Text Analyticsにおける自然言語処理(NLP)の概要
自然言語処理(NLP)は、人工知能(AI)のサブフィールドであり、機械が人間の言語を意味のある有用な方法で理解、解釈、生成できるようにする技術です。日々膨大なテキストデータが生成される中、NLPは計算言語学、機械学習、ディープラーニングを組み合わせ、機械が自然言語データを処理して貴重なインサイトを抽出し、ビジネスに価値を生み出すことを可能にします。自然言語処理は、データ駆動型の課題やビジネスユーザーが直面する問題に対して事前に対処することで、ユーザーエクスペリエンスを向上させ、ビジネスに大きな価値を提供します。
なぜ人気があるのか?
NLPの人気は、複雑な人間の言語を理解し、現実の問題に適用する能力に支えられており、テクノロジーとのインタラクションをより自然で直感的なものにしています。人気が高まっている主な理由は以下の通りです:
- データからのインサイト抽出: 企業は、ソーシャルメディア、記事、製品レビュー、フィードバック、法的文書など、さまざまなソースから大量のテキストデータを収集しています。顧客やユーザーが自社の製品やサービスについて何を語っているのかを理解する必要があります。NLPは、この大規模で非構造化されたデータを効率的に処理、分析し、貴重なインサイトを抽出する方法を提供します。
- ユーザー中心のアプリケーション: NLPの登場により、企業はバーチャルアシスタント、チャットボット、自動化されたカスタマーサービスシステムを活用して、ユーザーの問い合わせに迅速かつ効率的に対応しています。
- 翻訳機能: NLPは機械翻訳を可能にし、言語を超えたコミュニケーションを促進し、社会における言語の壁を取り除くことに貢献しています。
- 要約機能: 長文のドキュメントを短い要約に変換し、素早い閲覧を可能にすることで、時間と労力を節約できます。
これらはほんの一部のアプリケーションであり、日々新たなイノベーションが生まれています。
ビジネスアプリケーション
NLPは、NLPタスクを活用してビジネス環境におけるさまざまなアプリケーションを実現し、企業がプロセスを自動化し、大規模なデータセットからアクショナブルなインサイトを抽出することを支援します。いくつかのNLPタスクとそのリアルタイムのビジネスアプリケーションを見てみましょう。
NLPタスク
タスクとは、NLPモデルが実行または解決するように設計された特定の目的や問題を指します。各タスクは、自然言語の処理や分析の特定の側面に対応することに焦点を当てています。
NLPタスクの例
QuickMLのText Analyticsビルダーを使用して実行できるタスクは以下の通りです:
- スパム検出: スパム分類は二値分類モデルであり、受信したメールをスパムかどうかに分類することを目的としています。スパム検出モデルは、メールの本文、件名、送信者情報などを入力として受け取り、そのメールがスパムである確率を生成します。閾値に基づいて、メールをスパムまたは非スパムに分類します。 テキスト分類タスク:メールのスパム分類と同様に、テキスト分類に含まれるその他のタスクとして、意図検出、コミットメント分類、感情検出、トナリティ識別があります。
- 言語検出: 言語検出は、言語翻訳、文法修正、テキスト読み上げなど、さまざまなNLPアプリケーションで適用される基本的なステップです。Webコンテンツの検索に使用される言語を検出し、同じ言語で結果を返したり、チャットボットや翻訳ツールで同じ言語で応答を提供したりするために使用されます。
