モデル
MLパイプラインが正常に実行されると、対応するMLモデルが作成されます。このモデルビューを使用して、内部指標を理解することができます。
作成されたモデルの一覧は、以下のように各モデルのステータスとともにModelsページで確認できます。
モデル指標
QuickMLユーザーは、各バージョンのモデル指標にアクセスでき、機械学習モデルのパフォーマンスに関する価値ある洞察を得ることができます。これらの指標は、予測におけるモデルの精度と有効性を評価するための重要な指標として機能します。
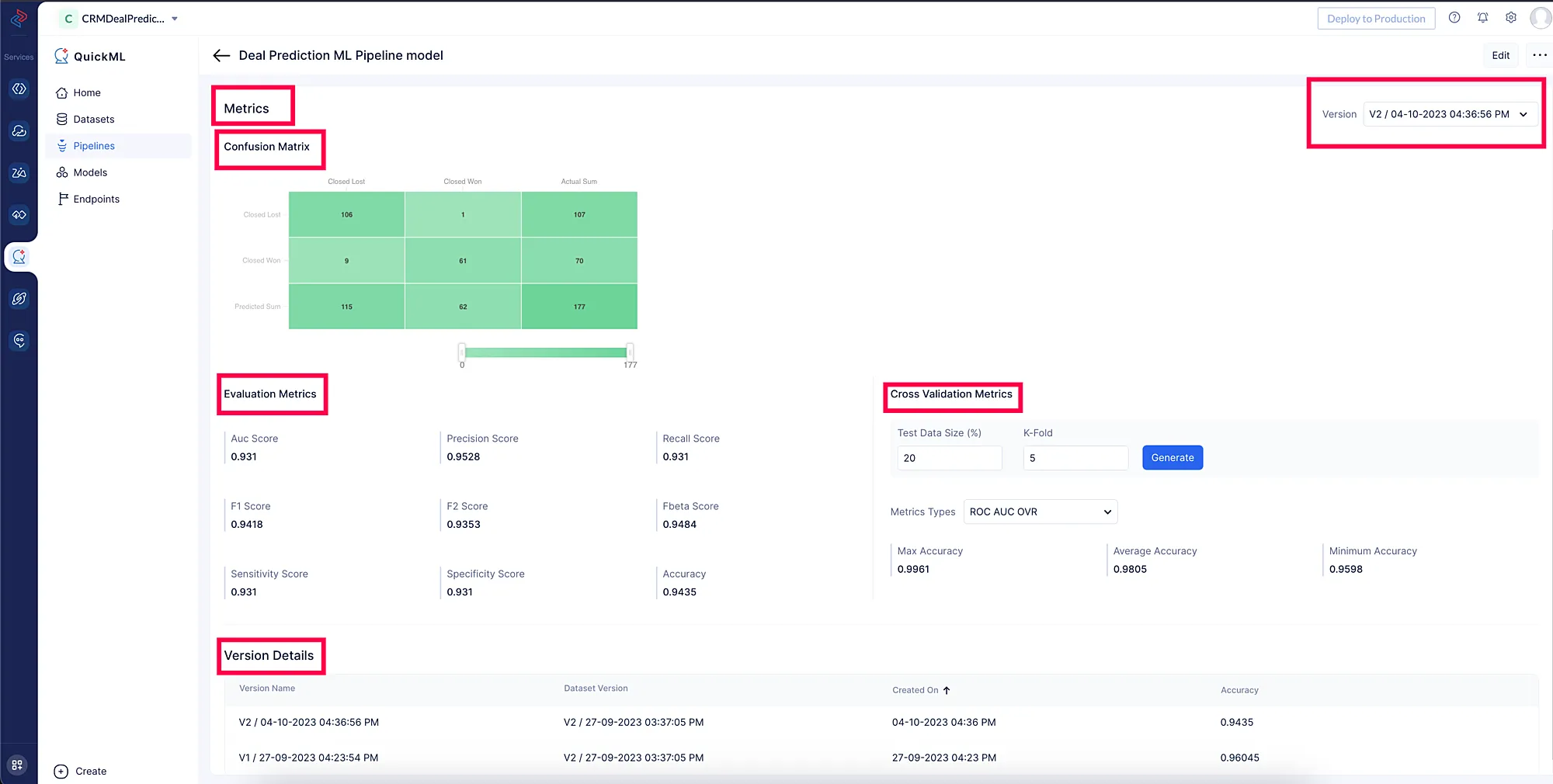
QuickMLユーザーは以下の指標にアクセスできます。
混同行列
機械学習において、混同行列は分類モデルのパフォーマンスを測定するために使用されます。簡単に言うと、混同行列は機械学習モデルが行った正しい予測と誤った予測の数をまとめたものです。行列は、以下のように真陽性(TP)、真陰性(TN)、偽陽性(FP)、偽陰性(FN)の数を表示します。

TP: 真陽性は、予測値と実際の値の両方が陽性であるインスタンスの数です。
TN: 真陰性は、予測値と実際の値の両方が陰性であるインスタンスの数です。
FP: 偽陽性は、モデルが陽性と予測したが実際の値が陰性であるインスタンスの数です。
FN: 偽陰性は、モデルが陰性と予測したが実際の値が陽性であるインスタンスの数です。
