Algoritmos de Detección de Anomalías
La detección de anomalías es una técnica de aprendizaje automático no supervisado que se centra en identificar puntos de datos, eventos u observaciones que se desvían significativamente de la mayoría de los datos. Estos valores atípicos pueden representar incidentes críticos como fraudes, intrusiones en la red, fallos de equipos o problemas de calidad de datos. En lugar de predecir etiquetas predefinidas, los modelos de detección de anomalías aprenden el comportamiento normal dentro de los datos y señalan las desviaciones que pueden requerir atención.
La detección de anomalías en Catalyst QuickML se clasifica ampliamente en Series Temporales y No Series Temporales, cada una ofreciendo su propio conjunto de algoritmos y parámetros configurables.
Dentro de Catalyst QuickML, la detección de anomalías para datos de series temporales se centra en identificar patrones anormales o desviaciones en puntos de datos secuenciales a lo largo del tiempo. Estos métodos tienen en cuenta las dependencias temporales y la estacionalidad, permitiendo la detección de picos repentinos, caídas o cambios de tendencia.
Antes de explorar los algoritmos individuales de detección de anomalías en series temporales, es importante comprender los parámetros comunes utilizados para el Control de Sensibilidad de Anomalías, como se muestra en la imagen a continuación. Estos parámetros son consistentes en todos los algoritmos de detección de anomalías en series temporales de Catalyst QuickML y son esenciales para controlar cómo se detectan e interpretan las anomalías. Permiten a los usuarios ajustar con precisión el umbral, el tamaño de la ventana y el método de puntuación de anomalías, asegurando que el sistema diferencie con precisión entre fluctuaciones normales y comportamiento verdaderamente anómalo.
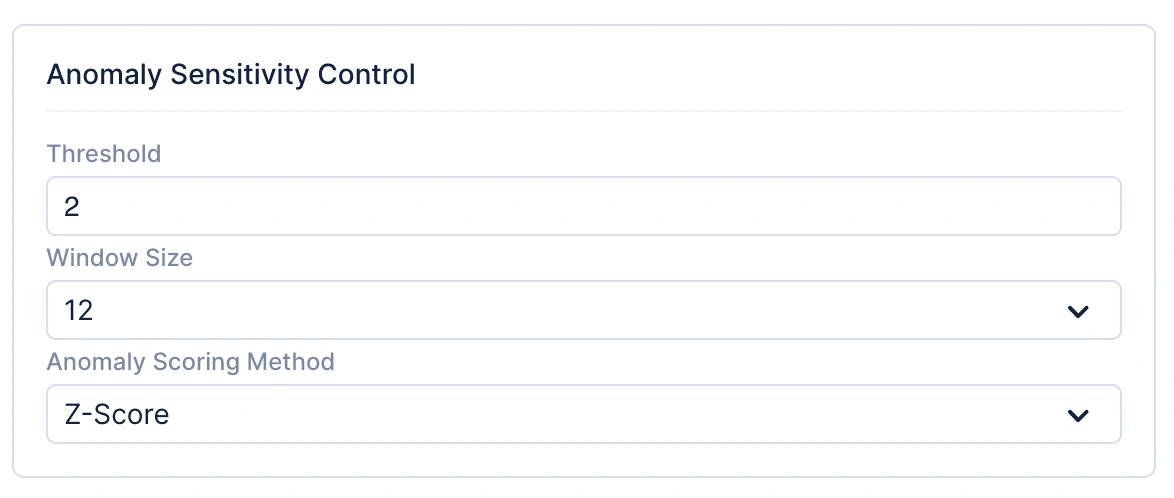
Parámetros comunes:
-
Threshold: Determina qué tan sensible es el modelo a las desviaciones del comportamiento esperado. Un umbral más bajo aumenta la sensibilidad, señalando fluctuaciones más pequeñas como anomalías, mientras que un umbral más alto reduce los falsos positivos.
-
Window size: Define la ventana móvil de puntos de datos utilizada para el análisis. Aplicable hasta un máximo de 24 pasos temporales.
-
Anomaly scoring method: Actualmente soporta Z-Score, que mide cuánto se desvía un punto de la media en términos de desviaciones estándar.
A continuación se presentan los algoritmos de detección de anomalías en series temporales soportados en Catalyst QuickML, junto con sus explicaciones, casos de uso del mundo real y parámetros clave.
