Detección de Anomalías
Introducción
La detección de anomalías es el proceso de identificar puntos de datos, eventos o patrones que se desvían significativamente del comportamiento esperado en un conjunto de datos. Estas observaciones inusuales, también llamadas outliers, pueden indicar situaciones críticas como fraude, mal funcionamiento de equipos, amenazas de ciberseguridad o cambios inesperados en el comportamiento del consumidor.
En QuickML, utilizamos ampliamente algoritmos de aprendizaje no supervisado para la detección de anomalías, donde los algoritmos aprenden patrones de normalidad sin depender de etiquetas predefinidas. En lugar de que se le indique explícitamente qué constituye una anomalía, el algoritmo construye una comprensión del comportamiento normal y resalta los puntos de datos que no caen dentro del rango esperado habitual. Esto hace que la detección de anomalías sea especialmente valiosa cuando las anomalías son raras, las etiquetas no están disponibles o los patrones normales son altamente dinámicos.
Imagine un conjunto de datos de transacciones de tarjetas de crédito. La mayoría de las transacciones siguen un patrón típico en términos de monto, frecuencia y ubicación. Sin embargo, una compra repentina de alto valor en un país extranjero podría marcarse como una anomalía. Detectar esta anomalía en tiempo real puede prevenir el fraude, proteger a los clientes y ahorrar costos para las instituciones financieras.
Impacto Empresarial de la Detección de Anomalías
La detección de anomalías es un proceso crítico para el negocio que permite a las organizaciones proteger activos, mejorar operaciones y optimizar la toma de decisiones. A continuación se presentan algunas razones clave por las que la detección de anomalías es esencial en todas las industrias:
-
Detección de fraude: En finanzas y comercio electrónico, las anomalías a menudo corresponden a actividades fraudulentas. Por ejemplo, una compra de valor inusualmente alto realizada desde una ubicación extranjera, cuando se compara con el comportamiento de gasto habitual de un cliente, podría ser una señal temprana de fraude con tarjeta de crédito. Identificar estos patrones en tiempo real previene pérdidas financieras y protege la confianza del cliente.
-
Mantenimiento predictivo: En entornos de manufactura e industriales, las máquinas generan continuamente datos de sensores. Detectar anomalías en las lecturas de vibración, temperatura o presión puede indicar señales tempranas de desgaste mecánico o fallo. Predecir y abordar estas anomalías antes de que conduzcan a averías reduce significativamente el tiempo de inactividad y los costos de mantenimiento.
-
Ciberseguridad y protección de redes: La detección de anomalías ayuda a identificar irregularidades en registros del sistema, tráfico de red o actividad de usuarios que pueden indicar un ciberataque, violación de datos o acceso no autorizado. Por ejemplo, un aumento repentino en intentos de inicio de sesión o volumen de transferencia de datos puede revelar amenazas de seguridad que requieren atención inmediata.
-
Salud y ciencias de la vida: En el sector de salud, la detección de anomalías puede monitorear signos vitales de pacientes, resultados de laboratorio o datos de imágenes médicas para señalar riesgos potenciales de salud. Por ejemplo, una caída repentina en la saturación de oxígeno o un patrón irregular de latidos cardíacos puede alertar a los médicos para intervenir antes de que la condición se vuelva crítica.
-
Información operativa y soporte a decisiones: Las organizaciones pueden usar la detección de anomalías para descubrir información oculta que mejore la eficiencia y apoye la toma de decisiones. Por ejemplo, picos inusuales en el tráfico del sitio web pueden revelar el éxito de una campaña de marketing o intereses inesperados de los clientes.
¿Qué Causa las Anomalías en los Datos?
Las anomalías en los datos pueden surgir de una variedad de causas subyacentes, que a menudo dependen de la naturaleza de los datos y el entorno en el que se recopilan. Los principales factores contribuyentes incluyen:
-
Error humano: Los errores de entrada manual de datos, el etiquetado incorrecto o la configuración inadecuada de los sistemas pueden introducir fácilmente irregularidades. Por ejemplo, un punto decimal mal colocado o un formato de fecha incorrecto puede distorsionar significativamente los resultados del análisis. Incluso descuidos simples, como olvidar actualizar un registro o duplicar entradas, pueden llevar a puntos de datos anómalos.
-
Fallos del sistema: Los mal funcionamientos de hardware, los errores de software o las interrupciones de comunicación entre sistemas pueden corromper o distorsionar los datos. Por ejemplo, una interrupción temporal de la red durante la transmisión de datos podría resultar en entradas incompletas o duplicadas, mientras que un error de software podría generar valores inesperados o inconsistencias.
-
Actividad fraudulenta o maliciosa: En áreas como finanzas, ciberseguridad o comercio electrónico, las anomalías a menudo señalan posible fraude o acceso no autorizado. Las transacciones de valor anormalmente alto, los patrones de inicio de sesión inusuales o los cambios repentinos en el comportamiento del usuario pueden indicar intentos deliberados de explotar o manipular el sistema.
-
Cambios ambientales o externos: Los cambios inesperados en las condiciones externas, como fluctuaciones económicas, volatilidad del mercado o cambios estacionales, pueden alterar los patrones normales de datos. Estos eventos introducen nuevas variables que causan desviaciones temporales o permanentes de las tendencias establecidas.
Tipos de Detección de Anomalías
Las anomalías se pueden categorizar en varios tipos dependiendo de la naturaleza y el contexto de los datos. Las siguientes secciones explican cada tipo en detalle con la correspondiente visualización y ejemplos conceptuales.
- Anomalías puntuales
Una anomalía puntual ocurre cuando una sola observación se desvía significativamente del resto de los datos. Estas son las anomalías más comunes y típicamente son fáciles de detectar.
Por ejemplo, en un conjunto de datos de transacciones de tarjetas de crédito, una transacción repentina de alto valor puede ser marcada como una anomalía puntual si no se alinea con el comportamiento de gasto previo del usuario.