ユースケース
混同行列をユースケースで説明しましょう:航空会社のフライトサービスに対する乗客の満足度を予測します。
概要説明: 航空会社は、乗客のデモグラフィック情報、フライト情報、航空会社のサービスに対する満足度に関するアンケート回答を含む乗客情報を収集します。その後、航空会社はこの情報を使用して、乗客が満足か中立/不満かを予測する機械学習分類モデルを作成します。
以下のように、QuickMLで混同行列を使用した分類モデルのパフォーマンスを評価しましょう:
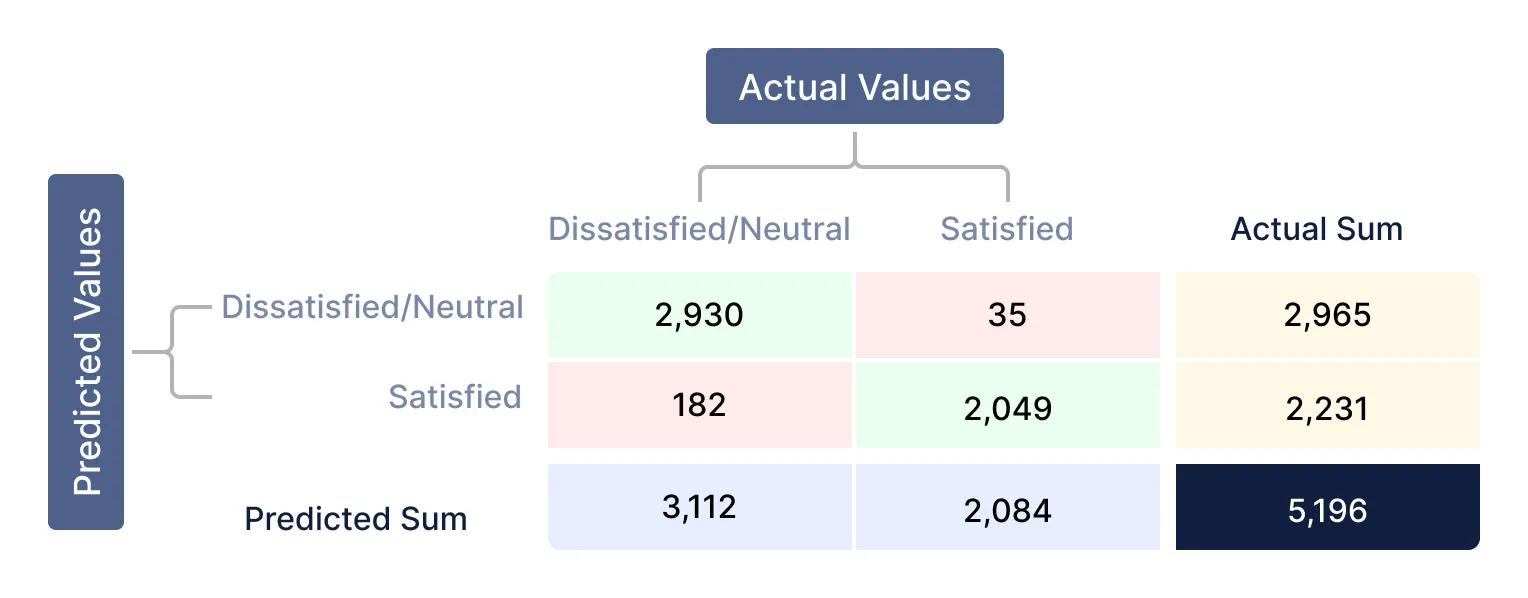
混同行列から得られた値:
| 総回答数 | 5,196 | 真陽性(TP) | 2,930 | 偽陰性(FN) | 182 | 偽陽性(FP) | 35 | 真陰性(TN) | 2,049 |
|---|
分類モデルを評価するために一般的に使用されるパフォーマンス指標は以下の通りです。
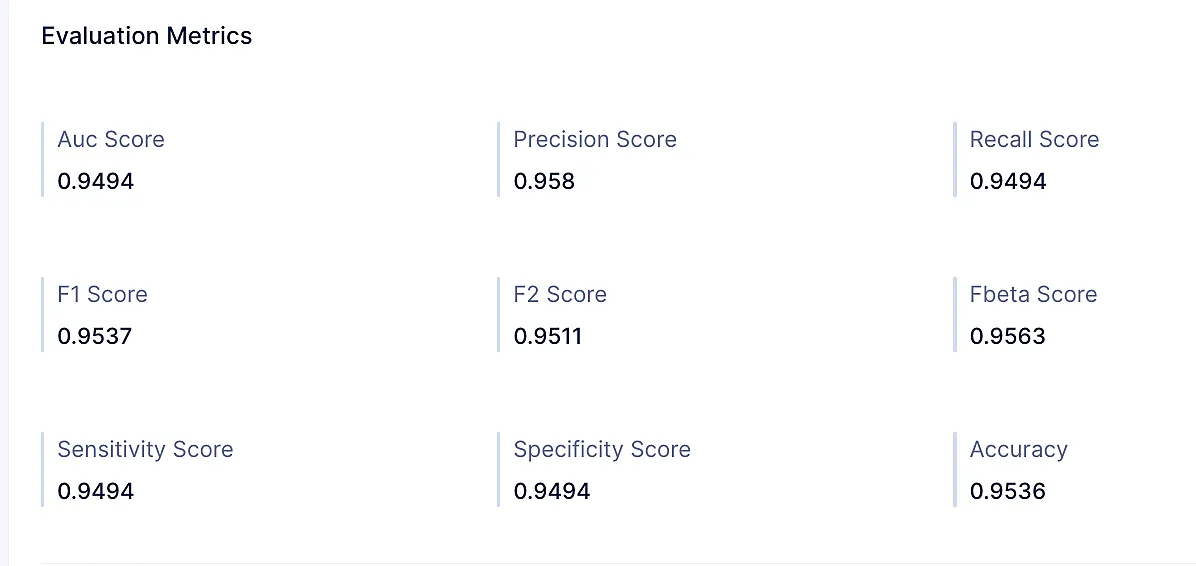
正解率スコア: 全インスタンスに対する正しく予測されたインスタンスの割合。
Accuracy = TP+TN/Total Responses = (2,930+2,049)/5,196 = 0.958適合率スコア: 適合率は、モデルの陽性予測がどれだけ正確であるかを示す指標です。真陽性予測の数を真陽性と偽陽性の予測の合計で割って計算されます。
