RAG
¿Qué es la Generación Aumentada por Recuperación (RAG)?
Para entender RAG, consideremos una analogía simple: Un usuario contacta al soporte técnico con un código de error—“7C05”—mostrado en su impresora. Aunque tiene experiencia, el agente de soporte no ha encontrado ese código específico antes. En lugar de hacer una suposición informada, el agente consulta el manual oficial de solución de problemas para ese modelo particular de impresora para encontrar una solución precisa. En este escenario, el agente representa el modelo de lenguaje, y el manual representa la fuente de conocimiento externa que RAG recupera, permitiendo al agente responder correctamente sin necesitar exposición previa a ese problema exacto.
En términos técnicos, RAG es una técnica avanzada que mejora la precisión, relevancia y confiabilidad de las salidas de modelos de lenguaje grande (LLM) al incorporar información recuperada de fuentes de conocimiento externas y autorizadas. En lugar de depender únicamente de los datos disponibles durante el entrenamiento, RAG permite que un modelo consulte contenido actualizado y específico del dominio en el momento de la inferencia, fundamentando sus respuestas en información verificable y contextualmente apropiada.
Los LLMs se construyen sobre arquitecturas de redes neuronales y se entrenan con vastos volúmenes de datos textuales. Su rendimiento está impulsado en gran medida por miles de millones de parámetros, que capturan patrones generalizados en el lenguaje humano. Este conocimiento parametrizado equipa a los LLMs para realizar una amplia gama de tareas, como responder preguntas, traducción y completar texto con una fluidez impresionante. Sin embargo, estos modelos pueden ser limitados cuando se les pide generar respuestas que requieren información específica, detallada o sensible al tiempo más allá de su alcance de entrenamiento.
RAG aborda esta limitación optimizando el proceso generativo para recuperar primero contenido relevante de una base de conocimiento curada—como documentos internos de la empresa, bases de datos específicas del dominio o fuentes en línea confiables—y luego generar respuestas que sean tanto informadas como contextualmente fundamentadas. Este enfoque particular no requiere ningún reentrenamiento del modelo base, lo que lo convierte en un método rentable y escalable para adaptar las capacidades de los LLM a necesidades organizacionales específicas o dominios especializados.
Beneficios de RAG
RAG ofrece una serie de ventajas significativas que mejoran la efectividad, flexibilidad y confiabilidad de las soluciones de IA generativa, particularmente para organizaciones que buscan implementar inteligencia específica del dominio sin la sobrecarga de reentrenar modelos grandes.
Implementación rentable
La mayoría del desarrollo de chatbots y aplicaciones de IA comienza con modelos fundacionales como los modelos de lenguaje grande (LLMs) entrenados en conjuntos de datos extensos y generalizados y típicamente accedidos a través de APIs. Adaptar estos modelos mediante reentrenamiento para acomodar contenido organizacional o específico de la industria suele ser prohibitivamente costoso e intensivo en recursos. RAG proporciona una alternativa más escalable y económica. Al permitir que el modelo recupere y haga referencia a datos externos durante la inferencia, RAG permite a las empresas integrar conocimiento específico sin modificar el modelo subyacente, lo que hace que las soluciones de IA generativa sean más alcanzables y rentables.
Acceso a información oportuna y dinámica
Mantener respuestas actualizadas es un gran desafío para los modelos estáticos, ya que sus datos de entrenamiento rápidamente se vuelven obsoletos. RAG aborda este problema al permitir a los usuarios alimentar el modelo con fuentes de información continuamente actualizadas. Ya sea la última investigación científica, noticias de último momento o feeds de redes sociales en tiempo real, RAG equipa a los modelos de IA generativa con acceso a datos actuales. Esto asegura que las respuestas permanezcan relevantes y precisas, incluso en dominios que evolucionan rápidamente.
Mayor transparencia y confianza del usuario
Una de las fortalezas clave de RAG es su capacidad para proporcionar respuestas basadas en fuentes. Al hacer referencia a documentos externos e incluir citas, ofrece transparencia sobre el origen de la información. Los usuarios pueden revisar estas fuentes para verificar el contenido o explorar más, mejorando su confianza en el sistema. Esta trazabilidad hace que las respuestas de IA generativa no solo sean más creíbles sino también más alineadas con los estándares de cumplimiento o aseguramiento de calidad en industrias reguladas.
Aplicaciones de RAG
La Generación Aumentada por Recuperación (RAG) se está adoptando cada vez más en todas las industrias para mejorar las capacidades de los modelos de lenguaje grande (LLMs), especialmente en áreas que requieren conocimiento específico del dominio, información en tiempo real o resultados transparentes. A continuación se presentan varias áreas de aplicación clave donde RAG ofrece un impacto significativo:
Asistentes de conocimiento empresarial
Las empresas recurren cada vez más a asistentes basados en RAG para optimizar el acceso al conocimiento interno de los empleados. Estas herramientas impulsadas por IA están diseñadas para consultar datos estructurados y no estructurados de repositorios específicos de la empresa, como wikis internos, SOPs, directrices de RR.HH., listas de verificación de cumplimiento, documentación de TI y materiales de incorporación. A diferencia de los chatbots estáticos, que dependen de reglas predefinidas o datos de entrenamiento desactualizados, RAG obtiene dinámicamente los documentos más relevantes, asegurando que los empleados reciban respuestas precisas, actualizadas y alineadas con las políticas. Esto lleva a una mayor productividad, menor dependencia de equipos de soporte y una fuente unificada de verdad entre departamentos.
Automatización del servicio al cliente
Las plataformas de servicio al cliente pueden elevar significativamente la experiencia del usuario al integrar RAG para ofrecer interacciones más inteligentes y conscientes del contexto. Al recuperar contenido directamente de manuales de productos, guías de solución de problemas, documentos de garantía y bases de conocimiento de mesa de ayuda, los chatbots impulsados por RAG pueden resolver consultas de clientes de manera más efectiva—incluso aquellas relacionadas con productos lanzados recientemente o raramente encontrados. Esto elimina la necesidad constante de reentrenar modelos con nuevo contenido y permite operaciones de soporte escalables con mínima intervención humana. La inclusión de fuentes rastreables también genera confianza en el cliente y aumenta la satisfacción del cliente.
Investigación legal y regulatoria
Los profesionales legales operan en un dominio donde la precisión, las citas y la trazabilidad son primordiales. Las herramientas basadas en RAG empoderan a los equipos legales al permitir la recuperación directa de cláusulas de estatutos, jurisprudencia anterior, políticas gubernamentales o documentos internos de cumplimiento. En lugar de revisar manualmente textos voluminosos, los usuarios pueden obtener resúmenes concisos, con referencias cruzadas a los documentos originales para solidez legal. Estas aplicaciones son especialmente útiles para redactar opiniones legales, realizar auditorías regulatorias o preparar respuestas para revisiones de cumplimiento, asegurando que cada resultado esté fundamentado en un contexto legal verificable.
Soporte de decisiones médicas y de salud
En el sector de la salud, la toma de decisiones oportuna y basada en evidencia puede impactar directamente los resultados de los pacientes. Los sistemas RAG apoyan a los clínicos, investigadores y administradores al hacer referencia a datos de fuentes médicas como guías de tratamiento y registros clínicos institucionales. Al incorporar información relevante en sus respuestas, un modelo RAG puede asistir con el soporte de decisiones clínicas, recomendaciones de atención específicas del paciente, diagnósticos diferenciales o interacciones medicamentosas, todo mientras cita el material fuente. Este enfoque mejora la confianza en las recomendaciones impulsadas por IA.
Investigación científica y redacción técnica
RAG desempeña un papel vital en la aceleración de los flujos de trabajo de investigación y en asegurar la precisión del contenido en la redacción técnica. Los investigadores pueden consultar bases de datos académicas extensas para resumir el estado del arte, generar revisiones de literatura o validar hipótesis con hallazgos actuales. De manera similar, los redactores técnicos pueden usar RAG para redactar documentación de productos basada en los datos más recientes y manuales de usuario. Ya sea resumiendo desarrollos científicos o redactando informes, RAG asegura que el contenido generado esté respaldado por fuentes confiables y específicas del dominio, manteniendo así tanto la precisión como la credibilidad.
¿Cómo funciona RAG?
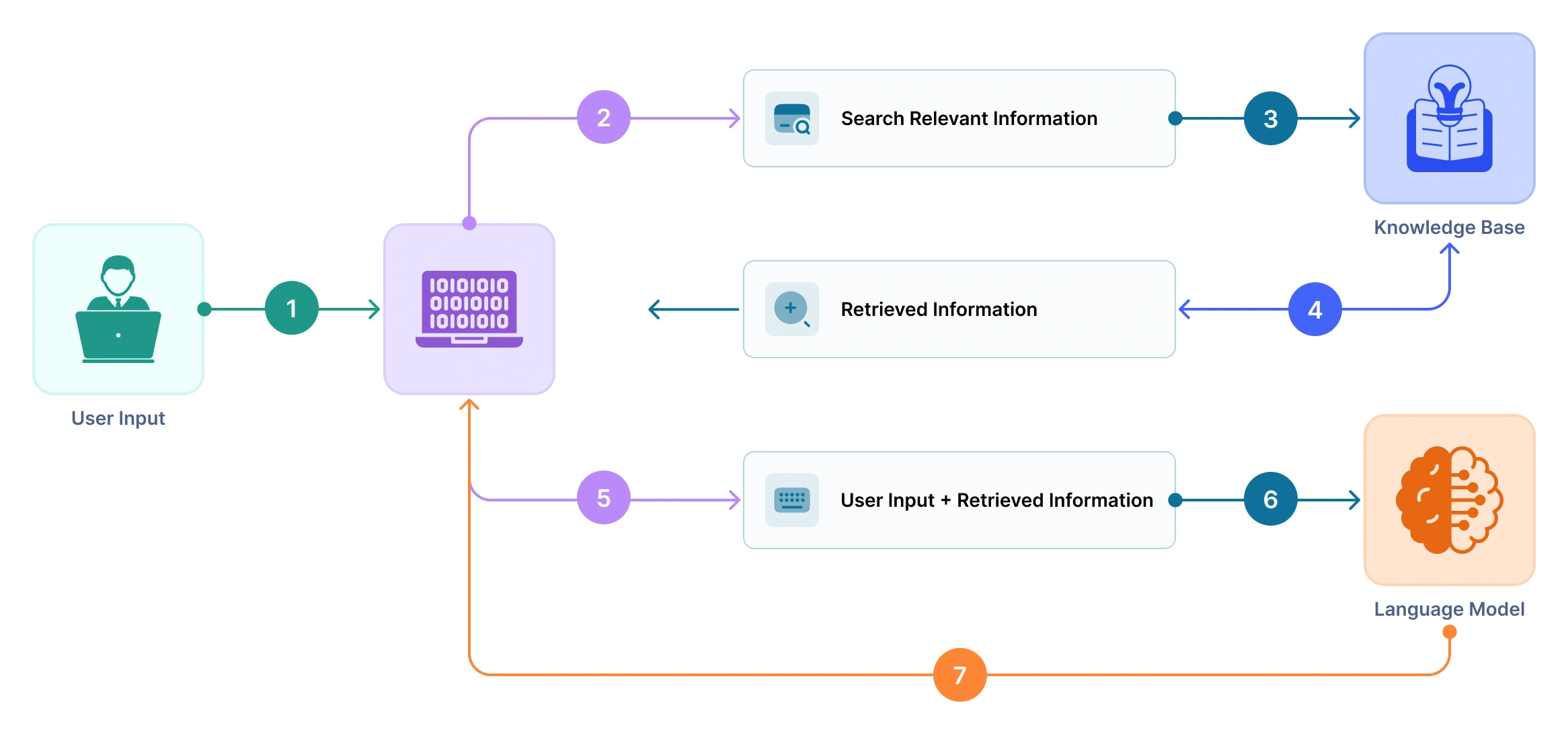
RAG integra dos procesos clave: recuperación y generación. En lugar de depender únicamente del conocimiento codificado durante el entrenamiento de un modelo de lenguaje, RAG lo complementa extrayendo dinámicamente información relevante de fuentes externas (como bases de datos, documentos o bases de conocimiento) en el momento de la inferencia. Este enfoque permite al modelo entregar respuestas que son más precisas, actuales y contextualmente apropiadas.