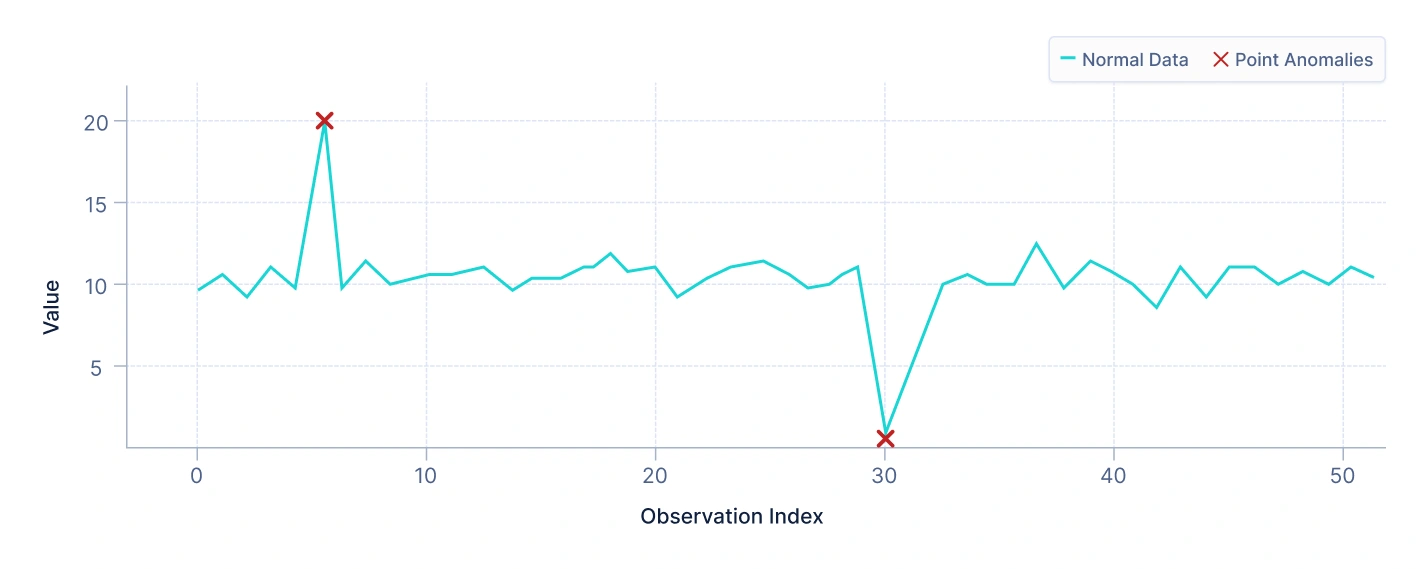
Interpretación: El gráfico anterior ilustra cómo algunos puntos de datos se encuentran lejos del grupo principal de datos. Estos puntos de datos aislados son ejemplos claros de anomalías puntuales porque difieren sustancialmente de la mayoría de los puntos de datos normales.
- Anomalías contextuales
Una anomalía contextual es una observación que se considera anómala solo dentro de un contexto específico. Este tipo de anomalía es especialmente común en conjuntos de datos donde el mismo valor puede ser normal bajo ciertas condiciones pero anormal bajo otras.
Por ejemplo, una lectura de temperatura de 10°C puede ser normal en invierno pero sería una anomalía en verano. De manera similar, una tienda en línea puede ver un alto número de compras durante las ventas de temporada festiva, pero el mismo número en un día ordinario podría señalar actividad sospechosa.
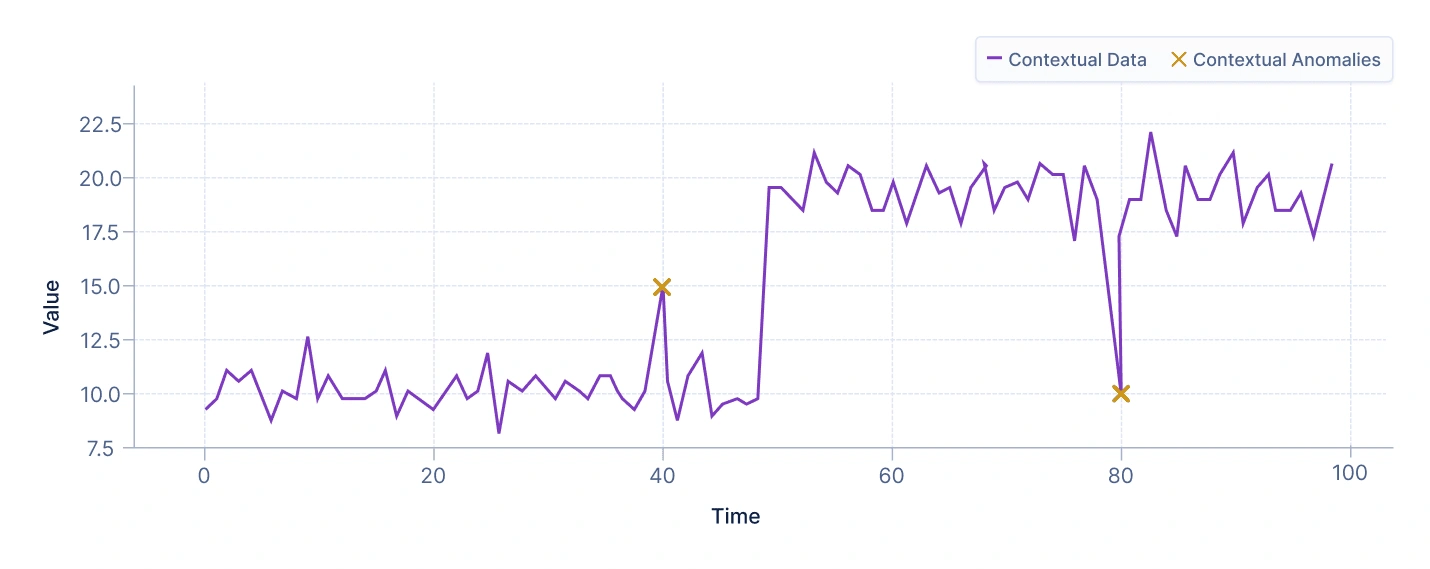
Interpretación: El gráfico ilustra dos contextos distintos, cada uno representado por un grupo separado de puntos de datos. Estos grupos reflejan diferentes patrones o entornos en los que los datos se comportan normalmente. El punto resaltado se encuentra cerca de uno de los grupos, pareciendo normal cuando se compara con el conjunto de datos general o cuando se evalúa en el contexto del otro grupo. Sin embargo, dentro de su propio grupo (cuando se analiza en relación con las características específicas y la distribución de puntos en su contexto local), el punto destaca como inusual. Esta situación resalta una anomalía contextual, donde una observación se considera anómala solo dentro de un contexto particular o bajo condiciones específicas, aunque pueda parecer normal en un contexto más amplio o diferente.
- Anomalías colectivas
Una anomalía colectiva surge cuando un grupo de puntos de datos relacionados juntos se comportan de manera inusual, incluso si los puntos individuales parecen normales.
Por ejemplo, en datos del mercado de valores, una caída consistente en el precio de las acciones de una empresa durante varios días consecutivos podría representar una anomalía colectiva, especialmente si este patrón se desvía de las fluctuaciones normales.
