Servicio LLM
Introducción al Modelo de Lenguaje Grande (LLM)
Un Modelo de Lenguaje Grande (LLM) es un sistema avanzado de IA entrenado para generar texto similar al humano basándose en patrones aprendidos de vastas cantidades de datos como libros, sitios web y artículos. Aprovecha técnicas de aprendizaje profundo, particularmente la arquitectura de red neuronal Transformer, que procesa secuencias completas de entrada en paralelo—a diferencia de modelos anteriores como las Redes Neuronales Recurrentes (RNNs), que manejaban las entradas secuencialmente. Este paralelismo permite el uso de GPUs para un entrenamiento eficiente, acelerando significativamente el proceso. Este entrenamiento típicamente involucra aprendizaje no supervisado o auto-supervisado, donde el modelo aprende a predecir la siguiente palabra en una oración reconociendo patrones, gramática y contexto dentro de los datos.
Mecanismo de LLM
Un aspecto fundamental de cómo operan los Modelos de Lenguaje Grande (LLMs) radica en su enfoque para representar palabras. Los modelos de aprendizaje automático anteriores dependían de tablas numéricas simples para representar palabras individuales, lo que dificultaba capturar las relaciones entre palabras—particularmente aquellas con significados similares. Esta limitación fue abordada con la introducción de vectores multidimensionales, conocidos como word embeddings. Estos embeddings mapean palabras en un espacio vectorial donde las palabras semántica o contextualmente similares se posicionan cerca unas de otras.
Con estos embeddings, los transformers convierten el texto en formatos numéricos usando el encoder, permitiendo al modelo comprender el contexto, el significado y las relaciones lingüísticas—como sinónimos o roles gramaticales. Esta comprensión procesada es luego utilizada por el decoder para generar texto significativo y coherente, permitiendo a los LLMs producir respuestas que reflejan la estructura y el flujo del lenguaje natural.
Aplicaciones de LLM
LLM permite soluciones impulsadas por IA en tiempo real en diversas industrias. Aquí están las aplicaciones clave donde los LLMs están generando un impacto significativo:
Chatbots y asistentes virtuales
Los LLMs impulsan chatbots y asistentes virtuales impulsados por IA utilizados en servicio al cliente, comercio electrónico y soporte empresarial. Estos asistentes pueden manejar consultas de clientes, proporcionar respuestas automatizadas y asistir con la solución de problemas. Las empresas los utilizan para mejorar la experiencia del usuario y reducir el tiempo de respuesta. Generación y resumen de contenido
Las organizaciones aprovechan los LLMs para generar contenido de alta calidad, como artículos, informes y descripciones de productos. Además, los LLMs resumen documentos extensos o artículos de noticias en formatos concisos y fáciles de leer, ahorrando tiempo y esfuerzo a los usuarios.
Generación y depuración de código
Los desarrolladores se benefician de los LLMs que asisten con la escritura, optimización y depuración de código en múltiples lenguajes de programación. Estos modelos ayudan a optimizar el desarrollo de software proporcionando sugerencias y explicaciones de código instantáneas, reduciendo el tiempo de desarrollo.
Traducción y localización de idiomas
Los LLMs mejoran los servicios de traducción proporcionando traducciones en tiempo real y conscientes del contexto para empresas e individuos. Esto es particularmente útil en la comunicación global, permitiendo una interacción fluida entre personas que hablan diferentes idiomas. Análisis de imágenes y texto (IA Multimodal)
Los LLMs multimodales avanzados, como Qwen 2.5 - 7B Vision Language, procesan tanto texto como imágenes. Estos modelos pueden describir imágenes, reconocer objetos y responder preguntas visuales. Industrias como la salud, la accesibilidad y la moderación de contenido digital utilizan estas capacidades para una automatización y toma de decisiones mejoradas. Los LLMs multimodales avanzados, como Qwen 2.5 - 7B Vision Language, procesan tanto texto como imágenes. Estos modelos pueden describir imágenes, reconocer objetos y responder preguntas visuales. Industrias como la salud, la accesibilidad y la moderación de contenido digital utilizan estas capacidades para una automatización y toma de decisiones mejoradas.
Comprendiendo LLM Serving
LLM Serving implica desplegar y ejecutar modelos de lenguaje grande (LLMs) para que puedan manejar solicitudes en tiempo real para predicciones o respuestas. Cuando un LLM está entrenado, se puede utilizar para realizar una variedad de tareas, como generar texto, responder preguntas, traducir idiomas o incluso comprender y analizar grandes conjuntos de datos.
Propósito de LLM Serving
El propósito principal de LLM Serving es cerrar la brecha entre un modelo entrenado y su uso en el mundo real. Permite a las organizaciones:
-
Operacionalizar modelos de IA en entornos de producción
-
Asegurar escalabilidad y confiabilidad para manejar solicitudes concurrentes en tiempo real
-
Ofrecer integración fluida en productos, herramientas y procesos comerciales
-
Transformar los LLMs de herramientas de investigación en sistemas prácticos y utilizables que impulsen resultados comerciales
Arquitectura de LLM Serving
Una arquitectura bien estructurada asegura que un sistema de servicio de LLM funcione eficientemente y responda rápidamente. Típicamente consiste en las siguientes capas:
-
Client layer: Recibe solicitudes de usuarios o aplicaciones, como preguntas o entradas de texto.
-
API layer: Convierte las solicitudes en un formato que el LLM puede entender y las envía al modelo.
-
Model layer: Ejecuta el LLM, procesa la solicitud y genera una respuesta.
-
Data layer: Maneja los datos de entrada y salida, asegurando un flujo de datos fluido entre el modelo y los usuarios.
Características únicas de LLM Serving en QuickML
QuickML facilita el uso de varios modelos de lenguaje grande (LLMs) dentro de una interfaz de chat. Los usuarios pueden seleccionar diferentes modelos según sus necesidades y obtener respuestas en tiempo real.
A diferencia de muchas plataformas competidoras que ofrecen opciones limitadas o rígidas de ajuste de parámetros, QuickML le otorga amplias opciones de personalización, asegurando mayor flexibilidad y control. Esto es lo que distingue a QuickML:
-
Ajuste de respuestas sin esfuerzo: Ajuste la creatividad, coherencia y longitud de salida directamente dentro de la interfaz fácil de usar.
-
Cambio de modelo fluido: Cambie fácilmente entre múltiples modelos LLM dentro de una sola interfaz de chat para encontrar el mejor ajuste para sus necesidades.
-
Integración sin esfuerzo: Despliegue modelos en aplicaciones de terceros usando la URL del endpoint proporcionada para una implementación fluida y escalable.
-
Rendimiento optimizado y control de costos: Adapte las respuestas para minimizar el uso innecesario de tokens, optimizando tanto la velocidad como la eficiencia de costos.
-
Accesibilidad mejorada: No se requiere configuración compleja; QuickML hace que las capacidades avanzadas de IA sean accesibles incluso para usuarios no técnicos.
Modelos disponibles en LLM serving
A continuación se presentan algunos de los modelos disponibles en QuickML, junto con sus capacidades y casos de uso.
Qwen 2.5 -14B Instruct
Un modelo de lenguaje ligero pero eficiente diseñado para tareas de propósito general, como responder preguntas, resumir texto y generación de contenido.