Aquí hay un flujo simplificado de cómo funciona RAG:
-
Entrada/consulta del usuario: El proceso comienza cuando un usuario introduce una pregunta o prompt.
-
Recuperación: El sistema usa la consulta para buscar en una fuente de conocimiento externa grande (por ejemplo, base de datos vectorial, almacén de documentos o índice de búsqueda) para recuperar las top-k piezas de información más relevantes (a menudo llamadas “pasajes” o “contextos”). Esto se realiza típicamente usando búsqueda semántica impulsada por embeddings.
-
Fusión/contextualización: Los pasajes recuperados se pasan junto con la consulta original a un modelo de lenguaje. Estos pasajes proporcionan contexto que fundamenta la generación en conocimiento factual o específico del dominio.
-
Paso de generación: El modelo de lenguaje (por ejemplo, un LLM basado en transformer) toma tanto la consulta como los documentos recuperados como entrada y genera una respuesta coherente e informada.
-
Citación/trazabilidad: Dado que los modelos RAG dependen de documentos reales para las respuestas, pueden proporcionar referencias rastreables o enlaces al material fuente, aumentando la transparencia y la confianza.
¿Qué hace único a RAG en QuickML?
El RAG de QuickML está diseñado para ofrecer una experiencia fluida, segura y transparente al generar respuestas impulsadas por una base de conocimiento. Esto es lo que distingue a RAG en QuickML:
-
Una vez que se genera una respuesta, un desglose detallado de la respuesta está disponible. Este desglose indica qué partes de los documentos recuperados fueron referenciadas durante el proceso de generación y muestra claramente el origen de la información de apoyo. Mejora la transparencia al permitirle ver exactamente qué documentos contribuyeron a la salida final.
-
La implementación de RAG de QuickML aprovecha el ecosistema de Zoho—como WorkDrive y Zoho Learn—para importar documentos relevantes a la base de conocimiento de manera fluida. Esta integración asegura que la información más precisa y específica del contexto esté siempre disponible para respaldar sus consultas.
Modelos disponibles en el RAG de QuickML
RAG en QuickML aprovecha el modelo Qwen 2.5 14B Instruct para entregar respuestas contextuales y relevantes. Qwen 2.5 14B Instruct es un modelo de IA altamente capaz diseñado para realizar una gama diversa de tareas de lenguaje con consistencia y precisión. Entrenado en conjuntos de datos de alta calidad a gran escala, entrega resultados confiables y demuestra un rendimiento sólido en múltiples benchmarks. Lo que distingue a Qwen 2.5-14B-Instruct es su capacidad para adaptarse rápidamente y responder a escenarios dinámicos del mundo real, haciéndolo excepcionalmente adecuado para aplicaciones empresariales y de grado de producción.
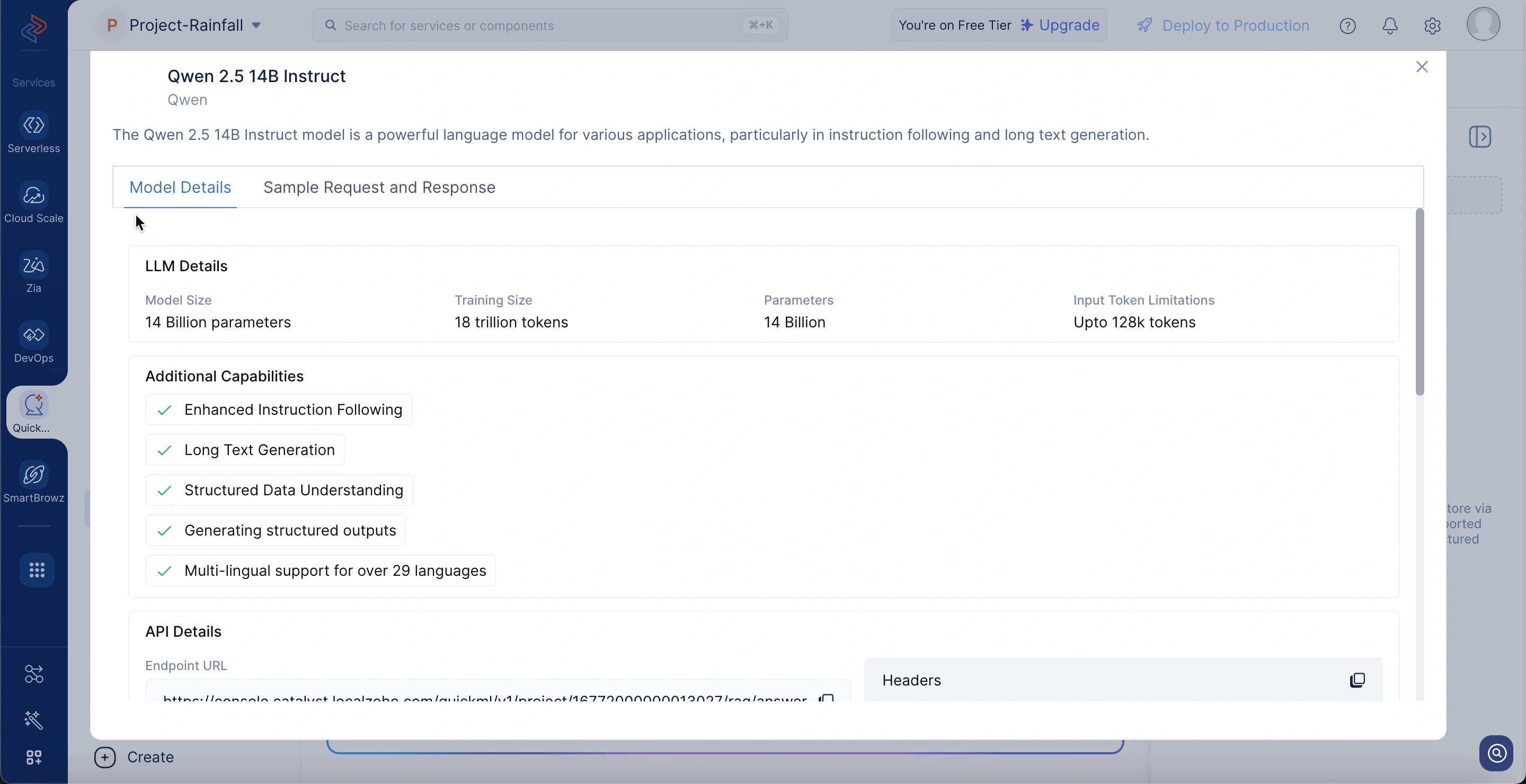
Detalles del modelo Qwen 2.5 14B Instruct
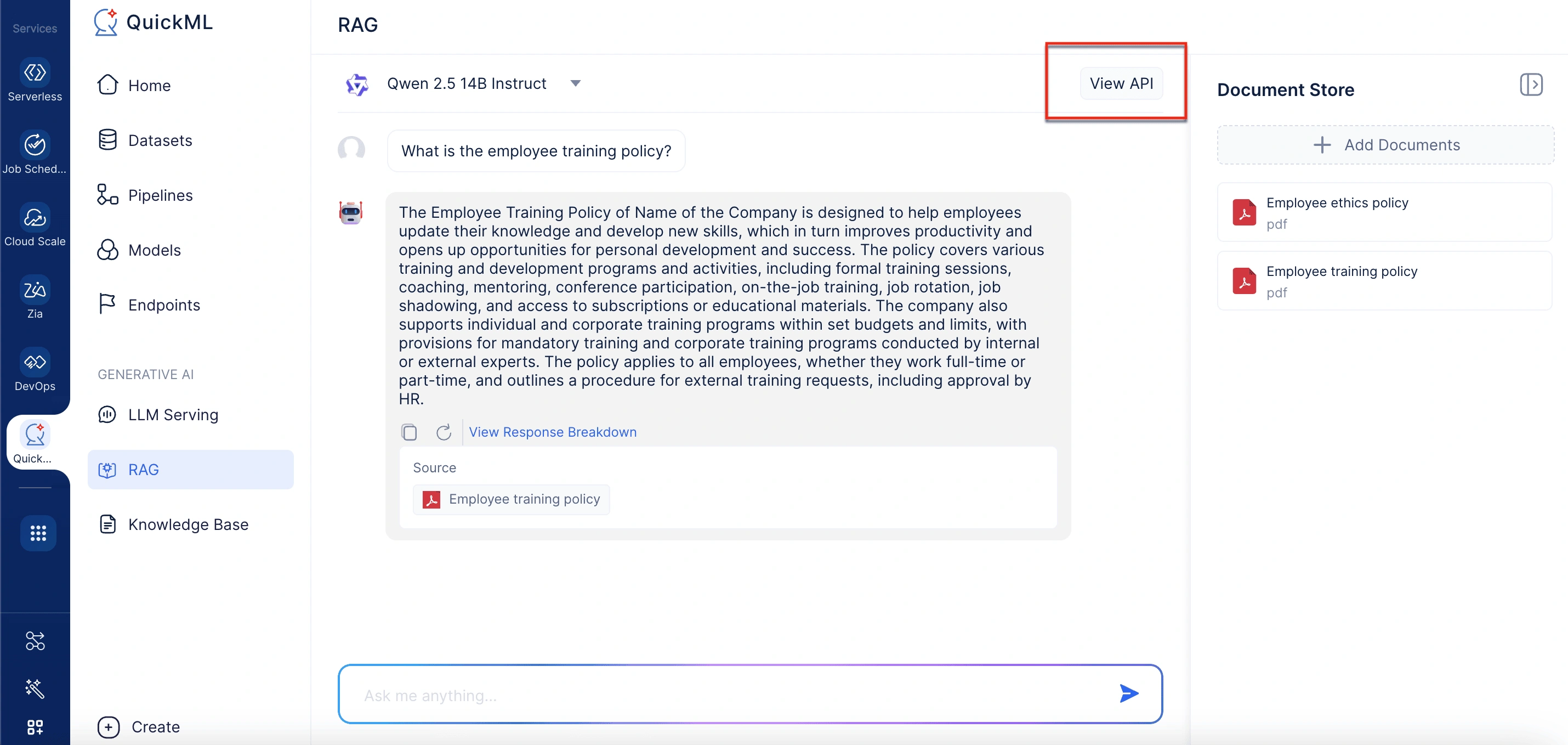
Para ver los detalles del modelo, vaya a la pestaña RAG y haga clic en la opción View API en la esquina superior derecha de la interfaz de chat. Los detalles del modelo incluyen:
-
Model size: Comprende 14 mil millones de parámetros, habilitando capacidades sofisticadas de comprensión y generación de lenguaje.
-
Training size: Entrenado en 18 billones de tokens para asegurar una cobertura extensa en una amplia gama de dominios.
-
Parameters: Utiliza 14 mil millones de pesos entrenables para generar respuestas matizadas y altamente relevantes.
-
Input token limitations: Admite 128K tokens con longitud de contexto de entrada, permitiendo contexto profundo y referencias de documentos largos durante la ejecución de RAG.
