時系列アルゴリズム
時系列予測は、時間の経過とともに収集された過去のデータを利用して将来のデータポイントを予測する予測分析タスクです。時系列における予測がどのように機能するかを深く掘り下げ、予測モデルを生成するために使用されるさまざまなアルゴリズムを探りましょう。
予測
予測とは、過去のデータのトレンドやパターンを調査して将来の値を予測するために統計的手法を使用することです。この分析により、ビジネスオーナーはモデルによって生成された予測に基づいて、将来の行動方針について十分な情報に基づいた意思決定を行うことができます。
時系列予測アルゴリズムは、単変量と多変量の2つのカテゴリに分類でき、それぞれ対応するタイプのモデルの作成につながります。
1. 単変量予測
単変量予測モデルは、時間の経過とともに記録された単一の特徴量または変数のみを含む単変量データセットを使用して構築されます。これらのモデルは、他の要因の影響を組み込まずに、その1つの変数の時間的パターン、トレンド、季節性のみに焦点を当てて将来の予測を行います。
単変量予測モデルを構築するために使用されるアルゴリズムには以下が含まれます:
- 移動平均 - MA
- 指数平滑法
- Holt-Winterの方法
- 自動自己回帰和分移動平均 - Auto ARIMA
- 季節性自己回帰和分移動平均 - SARIMA
- 自己回帰移動平均 - ARMA
- 自己回帰器 各アルゴリズムがどのように機能するかを詳しく理解しましょう。
a. 移動平均
移動平均(MA)モデルは、時系列分析における予測に一般的に使用される統計手法です。過去のデータポイントの平均を計算する代わりに、「ウィンドウサイズ」と呼ばれる固定期間数にわたる過去の予測誤差(または残差)の線形結合に基づいて将来の値を予測します。この方法はランダムな変動を平滑化し、データ内の短期的なトレンドやパターンを識別するのに役立ちます。
MAモデルは適用が容易でさまざまな種類の時系列データに有用ですが、過去の誤差のみに依存し、過去の値やデータに影響を与える可能性のある他の外部要因を直接考慮しません。そのため、精度を向上させデータのより複雑なダイナミクスを捉えるために、移動平均モデルを自己回帰モデルなどの他の予測手法と組み合わせることが推奨されることが多いです。
**移動平均(MA)**モデルで使用される過去の予測誤差の数は、MAの次数またはラグ(q)によって定義されます。MAの次数は、現在の値を予測するためにモデルに含まれる過去の誤差項(残差のラグ)の数を示します。
例えば、MA(q)モデルでは:
- q = 1の場合、モデルは前の誤差項(残差の1次ラグ)を使用します。
- q = 2の場合、前の2つの誤差項(1次と2次のラグ)を使用します。以降同様です。 MAの次数の選択はモデルのパフォーマンスに大きな影響を与える可能性があります。
利点
- この移動平均アルゴリズムは、次の数期間の売上予測など、短期予測に適しています。
- ランダムな変動を平滑化することで、時系列データからノイズを除去し、基礎となるパターンやトレンドを識別しやすくすることができます。
欠点
- 移動平均(MA)モデルは、過去の予測残差(誤差)のみに依存し、長期的にデータに影響を与える可能性のある過去の値や他の外部要因を直接考慮しないため、長期予測には適していません。
- 予測に使用される残差のウィンドウサイズに基づいて、データの突然の変化やトレンドへの反応が遅くなる場合があります。
- MAモデルは主に、単一の変数とその過去の誤差に焦点を当てた単変量時系列予測に使用されます。ただし、複数の変数が関与する多変量時系列予測では、移動平均はうまく機能しません。
