Models
Una vez que un ML pipeline se ejecuta exitosamente, se crea un modelo de ML respectivo. Esta vista del modelo se puede utilizar para obtener una comprensión de sus métricas internas.
La lista de modelos creados se puede ver en la página de Models junto con el estado de cada modelo como se muestra a continuación.
Métricas del Modelo
Los usuarios de QuickML tendrán acceso para ver las métricas del modelo para cada versión, que proporcionan información valiosa sobre el rendimiento de los modelos de aprendizaje automático. Estas métricas sirven como indicadores esenciales para evaluar la precisión y efectividad del modelo al realizar predicciones.
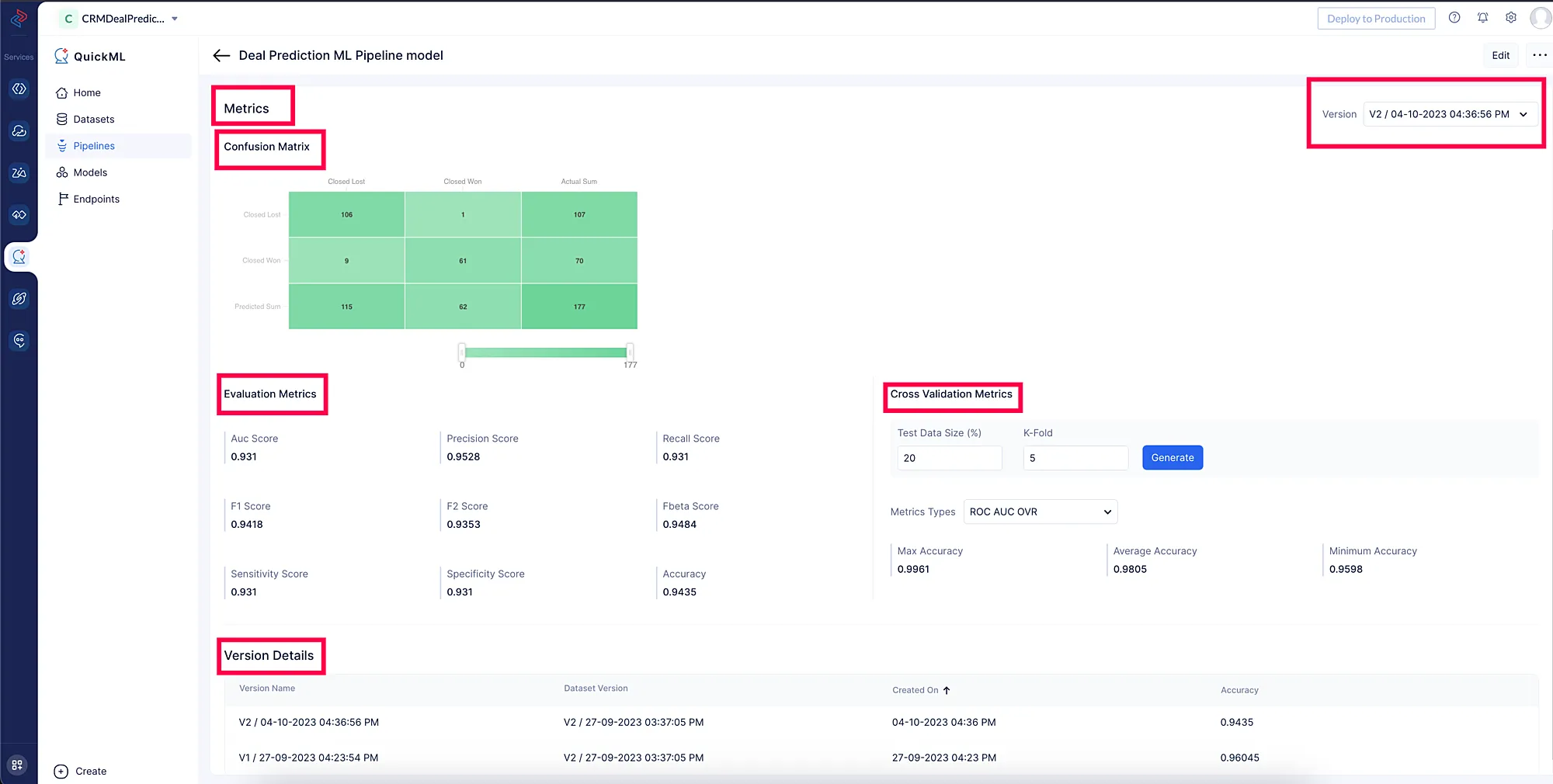
Los usuarios de QuickML tienen acceso a las siguientes métricas.