Auto Regressor
Explicación: El modelo Auto Regressor (AR) predice valores futuros basándose en una combinación lineal de observaciones pasadas. Asume que el comportamiento pasado influye directamente en el presente, con coeficientes que representan la fuerza de la relación entre los valores pasados y actuales. QuickML extiende esto con backends de regresión flexibles, incluyendo Linear Regressor, Random Forest Regressor, AdaBoost Regressor y Gradient Boosting Regressor, permitiendo el modelado temporal tanto lineal como no lineal.
Intuición matemática:
Yₜ = c + ∑ᵢ₌₁ᵖ φᵢ Yₜ₋ᵢ + εₜ Donde:
- Yt = valor actual
- c = intercepto (término constante)
- ϕi = coeficientes autorregresivos
- Yt−i = observaciones retrasadas
- εt = ruido aleatorio
Caso de uso: Se utiliza en pronósticos financieros, detección de deriva de sensores y monitoreo predictivo de procesos, donde el historial reciente influye significativamente en el siguiente resultado — por ejemplo, predecir tendencias bursátiles a corto plazo o detectar fluctuaciones anormales en sensores de temperatura.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| select_model_to_fit | Elige el modelo de regresión para ajustar la serie temporal. | string | {'Linear Regressor', 'Random-Forest Regressor', 'AdaBoost Regressor', 'Gradient Boosting Regressor'} | 'Linear Regressor' |
| max_lag | Define cuántos pasos temporales pasados se utilizan para predecir el valor actual. | int | [1, ∞) | 1 |
Moving Average (MA)
Explicación: El modelo Moving Average se centra en modelar el ruido o las perturbaciones aleatorias dentro de una serie temporal. En lugar de usar valores pasados directamente, predice las observaciones actuales como una suma ponderada de los errores de pronóstico pasados. Este enfoque ayuda a suavizar la volatilidad a corto plazo y es ideal para detectar desviaciones inusuales de los patrones residuales esperados.
Intuición matemática:
Yₜ = μ + ∑ᵢ₌₁ᵠ θᵢ εₜ₋ᵢ + εₜ Donde:
- Yt = observación actual
- μ = media de la serie
- θi = coeficientes de media móvil
- εt−i = errores de pronóstico pasados
Caso de uso: Se aplica en la detección de anomalías en precios de acciones, monitoreo de producción manufacturera y pronósticos de demanda a corto plazo, donde la identificación de patrones de error irregulares ayuda a descubrir anomalías transitorias o inestabilidad en los procesos.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| ma_lag (q) | Especifica el número de errores de pronóstico pasados utilizados para predecir valores futuros. | int | [0, 5] | 1 |
ARIMA (AutoRegressive Integrated Moving Average)
Explicación: ARIMA integra tres componentes:
- AR (AutoRegressive) – Utiliza valores pasados
- I (Integrated) – Elimina la tendencia y la no estacionariedad mediante diferenciación
- MA (Moving Average) – Modela el ruido residual
Al combinar estos, ARIMA captura tanto la dependencia temporal como los cambios de tendencia. Es altamente efectivo para series temporales estacionarias y para detectar desviaciones que violan las relaciones estadísticas establecidas a lo largo del tiempo.
Intuición matemática:
Y′ₜ = c + ∑ᵢ₌₁ᵖ φᵢ Y′ₜ₋ᵢ + ∑ⱼ₌₁ᵠ θⱼ εₜ₋ⱼ + εₜ Donde Yt′ es la serie diferenciada después de aplicar el orden d.
Caso de uso: Ampliamente utilizado en el monitoreo de indicadores económicos, detección de anomalías en registros del sistema y pronósticos de líneas de producción, donde es crucial detectar cambios en tendencias a largo plazo o estabilidad cíclica.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| ar_lag (p) | Número de observaciones retrasadas incluidas en el modelo. | int | [0, 5] | 1 |
| ma_lag (q) | Número de errores de pronóstico retrasados en la ecuación de predicción. | int | [0, 5] | 1 |
| integration (d) | Número de veces que los datos se diferencian para lograr la estacionariedad. | int | [0, 5] | 0 |
ARMA (AutoRegressive Moving Average)
Explicación: ARMA combina las fortalezas de los modelos AR y MA pero asume que la serie es estacionaria (sin diferenciación). Captura tanto la dependencia de observaciones pasadas como las correlaciones en los términos de error, proporcionando un equilibrio entre la sensibilidad a la tendencia y el filtrado de ruido.
