QuickML Pipeline Endpoints
El resultado principal de los pipelines de aprendizaje automático (ML) es crear endpoints que se pueden utilizar para realizar predicciones sobre nuevos datos. Estos endpoints se crean utilizando modelos de ML entrenados y se pueden utilizar para inferencia continua.
Una vez que un modelo de ML está desarrollado y entrenado, los usuarios de QuickML pueden crear un endpoint con la última versión del modelo. Este endpoint se puede utilizar para realizar predicciones sobre nuevos datos. QuickML monitorea todos los endpoints para identificar áreas donde el modelo puede mejorarse.
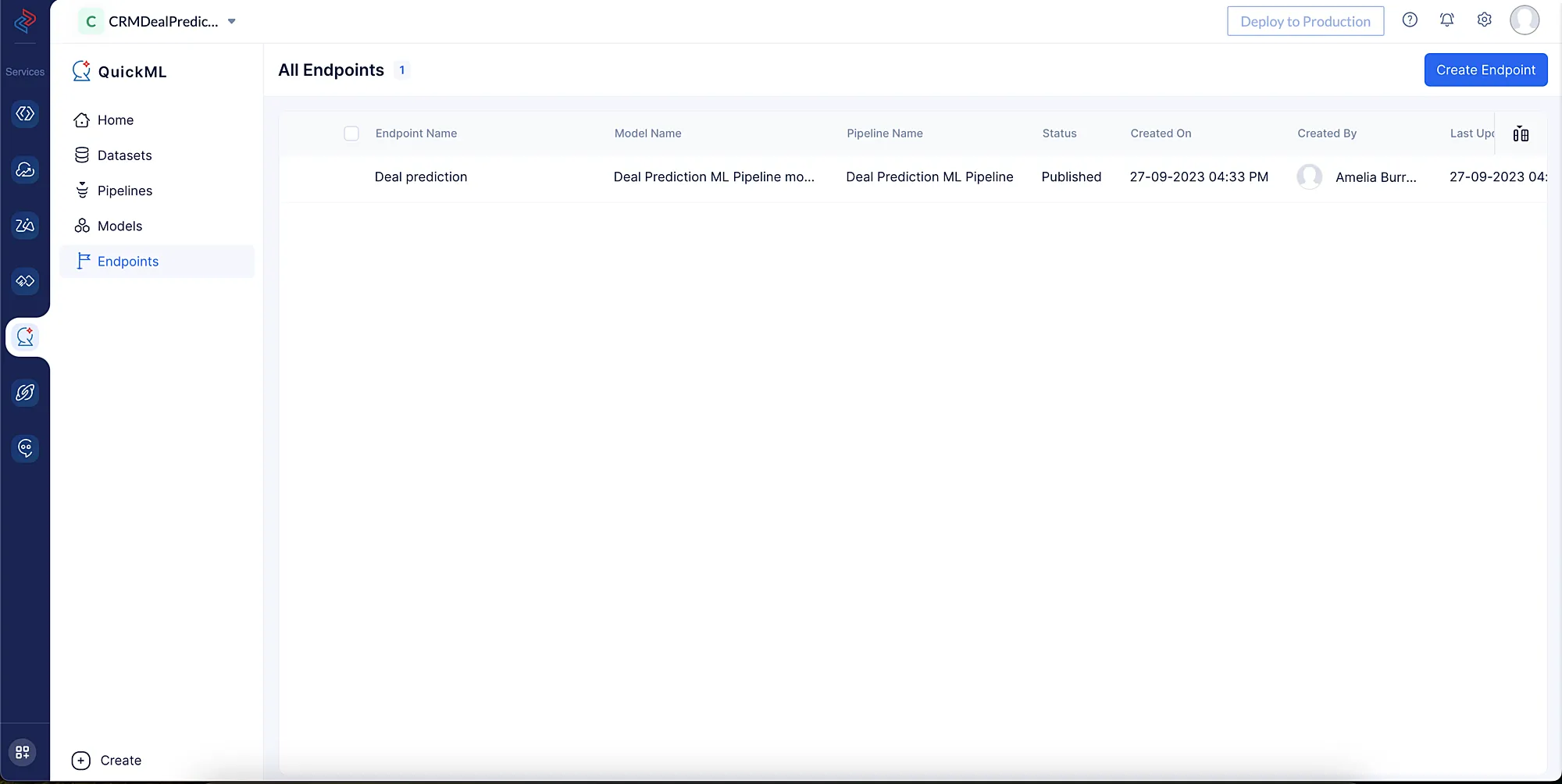
Versión del Modelo Publicada
Una vez que se ha generado un modelo de aprendizaje automático utilizando el pipeline de QuickML, un usuario puede elegir publicarlo como un endpoint con una versión específica del modelo. Esto permite a los usuarios desplegar y utilizar el modelo para realizar predicciones precisas.