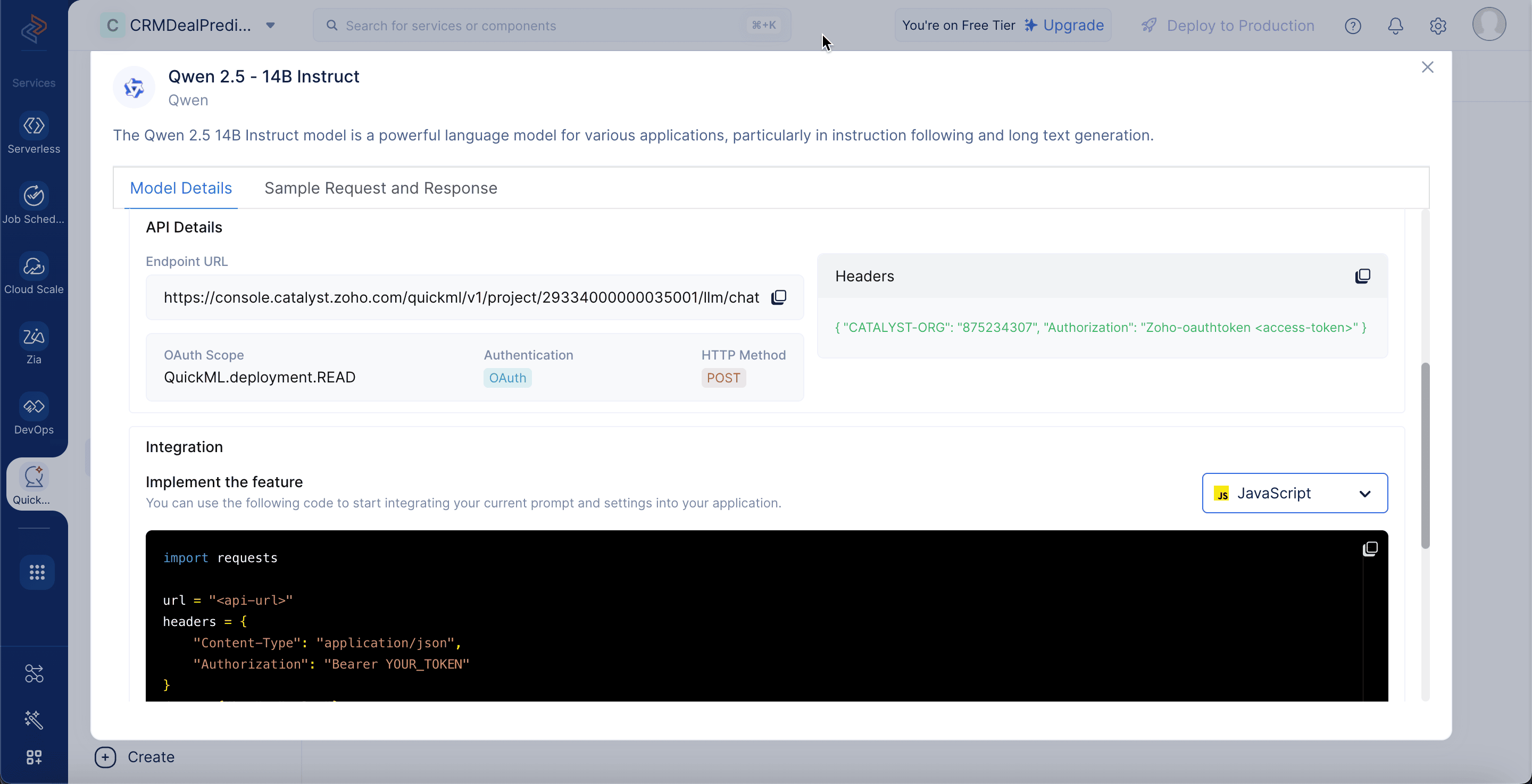
Detalles del modelo Qwen 2.5 - 14B Instruct
Para ver los detalles del modelo, vaya a la pestaña LLM Serving, seleccione Models y elija el modelo Qwen 2.5 - 14B Instruct. Los detalles del modelo incluyen:
-
Model Size: El modelo consta de 14 mil millones de parámetros, permitiendo comprensión y generación de lenguaje de alto nivel.
-
Training Size: Ha sido entrenado en un masivo de 18 billones de tokens, proporcionando amplia cobertura de conocimiento en dominios diversos.
-
Parameters: El modelo usa 14 mil millones de pesos aprendibles para generar respuestas precisas y conscientes del contexto.
-
Input Token Limitations: Admite entradas de hasta 128,000 tokens, permitiendo el procesamiento de contextos y documentos muy grandes.
-
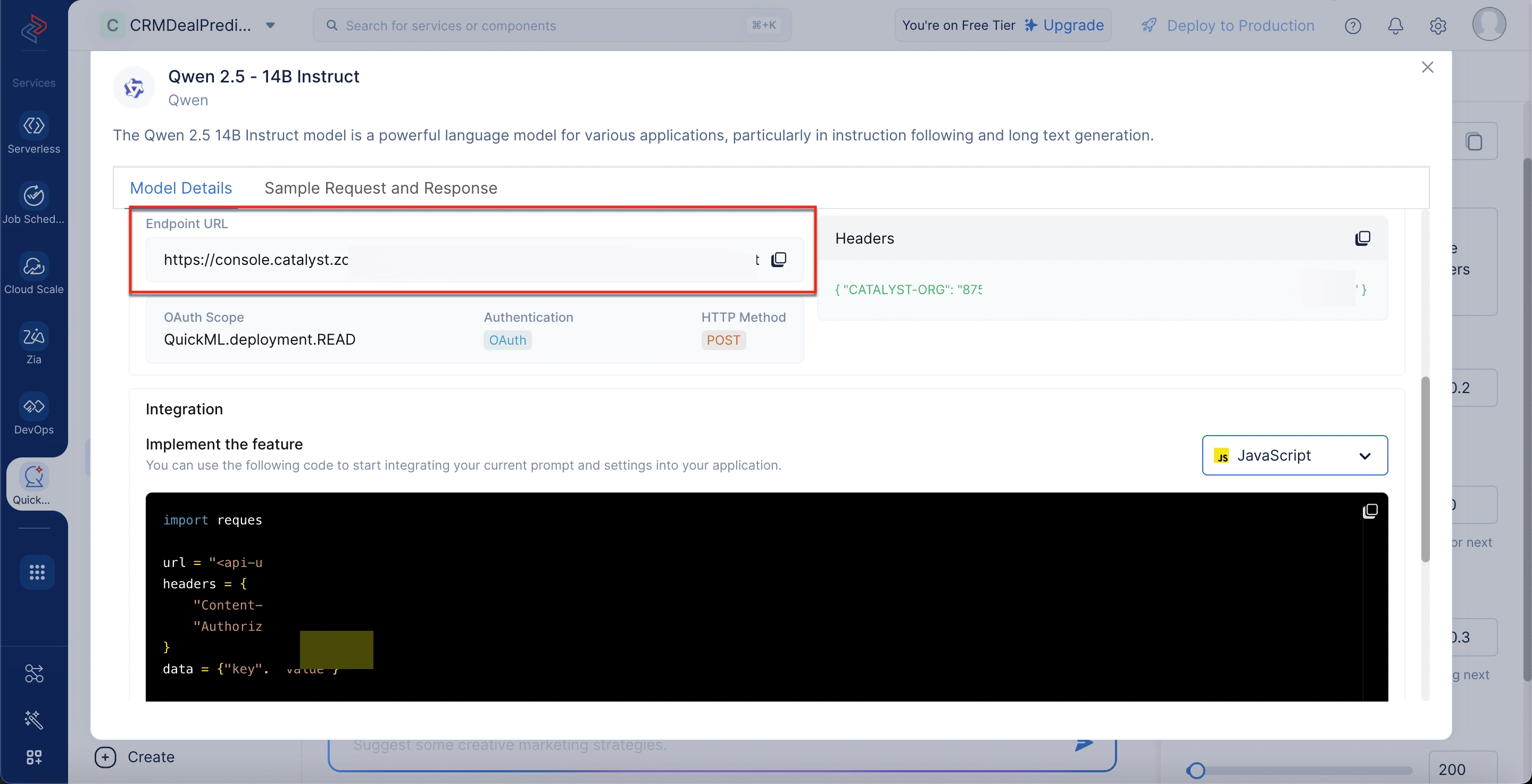
Endpoint URL: La dirección de API utilizada para enviar prompts al modelo.