Confusion Matrix
En aprendizaje automático, una confusion matrix se utiliza para medir el rendimiento de un modelo de clasificación. En términos simples, una confusion matrix es un resumen del número de predicciones correctas e incorrectas realizadas por el modelo de aprendizaje automático. La matriz muestra el número de true positives (TP), true negatives (TN), false positives (FP) y false negatives (FN) como se muestra a continuación.

TP: True Positive es el conteo de instancias donde tanto los valores predichos como los reales son positivos.
TN: True Negative es el conteo de instancias donde tanto los valores predichos como los reales son negativos.
FP: False Positive es el conteo de instancias donde el modelo las predijo como positivas pero los valores reales son negativos.
FN: False Negative es el conteo de instancias donde el modelo las predijo como negativas pero los valores reales son positivos.
Caso de uso
Expliquemos la confusion matrix con un caso de uso: predecir la satisfacción de los pasajeros de una aerolínea con el servicio de vuelo.
Explicación breve: Una aerolínea recopila información sobre sus pasajeros, incluyendo sus datos demográficos, información de vuelo y respuestas de encuestas sobre su satisfacción con el servicio de la aerolínea. Después, la aerolínea aplica esta información para crear un modelo de clasificación de aprendizaje automático que predice si el pasajero está satisfied o neutral/dissatisfied.
Evaluemos el rendimiento de un modelo de clasificación usando una confusion matrix en QuickML como se muestra a continuación:
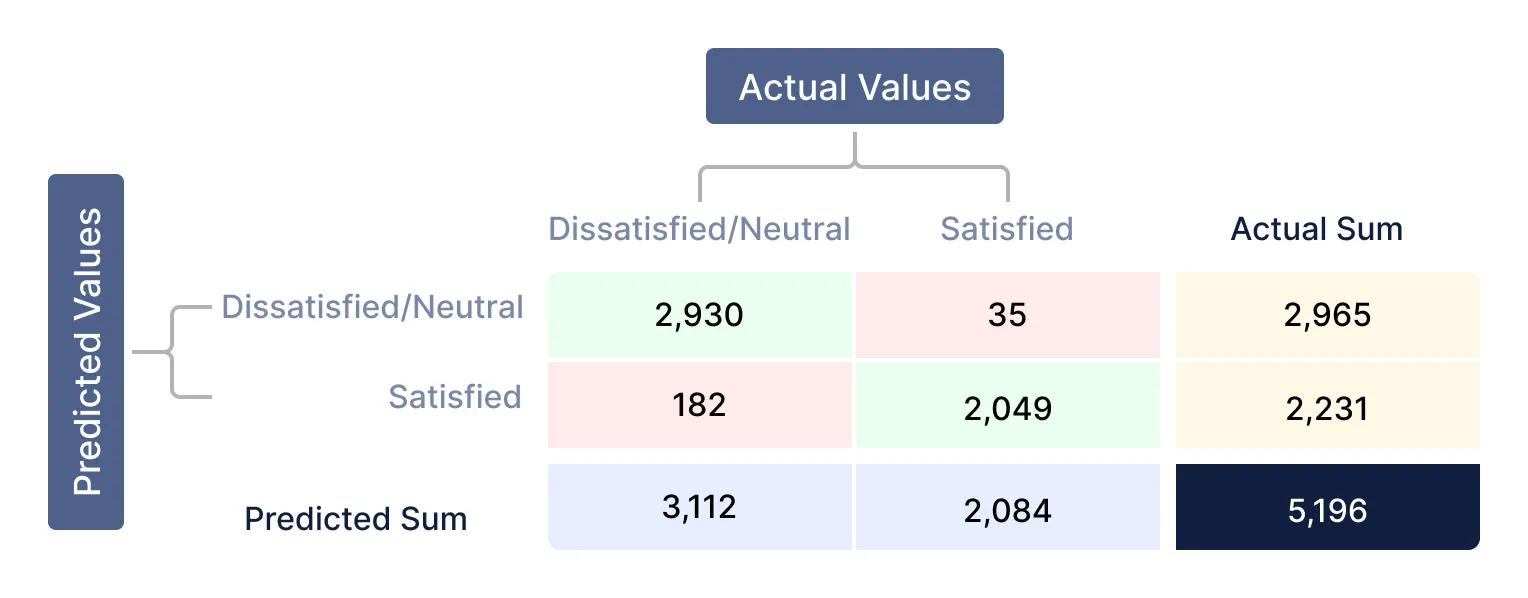
Valores listados de la confusion matrix:
| Conteo total de respuestas | 5,196 | True Positive (TP) | 2,930 | False Negative (FN) | 182 | False Positive (FP) | 35 | True Negative (TN) | 2,049 |
|---|
Las métricas de rendimiento comúnmente utilizadas para evaluar cualquier modelo de clasificación son las siguientes.