- 多変量時系列分析では、目標は多くの場合、複数の変数間の関係を理解し、これらの相関関係を活用してより良い予測を行うことです。
- 多変量データにおいて個々の変数に独立して単純な移動平均モデルを直接適用すると、変数間の潜在的な相互依存性を捉えることができません。
b. 自己回帰モデル
自己回帰(AR)モデルは、時系列分析で一般的に使用される統計モデルの一種で、時系列の過去の値を入力として使用して将来の値を予測します。前後の値の間の相関を評価することにより、データの時間的依存性を捉えるのに特に有用です。モデルは、過去の値が将来の動作に直接影響を与えるという仮定に基づいて、過去の観測値の線形結合として将来の値を予測します。
ARの次数(p)は、自己回帰(AR)モデルで使用される過去の観測値の数として定義できます。現在の値を予測するためにモデルに含まれる時系列の前の値(ラグ)の数を示します。
例えば、AR(p)モデルでは:
- p = 1の場合、モデルは前の値(1次ラグ)を使用します。
- p = 2の場合、前の2つの値(1次と2次のラグ)を使用します。以降同様です。 ARの次数の選択はモデルのパフォーマンスに大きな影響を与える可能性があります。
利点
- ARモデルは、時系列データに存在する時間的依存性を効果的に捉えます。現在の値を自身の過去の値に回帰させることで、データのパターンやトレンドを捉えることができます。
- ARモデルのパラメータは明確な解釈を持ちます。各自己回帰パラメータは、現在の値に対する特定のラグ値の影響を表し、過去と現在の観測値の間の関係を理解しやすくします。
- ARモデルは外れ値に対してロバストで、ノイズの多いデータをうまく処理できます。短期的な変動を効果的にフィルタリングし、データの長期的なトレンドの捕捉に焦点を当てることができます。
- ARモデルは計算効率が高く、特に小規模から中規模のデータセットに適しています。他の時系列モデルと比較して比較的少ないパラメータで済むため、迅速な分析と予測に適しています。
欠点
- ARモデルは、過去と現在の観測値の間の線形関係を仮定します。この仮定は、すべての時系列データ、特に非線形関係や複雑なパターンに対しては成り立たない場合があります。
- ARモデルは、基礎となる時系列が定常であること、つまりその統計的特性が時間の経過とともに変化しないことを仮定します。しかし、多くの実世界の時系列は非定常な動作を示し、ARモデルの適用性を制限する可能性があります。
- ARモデルの適切な次数(ARラグ(p))の選択は難しく、反復的な実験や統計的診断が必要になる場合があります。不適切な次数を選択すると、モデルのパフォーマンスが低下し、不正確な予測につながる可能性があります。
- ARモデルは、特に基礎となるデータが非常に不安定であったり構造的変化を受けやすい場合、長期予測に対して正確な予測を提供するのに苦労する場合があります。
c. ARMAモデル
ARMA(自己回帰移動平均)は、自己回帰と移動平均の両方のコンポーネントを組み合わせた時系列予測手法です。自己回帰からの過去の値と移動平均手法からの過去の残差(誤差)を使用して将来の値を予測する統計モデルを構築します。このモデルは、定常時系列データにおける短期的な依存性やパターンを捉えるのに特に使用されます。
- 自己回帰(AR)コンポーネント:自己回帰コンポーネントでは、時系列の現在の値はその前の値の線形結合としてモデル化されます。自己回帰の「自己」は、現在の値が自身の過去の値に回帰されることを意味します。pの値が高いほど、より複雑な依存性を捉えます。