Precision = TP/(TP+FP)= 2,930/(2,930+35) = 0.988再現率スコア: 再現率スコアは感度とも呼ばれ、モデルが正しく予測した実際の陽性ケースの割合です。真陽性予測の数を真陽性と偽陰性の予測の合計で割って計算されます。
簡単に言うと、再現率スコアは、モデルがデータセット内のすべての陽性ケースをどれだけうまく識別できるかを測定します。高い再現率スコアは、モデルがすべての陽性ケースを見つけるのに優れていることを意味し、低い再現率スコアは、モデルが多くの陽性ケースを見逃していることを意味します。
Recall score = TP/(TP+FN) = 2930/3112 = 0.941F1スコア: 適合率と再現率の調和平均であり、モデルのパフォーマンスのバランスの取れた評価を提供します。
F1 Score = 2*Recall*Precision/(Recall+Precision)
= 2*0.941*0.988/(0.941+0.988)
= 0.9639上記の指標から、モデルについていくつかの結論を導くことができます。
- 航空会社モデルは4,979人の乗客の満足度レベルを正確に予測しましたが、182人が誤って満足と予測され、35人が不満/中立と予測されました。
- 正解率95.8%、適合率98.8%、再現率94.1%と良好なパフォーマンスを示しています。ただし、182件の満足した乗客の予測を見逃しています。 したがって、すべての満足した乗客を識別できるように、再現率スコアを向上させるためにモデルを微調整する必要があります。
QuickMLでこれらのモデル指標を調べることで、あらゆる機械学習モデルのパフォーマンスに関するより深い洞察を得て、モデルの選択と最適化に関する情報に基づいた意思決定を行うことができます。これにより、ユーザーはモデルを微調整し、予測精度を向上させることができます。
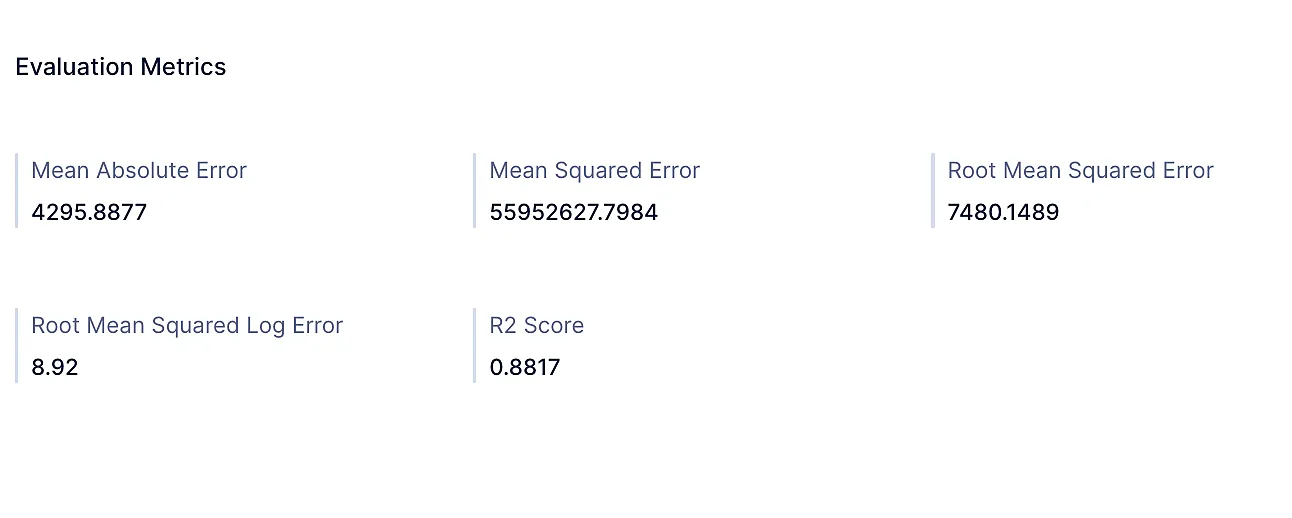
評価指標
QuickMLは、作成された分類モデルと回帰モデルに関する以下の評価指標を表示します。
交差検証指標
交差検証は、トレーニングデータをk個のフォールドに分割し、k-1個のフォールドでモデルをトレーニングし、残りのフォールドでモデルを評価することにより、機械学習モデルのパフォーマンスを評価する方法です。このプロセスがk回繰り返され、k個のフォールドに対するモデルの平均パフォーマンスが全体的なパフォーマンスの評価に使用されます。
簡単に言うと、交差検証はトレーニングデータのサブセットでモデルをトレーニングし、トレーニングデータの残りのサブセットでパフォーマンスを評価することで機能します。これが複数回繰り返され、すべてのサブセットに対するモデルの平均パフォーマンスが全体的なパフォーマンスの評価に使用されます。これにより、モデルがトレーニングデータに過学習していないこと、および新しいデータに対して適切に汎化することを確認できます。
