時系列データの概要
時系列とは、1つ以上の特徴が時間の経過とともにどのように変化するかを表すデータポイントのシーケンスを指します。これらのデータポイントは一定の間隔で記録され、時間の経過に伴うトレンド、季節性の変化、パターン、異常の分析を可能にします。
時系列データは、1つの特徴のみが記録される単変量と、複数の特徴が同時に追跡される多変量の2つのタイプに分類できます。
時系列分析の主な目的は、多くの場合、特徴の将来の値を予測することであり、これは予測や異常検知などのタスクにおけるターゲット変数として機能します。
時系列の構成要素
時系列の構成要素は、データ系列の時間経過に伴う基本的なパターンや挙動を特徴付けます。これらは観測されたデータポイントの値に影響を与える要因にすぎません。これらの構成要素を理解することで、より優れた正確なモデルの作成に役立ちます。時系列データの4つの構成要素は以下の通りです:
- トレンド
- 季節性
- 循環性
- ノイズ
1. トレンド
トレンド成分は、時系列における長期的な方向性や動きを表します。データが時間の経過とともに全般的に増加しているか、減少しているか、または一定であるかを示します。
特徴
- より長い期間にわたる系列の基本的な傾向を反映します。
- トレンドは線形または非線形の場合があります。
- トレンドは短期的な変動や不規則性の影響を受けません。
例
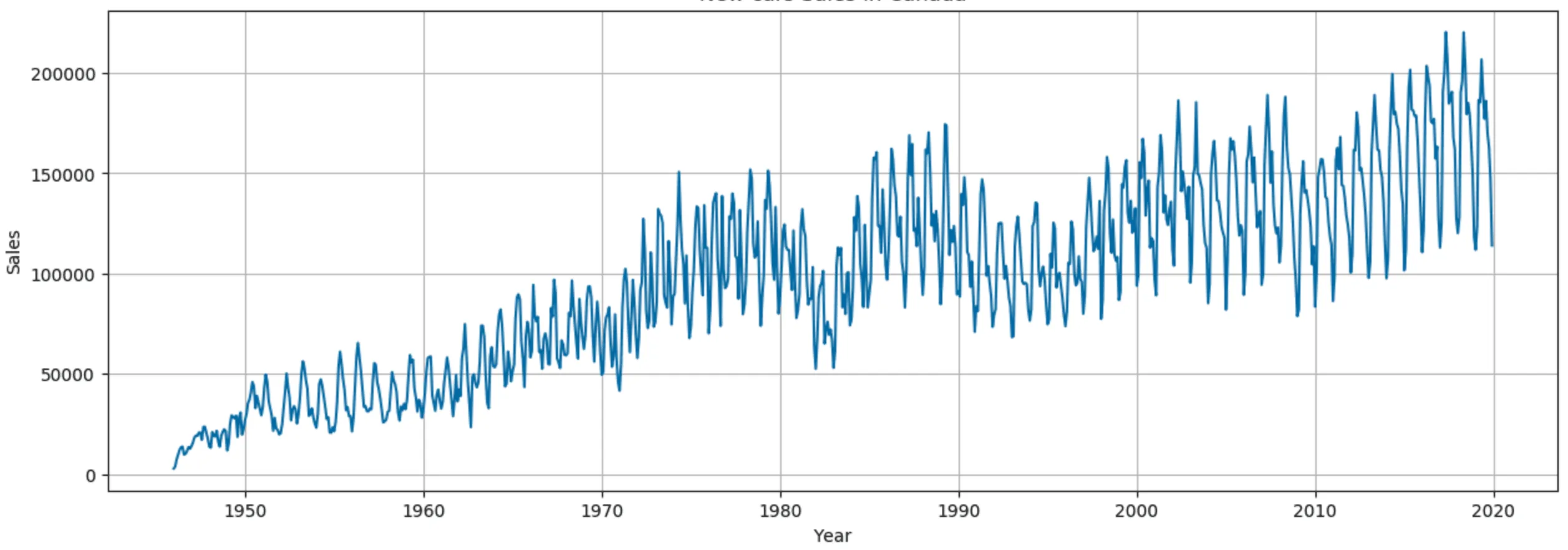
企業の売上データにおいて、数年にわたる売上の着実な増加は正のトレンドを示しています。
2. 季節性
季節性成分は、日次、月次、年次など、固定された期間内で発生する規則的で繰り返しのパターンを時系列中に表します。
特徴
- 季節性は一定の間隔で発生し、固定された周期を持ちます。