- 移動平均(MA)コンポーネント:移動平均コンポーネントでは、時系列の現在の値は過去の予測誤差の線形結合としてモデル化されます。移動平均パラメータは、現在の値の予測に過去の予測誤差に割り当てられる重みを決定します。自己回帰モデルと同様に、qの値が高いほど、より複雑な依存性を捉えます。
ARMAモデルは、自己回帰と移動平均の両方のコンポーネントを組み合わせて、データに存在する時間的依存性とランダムな変動を捉えます。
ARMA(p, q)モデルは、AR(p)とMA(q)コンポーネントの和として表されます。
利点
- ARMAモデルは、時系列データに存在する幅広いパターンやダイナミクスを捉えることができ、さまざまなアプリケーションに対して汎用性があります。
- ARMAモデルのパラメータは明確な解釈を持ち、アナリストが過去の観測値と将来の予測の間の基礎となる関係を理解することができます。
- ARMAモデルは外れ値に対してロバストで、ノイズの多いデータをうまく処理でき、不規則性のある実世界のデータセットに適しています。
- ARMAモデルは計算効率が高く、特に小規模から中規模のデータセットに適しており、迅速なモデル推定と予測が可能です。
欠点
- ARMAモデルは、基礎となる時系列が定常であること、つまりその統計的特性が時間の経過とともに変化しないことを仮定します。しかし、多くの実世界の時系列は非定常な動作を示し、ARMAモデルの適用性を制限する可能性があります。
- ARMAモデルは、特に基礎となるデータが非常に不安定であったり構造的変化を受けやすい場合、長期予測に対して正確な予測を提供するのに苦労する場合があります。
- ARMAモデルのARおよびMAコンポーネントの適切な次数(pとq)の選択は難しく、反復的な実験や統計的診断が必要になる場合があります。
- ARMAモデルのパフォーマンスは初期パラメータ推定に敏感である可能性があり、特に高次元パラメータ空間では収束の問題や次善の解につながる可能性があります。
d. ARIMAモデル
ARIMA(自己回帰和分移動平均)モデルは、ARMAモデルのARおよびMAコンポーネントに加えて差分コンポーネントを組み込むことで非定常データを処理するために設計された、時系列予測の一般的な統計手法です。定常および非定常の両方の時系列データに適用できるため、汎用性が高く強力な手法です。
そのコンポーネントの内訳は以下の通りです:
- 自己回帰(AR)項:観測値と一定数のラグ付き観測値(前の時間ステップ)との関係を表します。AR(p)モデルでは、時間’t’の系列の値は、時間’t-1’、’t-2’、…、’t-p’の値に線形に依存します。
- 和分(I)項:時系列を定常にするための生の観測値の差分を指します。定常性とは、平均や分散などの時系列の統計的特性が時間の経過とともに変化しないことを意味します。’d’で表される差分の次数は、定常性を達成するために必要な差分の回数を示します。
- 移動平均(MA)項:ラグ付き観測値に適用された移動平均モデルからの観測値と残差誤差の関係を説明します。MA(q)モデルでは、時間’t’の系列の値は、時間’t-1’、’t-2’、…、’t-q’の誤差項に線形に依存します。
ARIMAモデルはARIMA(p, d, q)として表されます:
- ‘p’は自己回帰部分の次数です。
- ’d’は差分の次数です。
- ‘q’は移動平均部分の次数です。 ARIMAモデルは、過去の観測値の線形結合、系列を安定させるための差分、およびモデルで説明されない予期しない変動を捉える誤差項に基づいて予測を行います。
Auto ARIMA