-
OAuth Scope: El nivel de permiso requerido para acceder al modelo.
-
Authentication: Especifica OAuth como el método para verificar la identidad del usuario.
-
HTTP Method: Indica que las solicitudes de API deben realizarse usando el método POST.
-
Headers: Requiere metadatos, incluyendo ID de organización y token OAuth, para autorización.
-
Integration Section: Proporciona código de ejemplo para conectar su aplicación con el modelo.
-
Sample Request 1: Un formato JSON de entrada de ejemplo que muestra cómo enviar un prompt al modelo Qwen 2.5 - 14B Instruct junto con parámetros como top_p, temperature y max_tokens.
-
Sample Response 1: El formato JSON de salida que contiene la respuesta generada por el modelo basada en el prompt.
-
Possible Error Responses: Lista errores de estado HTTP comunes como 400 (Bad Request) y 500 (Internal Server Error).
-
Sample Error Response: Un mensaje de error estructurado que incluye un código, mensaje y razón opcional para depurar llamadas de API fallidas.
Puede consultar la sección Integrar LLM en su aplicación para los pasos de integración del modelo en su aplicación.
Qwen 2.5 - 7B Coder
Un modelo especializado construido para tareas relacionadas con programación, incluyendo generación de código, depuración y explicación.
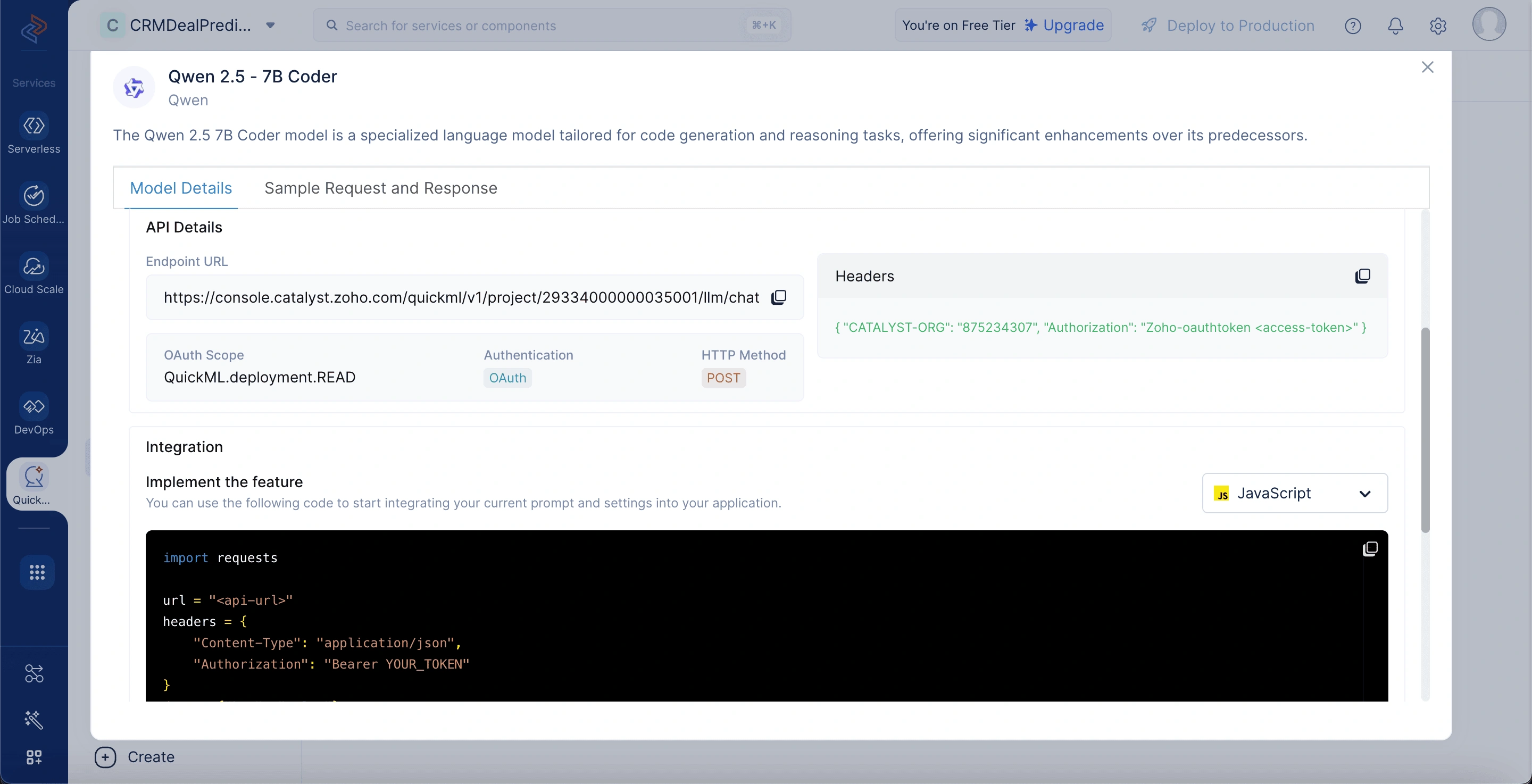
Detalles del modelo Qwen 2.5 - 7B
Para ver los detalles del modelo, vaya a la pestaña LLM Serving, seleccione Models y elija el modelo Qwen 7B. Los detalles del modelo incluyen:
-
Model Size: El modelo consta de 7 mil millones de parámetros, ofreciendo un rendimiento sólido en comprensión y generación de lenguaje natural.
-
Training Size: Ha sido entrenado en 5.5 billones de tokens, permitiendo amplio conocimiento de dominio y comprensión contextual.
-
Parameters: El modelo utiliza 7 mil millones de pesos aprendibles para generar respuestas inteligentes y conscientes del contexto. Input Token Limitations: Admite entradas de hasta 128,000 tokens, haciéndolo adecuado para manejar código extenso e instrucciones complejas.
-
Additional Capabilities: Equipado con características como generación de código, razonamiento y comprensión de contexto extendido. Endpoint URL: El endpoint de API utilizado para enviar solicitudes y prompts al modelo desplegado.
-
OAuth Scope: Define el nivel de acceso requerido para interactuar con el modelo (QuickML.deployment.READ).
-
Authentication: Usa OAuth para verificar y autorizar de forma segura el acceso del usuario.
-
HTTP Method: Requiere usar el método POST para enviar datos al modelo.
-
Headers: Contiene metadatos necesarios como ID de organización y token OAuth para autenticación.
-
Integration Section: Ofrece fragmentos de código listos para usar para ayudar a conectar y usar el modelo en su aplicación.
-
Sample Request 1: Demuestra cómo estructurar un prompt y configurar parámetros como nombre del modelo, temperature y max tokens.
-
Sample Response 1: Muestra la salida estructurada generada por el modelo en respuesta a la solicitud de ejemplo.
-
Possible Error Responses: Incluye errores típicos como 400 (Bad Request) y 500 (Internal Server Error) indicando solicitudes fallidas.
-
Sample Error Response: Muestra un mensaje de error en formato JSON con campos como código, mensaje y razón para solución de problemas.
Puede consultar la sección Integrar LLM en su aplicación para los pasos de integración del modelo en su aplicación.