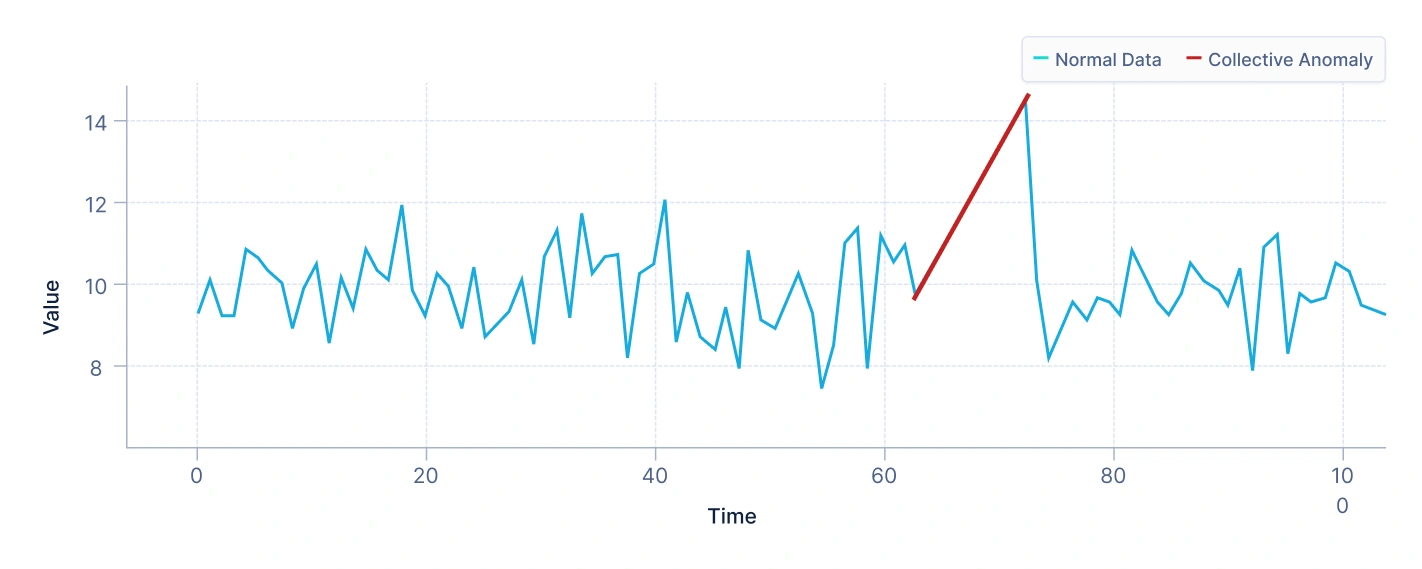
Interpretación: El gráfico anterior muestra un pequeño grupo de puntos que forman un grupo distinto separado de la mayoría de los datos. Si bien cada punto individual dentro de este grupo puede parecer normal cuando se evalúa por sí solo, su comportamiento colectivo revela un patrón que se desvía significativamente de la distribución general. Esto indica la presencia de una anomalía colectiva, donde la anomalía no surge de puntos de datos individuales, sino de su relación entre sí y con el resto del conjunto de datos.
Categorías de Detección de Anomalías
En QuickML, hay dos categorías amplias de detección de anomalías: Detección de anomalías en series temporales y Detección de anomalías en no series temporales. Cada uno de estos enfoques se centra en identificar outliers en diferentes tipos de conjuntos de datos, dependiendo de si el tiempo juega un papel en la estructura de los datos.
Aquí hay una tabla comparativa que muestra la diferencia entre la Detección de Anomalías en Series Temporales y No Series Temporales:
| Característica | Detección de Anomalías en Series Temporales | Detección de Anomalías en No Series Temporales |
|---|---|---|
| Estructura de Datos | Los puntos de datos están indexados por tiempo y siguen un orden secuencial. | Los puntos de datos no están indexados por tiempo y se tratan como observaciones independientes. |
| Dependencia Temporal | Requiere algoritmos que tengan en cuenta las dependencias temporales, tendencias y estacionalidad. | Asume que los puntos de datos son independientes sin relación temporal. |
| Método de Detección | Las anomalías se detectan comparando valores reales contra patrones históricos o pronósticos. | Las anomalías se detectan evaluando la similitud o distancia entre puntos de datos en el espacio de características. |
| Factores Influyentes | Influenciado por la estacionalidad, tendencias y dependencias a largo plazo en el tiempo. | Influenciado por las relaciones entre características y la distribución de datos a través de múltiples variables. |
| Algoritmos Comunes | ARIMA, LSTM Autoencoders, Prophet, Isolation Forest (basado en tiempo). | Isolation Forest, One-Class SVM, DBSCAN, LOF. |
| Casos de Uso de Ejemplo | Monitoreo de precios de acciones, lecturas de sensores de máquinas, rendimiento de red a lo largo del tiempo. | Detección de transacciones fraudulentas, productos defectuosos o comportamiento anormal de clientes. |
| Enfoque Clave | Se centra en desviaciones de patrones a lo largo del tiempo. | Se centra en outliers basados en características sin considerar el tiempo. |
Ahora que entendemos las diferencias clave entre la detección de anomalías en series temporales y no series temporales, exploremos cada uno de estos enfoques en profundidad para obtener una comprensión más clara y completa.
Detección de Anomalías en Series Temporales
La detección de anomalías en series temporales trata con datos que se recopilan y organizan de manera secuencial, donde cada punto de datos está asociado con una marca de tiempo específica. Este tipo de datos refleja cómo los valores cambian a lo largo del tiempo, como precios de acciones, métricas de rendimiento de servidores, lecturas de sensores o tráfico de sitios web. Debido a que el tiempo es una parte inherente del conjunto de datos, detectar anomalías implica analizar patrones temporales como tendencias, estacionalidad y desviaciones repentinas.
En la detección de anomalías en series temporales, el objetivo es identificar momentos en los que el comportamiento de un sistema cambia inesperadamente en comparación con su patrón histórico. Estas anomalías pueden aparecer como picos repentinos, caídas bruscas o fluctuaciones irregulares que rompen el ritmo habitual de los datos.
Los métodos de detección de anomalías en series temporales a menudo usan modelos de pronóstico que aprenden de tendencias pasadas para predecir valores futuros esperados. Si la observación real se desvía significativamente del valor predicho, el sistema lo marca como una anomalía.
Construyendo Intuición Detrás de la Detección de Anomalías en Series Temporales
En conjuntos de datos de series temporales, las observaciones están ordenadas en el tiempo, lo que significa que cada punto de datos puede depender de valores anteriores. Detectar anomalías implica comprender patrones temporales, tendencias y estacionalidad, además de las relaciones entre características. El objetivo es identificar puntos o períodos que se desvían del comportamiento temporal esperado.
-
Perspectiva de patrón temporal: Cada observación es parte de una secuencia, y los puntos normales siguen patrones predecibles a lo largo del tiempo, incluyendo tendencias, ciclos estacionales y fluctuaciones recurrentes. Las anomalías rompen estos patrones y destacan como puntos o secuencias inusuales que se desvían del comportamiento esperado.
-
Consideración de tendencias y estacionalidad: Los picos repentinos, caídas o cambios de tendencias establecidas a menudo indican anomalías. Es esencial tener en cuenta los cambios estacionales, porque las desviaciones solo pueden ser anómalas si violan los patrones estacionales esperados. Por ejemplo, un valor de ventas alto podría ser normal durante una temporada festiva pero anómalo durante un período típico de baja temporada. Modelar correctamente las tendencias y la estacionalidad permite al sistema distinguir entre variaciones esperadas y anomalías verdaderas.
-
Dependencias contextuales: El contexto basado en el tiempo es crítico porque el mismo valor puede ser normal en un punto del tiempo pero anómalo en otro, dependiendo de la secuencia circundante. Además, las relaciones entre múltiples variables dependientes del tiempo pueden revelar anomalías que podrían no ser aparentes al analizar una sola serie de forma aislada. Considerar estas dependencias temporales multivariadas mejora la precisión de detección al capturar patrones que emergen solo cuando se observan múltiples factores juntos.
-
Densidad y distribución a lo largo del tiempo: Las anomalías a menudo ocurren en regiones de baja probabilidad dentro de la distribución temporal esperada. Los puntos que se encuentran lejos del rango predicho o la línea base histórica pueden ser marcados como inusuales, y los enfoques probabilísticos como los procesos gaussianos o el modelado de distribución histórica pueden cuantificar estas desviaciones. Al comprender la densidad esperada de observaciones a lo largo del tiempo, el modelo puede asignar puntuaciones de anomalía que reflejen cuán improbable es cada punto en relación con el comportamiento temporal normal.
