Agrupamiento
Introducción
Clustering es un proceso de agrupar puntos de datos similares en grupos significativos, donde los elementos en el mismo grupo comparten características comunes mientras difieren de los elementos en otros grupos. Pertenece al dominio del aprendizaje no supervisado, una rama del aprendizaje automático que funciona sin etiquetas o resultados predefinidos. En lugar de que se le indique cuáles son los agrupamientos correctos, el algoritmo descubre estructuras ocultas dentro de los datos por sí mismo. Esto hace que el clustering sea especialmente valioso cuando se trata de conjuntos de datos grandes y desorganizados, ayudando a los usuarios a detectar patrones, descubrir agrupaciones naturales y simplificar información compleja en segmentos más comprensibles.
En su esencia, el clustering responde a la pregunta: “¿Qué puntos de datos son similares entre sí?” Se puede aplicar en dominios como segmentación de clientes, reconocimiento de imágenes, detección de anomalías y categorización de documentos, entre muchos otros.
Construyendo Intuición Detrás del Clustering
Antes de profundizar en los tipos de clustering y sus algoritmos, comencemos con una comprensión intuitiva del clustering. Imagine que tiene un conjunto de datos de espectadores de películas, donde cada espectador se describe por múltiples atributos como el número de películas vistas por género, calificación promedio otorgada y frecuencia de visualización. No sabe de antemano qué espectadores tienen gustos similares.
Al aplicar un algoritmo de clustering, a cada espectador se le asigna un cluster basado en la similitud general a través de todas las características. Al final, puede ver visualmente agrupaciones naturales de espectadores: un cluster podría contener fanáticos de películas de acción y thriller, otro podría ser entusiastas de la comedia, y un tercero podría representar espectadores que prefieren romance o drama. El algoritmo ha descubierto patrones ocultos en el comportamiento de los espectadores sin que nunca se le haya indicado qué espectadores son similares.
Criterios Clave de Éxito para el Análisis de Clustering
El clustering es inherentemente iterativo y exploratorio, requiriendo experiencia en el dominio y juicio humano. A diferencia del aprendizaje supervisado, no hay resultados etiquetados, por lo que no puede usar métricas tradicionales como precisión o RMSE para evaluar el rendimiento. Esto hace que la evaluación de modelos de clustering sea subjetiva y dependiente de los objetivos del negocio.
Los criterios clave para el éxito incluyen:
-
Interpretabilidad: ¿Puede explicar por qué los puntos fueron agrupados juntos?
-
Utilidad empresarial: ¿La salida del clustering proporciona información accionable?
-
Descubrimiento de conocimiento: ¿Ha aprendido nuevos patrones o descubierto estructuras ocultas en los datos?
El éxito en el clustering a menudo proviene de combinar la salida algorítmica con el conocimiento del dominio para refinar los clusters y extraer información significativa.
Aplicaciones Empresariales del Clustering
El clustering encuentra aplicaciones en una amplia gama de industrias, como las que se enumeran a continuación, porque ayuda a revelar agrupaciones naturales en los datos sobre las cuales las empresas pueden actuar.
Retail y Marketing
El clustering se usa ampliamente en retail y marketing para segmentar clientes en grupos, como compradores económicos, compradores estacionales o clientes premium. Estas ideas permiten a las empresas ejecutar campañas dirigidas, diseñar programas de fidelización e incluso optimizar los diseños de tiendas identificando productos que se compran frecuentemente juntos.
Comercio Electrónico y Plataformas en Línea
Las plataformas de comercio electrónico dependen en gran medida del clustering para la personalización. Al analizar los historiales de navegación y compra, los algoritmos de clustering pueden agrupar usuarios con comportamiento similar y generar recomendaciones de productos adaptadas a cada segmento. Más allá de los clientes, el clustering también ayuda a organizar vastos catálogos de productos en categorías, mientras que los patrones inusuales de navegación o reseñas pueden ser marcados como actividad sospechosa.
Finanzas y Banca
En el sector financiero, el clustering juega un papel clave en la detección de fraude al distinguir clusters de transacciones normales de outliers raros y aislados que pueden representar actividad fraudulenta. Los bancos también usan clustering para segmentar clientes basándose en patrones de gasto y niveles de ingresos, permitiéndoles diseñar tarjetas de crédito personalizadas, ofertas de préstamos o portafolios de inversión. De manera similar, los analistas usan clustering para agrupar acciones que se comportan de manera similar en el mercado, ayudando en la diversificación de portafolios.
Salud y Ciencias de la Vida
La salud y las ciencias de la vida también se benefician de las técnicas de clustering. Los registros de pacientes se pueden agrupar para identificar subtipos de enfermedades o poblaciones de alto riesgo, lo que apoya la intervención temprana y los planes de tratamiento personalizados. Los datos genéticos y clínicos, cuando se agrupan, a menudo revelan agrupaciones biológicas ocultas que aceleran el descubrimiento de medicamentos. Los hospitales también usan clustering para categorizar pacientes por costos de tratamiento, estancias hospitalarias o resultados, ayudando a mejorar la eficiencia operativa.
Telecomunicaciones y Tecnología
Las empresas de telecomunicaciones aplican clustering para comprender el comportamiento del usuario, como agrupar clientes por patrones de llamadas o uso de internet, lo que luego informa la creación de planes de datos personalizados. También se usa para detectar anomalías en el tráfico de red o para optimizar el servicio al cliente agrupando automáticamente tickets de soporte en categorías como facturación, problemas de inicio de sesión o fallos técnicos.
Cómo Funciona el Clustering
Entendamos el clustering usando el algoritmo K-Means, uno de los métodos más ampliamente utilizados.
Paso 1: Elegir el número de clusters (k)
El proceso comienza decidiendo cuántos clusters desea que el algoritmo identifique. Este número, denotado como k, se puede determinar basándose en técnicas estadísticas como el Método del Codo que ayudan a estimar un equilibrio óptimo entre precisión e interoperabilidad.
