar la hipótesis nula de raíz unitaria, sugiriendo que la serie es no estacionaria.
En la prueba KPSS
Hipótesis nula: La serie temporal es estacionaria alrededor de una media constante o tendencia determinística.
Interpretación: Asumiendo que el intervalo de confianza es 5%.
- P-value bajo ( ≤ 0.05): Un p-value bajo sugiere que rechaza la hipótesis nula indicando que la serie es no estacionaria.
- P-value alto ( > 0.05): Un p-value alto sugiere que no puede rechazar la hipótesis nula de estacionariedad.
Valores Críticos (en niveles del 1%, 5% y 10%):
Los valores críticos son umbrales o referencias predefinidas utilizados en pruebas de estacionariedad como las pruebas Augmented Dickey-Fuller (ADF) y Kwiatkowski-Phillips-Schmidt-Shin (KPSS) para determinar si rechazar o no rechazar la hipótesis nula. Estos valores ayudan a evaluar la significancia estadística de los resultados de las pruebas.
Estos valores sirven como referencias para la toma de decisiones en ambas pruebas ADF y KPSS. Por ejemplo, al intervalo de significancia del 5%:
- Al valor crítico del 1%: Es un criterio muy estricto. Si el valor del estadístico de prueba es más extremo que el valor crítico del 1%, entonces hay evidencia fuerte para rechazar la hipótesis nula.
- Al valor crítico del 5%: Si el estadístico de prueba es más extremo que el valor crítico del 5%, entonces hay evidencia moderada para rechazar la hipótesis nula.
- Al valor crítico del 10%: Es un criterio más indulgente. Si el estadístico de prueba es más extremo que el valor crítico del 10%, entonces hay evidencia más débil para rechazar la hipótesis nula.
Ejemplo:
| Prueba ADF | Prueba KPSS |
|---|---|
|
|
|
|
Resultados posibles de las pruebas
Los siguientes son los resultados posibles de aplicar ambas pruebas.
Resultado 1: Ambas pruebas concluyen que la serie dada es estacionaria - La serie es estacionaria.
Resultado 2: Ambas pruebas concluyen que la serie dada es no estacionaria - La serie es no estacionaria.
Resultado 3: ADF concluye no estacionaria, y KPSS concluye estacionaria - La serie es estacionaria en tendencia. Para hacer la serie estrictamente estacionaria, la tendencia necesita ser eliminada en este caso. Luego, la serie sin tendencia se verifica por estacionariedad.
Resultado 4: ADF concluye estacionaria, y KPSS concluye no estacionaria - La serie es estacionaria en diferencia. Se debe usar la diferenciación para hacer la serie estacionaria. La serie diferenciada se verifica luego por estacionariedad.
Cómo abordar la estacionariedad presente en las columnas
En QuickML, usaremos tanto la prueba Augmented Dickey-Fuller (ADF) como la prueba Kwiatkowski-Phillips-Schmidt-Shin (KPSS) como se explicó anteriormente para verificar la estacionariedad de cada característica en el conjunto de datos de series temporales.
La plataforma QuickML ofrece un conjunto de técnicas de transformación de datos que ayudan a transformar columnas no estacionarias en el conjunto de datos. Al transformar estas columnas en estacionarias, QuickML asegura que los modelos generados usando los datos transformados estén bien adaptados para capturar los patrones y tendencias subyacentes.
Dos técnicas de transformación de datos que se usan principalmente para abordar la estacionariedad presente en las columnas son:
Diferenciación
La diferenciación se realiza calculando las diferencias entre observaciones consecutivas. Puede ayudar a estabilizar la media de una serie temporal eliminando cambios en el nivel de la serie temporal y por lo tanto eliminando (o reduciendo) la tendencia y la estacionalidad.
El orden de diferenciación indica el número de veces que la diferenciación necesita ser realizada en la serie no estacionaria para transformarla en serie estacionaria. El orden máximo de diferenciación a proporcionar en QuickML es 5. Si incluso después del quinto orden de diferenciación la serie es no estacionaria, cualquiera de los métodos en transformaciones de potencia se puede aplicar para estabilizar la varianza en la serie temporal.
Transformación de potencia
Una transformación de potencia hará que la distribución de probabilidad de una variable sea más gaussiana. Esto se describe a menudo como la eliminación del sesgo en la distribución, aunque más generalmente se describe como la estabilización de la varianza de la distribución. Aparte de la transformación logarítmica, podemos usar una versión generalizada de la transformación que encuentra un parámetro (lambda) que mejor transforma una variable a una distribución de probabilidad gaussiana.
En QuickML, hay dos tipos de transformaciones de potencia disponibles
- Transformación Box Cox
La transformación Box-Cox busca encontrar la mejor transformación de potencia de los datos que reduce el sesgo y estabiliza la varianza. Es efectiva cuando los datos exhiben heterocedasticidad (varianza desigual a través de los niveles de predictores) y/o sesgo. - Transformación Yeo Johnson
La transformación Yeo-Johnson es una modificación de la transformación Box-Cox que puede manejar tanto valores positivos como negativos de la variable objetivo. Al igual que Box-Cox, Yeo-Johnson transforma los datos para estabilizar la varianza y normalizar las distribuciones. Es más flexible, ya que puede manejar valores negativos. Yeo-Johnson se prefiere a menudo cuando los datos incluyen ceros o valores negativos, que el Box-Cox original no puede manejar.
Un parámetro en la transformación Yeo-Johnson, a menudo referido como lambda, se usa para controlar la naturaleza de la transformación. Se seleccionan diferentes técnicas de transformación basándose en el valor de lambda.
- lambda = -1. es una transformación recíproca.
