Introducción a NLP en Text Analytics
El Procesamiento de Lenguaje Natural (NLP) es un subcampo de la inteligencia artificial (IA) que otorga a las máquinas la capacidad de comprender, interpretar y generar lenguaje humano de una manera significativa y útil. Con las enormes cantidades de datos textuales que se generan cada día, NLP combina lingüística computacional, aprendizaje automático y aprendizaje profundo para permitir que las máquinas procesen datos de lenguaje natural y extraigan información valiosa de ellos, generando a su vez valor para las empresas. El procesamiento de lenguaje natural mejora la experiencia del usuario al abordar proactivamente las preocupaciones y desafíos basados en datos que enfrentan los usuarios empresariales, agregando así un valor significativo al negocio.
¿Por qué es popular?
La popularidad de NLP está impulsada por su capacidad para dar sentido al complejo lenguaje humano y aplicarlo a problemas del mundo real, haciendo las interacciones con la tecnología más naturales e intuitivas. Las razones clave de su creciente popularidad incluyen:
- Extracción de Información de los Datos: Las empresas recopilan grandes cantidades de datos textuales de diversas fuentes como redes sociales, artículos, reseñas de productos, retroalimentación, documentación legal, etc. Necesitan entender lo que los clientes o usuarios están diciendo sobre sus productos o servicios. NLP proporciona formas eficientes de procesar, analizar y extraer información valiosa de estos datos grandes y no estructurados.
- Aplicaciones Centradas en el Usuario: Con el advenimiento de NLP, las empresas dependen de asistentes virtuales, chatbots y sistemas automatizados de servicio al cliente para abordar las consultas de los usuarios de manera más rápida y eficiente.
- Capacidades de Traducción: NLP permite la traducción automática, facilitando la comunicación entre idiomas y ayudando a eliminar las barreras lingüísticas en la sociedad.
- Capacidades de Resumen: Los documentos extensos se pueden convertir en resúmenes cortos para una lectura rápida, ahorrando tiempo y esfuerzo.
Estas son solo algunas aplicaciones, con más innovaciones surgiendo cada día.
Aplicaciones empresariales
NLP permite varias aplicaciones en entornos empresariales al utilizar tareas de NLP para ayudar a las empresas a automatizar procesos y extraer información accionable de grandes conjuntos de datos. Veamos algunas tareas de NLP y sus aplicaciones empresariales en tiempo real.
Tareas de NLP
Las tareas se refieren a objetivos o problemas específicos que un modelo de NLP está diseñado para realizar o resolver. Cada tarea se enfoca en abordar un aspecto particular del procesamiento o análisis del lenguaje natural.
Ejemplos de Tareas de NLP
Las tareas que se pueden realizar usando el constructor de Text Analytics de QuickML incluyen:
- Detección de spam: La clasificación de spam es el modelo de clasificación binaria, donde el propósito es clasificar los correos electrónicos recibidos como spam o no. El modelo de detección de spam toma el correo electrónico, asunto, detalles del remitente, etc. como entrada al modelo y genera la probabilidad de que el correo sea spam. Basándose en el umbral, clasificará el correo como spam o no spam. Tareas de clasificación de texto: Varias otras tareas que caen bajo la clasificación de texto similares a la clasificación de spam para correos electrónicos son la detección de intención, la clasificación de compromisos, y la detección de emociones e identificación de tonalidad caen bajo las tareas de clasificación de texto.
- Detección de idioma: La detección de idioma es un paso fundamental aplicado en varias aplicaciones de NLP como traducción de idiomas, corrección gramatical y texto a voz. Detectar el idioma utilizado para buscar contenido web y devolver los resultados en el mismo idioma o usado en chatbots/herramientas de traducción para proporcionar respuestas en el mismo idioma.
- Análisis de Sentimiento: Determina el tono de sentimiento (positivo, negativo o neutral) de un fragmento de texto. En general, la entrada a un modelo de clasificación de sentimiento sería un fragmento de texto, y la salida es el sentimiento que se expresa en el texto. En un escenario del mundo real, la clasificación de sentimiento sería útil para que las empresas descubran lo que sienten sus clientes sobre sus productos usando las reseñas de productos y comprendan las áreas de impacto negativo.
Las tareas que se pueden realizar usando las características de Zia en QuickML son: Zia Features
Las siguientes tareas se pueden realizar usando los servicios de Catalyst Zia:
- Reconocimiento de Entidades Nombradas (NER): Detecta nombres propios, como nombres de personas, lugares y organizaciones.