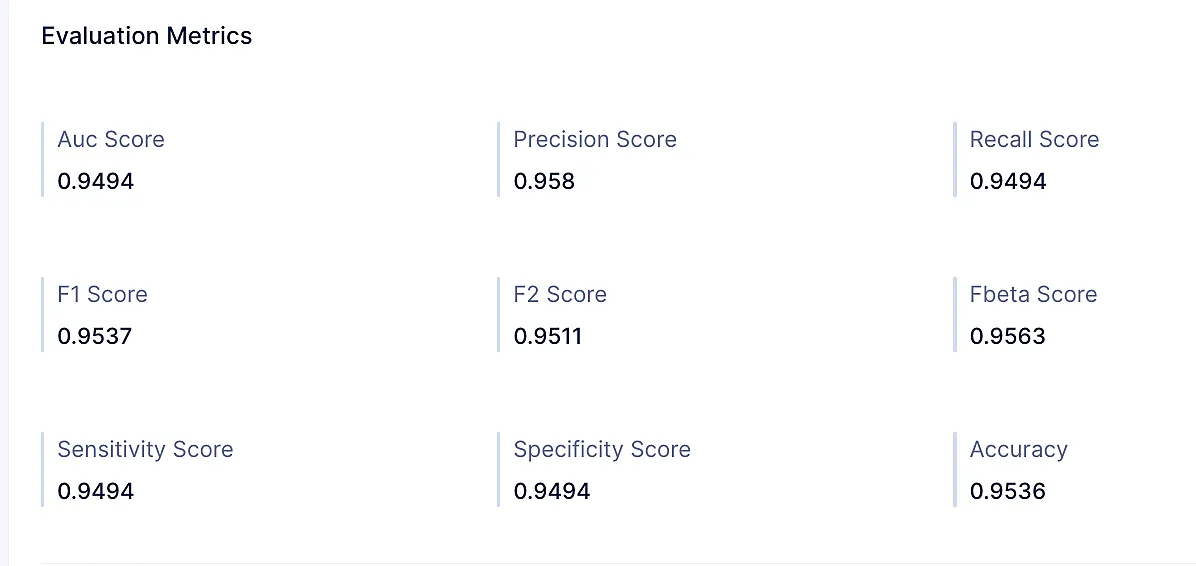
Accuracy score: La proporción de instancias correctamente predichas entre el total de instancias.
Accuracy = TP+TN/Total Responses = (2,930+2,049)/5,196 = 0.958Precision score: Precision es una medida de cuán precisas son las predicciones positivas del modelo. Se calcula como la proporción de predicciones verdaderamente positivas sobre la suma de predicciones verdaderamente positivas y falsamente positivas.
Precision = TP/(TP+FP)= 2,930/(2,930+35) = 0.988Recall score: El recall score, también conocido como sensibilidad, es el porcentaje de casos positivos reales que un modelo predice correctamente. Se calcula dividiendo el número de predicciones verdaderamente positivas entre la suma de las predicciones verdaderamente positivas y falsamente negativas.