Criterios Clave de Éxito para la Detección de Anomalías en Series Temporales
La detección de anomalías en series temporales se centra en secuencias de puntos de datos a lo largo del tiempo. El éxito depende de capturar patrones temporales, tendencias y estacionalidad mientras se proporcionan información interpretable y accionable. Los criterios clave para el éxito incluyen:
-
Comprensión de datos temporales: Modelar con precisión tendencias, estacionalidad y dependencias a corto y largo plazo. Preparación de datos de calidad: Manejar marcas de tiempo faltantes, intervalos irregulares y tasas de muestreo inconsistentes.
-
Ingeniería de características efectiva: Incluir características de retardo, estadísticas móviles (media, varianza), diferencias o transformadas de Fourier para capturar el comportamiento temporal.
-
Patrones históricos representativos: Asegurar que los datos de entrenamiento reflejen variaciones temporales normales, incluyendo patrones estacionales raros, para reducir los falsos positivos.
-
Selección robusta de modelos: Elegir algoritmos capaces de capturar dependencias temporales, tendencias y estacionalidad. Por ejemplo, ARIMA, AutoRegressor, Auto ARIMA o SARIMA.
Aplicaciones Empresariales de la Detección de Anomalías en Series Temporales
La detección de anomalías en series temporales tiene aplicaciones de amplio alcance en todas las industrias, ayudando a las organizaciones a identificar patrones inusuales, prevenir fallos y tomar decisiones basadas en datos al monitorear cómo los valores evolucionan a lo largo del tiempo.
-
Finanzas y banca
La detección de anomalías en series temporales en finanzas y banca se utiliza para monitorear secuencias de transacciones en busca de patrones inusuales que puedan indicar fraude u otras actividades irregulares. Los picos repentinos en transferencias, los comportamientos comerciales anormales o las actividades atípicas de cuentas pueden ser marcados en tiempo real, permitiendo a los bancos e instituciones financieras investigar comportamientos sospechosos de manera oportuna. Al analizar los patrones temporales de las transacciones, los modelos pueden distinguir entre actividad legítima estacional o cíclica y anomalías genuinas que requieren atención.
-
IoT y operaciones industriales
En IoT y operaciones industriales, la detección de anomalías en series temporales juega un papel crítico en el monitoreo de equipos y procesos de producción. Las lecturas de sensores recopiladas a lo largo del tiempo pueden revelar señales tempranas de fallo de máquinas, desviaciones en el rendimiento o ineficiencias en las líneas de producción. Al identificar estas anomalías tempranamente, las organizaciones pueden programar mantenimiento predictivo antes de que ocurran averías, reducir el tiempo de inactividad y mantener la eficiencia operativa óptima. Detectar patrones temporales irregulares también ayuda a prevenir interrupciones costosas y asegura la longevidad de los equipos.
-
Retail y Comercio Electrónico
La detección de anomalías en series temporales también es valiosa en retail y comercio electrónico para monitorear ventas, devoluciones y actividad del sitio web a lo largo del tiempo. Caídas o picos repentinos en estas métricas pueden apuntar a problemas operativos, cambios en el comportamiento del cliente o actividad fraudulenta. Al analizar los patrones temporales, las empresas pueden distinguir entre fluctuaciones estacionales normales y anomalías verdaderas, permitiendo una respuesta más rápida a eventos inesperados, mejorando la experiencia del cliente y optimizando las decisiones operativas.
Pronóstico Univariado vs Multivariado en Series Temporales
En la detección de anomalías en series temporales, los datos que se analizan pueden ser univariados o multivariados, dependiendo del número de variables rastreadas a lo largo del tiempo. En QuickML, los datos se categorizan de esta manera para asegurar que los modelos se apliquen apropiadamente: el pronóstico univariado es más simple y computacionalmente eficiente para tendencias de una sola variable, mientras que el pronóstico multivariado es necesario cuando las anomalías surgen de interacciones entre múltiples características, que podrían pasarse por alto en un enfoque univariado. Esta distinción le ayuda a elegir la estrategia de modelado y representación de características correcta para una detección precisa de anomalías, ya sea que el enfoque esté en una sola métrica o en patrones complejos a través de varias variables interdependientes.
Es importante entender la diferencia entre datos univariados y multivariados, ya que esta elección impacta directamente en cómo se detectan e interpretan las anomalías en el análisis de series temporales.
| Característica | Datos Univariados | Datos Multivariados |
|---|---|---|
| Definición | Rastrea una sola variable a lo largo del tiempo. | Rastrea múltiples variables interrelacionadas a lo largo del tiempo y pronostica una sola variable objetivo mientras tiene en cuenta sus dependencias con otras variables relacionadas (pronóstico multivariado), similar a cómo operan los modelos predictivos tradicionales. |
| Enfoque | Monitorea tendencias, estacionalidad y fluctuaciones de una métrica. | Monitorea patrones e interacciones entre múltiples métricas simultáneamente. |
| Detección de Anomalías | Marca desviaciones en la variable única del comportamiento esperado. | Marca anomalías basadas en irregularidades en las relaciones entre variables, capturando patrones que pueden no aparecer de forma aislada. |
| Complejidad | Más simple y computacionalmente eficiente. | Más complejo, requiere modelar dependencias e interacciones entre variables. |
| Casos de Uso | Tráfico de sitios web, ventas diarias, consumo de electricidad, monitoreo de ingresos. | Análisis de retail (ventas vs gasto en marketing), análisis del mercado de valores (precio, volumen, volatilidad), monitoreo de salud (frecuencia cardíaca, presión arterial, niveles de oxígeno). |
| Fortalezas | Fácil de implementar e interpretar; bueno para monitoreo de una sola métrica. | Detecta anomalías sutiles que surgen de interacciones entre variables; captura patrones complejos. |
Cómo Funciona la Detección de Anomalías en Series Temporales
Repasemos la detección de anomalías en series temporales usando el modelo ARIMA (AutoRegressive Integrated Moving Average), uno de los métodos basados en pronóstico más ampliamente utilizados.
-
Comprender los datos de series temporales
El proceso comienza con la recopilación de puntos de datos secuenciales, donde cada valor está vinculado a una marca de tiempo específica, por ejemplo, visitas diarias al sitio web, lecturas de temperatura por hora o precios de acciones minuto a minuto. Debido a que el tiempo es un factor esencial, patrones como tendencias (crecimiento o declive general) y estacionalidad (ciclos repetidos) son importantes de identificar.
-
Entrenar el modelo de pronóstico
ARIMA aprende de los datos históricos de series temporales para comprender sus patrones subyacentes. Combina tres componentes:
- AR (AutoRegressive): Usa valores pasados para predecir valores futuros.
- I (Integrated): Hace los datos estacionarios eliminando tendencias.
- MA (Moving Average): Usa errores de pronóstico pasados para refinar predicciones.
El modelo se entrena para capturar cómo los datos usualmente se comportan a lo largo del tiempo.