- 天候、祝日、文化的なイベントなどの外部要因によって駆動されることが多いです。
- 季節性の効果は予測可能であり、毎年、毎月、毎週、または毎日同じ時期に繰り返し発生します。
例
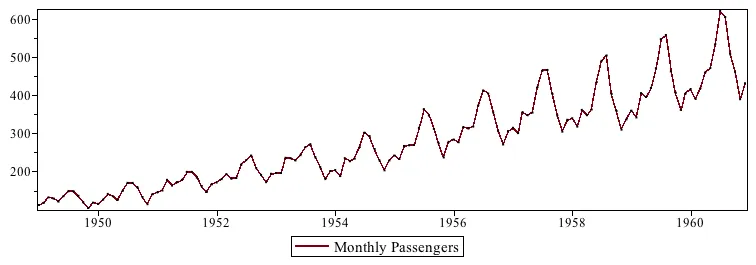
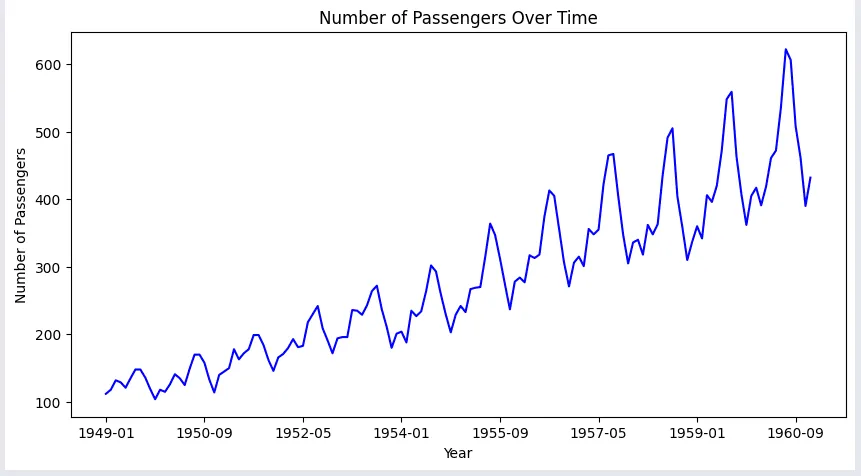
この例は、1949年から1960年までの各月の月間乗客数を示しており、チャートで乗客の季節的な分布を確認できます。
3. 循環性
循環性成分は、通常、経済サイクルやビジネスサイクルの影響を受けて、より長い期間にわたって発生する時系列の変動を指します。
特徴
- サイクルは通常、周期と振幅が不規則です。
- 1年以上、多くの場合数年続くことがあります。
- 季節性とは異なり、循環パターンはその頻度と持続期間において予測が困難ですが、より広範な経済的要因の影響を受けます。
例
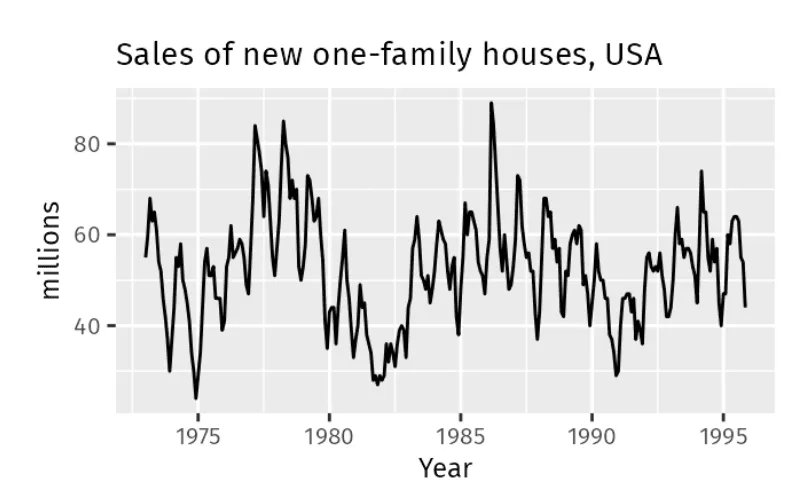
新築ファミリー住宅の売上は特定の期間に変動しますが、グラフに示されているように、これらの変化は季節性ではありません。これらの変動は、季節パターンよりも予測が困難な景気拡大期と景気後退期の影響を受けている可能性があります。
4. ノイズ
ノイズ成分は、トレンド、循環性、または季節性パターンに帰属できない時系列のランダムな変動を捉えます。データの予測不可能で不規則な変動を表します。
特徴
- ノイズは、トレンド、循環性、および季節性成分を除去した後の時系列の残差部分です。
- ランダムで予測不可能です。
- ノイズは特定のパターンに従わず、ランダムな要因や測定誤差によって引き起こされる可能性があります。
例
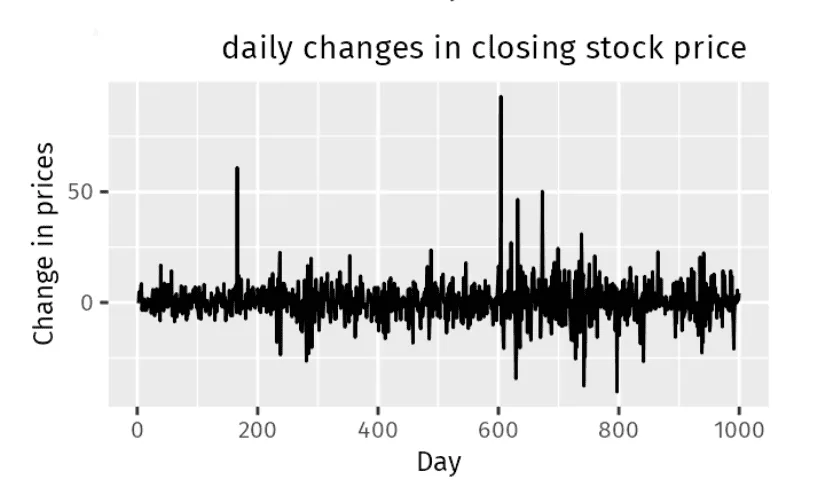