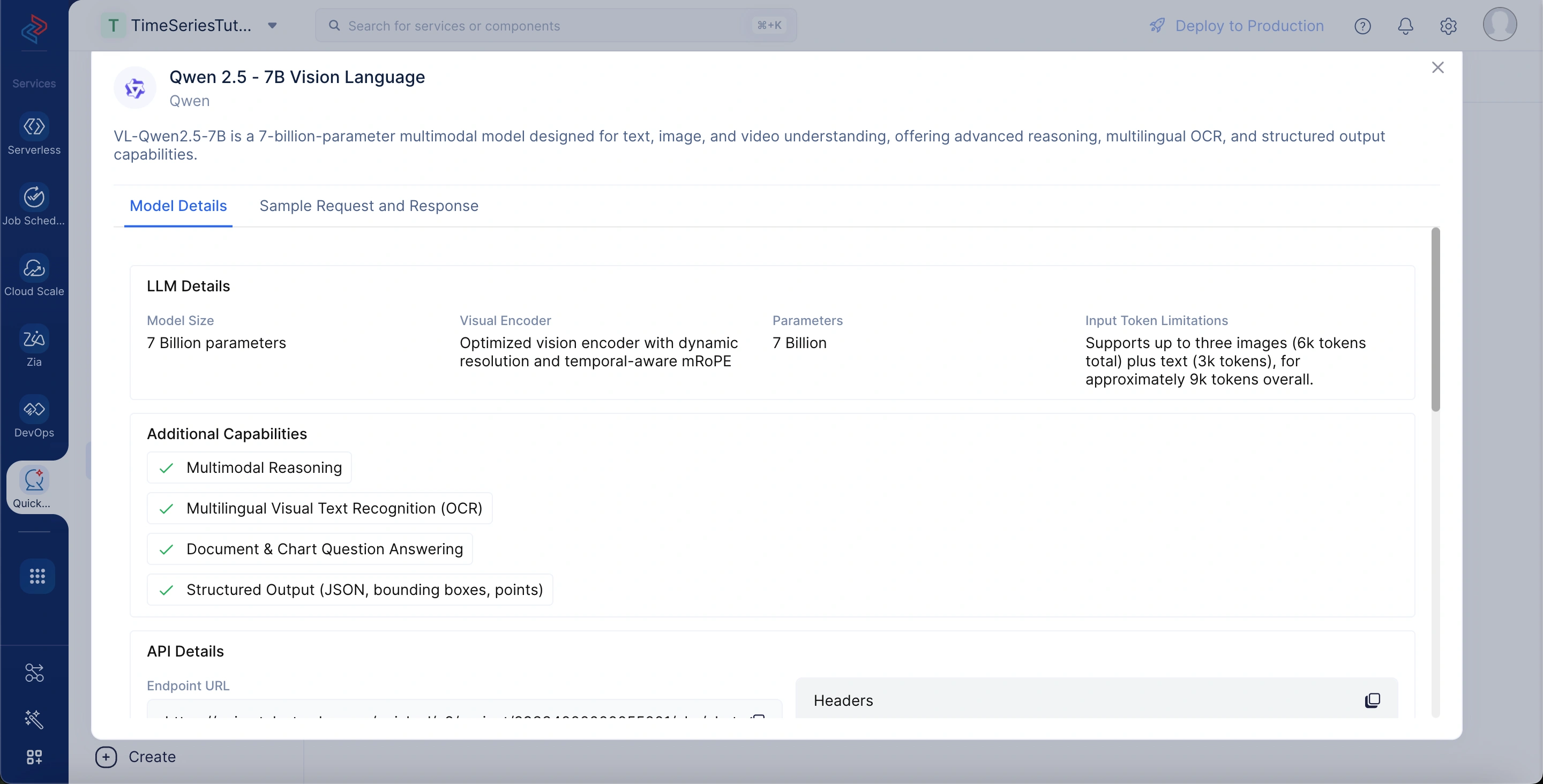
Qwen 2.5 - 7B Vision Language
Es un modelo de visión-lenguaje de 7 mil millones de parámetros que puede comprender tanto imágenes como texto. Está diseñado para tareas como subtitulado de imágenes, respuesta a preguntas visuales y razonamiento multimodal.
Para ver los detalles del modelo, vaya a la pestaña LLM Serving, seleccione Models y elija el modelo Qwen 2.5 - 7B Vision Language. Los detalles del modelo incluyen:
-
Model Size: El modelo de lenguaje principal consta de 7 mil millones de parámetros.
-
Visual Encoder: Usa un encoder de visión optimizado con resolución dinámica y mRoPE con consciencia temporal.
-
Parameters: Un total de 7 mil millones de pesos entrenables impulsan el modelo.
-
Input Token Limitations: Admite hasta tres imágenes (≈6k tokens) más texto (≈3k tokens), para un total de ~9k tokens.
-
Additional Capabilities: Proporciona razonamiento multimodal, OCR multilingüe, respuesta a preguntas sobre documentos y gráficos, y salidas estructuradas (JSON, cuadros delimitadores, puntos).
-
Endpoint URL: El endpoint de API utilizado para enviar prompts de texto e imagen al modelo de visión-lenguaje desplegado.
-
OAuth Scope: Requiere el ámbito de permiso QuickML.deployment.READ para interactuar con el modelo.
-
Authentication: Asegurado usando autenticación OAuth para acceso autorizado.
-
HTTP Method: Usa el método POST para transmitir datos de prompt y medios al modelo.
-
Headers: Incluye metadatos obligatorios como ID de organización y token de acceso para solicitudes de API seguras.
-
Integration Section: Proporciona código de ejemplo listo para usar en Python, JavaScript y otros lenguajes para integración.
-
Integration Section: Proporciona código de ejemplo listo para usar en Python, JavaScript y otros lenguajes para integración.
-
Sample Request 1: Demuestra entrada multimodal (texto + imágenes codificadas en base64), con parámetros configurables como system_prompt, top_k, top_p, temperature y max_tokens.
-
Sample Response 1: Muestra salida JSON estructurada, extrayendo detalles como información de contacto, habilidades, educación y proyectos de las imágenes de documentos proporcionadas.
-
Possible Error Responses: Incluye errores estándar como 400 (Bad Request) y 500 (Internal Server Error).
-
Sample Error Response: Devuelve un JSON con código, mensaje y razón para ayudar a depurar problemas de API.
Puede consultar la sección Integrar LLM en su aplicación para los pasos de integración del modelo en su aplicación.
Desglose de la Interfaz de Chat
Antes de ver cómo acceder a la función LLM Serving en QuickML, veamos brevemente cómo está estructurada la interfaz de chat.
Selección de modelo
Ubicada en la parte superior izquierda bajo la pestaña “Chat”, esta sección le permite elegir entre los modelos LLM disponibles. Permite cambiar rápidamente de modelo dentro de la misma interfaz, facilitando probar diferentes modelos para casos de uso específicos sin salir de la interfaz de chat.
Ver detalles del modelo
Junto al nombre del modelo seleccionado, la opción View Model Details abre una ventana emergente que muestra información detallada sobre el modelo. Esto incluye aspectos como el tamaño del modelo, límites de tokens de entrada, datos de entrenamiento y opciones de integración. Le brinda información más profunda sobre lo que el modelo puede hacer y cómo se puede utilizar.