- Extracción de palabras clave: Una técnica en NLP para identificar y extraer las palabras clave más relevantes de datos de texto, ayudando a capturar los temas principales y, a su vez, asistiendo en resumir información, indexar y categorizar documentos.
Aplicaciones de NLP
Las aplicaciones se refieren a los casos de uso prácticos del mundo real de los modelos de NLP. Una aplicación a menudo se construye usando una o más tareas de NLP para resolver problemas más amplios del usuario final o proporcionar servicios.
Ejemplos de Aplicaciones de NLP:
- Herramientas de Análisis de Sentimiento: Usa tareas de extracción de sentimiento, tonalidad e identificación de emociones para medir la opinión pública. Es crucial para las empresas y marcas que valoran mucho la comprensión de las experiencias de los clientes. Se puede implementar para los siguientes propósitos:
- Medir y monitorear los sentimientos expresados por los clientes en plataformas de redes sociales y encuestas de opinión
- Automatizar el análisis de retroalimentación y reseñas de clientes y reducir la carga de trabajo manual involucrada.
- Identificar y abordar situaciones críticas en tiempo real mediante el monitoreo automatizado de sentimientos negativos
- Filtros de Spam de Correo Electrónico: Los filtros de spam aprovechan tareas como la clasificación de spam para identificar y filtrar correos electrónicos no solicitados o no deseados, moviéndolos automáticamente a la carpeta de spam. Esto mejora la experiencia del usuario al reducir el desorden en la bandeja de entrada, ahorrar tiempo y minimizar el riesgo de exposición a intentos de phishing, esquemas fraudulentos y otras estafas dañinas.
- Análisis de retroalimentación del cliente: Al aprovechar múltiples tareas de NLP como el análisis de sentimiento y la extracción de palabras clave, las empresas pueden obtener información sobre lo que los clientes dicen sobre sus productos en reseñas o en las redes sociales. Esto les permite abordar las preocupaciones o quejas de los clientes de manera efectiva, mejorando en última instancia la satisfacción del cliente y la experiencia general.
- Mejorar la eficiencia del soporte al cliente: Tareas como la detección de emociones permiten a las empresas analizar las interacciones de los clientes con su personal de soporte al cliente a través de chats, llamadas, quejas, retroalimentación o reseñas, publicaciones en redes sociales y más. Esto ayuda a identificar las emociones por las que pasa el cliente, como felicidad, frustración o enojo al usar sus productos o servicios. Esto ayuda a las empresas a comprender mejor el sentimiento de sus clientes, permitiéndoles responder con empatía, adaptar sus servicios y mejorar las relaciones con los clientes. Detectar lo que siente el cliente da una ventana para implementar medidas proactivas para abordar sus preocupaciones, resolver sus problemas y así mejorar la lealtad a la marca.
- Soporte al cliente a escala: Las empresas aprovechan las tareas de clasificación de intención y actividad para interpretar las consultas de los usuarios con precisión y proporcionar respuestas en consecuencia. Al automatizar la resolución de consultas comunes o básicas, las organizaciones pueden reducir significativamente los tiempos de respuesta y liberar recursos para problemas más complejos. Esta automatización permite que el soporte al cliente escale eficientemente, extendiendo el alcance de sus servicios de soporte y asegurando una prestación de servicio consistente. Además, se emplean asistentes virtuales para modelar y entregar respuestas, mejorando aún más la velocidad y calidad del soporte mientras se mantiene una experiencia de usuario personalizada.
Una aplicación es esencialmente una implementación práctica donde múltiples tareas se unen para crear valor para los usuarios. Mientras que las tareas se enfocan en operaciones de lenguaje específicas, las aplicaciones se enfocan en resolver problemas más amplios centrados en el usuario al combinar varias tareas. Estos son solo algunos ejemplos de cómo las tareas de NLP se están aplicando en negocios del mundo real. Con los avances en tecnología, una gran cantidad de aplicaciones innovadoras continúa emergiendo, revolucionando las experiencias de los usuarios, optimizando procesos y fomentando una mayor lealtad del cliente al abordar sus necesidades de manera más efectiva.
Pasos para construir un pipeline
QuickML usa constructores de pipelines en modo clásico y modo inteligente para crear modelos de text analytics.
