Data Profiler y Viewer
¿Qué es el Data Profiling?
El data profiling es el proceso de revisar datos sin procesar; comprender su estructura, contenido e interrelaciones; e identificar oportunidades para obtener información analítica.
Es crucial al realizar el preprocesamiento de datos, realizar la visualización de datos y mejorar la puntuación de calidad de los datos. También ayuda a mejorar el análisis proporcionando inteligencia general sobre los datos que se están utilizando.
Ejemplos de cómo se puede utilizar el data profiling:
- Preprocesamiento de datos: Para identificar valores faltantes, valores únicos y duplicados, y formatos de datos inconsistentes, lo que ayuda a limpiar y preparar los datos para el análisis.
- Visualización de datos: El data profiling nos ayuda a comprender la distribución real de los datos e identificar cualquier valor atípico, para que podamos crear visualizaciones de datos más precisas e informativas.
- Mejora de la puntuación de calidad de datos: Al identificar y corregir los problemas de calidad de datos, el data profiling ayuda a mejorar la confiabilidad de los datos para análisis posteriores.
El data profiling involucra una variedad de actividades, incluyendo:
- Recopilar detalles estadísticos como min, max, mean y más para columnas numéricas
- Recopilar tipos de datos e identificar patrones recurrentes en los datos
- Encontrar redundancia y calidad de los datos
- Realizar análisis inter-tabla de datos tabulares
Data Profiling en QuickML
Los datos cargados en el módulo de datasets de QuickML pasan automáticamente por la sección de data profiling y proporcionan una comprensión rica e información valiosa de los datos.
-
Conteo de registros, valores únicos y porcentajes: QuickML puede encontrar el número de valores únicos y duplicados y sus respectivos porcentajes del total en cada columna de tus datos, que se pueden utilizar para actualizar eficientemente las filas y columnas.
-
Tipo de dato y Visualización: El Data Profiler de QuickML identifica con precisión el tipo de dato de cada característica en un conjunto de datos y visualiza la distribución para obtener información clara sobre los datos.
-
Valores faltantes: El Data Profiler de QuickML puede obtener el conteo y porcentaje de valores faltantes, como valores en blanco y nulos, y ayuda a los científicos de datos a establecer valores apropiados.
-
Detalles estadísticos: El Data Profiler de QuickML genera los siguientes datos estadísticos para columnas numéricas y categóricas:
| Columnas numéricas | Sum, Min, Max, Mean, Median, Standard Deviation, Variance y percentiles bajo, medio, alto | Columnas categóricas | Unique, Duplicates |
|---|
-
Versionado de Datasets y Puntuación de calidad QuickML puede perfilar múltiples versiones de los mismos datos y generar puntuaciones de calidad para cada versión. El perfil de datos se puede ver en cualquier momento usando la opción de versión en la página de detalles del Dataset.
-
Correlation Heatmap El data profiler genera un correlation heatmap para todas las versiones del conjunto de datos, que visualiza las interrelaciones de las características y el grado en que están relacionadas entre sí y con la característica objetivo.

Data Viewer en QuickML
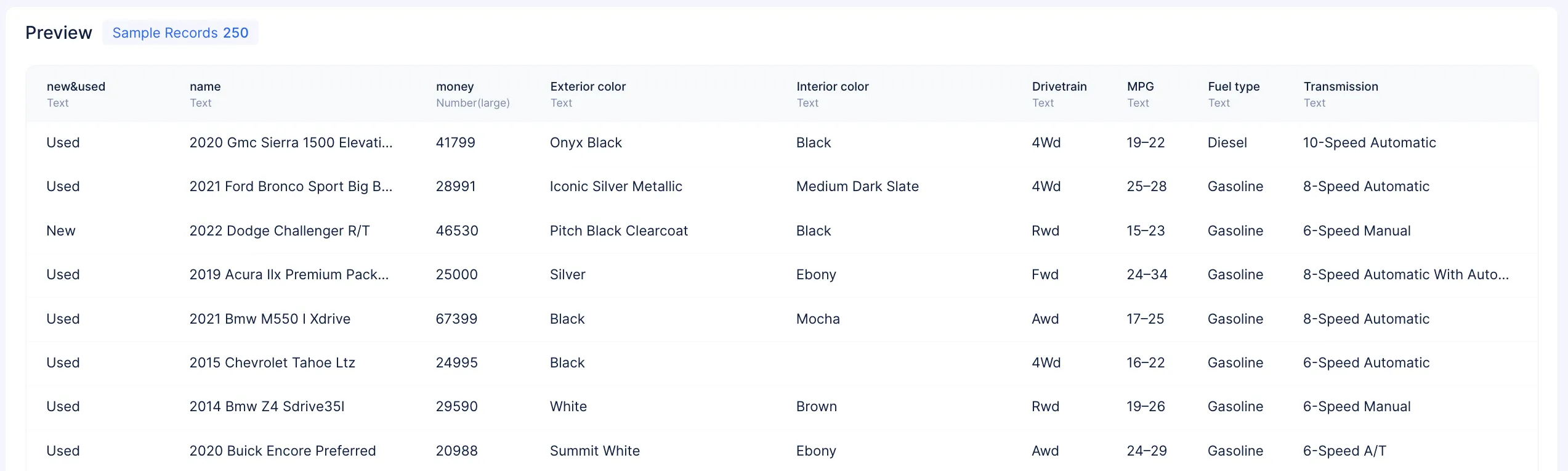
Se genera una vista previa de datos en la página de detalles del dataset muestreando 250 registros del conjunto de datos original, lo que ayuda a identificar los tipos de datos de cada característica.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us