- 感情分析: テキストの感情トーン(ポジティブ、ネガティブ、ニュートラル)を判定します。一般的に、感情分類モデルへの入力はテキストの一部であり、出力はそのテキストで表現されている感情です。現実のシナリオでは、感情分類は、企業が製品レビューを通じて顧客が自社製品についてどのように感じているかを把握し、ネガティブな影響を与えている分野を理解するのに役立ちます。
QuickMLのZia機能を使用して実行できるタスクは以下の通りです:Zia Features
以下のタスクはCatalyst Ziaサービスを使用して実行できます:
- 固有表現認識(NER): 人名、地名、組織名などの固有名詞を検出します。
- キーワード抽出: テキストデータから最も関連性の高いキーワードを特定・抽出するNLP技術であり、主要なトピックの把握、情報の要約、索引付け、ドキュメントの分類に役立ちます。
NLPアプリケーション
アプリケーションとは、NLPモデルの実用的かつ現実世界でのユースケースを指します。アプリケーションは、より広範なエンドユーザーの問題を解決したりサービスを提供したりするために、1つ以上のNLPタスクを使用して構築されることが多いです。
NLPアプリケーションの例:
- 感情分析ツール: 感情抽出、トナリティ、感情識別タスクを使用して世論を測定します。顧客体験の理解に大きな価値を置く企業やブランドにとって不可欠です。以下の目的で実装できます:
- ソーシャルメディアプラットフォームやアンケート調査で顧客が表明する感情の測定・モニタリング
- 顧客フィードバックやレビューの分析を自動化し、手作業の負担を軽減
- ネガティブな感情の自動モニタリングによる、リアルタイムでの重大な状況の特定と対処
- メールスパムフィルター: スパムフィルターは、スパム分類などのタスクを活用して、不要な迷惑メールを識別・フィルタリングし、自動的にスパムフォルダに移動します。これにより、受信トレイの煩雑さを軽減し、時間を節約し、フィッシング詐欺やその他の有害な詐欺への露出リスクを最小限に抑えることで、ユーザーエクスペリエンスを向上させます。
- 顧客フィードバック分析: 感情分析やキーワード抽出など、複数のNLPタスクを活用することで、企業はレビューやソーシャルメディアで顧客が自社製品について何を語っているかについてのインサイトを得ることができます。これにより、顧客の懸念や苦情に効果的に対処し、最終的に顧客満足度を高め、全体的な体験を向上させることができます。
- カスタマーサポート効率の向上: 感情検出などのタスクにより、企業はチャット、電話、苦情、フィードバック、レビュー、ソーシャルメディア投稿などを通じた顧客とカスタマーサポートスタッフとのやり取りを分析できます。これにより、製品やサービスを使用した際に顧客が経験する喜び、フラストレーション、怒りなどの感情を特定できます。企業は顧客の感情をより深く理解し、共感を持って対応し、サービスをカスタマイズし、顧客との関係を改善できます。 顧客の感情を検出することは、懸念に対処し、問題を解決し、ブランドロイヤルティを高めるための積極的な対策を実施する機会を提供します。