El modo Clásico presenta una interfaz de constructor de pipelines de arrastrar y soltar donde una lista de operaciones de datos y aprendizaje automático están disponibles para construir modelos de NLP. Estos nodos se pueden arrastrar y soltar en el constructor para construir el pipeline de aprendizaje automático, que, al ejecutarse, genera un modelo de NLP.
El modo Inteligente proporciona una plantilla preconstruida para construir modelos de NLP, diseñada para simplificar el proceso de desarrollo del modelo desde el preprocesamiento de datos, extracción de características hasta la selección del modelo. Con esta plantilla preconstruida, los stages están predefinidos y los usuarios tienen varios parámetros para configurar las operaciones en cada stage. Esta plantilla elimina la ambigüedad de qué operación usar y cuándo, para construir modelos de NLP y optimiza el proceso de construcción de modelos.
Construir un Modelo Usando Smart Builder
La construcción de modelos de aprendizaje automático basados en texto sigue un proceso similar a otros modelos de ML, involucrando pasos similares desde el preprocesamiento de datos, selección de algoritmos y ajuste del modelo. Sin embargo, los modelos de NLP difieren en la secuencia de aplicación de operaciones específicas basadas en texto. Esta secuencia es crucial para construir un modelo, ya que asegura que los datos de texto se transformen y procesen de la manera más efectiva antes de aplicar algoritmos de aprendizaje automático.
En el Modo Inteligente de construcción de modelos, el constructor de pipelines se simplifica en tres pasos principales:
- Preprocesamiento: En este paso, los datos de texto sin procesar se limpian y preparan para un análisis posterior. Esto implica operaciones como tokenización, conversión de mayúsculas/minúsculas, stemming y lematización, eliminación de stopwords y ruido, y normalización.
- Extracción de Características: Este paso implica convertir los datos de texto en características numéricas que pueden ser comprendidas por los algoritmos de aprendizaje automático. Se usan comúnmente técnicas como TF-IDF, word embeddings y bag-of-words.
- Selección de Algoritmo: En el paso final, se elige un algoritmo adecuado de los algoritmos de aprendizaje supervisado o no supervisado disponibles según el caso de uso. El modelo se entrena entonces usando los datos preprocesados del paso de extracción de características.
Cada paso en el Constructor de Pipelines del Modo Inteligente viene con stages/operaciones configurables que le permiten configurar las operaciones para su problema específico de NLP.
Profundicemos en cada paso y exploremos los stages/operaciones disponibles en ellos:
Stage 1: Preprocesamiento
Los datos de texto generalmente son sin procesar, por lo que es importante procesar los datos antes de alimentarlos a cualquier algoritmo para mejorar el rendimiento. En nuestro smart builder, el stage de preprocesamiento de datos textuales tiene 7 operaciones donde las primeras seis operaciones trabajan en los datos textuales y la operación final Label Encoding se aplica en la columna objetivo de los conjuntos de datos etiquetados. La salida de este stage se pasa al stage de Extracción de Características, donde todos los datos de texto se convierten a formato numérico.
Veamos las operaciones en el stage de preprocesamiento.
a. Conversión de mayúsculas/minúsculas
Convierte los datos de texto sin procesar con diferentes mayúsculas/minúsculas a un caso común deseado (minúsculas en general). Esto ayudaría a reducir la dispersión (sin un caso común “NLP, Nlp, nlp” se considerarían como tres palabras diferentes).
b. Tokenización
La tokenización es descomponer los datos textuales en unidades más pequeñas. Por ejemplo, los párrafos se pueden segmentar en oraciones, las oraciones en palabras y las palabras en caracteres individuales, permitiendo descubrir patrones o información que no son visibles en segmentos más grandes.
En QuickML, la tokenización de oraciones se puede realizar tanto a nivel de palabra como de carácter. Después de aplicar la tokenización en los datos a nivel de Palabra, las operaciones posteriores (Stemming y lematización, Eliminación de stopwords, Eliminación de ruido, Normalización) se pueden aplicar a los datos según sea necesario.
Sin embargo, a nivel de Carácter, solo la operación de Eliminación de ruido se puede aplicar a los datos tokenizados.
Stages de tokenización: Texto : Oraciones ➔ palabras ➔ caracteres
c. Stemming y Lematización
Ambas técnicas reducen las palabras a sus formas raíz, ayudando a normalizar las variaciones de palabras para un análisis más consistente. El stemming recorta los caracteres finales para obtener su forma raíz, que puede no ser siempre una palabra correcta. La lematización, sin embargo, reduce las palabras a su forma de diccionario considerando el contexto, resultando en una palabra correcta con un significado preciso.