QuickMLは、分類モデルまたは回帰モデルのパフォーマンスを追跡するための豊富な交差検証指標を提供しています。
交差検証で提供される指標タイプの一覧は以下の通りです:
-
分類モデル
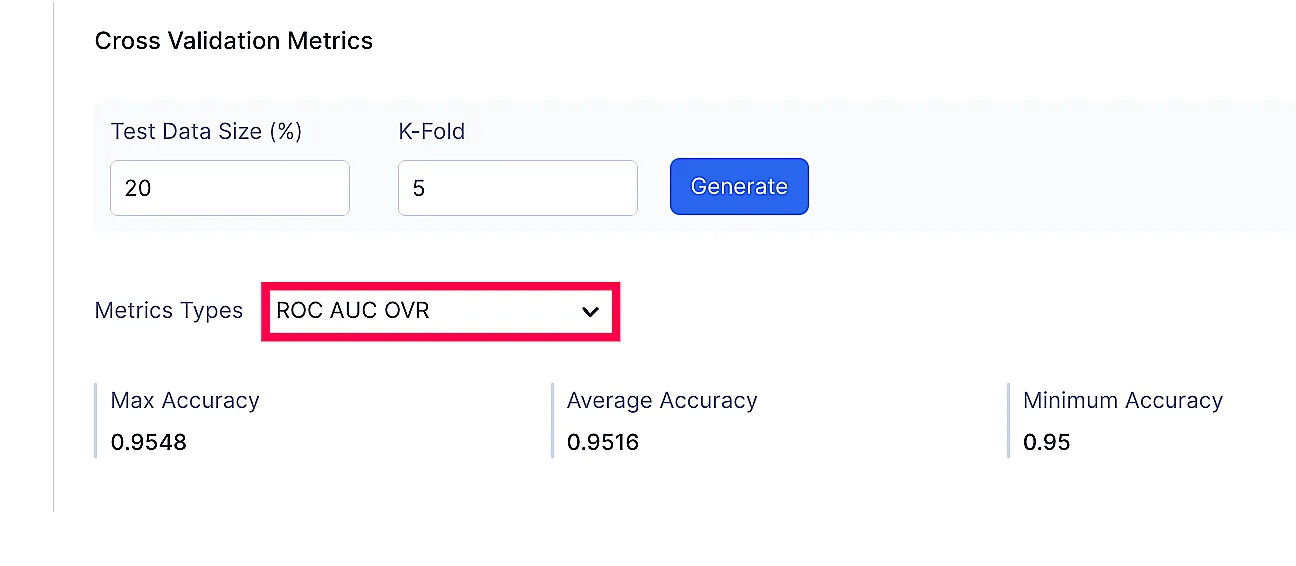
指標タイプ:
- ROC AUC OVR
- ROC AUC OVO
- ROC AUC OVR weighted
- ROC AUC OVO weighted
- Balanced accuracy
- Average precision
- F1 score
- F1 macro
- F1 micro
- F1 samples
- F1 weighted
-
回帰モデル
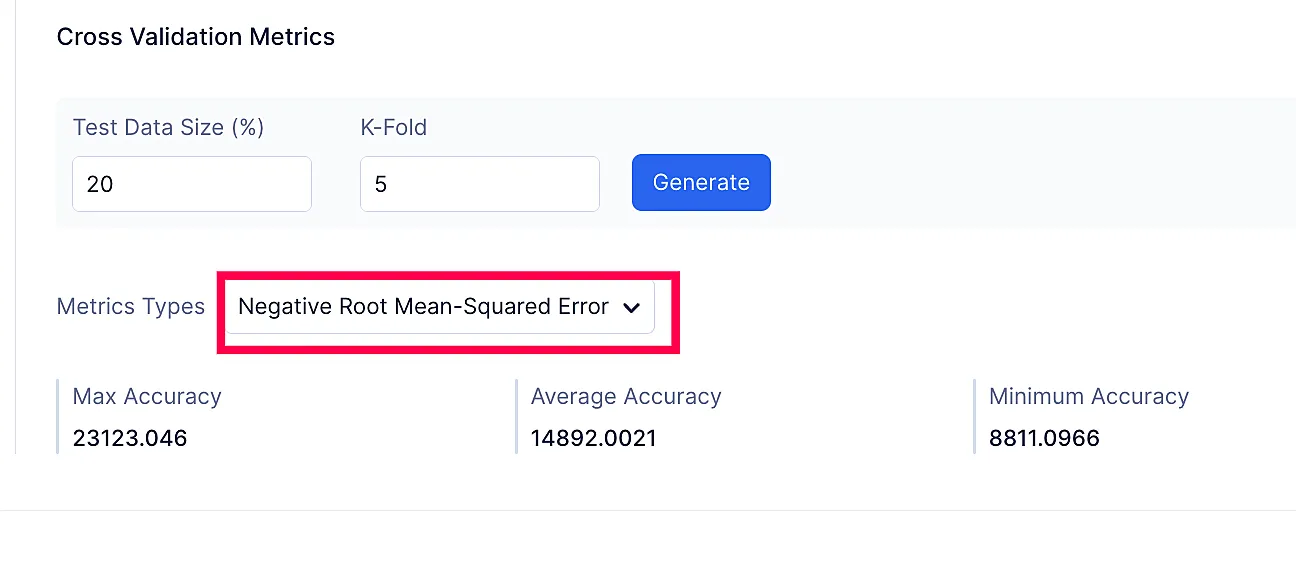
指標タイプ:
- Negative mean-squared error
- Negative mean-squared log error
- Negative root mean-squared error
- Negative mean absolute error
- Negative median absolute error