Los modelos se versionan cada vez que hay un cambio en las configuraciones de las etapas del pipeline para la ejecución del pipeline.
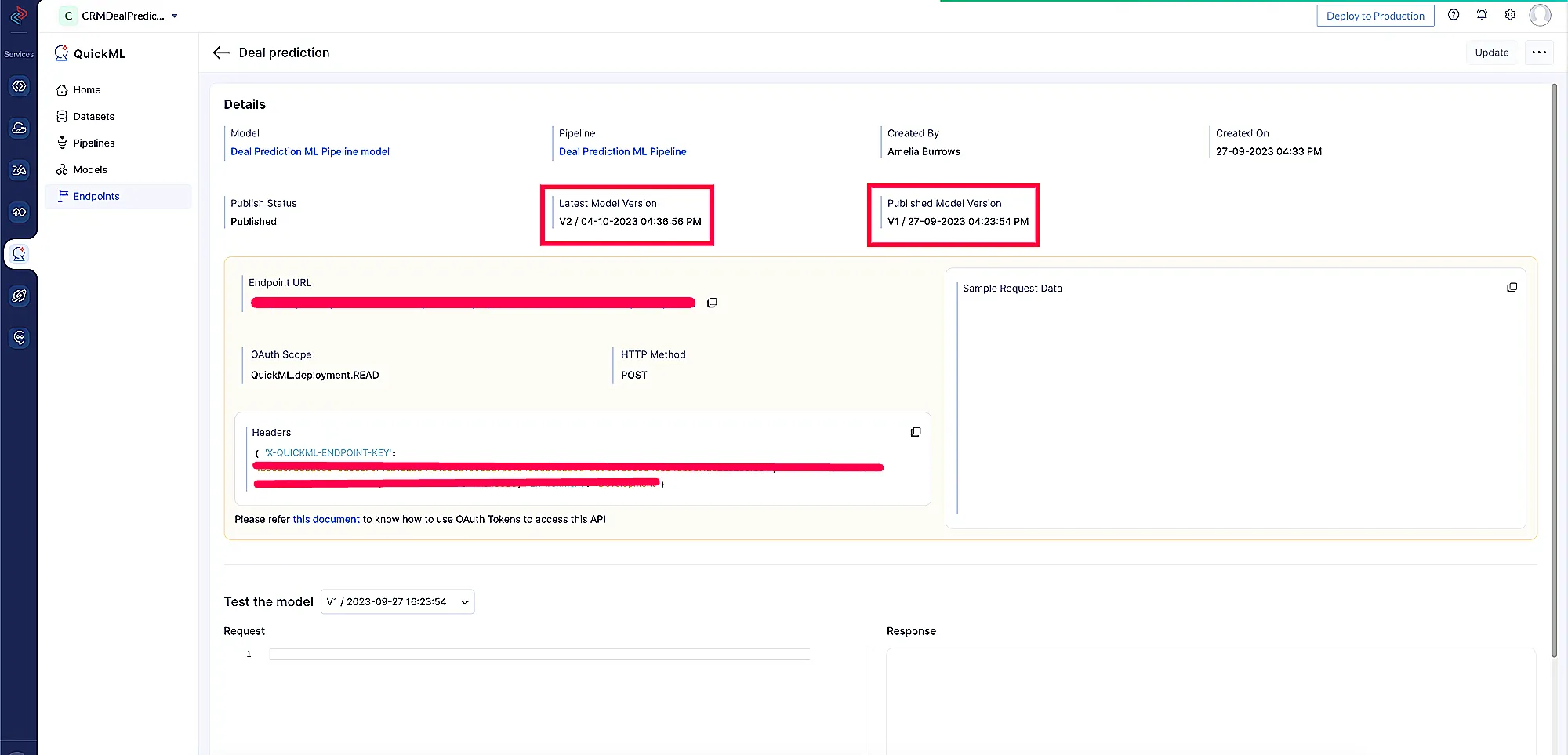
Model Tester
Para verificar la precisión del modelo, se ha integrado un componente Test the Model con respecto a las versiones del modelo en el módulo de endpoints de QuickML, en el cual se pueden realizar solicitudes en vivo dentro de la aplicación web usando la Endpoint URL para probar la inferencia del modelo.
Model Explanation Chart
Cada característica de entrada en los datos utilizados para entrenar el modelo de aprendizaje automático tiene un impacto en las predicciones del modelo. Sin embargo, estos modelos exhiben el comportamiento de caja negra, lo que dificulta comprender cómo llegó a esas predicciones. Cuantificar la contribución de cada característica a la predicción final es un desafío, lo que dificulta nuestra comprensión del comportamiento del modelo.
Para abordar este problema, QuickML ha creado un Model Explanation Chart. Este gráfico muestra el efecto en la predicción en el eje x y la lista de características en el eje y.