- 大規模なカスタマーサポート: 企業は意図分類やアクティビティ分類タスクを活用して、ユーザーの問い合わせを正確に解釈し、それに応じた応答を提供します。一般的または基本的な問い合わせの解決を自動化することで、応答時間を大幅に短縮し、より複雑な問題にリソースを集中させることができます。この自動化により、カスタマーサポートは効率的にスケールし、サポートサービスの範囲を拡大し、一貫したサービス提供を確保します。さらに、バーチャルアシスタントを活用して応答をモデリング・配信し、パーソナライズされたユーザーエクスペリエンスを維持しながら、サポートの速度と品質をさらに向上させます。
アプリケーションは、本質的に複数のタスクが組み合わさってユーザーに価値を提供する実用的な実装です。タスクが特定の言語操作に焦点を当てるのに対し、アプリケーションは複数のタスクを組み合わせて、より広範なユーザー中心の問題を解決することに焦点を当てています。これらは、NLPタスクが現実のビジネスでどのように適用されているかのほんの一例です。技術の進歩に伴い、ユーザーエクスペリエンスを革新し、プロセスを合理化し、ニーズにより効果的に対応することで顧客ロイヤルティを高める、多くの革新的なアプリケーションが登場し続けています。
パイプライン構築のステップ
QuickMLでは、クラシックモードとスマートモードのパイプラインビルダーを使用してText Analyticsモデルを作成します。
クラシックモードは、NLPモデルを構築するためのデータおよび機械学習操作のリストが利用可能なドラッグ&ドロップ式のパイプラインビルダーインターフェースを備えています。これらのノードをビルダーにドラッグ&ドロップして機械学習パイプラインを構築し、実行するとNLPモデルが生成されます。
スマートモードは、データの前処理、特徴抽出からモデル選択まで、NLPモデルの構築プロセスを簡素化するように設計された事前構築テンプレートを提供します。この事前構築テンプレートでは、ステージが事前定義されており、各ステージで操作を設定するためのさまざまなパラメータがユーザーに提示されます。このテンプレートにより、NLPモデルを構築する際にどの操作をいつ使用するかという曖昧さが排除され、モデル構築プロセスが合理化されます。
Smart Builderを使用したモデル構築
テキストベースの機械学習モデルの構築は、データの前処理、アルゴリズムの選択、モデルのチューニングなど、他のMLモデルと同様のプロセスに従います。ただし、NLPモデルは、特定のテキストベースの操作を適用する順序が異なります。この順序は、テキストデータが機械学習アルゴリズムを適用する前に最も効果的な方法で変換・処理されることを保証するため、モデル構築において非常に重要です。
スマートモードのモデル構築では、パイプラインビルダーは3つの主要なステップに合理化されています:
- 前処理: このステップでは、生のテキストデータをクリーニングし、さらなる分析に備えます。トークン化、大文字小文字変換、ステミングとレンマタイゼーション、ストップワードおよびノイズの除去、正規化などの操作が含まれます。
- 特徴抽出: このステップでは、テキストデータを機械学習アルゴリズムが理解できる数値特徴に変換します。TF-IDF、ワードエンベディング、Bag-of-Wordsなどの手法が一般的に使用されます。
- アルゴリズム選択: 最終ステップでは、ユースケースに基づいて利用可能な教師あり学習または教師なし学習アルゴリズムから適切なアルゴリズムを選択します。その後、特徴抽出ステップからの前処理済みデータを使用してモデルがトレーニングされます。
スマートモードパイプラインビルダーの各ステップには、特定のNLP問題に合わせて操作を設定できる構成可能なステージ/操作が用意されています。