-
Generar valores pronosticados
Después del entrenamiento, ARIMA predice cómo deberían verse los próximos puntos de datos basándose en patrones históricos. Para cada marca de tiempo, el modelo produce un valor esperado (pronosticado) y un intervalo de confianza, que representa el rango normal de variación.
-
Comparar valores reales vs. predichos
El valor real observado del conjunto de datos se compara entonces con el valor predicho del modelo. Si el valor observado se encuentra muy fuera del rango esperado (por ejemplo, mucho más alto o más bajo que la banda de confianza pronosticada), se considera un punto anómalo.
-
Detectar y reportar anomalías
Una vez que se analiza toda la serie temporal, el sistema marca las marcas de tiempo donde ocurren desviaciones significativas. Por ejemplo, un pico repentino en el tráfico de red podría indicar un ciberataque. La salida típicamente resalta estas marcas de tiempo y muestra el número de anomalías detectadas para investigación posterior.
Ejemplo: Imagine una empresa monitoreando el tráfico por hora de su sitio web. ARIMA predice que la próxima hora debería tener alrededor de 1,200 ± 100 visitas, pero el conteo real cae repentinamente a 400. Dado que este valor se encuentra muy fuera del rango esperado, el sistema lo marca como una anomalía, impulsando a la empresa a investigar posibles causas como una caída del servidor o un problema de conectividad.
Pasos para Construir un Pipeline de Detección de Anomalías en Series Temporales
En QuickML, la detección de anomalías en series temporales se implementa a través del Smart Builder, que está diseñado específicamente para conjuntos de datos donde las observaciones se realizan a lo largo del tiempo. El Smart Builder estructura este proceso en cuatro stages principales: Source → Preprocessing → Algorithm → Destination.
Stage 1: Source
El pipeline comienza con la ingesta del conjunto de datos de series temporales, como precios de acciones, lecturas de sensores de máquinas o ventas diarias. Dado que estos conjuntos de datos son secuenciales, seleccionar la entrada correcta basada en el tiempo asegura que el sistema pueda detectar anomalías en relación con los patrones históricos.
Stage 2: Preprocessing
Smart Builder prepara automáticamente los datos sin procesar basados en el tiempo para la detección de anomalías.
Frecuencia: Para conjuntos de datos de series temporales, los datos se remuestrean a una frecuencia consistente (por ejemplo, diaria, semanal). Esta estandarización asegura que las anomalías se detecten a través de intervalos uniformes en lugar de ser distorsionadas por marcas de tiempo irregulares.
Imputación: Los valores faltantes en el conjunto de datos se manejan a través de imputación. Sin este paso, los vacíos pueden ser mal interpretados como anomalías o distorsionar la capacidad del modelo para reconocer patrones verdaderos.
Transformación: La transformación asegura que el conjunto de datos se ajuste para que las anomalías destaquen más claramente en lugar de estar ocultas por tendencias o efectos de escala. En Smart Builder, este paso se puede configurar directamente, y los usuarios tienen dos opciones principales: Differencing o Power Transformation.
-
Differencing: Differencing funciona calculando la diferencia entre observaciones consecutivas en una serie temporal. Este proceso ayuda a estabilizar la media eliminando cambios en el nivel de la serie, reduciendo o eliminando efectivamente tendencias y estacionalidad. El orden de diferenciación especifica cuántas veces se aplica esta operación para transformar una serie no estacionaria en una estacionaria. En QuickML, puede especificar un orden máximo de diferenciación de hasta 5. Si la serie permanece no estacionaria incluso después del quinto orden de diferenciación, puede aplicar uno de los métodos de transformación de potencia disponibles para estabilizar aún más la varianza y hacer que la serie sea adecuada para la detección de anomalías.
-
Power Transformation: Estabiliza la varianza y normaliza las distribuciones de datos sesgadas. Esto es especialmente útil cuando los valores de datos sin procesar están distribuidos en escalas muy diferentes, haciendo que las anomalías en valores más pequeños sean más difíciles de detectar. Las opciones disponibles para transformación de potencia en QuickML son:
- Log Transformation: Aplica una escala logarítmica para comprimir valores grandes y extender los más pequeños. Esto ayuda a revelar anomalías que de otro modo podrían ser opacadas por outliers extremos.
- Square Root Transformation: Útil cuando se trata con sesgo moderado; reduce el impacto de valores altos mientras retiene las diferencias relativas a través de valores más pequeños.
- Box-Cox Transformation: Una opción flexible que determina automáticamente el mejor parámetro de potencia (λ) para estabilizar la varianza y normalizar el conjunto de datos. Particularmente efectiva cuando los valores son estrictamente positivos y la distribución está fuertemente sesgada.
- Yeo-Johnson Transformation: Similar a Box-Cox pero también funciona con valores cero o negativos, haciéndola más versátil para conjuntos de datos que no son estrictamente positivos.
Stage 3: Algorithm
Una vez preprocesado, Smart Builder aplica algoritmos diseñados para la detección de anomalías en series temporales, como Isolation Forest o One-Class SVM. Estos modelos aprenden el comportamiento temporal normal y marcan las desviaciones como anomalías potenciales, ya sea que aparezcan como picos repentinos, caídas o secuencias irregulares.
Stage 4: Destination
Finalmente, Smart Builder genera anomalías junto con métricas de apoyo y visualizaciones. Estos resultados permiten a los usuarios validar las anomalías marcadas, interpretar el contexto y tomar acciones oportunas. El sistema asegura que las anomalías se presenten en un formato accesible para una toma de decisiones más rápida.
Detección de Anomalías en No Series Temporales
La detección de anomalías en no series temporales trata con datos que no tienen un orden temporal inherente, lo que significa que los puntos de datos individuales son independientes del tiempo o la secuencia. Cada observación se trata como una instancia independiente en lugar de parte de una línea de tiempo continua. Los ejemplos incluyen transacciones de tarjetas de crédito, registros médicos, paquetes de red, reseñas de productos o mediciones de manufactura.
En la detección de anomalías en no series temporales, el objetivo es identificar puntos de datos que se comportan de manera diferente a la mayoría del conjunto de datos. Dado que no hay un componente temporal, detectar anomalías en datos no secuenciales se centra en patrones espaciales, relacionales o estadísticos en lugar de temporales. Los métodos analizan la distribución y estructura de los datos, midiendo cuán lejos se desvía cada punto de la población normal.
Construyendo Intuición Detrás de la Detección de Anomalías en No Series Temporales
En conjuntos de datos de no series temporales, las observaciones son estáticas e independientes del tiempo. Detectar anomalías implica comprender las relaciones entre múltiples características. El objetivo es definir el límite que separa el comportamiento normal del comportamiento anormal.
-
Perspectiva del espacio de características: Cada observación se puede visualizar como un punto en un espacio de alta dimensión. Los puntos normales se agrupan juntos, mientras que las anomalías se encuentran lejos de estos grupos.
-
Pensamiento basado en densidad: Las anomalías a menudo ocurren en regiones de baja densidad donde existen pocos puntos de datos. Los algoritmos usan esta intuición para asignar puntuaciones de anomalía.
-
Dependencias multivariadas: Se deben considerar las relaciones entre múltiples características. Un punto podría parecer normal a lo largo de dimensiones individuales pero ser anómalo cuando se combina con otras características.