Auto ARIMAは、自己回帰(AR)、和分(I)、移動平均(MA)コンポーネントのさまざまな組み合わせを含む、可能なARIMAモデルの範囲を自動的に検索し、データに最も適合するモデルを識別します。AIC(赤池情報量基準)やBIC(ベイズ情報量基準)などの統計基準に基づいて各モデルを評価し、最適なモデルを決定します。
利点
- ARIMAは、経済、金融、社会データを含む幅広い時系列データを処理でき、さまざまな分野に適用可能です。
- モデルパラメータ(p, d, q)は、ラグ効果や差分の影響など、時系列の基礎となるダイナミクスに関する洞察を提供できます。
- ARIMAは堅固な統計原理に基づいており、時系列分析の信頼性の高い手法です。
- ARIMAは将来の期間の予測を生成でき、意思決定と計画のための貴重な洞察を提供します。
- ARIMAモデルは追加の外部要因や共変量を必要としないため、実装と解釈が比較的簡単です。
欠点
- ARIMAは、時系列が定常であるか、差分によって定常にできることを仮定します。実際には、一部のデータセットでは定常性の達成が困難な場合があります。
- 従来のARIMAモデルは、データの季節パターンの捕捉には適していません。季節データには季節性ARIMA(SARIMA)やその他の手法が必要です。
- 線形であり、一部の時系列データに存在する複雑な非線形関係を効果的に捉えられない場合があります。
- ARIMAモデルは、モデルパラメータを正確に推定するために十分な量の過去データを必要とします。短いまたはスパースなデータの場合、ARIMAはうまく機能しない可能性があります。
- ARIMAは、観測値が互いに独立であることを仮定しますが、すべての時系列データ、特に自己相関や系列相関がある場合には成り立たない可能性があります。
e. SARIMAモデル
季節性自己回帰和分移動平均(SARIMA)は、時系列データの分析と予測に季節性を組み込んだARIMAモデルの拡張です。SARIMAモデルは、非季節性パターンと季節性パターンの両方を示すデータに特に有用です:
- 季節差分:SARIMAは、トレンドの除去だけでなく季節パターンの除去のためにも時系列の差分を行います。これは、時間’t’の観測値から時間’t-s’の観測値を引くことで行われます。ここで’s’は季節周期を表します。
- 季節自己回帰(SAR)項:季節ARラグコンポーネントは、現在の観測値と季節間隔での過去の観測値との関係を説明します。データの季節パターンを捉えます。
- 季節移動平均(SMA)項:季節MAラグコンポーネントは、現在の観測値と季節間隔での過去の予測誤差との依存関係をモデル化します。
- 和分:ARIMAと同様に、和分は差分によって時系列を定常にするために使用されます。和分の次数(’d’で表される)は、定常性を達成するために必要な非季節差分の回数を表します。
- 自己回帰(AR)と移動平均(MA)項:これらのコンポーネントは、ARIMAと同様に、時系列の非季節的なダイナミクスを捉えます。
利点
- SARIMAはデータの季節パターンを明示的にモデル化し、月次売上データや四半期経済指標など、周期的な変動を持つ時系列のより正確な予測を可能にします。
- SARIMAモデルは、乗法的および加法的季節性、および不規則な季節パターンを含む、幅広い季節パターンを処理できます。
- ARIMAと同様に、SARIMAモデルは解釈可能なパラメータ(例:AR、MA、季節AR、季節MA)を提供し、時系列の基礎となるダイナミクスに関する洞察を提供できます。
- SARIMAモデルは、適切な季節周期とモデルパラメータが選択されている場合、基礎となるデータパターンの変化に対してロバストであり得ます。