- lambda = -0.5 es una transformación de raíz cuadrada recíproca.
- lambda = 0.0 es una transformación logarítmica.
- lambda = 0.5 es una transformación de raíz cuadrada.
- lambda = 1.0 es sin transformación.
Métricas de evaluación del modelo
Métricas para Pronóstico
Al evaluar pronósticos en el análisis de series temporales, se usan comúnmente varias métricas para evaluar la precisión y el rendimiento del modelo. Cada métrica proporciona diferentes perspectivas sobre qué tan bien los valores pronosticados se alinean con los valores reales observados.
1. Error Porcentual Absoluto Medio (MAPE)
MAPE expresa la diferencia porcentual absoluta promedio entre los valores predichos y reales en relación con los valores reales. Proporciona información sobre la precisión relativa de los pronósticos y es particularmente útil cuando se compara la precisión de modelos a través de diferentes conjuntos de datos o escalas.
Interpretación:
Por ejemplo, un valor de MAPE del 8% indica que el modelo es relativamente preciso ya que sus predicciones se desvían, en promedio, un 8% de los valores reales. Generalmente, valores de MAPE por debajo del 10% indican que el modelo es altamente preciso, entre 10-20% es bueno, y valores por encima del 20% pueden indicar la necesidad de mejorar el rendimiento del modelo.
2. Error Porcentual Absoluto Medio Simétrico (SMAPE)
SMAPE aborda el problema de la asimetría en MAPE al usar el promedio de los valores absolutos de los valores reales y predichos en el denominador. Se prefiere a menudo cuando se tratan valores pequeños o cero en el conjunto de datos, ya que evita la división por cero y proporciona una medida más equilibrada de la precisión.
Interpretación:
SMAPE ofrece una perspectiva equilibrada sobre el error, particularmente útil cuando los valores reales son pequeños o cero. Al usar el promedio de los valores reales y predichos en el denominador, SMAPE mitiga el impacto de la asimetría. Un valor de SMAPE más bajo indica una diferencia porcentual menor entre los valores reales y predichos, señalando una mejor precisión del modelo. Proporciona una medida simétrica que evita los problemas de errores porcentuales extremos presentes en otras métricas como MAPE.
3. Error Cuadrático Medio (MSE)
MSE mide el promedio de los cuadrados de los errores, dando más peso a los errores grandes. Proporciona una visión más detallada de la dispersión de los errores pero puede estar fuertemente influenciado por los outliers debido a la operación de elevación al cuadrado. MSE es útil para penalizar los errores más grandes de manera más significativa.
Interpretación:
MSE destaca la varianza de los errores, con los errores más grandes recibiendo más peso debido a la función de elevación al cuadrado. Esta métrica es particularmente sensible a los outliers, haciéndola ideal para casos donde queremos penalizar las desviaciones grandes del valor real. Un MSE más bajo indica un modelo con menos y menores errores en promedio, aunque puede verse afectado desproporcionadamente por los outliers. Es útil para entender la dispersión del error pero puede no ser tan interpretable en unidades del mundo real.
4. Raíz del Error Cuadrático Medio (RMSE)
RMSE es la raíz cuadrada del MSE y es más interpretable en las mismas unidades que los datos originales. Al igual que MSE, RMSE da una medida de la magnitud promedio del error, con valores más altos indicando errores promedio más grandes. Se usa ampliamente y proporciona un buen equilibrio entre la sensibilidad al tamaño del error y la interpretabilidad.
Interpretación:
RMSE proporciona una magnitud de error promedio, reteniendo las mismas unidades que los datos originales, lo que la hace más interpretable que MSE. RMSE es sensible a errores grandes y se usa comúnmente para entender los errores de predicción típicos. Un valor de RMSE más bajo indica un modelo con menor error y mejor precisión predictiva. Es útil para modelos donde interpretar los errores en términos de las unidades de datos originales es útil, dando una idea clara del “tamaño” de los errores.
5. Error Logarítmico Cuadrático Medio (MSLE)
MSLE calcula la media de las diferencias al cuadrado entre el logaritmo natural de los valores predichos más uno y el logaritmo natural de los valores reales más uno. Penaliza las subestimaciones más fuertemente que las sobreestimaciones.
Interpretación:
MSLE se enfoca en la razón de los valores predichos a los reales, amortiguando el impacto de los valores grandes al aplicar una transformación logarítmica. Esta métrica penaliza las sub-predicciones más que las sobre-predicciones, haciéndola adecuada para modelos donde las subestimaciones son más perjudiciales que las sobreestimaciones. Un valor de MSLE más bajo implica que los valores predichos se alinean estrechamente con los valores reales en una escala logarítmica, reduciendo la penalización por alta varianza en valores grandes y enfatizando el rendimiento en una escala multiplicativa.
6. Raíz del Error Logarítmico Cuadrático Medio (RMSLE)
RMSLE es simplemente la raíz cuadrada de MSLE. Proporciona una medida más interpretable en las mismas unidades que la variable objetivo. Al igual que MSLE, RMSLE penaliza las subestimaciones más fuertemente que las sobreestimaciones debido a las diferencias al cuadrado.
Interpretación:
RMSLE es la raíz cuadrada de MSLE, preservando la interpretabilidad en términos de las unidades originales, aunque en una escala logarítmica. Al igual que MSLE, RMSLE penaliza las sub-predicciones más fuertemente, proporcionando una medida que prioriza los errores en el rango inferior. Un valor de RMSLE más bajo sugiere una alineación más cercana entre los valores predichos y reales en una escala logarítmica, ideal cuando las grandes discrepancias positivas son tolerables pero las subestimaciones necesitan ser minimizadas.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us