-
Consciencia del contexto: En datos categóricos o agrupados, la normalidad puede variar entre grupos. Comprender esta variación contextual es esencial para una detección precisa.
Criterios Clave de Éxito para la Detección de Anomalías en No Series Temporales
La detección de anomalías en no series temporales se centra en puntos de datos estáticos o independientes en lugar de secuencias a lo largo del tiempo. El éxito depende de identificar con precisión patrones anormales dentro de estos conjuntos de datos estáticos, comprender las relaciones entre características y proporcionar información interpretable y accionable. Los criterios clave para el éxito incluyen:
-
Preparación de datos de calidad: Asegurar que los datos estén limpios, consistentes y sean representativos del comportamiento normal.
-
Ingeniería de características efectiva: Elegir características que capturen variaciones significativas en el comportamiento. Combinar atributos numéricos y categóricos proporciona una representación más rica de la normalidad.
-
Muestras normales representativas: Los datos de entrenamiento deben cubrir el rango completo de patrones legítimos para prevenir la clasificación errónea de variaciones válidas como anomalías.
-
Selección robusta de modelos: El algoritmo elegido debe manejar ruido, outliers y diferentes distribuciones de datos.
Aplicaciones Empresariales de la Detección de Anomalías en No Series Temporales
La detección de anomalías en no series temporales se aplica en muchas industrias para identificar puntos de datos o comportamientos inusuales que se desvían de los patrones normales. Debido a que este tipo de datos no depende del tiempo, ayuda a las organizaciones a detectar eventos raros o sospechosos y fortalecer la toma de decisiones en una amplia gama de operaciones.
-
Salud
En el sector salud, la detección de anomalías en no series temporales se utiliza para encontrar registros de pacientes o resultados diagnósticos inusuales que pueden indicar errores, enfermedades raras o potencial fraude en reclamaciones de seguros. Por ejemplo, un número inusualmente alto de procedimientos para un solo paciente o resultados de pruebas médicas que difieren mucho de los rangos normales pueden ser marcados para revisión adicional. Detectar estas irregularidades ayuda a mejorar la seguridad del paciente, reducir el fraude de facturación y mantener la precisión de datos en sistemas médicos.
-
Recursos Humanos y Reclutamiento
En RR.HH. y reclutamiento, la detección de anomalías puede ayudar a identificar datos inusuales de empleados, como niveles salariales inesperados, métricas de rendimiento inconsistentes o patrones de solicitud irregulares. Detectar estos outliers ayuda a las organizaciones a mantener la equidad, detectar errores de datos y prevenir posibles violaciones de políticas. También asiste en identificar talento excepcional o señales tempranas de problemas en la fuerza laboral.
-
Ciberseguridad
En ciberseguridad, la detección de anomalías ayuda a identificar actividades de red sospechosas o patrones de acceso al sistema que difieren del comportamiento típico del usuario. Por ejemplo, un intento de inicio de sesión desde una ubicación inusual, acceso no autorizado a datos o transferencias de archivos anormales pueden indicar posibles ciberataques o amenazas internas. Al analizar las relaciones y características de los datos de red, los sistemas de seguridad pueden detectar y responder a amenazas rápidamente, incluso sin depender de secuencias basadas en el tiempo.
Cómo Funciona la Detección de Anomalías en No Series Temporales
Ahora, entendamos la detección de anomalías en no series temporales usando el algoritmo Isolation Forest, un método popular que funciona bien para datos tabulares de alta dimensión.
-
Comprender el conjunto de datos
En datos de no series temporales, cada registro se trata como una observación independiente con múltiples características (por ejemplo, edad del cliente, ingresos y puntuación de gasto). No hay marca de tiempo ni orden secuencial; el objetivo es simplemente encontrar puntos de datos que se vean muy diferentes de la mayoría.
-
Construir árboles aleatorios
Isolation Forest crea muchos árboles de decisión aleatorios dividiendo repetidamente el conjunto de datos en secciones más pequeñas. Cada división selecciona aleatoriamente una característica y un valor de división. La idea es que los puntos de datos normales necesitan más divisiones para ser aislados, mientras que las anomalías, siendo raras y diferentes, se aíslan rápidamente con menos divisiones.
-
Medir la profundidad de aislamiento
Para cada punto de datos, el algoritmo calcula el número promedio de divisiones (longitud del camino) necesarias para aislarlo a través de todos los árboles.
- Si un punto se aísla rápidamente, es probable que sea una anomalía.
- Si requiere muchas divisiones, se considera normal.
-
Calcular puntuaciones de anomalía
Luego se calcula una puntuación de anomalía para cada registro basándose en su longitud de camino promedio. Los valores más cercanos a 1 indican anomalías más fuertes, mientras que los valores cercanos a 0 sugieren comportamiento normal.
-
Detectar y reportar anomalías
Finalmente, el modelo clasifica los registros con puntuaciones de anomalía altas como outliers y reporta el número de anomalías detectadas en el conjunto de datos. Estos puntos pueden ser examinados para entender por qué difieren de la norma, por ejemplo, transacciones fraudulentas o errores de entrada de datos.
Ejemplo: Imagine un banco analizando transacciones de clientes. La mayoría de los clientes gastan cantidades entre $50 y $500, pero algunas transacciones aparecen repentinamente a $10,000+. Isolation Forest aísla estas transacciones de alto valor con muy pocas divisiones, las marca como anomalías y reporta cuántos casos sospechosos existen, ayudando al banco a enfocarse en posible fraude.
Pasos para Construir un Pipeline de Detección de Anomalías en No Series Temporales
Para datos de no series temporales, como transacciones de clientes, registros de empleados o respuestas de encuestas, los pipelines de detección de anomalías se construyen usando Classic Builder. Aquí, el proceso omite la alineación de frecuencia y las transformaciones temporales, ya que los datos no son secuenciales. En cambio, Classic Builder prepara directamente los datos tabulares, aplica algoritmos y genera anomalías que resaltan registros inusuales o sospechosos.
Al separar Smart Builder para datos de series temporales y Classic Builder para datos de no series temporales, QuickML asegura que cada pipeline de detección de anomalías esté adaptado a la estructura única del conjunto de datos, mejorando tanto la precisión como la interpretabilidad.
Stage 1: Ingesta de datos
El proceso comienza con la carga del conjunto de datos en QuickML, que sirve como base para el flujo de trabajo de detección de anomalías. Este paso implica importar datos de varias fuentes como archivos CSV, bases de datos relacionales, APIs o sistemas de almacenamiento en la nube. Dado que los datos de no series temporales no dependen del orden temporal, cada registro se trata como una observación independiente. Asegurar una ingesta de datos precisa y completa es crítico para resultados confiables de detección de anomalías.
Stage 2: Preprocesamiento de datos
Una vez que los datos se importan, pasan por una fase de preprocesamiento para asegurar precisión, consistencia y preparación para el análisis. Este paso incluye el manejo de valores faltantes a través de imputación o eliminación y la codificación de variables categóricas usando codificación de etiquetas o one-hot. Un preprocesamiento efectivo asegura que las anomalías reflejen irregularidades verdaderas en lugar de problemas de calidad de datos, mejorando el rendimiento y la interoperabilidad del modelo de detección.