Paso 2: Inicializar centroides
A continuación, el algoritmo selecciona aleatoriamente k puntos de datos del conjunto de datos como los centroides iniciales del cluster. Estos sirven como los puntos de referencia iniciales alrededor de los cuales los clusters comenzarán a formarse. En algunos casos, se usan métodos de inicialización mejorados como K-Means++ para seleccionar mejores posiciones iniciales, lo que puede ayudar al algoritmo a converger más rápido y producir resultados más confiables.
Paso 3: Asignar puntos de datos a clusters
Una vez que los centroides se inicializan, cada punto de datos en el conjunto de datos se asigna al centroide más cercano basándose en una métrica de distancia elegida, la distancia euclidiana, que mide cuán separados están dos puntos en el espacio.
La fórmula para la distancia euclidiana entre dos puntos (x1,y1) y (x2,y2) es:
Distance = √((x1 - x2)² + (y1 - y2)²) donde (x1,y1) y (x2,y2) son las coordenadas de dos puntos.
Este paso efectivamente divide el conjunto de datos en k grupos, donde cada punto pertenece al cluster con el centroide más cercano.
Paso 4: Actualizar centroides
Después de que todos los puntos han sido asignados, el algoritmo recalcula la posición de cada centroide. Esto se hace tomando la media de todos los puntos de datos que pertenecen al mismo cluster. El nuevo valor medio se convierte en la ubicación actualizada del centroide, representando el centro de ese cluster más precisamente que antes.
Paso 5: Repetir asignación y actualización
El proceso de asignar puntos y actualizar centroides se repite iterativamente. Con cada iteración, los centroides ajustan sus posiciones ligeramente, y los puntos pueden cambiar entre clusters a medida que el algoritmo refina los límites. Este ciclo continúa hasta que las asignaciones de cluster ya no cambian significativamente o el movimiento de los centroides se vuelve mínimo.
Paso 6: Verificar la convergencia
Se dice que K-Means ha convergido cuando los centroides se estabilizan, lo que significa que dejan de moverse apreciablemente entre iteraciones. Alternativamente, el proceso puede detenerse cuando se alcanza un número máximo predefinido de iteraciones. En esta etapa, el algoritmo considera que el proceso de clustering está completo.
Paso 7: Generar la salida final
En el paso final, a cada punto de datos se le asigna una etiqueta de cluster (como 0, 1, 2, …, k–1) correspondiente al grupo al que pertenece. Las coordenadas finales de los centroides representan los centros de estos clusters. Estos resultados se pueden usar para casos de uso en tiempo real como segmentación de clientes.
Ejemplo
Apliquemos estos pasos a un ejemplo de segmentación de clientes para una mejor comprensión.
Imagine que administra una tienda en línea y tiene un conjunto de datos de clientes con múltiples atributos, como gasto mensual, número de compras, preferencias de productos y más. No sabe de antemano qué clientes se comportan de manera similar.
Después de aplicar un algoritmo de clustering, como K-Means, a cada cliente se le asigna un cluster basado en la similitud general a través de todas las características. Para visualizar los resultados, los datos se reducen a dos componentes: Componente 1 y Componente 2.
Cada cliente se convierte en un punto en un gráfico de dispersión 2D:
- Eje X: Componente 1
- Eje Y: Componente 2
Los puntos están codificados por colores según su cluster. Esta visualización facilita ver las agrupaciones naturales de clientes.
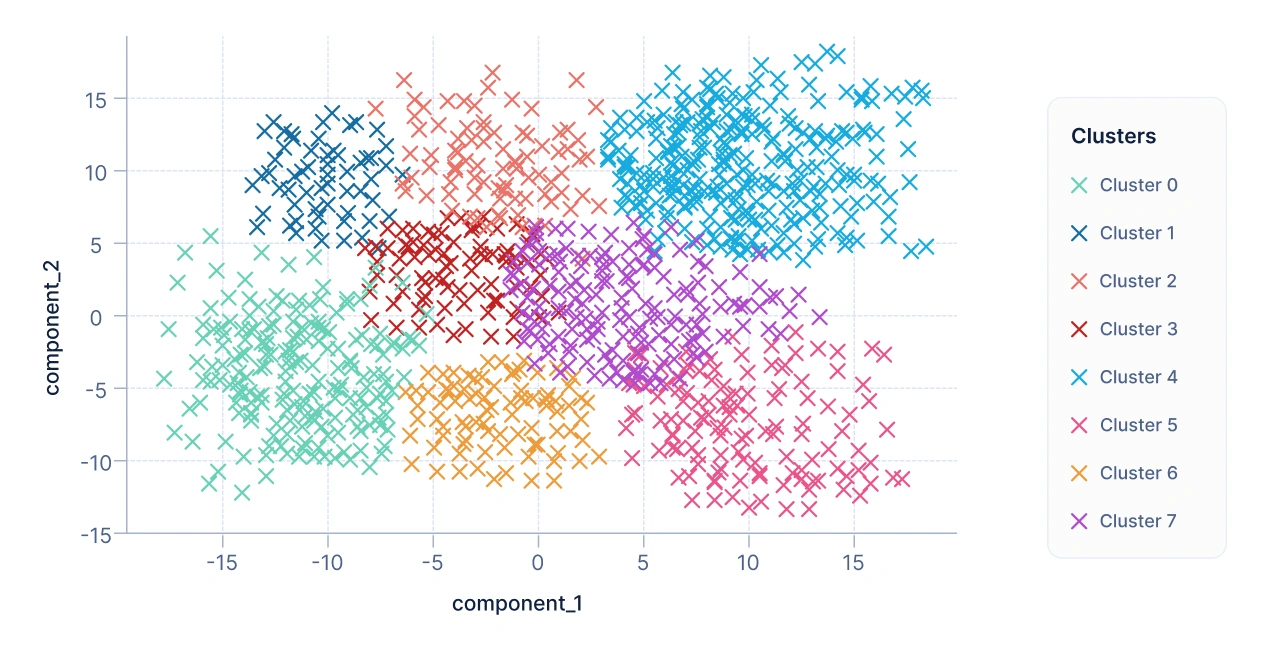
Del gráfico anterior, podemos concluir que cada cluster formado representa un grupo de clientes con atributos e intereses similares. Y el negocio puede dirigirse a estos segmentos de clientes para aumentar los ingresos y las ganancias.