La diferencia clave es que el stemming es más rápido pero menos preciso, mientras que la lematización es más precisa pero más lenta, ya que depende del vocabulario y la gramática.
Ejemplo:
| Palabras | Palabra con stem | Palabra lematizada |
|---|---|---|
| Studying, Studies, Studied |
Studi | Study |
| Running, Runner, Runs | Run or Runn | Run |
| Changing | Chang | Change |
d. Eliminación de stopwords
Los idiomas tienen muchas palabras de relleno que no proporcionan ningún uso significativo durante el entrenamiento. Al eliminarlas, podemos hacer que nuestro modelo se enfoque más en palabras importantes. Los artículos, preposiciones, etc., entran en la categoría de stopwords.
e. Eliminación de ruido
Eliminar palabras no deseadas o partes de texto dependiendo de la característica en cuestión. Ejemplo: la clasificación de sentimiento en NLP no requiere las direcciones de correo electrónico. Se puede hacer usando regex o teniendo una lista de palabras de ruido. Los espacios adicionales, caracteres especiales y dígitos también se pueden considerar como ruido.
f. Normalización
Convertir diferentes formatos de texto en un formato estándar. Ejemplo: Las palabras USA, usa, United states of America, The united states of America, the usa a usa. Esto se puede lograr usando mapeo de diccionario. La eliminación de ruido también se puede considerar como parte de la normalización de texto.
| Sin procesar | Normalizado |
|---|---|
|
2moro 2mrrw 2morrow 2mrw tomrw |
tomorrow |
| b4 | before |
| otw | on the way |
| :) :-) ;) |
smile |
g. Label Encoding
Label encoding es un método utilizado para transformar variables categóricas en valores numéricos asignando un entero único a cada categoría. Ayuda a los algoritmos de aprendizaje automático a procesar datos categóricos de manera efectiva. En el contexto de datos de texto, la etiqueta objetivo representa una variable categórica con varias clases que se pueden convertir en forma numérica para entrenar el modelo de manera efectiva.
Ahora, nuestros datos de texto están limpios y listos para ser transformados en vectores de palabras usando las técnicas de vectorización disponibles en el stage de extracción de características a continuación.
Stage 2: Extracción de Características
Los datos textuales no se pueden alimentar directamente a un algoritmo; primero deben convertirse a un formato numérico. Hay varios métodos para esta conversión, conocidos como técnicas de vectorización, que también se pueden usar para extraer características adicionales de los datos vectorizados. En este contexto, cada palabra, oración o carácter presentado a un modelo se trata como una característica.
Dicho esto, en QuickML, la conversión de texto a número ocurre usando las técnicas a continuación. Este es el proceso de transformar datos textuales en formato numérico que captura el significado semántico de palabras o frases.
Las técnicas disponibles en QuickML incluyen:
a. Bag Of Words (BOW)
Bag of words crea un vocabulario de palabras únicas presentes en todo el corpus de texto. Cada oración se representa entonces como un vector, hace el mapeo basándose en la presencia de estas palabras, con los valores representando la frecuencia de ocurrencia de cada palabra dentro de esa oración.
Ejemplo:
A continuación se muestra un ejemplo que presenta la representación vectorizada del modelo Bag of Words
para las siguientes oraciones:
S1. Machine learning solves real world problems
S2. NLP popularity is rising
S3. Language translation is NLP task
Representación de tabla de Bag of Words:

Las filas representan las oraciones proporcionadas, y las columnas representan cada palabra en estas oraciones, y los valores representan la frecuencia de ocurrencia de la palabra específica en cada oración.
Representación Vectorial: Cada oración se representa como un vector teniendo los conteos de palabras de la tabla BoW. La longitud del vector es igual al número de palabras únicas en el vocabulario. A continuación se muestra la representación vectorizada de las tres oraciones anteriores. Oración 1 → [ 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]
Oración 2 → [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0]
Oración 3 → [0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1]
El modelo BoW representa datos de texto como vectores y cada palabra en el corpus de texto como una característica. Simplifica los datos para el modelado pero no logra capturar la santidad del orden de las palabras y su significado contextual.
b. TF-IDF (Term Frequency - Inverse Document Frequency)
TF-IDF cuantifica la importancia de cada palabra en el corpus y permite extraer características importantes de los datos de texto que son útiles para entrenar el modelo para un mejor rendimiento. Cuanto más alto sea el puntaje TF-IDF, más importante es la palabra, y viceversa.