Stage 3: Selección de algoritmo
Después del preprocesamiento, QuickML permite a los usuarios seleccionar un algoritmo de detección de anomalías apropiado basado en las características del conjunto de datos y la naturaleza de las anomalías esperadas. Los enfoques comunes incluyen Isolation Forest, One-Class SVM y Local Outlier Factor (LOF). Cada algoritmo usa diferentes principios para distinguir datos normales de anomalías. Elegir el método correcto es crucial para capturar con precisión los patrones y relaciones únicos dentro del conjunto de datos.
Stage 4: Entrenamiento del modelo y detección
En este paso, el algoritmo seleccionado se entrena con los datos procesados para aprender el comportamiento o estructura normal del conjunto de datos. Durante el entrenamiento, el modelo identifica patrones típicos, límites o distribuciones y luego evalúa cada instancia para detectar aquellas que se desvían significativamente de las normas aprendidas.
Stage 5: Reporte de anomalías
Después de que el modelo identifica las anomalías, QuickML resume los resultados mostrando el número de anomalías detectadas en el conjunto de datos. Esta salida proporciona una vista clara de cuántos puntos de datos se desvían de los patrones normales basándose en el modelo entrenado.
Métricas de Evaluación en la Detección de Anomalías
Las métricas de evaluación a continuación ayudan a evaluar qué tan bien el modelo de detección de anomalías está identificando desviaciones del comportamiento normal y qué tan precisas son sus predicciones subyacentes. Estas métricas cuantifican el error de predicción, la confiabilidad del modelo y, en última instancia, la confianza que puede depositar en las anomalías marcadas.
Error Porcentual Absoluto Medio (MAPE)
Qué le dice: MAPE mide cuán lejos, en promedio, los valores predichos del modelo se desvían de los valores reales observados en términos porcentuales. Expresa el tamaño de los errores de predicción en relación con la magnitud de los datos reales, lo que lo hace intuitivo y fácil de interpretar a través de diferentes conjuntos de datos o escalas. Esta métrica es particularmente útil cuando necesita entender qué tan precisas son las predicciones de su modelo en términos de desviación porcentual en lugar de diferencia absoluta.
Intuición:
- Un MAPE más bajo indica que las predicciones del modelo están más cerca de los valores verdaderos.
- Un MAPE muy alto generalmente señala poca precisión del modelo — o que los valores reales son muy pequeños, lo que infla los errores porcentuales.
Ejemplo de Inferencia: Si MAPE es 15%, significa que las predicciones se desvían de los valores reales en un 15% en promedio.
Error Porcentual Absoluto Medio Simétrico (SMAPE)
Qué le dice: SMAPE mejora respecto a MAPE al tratar las sobrepredicciones y subpredicciones de manera igual. Esto lo convierte en una medida más justa y equilibrada, especialmente cuando su conjunto de datos contiene valores pequeños o cero que pueden distorsionar los errores porcentuales tradicionales. SMAPE expresa cuán grandes son los errores de predicción en comparación con el promedio de los valores predichos y reales, asegurando que la métrica permanezca estable incluso cuando los valores reales están cerca de cero.
Intuición:
- SMAPE varía entre 0% (predicción perfecta) y 200% (completamente inexacto).
- Se prefiere sobre MAPE cuando su conjunto de datos contiene valores muy pequeños o cero para evitar errores desproporcionadamente grandes.
Ejemplo de Inferencia: Un SMAPE de 18.68% indica que, en promedio, las predicciones se desvían un 18.68% de los valores reales de manera simétrica, lo cual es un nivel de error razonablemente aceptable para muchas tareas de detección de anomalías del mundo real.
Error Cuadrático Medio (MSE)
Qué le dice: MSE calcula el promedio de las diferencias al cuadrado entre los valores predichos y reales. Al elevar al cuadrado los errores, enfatiza las desviaciones grandes, lo que significa que los errores grandes tienen un impacto mucho más fuerte en la puntuación. Esto hace que MSE sea valioso para entender cuán significativamente varían los errores de predicción a través del conjunto de datos y para identificar modelos que puedan estar cometiendo errores grandes y costosos.
Intuición:
- Un MSE de 0 significa predicciones perfectas.
- Valores de MSE más altos indican un mayor nivel de error de predicción.
- Debido a que los errores se elevan al cuadrado, las desviaciones grandes contribuyen desproporcionadamente, haciendo que MSE sea sensible a los outliers.
Ejemplo de Inferencia: En la salida proporcionada, MSE es 0, lo que significa que las predicciones del modelo coinciden exactamente con los valores observados, lo cual es un caso ideal.
Raíz del Error Cuadrático Medio (RMSE)
Qué le dice: RMSE es la raíz cuadrada de MSE y proporciona una medida de error en la misma unidad que los datos originales, haciéndola más interpretable. Representa la desviación estándar de los errores de predicción, o cuán dispersos están los residuos alrededor de los valores verdaderos. RMSE es especialmente útil cuando se comparan modelos o se evalúa la consistencia de las predicciones.
Intuición:
- RMSE es más fácil de interpretar que MSE porque se expresa en la misma unidad que la variable predicha.
- Un RMSE más bajo significa mejor precisión de predicción.
Ejemplo de Inferencia: Un RMSE de 0.0041 indica que, en promedio, el error de predicción es muy pequeño y cercano a los valores verdaderos.
Error Logarítmico Cuadrático Medio (MSLE)
Qué le dice: MSLE mide la diferencia al cuadrado entre los logaritmos de los valores predichos y reales. En lugar de centrarse en diferencias absolutas, enfatiza los errores relativos, haciéndolo ideal para datos que abarcan múltiples escalas o involucran crecimiento exponencial (por ejemplo, población, ventas o tráfico web). MSLE recompensa las predicciones que están proporcionalmente cerca de los valores reales y penaliza la subestimación más fuertemente que la sobreestimación, lo cual es útil cuando perder un pico es más grave que sobrepredicir uno.
Intuición:
- MSLE penaliza la subestimación más que la sobreestimación.
- Mejor utilizado cuando sus datos abarcan múltiples órdenes de magnitud (por ejemplo, patrones de crecimiento exponencial).
Ejemplo de Inferencia: Un MSLE de 0 indica alineación perfecta entre valores predichos y reales en escala logarítmica, lo que significa que no hay sub o sobrepredicción significativa.
Raíz del Error Logarítmico Cuadrático Medio (RMSLE)
Qué le dice: RMSLE es la raíz cuadrada de MSLE, haciéndola más fácil de interpretar mientras retiene su enfoque en la precisión predictiva relativa. Ayuda a evaluar cuánto difieren las predicciones del modelo de los valores reales en términos similares a porcentajes sin ser excesivamente influenciada por grandes outliers. RMSLE es particularmente útil para problemas donde las diferencias relativas de crecimiento o proporcionales son más importantes que la precisión numérica exacta.
Intuición:
- RMSLE es menos sensible a errores absolutos grandes pero enfatiza la precisión relativa.
- Particularmente útil cuando las diferencias porcentuales importan más que las diferencias brutas.
Ejemplo de Inferencia: Un RMSLE de 0.0041 indica que, en una escala logarítmica, los errores de predicción son extremadamente bajos, confirmando un pronóstico de alta calidad.