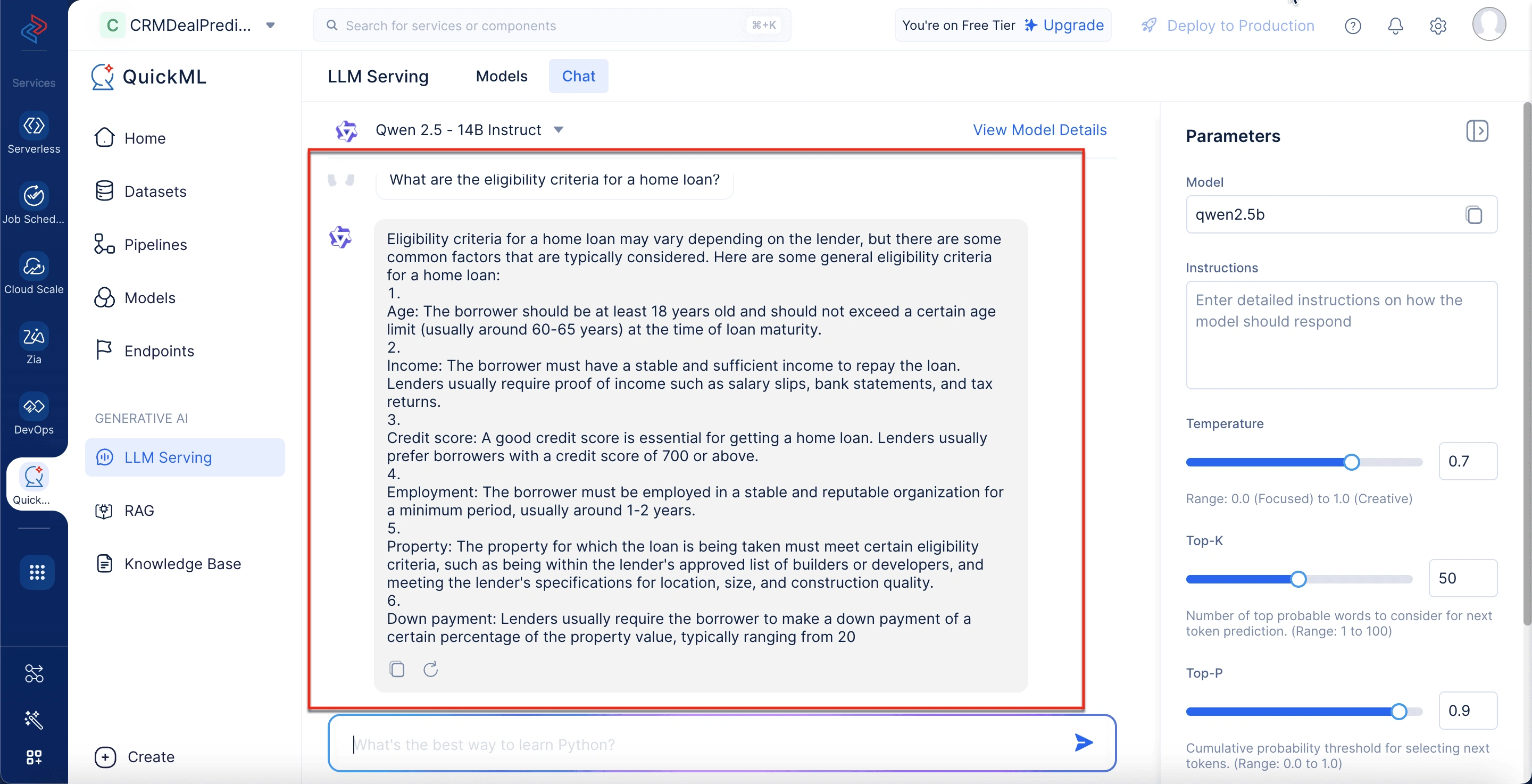
Interfaz de chat (Panel de conversación)
Esta área central es donde tienen lugar todas las interacciones. Puede escribir prompts y ver las respuestas generadas por el modelo en un formato de hilo. Cada respuesta incluye iconos para acciones como copiar y regenerar respuestas individuales.
Panel de parámetros
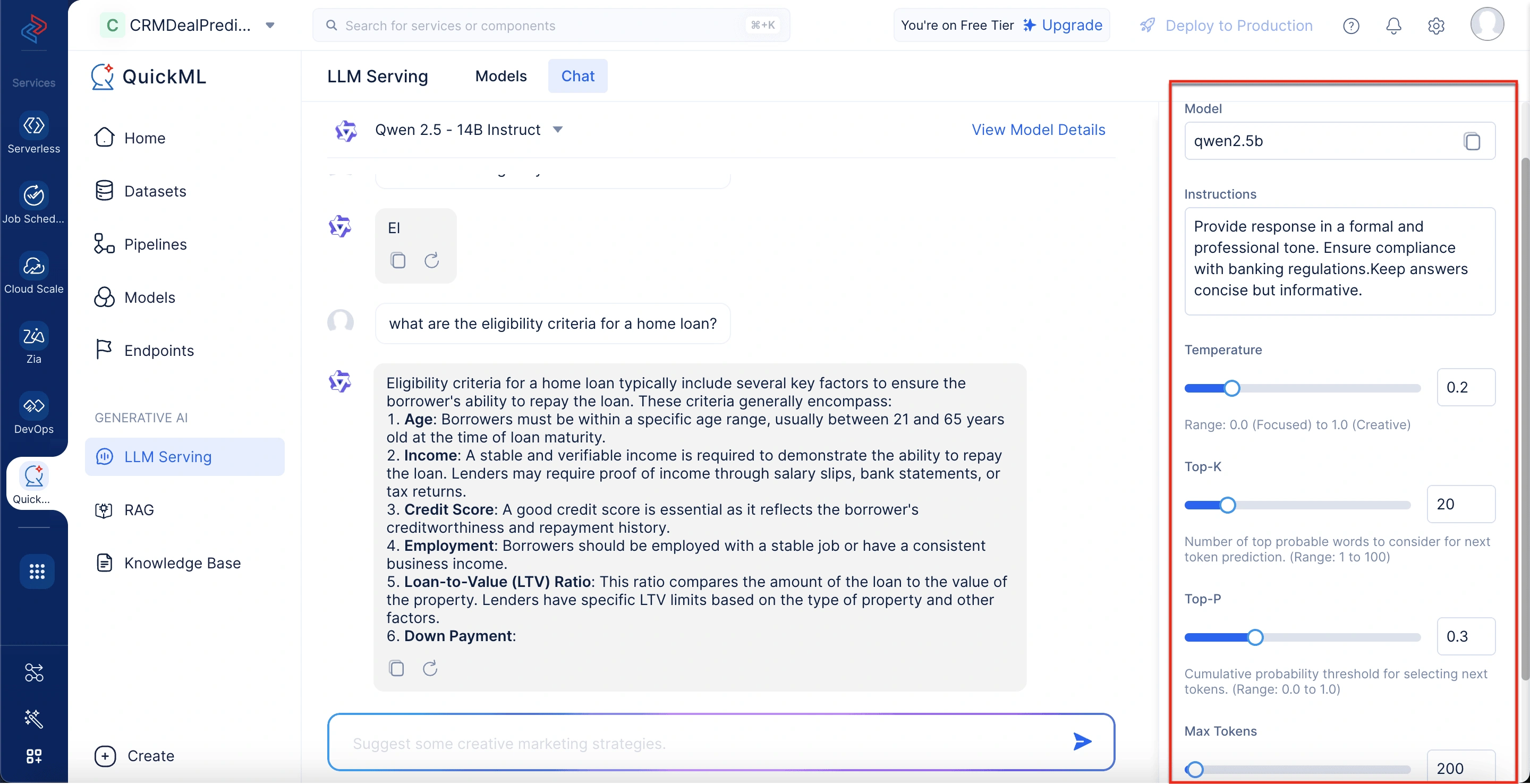
Ubicado en el lado derecho, este panel le permite ajustar el comportamiento del modelo modificando parámetros como Temperature, Top-K, Top-P y Max Tokens. También hay un campo de instrucciones para especificar tono, formato o requisitos específicos del dominio. Estas configuraciones ayudan a alinear la salida con las necesidades empresariales o específicas del usuario.