各ステップの詳細と、利用可能なステージ/操作を見ていきましょう:
ステージ1:前処理
テキストデータは通常生のままであるため、パフォーマンスを向上させるためにアルゴリズムに入力する前にデータを処理することが重要です。スマートビルダーでは、テキストデータの前処理ステージに7つの操作があり、最初の6つの操作はテキストデータに適用され、最後の操作であるラベルエンコーディングはラベル付きデータセットのターゲット列に適用されます。このステージの出力は特徴抽出ステージに渡され、テキストデータ全体が数値形式に変換されます。
前処理ステージの操作を見てみましょう。
a. 大文字小文字変換
異なるケースの生のテキストデータを、共通の目的のケース(一般的には小文字)に変換します。これにより、スパース性を軽減できます(共通のケーシングなしでは「NLP、Nlp、nlp」は3つの異なる単語として扱われます)。
b. トークン化
トークン化は、テキストデータをさらに小さな単位に分割することです。例えば、段落を文に、文を単語に、単語を個々の文字に分割できます。これにより、より大きなセグメントでは見えないパターンやインサイトを発見することが可能になります。
QuickMLでは、文のトークン化を単語レベルと文字レベルの両方で実行できます。単語レベルでトークン化を適用した後、必要に応じてデータに後続の操作(ステミングとレンマタイゼーション、ストップワード除去、ノイズ除去、正規化)を適用できます。
ただし、文字レベルでは、トークン化されたデータに対してノイズ除去操作のみを適用できます。
トークン化のステージ: テキスト:文 ➔ 単語 ➔ 文字
c. ステミングとレンマタイゼーション
両方の手法は単語をルート形式に変換し、より一貫性のある分析のために単語のバリエーションを正規化するのに役立ちます。ステミングは末尾の文字を切り取ってルート形式を取得しますが、常に正しい単語になるとは限りません。一方、レンマタイゼーションはコンテキストを考慮して単語を辞書形式に変換するため、正確な意味を持つ適切な単語になります。
主な違いは、ステミングは高速ですが精度が低く、レンマタイゼーションはより正確ですが、語彙と文法に依存するため処理が遅いことです。
サンプル:
| Words | Stem word | Lemmatized word |
|---|---|---|
| Studying, Studies, Studied |
Studi | Study |
| Running, Runner, Runs | Run or Runn | Run |
| Changing | Chang | Change |
d. ストップワード除去
言語には、トレーニング中に重要な意味を持たない多くのフィラーワードがあります。これらを除去することで、モデルが重要な単語により集中できるようになります。冠詞、前置詞などがストップワードのカテゴリに含まれます。
e. ノイズ除去
対象の特徴に応じて、不要な単語やテキストの一部を除去します。例:NLPにおける感情分類ではメールアドレスは不要です。正規表現やノイズワードのリストを使用して実行できます。余分なスペース、特殊文字、数字もノイズと見なされる場合があります。
f. 正規化
異なる形式のテキストを標準形式に変換します。 例:USA、usa、United states of America、The united states of America、the usaをusaに統一します。これは辞書マッピングを使用して実現できます。 ノイズ除去もテキスト正規化の一部と見なすことができます。