-
Endpoint URL: Esta es la URL utilizada para enviar solicitudes de API.
-
OAuth Scope: QuickML.deployment.READ; define el nivel de acceso requerido para usar el deployment.
-
Authentication: Se utiliza OAuth para verificar la identidad del cliente de forma segura.
-
HTTP method: POST; todas las llamadas a la API deben realizarse a través del método POST.
-
Headers: Incluyen metadatos requeridos y el token de autorización para autenticar las solicitudes.
-
Sample request: Un formato JSON predefinido muestra cómo estructurar su prompt de entrada.
-
Sample response: Muestra la salida del modelo, incluyendo texto contextualmente fundamentado generado basándose tanto en el prompt como en la información recuperada de los documentos de KB.
Puede consultar la sección Integración de RAG en sus aplicaciones para los pasos para integrar el modelo en su aplicación.
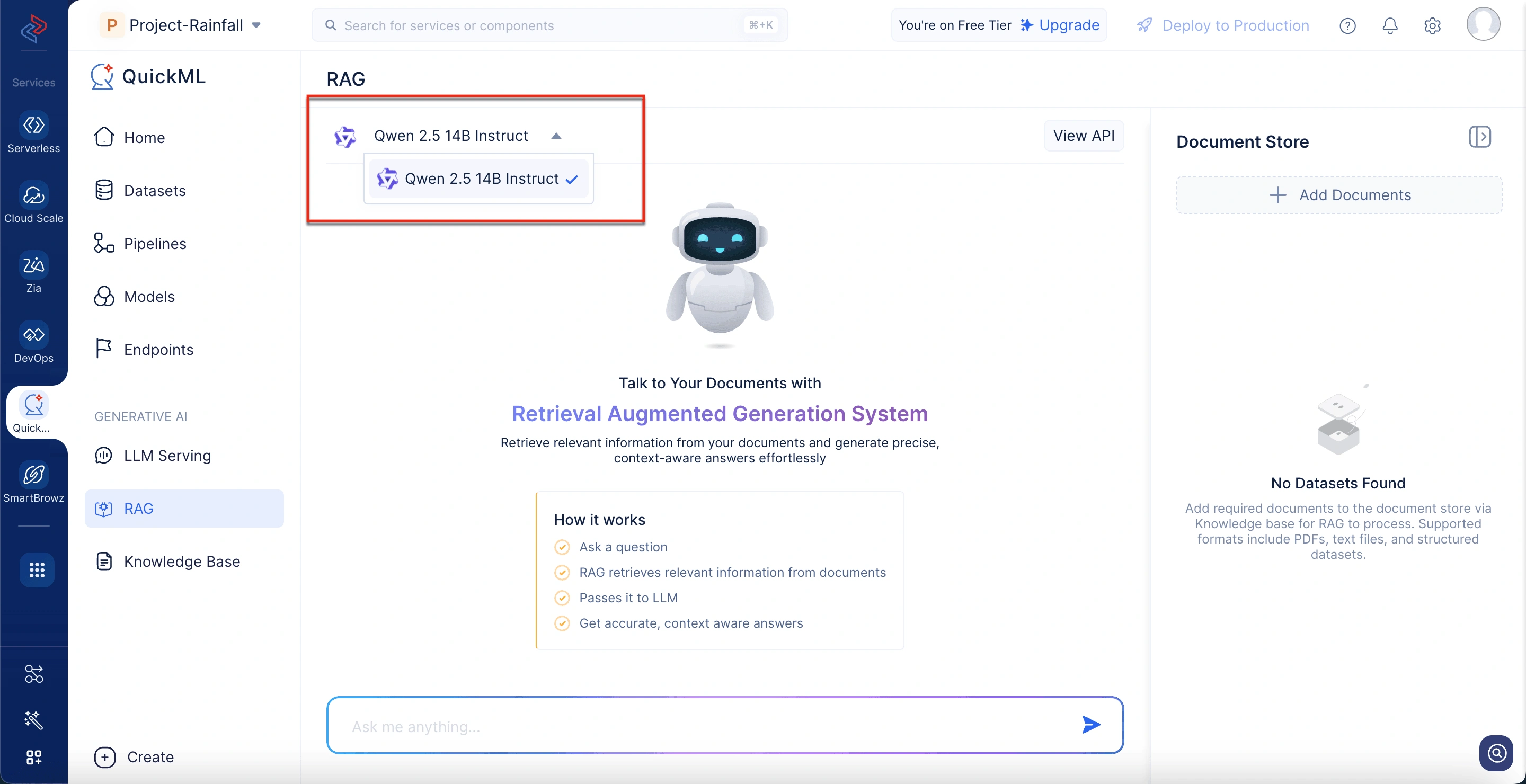
Comprendiendo la interfaz de RAG en QuickML
La función RAG en QuickML le permite obtener respuestas basadas en documentos usando Qwen 2.5 14B Instruct. La interfaz está diseñada para facilitar la carga de documentos, hacer preguntas y rastrear la fuente de cada respuesta. Aquí hay un desglose de cómo se ve.
Selección de modelo
En la parte superior del panel de chat, los usuarios pueden seleccionar el modelo disponible. Actualmente, Qwen 2.5 14B Instruct es compatible para conversaciones basadas en RAG. Este modelo está optimizado para generar respuestas fundamentadas y conscientes del contexto a partir de documentos cargados.
Interfaz de chat (panel de conversación)
En el centro está el espacio de interacción principal donde usted ingresa sus consultas y ve las respuestas. Cada respuesta generada por IA se muestra debajo de la entrada del usuario y puede incluir:
- Iconos de acción para copiar o regenerar la respuesta
- Una opción “View Response Breakdown”, que brinda información sobre cómo se generó la respuesta y de qué documentos
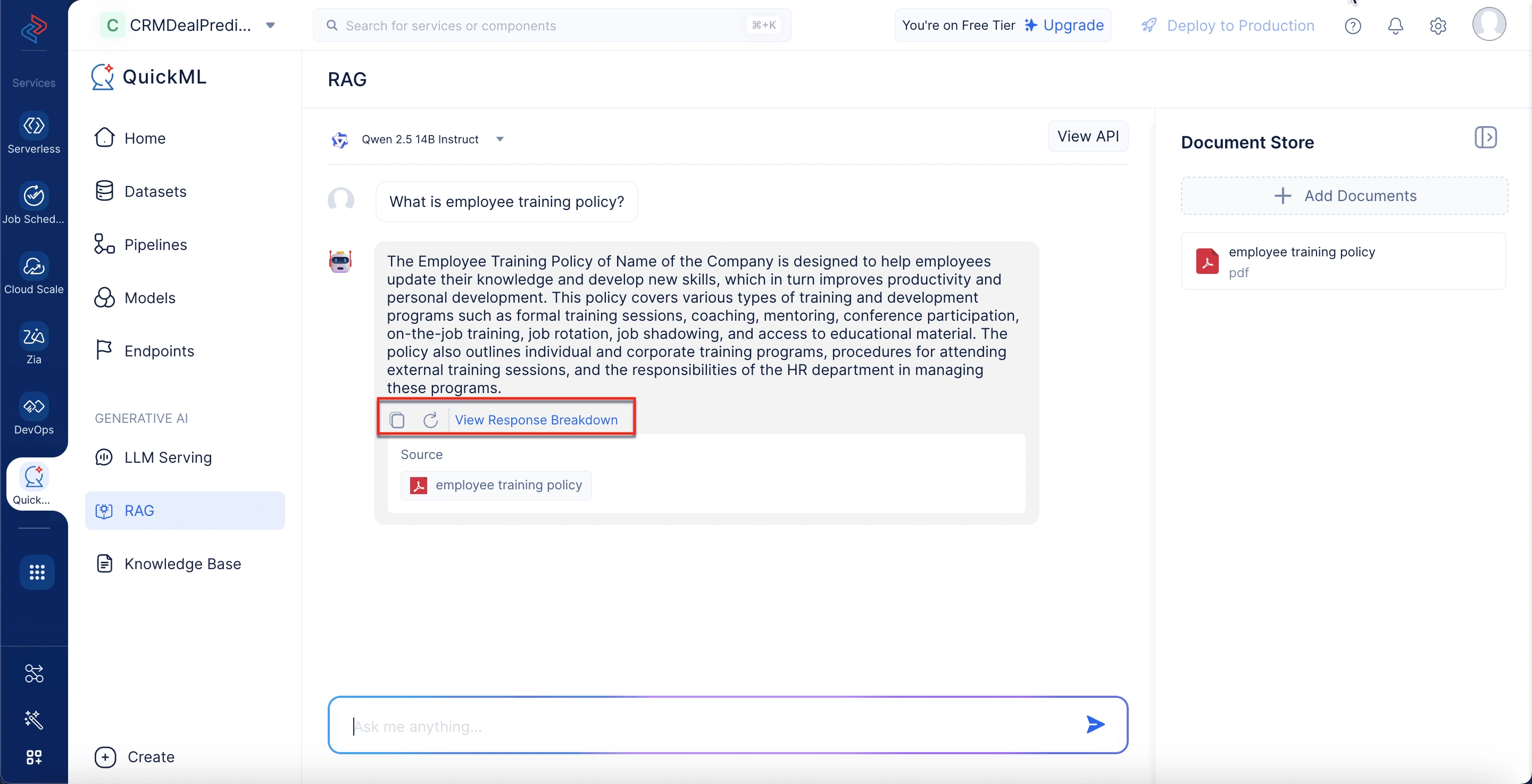
Panel de desglose de respuesta
Cuando hace clic en “View Response Breakdown”, aparece una ventana emergente que ofrece información detallada:
-
Thought process: Muestra los fragmentos de contenido específicos referenciados durante la generación de la respuesta, junto con sus fuentes correspondientes e IDs de documento.
-
Citations: Lista los documentos utilizados y resalta las secciones exactas que se usaron para generar la respuesta.
Almacén de documentos
En el lado derecho de la interfaz, el almacén de documentos lista todos los documentos actualmente activos para recuperación. Cada documento muestra su nombre, formato y tamaño. Los usuarios pueden incluir documentos relevantes para la generación de respuestas desde la base de conocimiento seleccionando la opción Add Documents.