欠点
- SARIMAモデルは非季節性ARIMAモデルよりも複雑で、季節的なダイナミクスを捉えるために追加のパラメータが必要です。この複雑さにより、モデルの推定と解釈がより困難になる場合があります。
- 適切な季節周期の選択とAR、MA、季節AR、季節MAの各項の次数の決定は困難であり、広範なモデル診断とテストが必要になる場合があります。
- SARIMAモデルの推定は、特に大規模なデータセットや多くのパラメータを持つモデルの場合、計算負荷が高く時間がかかる場合があります。
- SARIMAは差分後の時系列が定常であることを仮定します。定常性の確保には、データの慎重な検査と反復的なモデルフィッティングが必要になる場合があります。
これらの課題にもかかわらず、SARIMAは非季節性パターンと季節性パターンの両方を示すデータの時系列予測に強力なツールであり続けます。慎重なモデルの仕様とパラメータの選択により、SARIMAモデルは正確な予測と時系列データに関する貴重な洞察を提供できます。
f. 指数平滑法モデル
指数平滑法は、体系的なトレンドや季節コンポーネントを持つデータをサポートするように拡張できる、単変量データの時系列予測手法です。
ARIMAと同様に過去の観測値に基づいて予測を行いますが、これらの観測値の重み付け方法に重要な違いがあります:
- 指数的に減少する重み
- ARIMAでは重みが任意になり得るのとは異なり、指数平滑法は過去の観測値に指数的に減少する重みを割り当てます。これは、最近の観測値が古い観測値よりも予測にはるかに大きな影響を与えることを意味します。
- 例:今日の売上を予測する場合、昨日の売上は1週間前の売上よりも予測に大きな影響を与えます。
- 指数平滑法の種類
- 単純指数平滑法(SES):トレンドや季節性のないデータに適しています。過去の観測値のみを使用します。
- Holtの線形トレンドモデル:データのトレンドを捉えるためにSESを拡張します。
- Holt-Winters季節モデル:季節性(月次売上ピークなどの繰り返しパターン)を捉えるためにさらに拡張します。
利点
- さまざまなパターンを処理できるということは、以下を含むさまざまな種類の時系列データを処理するように適応できることを意味します:
- トレンドなし(単純指数平滑法)
- 線形トレンド(Holtの線形トレンドモデル)
- 季節パターン(Holt-Winters季節モデル)
- ARIMAや機械学習モデルなど、他のより複雑な予測手法と比較して、比較的少ない過去データで済みます。
- 最近の観測値により多くの重みが与えられるため、変化への応答性が高く、データの変化やシフトに素早く適応できます。
欠点
- 指数平滑法は、データに存在する複雑な関係や不規則な変動を捉えるのに苦労する場合があります。
- 指数平滑法モデルのパフォーマンスは、平滑化因子(alpha)などの平滑化パラメータの選択に敏感である可能性があります。
- 指数平滑法は、基礎となる時系列が定常であること、つまりその統計的特性が時間の経過とともに一定であることを仮定します。しかし、多くの実世界の時系列は非定常な動作を示します。
- 指数平滑法モデルは、データの外れ値や極端な値に敏感です。
g. Holt-Winter季節モデル
Holt-Wintersの方法は、三重指数平滑法とも呼ばれ、特にトレンドと季節性を示すデータを扱う際に時系列データの予測に広く使用される手法です。単純な指数平滑法を拡張して、これらのコンポーネントをより効果的に処理します。