| Raw | Normalized |
|---|---|
|
2moro 2mrrw 2morrow 2mrw tomrw |
tomorrow |
| b4 | before |
| otw | on the way |
| :) :-) ;) |
smile |
g. ラベルエンコーディング
ラベルエンコーディングは、各カテゴリに一意の整数を割り当てることでカテゴリ変数を数値に変換する手法です。機械学習アルゴリズムがカテゴリデータを効果的に処理するのに役立ちます。 テキストデータのコンテキストでは、ターゲットラベルはさまざまなクラスを持つカテゴリ変数を表し、モデルを効果的にトレーニングするために数値形式に変換できます。
これで、テキストデータがクリーニングされ、以下の特徴抽出ステージで利用可能なベクトル化手法を使用してワードベクトルに変換する準備が整いました。
ステージ2:特徴抽出
テキストデータをアルゴリズムに直接入力することはできません。まず数値形式に変換する必要があります。この変換にはいくつかの方法があり、ベクトル化手法として知られています。これらの手法は、ベクトル化されたデータから追加の特徴を抽出するためにも使用できます。このコンテキストでは、モデルに提示される各単語、文、または文字は特徴として扱われます。
QuickMLでは、以下の手法を使用してテキストから数値への変換が行われます。これは、テキストデータを単語やフレーズの意味的な意味を捉える数値形式に変換するプロセスです。
QuickMLで利用可能な手法は以下の通りです:
a. Bag Of Words(BOW)
Bag of Wordsは、テキストコーパス全体に含まれるユニークな単語の語彙を作成します。各文はベクトルとして表現され、これらの単語の存在に基づいてマッピングが行われ、値はその文内での各単語の出現頻度を表します。
例:
以下は、次の文に対するBag of Wordsモデルのベクトル化表現を示す例です:
S1. Machine learning solves real world problems
S2. NLP popularity is rising
S3. Language translation is NLP task
Bag of Wordsのテーブル表現:

行は提供された文を表し、列はこれらの文の各単語を表し、値は各文における特定の単語の出現頻度を表します。
ベクトル表現: 各文は、BOWテーブルからの単語カウントを持つベクトルとして表現されます。ベクトルの長さは語彙内のユニークな単語数と等しくなります。以下は、上記の3つの文のベクトル化表現です。 Sentence 1 → [ 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]
Sentence 2 → [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0]
Sentence 3 → [0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1]
BOWモデルはテキストデータをベクトルとして表現し、テキストコーパス内の各単語を特徴として扱います。データをモデリング用に簡素化しますが、単語の順序の重要性やその文脈的な意味を捉えることはできません。