K-Means es un algoritmo que pertenece al clustering basado en centroides. QuickML también admite varios algoritmos que pertenecen a diferentes tipos de clustering. Veamos los tipos de clustering.
Tipos de Clustering
Los métodos de clustering se pueden clasificar ampliamente en cuatro tipos principales, cada uno con su propio enfoque y aplicaciones.
1. Clustering basado en centroides: Se basa en un punto central, o centroide, para representar cada cluster. Los puntos de datos se asignan al cluster cuyo centroide está más cerca, con clusters formados minimizando la distancia entre los puntos de datos y estos centroides. Un ejemplo común es la segmentación de clientes, donde los compradores se agrupan en categorías como económico, rango medio o premium basándose en su gasto mensual promedio.
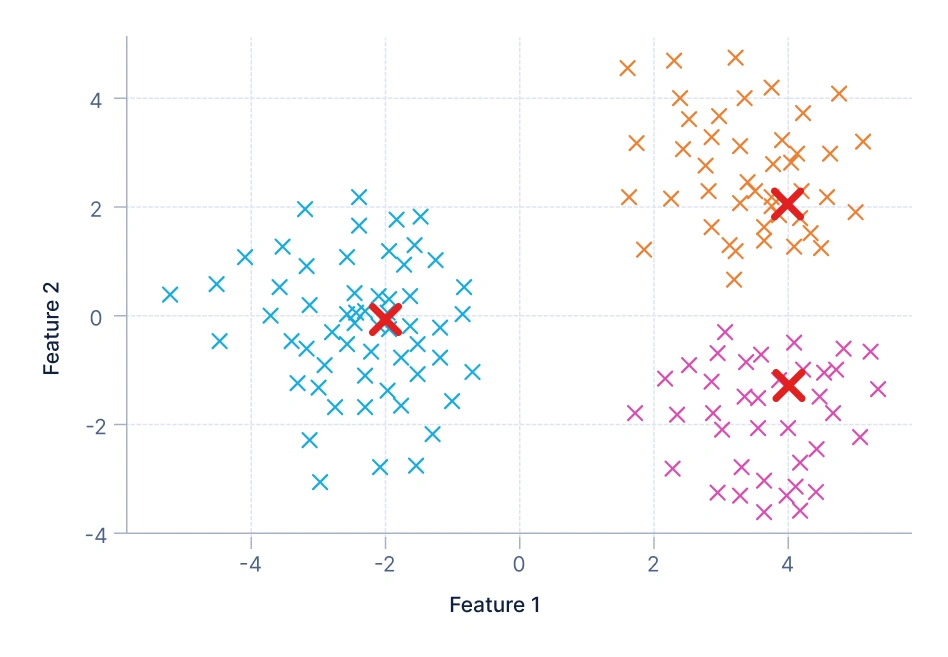
En esta visualización, los puntos de datos están agrupados alrededor de centroides — los marcadores rojos X representan estos centroides. Cada color indica un cluster distinto, y cada punto pertenece al cluster cuyo centroide está más cerca. El objetivo es minimizar la distancia total entre los puntos y sus centroides asignados. Este método asume que los clusters son aproximadamente esféricos e igualmente dimensionados, lo que funciona bien para distribuciones de datos simples y bien separadas. Algoritmos como K-Means y MiniBatchKMeans son ejemplos de clustering basado en centroides.
2. Clustering basado en medoides: Es similar al de centroides pero en lugar de usar centroides calculados, elige puntos de datos reales, llamados medoides, como representantes del cluster. Esto hace que el enfoque sea más robusto al ruido y los outliers, ya que los clusters están anclados en observaciones reales. Por ejemplo, las empresas de telecomunicaciones pueden usar clustering basado en medoides para agrupar usuarios seleccionando perfiles de clientes representativos reales a partir de datos de comportamiento de llamadas.