Intuición matemática:
Yₜ = c + ∑ᵢ₌₁ᵖ φᵢ Yₜ₋ᵢ + ∑ⱼ₌₁ᵠ θⱼ εₜ₋ⱼ + εₜ Caso de uso: Se utiliza en el monitoreo de latencia de red, análisis de rendimiento de servidores y detección de anomalías en procesos estables, donde el comportamiento consistente a lo largo del tiempo hace que las pequeñas desviaciones sean altamente significativas.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| ar_lag (p) | Número de observaciones retrasadas utilizadas en el modelo. | int | [0, 5] | 1 |
| ma_lag (q) | Número de errores de pronóstico retrasados en el modelo. | int | [0, 5] | 1 |
Auto ARIMA
Explicación: Auto ARIMA automatiza la selección del modelo ARIMA evaluando múltiples combinaciones de parámetros (p,d,q) y opcionalmente parámetros estacionales basados en criterios de información (como AIC o BIC). Esto permite un ajuste óptimo sin la necesidad de ajustar manualmente los parámetros y asegura que el modelo se adapte a las dinámicas temporales cambiantes.
Intuición matemática: Selecciona automáticamente los parámetros minimizando:
AIC = 2k − 2ln(L) Donde k = número de parámetros y L = estimación de máxima verosimilitud.
Caso de uso: Ideal para pronósticos estacionales de retail, seguimiento de anomalías en el consumo de servicios públicos y monitoreo operacional automatizado, donde las series temporales exhiben irregularidades tanto periódicas como no periódicas.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| seasonal | Indica si el modelo debe tener en cuenta la estacionalidad. | bool | {True, False} | True |
| ar_lag (p) | Parámetro de retardo AR no estacional. | int | [0, 5] | 1 |
| ma_lag (q) | Parámetro de retardo MA no estacional. | int | [0, 5] | 1 |
| integration (d) | Orden de diferenciación no estacional. | int | [0, 5] | 0 |
| periodicity (s) | Longitud del período estacional (por ejemplo, 12 para datos mensuales). | int | [0, ∞) | 12 |
| integration (D) | Orden de diferenciación estacional. | int | [0, 5] | 0 |
| max_order | Orden total máximo del modelo (opcional). | int | [0, 5] | 5 |
SARIMA (Seasonal ARIMA)
Explicación: SARIMA extiende ARIMA incluyendo componentes autorregresivos estacionales, diferenciación y media móvil, permitiéndole modelar fluctuaciones periódicas (por ejemplo, ciclos diarios, mensuales, anuales). Sobresale en la detección de anomalías que ocurren en relación con las expectativas estacionales.
Intuición matemática:
Φᴾ(Bˢ) φᵖ(B) (1 − B)ᵈ (1 − Bˢ)ᴰ Yₜ = Θᵠ(Bˢ) θᵩ(B) εₜ Donde:
- s = período estacional
- (p,d,q) = parámetros no estacionales
- (P,D,Q) = parámetros estacionales
Caso de uso: Se aplica en la detección de anomalías en carga energética, monitoreo climático y análisis de estacionalidad de ventas, donde las desviaciones del comportamiento estacional esperado señalan anomalías potenciales.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| ar_lag (p) | Término AR no estacional. | int | [0, 5] | 1 |
| ma_lag (q) | Término MA no estacional. | int | [0, 5] | 1 |
| integration (d) | Diferenciación no estacional. | int | [0, 5] | 0 |
| seasonal_ar (P) | Término AR estacional. | int | [0, 5] | 1 |
| seasonal_ma (Q) | Término MA estacional. | int | [0, 5] | 1 |
| seasonal_integration (D) | Diferenciación estacional. | int | [0, 5] | 0 |
| periodicity (s) | Período estacional (por ejemplo, 12 para estacionalidad mensual). | int | [0, ∞) | 12 |
| enforce_stationarity | Si se debe forzar la estacionariedad en el modelo. | bool | {True, False} | False |
| enforce_invertibility | Si se debe forzar la invertibilidad del modelo. | bool | {True, False} | False |
Exponential Smoothing
Explicación: Exponential Smoothing predice valores futuros dando pesos exponencialmente decrecientes a las observaciones más antiguas. Esto enfatiza los datos recientes mientras mantiene la conciencia de la tendencia general. Es altamente receptivo a cambios repentinos en la tendencia o el nivel.