En términos más simples, un recall score mide qué tan bien un modelo puede identificar todos los casos positivos en un conjunto de datos. Un recall score alto significa que el modelo es bueno encontrando todos los casos positivos, mientras que un recall score bajo significa que el modelo está perdiendo muchos casos positivos.
Recall score = TP/(TP+FN) = 2930/3112 = 0.941F1 score: La media armónica de precision y recall, proporcionando una evaluación equilibrada del rendimiento del modelo.
F1 Score = 2*Recall*Precision/(Recall+Precision)
= 2*0.941*0.988/(0.941+0.988)
= 0.9639De las métricas anteriores, podemos inferir algunas conclusiones sobre el modelo.
- El modelo de la aerolínea predijo correctamente el nivel de satisfacción de 4,979 pasajeros, mientras que 182 fueron incorrectamente predichos como satisfechos y 35 como insatisfechos/neutrales.
- Tiene buen rendimiento con un accuracy del 95.8%, un precision del 98.8% y un recall del 94.1%. Sin embargo, ha fallado en 182 predicciones de pasajeros satisfechos. Por lo tanto, el modelo debería ser ajustado para aumentar el recall score, lo que luego identificaría a todos los pasajeros satisfechos.
Al examinar estas métricas del modelo en QuickML, podemos obtener información más profunda sobre el rendimiento de cualquier modelo de aprendizaje automático y tomar decisiones informadas sobre la selección y optimización del modelo. Esto empoderará a los usuarios para ajustar sus modelos y mejorar la precisión predictiva.
Métricas de evaluación
QuickML muestra las siguientes métricas de evaluación respecto a los modelos de clasificación y regresión creados.
-
Classification
-
Regression
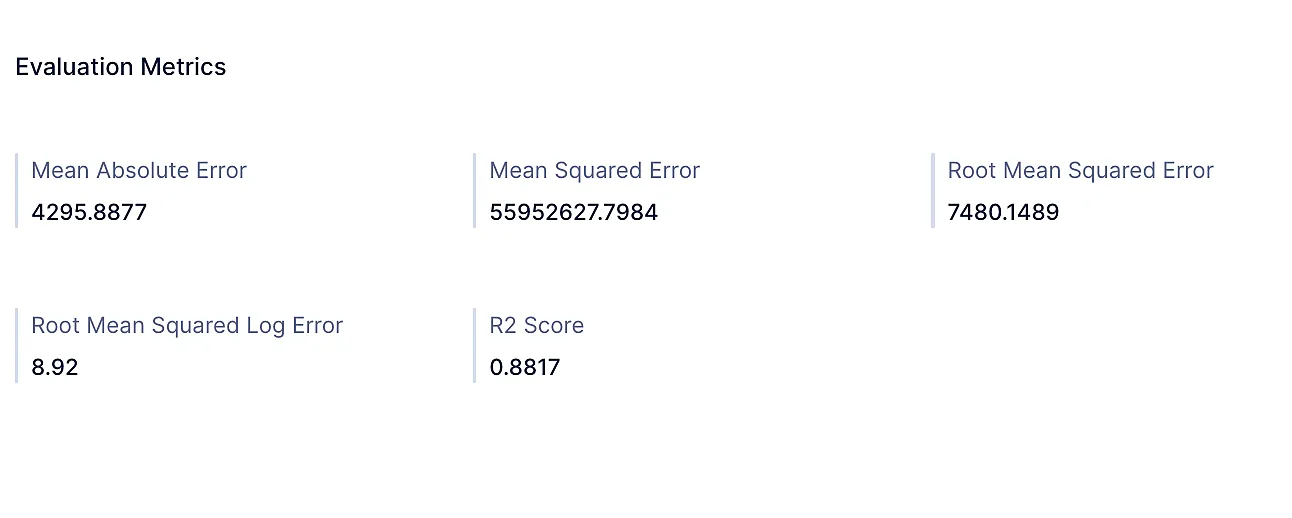
-
Recommendation
-
Time Series
Métricas de Cross Validation
Cross validation es un método para evaluar el rendimiento de un modelo de aprendizaje automático dividiendo los datos de entrenamiento en k pliegues, entrenando el modelo en k-1 pliegues y evaluando el modelo en el pliegue restante. Este proceso se repite k veces, y el rendimiento promedio del modelo en los k pliegues se utiliza para evaluar su rendimiento general.