グラフから結論づけられるように、企業の株価変動には特定のトレンド、季節性、または循環パターンはありません。価格の変動は、予測可能なパターンのないランダムな上昇と下降として現れています。
定常性
定常性とは、平均、分散、自己相関などの統計的特性が時間の経過とともに一定のままである時系列データの特性を指します。
- 平均は、一定期間における観測値の平均値です。
- 分散は、平均周辺の値の広がりまたは分散の尺度です。
- 自己相関は、系列とその以前の値との相関です。
系列が定常であると結論づけるためには、時系列データのこれら3つの統計的特性すべてが時間の経過とともに一定でなければなりません。系列が定常であるかどうかを理解することは、効果的な時系列モデルを構築するために必要な前処理の種類を判断するために重要です。系列が定常である場合、記録された値は変化しないか、時間の経過とともに同じ範囲内に留まります。
記録された系列が定常または非定常と見なされるユースケースの例を見てみましょう。
a. 非定常系列
時系列データは、トレンド、季節性、循環性、またはノイズの存在により、記録された値が異なる時点で影響を受けた場合、非定常と見なされます。
例:
航空会社の乗客数は、プロットに示されているように、毎年の季節変動を伴いながら増加トレンドにあります。したがって、この系列は非定常系列と見なされます。
定常性の有無を評価するためのADFテスト結果
ADF Statistic: 0.81
p-value: 0.99
Critical Values: {'1%': -3.48, '5%':-2.88, '10%': -2.57}
Fail to reject the null hypothesis: The series is not stationary.