Intuición matemática:
Ŷₜ₊₁ = αYₜ + (1 − α)Ŷₜ Donde:
- Y^t+1 = pronóstico
- α = parámetro de suavizado (0–1)
- Yt = valor real
Caso de uso: Común en control de inventario, monitoreo de tendencias de ventas y telemetría de máquinas, donde la detección rápida de cambios o deterioro en el comportamiento reciente es vital.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| damped_trends | Si se debe aplicar amortiguación a los componentes de tendencia. | bool | {True, False} | False |
| season | Tipo de estacionalidad a aplicar. | string | {'Add', 'Mul'} | 'Add' |
| seasonal_periods | Número de períodos en un ciclo estacional completo. | int | [1, ∞) | 12 |
Holt-Winter’s Method
Explicación: El método de Holt-Winter (Triple Exponential Smoothing) extiende el suavizado exponencial añadiendo componentes de tendencia y estacionalidad. Puede adaptarse a cambios de nivel, tendencias ascendentes o descendentes y variaciones cíclicas, proporcionando una detección robusta de anomalías para series temporales periódicas.
Intuición matemática:
Lₜ = α (Yₜ / Sₜ₋ₛ) + (1 − α)(Lₜ₋₁ + Tₜ₋₁)
Tₜ = β (Lₜ − Lₜ₋₁) + (1 − β)Tₜ₋₁
Sₜ = γ (Yₜ / Lₜ) + (1 − γ)Sₜ₋ₛ
Ŷₜ₊ₘ = (Lₜ + mTₜ) Sₜ₋ₛ₊ₘ
Donde Lt = nivel, Tt = tendencia, St = componente estacional.
Caso de uso: Ampliamente utilizado en pronósticos de demanda de retail, monitoreo de utilización de recursos y detección de anomalías de temperatura, donde tanto la estacionalidad como los cambios de tendencia deben capturarse para una identificación precisa de anomalías.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| smoothing_level | Factor de suavizado para el componente de nivel. | float | [0, 1] | 0.8 |
| smoothing_trend | Factor de suavizado para el componente de tendencia. | float | [0, 1] | 0.2 |
| damping_trend | Controla la amortiguación del componente de tendencia. | bool | {True, False} | True |
| optimise | Especifica si los parámetros deben optimizarse automáticamente. | string | {'Select', 'Manual'} | 'Select' |
| exponential | Si se debe utilizar el suavizado de tendencia exponencial. | bool | {True, False} | False |
One-Class SVM
Explicación: One-Class SVM (Support Vector Machine) aprende un límite de decisión alrededor de la mayoría de los puntos de datos (normales) en el espacio de características. Los puntos que caen fuera de este límite se clasifican como anomalías. Funciona bien en conjuntos de datos de alta dimensionalidad y es efectivo cuando las anomalías son raras y distintas de los datos normales.
Intuición Matemática:
El algoritmo encuentra una función f(x) que es positiva para regiones con alta densidad de datos (puntos normales) y negativa para regiones de baja densidad (anomalías). Su objetivo es resolver:
min (1/2) ||w||² + (1 / (νn)) Σ ξᵢ − ρ
subject to:
(w · φ(xᵢ)) ≥ ρ − ξᵢ , ξᵢ ≥ 0 Donde:
- ν: controla el límite superior de valores atípicos
- ξi: variables de holgura que permiten márgenes suaves
- ϕ(x): función kernel que mapea datos a dimensiones superiores
Caso de uso: Se utiliza en detección de fraude, detección de intrusiones en la red o detección de novedades en sistemas industriales donde el comportamiento normal está bien definido pero las anomalías son raras.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| kernel | Especifica el tipo de kernel a utilizar. Si no se proporciona ninguno, se usa 'rbf'. | string | {'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'} | 'rbf' |
| degree | Grado de la función kernel polinómica ('poly'). Ignorado por otros kernels. | int | [1, ∞) | 3 |
| gamma | Coeficiente del kernel para 'rbf', 'poly' y 'sigmoid'. | string | {'scale', 'auto'} | 'scale' |
| coef0 | Término independiente en la función kernel, significativo en 'poly' y 'sigmoid'. | float | [0, 1] | 0.0 |
| tol | Tolerancia para el criterio de parada. | float | [0, 1] | 1e-3 |
| nu | Límite superior de la fracción de errores de entrenamiento y límite inferior de la fracción de vectores de soporte. | float | (0, 1] | 0.5 |
| shrinking | Si se debe usar la heurística de reducción. | bool | {False, True} | True |
| max_iter | Límite estricto en las iteraciones del solver, o -1 sin límite. | int | [1, ∞), {-1} | -1 |
Isolation Forest
Explicación: Isolation Forest identifica anomalías aislando observaciones en lugar de modelar puntos de datos normales. Selecciona aleatoriamente una característica y divide los datos basándose en un umbral aleatorio. Dado que las anomalías son pocas y diferentes, son más fáciles de aislar y requieren menos divisiones. La longitud promedio del camino en los árboles es más corta para las anomalías y más larga para los puntos normales.