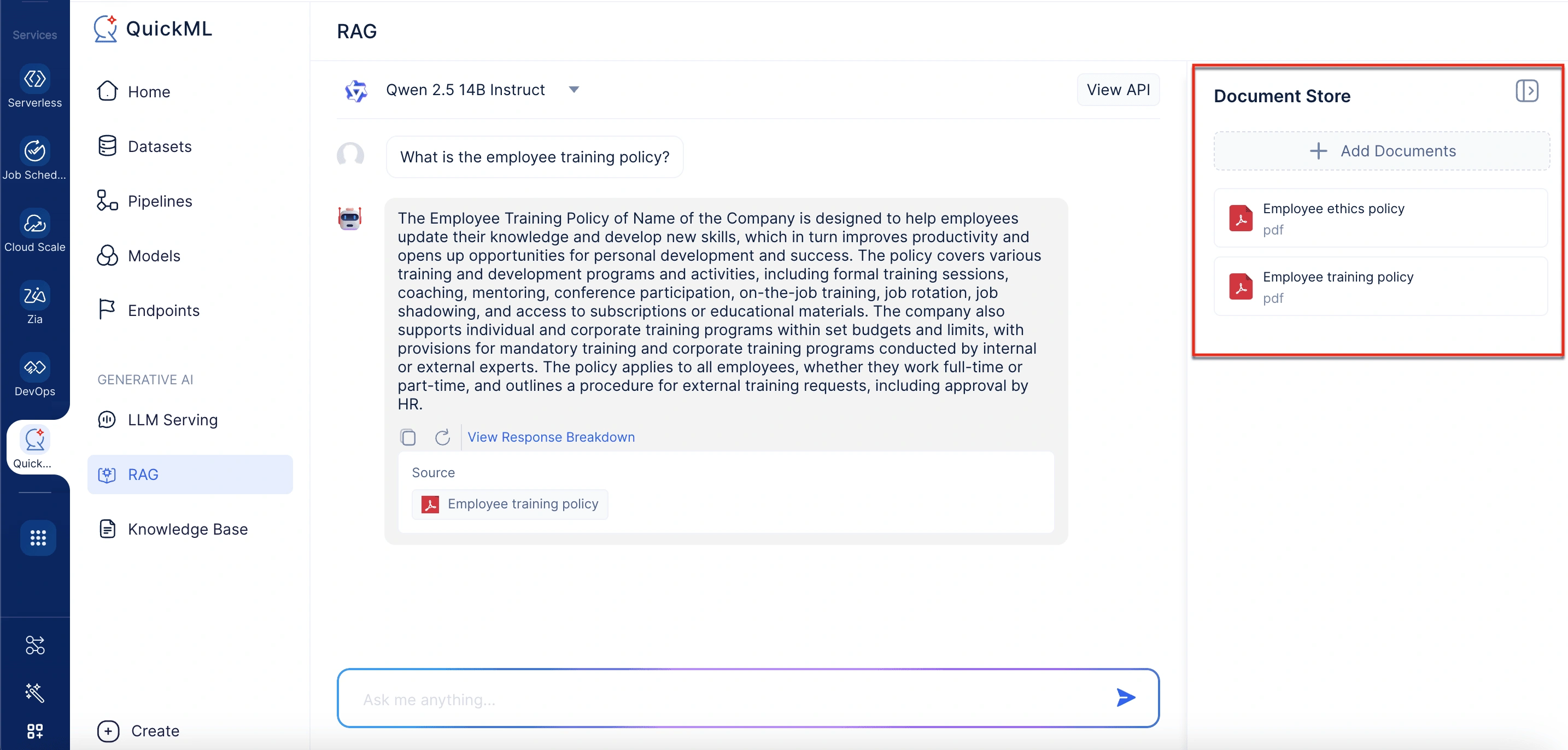
Agregar documentos
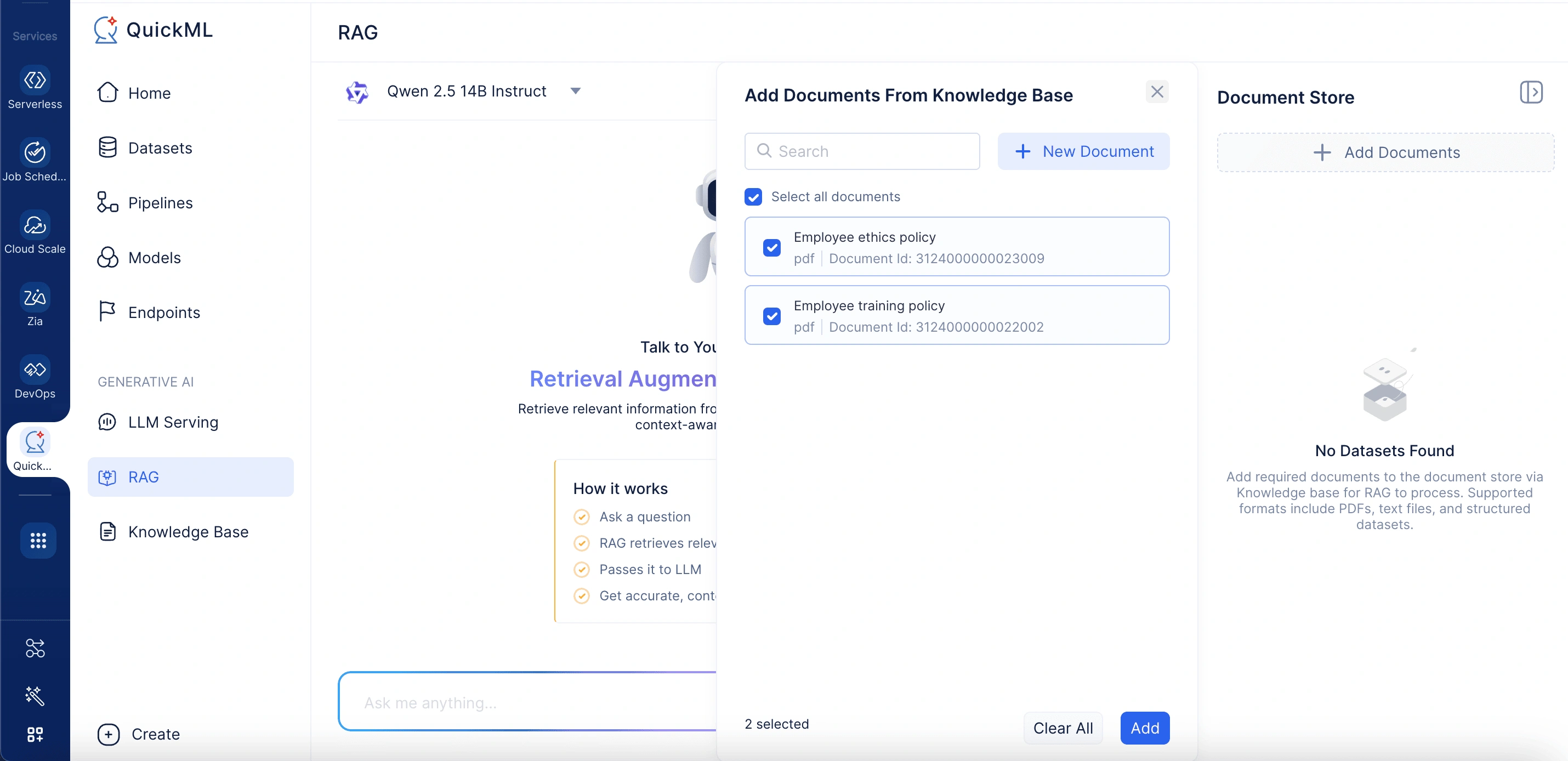
Al hacer clic en Add Documents se abre un panel etiquetado Add Documents From Knowledge Base. Aquí, los usuarios pueden seleccionar documentos existentes o cargar nuevos. El panel incluye una barra de búsqueda para localizar documentos en la base de conocimiento rápidamente.
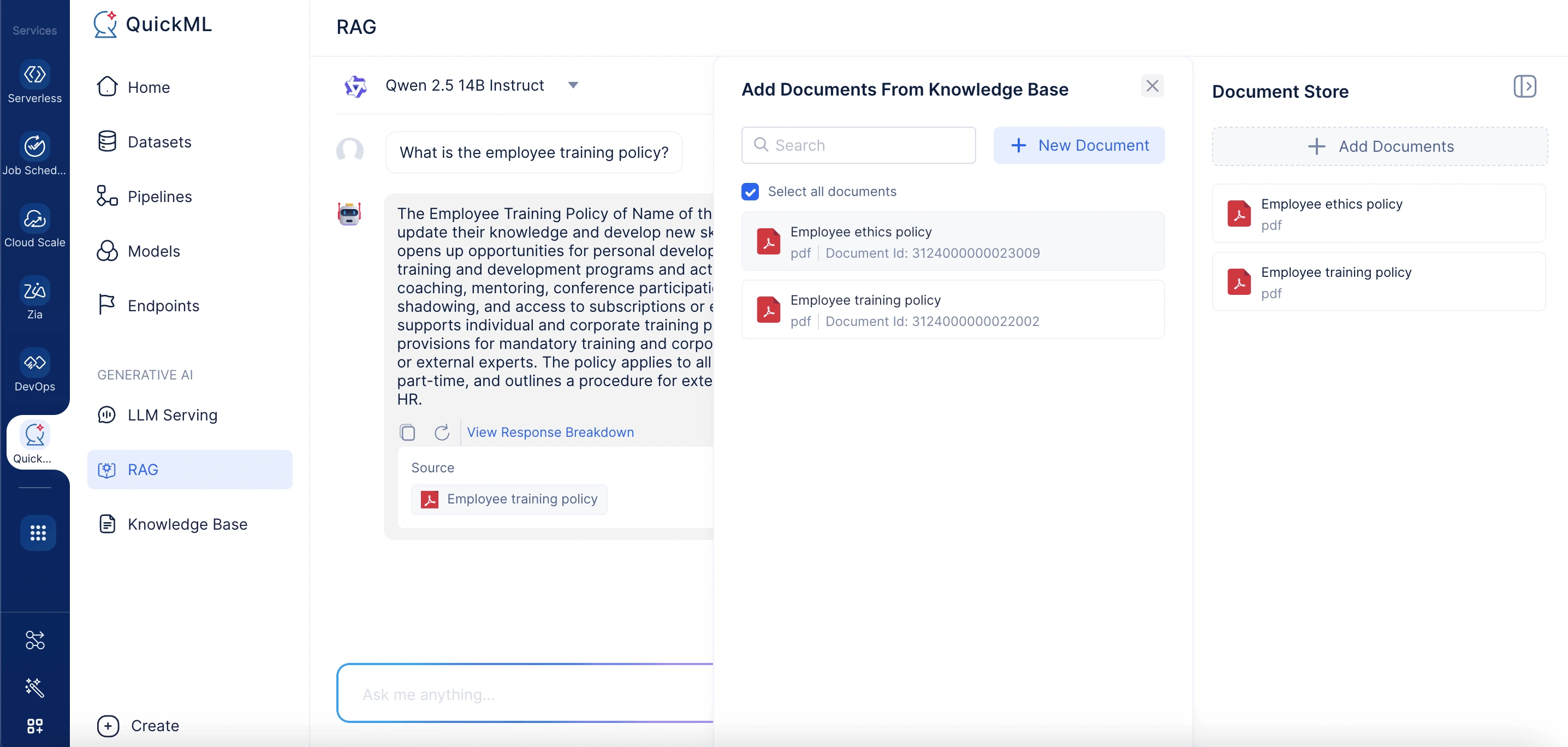
-
Opciones de carga
Al cargar un nuevo documento, se admiten tres métodos convenientes:
- From desktop: Admite archivos .pdf, .docx y .txt, con un límite de tamaño de 500KB por archivo.
- From WorkDrive: Permite a los usuarios importar archivos directamente desde el almacenamiento en la nube.
- Via Zoho Learn link: Permite la importación de documentos pegando la URL del artículo deseado de Zoho Learn.
Cada archivo cargado recibe un ID único y queda disponible para recuperación durante las conversaciones.