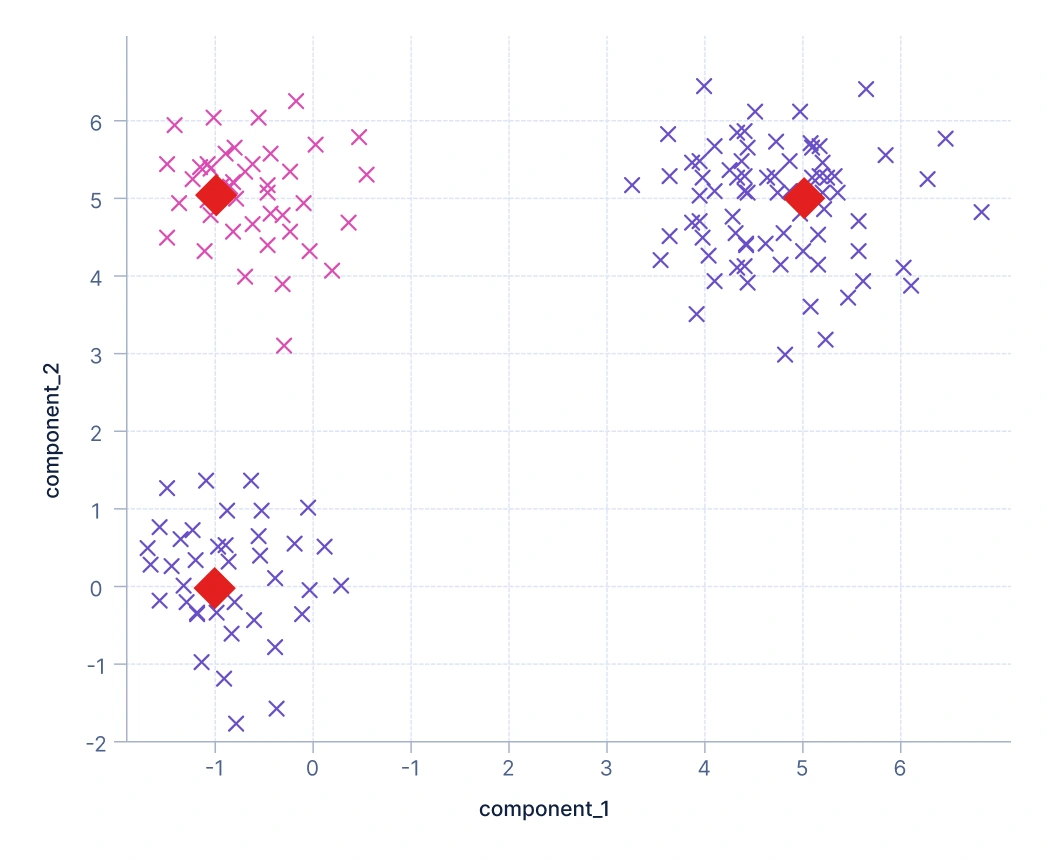
Aquí, los clusters están representados por medoides — puntos de datos reales mostrados como marcadores de diamante rojos. A diferencia de los centroides (que son promedios), los medoides son observaciones reales del conjunto de datos que minimizan la disimilitud total con otros puntos en su cluster. Esto hace que el enfoque sea más robusto al ruido y los outliers ya que los valores extremos tienen menos influencia en los centros del cluster. El gráfico muestra cómo los clusters se forman alrededor de puntos de datos representativos. Algoritmos como K-Medoids, CLARA y CLARANS siguen este principio.
3. Clustering basado en densidad: Toma un camino diferente identificando regiones densas de puntos de datos y tratándolas como clusters, mientras que las áreas de baja densidad actúan como separadores. Una de sus fortalezas es la detección natural de outliers, ya que los puntos que no pertenecen a ninguna región densa se marcan como ruido. Una aplicación típica es la detección de fraude financiero, donde las regiones densas corresponden al comportamiento normal de gasto y los puntos dispersos o aislados indican transacciones sospechosas.
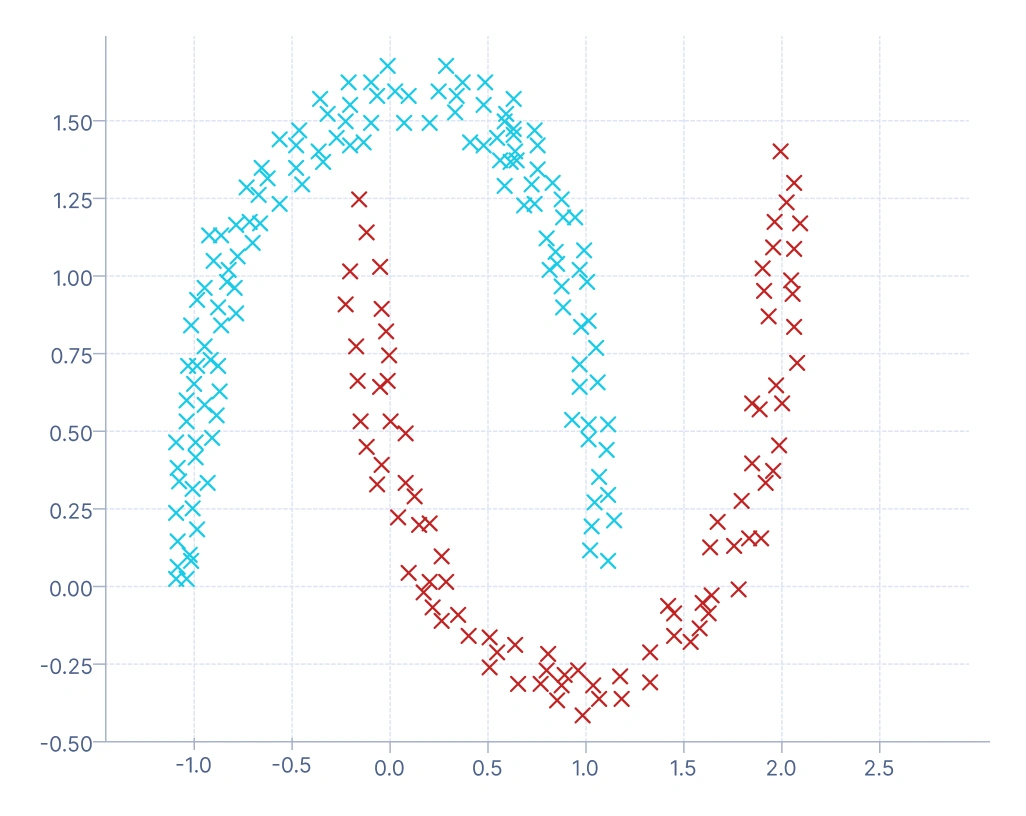
En este gráfico, los clusters se forman basándose en regiones de alta densidad de datos. El algoritmo agrupa puntos que están cerca entre sí y etiqueta los puntos en regiones de baja densidad como ruido (a menudo marcados en un color diferente, como -1 en DBSCAN). Puede ver que este enfoque captura formas de cluster complejas y no esféricas (como el patrón curvado de “dos lunas”), con las que los métodos basados en centroides o medoides tienen dificultades. Es ideal para conjuntos de datos con límites irregulares o cuando detectar outliers es importante — por ejemplo, en la detección de fraude o anomalías.
4. Clustering basado en modelos: Asume que los datos se generan a partir de una mezcla de distribuciones de probabilidad subyacentes, y asigna probabilidades de membresía al cluster en lugar de etiquetas duras (cada punto de datos se asigna a exactamente un cluster, como en K-Means). Este marco probabilístico lo hace especialmente útil en dominios complejos como el reconocimiento de voz, donde los patrones de sonido superpuestos se pueden modelar como una mezcla de distribuciones gaussianas.