- Negative mean poisson deviance
- Negative mean gamma deviance
- Negative log loss
- Negative brier score
- R2 score
モデルバージョン
モデルバージョニングは、機械学習モデルの異なるバージョンを追跡・管理するプロセスです。

これは、モデルの異なるバージョンを比較し、パフォーマンスを追跡し、デプロイに最適なバージョンを選択できるため重要です。モデルバージョニングは、必要に応じてモデルの以前のバージョンにロールバックするのにも役立ちます。
特徴量重要度
機械学習モデルの構築に使用される各入力特徴量の重要度を特定することで、モデルの品質と意思決定プロセスにどのように影響するかを追跡できます。
特徴量重要度スコアは重要度を定量化するために計算されます。特徴量のスコアが高いほど、ターゲット変数を予測するモデルに対するその特徴量の影響が大きくなります。各特徴量の重要度を定量化することで、データとモデルに関する洞察を提供し、モデルのパフォーマンスのより良い理解、解釈、および潜在的な改善を可能にします。
特徴量重要度は、順列重要度や不純度の平均減少量など、さまざまな方法を使用して計算できます。また、ツリーベースモデルのfeature importances属性などのモデル固有のテクニックも使用できます。
特徴量重要度の用途
特徴量重要度は、相関行列と同様に、入力特徴量とターゲット変数の関係を理解するためにも使用されます。モデルに影響を与える関連性の高い特徴量は、重要度スコアを使用して特定されます。
- 次元削減: 特徴量重要度は、スコアの高い特徴量を保持し、スコアの低い特徴量をトレーニングデータから除去することで、モデルの次元を削減するのに役立ちます。この簡素化により、バイアスが削減され、ノイズが除去され、モデルトレーニングが高速化し、最終的により良いパフォーマンスのモデルが生成されます。
- モデルパフォーマンス: 最も関連性の高い特徴量に焦点を当てることで、特徴量重要度はモデルの最適化とより良いパフォーマンス、予測性の向上に役立ちます。
- ステークホルダーへの洞察: 特徴量重要度は、モデルの予測に最も大きな影響を与える特徴量についてステークホルダーに洞察を提供し、モデルの動作の理解に役立ちます。
要約すると、特徴量重要度はモデルに対する各特徴量の重要性を説明します。
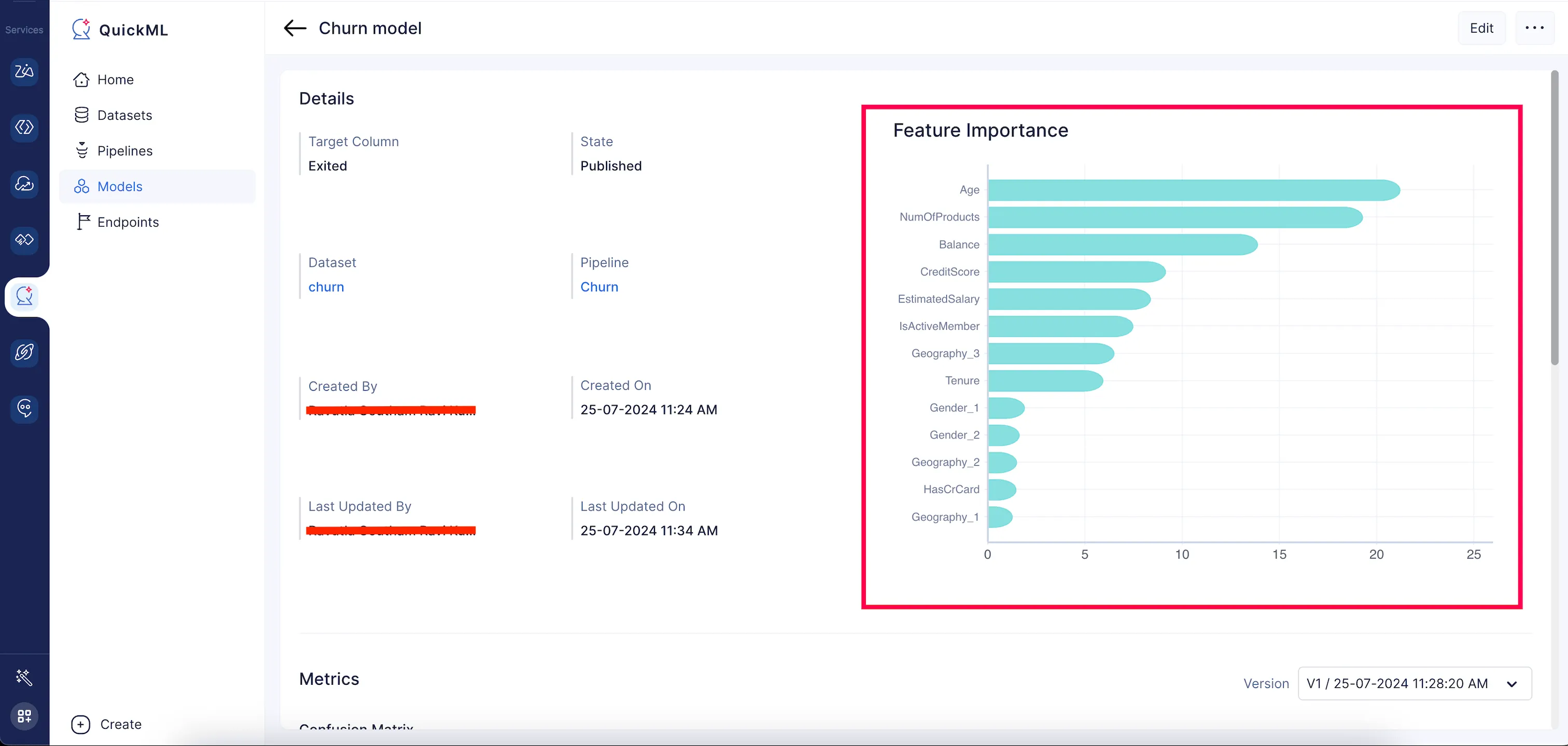
QuickMLのモデル詳細ページでは、上位20特徴量の特徴量重要度スコアを降順で視覚的に表示する棒グラフが生成され、残りは「その他」としてカテゴリ分けされます。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us