- レベルコンポーネント(lt):系列の時間経過に伴う平均値を表します。観測値と前のレベルに基づいて各時間ステップで更新されます。時間’t’での更新されたレベルは、観測値’yt’、前のレベル’lt-1’、前のトレンド’bt-1’の組み合わせです。平滑化パラメータalphaを使用して計算されます。
- トレンドコンポーネント(bt):系列の時間経過に伴う変化の方向と速度を捉えます。最近のデータで観測されたトレンドを反映するように更新されます。時間’t’での更新されたトレンドは、現在のレベルと前のレベルの差、および前のトレンドの組み合わせです。平滑化パラメータbetaを使用して計算されます。
- 季節コンポーネント(st):固定間隔(例:日次、週次、月次)で繰り返される季節的な変動やパターンを説明します。データで観測された季節的な動作を反映するように更新されます。時間’t’での更新された季節コンポーネントは、観測値と前のシーズンの同じ時期に観測された対応する季節コンポーネントの組み合わせです。平滑化パラメータgammaを使用して計算されます。
Holt-Wintersモデルには2つの主要なタイプがあります
加法モデル:加法モデルは、季節変動が系列全体でほぼ一定である場合に使用されます。季節効果の大きさが時系列のレベルに依存しない場合に適しています。
Level : Lt=α(Yt−St−m)+(1−α)(Lt−1+Tt−1)
Trend: Tt=β(Lt−Lt−1)+(1−β)Tt−1
Season: St=γ(Yt−Lt)+(1−γ)St−m
Forecast: Yt+h=L t+hTt+St−m+h
乗法モデル:乗法モデルは、季節変動が系列のレベルに比例して変化する場合に使用されます。季節効果の大きさが時系列のレベルに応じて変化する場合に適しています。
Level : Lt=α(Yt/St−m)+(1−α)(Lt−1+Tt−1)
Trend: Tt=β(Lt−Lt−1)+(1−β)Tt−1
Season: St=γ(Yt/Lt)+(1−γ)St−m
Forecast: Yt+h=(Lt+hTt)St−m+h
利点
- トレンドと季節性の両方を持つ時系列データを捉えて予測するために特別に設計されており、幅広い実世界のアプリケーションに適しています。
- この方法は基礎となるデータパターンの時間的変化に適応するため、データが進化するトレンドや季節パターンを示す可能性のある動的な環境でロバストです。
- 結果の予測はレベル、トレンド、季節コンポーネントに基づいているため容易に解釈でき、時系列の将来の動作に関する洞察を提供します。
- この方法は複数のコンポーネントとパラメータを含みますが、より複雑な予測手法と比較して実装が比較的簡単です。
欠点
- 平滑化パラメータalpha、beta、gammaの適切な値の選択は困難であり、特にさまざまな特性を持つデータセットの場合、専門知識や広範な実験が必要になる場合があります。
- データの外れ値や突然の変化に敏感であり、特にこれらの異常が適切に対処されていない場合、予測の精度に影響を与える可能性があります。
- 他の指数平滑法と同様に、Holt-Wintersの方法はコンポーネント間の線形関係を仮定しており、一部の時系列データに存在する複雑な非線形パターンを十分に捉えられない場合があります。
- 大規模なデータセットや高頻度データに対するHolt-Wintersの方法のコンポーネントの推定と更新は、特に最適化手法なしで実装された場合、計算負荷が高くなる可能性があります。
2. 多変量予測アルゴリズム
a. ベクトル自己回帰(VAR)