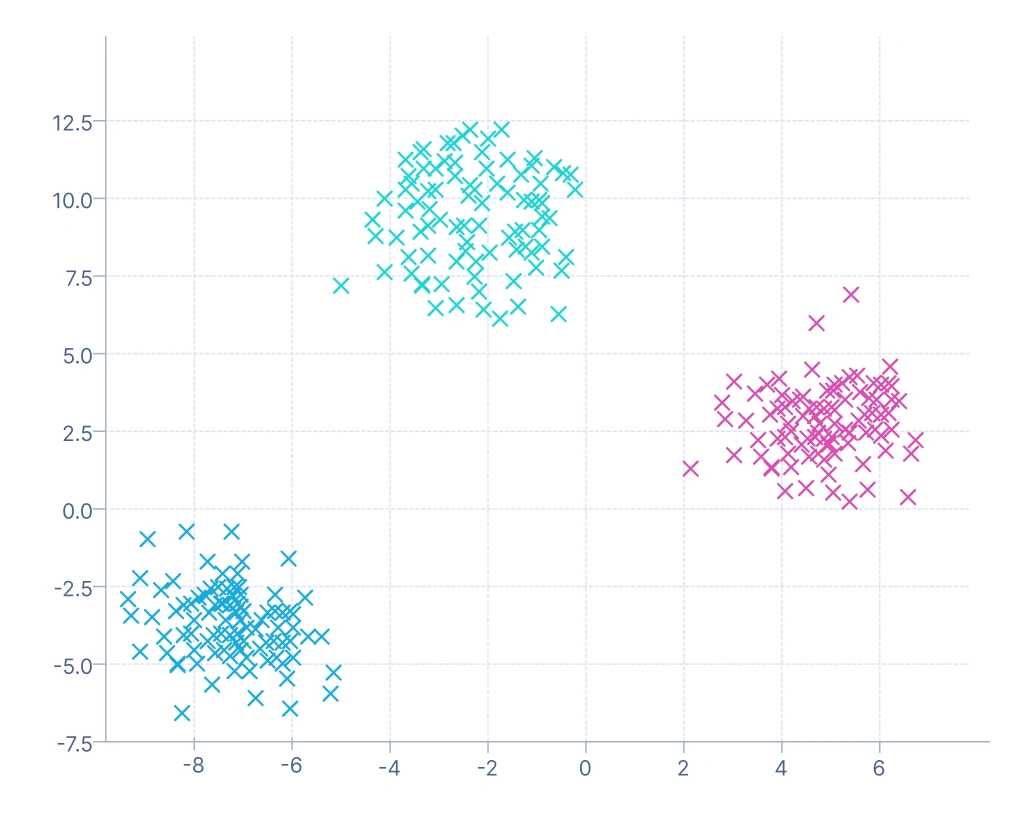
Esta visualización muestra clusters formados al modelar los datos como una mezcla de distribuciones gaussianas. Cada cluster corresponde a un componente gaussiano, y los puntos de datos tienen membresía probabilística — lo que significa que un punto puede pertenecer parcialmente a múltiples clusters. Los colores indican la asignación de cluster más probable para cada punto. Este método maneja mejor los clusters superpuestos y elípticos que K-Means, haciéndolo adecuado para distribuciones de datos más complejas y continuas.
Pasos para Construir un Pipeline de Clustering en QuickML
La construcción de un pipeline de clustering en QuickML usa Classic Builder, que asegura la identificación precisa de clusters e información accionable.
Paso 1: Ingesta de datos
El proceso comienza con la carga del conjunto de datos en QuickML, que sirve como base para el flujo de trabajo de clustering. Este paso implica importar datos de varias fuentes como archivos CSV, bases de datos o sistemas de almacenamiento en la nube.
Paso 2: Preprocesamiento de datos
Una vez que los datos se ingestan, pasan por una fase de preprocesamiento para asegurar calidad y consistencia. Este paso incluye el manejo de valores faltantes a través de técnicas como imputación o eliminación, codificación de variables categóricas usando métodos como codificación de etiquetas o one-hot, y aplicación de técnicas de transformación de datos para mejorar la calidad de los datos y el rendimiento del modelo. Un preprocesamiento efectivo reduce el sesgo y mejora la precisión del clustering al asegurar que los algoritmos basados en distancia traten todas las características de manera justa.
Paso 3: Selección de algoritmo
Después del preprocesamiento, QuickML permite a los usuarios seleccionar un algoritmo de clustering apropiado basado en las características de los datos y el resultado deseado. Algoritmos como K-Means, DBSCAN, BIRCH o Gaussian Mixture Models (GMM) se pueden aplicar dependiendo de si el conjunto de datos tiene estructuras de cluster bien separadas, basadas en densidad o probabilísticas. La selección del algoritmo correcto es crucial, ya que diferentes métodos capturan diferentes tipos de relaciones y estructuras dentro de los datos.
Paso 4: Entrenamiento del modelo
En este paso, el algoritmo seleccionado se aplica a los datos procesados para identificar agrupaciones naturales. El modelo aprende iterativamente asignando puntos de datos similares al mismo cluster basándose en la medida de similitud o distancia definida. Los parámetros clave, como el número de clusters en K-Means o el valor epsilon en DBSCAN, se ajustan para producir resultados significativos y estables. El resultado de esta fase es la identificación de clusters de datos distintos que revelan patrones y estructuras ocultos dentro del conjunto de datos.
Paso 5: Evaluación de clusters
Después de que los clusters se forman, QuickML evalúa su calidad y validez usando varias métricas estadísticas. Las métricas comúnmente utilizadas incluyen el Silhouette Score, que mide qué tan bien cada punto de datos encaja dentro de su cluster; el Calinski-Harabasz Score, que evalúa la compacidad y separación del cluster; y el Davies-Bouldin Score, que evalúa la similitud promedio del cluster. Estas métricas de evaluación ayudan a determinar si los resultados del clustering son tanto interpretables como confiables para aplicaciones prácticas.