b. 定常系列
系列が定常である場合、記録された値は変化しないか、時間の経過とともに同じ範囲内に留まります。
例:
ラグ2の差分変換手法を適用した後、非定常系列は定常系列に変換されます。変換された値をチャートにプロットすると、以下のように表示されます:
データ変換後の定常性の有無を評価するためのADFテスト結果
ADF Statistic: -2.96
p-value: 0.03
Critical Values: {
'1%': -3.48,
'5%': -2.88,
'10%':-2.57
}
Reject the null hypothesis: The series is stationary.
時系列モデルは通常、定常データを使用して構築されます。系列が非定常の場合、正確な将来の予測を確保するために、モデルのトレーニング前に定常系列に変換する必要があります。ADFテストとKPSSテストとして知られる2つの統計検定を時系列データに対して実行し、系列に定常性が存在するかどうかを判定します。
定常性の検定
時系列における定常性とは、系列の統計的特性が時間の経過とともに変化しないことを意味します。言い換えれば、系列の異なる部分を見ても、統計的に類似しているはずです。系列が定常であるためには、一定の平均、一定の分散、一定の自己相関を持つ必要があります。
時系列データに対して定常性の有無を確認するために実行できる統計的手法には2つのタイプがあります。ADFテストとKPSSテストです。ただし、定常性検定に進む前に、統計検定における仮説という概念を理解しましょう。
仮説: 仮説検定は、利用可能なデータ全体から抽出されたサンプルデータを使用して、データセットに関する推論や結論を導くために使用される統計的手法です。サンプルにおいて、データセット全体に関する特定の主張や仮説を支持または棄却するのに十分な証拠があるかどうかを判断するのに役立ちます。
- 帰無仮説(H₀): 効果や差異がないという仮定です。現状を表します。
- 対立仮説(H₁): 帰無仮説の反対であり、新しい主張や効果を表します。これが検定の対象となります。
仮説の意味を理解したところで、定常性検定を見てみましょう:
-
ADFテスト
拡張ディッキー・フラー(ADF)テストは、時系列に単位根があるかどうかを判定するために使用される統計検定です。単位根の存在は、値が以前の値に強く依存していることを示し、系列が非定常であることを意味します。
目的: ADFテストは、系列に単位根が含まれているかどうかを確認するために使用されます。
帰無仮説: 時系列には単位根があり、したがって非定常です。
解釈: ADF検定統計量が臨界値より小さい場合、帰無仮説は棄却され、時系列が定常であると結論づけられます。
検定プロセス: ADFテストは、帰無仮説を検定することで、時系列における単位根の存在を確認します。単位根の存在は系列が非定常であることを示します。
-
KPSSテスト
クワトコフスキー・フィリップス・シュミット・シン(KPSS)テストは、時系列の定常性を確認するために使用されるもう1つの統計検定です。ADFテストとは異なり、時系列が平均または確定的トレンドの周りで定常であるという帰無仮説を検定します。
目的: KPSSテストは、系列が定常であるかどうかを確認するために使用されます。
帰無仮説: 時系列は一定の平均または確定的トレンドの周りで定常です。
解釈: KPSS検定統計量が臨界値より大きい場合、帰無仮説は棄却され、系列が非定常であることを示します。
検定プロセス: KPSSテストは、確定的トレンドまたは平均の周りで変動する時系列が定常であるかどうかを検定します。
検定結果の解釈方法
ADFテストとKPSSテストは、系列が定常であるかどうかを分類するのに役立ついくつかの統計値を生成します。これらの値は以下の通りです:
- 検定統計量
- P値
- 1%、5%、10%信頼区間における臨界値
検定統計量
検定統計量は、帰無仮説が真であった場合にその値がどの程度起こりやすいかを判定するために検定で計算される値です。