ベクトル自己回帰(VAR)モデルは、複数の時系列間の線形相互依存関係を捉えるために使用される多変量時系列アルゴリズムです。単変量自己回帰(AR)モデルを多変量時系列データに一般化します。VARモデルの各変数は、自身の過去のラグとシステム内の他のすべての変数の過去のラグの線形関数です。
利点
- VARモデルは、従属変数と独立変数の仕様を必要とせずに、複数の時系列間の動的な関係を捉えるのに適しています。これにより、変数間の複雑な相互依存関係のモデリングに柔軟性があります。
- VARモデルのすべての変数は内生変数として扱われ、従属変数や独立変数として分類する必要がありません。この対称性により、変数が時間の経過とともにどのように相互作用するかについてより包括的な理解が可能になります。
- VARモデルは、各変数の自身および他の変数に対するラグ効果を明示的に考慮し、時間的依存性の詳細な分析を可能にします。
- VARフレームワークはグレンジャー因果性テストを可能にし、1つの時系列が別の時系列を予測できるかどうかを識別し、変数間の因果関係に関する洞察を提供します。
- VARモデルはインパルス応答分析を可能にし、1つの変数へのショックが時間の経過とともにシステム内の他の変数に与える影響を理解するのに役立ちます。これは政策分析や経済予測に特に有用です。
欠点
- VARモデルは、特に多くの変数とラグを扱う場合、多数のパラメータの推定が必要です。これにより過学習が発生し、モデルがノイズに敏感になり、汎化性が低下する可能性があります。
- 推定すべきパラメータの数が多いため、VARモデルは安定した信頼性の高い結果を得るために大量のデータを必要とします。これは、短い時系列やスパースなデータで作業する場合の制限となる可能性があります。
- VARモデルは強力ですが、特にモデルに多くの変数とラグが含まれる場合、変数間の関係の解釈は困難になる可能性があります。モデルの出力は複雑であり、正しく解釈するには高度な統計知識が必要になる場合があります。
- VARモデルは変数間の線形関係を仮定します。実際には、時系列変数間の関係は非線形である可能性があり、真のダイナミクスを捉えるモデルの有効性を制限する場合があります。
- ラグ長pの選択はVARモデリングにおいて重要です。ラグが少なすぎるとモデルの誤った仕様につながり、多すぎると過学習を引き起こす可能性があります。最適なラグ長の選択は常に簡単ではなく、慎重なテストと検証が必要なことがよくあります。
- 構造VAR(SVAR)モデルとは異なり、標準的なVARモデルは変数間の関係の構造的な解釈を提供しません。これは、基礎となるメカニズムの理解が重要な経済分析や政策分析において制限となる可能性があります。
- VARモデルの変数が高度に相関している場合、多重共線性が問題になり、係数の信頼性の低い推定につながる可能性があります。これにより、各変数が他の変数に与える真の影響を見分けることが困難になる可能性があります。
- 変数とラグの数が増加するにつれて、モデルパラメータの推定の計算負荷が増大します。これにより、特に大規模なデータセットの場合、VARモデルの計算負荷が高くなる可能性があります。
交差検証
時系列における交差検証は、時系列データセットでのモデルのパフォーマンスを評価するために使用される手法です。標準的な機械学習で使用される一般的なk分割交差検証とは異なり、時系列データには保持する必要のある時間的順序があります。そのため、この時間的依存性を処理するための特定の方法が使用されます。
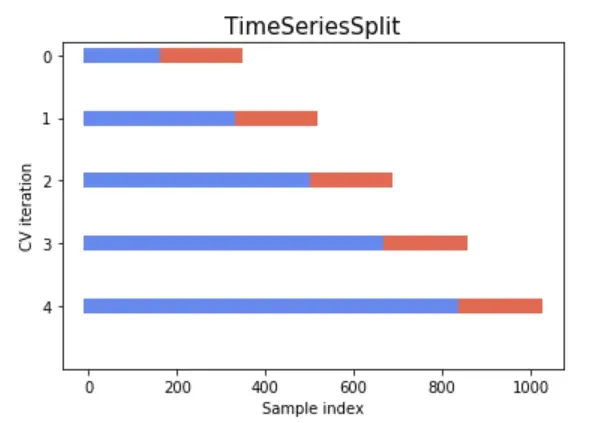
i. ローリング時系列分割
- この方法は、トレーニングセットが常に検証セットよりも前になるように、時系列データをトレーニングセットと検証セットに複数回分割します。