Se puede calcular en tres pasos.
Paso 1: Term Frequency (TF) mide cuán frecuentemente aparece un término en un documento en relación con el número total de palabras únicas en ese documento.
Term Frequency de una palabra (TF) = Número de veces que una palabra aparece en un documento / Número total de palabras únicas en el documento
Paso 2: Inverse Document Frequency (IDF) mide cuán importante es un término a través de los documentos.
IDF de una palabra= log(N/n), donde, N es el número total de documentos y n es el número de documentos en los que ha aparecido una palabra.
Paso 3: Calcular el puntaje TF-IDF
TF-IDF = TF * IDF
El IDF de las palabras que ocurren con menos frecuencia será alto y bajo para las palabras comunes. Así, palabras como ’the, is, a’ etc. tendrán una importancia baja, y se podría dar mayor importancia a las palabras específicas del documento.
Ejemplo:
Usemos el ejemplo de muestra de Bag of Words:
S1. Machine learning solves real world problems
S2. NLP popularity is rising
S3. Language translation is NLP task
Paso 1: Calcular Term Frequency (TF)
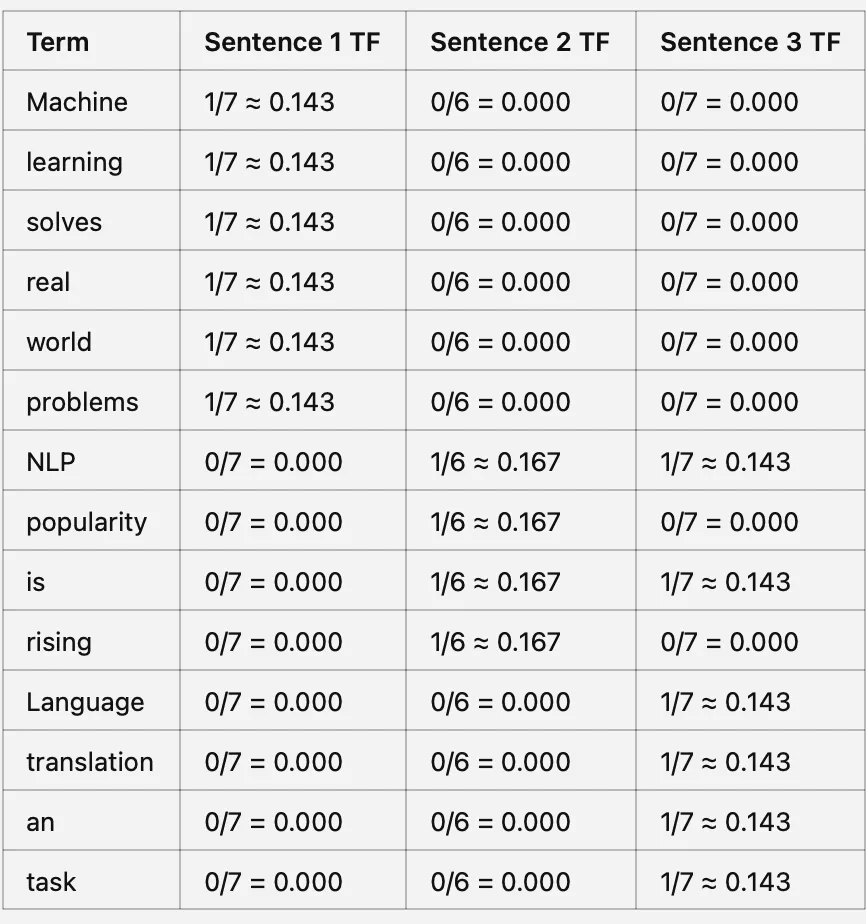