Cuadro de chat
En la parte inferior de la pantalla se encuentra el cuadro de entrada de chat—el área principal donde puede escribir sus prompts o preguntas para interactuar con el modelo de lenguaje seleccionado.
Parámetros en LLM serving
QuickML proporciona un entorno de servicio de LLM (Modelo de Lenguaje Grande) robusto y flexible, permitiendo a los desarrolladores y empresas ajustar el comportamiento del modelo de IA a través de una variedad de parámetros personalizables. Estas configuraciones le permiten controlar cómo el modelo interpreta las entradas, genera respuestas y alinea su salida con el tono, estructura y propósito deseados. Ya sea que esté construyendo un bot asesor legal, una herramienta de creación de contenido o un asistente de servicio al cliente, las opciones de configuración de parámetros de QuickML aseguran que su aplicación entregue respuestas que no solo son relevantes, sino también contextualmente adaptadas.
A diferencia de otras plataformas que restringen el control del usuario, QuickML prioriza la transparencia y la adaptabilidad—permitiéndole equilibrar la creatividad con la precisión, determinar la longitud ideal de respuesta y guiar al modelo para que se comporte de maneras que mejor sirvan a sus necesidades específicas del dominio.
Aquí hay un desglose de los parámetros disponibles:
Nombre del modelo
El campo del modelo le permite copiar el nombre del modelo para fácil referencia y despliegue.
Instructions
En el cuadro del campo Instructions, puede introducir instrucciones detalladas, guiando el estilo de respuesta del modelo y el enfoque de generación de contenido. Esto mejora la relevancia y consistencia de la salida para aplicaciones específicas.
Por ejemplo, una firma legal puede ingresar instrucciones como “Proporcionar respuestas en un tono legal formal con citas cuando sea aplicable.”, asegurando que el contenido generado por IA se alinee con los estándares de cumplimiento y profesionales.
Temperature
Controla el nivel de creatividad de las respuestas del modelo:
- Valores bajos (por ejemplo, 0.0 - 0.3): Respuestas más deterministas y precisas.
- Valores altos (por ejemplo, 0.7 - 1.0): Aumenta la variabilidad y creatividad, haciendo las respuestas más diversas y atractivas.
Por ejemplo, una institución financiera que establece la Temperature en 0.2 obtendría respuestas precisas como “La Reserva Federal aumentó las tasas de interés en un 0.25%.” mientras que establecerla en 0.8 podría generar “El reciente aumento de tasas de la Reserva Federal del 0.25% busca frenar la inflación, afectando las tasas hipotecarias y de préstamos.”
Top-K
Determina el número de palabras más probables consideradas para la predicción del siguiente token:
- Valores bajos (por ejemplo, 10 - 20): Produce respuestas más predecibles y controladas.
- Valores altos (por ejemplo, 50 - 100): Mejora la diversidad y variación en el texto generado.
Por ejemplo, un chatbot corporativo de RR.HH. con Top-K establecido en 10 puede generar respuestas estándar como “Valoramos la diversidad en nuestro proceso de contratación.”, mientras que 50 permite respuestas más ricas y atractivas como “En [Nombre de la Empresa], la diversidad está en el centro de nuestro proceso de contratación, fomentando la innovación y la inclusividad.”
Top-P
El muestreo Top-P también se conoce como muestreo Nucleus que generalmente varía de 0.0 - 1.0. Este parámetro establece un umbral de probabilidad acumulativa para la selección del siguiente token:
- Valores bajos (por ejemplo, 0.1 - 0.3): Produce respuestas altamente deterministas.
- Valores altos (por ejemplo, 0.8 - 0.9): Permite una generación de texto más diversa manteniendo la coherencia.
Por ejemplo, una IA de soporte al cliente usando una configuración de Top-P de 0.3 podría generar respuestas directas como “Su pedido llegará en 3 días.”, mientras que 0.9 podría llevar a “Se espera que su pedido llegue dentro de 3 días. ¡Recibirá una actualización de seguimiento pronto! Háganos saber si necesita más asistencia.”
Max tokens
Define el número máximo de tokens (entre 1 y 4096) que el modelo puede generar en una respuesta. QuickML permite un control preciso sobre la longitud de la respuesta, optimizando costo y latencia.
Por ejemplo, un equipo de cumplimiento que establece Max Tokens en 50 asegura resúmenes regulatorios concisos, como “GDPR exige la protección de datos para ciudadanos de la UE.”, mientras que 500 podría generar un análisis legal integral detallando disposiciones clave y medidas de cumplimiento.
Funcionamiento de LLM Serving en QuickML
-
Cuando un usuario envía una solicitud en la interfaz de chat de LLM serving de QuickML, el modelo seleccionado (como Qwen 2.5 - 14B Instruct) procesa la entrada.
-
El modelo analiza el contexto, la intención y el significado de la consulta para generar una respuesta relevante y coherente.
-
La respuesta se formula basándose en los datos de entrenamiento del modelo, asegurando precisión y relevancia contextual.
-
Los usuarios pueden refinar sus consultas o ajustar los parámetros del modelo para influir en el estilo de respuesta, tono y nivel de detalle.

Puntos clave a tener en cuenta:
-
La función LLM serving está disponible para usuarios que tienen acceso a la plataforma QuickML.
-
Puede cambiar fluidamente entre múltiples modelos LLM dentro de la interfaz de chat de QuickML.
-
Actualmente, no puede borrar las conversaciones de chat anteriores ni abrir una nueva ventana de chat; todas las conversaciones permanecen dentro de la misma interfaz de chat.
-
Los chats son específicos del usuario, asegurando que un usuario no pueda acceder a la conversación de otro usuario.
-
Puede cargar imágenes y escribir su consulta usando el modelo Qwen 2.5 - 7B Vision Language para generar respuestas.
-
El LLM serving de QuickML no usa sus datos para el entrenamiento del modelo. Todas las respuestas se generan basándose en sus datos preentrenados.
Acceso a LLM Serving en QuickML
Se puede acceder a LLM Serving en QuickML siguiendo los pasos a continuación:
- Inicie sesión en la plataforma QuickML.
- En la sección Generative AI, seleccione LLM Serving.
- Navegue a la pestaña Chat.