Métricas de Evaluación de Clustering
Las métricas de evaluación mencionadas a continuación proporcionan colectivamente información sobre diferentes aspectos del rendimiento del modelo de clustering, como qué tan bien están separados los grupos, qué tan compactos son y si los clusters revelan similitudes significativas en los datos, en lugar de agrupaciones arbitrarias. A diferencia del aprendizaje supervisado, el clustering no tiene etiquetas predefinidas, por lo que estas métricas actúan como medidas guía para juzgar la calidad de los clusters.
Exploremos e interpretemos las métricas comúnmente utilizadas para evaluar modelos de clustering en QuickML:
1. Silhouette Score
Qué le dice: Mide qué tan similar es un punto de datos a su propio cluster en comparación con otros clusters.
Intuición:
- El silhouette score varía de -1 a +1.
- Una puntuación alta (cercana a +1) indica que los puntos de datos están bien agrupados, con agrupación compacta y separación clara de otros clusters.
- Una puntuación cercana a 0 sugiere clusters superpuestos o puntos que se encuentran en el límite entre clusters.
- Una puntuación negativa (cercana a -1) indica un clustering deficiente donde los puntos pueden estar asignados al cluster incorrecto o los clusters se superponen significativamente.
Ejemplo de Inferencia: Si el silhouette score es 0.52, significa que los clusters están razonablemente bien formados y separados, pero todavía hay alguna superposición entre los puntos de datos.
2. Calinski-Harabasz Score
Qué le dice: Esta puntuación compara cuán separados están los clusters (dispersión entre clusters) con cuán compactos son los puntos dentro de cada cluster (dispersión dentro del cluster).
Intuición:
- La puntuación es ilimitada y varía de -∞ a +∞ (mayor es mejor).
- Una puntuación más alta indica que los clusters son compactos dentro de sí mismos y están bien separados de los demás.
- Una puntuación más baja sugiere que los clusters están dispersos internamente o no están claramente separados.
Ejemplo de Inferencia: Si el Calinski-Harabasz score es 950, sugiere que los clusters son relativamente densos y claramente particionados, mostrando una buena estructura de separación.
3. Davies-Bouldin Score
Qué le dice: Mide la similitud promedio entre clusters, basándose en la relación de la distancia intra-cluster a la separación inter-cluster.
Intuición:
- La puntuación varía de -∞ a +∞ (menor es mejor).
- Una puntuación más baja significa que los clusters son más distintos y tienen menos superposición.
- Una puntuación más alta sugiere similitud significativa entre clusters, lo que implica una separación deficiente.
Ejemplo de Inferencia: Si el Davies-Bouldin score es 0.60, indica que los clusters están razonablemente bien separados, pero no perfectamente distintos — todavía existe alguna superposición.
4. Número de Clusters
Indica cuántos grupos distintos el algoritmo ha identificado en el conjunto de datos.
Ejemplo de Inferencia: Si el modelo produce 3 clusters, sugiere que el conjunto de datos se puede dividir significativamente en tres grupos distintos, por ejemplo, tres tipos de segmentos de clientes: compradores económicos, de rango medio y premium.
Evaluación Visual de Clusters
Además de las puntuaciones numéricas, la evaluación de clusters también se puede hacer a través de visualización en QuickML. La distribución de clusters y los gráficos de clusters dan una sensación intuitiva de equilibrio, separación y estructura dentro de los datos.
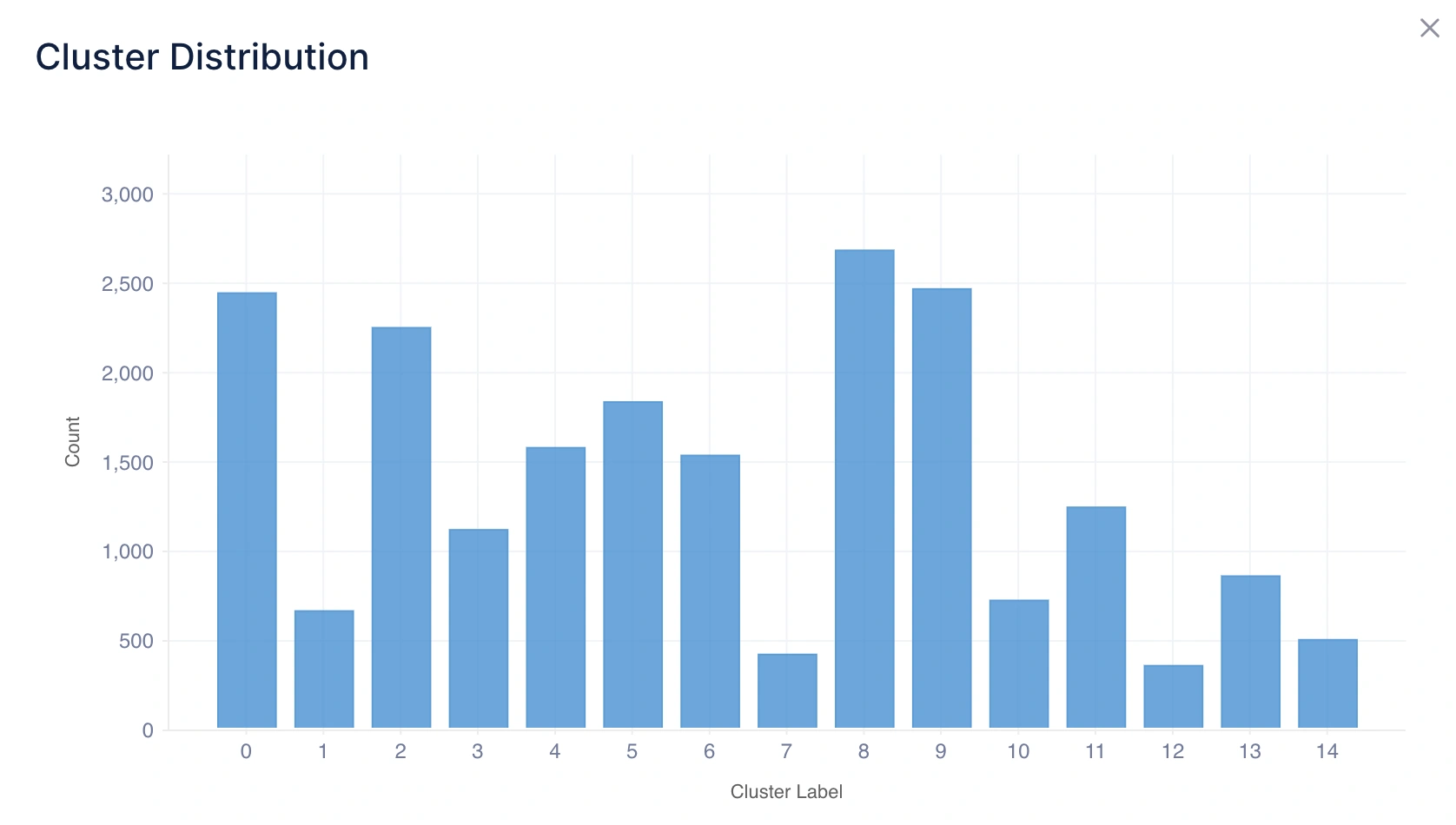
1. Distribución de Clusters
Qué le dice: Esto muestra cuántos puntos de datos caen en cada cluster usando un gráfico de histograma.