b. TF-IDF(Term Frequency - Inverse Document Frequency)
TF-IDFはコーパス内の各単語の重要度を定量化し、より良いパフォーマンスでモデルをトレーニングするのに役立つテキストデータから重要な特徴を抽出できます。TF-IDFスコアが高いほどその単語は重要であり、その逆も同様です。
3つのステップで計算できます。
**ステップ1:Term Frequency(TF)**は、ドキュメント内のユニークな単語の総数に対して、ある用語がドキュメント内でどの程度頻繁に出現するかを測定します。
単語のTerm Frequency(TF)= ドキュメント内での単語の出現回数 / ドキュメント内のユニークな単語の総数
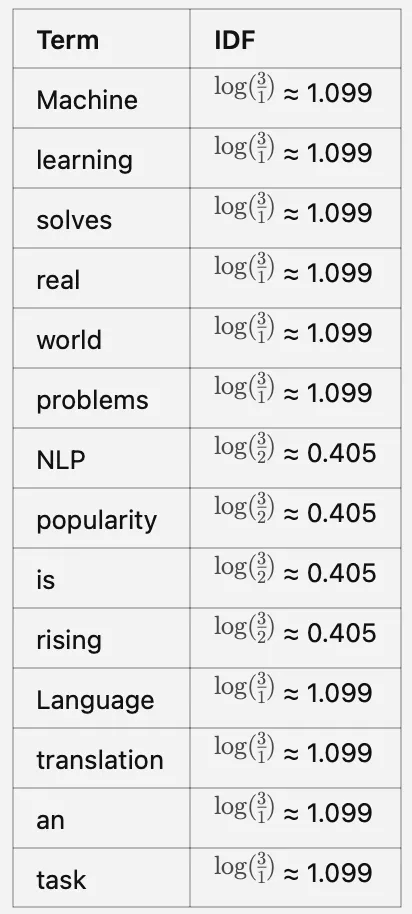
**ステップ2:Inverse Document Frequency(IDF)**は、ドキュメント全体にわたって用語がどの程度重要かを測定します。
単語のIDF = log(N/n)、ここでNはドキュメントの総数、nはその単語が出現したドキュメントの数です。
ステップ3:TF-IDFスコアの計算
TF-IDF = TF * IDF
出現頻度の低い単語のIDFは高くなり、一般的な単語のIDFは低くなります。したがって、「the、is、a」などの単語は重要度が低くなり、ドキュメント固有の実際の単語により高い重要度が与えられます。
例:
Bag of Wordsのサンプル例を使用しましょう:
S1. Machine learning solves real world problems
S2. NLP popularity is rising
S3. Language translation is NLP task
ステップ1:Term Frequency(TF)の計算
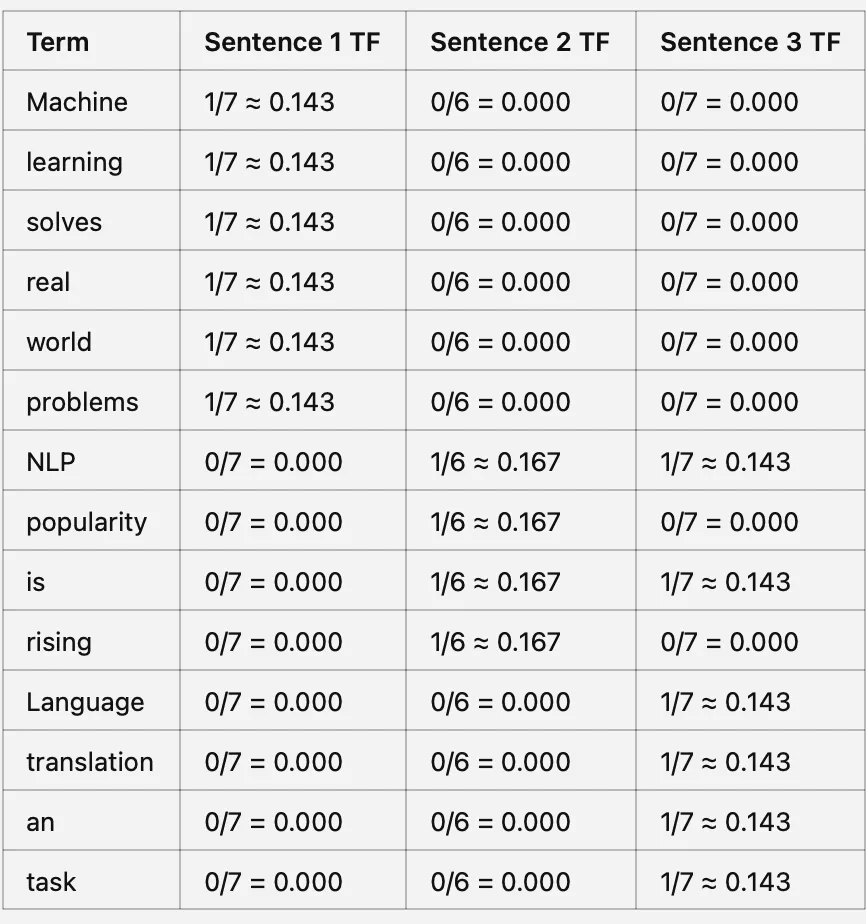
ステップ2:IDFスコアの計算
ステップ3:TF-IDFの計算
各文の各用語についてTFにIDFを掛けます
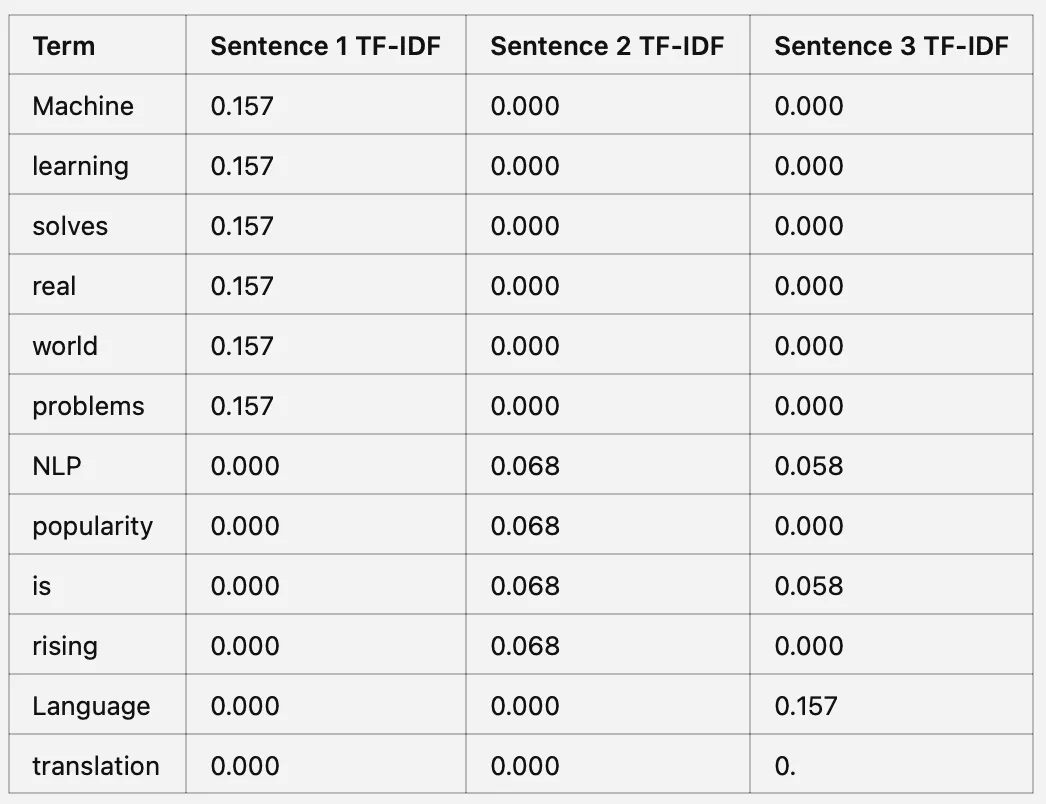
この例から得られる主なインサイトは以下の通りです:
高いTF-IDF値は、ある用語が特定の文で重要であり、すべての文に共通ではないことを示します。
低いTF-IDF値は、ある用語が文全体で共通であるか、特定の文に固有ではないことを示します。
TF-IDFは、コーパス内のコンテキストを理解するために重要な単語を強調します。一部の単語や用語が他よりも特定のテキストにおいて重要であることを示します。
c. Word2Vec
Word2Vecは、単語の意味的および文脈的関係に基づいて数値ベクトル(エンベディング)を生成する事前学習済みのワードエンベディングモデルです。大規模なテキストコーパスでトレーニングされ、類似の意味やコンテキストを持つ単語がベクトル空間で近い位置にエンベディングベクトルを持つようになります。これらの関係はコサイン類似度を使用して定量化でき、スコアが高いほど類似度が高いことを示します。
例:
「king」と「queen」のような単語は互いに近いベクトルを持ち、王族という共有コンテキストを反映します。同様に、「man」と「woman」はその関係と共有される意味を捉えたベクトルを持ち、Word2Vecが意味的関係を効果的にモデル化する能力を示しています。
d. GloVe