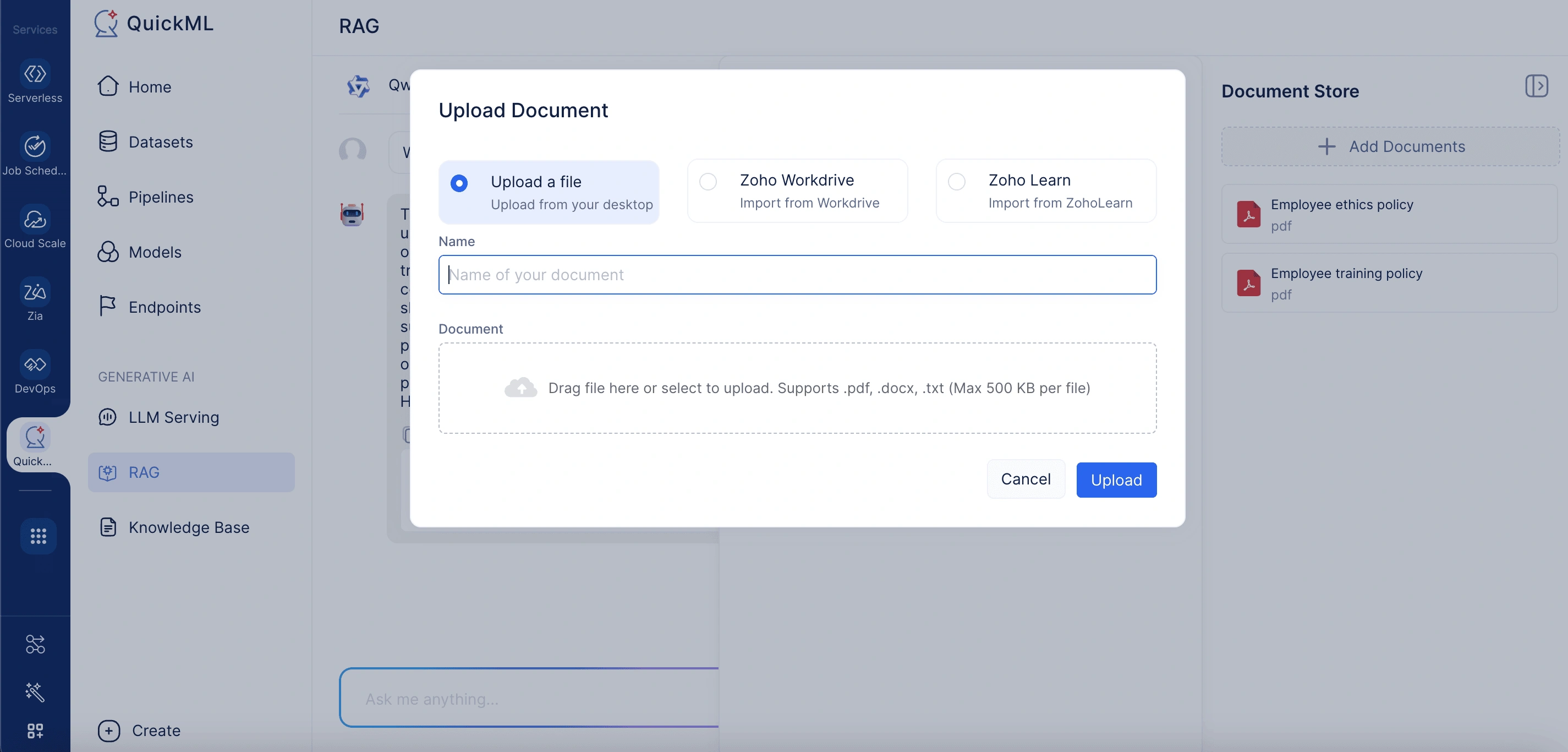
Carga de documentos a la base de conocimiento
Para asegurar que los documentos aparezcan en el panel Add Documents From Knowledge Base, los archivos relevantes primero deben cargarse en el repositorio de Knowledge Base.
Tenga en cuenta que, al hacer clic en New Document en el panel Add Documents From Knowledge Base, los documentos se agregarán automáticamente a la base de conocimiento.
La Knowledge Base funciona como un repositorio centralizado de documentos donde los usuarios pueden cargar y gestionar contenido crítico para la generación consciente del contexto. La integración con los ecosistemas de Zoho como WorkDrive y Zoho Learn permite la importación fluida de archivos internos, manuales, preguntas frecuentes y otros recursos. Esta configuración asegura que la Knowledge Base permanezca actualizada y completa, respaldando la capacidad del modelo para proporcionar respuestas respaldadas por fuentes y adaptadas a las consultas de los usuarios.
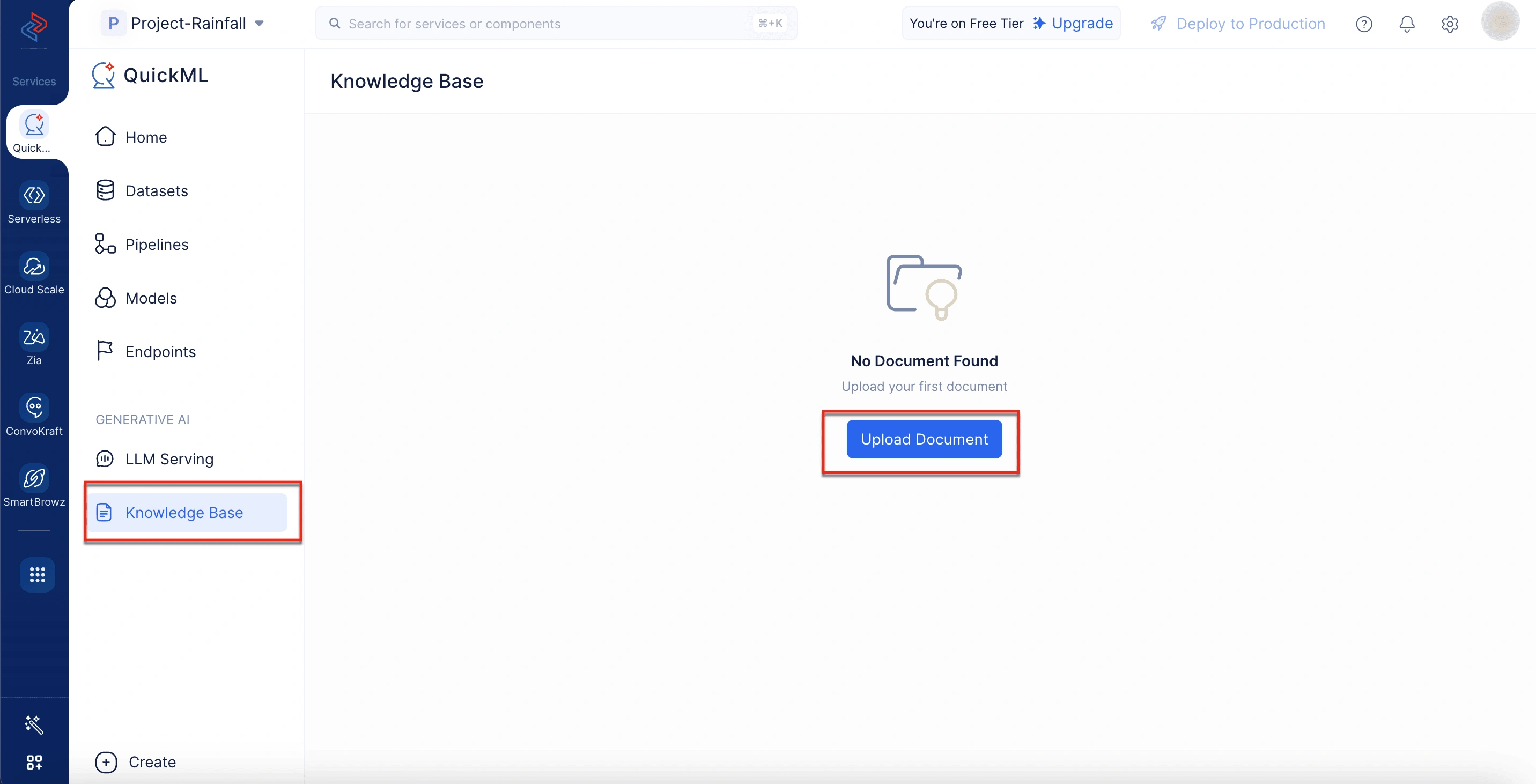
Para cargar documentos desde la base de conocimiento
- Navegue a la pestaña Knowledge Base en la plataforma QuickML.
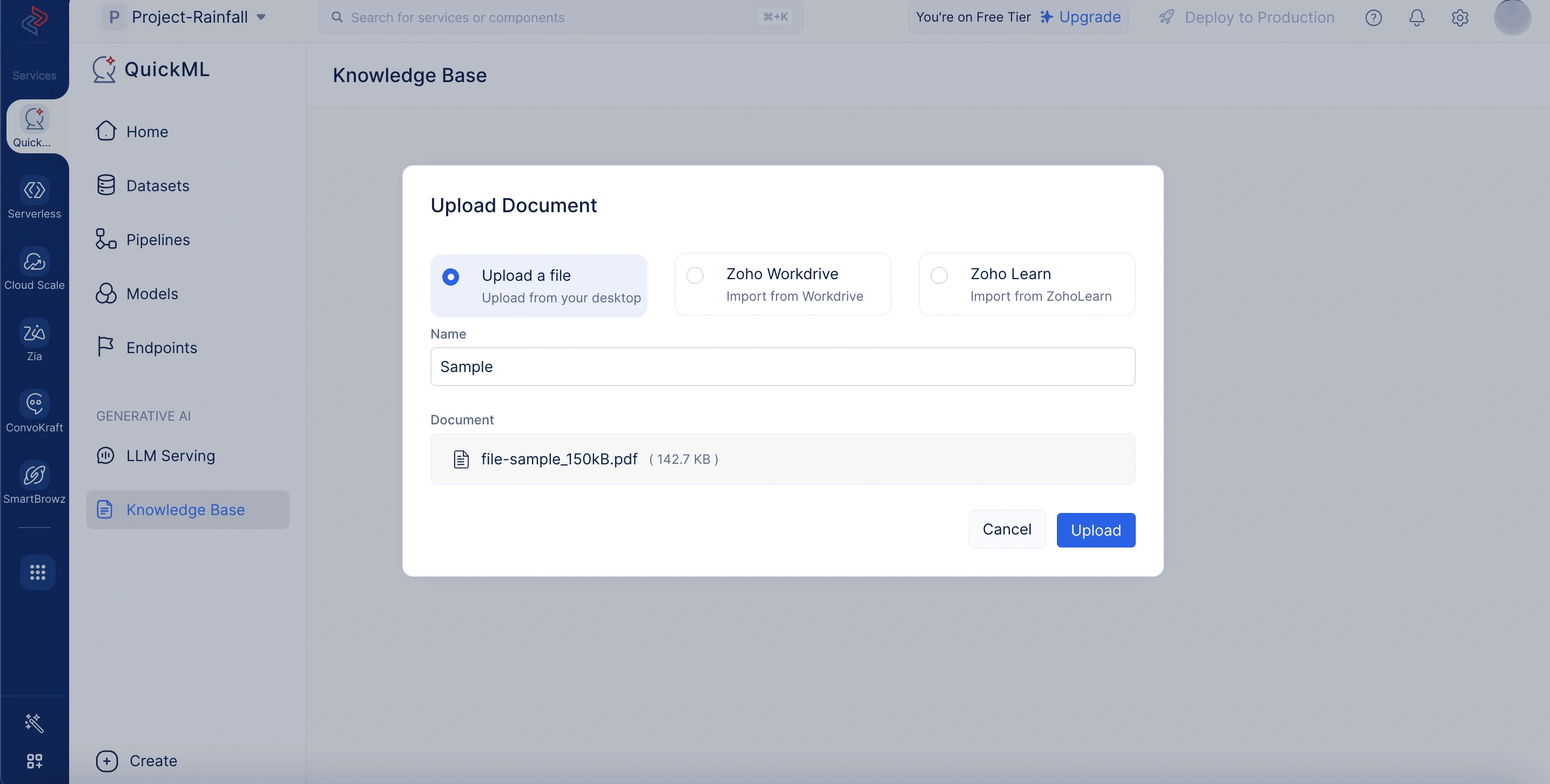
- Haga clic en Upload Document.