Intuición:
- Una distribución equilibrada significa que los clusters son relativamente uniformes en tamaño, lo que a menudo indica una agrupación natural.
- Una distribución desequilibrada significa que uno o más clusters dominan en tamaño, lo que puede sugerir ya sea un dominio del mundo real (por ejemplo, la mayoría de los clientes pertenecen a un segmento) o una limitación del método de clustering.
Ejemplo de Inferencia: Si el Cluster 0 tiene 600 puntos, el Cluster 1 tiene 150 puntos y el Cluster 2 tiene 30 puntos, sugiere que la mayoría de los puntos de datos pertenecen al Cluster 0, mientras que los Clusters 1 y 2 representan grupos más pequeños y de nicho.
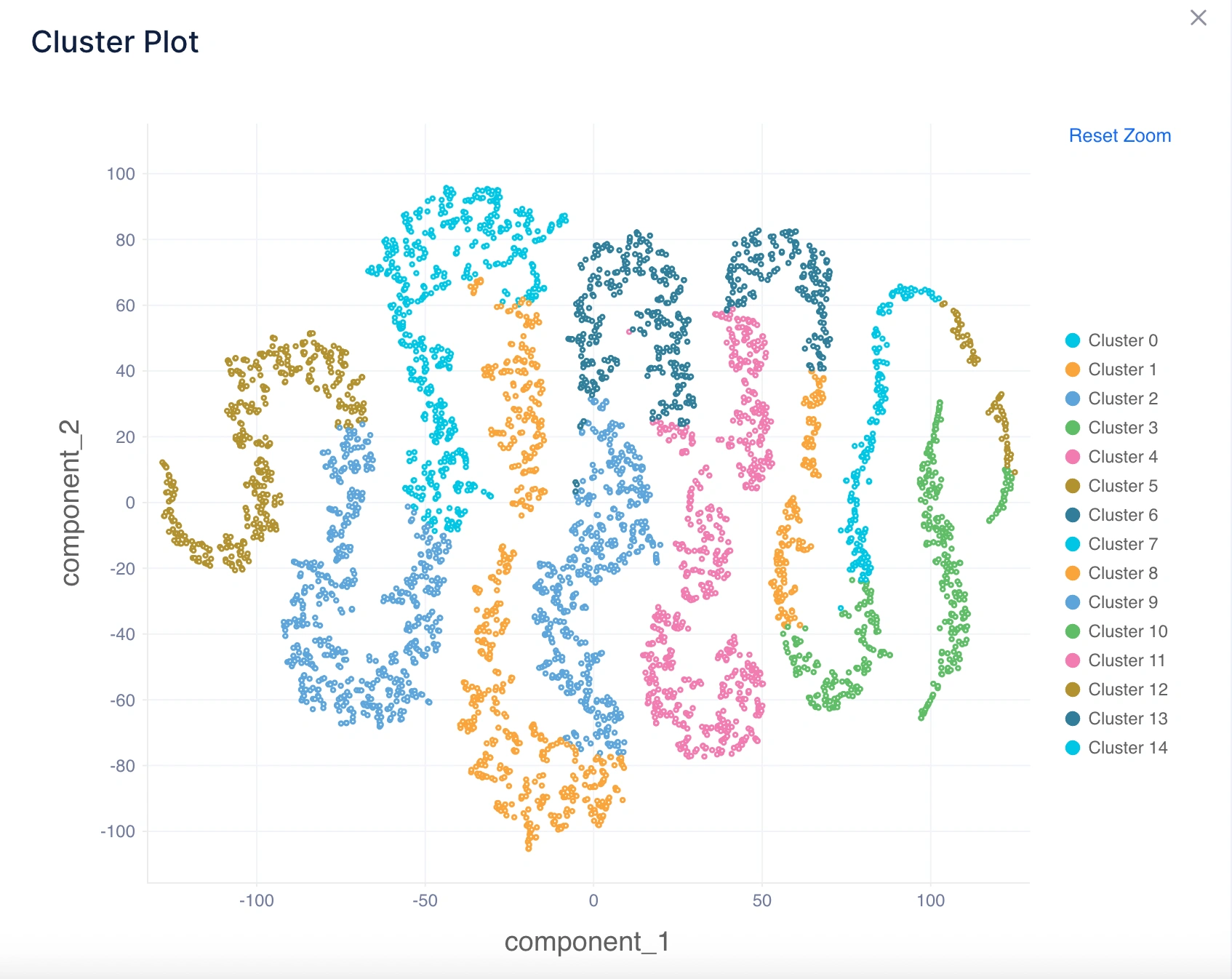
2. Gráfico de Clusters
Qué le dice: Visualiza cómo los clusters están separados en un espacio de menor dimensión usando un gráfico de dispersión (generalmente usando PCA o t-SNE para reducción de dimensionalidad).