En términos más simples, cross validation funciona entrenando el modelo en un subconjunto de los datos de entrenamiento y luego evaluando su rendimiento en el subconjunto restante de los datos de entrenamiento. Esto se repite múltiples veces, y el rendimiento promedio del modelo en todos los subconjuntos se utiliza para evaluar su rendimiento general. Ayuda a asegurar que el modelo no esté sobreajustándose a los datos de entrenamiento y que generalice bien a nuevos datos.
QuickML te proporciona una gran cantidad de métricas de cross validation para rastrear el rendimiento tanto para modelos de clasificación como de regresión.
La lista de tipos de métricas proporcionadas en cross validation es la siguiente:
-
Classification Model
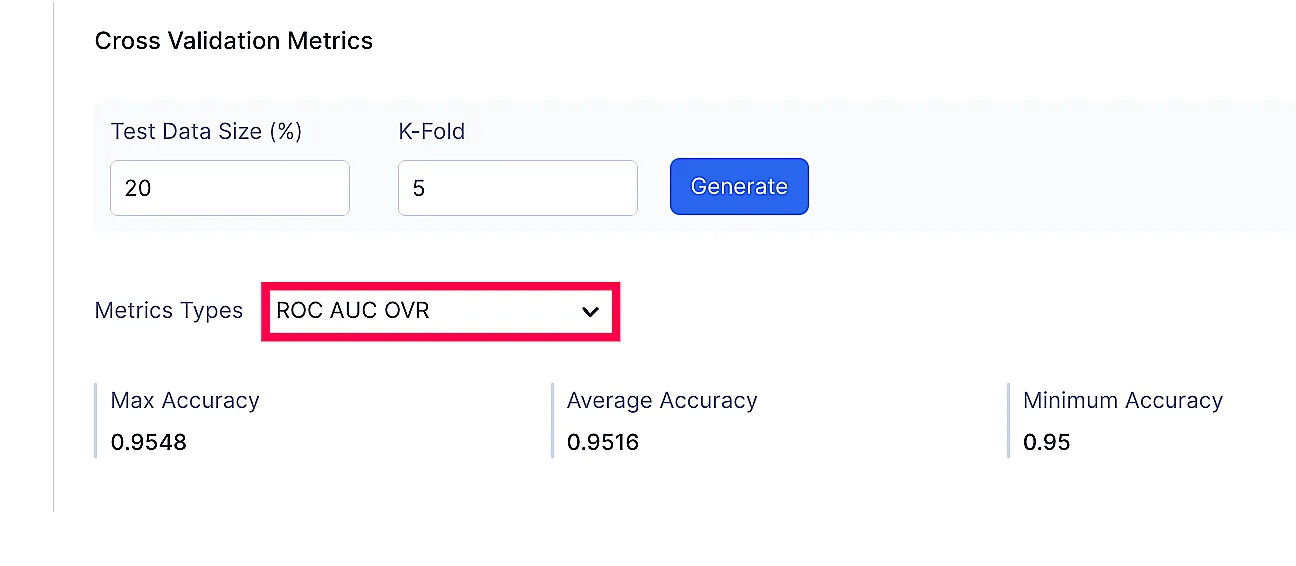
Tipos de Métricas:
- ROC AUC OVR
- ROC AUC OVO
- ROC AUC OVR weighted
- ROC AUC OVO weighted
- Balanced accuracy
- Average precision
- F1 score
- F1 macro
- F1 micro
- F1 samples
- F1 weighted
-
Regression Model
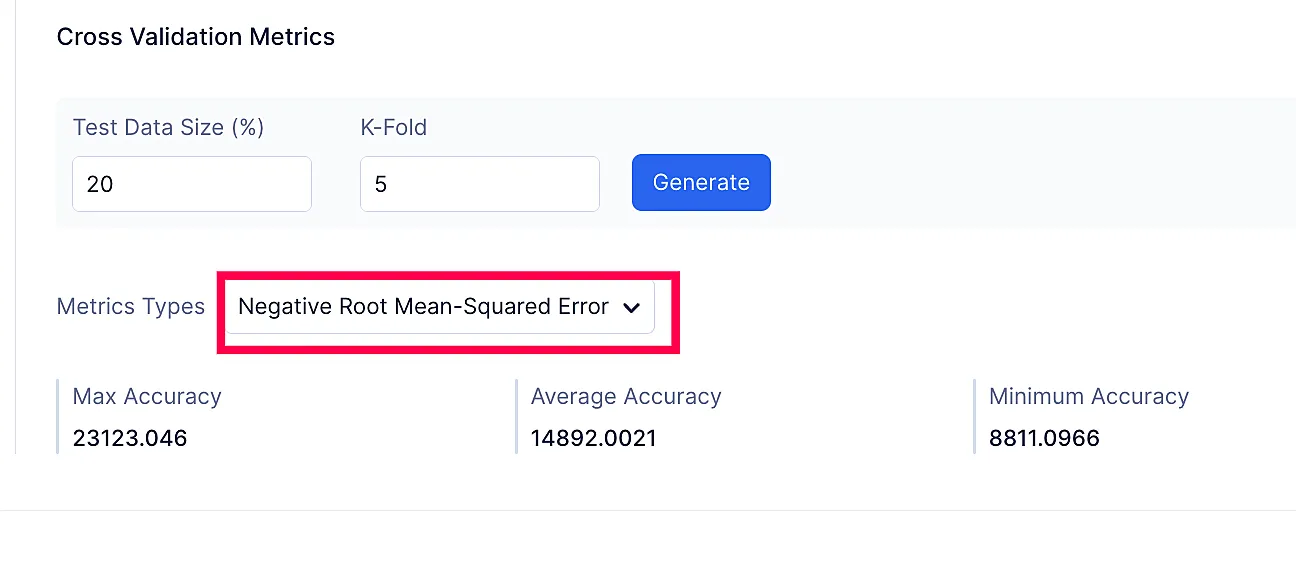
Tipos de Métricas:
- Negative mean-squared error
- Negative mean-squared log error
- Negative root mean-squared error
- Negative mean absolute error
- Negative median absolute error
- Negative mean poisson deviance
- Negative mean gamma deviance
- Negative log loss
- Negative brier score
- R2 score
Versiones del Modelo
El versionado de modelos es el proceso de rastrear y gestionar diferentes versiones de un modelo de aprendizaje automático.

Esto es importante porque te permite comparar diferentes versiones del modelo, rastrear su rendimiento y seleccionar la mejor versión para el despliegue. El versionado de modelos también puede ayudarte a revertir a una versión anterior del modelo si es necesario.
Feature Importance