- Elija cualquiera de las siguientes formas para cargar el documento:
- Seleccione Upload a file para cargar el documento desde su escritorio. Aquí, debe ingresar el nombre y seleccionar el archivo a cargar desde su sistema local.
- Seleccione Zoho Workdrive para importar el documento desde workdrive. Aquí, debe proporcionar el nombre del documento y el enlace de workdrive de su documento.
- Seleccione Zoho Learn para importar un artículo de Zoho Learn. Aquí, debe ingresar el nombre del documento, seleccionar si está importando un artículo o un manual, y proporcionar el enlace del artículo.
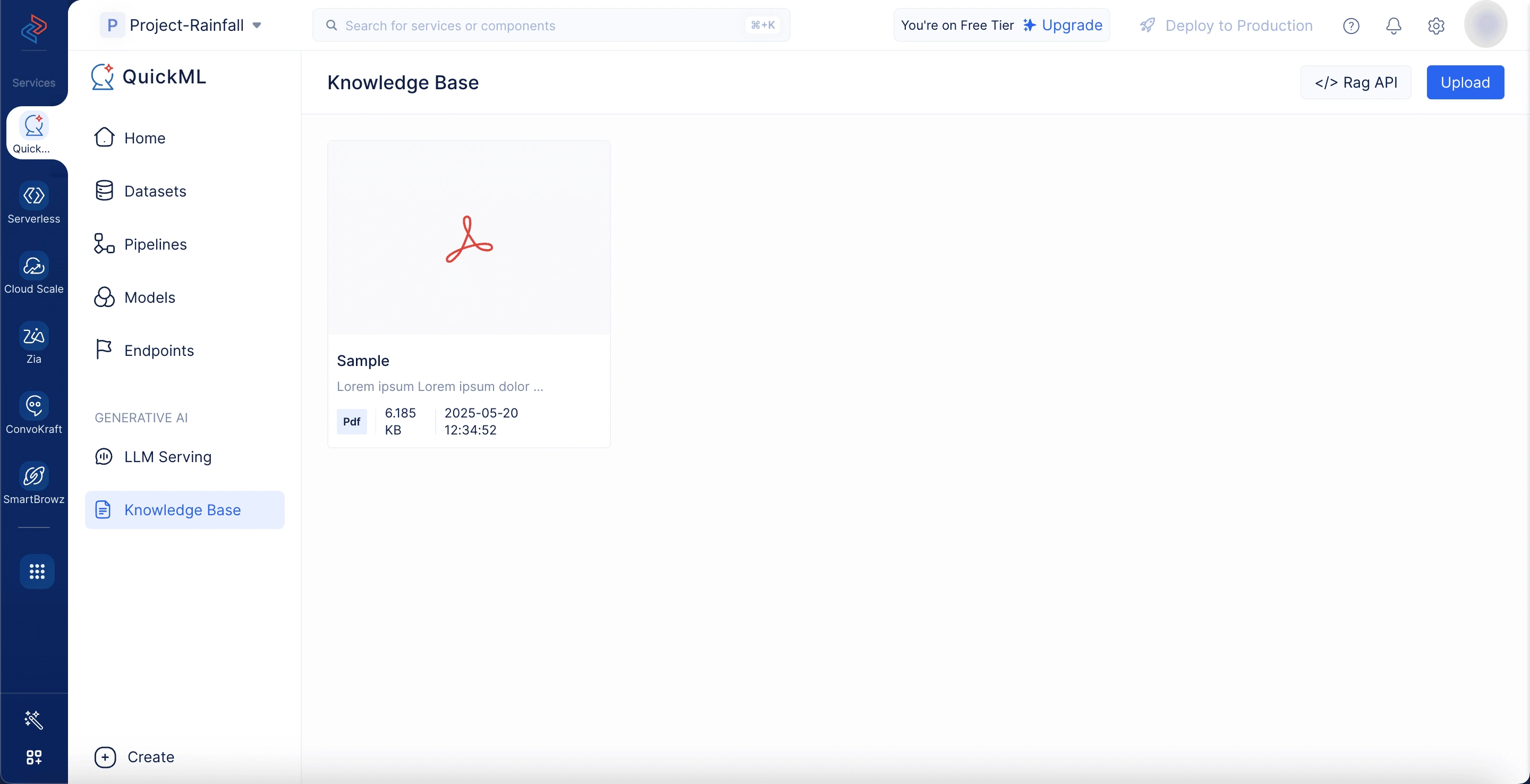
- Una vez cargado, el documento aparecerá en el repositorio de la base de conocimiento. Desde allí, puede eliminarlo o copiar el ID del documento según sea necesario.
Notas:
-
Los documentos cargados en el almacén de documentos se pueden eliminar pasando el cursor sobre el documento deseado y haciendo clic en el icono Eliminar.
-
Cuando se envía una consulta con documentos específicos de la base de conocimiento agregados al almacén de documentos, RAG limita su búsqueda solo a esos documentos agregados. Si no se agregan documentos al almacén de documentos, RAG busca automáticamente en todos los documentos activos de la base de conocimiento. Esto asegura que la consulta se responda usando el contenido disponible más relevante sin requerir selección manual de documentos.
View API
La interfaz de chat también incluye una opción View API en la esquina superior derecha. Al seleccionarla se abre un panel que muestra información detallada sobre el modelo actual, como su tamaño, límites de tokens, URL del endpoint y requisitos de autenticación.
Cómo funciona RAG en QuickML
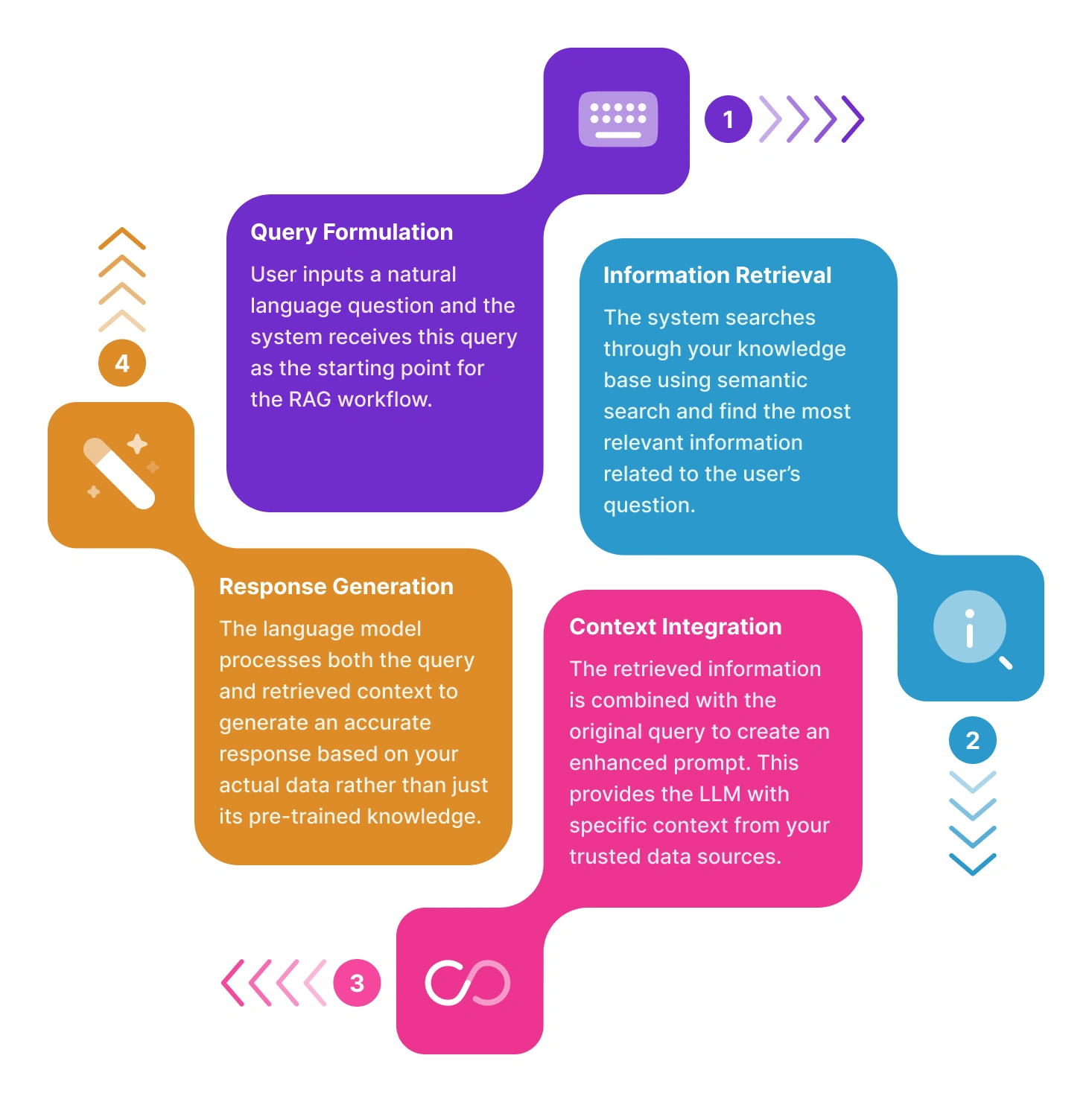
Sin RAG, un modelo de lenguaje grande (LLM) genera respuestas basándose únicamente en sus datos de entrenamiento. Con RAG, el proceso se mejora al introducir un paso de recuperación de información externa, permitiendo al modelo acceder a datos frescos y relevantes en el momento de la consulta. Así es como funciona brevemente:
Hacer una pregunta
El usuario comienza ingresando una consulta en lenguaje natural, por ejemplo, “¿Cuál es la política de devolución de nuestra empresa?” o “Resume las últimas actualizaciones en nuestra documentación de producto.” Esta consulta actúa como una entrada inicial que activa el pipeline de RAG.
Recuperar información relevante de sus documentos
En lugar de depender únicamente del conocimiento preentrenado del modelo de lenguaje, RAG se conecta a su base de conocimiento (como archivos internos, PDFs, etc.). Usando técnicas avanzadas de embedding y búsqueda semántica, el sistema identifica y obtiene las piezas de información más relevantes basándose en la pregunta del usuario.
Refinar resultados con re-ranking
Una vez que se recuperan los documentos relevantes, se aplica un proceso de re-ranking para alinear mejor el contenido seleccionado con la intención del usuario. Este paso evalúa múltiples señales—como similitud semántica y presencia de palabras clave—para reordenar los resultados y destacar el contenido más contextualmente apropiado para la consulta.
Pasarlo al LLM
El contenido recuperado se combina entonces con la consulta original y se envía como un prompt aumentado al LLM (Qwen 2.5-14B-Instruct). Este paso permite al LLM leer la información específica del contexto y usarla para generar una respuesta informada.
Generar respuestas conscientes del contexto
Con tanto la consulta del usuario como los datos de apoyo en mano, el LLM elabora una respuesta que no solo es relevante sino que está basada en el material fuente real. Este enfoque ayuda a asegurar que las respuestas se basen en información verificable y estén alineadas con el material fuente. También permite a los usuarios rastrear las respuestas hasta los documentos originales, lo que promueve la transparencia y genera confianza en el sistema.
Notas importantes
-
La función RAG está disponible para usuarios que tienen acceso a la plataforma QuickML.
-
Los chats son específicos del usuario, asegurando que un usuario no pueda acceder a la conversación de otro usuario. Actualmente, el historial de chat no es compatible. Las conversaciones permanecen visibles hasta que se actualiza la página; una vez actualizada, todos los chats se borran.
Acceso a RAG en QuickML
Se puede acceder a RAG dentro de QuickML mediante estos pasos:
- Inicie sesión en su cuenta de QuickML.