Intuición:
- Clusters bien separados en el gráfico indican un buen rendimiento del algoritmo de clustering.
- Clusters superpuestos sugieren ambigüedad en las asignaciones, lo que significa que el algoritmo encontró difícil separar claramente los grupos.
Ejemplo de Inferencia: Si el gráfico muestra grupos claramente visibles con límites distintos, confirma que el algoritmo ha identificado clusters significativos. Si los grupos se superponen mucho, sugiere la necesidad de probar un algoritmo diferente (por ejemplo, DBSCAN para formas irregulares).
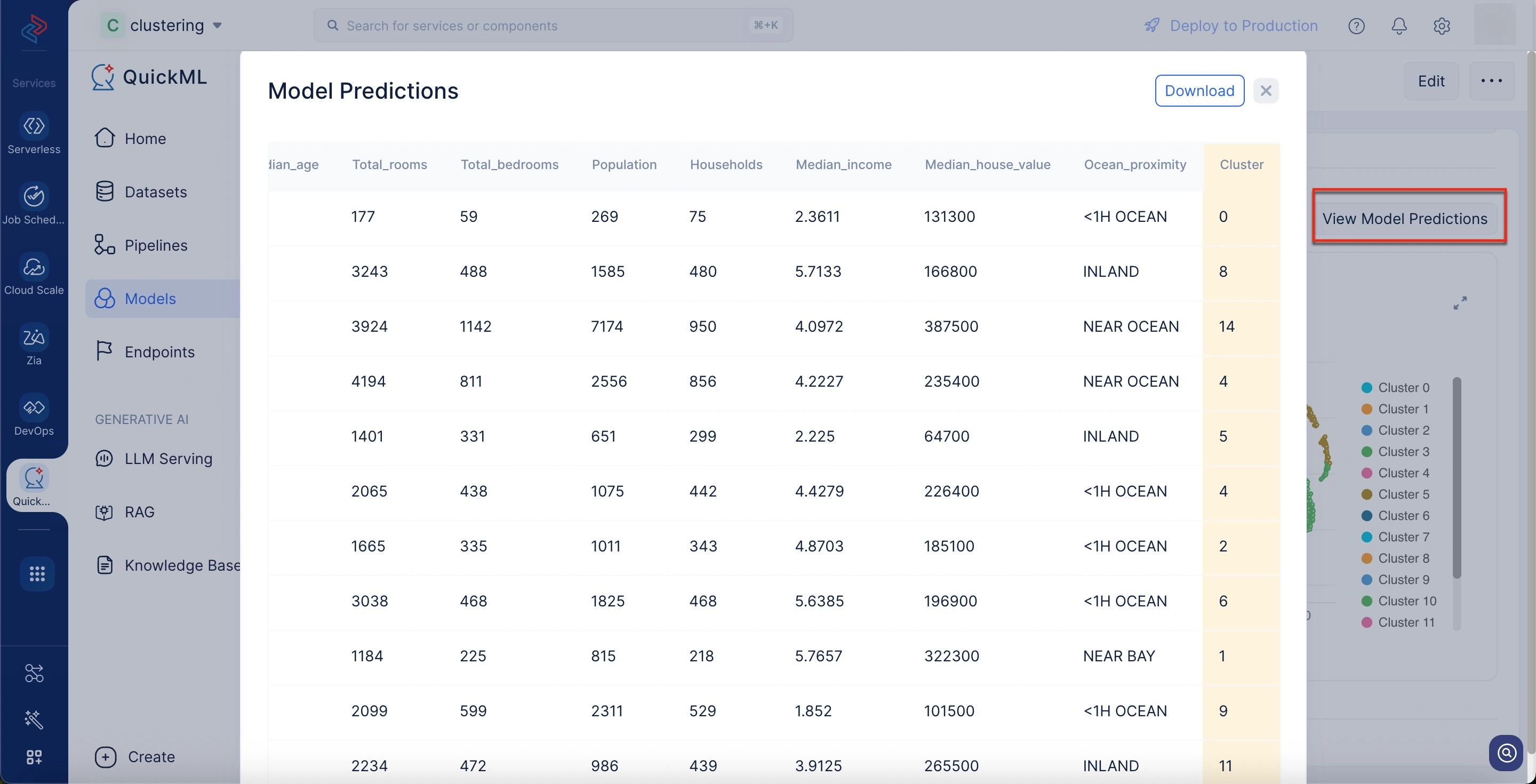
3. Descargar Predicciones del Modelo
Qué le dice: Esto le permite exportar los resultados de clustering del modelo para todo el conjunto de datos. Cada punto de datos se etiqueta con el cluster al que pertenece.
Beneficios:
- Proporciona un mapeo directo de puntos de datos a clusters, facilitando el análisis de asignaciones individuales fuera de QuickML.
- Permite análisis posterior adicional, como perfilado de clusters, referencias cruzadas con datos externos o realización de acciones dirigidas (por ejemplo, marketing a un segmento específico de clientes).
- Esto ofrece transparencia y trazabilidad ya que puede ver exactamente qué puntos de datos fueron asignados a qué cluster, lo cual es útil para validación y reportes.
Para descargar predicciones del modelo
- Navegue a la página de detalles del modelo deseado.
- Desplácese hacia abajo hasta la sección Visualizations.
- Haga clic en el botón View Model Predictions arriba del gráfico de clusters.
Aparece una ventana emergente de Model Predictions desde la cual puede descargar las predicciones.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us