サンプルデータに基づいて検定統計量を計算します。
- z検定の場合:検定統計量は z = (X̄ - μ) / ( σ/ √n)(全データの統計値)
- t検定の場合:検定統計量は t = (X̄ - μ) / (s / √n)(サンプルデータの統計値)
ここで、X̄はサンプル平均、μは母平均、sはサンプルの標準偏差またはσは全データの標準偏差、nはサンプルサイズです。
QuickMLでは、ADFおよびKPSSの検定統計量は、入力データ全体に対するそれぞれの検定から計算されます。これらの検定統計量は両方とも、帰無仮説に対する証拠の尺度を提供します。
証拠の強さは、検定統計量の値を1%、5%、10%の有意水準における臨界値と比較することにより、強い、中程度、弱いの3段階で評価されます。
P値
P値とは? 両検定におけるP値は、帰無仮説が真であると仮定した場合に、観測された検定統計量の値と同程度またはそれ以上に極端な値が得られる確率を示します。P値は統計表から取得でき、帰無仮説を棄却すべきかどうかを判定するために使用されます。
どのように導出されるか?
- ADF / KPSS回帰モデルの定式化と推定
- 上記の通り検定統計量 t𝛄 を計算
- シミュレーションから導出された臨界値と t𝛄 を比較
- 帰無仮説の下で検定統計量が臨界値とどのように比較されるかに基づいて、近似P値を内挿して取得
ADFテストの場合
帰無仮説: 時系列には単位根があり、非定常であることを意味します。
解釈: 有意水準を5%と仮定します。
- 低いP値(≤ 0.05): 低いP値は、単位根の帰無仮説を棄却できることを示し、系列が定常であることを示唆します。
- 高いP値(> 0.05): 高いP値は、単位根の帰無仮説を棄却できなかったことを示し、系列が非定常であることを示唆します。
KPSSテストの場合
帰無仮説: 時系列は一定の平均または確定的トレンドの周りで定常です。
解釈: 信頼区間を5%と仮定します。
- 低いP値(≤ 0.05): 低いP値は、帰無仮説を棄却することを示唆し、系列が非定常であることを示します。
- 高いP値(> 0.05): 高いP値は、定常性の帰無仮説を棄却できないことを示唆します。
臨界値(1%、5%、10%水準):
臨界値は、拡張ディッキー・フラー(ADF)テストやクワトコフスキー・フィリップス・シュミット・シン(KPSS)テストなどの定常性検定において、帰無仮説を棄却するか棄却しないかを判定するために使用される事前定義された閾値またはベンチマークです。これらの値は、検定結果の統計的有意性を評価するのに役立ちます。
これらの値は、ADFおよびKPSS検定の両方における意思決定のベンチマークとして機能します。例えば、5%の有意水準の場合:
- 1%における臨界値: 非常に厳格な基準です。検定統計量の値が1%の臨界値よりも極端であれば、帰無仮説を棄却するための強い証拠があります。
- 5%における臨界値: 検定統計量が5%の臨界値よりも極端であれば、帰無仮説を棄却するための中程度の証拠があります。
- 10%における臨界値: より緩い基準です。検定統計量が10%の臨界値よりも極端であれば、帰無仮説を棄却するための弱い証拠があります。
例:
| ADF Test | KPSS Test |
|---|---|
|
|
|
|
検定の可能な結果
両方の検定を適用した場合の可能な結果は以下の通りです。
結果1: 両方の検定が、与えられた系列が定常であると結論づける場合 - 系列は定常です。
結果2: 両方の検定が、与えられた系列が非定常であると結論づける場合 - 系列は非定常です。
結果3: ADFが非定常と結論づけ、KPSSが定常と結論づける場合 - 系列はトレンド定常です。系列を厳密に定常にするためには、この場合トレンドを除去する必要があります。その後、トレンド除去された系列の定常性が確認されます。