Paso 2: Calcular el puntaje IDF
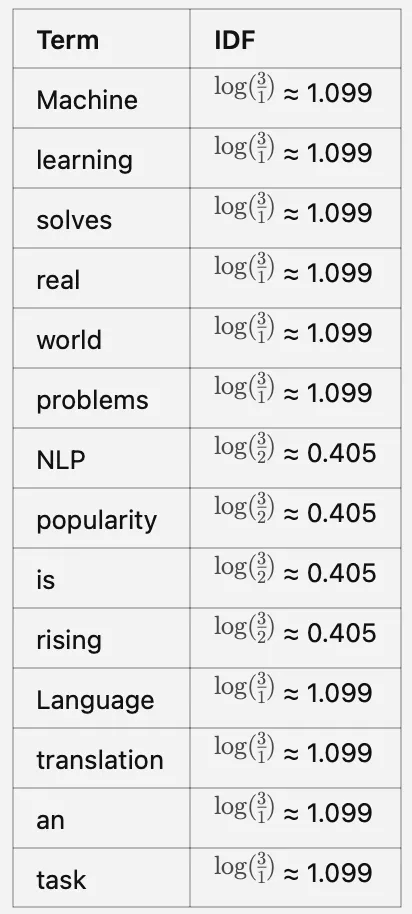
Paso 3: Calcular TF-IDF
Multiplicar TF por IDF para cada término en cada oración
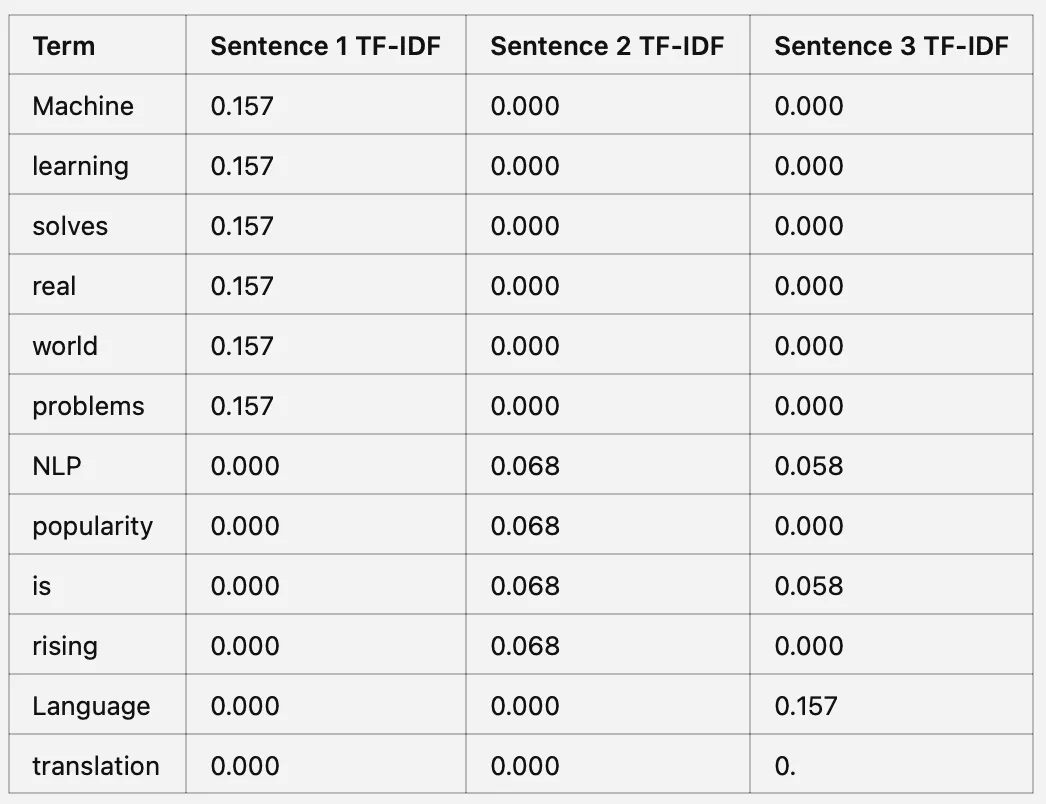
Las ideas clave del ejemplo incluyen:
TF-IDF alto: los valores indican que un término es importante en una oración específica y no es común en todas las oraciones.
TF-IDF bajo: los valores sugieren que un término es común en todas las oraciones o no es único para ninguna oración individual.
TF-IDF resalta las palabras importantes para entender el contexto en el corpus. Muestra cómo algunas palabras o términos son más importantes en un texto específico que en otros.
c. Word2Vec
Word2Vec es un modelo de word embedding preentrenado que genera vectores numéricos (embeddings) para palabras basándose en sus relaciones semánticas y contextuales. Se entrena en un gran corpus de texto para asegurar que las palabras con significados o contextos similares tengan vectores de embedding cercanos en el espacio vectorial. Estas relaciones se pueden cuantificar usando similitud coseno, donde una puntuación más alta indica mayor similitud.