Número de Anomalías
Qué le dice: Esta métrica representa el conteo de puntos de datos marcados como anomalías por el modelo después de procesar el conjunto de datos. Proporciona una medida directa de cuán frecuentemente el sistema detecta desviaciones del comportamiento normal.
Intuición:
- Un número muy alto de anomalías podría indicar que el modelo es demasiado sensible (muchos falsos positivos).
- Un número muy bajo podría significar que el modelo es demasiado estricto y está perdiendo anomalías significativas.
Ejemplo de Inferencia: Si el modelo detecta 42 anomalías, puede revisarlas para asegurar que correspondan a eventos significativos, como picos repentinos de demanda o fallos de sensores, y no a ruido aleatorio.
Cómo usar estas métricas juntas
Ninguna métrica individual cuenta la historia completa del rendimiento del modelo. Úselas colectivamente para obtener una visión holística; las métricas de error de predicción (MAPE, SMAPE, MSE, RMSE, MSLE, RMSLE) indican cuán precisamente el modelo pronostica el comportamiento normal, mientras que el número de anomalías muestra cuán frecuentemente el modelo marca desviaciones.
Ejemplo: Suponga que su modelo tiene un RMSE de 0.0041, un MAPE de 15% y detecta 42 anomalías en un conjunto de datos. El bajo RMSE y el MAPE moderado indican que las predicciones están muy cerca de los valores reales, y el número de anomalías es razonable, sugiriendo que el modelo es preciso y apropiadamente sensible. Si en cambio el modelo marcara 300 anomalías, podría sospechar que es demasiado sensible y produce muchos falsos positivos.
Interpretar estas métricas juntas ayuda a equilibrar la precisión de predicción con la detección significativa de anomalías, dándole confianza en información accionable.
Evaluación Visual de Anomalías
La evaluación visual es un paso crucial para validar el rendimiento de un modelo de detección de anomalías en series temporales. Permite una evaluación cualitativa de las salidas del modelo comparando las anomalías predichas contra el comportamiento real de la serie temporal. Esta visualización permite a los usuarios:
- Validar rápidamente si las anomalías detectadas se alinean con cambios reales en los datos.
- Identificar falsas alarmas o anomalías perdidas.
- Obtener información sobre la confiabilidad del modelo a través de diferentes segmentos temporales y tendencias.
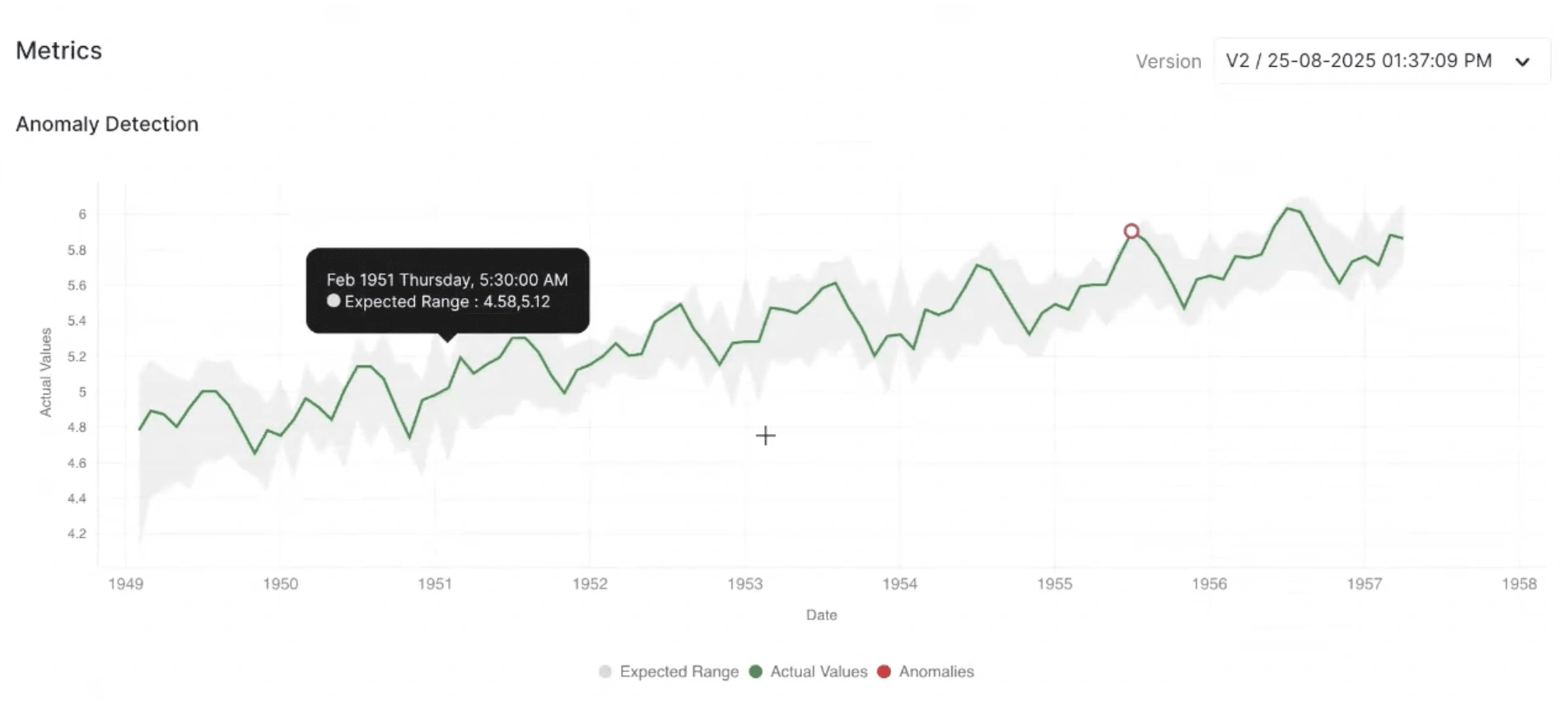
Qué le dice: Esta visualización muestra cómo el modelo identifica anomalías en un conjunto de datos de series temporales. El gráfico traza los valores de datos reales a lo largo del tiempo, resalta el rango esperado (normal) y marca los puntos que se desvían significativamente como anomalías.
Intuición:
- Línea verde: Representa los valores reales observados a lo largo del tiempo.
- Área sombreada gris: Indica el rango esperado o predicho de comportamiento normal basándose en el modelo.
- Círculos rojos: Resaltan los puntos detectados como anomalías, donde los valores reales se desvían significativamente del rango esperado.
- Si los puntos de anomalía rojos se alinean con picos claros, caídas o desviaciones fuera del rango esperado gris, indica que el modelo está capturando con precisión los patrones inusuales.
- Pocas anomalías bien ubicadas sugieren que el modelo es estable y preciso.
- Puntos de anomalía frecuentes o aleatorios dentro de regiones normales pueden indicar un umbral excesivamente sensible o ruido en la detección.
Ejemplo: Si las anomalías aparecen en picos agudos de la serie (por ejemplo, aumentos repentinos en los valores), sugiere outliers genuinos o eventos inesperados. Si las anomalías aparecen durante fluctuaciones normales, puede indicar que el modelo necesita ajuste del umbral para reducir los falsos positivos.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us