Técnicas de Preprocesamiento de Datos en QuickML
QuickML proporciona las principales técnicas de preprocesamiento de datos divididas en tres categorías principales.
- Data Cleaning
- Data Transformation
- Dataset Extraction
Todas las operaciones listadas en las próximas secciones están disponibles como etapas en el proceso de construcción del pipeline que ayuda al usuario a crear mejores modelos de aprendizaje automático.
Data Cleaning es el proceso de corregir o eliminar datos incorrectos, corruptos, con formato incorrecto, duplicados o incompletos dentro de un dataset. Si los datos son incorrectos, los resultados y algoritmos no serán confiables.
-
Fill Columns
Se utiliza para cambiar los valores de una columna específica basándose en los criterios establecidos por el usuario. Si los criterios no se especifican en la configuración, entonces todos los valores en esa columna serán reemplazados por el valor/método específico del usuario.
Ejemplo:
Para datos de población de un país que contienen detalles del paciente como nombre, edad, dirección, elegible para votar, etc., podemos rellenar la columna de elegible para votar como sí para todas las personas cuya edad sea mayor de 18 como criterio. -
Filter
Se utiliza para extraer los datos del dataset que necesitamos preprocesar aplicando criterios en la configuración. También podemos utilizar los datos que no satisfacen los criterios para el preprocesamiento.
Ejemplo:-
Single Output Filter:
En un dataset de estudiantes, si solo requerimos los datos del departamento CSE, podemos establecer el criterio como dept=CSE, lo que reducirá los datos que necesitamos preprocesar. -
Double Output Filter:
Si se requiere preprocesar los datos tanto de chicos como de chicas del dataset de estudiantes en un flujo diferente, podemos usar la casilla “Show unmatched records as secondary output” en la configuración. Esto será útil si deseas realizar alguna operación o proceso especial para los datos no coincidentes del nodo de filtro.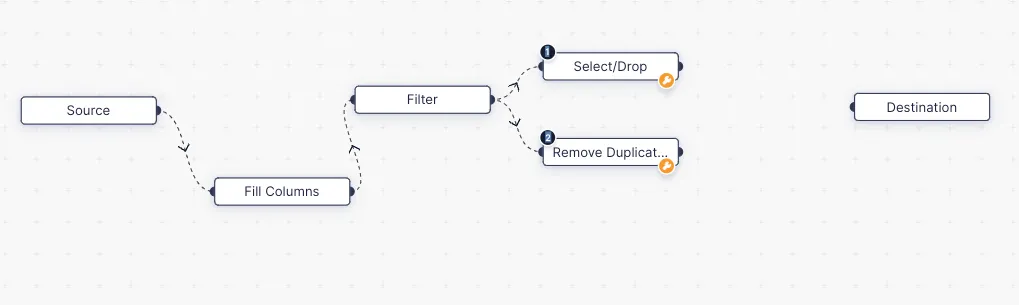
-
-
Remove Duplicates
Se utiliza para eliminar las filas duplicadas en el dataset. También podemos controlar cómo deben eliminarse las filas duplicadas.
Ejemplo:
Para un dataset de estudiantes que tenía cinco filas duplicadas con ID de estudiante 101 en los índices 1, 5, 7. Opción de preferencia de conservación:
First - El dataset de salida tendrá solo la fila en el índice 1, las otras filas en los índices 5 y 7 serán eliminadas.
Last - El dataset de salida tendrá solo la fila en el índice 7, las otras filas en los índices 1 y 5 serán eliminadas.
None - El dataset de salida no tendrá filas duplicadas, las filas en los índices 1, 5 y 7 serán eliminadas. -
Select or Drop
Se utiliza para seleccionar o eliminar columnas en el dataset. Si un usuario necesita tener solo dos columnas del dataset, simplemente puede seleccionar las dos columnas requeridas del menú desplegable y elegir la operación de selección. Para eliminar columnas, elige la operación de eliminación.
Última actualización 2026-03-24 17:38:39 +0530 IST
Yes
No
Send your feedback to us