Intuición matemática:
La puntuación de anomalía se calcula como:
s(x, n) = 2^(− E(h(x)) / c(n)) Donde:
- E(h(x)): longitud promedio del camino de la observación x
- c(n): longitud promedio del camino de una búsqueda no exitosa en un Árbol de Búsqueda Binario
- Puntuaciones cercanas a 1 → anomalías; cercanas a 0.5 → normales
Caso de uso: Comúnmente utilizado en detección de fraude, detección de intrusiones en la red, detección de defectos de fabricación e identificación de anomalías en sensores IoT. En la detección de fraude, ayuda a descubrir transacciones sospechosas que se desvían del comportamiento de gasto normal. En la detección de intrusiones en la red, identifica patrones de acceso anormales o picos de tráfico que pueden indicar una brecha de seguridad.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| n_estimators | Número de estimadores base (árboles) en el conjunto. | int | [1, ∞) | 100 |
| max_samples | Número de muestras a extraer para entrenar cada estimador. | string, int, float | [1, ∞), [0, 1], {'auto'} | 'auto' |
| contamination | Proporción de valores atípicos en el conjunto de datos. | string, float | {'auto'}, (0, 0.5] | 'auto' |
| max_features | Número de características a extraer para cada estimador. | int, float | [1, ∞), [0, 1] | 1.0 |
| bootstrap | Si se deben muestrear los datos de entrenamiento con reemplazo. | bool | {False, True} | False |
Local Outlier Factor (LOF)
Explicación: Local Outlier Factor detecta anomalías comparando la densidad local de un punto de datos con la de sus vecinos. Si un punto tiene una densidad sustancialmente menor que sus vecinos, se considera una anomalía. LOF es particularmente efectivo para detectar anomalías locales en lugar de globales.
Intuición matemática:
LOF se basa en el concepto de densidad de alcanzabilidad local (LRD). La puntuación LOF de un punto de datos A viene dada por:
LOFₖ(A) = ( Σ_{B ∈ Nₖ(A)} [LRDₖ(B) / LRDₖ(A)] ) / |Nₖ(A)| Donde:
- Nk(A): k-vecinos más cercanos de A
- LRDk(A): densidad de alcanzabilidad local de A
- Valores ≈ 1 → normales, > 1 → valor atípico
Caso de uso: Se utiliza efectivamente en diversos dominios donde es esencial identificar desviaciones locales de los patrones normales. En la detección de fraude, destaca clientes o transacciones que se comportan de manera diferente a sus grupos de pares, ayudando a descubrir patrones de fraude sutiles o en evolución. Para la segmentación de clientes, detecta perfiles atípicos dentro de segmentos definidos, como clientes inusualmente de alto valor o inactivos, permitiendo estrategias de targeting y retención más precisas.
Parámetros clave:
| Parámetro | Descripción | Tipo de Dato | Valores Posibles | Valor Predeterminado |
|---|---|---|---|---|
| n_neighbors | Número de vecinos a usar para consultas de kneighbors. | int | [1, n_samples) | 20 |
| algorithm | Algoritmo utilizado para calcular los vecinos más cercanos. | string | {'auto', 'ball_tree', 'kd_tree', 'brute'} | 'auto' |
| leaf_size | Tamaño de hoja para BallTree o KDTree, que afecta la velocidad y la memoria. | int | [1, ∞) | 20 |
| metric | Métrica para el cálculo de distancia. | string | {'cityblock', 'cosine', 'euclidean', 'haversine', 'l1', 'l2', 'manhattan', 'nan_euclidean'} | 'minkowski' |
| p | Parámetro para la métrica de Minkowski (1=Manhattan, 2=Euclidean). | float | [1, ∞) | 2 |
| contamination | Proporción de valores atípicos en el conjunto de datos. | float, string | (0, 0.5], {'auto'} | 'auto' |
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us