Identificar la importancia de cada característica de entrada utilizada en la construcción de un modelo de aprendizaje automático puede ayudarte a rastrear cómo afectarán la calidad del modelo y su progreso en la toma de decisiones.
Se calcula una puntuación de feature importance para cuantificar la importancia; cuanto mayor sea la puntuación de una característica, mayor será el impacto de la característica en el modelo que predice la variable objetivo. Al cuantificar la importancia de cada característica, proporciona información sobre los datos y el modelo, permitiendo una mejor comprensión, interpretación y potencial mejora del rendimiento del modelo.
Feature importance se puede calcular usando varios métodos, como permutation importance o mean decrease in impurity, o usando técnicas específicas del modelo como el atributo feature importances en modelos basados en árboles.
Usos de Feature Importance
Feature importance también se utiliza para comprender la relación entre las características de entrada y las variables objetivo, similar a la correlation matrix. Las características altamente relevantes que impactan el modelo se identifican usando la puntuación de importancia.
- Reducción de dimensionalidad: Feature importance ayuda a reducir la dimensionalidad del modelo manteniendo las características con puntuaciones más altas y eliminando aquellas con puntuaciones más bajas de los datos de entrenamiento. Esta simplificación reduce el sesgo, elimina el ruido y acelera el entrenamiento del modelo, generando finalmente un modelo con mejor rendimiento.
- Rendimiento del modelo: Al enfocarse en las características más relevantes, feature importance ayuda a optimizar el modelo para un mejor rendimiento y mejorar su predictibilidad.
- Información para stakeholders: Feature importance proporciona a los stakeholders información sobre qué características tienen el mayor impacto en las predicciones del modelo y ayuda a comprender el comportamiento del modelo.