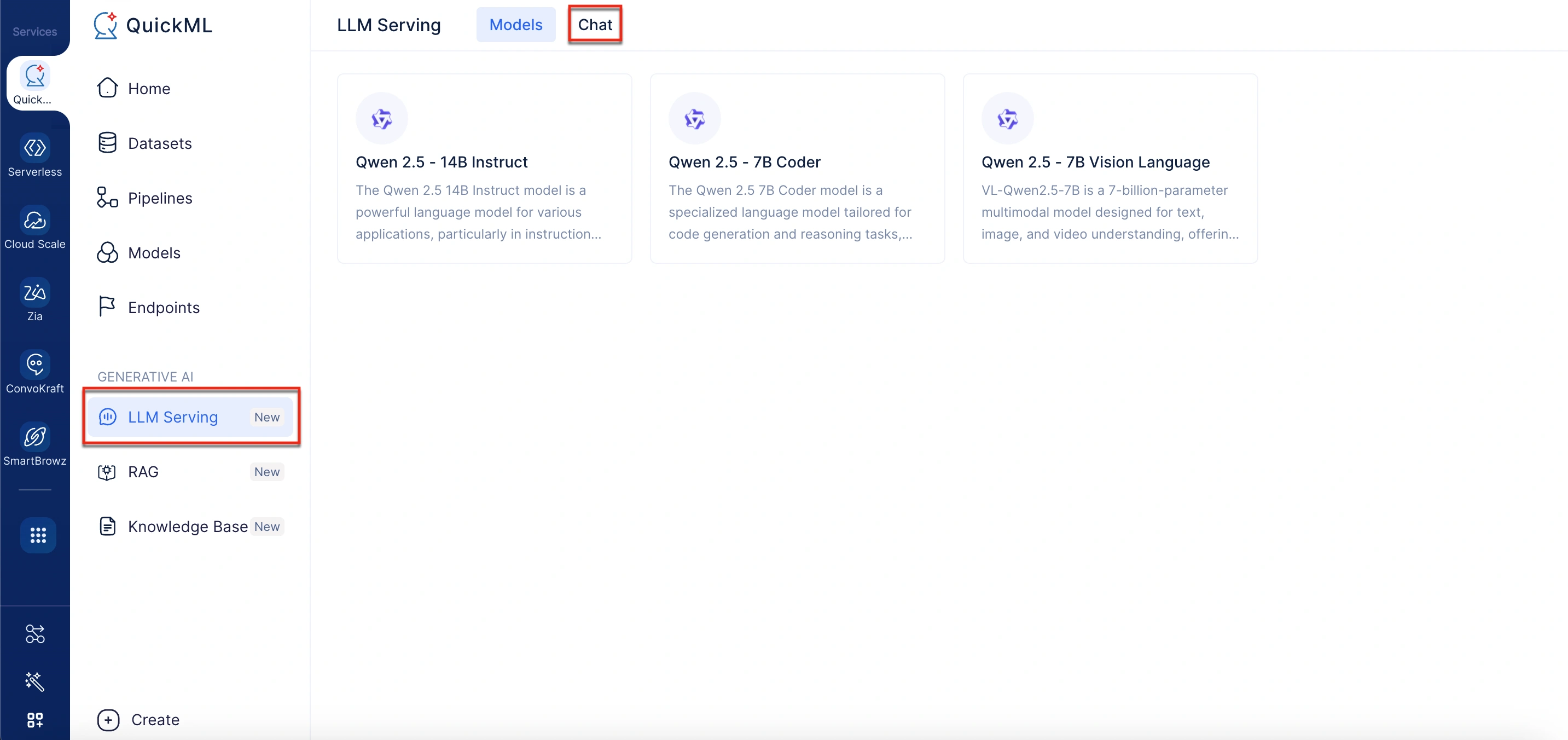
- Seleccione el modelo LLM deseado del menú desplegable.
- Puede seleccionar Qwen 2.5 - 14B Instruct, Qwen 2.5 - 7B Coder o Qwen 2.5 - 7B Vision Language
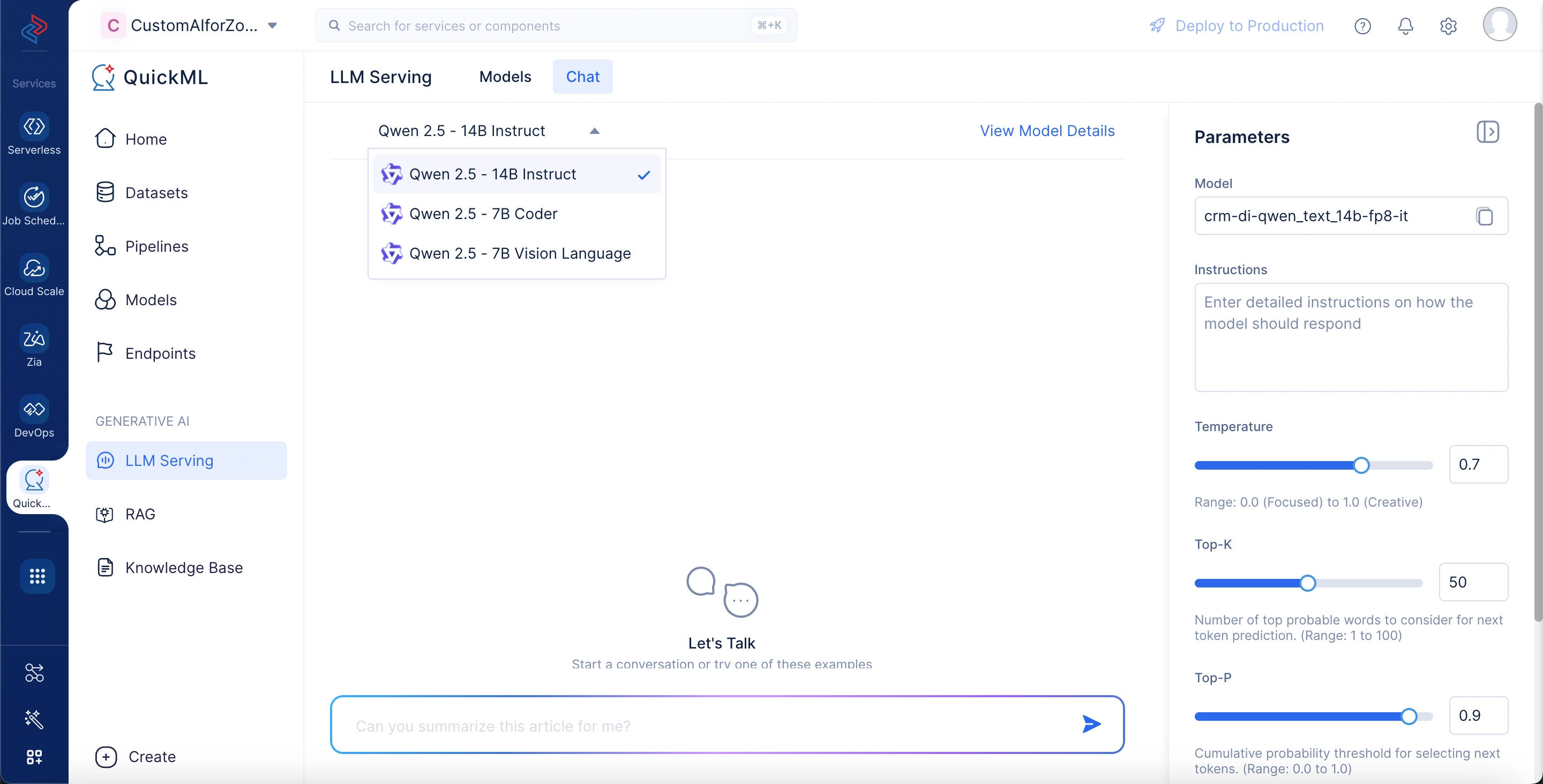
- Comience a ingresar sus consultas en la interfaz de chat.
Nota: La interfaz de chat genera respuestas basándose en la configuración de parámetros predeterminada. Sin embargo, puede ajustar las configuraciones según sea necesario para adaptarse a sus requisitos.
Para configurar los ajustes de parámetros
- En la sección Generative AI, seleccione la pestaña LLM Serving.
- Navegue a la pestaña Chat.