Para cada característica, el efecto en la predicción se cuantifica mediante valores SHAP (SHapley Additive exPlanations), que explican la decisión del modelo de aprendizaje automático. Estos valores ayudan a comprender e interpretar las decisiones del modelo y aumentan la transparencia. La distribución de valores en el eje x indica si la característica respectiva tiene un impacto positivo o negativo en la predicción, junto con su puntuación.
Este gráfico se encuentra en la página de detalles del endpoint, como se muestra a continuación.
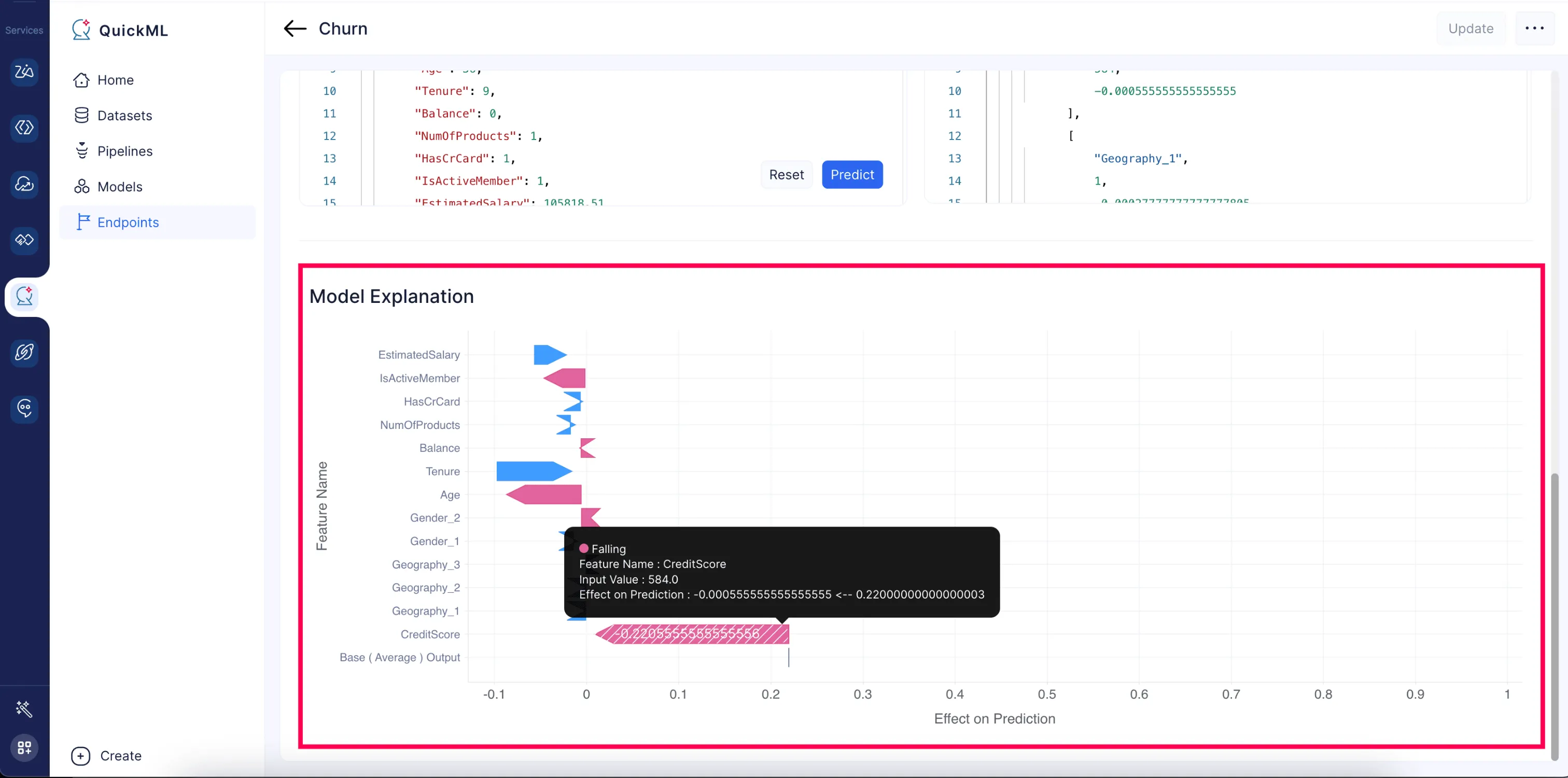
En resumen, el Model Explanation Chart en QuickML muestra la influencia de cada característica en el resultado de predicción final para una entrada dada.
Video de referencia rápida sobre la vista del model explanation chart.
Una descripción general rápida del model explanation chart ubicado en la página de detalles del endpoint muestra la puntuación de impacto de cada característica en la predicción en el cuadro de respuesta y la representación visual del impacto en el gráfico anterior.
Autenticación de Endpoints
Los endpoints en vivo se exponen a través de REST APIs desde el servicio QuickML y se pueden acceder con dos modos:
- Autenticación externa OAuth2
- Autenticación interna
Autenticación externa OAuth2
Los endpoints que se exponen como REST APIs se autentican con el mecanismo OAuth2 de Zoho accounts. Los usuarios pueden realizar las llamadas de predicción externamente generando los tokens desde la consola de accounts.
- Directrices de predicción: Para realizar las llamadas de REST API, el usuario debe proporcionar los siguientes detalles,
- Request URL: Deployment Url proporcionada en los detalles
- HTTP Method: POST
- Headers :
{
'X-QUICKML-ENDPOINT-KEY' : ************************,
'Authorization': 'Zoho-oauthtoken ',
'CATALYST-ORG': ********
'Environment': , 'Development/Production'
} Para generar un access token, sigue los pasos en este documento,
- Scope: QuickML.deployment.READ
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us