En resumen, feature importance explica la importancia de cada característica en el modelo.
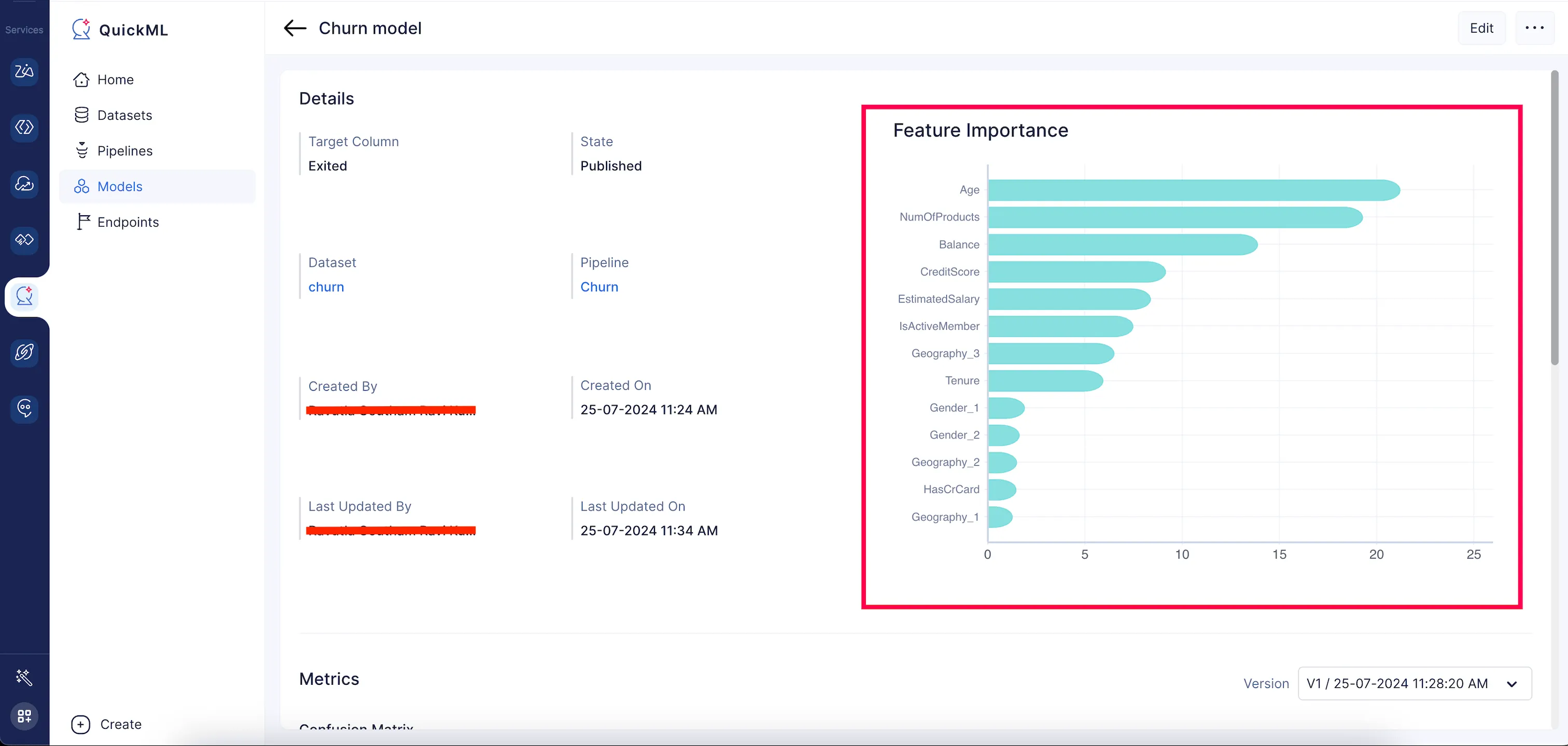
En la página de detalles del modelo de QuickML, se genera un gráfico de barras para representar visualmente la puntuación de feature importance de las 20 características principales en orden descendente, y el resto se categorizará como otros.
Última actualización 2026-03-20 21:51:56 +0530 IST
Yes
No
Send your feedback to us