- En la sección Generative AI, seleccione RAG.
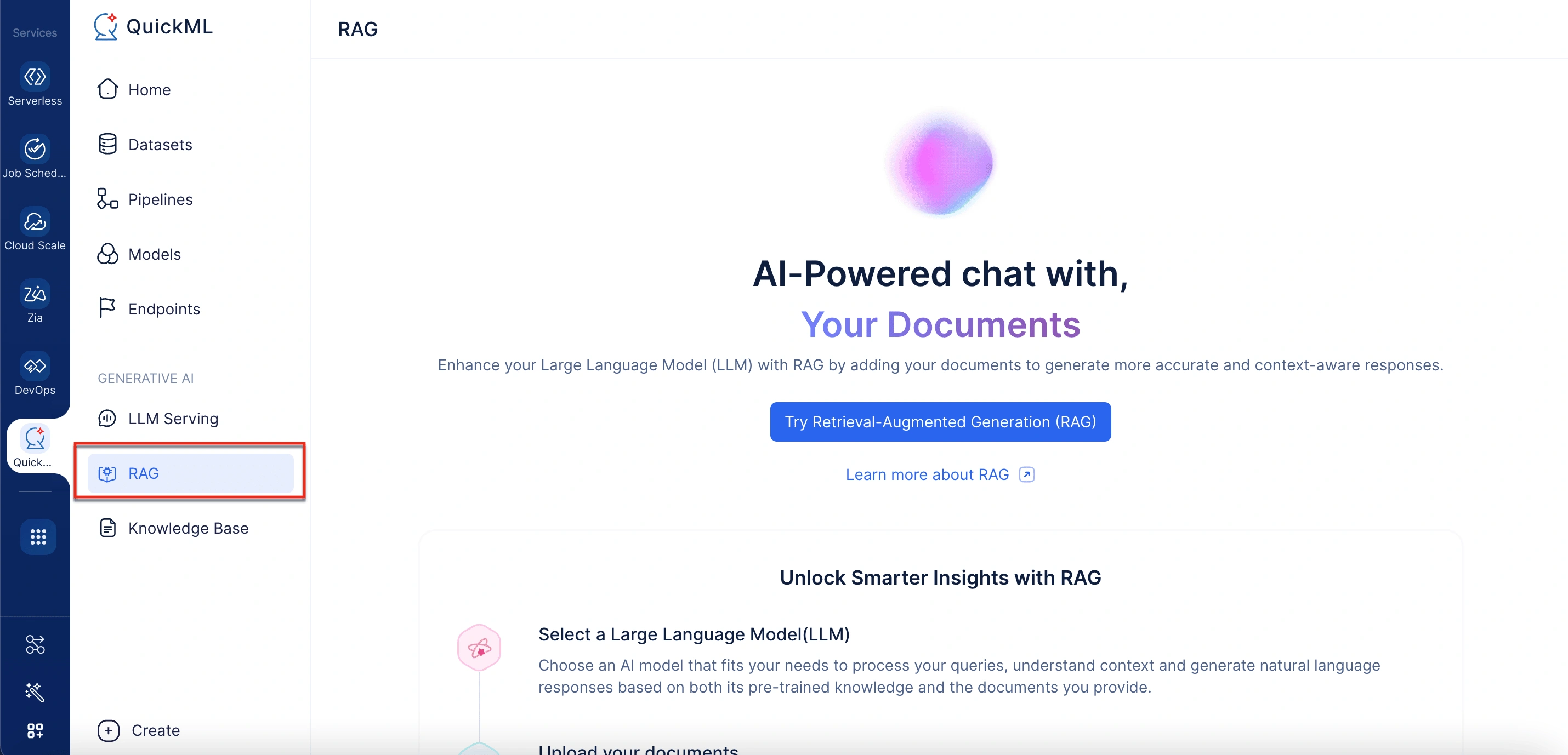
- En Document Store en el panel derecho, haga clic en Add Documents. Esto abrirá un panel etiquetado Add Documents From Knowledge Base.
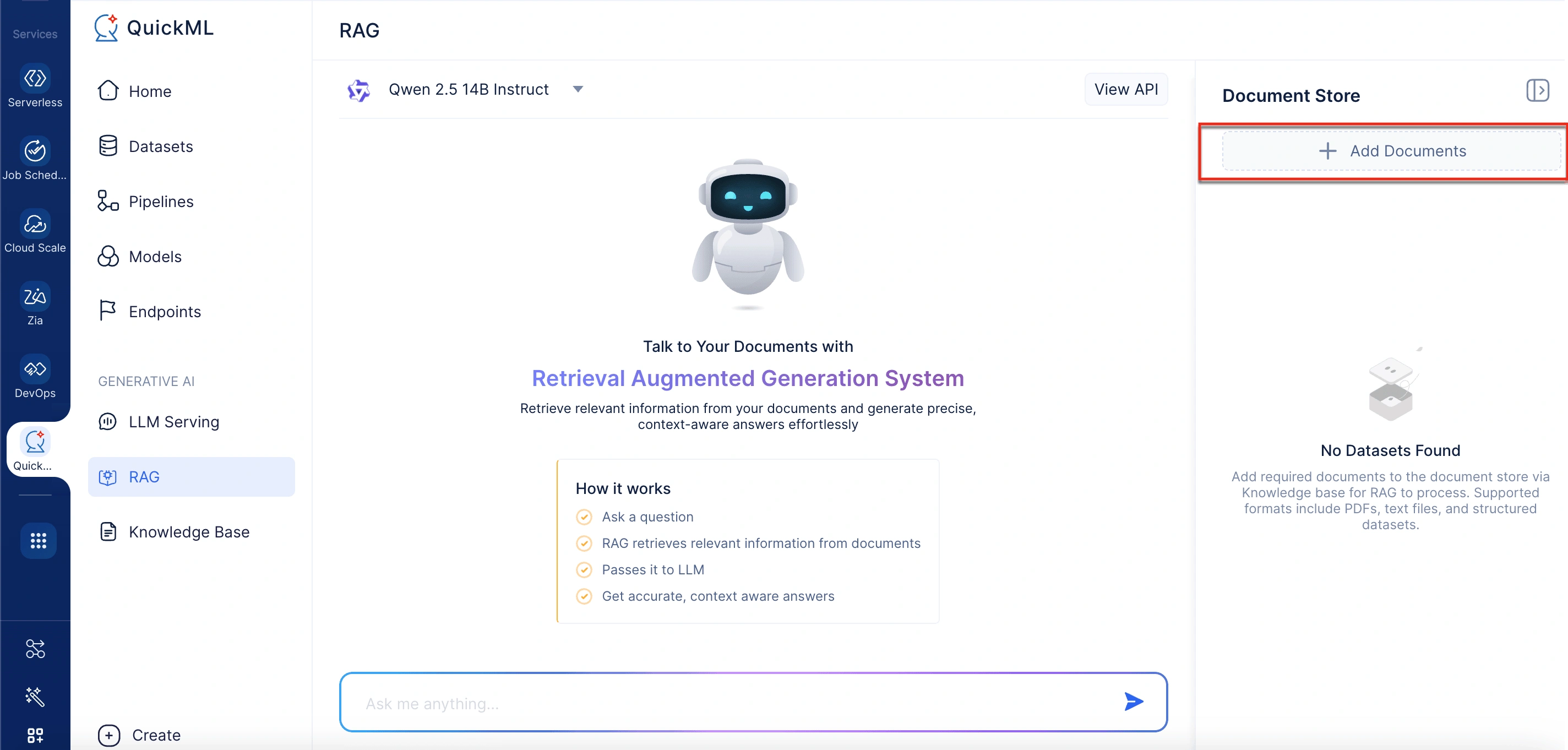
- En el panel Add Documents From Knowledge Base, seleccione archivos existentes o haga clic en New Document para cargar desde su escritorio, WorkDrive o Zoho Learn.
- Ingrese sus consultas en la interfaz de chat.
El modelo recuperará información relevante de la base de conocimiento y proporcionará respuestas conscientes del contexto, incluyendo el desglose detallado de la respuesta.
Nota: Las respuestas se generan basándose en los documentos almacenados en la base de conocimiento. Puede agregar nuevos documentos según sea necesario para asegurar que el modelo tenga los datos requeridos para responder consultas.
Consideremos algunos casos de uso de ejemplo para entender cómo RAG se puede usar en un escenario empresarial en tiempo real.
Caso de uso de ejemplo 1: Implementación de RAG para asistencia de políticas de empleados en una organización
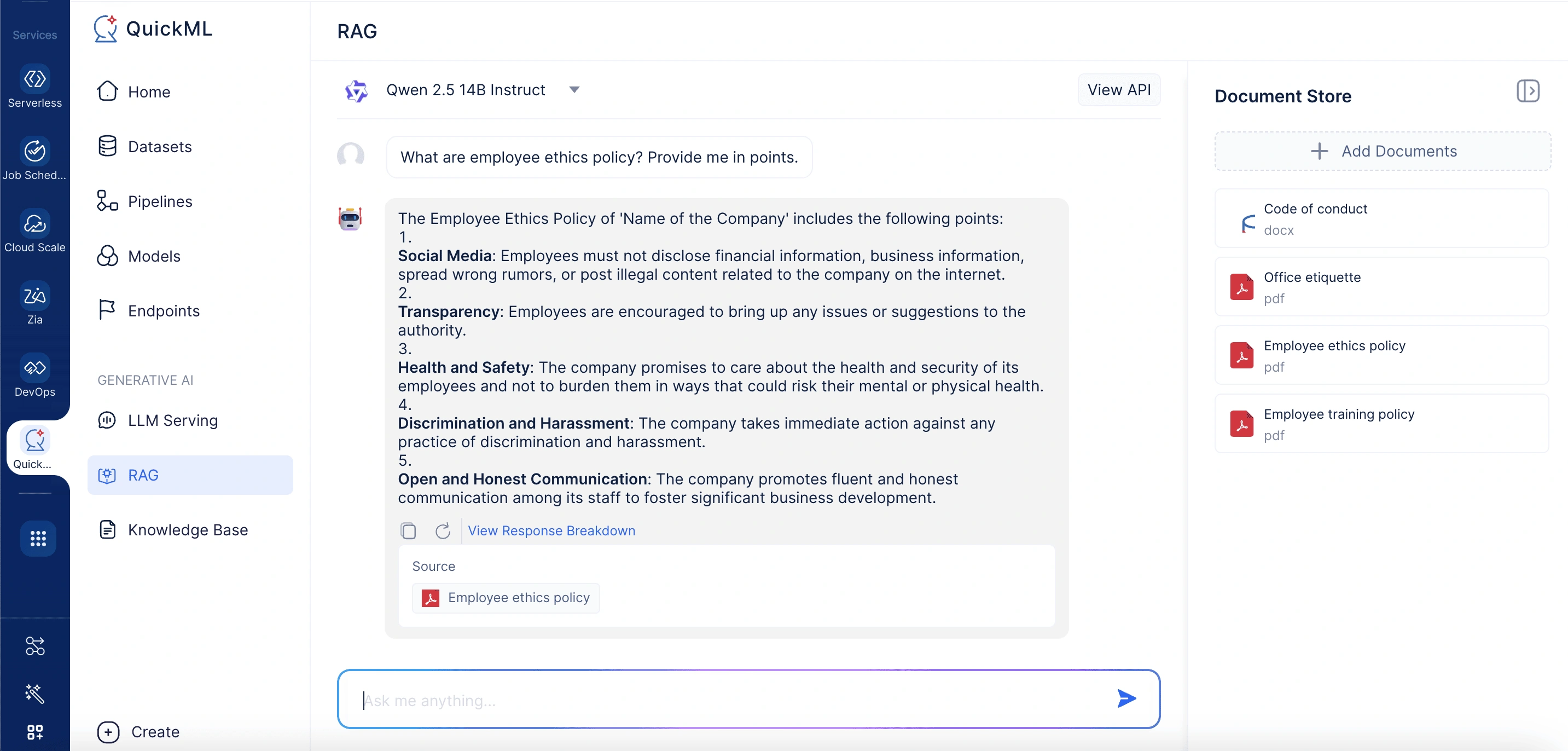
Una empresa que busca mejorar la comprensión de los empleados sobre las políticas de ética y capacitación comienza reuniendo todos los documentos relevantes—como el Código de Conducta, la Política de Etiqueta en la Oficina, la Política Anti-Acoso, las Directrices de Comportamiento en el Lugar de Trabajo y los Manuales de Capacitación Obligatoria—y cargándolos en la base de conocimiento RAG de QuickML. Desde la interfaz de chat de RAG, el administrador accede al panel Add Documents From Knowledge Base para importar o seleccionar archivos existentes. Una vez cargados, los documentos forman un repositorio centralizado y estructurado que Qwen 2.5 14B Instruct puede referenciar durante las interacciones con los usuarios.