結果4: ADFが定常と結論づけ、KPSSが非定常と結論づける場合 - 系列は差分定常です。系列を定常にするために差分が使用されます。差分された系列は、その後定常性が確認されます。
列に存在する定常性への対処方法
QuickMLでは、上記で説明したように、拡張ディッキー・フラー(ADF)テストとクワトコフスキー・フィリップス・シュミット・シン(KPSS)テストの両方を使用して、時系列データセットの各特徴の定常性を確認します。
QuickMLプラットフォームは、データセット内の非定常列を変換するのに役立つデータ変換手法のセットを提供します。これらの列を定常に変換することで、QuickMLは変換されたデータを使用して生成されたモデルが基礎的なパターンとトレンドを捉えるのに適していることを保証します。
列に存在する定常性に対処するために主に使用される2つのデータ変換手法は以下の通りです:
差分
差分は、連続する観測値間の差を計算することで行われます。時系列の水準の変化を除去することで平均を安定化させ、トレンドと季節性を除去(または軽減)するのに役立ちます。
差分の次数は、非定常系列を定常系列に変換するために差分を実行する回数を示します。QuickMLで指定できる最大差分次数は5です。5次の差分を行っても系列が非定常の場合、パワー変換のいずれかの方法を適用して時系列の分散を安定化できます。
パワー変換
パワー変換は、変数の確率分布をよりガウス分布に近づけます。これは一般的に分布のスキュー(歪度)を除去すると説明されますが、より一般的には分布の分散を安定化させると説明されます。対数変換に加えて、変数をガウス確率分布に最も適切に変換するパラメータ(ラムダ)を見つける変換の一般化バージョンを使用できます。
QuickMLでは、2種類のパワー変換が利用可能です
- Box-Cox変換
Box-Cox変換は、スキューを軽減し分散を安定化させるデータの最適なパワー変換を見つけることを目的としています。データが不均一分散(予測変数のレベルにわたって不均等な分散)やスキューを示す場合に効果的です。 - Yeo-Johnson変換
Yeo-Johnson変換は、ターゲット変数の正の値と負の値の両方を扱えるBox-Cox変換の修正版です。Box-Coxと同様に、Yeo-Johnsonはデータを変換して分散を安定化させ、分布を正規化します。負の値を扱えるため、より柔軟です。Yeo-Johnsonは、元のBox-Coxでは扱えないゼロや負の値を含むデータの場合に好まれることが多いです。
Yeo-Johnson変換のパラメータ(通常ラムダと呼ばれます)は、変換の性質を制御するために使用されます。ラムダの値に基づいて異なる変換手法が選択されます。
- lambda = -1. は逆数変換です。
- lambda = -0.5 は逆数平方根変換です。
- lambda = 0.0 は対数変換です。
- lambda = 0.5 は平方根変換です。
- lambda = 1.0 は変換なしです。
モデル評価指標
予測のための指標
時系列分析における予測を評価する際、モデルの精度とパフォーマンスを評価するためにいくつかの指標が一般的に使用されます。各指標は、予測値が実際の観測値とどの程度一致しているかについて異なるインサイトを提供します。
1. Mean Absolute Percentage Error(MAPE)
MAPEは、実際の値に対する予測値と実際の値の平均絶対パーセンテージ差を表します。予測の相対的な精度に関するインサイトを提供し、異なるデータセットやスケールにわたるモデルの精度を比較する際に特に有用です。
解釈:
例えば、MAPEの値が8%の場合、モデルの予測が実際の値から平均8%乖離しているため、比較的正確であることを示します。一般的に、MAPEの値が10%未満はモデルが非常に正確であることを示し、10〜20%は良好であり、20%を超える値はモデルパフォーマンスの改善が必要であることを示す場合があります。
2. Symmetric Mean Absolute Percentage Error(SMAPE)