Ejemplo:
Palabras como “king” y “queen” tendrán vectores cercanos entre sí, reflejando su contexto compartido de realeza. De manera similar, “man” y “woman” tendrán vectores que capturan su relación y significado compartido, demostrando la capacidad de Word2Vec para modelar relaciones semánticas de manera efectiva.
d. GloVe
GloVe (Global Vectors for Word Representation) es un modelo de word embedding preentrenado similar a Word2Vec que genera vectores de embedding para palabras dadas. Es un modelo basado en conteo que produce embeddings factorizando una matriz de co-ocurrencia de palabras derivada de todo el corpus. GloVe captura información estadística global analizando cuán frecuentemente co-ocurren las palabras a través del corpus. A diferencia de Word2Vec, que usa un enfoque predictivo basado en el contexto local, GloVe se basa en estadísticas globales de co-ocurrencia para el entrenamiento. Difiere de Word2Vec en el método de entrenamiento.
Ejemplo:
En GloVe, palabras como “king” y “queen” tendrán vectores similares, reflejando su relación semántica (por ejemplo, realeza). Además, GloVe sobresale en capturar relaciones analógicas.
Por ejemplo:
king - man + woman ≈ queen
Esta analogía representa la transformación: La relación entre “king” y “man” (que se puede pensar como “king es a man como queen es a woman”) se captura matemáticamente restando “man” de “king” y sumando “woman”. El resultado es “queen”, lo que significa que el modelo entiende que así como king es a man, queen es a woman.
Esto significa que la diferencia vectorial entre “king” y “man” es similar a la diferencia entre “queen” y “woman”, ilustrando la capacidad de GloVe para modelar tanto el significado como las relaciones de manera efectiva.
Stage 3: Algoritmos y Modelado
Los datos de texto se alimentan a los algoritmos en forma vectorizada para generar un modelo de NLP. Los modelos de NLP se pueden clasificar ampliamente en modelos de aprendizaje supervisado y no supervisado. En QuickML, tenemos algoritmos que usan datos etiquetados para construir modelos de aprendizaje supervisado.
Los algoritmos incluyen:
Métricas de Evaluación del Modelo
NLP también tiene las métricas de evaluación comunes como accuracy, precision, f1 score, etc.
i. Puntuación Log-Loss
Log-loss, también conocido como pérdida logística o pérdida de entropía cruzada, es una métrica de evaluación comúnmente utilizada en modelos de procesamiento de lenguaje natural (NLP), especialmente para tareas de clasificación binaria y multiclase. Log-loss cuantifica la diferencia entre las probabilidades predichas y las etiquetas de clase reales. La probabilidad de predicción de un registro de datos es la probabilidad que el modelo tiene que predecir para cada clase bajo la cual clasificó.
La etiqueta de clase real es la clase verdadera a la que pertenece el registro de datos. La puntuación de log loss indica cuán cerca está la probabilidad de predicción de la etiqueta de clase real. Cuanto más divergidos estén los valores de posibilidad predichos de los valores reales, mayor será la puntuación de log loss.
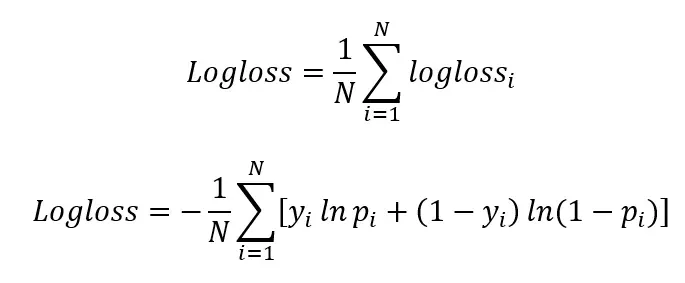
donde
i es la observación/registro dado,
y es el valor real/verdadero,
p es la probabilidad de predicción, y
ln se refiere al logaritmo natural (valor logarítmico usando base de e) de un número
N es el número de observaciones
Mide el rendimiento de un modelo de clasificación cuya salida es un valor de probabilidad entre 0 y 1. Cuanto menor sea la puntuación de log-loss, mejor se ajusta el modelo y mayor es el rendimiento. Un modelo con una puntuación de log-loss de 0 tiene la habilidad perfecta para predecir.