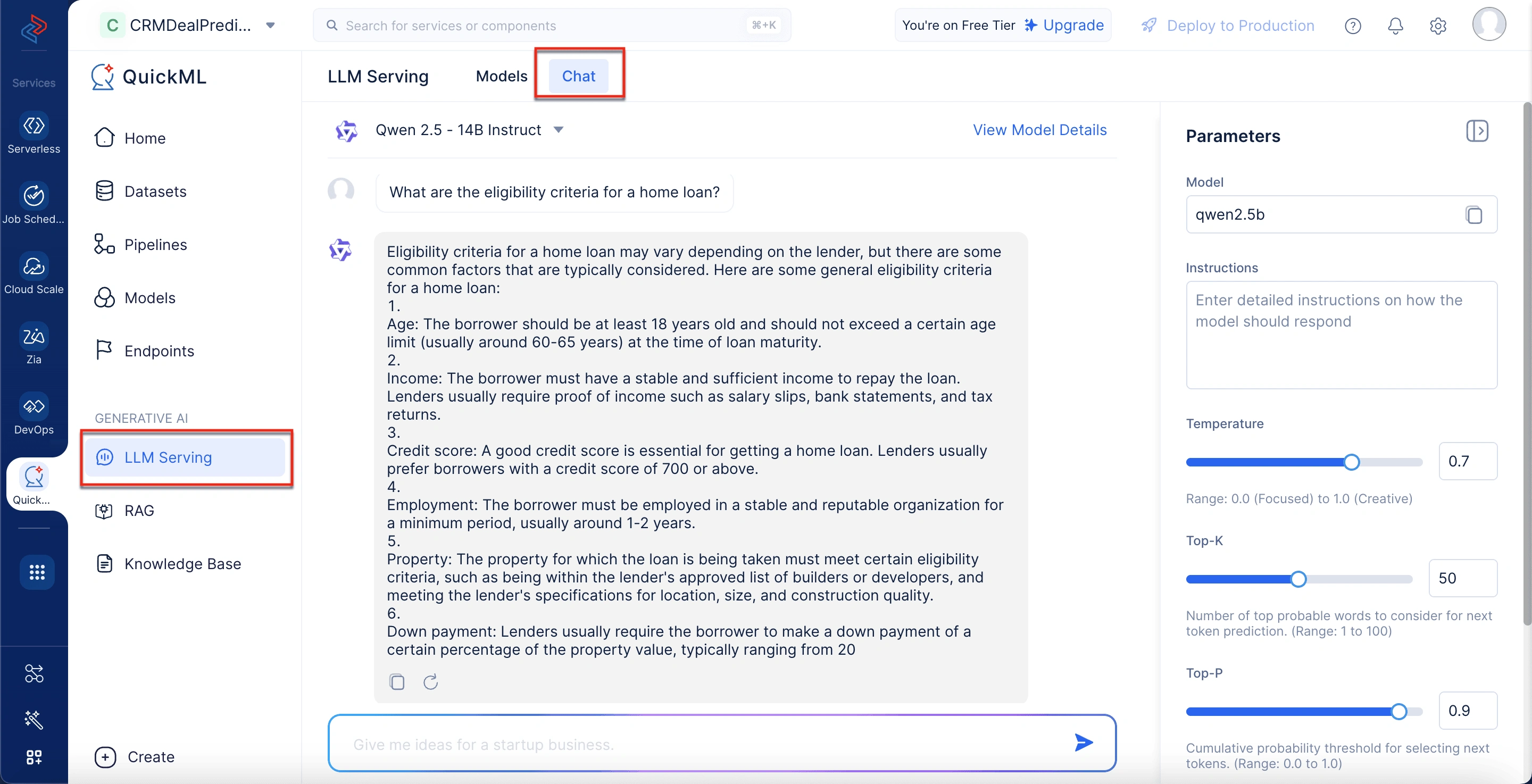
- En Parameters en el panel derecho, configure lo siguiente:
- Ingrese las instrucciones detalladas sobre cómo debe funcionar el modelo.
- Controle el nivel de creatividad de las respuestas del modelo ajustando la Temperature.
- Ajuste el número de palabras más probables consideradas para la predicción del siguiente token en el campo Top-K.
- Establezca el parámetro para un umbral de probabilidad acumulativa para la selección del siguiente token en el campo Top-P.
- Defina el número máximo de tokens que el modelo genera por respuesta en el campo Max Tokens.
- Haga clic en Save.
Consideremos un caso de uso de ejemplo para entender cómo estos parámetros se pueden configurar en un escenario empresarial en tiempo real.
Configuración de parámetros para un chatbot de soporte al cliente en una institución financiera
Caso de uso:
Un banco quiere asistir a los clientes con consultas bancarias generales mientras asegura que las respuestas sean precisas, concisas y alineadas con las directrices regulatorias.
Paso 1: Ajuste de Parámetros para un Rendimiento Óptimo
| Parámetro | Configuración | Razón |
|---|---|---|
| Model | Qwen 2.5 -14B Instruct | Seleccionado por su equilibrio entre precisión y eficiencia. |
| Instructions | Proporcionar respuestas en un tono formal y profesional. Asegurar el cumplimiento de las regulaciones bancarias. Mantener las respuestas concisas pero informativas. | Asegura consistencia en las interacciones con los clientes. |
| Temperature | 0.2 | Mantiene las respuestas factuales y evita creatividad innecesaria. |
| Top-K | 20 | Limita la selección de palabras a las opciones más relevantes, reduciendo la variabilidad. |
| Top-P | 0.3 | Mantiene las respuestas enfocadas y predecibles, asegurando el cumplimiento regulatorio. |
| Max Tokens | 200 | Previene respuestas excesivamente largas mientras mantiene suficiente detalle para claridad. |
Paso 2: Interacción con la Interfaz de Chat
Una vez que los parámetros están configurados, el chatbot está listo para usar. Aquí hay un ejemplo de interacción:
Usuario: “¿Cuáles son los criterios de elegibilidad para un préstamo hipotecario?”
Respuesta del Chatbot (Qwen 2.5 - 14B Instruct, con parámetros ajustados): Los criterios de elegibilidad para un préstamo hipotecario típicamente incluyen varios factores clave para asegurar la capacidad del prestatario de pagar el préstamo. Estos criterios generalmente abarcan:
- Edad: Los prestatarios deben estar dentro de un rango de edad específico, generalmente entre 21 y 65 años al momento del vencimiento del préstamo.
- Ingresos: Se requiere un ingreso estable y verificable para demostrar la capacidad de pagar el préstamo. Los prestamistas pueden requerir prueba de ingresos a través de recibos de salario, estados de cuenta bancarios o declaraciones de impuestos.
- Puntuación crediticia: Una buena puntuación crediticia es esencial ya que refleja la solvencia y el historial de pagos del prestatario.
- Empleo: Los prestatarios deben estar empleados con un trabajo estable o tener un ingreso comercial consistente. Relación Préstamo-Valor (LTV): Esta relación compara el monto del préstamo con el valor de la propiedad. Los prestamistas tienen límites específicos de LTV basados en el tipo de propiedad y otros factores.
Integrar LLM en sus Aplicaciones
Más allá de utilizar modelos LLM dentro de la plataforma QuickML, puede integrarlos fluidamente en sus propias aplicaciones usando la URL del endpoint proporcionada. Esto permite a las empresas incorporar respuestas impulsadas por IA en varios procesos comerciales, como bots de soporte al cliente, herramientas de automatización de contenido y aplicaciones de análisis de datos.
Para habilitar una integración segura y eficiente, QuickML admite autenticación basada en OAuth para la generación de tokens de acceso. Puede consultar esta documentación para detalles sobre los diferentes tipos de aplicaciones OAuth y los pasos necesarios para generar y gestionar tokens de acceso.
Para obtener la URL del endpoint
- Navegue a la sección Generative AI dentro de QuickML.
- Seleccione la pestaña LLM Serving.
- En la pestaña Models, elija el modelo deseado.
- En la ventana emergente Model Details, desplácese hasta la sección API Details para obtener la URL del endpoint.
Última actualización 2026-03-30 13:40:30 +0530 IST
Yes
No
Send your feedback to us