SMAPEは、分母に実際の値と予測値の絶対値の平均を使用することで、MAPEにおける非対称性の問題に対処します。データセット内の小さな値やゼロの値を扱う場合に好まれることが多く、ゼロ除算を回避し、より均衡の取れた精度の尺度を提供します。
解釈:
SMAPEは、特に実際の値が小さいかゼロの場合に、誤差のバランスの取れた視点を提供します。分母に実際の値と予測値の平均を使用することで、SMAPEは非対称性の影響を軽減します。SMAPEの値が低いほど、実際の値と予測値のパーセンテージ差が小さく、モデルの精度が優れていることを示します。MAPEなどの他の指標に見られる極端なパーセンテージ誤差の問題を回避する対称的な尺度を提供します。
3. Mean Square Error(MSE)
MSEは誤差の二乗の平均を測定し、大きな誤差により大きな重みを与えます。誤差の広がりに関するより詳細なインサイトを提供しますが、二乗操作のため外れ値に大きく影響される可能性があります。MSEは、大きな誤差をより顕著にペナルティするのに有用です。
解釈:
MSEは誤差の分散を強調し、二乗関数により大きな誤差がより大きな重みを受けます。この指標は外れ値に特に敏感であり、実際の値からの大きな逸脱にペナルティを与えたい場合に理想的です。MSEが低いほど、平均的に誤差が少なく小さいモデルであることを示しますが、外れ値によって不均衡に影響を受ける可能性があります。誤差の広がりを理解するのに有用ですが、現実世界の単位では解釈しにくい場合があります。
4. Root Mean Square Error(RMSE)
RMSEはMSEの平方根であり、元のデータと同じ単位でより解釈しやすくなっています。MSEと同様に、RMSEは誤差の平均的な大きさの尺度を提供し、値が高いほど平均誤差が大きいことを示します。広く使用されており、誤差の大きさへの感度と解釈のしやすさのバランスが良い指標です。
解釈:
RMSEは平均的な誤差の大きさを提供し、元のデータと同じ単位を保持するため、MSEよりも解釈しやすくなっています。RMSEは大きな誤差に敏感であり、典型的な予測誤差を理解するために一般的に使用されます。RMSEの値が低いほど、誤差が小さくモデルの予測精度が優れていることを示します。元のデータの単位で誤差を解釈するのに有用で、誤差の「大きさ」を明確に把握できます。
5. Mean Square Log Error(MSLE)
MSLEは、予測値に1を加えた自然対数と実際の値に1を加えた自然対数の差の二乗の平均を計算します。過大予測よりも過小予測により重いペナルティを与えます。
解釈:
MSLEは、対数変換を適用することで大きな値の影響を緩和し、予測値と実際の値の比率に焦点を当てます。この指標は、過大予測よりも過小予測により重いペナルティを与えるため、過小評価が過大評価よりも有害であるモデルに適しています。MSLEの値が低いほど、対数スケールで予測値が実際の値に密接に一致していることを意味し、大きな値の高分散に対するペナルティを軽減し、乗法スケールでのパフォーマンスを重視します。
6. Root Mean Square Log Error(RMSLE)
RMSLEはMSLEの平方根です。ターゲット変数と同じ単位でより解釈しやすい尺度を提供します。MSLEと同様に、RMSLEは二乗差により過小予測に対してより重いペナルティを与えます。
解釈:
RMSLEはMSLEの平方根であり、対数スケール上ではありますが、元の単位での解釈のしやすさを維持しています。MSLEと同様に、RMSLEは過小予測により重いペナルティを与え、低い範囲の誤差を優先する尺度を提供します。RMSLEの値が低いほど、対数スケールで予測値と実際の値がより密接に一致していることを示し、大きな正の乖離は許容できるが過小評価は最小限に抑える必要がある場合に理想的です。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us