Cuando un empleado hace una pregunta como "¿Cuál es la política de ética de los empleados?", el sistema RAG de QuickML realiza una búsqueda semántica en las políticas cargadas, recupera la información más relevante y la combina con la consulta. Este contexto se envía entonces a Qwen 2.5 14B Instruct, que genera una respuesta concisa y contextualmente precisa. El usuario también puede ver un desglose detallado de qué documentos y secciones específicas se utilizaron para generar la respuesta—asegurando transparencia y confianza en la información proporcionada.
Caso de uso de ejemplo 2: Mejorando el soporte al cliente con RAG para una plataforma SaaS
Una empresa SaaS que busca mejorar su experiencia de soporte al cliente aprovecha RAG para construir un asistente de ayuda inteligente. El equipo de soporte recopila todos los recursos relevantes—preguntas frecuentes del producto, manuales de usuario, guías de solución de problemas, notas de lanzamiento y documentación de API—y los carga en la base de conocimiento RAG dentro de QuickML. A través de la interfaz de chat de RAG, el administrador usa el panel Add Documents From Knowledge Base para poblar el almacén de documentos con este contenido, asegurándose de que se mantenga actualizado con cada lanzamiento de producto. Una vez configurado, el sistema RAG se convierte en un repositorio central de soporte.
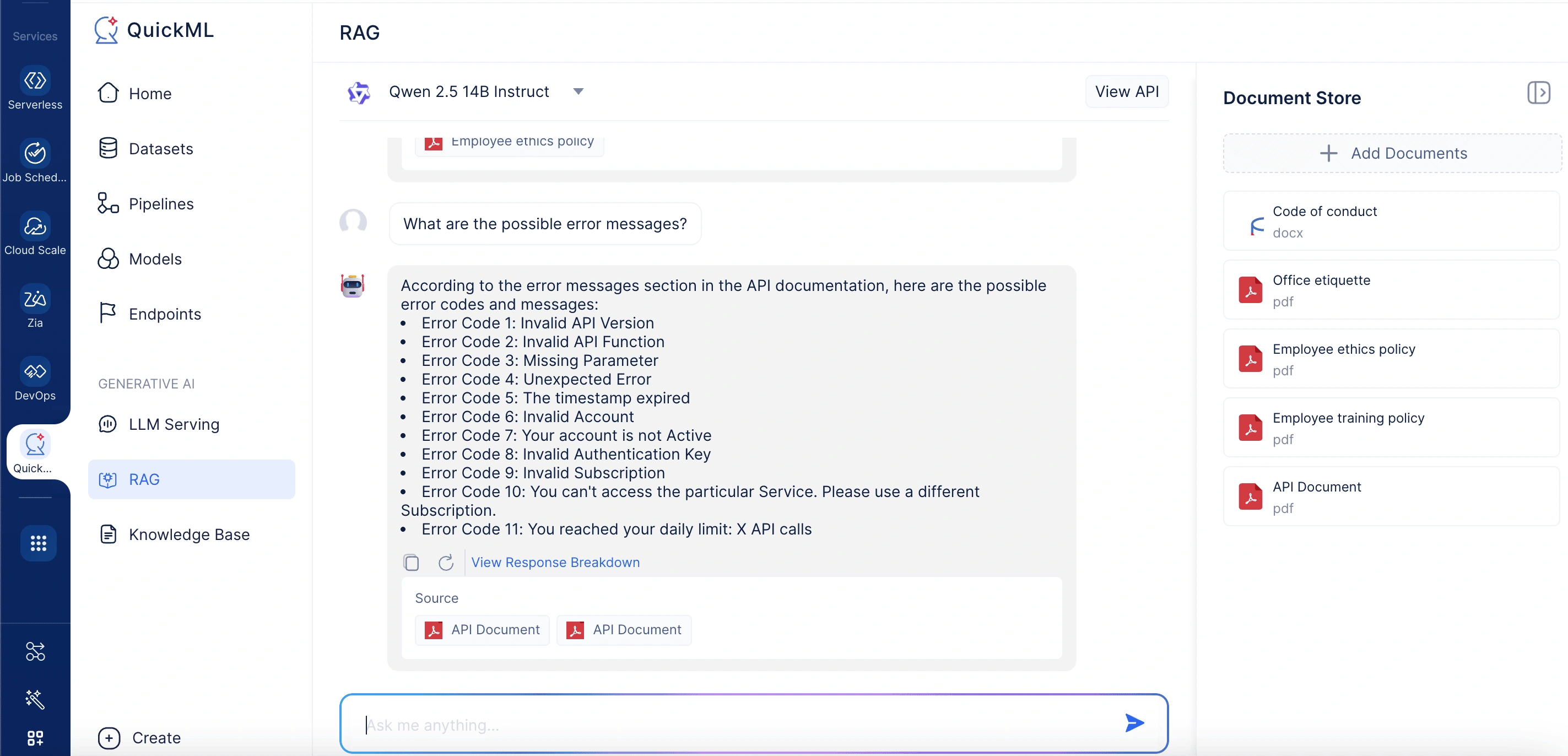
Cuando un usuario envía una consulta como "¿Cuáles son los posibles mensajes de error?", el sistema busca semánticamente en el almacén de documentos la información más relevante, recupera el contenido coincidente y envía tanto la consulta como el contexto de apoyo al modelo de lenguaje. El modelo entonces genera una solución precisa y fácil de seguir, haciendo referencia a las secciones precisas de la documentación. Los usuarios pueden ver el material fuente detrás de la respuesta para transparencia y lectura adicional, reduciendo el volumen de tickets y mejorando la efectividad del autoservicio.
Integración de RAG en sus aplicaciones
Puede integrar el RAG de QuickML en sus aplicaciones usando la URL del endpoint proporcionada. Esto permite a las empresas mejorar las herramientas de soporte al cliente, chatbots internos y sistemas de automatización de documentos con capacidades de IA ricas en contexto.
Para habilitar una integración segura y eficiente, QuickML admite autenticación basada en OAuth para la generación de tokens de acceso. Puede consultar esta documentación para detalles sobre los diferentes tipos de aplicaciones OAuth y los pasos necesarios para generar y gestionar tokens de acceso.
Para obtener la URL del endpoint
- Navegue a la sección Generative AI en QuickML.
- Seleccione la pestaña RAG.
- Haga clic en la opción View API en la esquina superior derecha de la interfaz de chat.
- En la ventana emergente Model Details, desplácese hasta la sección API Details para obtener la URL del endpoint.
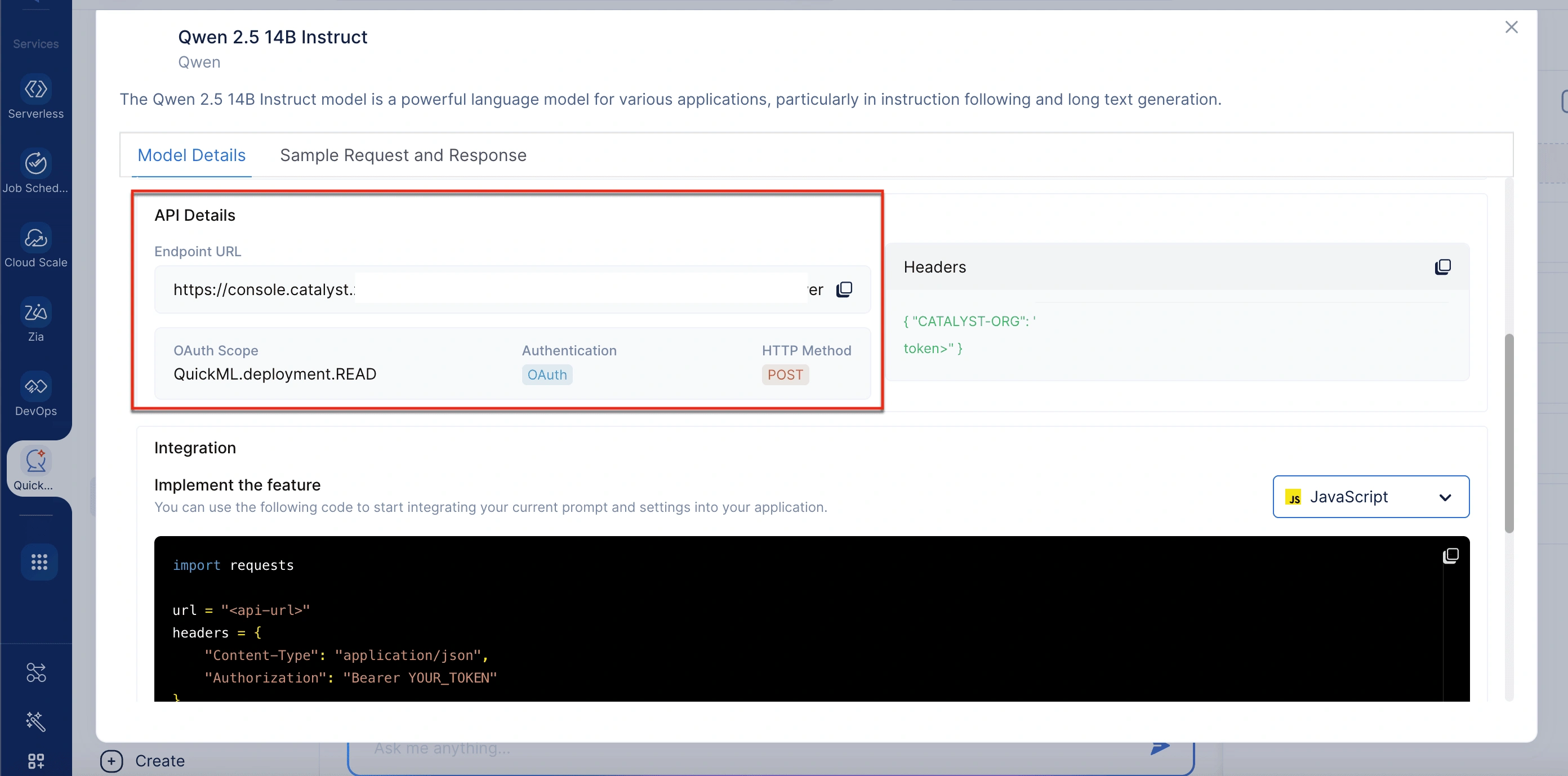
Última actualización 2026-03-20 21:51:56 +0530 IST
Yes
No
Send your feedback to us