GloVe(Global Vectors for Word Representation)は、Word2Vecと同様に、与えられた単語のエンベディングベクトルを生成する事前学習済みのワードエンベディングモデルです。これはカウントベースのモデルであり、コーパス全体から導出された単語の共起行列を分解することでエンベディングを生成します。GloVeは、コーパス全体にわたって単語がどの程度頻繁に共起するかを分析することで、グローバルな統計情報を捉えます。ローカルコンテキストに基づく予測的アプローチを使用するWord2Vecとは異なり、GloVeはトレーニングにグローバルな共起統計を使用します。トレーニング方法がWord2Vecと異なります。
例:
GloVeでは、「king」と「queen」のような単語は類似のベクトルを持ち、意味的関係(例:王族)を反映します。さらに、GloVeは類推関係の捕捉に優れています。
例えば:
king - man + woman ≈ queen
この類推は次の変換を表します:「king」と「man」の関係(「kingがmanに対する関係は、queenがwomanに対する関係と同じ」と考えることができます)は、「man」を「king」から引いて「woman」を加えることで数学的に捕捉されます。結果は「queen」となり、kingがmanに対する関係と同様に、queenがwomanに対する関係をモデルが理解していることを意味します。
これは、「king」と「man」のベクトル差が「queen」と「woman」の差と類似していることを意味し、GloVeが意味と関係の両方を効果的にモデル化する能力を示しています。
ステージ3:アルゴリズムとモデリング
テキストデータはベクトル化された形式でアルゴリズムに入力され、NLPモデルが生成されます。NLPモデルは、教師あり学習モデルと教師なし学習モデルに大別されます。QuickMLでは、ラベル付きデータを使用して教師あり学習モデルを構築するアルゴリズムが用意されています。
アルゴリズムは以下の通りです:
モデル評価指標
NLPにも、精度、適合率、F1スコアなどの一般的な評価指標があります。
i. Log-Lossスコア
Log-Loss(ロジスティック損失またはクロスエントロピー損失とも呼ばれます)は、自然言語処理(NLP)モデル、特に二値分類およびマルチクラス分類タスクで一般的に使用される評価指標です。Log-Lossは、予測確率と実際のクラスラベルの差を定量化します。データレコードの予測確率は、モデルが分類した各クラスに対して予測する確率です。
実際のクラスラベルは、データレコードが属する真のクラスです。Log-Lossスコアは、予測確率が実際のクラスラベルにどの程度近いかを示します。予測確率値が実際の値から乖離するほど、Log-Lossスコアは高くなります。
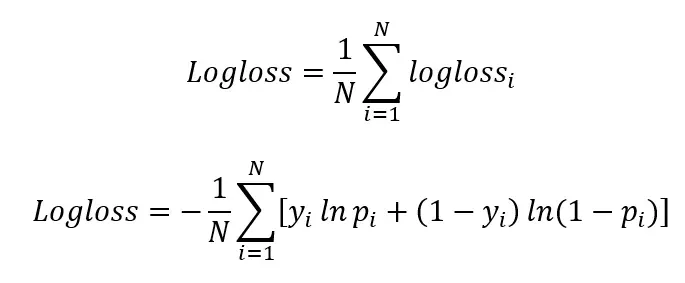
ここで
iは与えられた観測値/レコード、
yは実際の/真の値、
pは予測確率、
lnは数値の自然対数(eを底とする対数値)、
Nは観測値の数です。
この指標は、出力が0から1の間の確率値である分類モデルのパフォーマンスを測定します。Log-Lossスコアが低いほどモデルの適合度が高く、パフォーマンスが優れています。Log-Lossスコアが0のモデルは完璧な予測能力を持っています。
例:
スパム分類において、あるメールの実際のクラスが「Spam」であるとします。そのメールが「Spam」である予測確率は0.78、「Not-Spam」である予測確率は0.22です。正しいクラス(Spam)の予測確率の負の自然対数は0.2485であり、これがその特定のレコードのLog-Lossスコアを表します。モデルのLog-Lossスコアは、すべてのレコードにわたる正しいクラスの予測確率の負の自然対数の平均として計算されます。
ii. AUC-ROC曲線
AUC-ROC(Area under the Receiver Operating Characteristic)曲線は、分類モデルのパフォーマンスを測定する機械学習指標です。AUCはROC曲線の下の面積を表し、ROCはさまざまな分類閾値におけるTrue Positive Rate(TPR)とFalse Positive Rate(FPR)をプロットしたグラフです。
True Positive(TP)とFalse Positive(FP)は、分類モデルのパフォーマンスを評価するための混同行列で使用される用語です。
- True Positive Rate(TPR)は、感度またはリコールとも呼ばれ、モデルによって正しく識別された実際の正のレコードの割合を測定します。
- False Positive Rate(FPR)は、誤って正と分類された実際の負のレコードの比率を測定します。
Specificityは、モデルによって正しく識別された実際の負のインスタンスを測定します。
以下はAUC-ROC曲線の視覚的な解釈です。ROCはすべての可能な閾値にわたるTPRとFPRの間のプロットであり、AUCはROC曲線の下の全面積です。
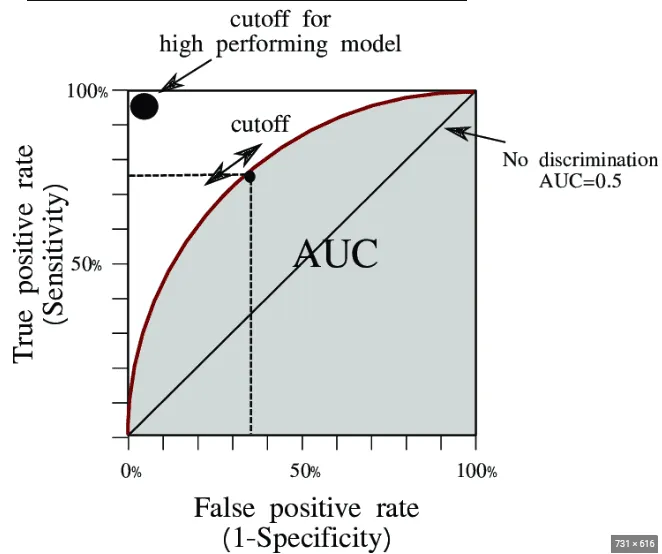
AUC(Area Under the Curve)スコアは0から1の範囲であり、スコアが高いほどモデルのパフォーマンスが優れていることを示します。
-
AUCが1の場合、完璧なモデルを意味し、ROC(Receiver Operating Characteristic)曲線が完全な直角パスを形成し、0%のFalse Positive Rateで100%の感度(True Positive Rate)を達成します。
-
AUCが0.75の場合、モデルが正と負のクラスを75%の確率で区別する良好な能力を持っていることを示しますが、まだ改善の余地があります。
-
AUCが0.5の場合、モデルがランダムな推測と同程度のパフォーマンスしかないことを示し、最も望ましくない結果です。
AUCスコアが高いほど、クラス間のモデルの識別能力が優れていることを常に反映します。
可視化
ワードクラウド
ワードクラウドは、テキストコーパス内で最も頻繁に出現する単語を視覚的に表現したものです。ワードクラウド内の各単語のサイズは、その出現頻度を反映しています。ワードクラウドは、大規模なテキストデータセット内の最も顕著なキーワードやフレーズを素早く特定・強調するために一般的に使用され、議論されている主要な用語やコンセプトを伝えやすくします。
例: 「ナルニア国物語:ライオンと魔女」からの抜粋を例に取りましょう。

提供されたテキストに対して生成された以下のワードクラウドを分析し、頻繁に使用されている重要な単語を特定しましょう。

このワードクラウドにより、重要なキーワードを素早く抽出し、インサイトを得て、テキストの全体的なコンテキストを視覚的に魅力的かつ時間効率の良い方法で理解できます。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us