Por ejemplo:
En la clasificación de spam, la clase real de un correo electrónico es “Spam”. La probabilidad predicha para que el correo sea “Spam” es 0.78, y para ser “No-Spam” es 0.22. El logaritmo natural negativo de la probabilidad predicha para la clase correcta (Spam) es 0.2485, que representa la puntuación de log-loss para ese registro particular. La puntuación de log-loss del
modelo se calcula como el promedio del logaritmo natural negativo de las probabilidades predichas para las clases correctas en todos los registros.
ii. Curva AUC-ROC
El Área bajo la curva de la Característica Operativa del Receptor (AUC-ROC) es una métrica de aprendizaje automático que mide qué tan bien está funcionando un modelo de clasificación. AUC representa el área bajo la curva ROC, donde ROC es un gráfico que traza la Tasa de Verdaderos Positivos (TPR) contra la Tasa de Falsos Positivos (FPR) en diferentes umbrales de clasificación.
Verdadero Positivo (TP) y Falso Positivo (FP) son términos utilizados en la matriz de confusión para evaluar el rendimiento de los modelos de clasificación.
- Tasa de Verdaderos Positivos (TPR), también llamada sensibilidad o recall, mide la proporción de registros positivos reales que son correctamente identificados por el modelo.
- Tasa de Falsos Positivos (FPR) mide la proporción de registros negativos reales que son incorrectamente clasificados como positivos.
La especificidad mide las instancias negativas reales que son correctamente identificadas por el modelo.
Una interpretación visual de la curva AUC - ROC se muestra a continuación. Una ROC es el gráfico entre TPR y FPR a través de todos los umbrales posibles, mientras que AUC es el área completa bajo la curva ROC.
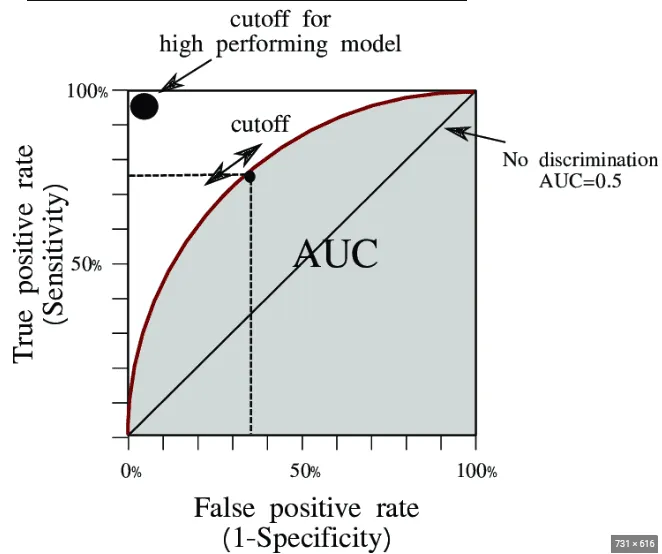
La puntuación AUC (Área Bajo la Curva) varía de 0 a 1, con puntuaciones más altas indicando mejor rendimiento del modelo.
-
Un AUC de 1 significa un modelo perfecto, donde la curva ROC (Característica Operativa del Receptor) forma un camino de ángulo recto completo, logrando 100% de sensibilidad (Tasa de Verdaderos Positivos) con 0% de Tasa de Falsos Positivos.
-
Un AUC de 0.75 indica que el modelo tiene una buena capacidad para distinguir entre clases positivas y negativas el 75% del tiempo, mostrando un mejor rendimiento pero aún dejando margen de mejora.
-
Un AUC de 0.5 sugiere que el modelo no funciona mejor que una predicción aleatoria, que es el resultado menos deseable.
Una puntuación AUC más alta siempre refleja una mejor discriminación del modelo entre clases.
Visualizaciones
Wordcloud
Un Word Cloud es una representación visual de las palabras que ocurren con más frecuencia en un corpus de texto. El tamaño de cada palabra en el word cloud refleja su frecuencia de ocurrencia. Los word clouds se usan comúnmente para identificar rápidamente y resaltar las palabras clave o frases más prominentes en grandes conjuntos de datos de texto, facilitando la comunicación de los términos o conceptos clave que se están discutiendo.
Ejemplo: Tomemos un ejemplo de un extracto de “Las Crónicas de Narnia: El León, la Bruja y el Armario”.

Analicemos el word cloud generado a continuación para ese texto proporcionado para identificar las palabras frecuentes y significativas utilizadas.

Con este word cloud, podemos extraer rápidamente palabras clave importantes, obtener información y comprender el contexto general del texto de una manera visualmente atractiva y eficiente en tiempo.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us