- 新しいデータが時間の経過とともに利用可能になる方法をシミュレートし、モデルが常にトレーニングセットに対して将来のデータでテストされることを保証します。
- データ分割の理解については、以下の画像を参照してください。
ii. ブロッキング時系列分割
- データを連続するブロックまたは分割に分けつつ、トレーニングセットとテストセットの間に重複がなく、データの時間的順序が維持されるようにします。
- トレーニング中にモデルが将来のデータを見ることを防ぎ、過学習を防止します。
- トレーニングセットが常に検証セットよりも前になるようにし、時間順序を尊重します。
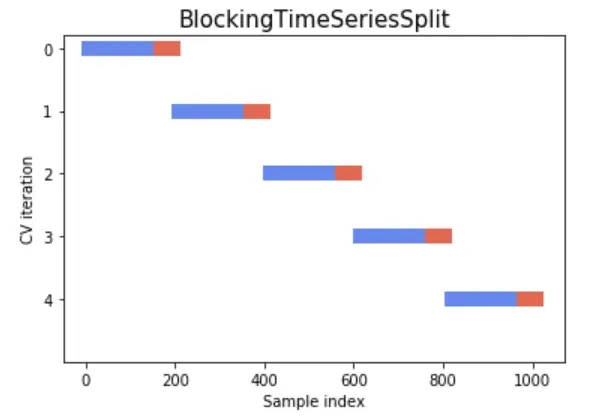
iii. 日次フォワードチェーニング
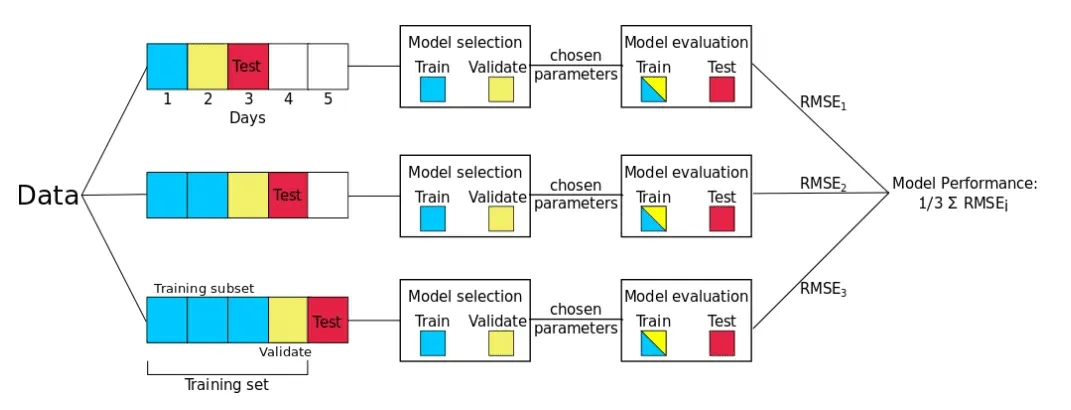
- 日次フォワードチェーニングは、フォワードチェーニングおよびローリングオリジン再キャリブレーション評価と呼ばれる方法に基づいています。この方法を使用して、各日をテストセットとして順次考慮し、すべての前のデータをトレーニングセットに割り当てます。
- この方法は多くの異なるトレーニング/テスト分割を生成します。モデル誤差のロバストな推定を計算するために、各分割の誤差が平均化されます。
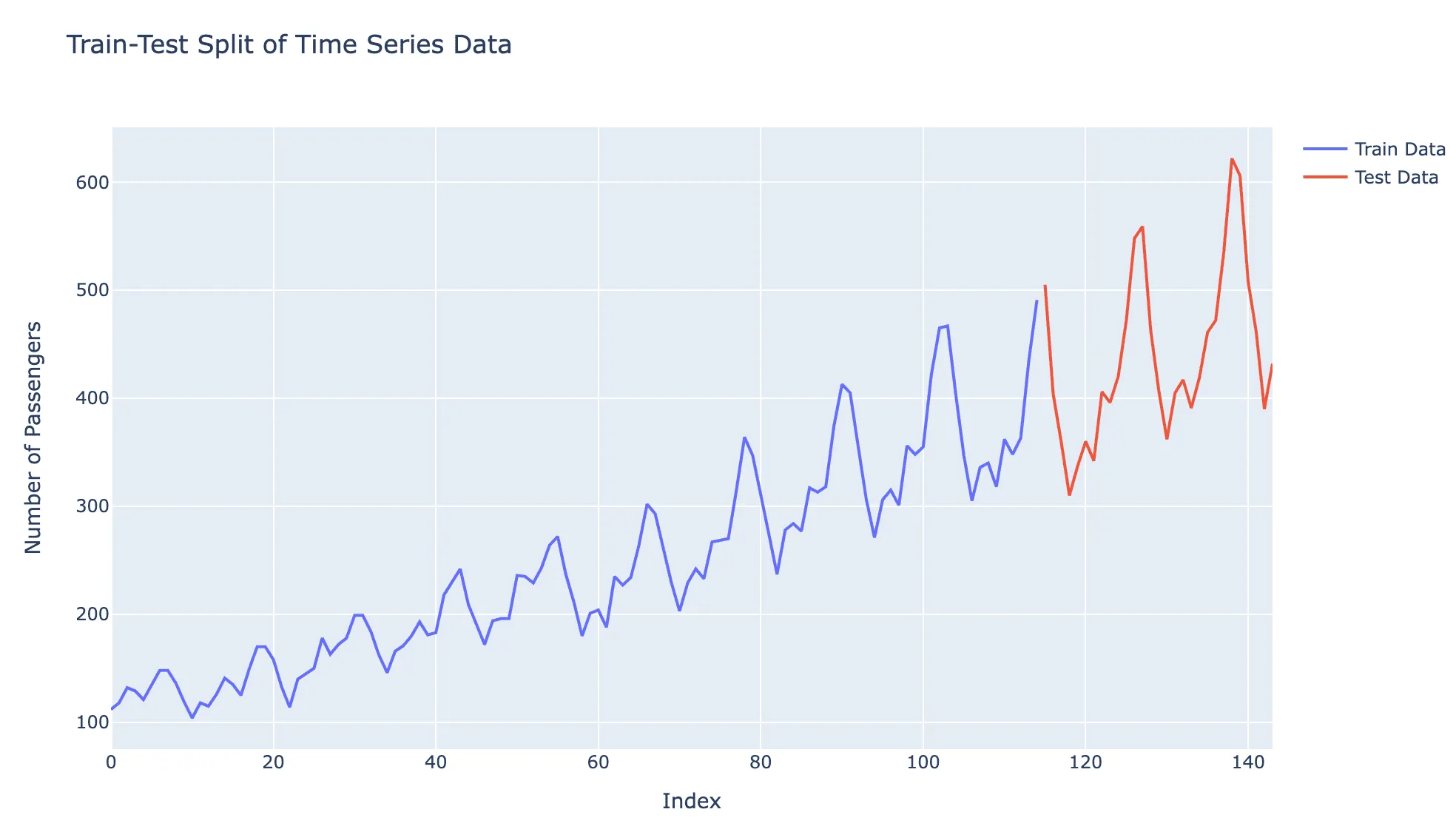
iv. 通常のトレーニング・テスト分割 - デフォルト 標準的なトレーニング・テスト分割シナリオでは、時系列データセットは2つのサブセットに分割されます:トレーニングセットとテストセットです。過去のデータを含むトレーニングセットはモデルのトレーニングに使用され、将来の未知のデータを含むテストセットでテストされます。これにより、過去のデータに基づいて将来の値を予測するモデルの能力をテストすることで、モデルのパフォーマンスと汎化能力を評価できます。
データのトレーニング・テスト分割の視覚的表現は以下の通りです:
パイプラインの構築
QuickMLは、時系列モデルを作成するためにスマートモードパイプラインビルダーを使用します。スマートビルダーは、データの前処理からモデル選択まで、モデル開発プロセスを簡素化するように設計された時系列モデル用のプリビルトテンプレートを提供します。これらのプリビルトテンプレートでは、オペレーションが事前に定義されており、ユーザーには各ステージを構成するためのさまざまなパラメータが提示されます。このテンプレートは、時系列モデルを構築するためにどのステージを使用するかの曖昧さを取り除き、モデル構築プロセスを効率化します。
可視化
分解チャート
分解チャートは、時系列データをその主要コンポーネントであるトレンド、季節性、残差(またはノイズ)に分解します。これらのコンポーネントの存在を検証し、データの全体的なパターンへの寄与を理解するのに役立ちます。分解は、異なる期間にわたって定期的な間隔で記録された時系列データの分析に特に有用です。
QuickMLでは、分解チャートは加法手法を使用し、元の時系列はそのコンポーネントの和として表されます:
Original Series = Trend + Seasonality + Residual
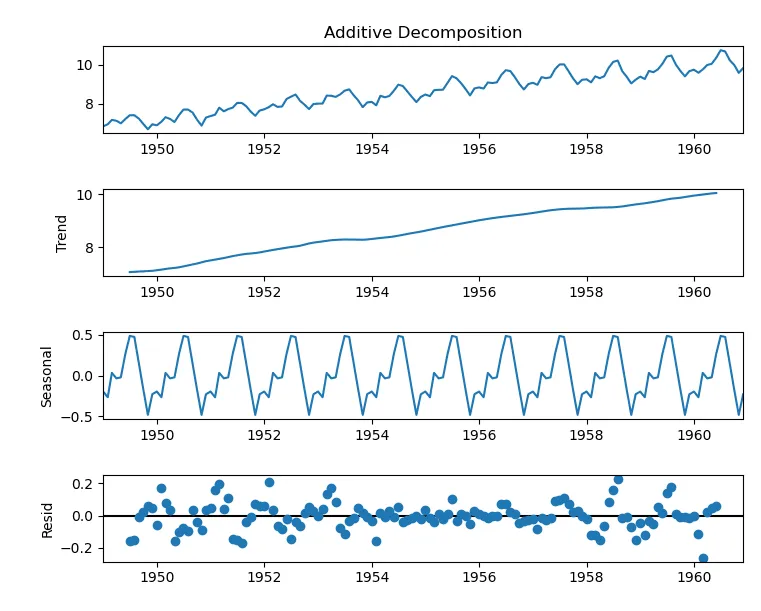
この手法は、季節性と残差の変動の大きさが系列全体にわたって一定であると仮定します。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us