クラスタリング
はじめに
クラスタリングは、類似するデータポイントを意味のあるクラスターにグループ化するプロセスであり、同じグループ内のアイテムは共通の特性を共有し、他のグループのアイテムとは異なります。これは教師なし学習の分野に属する機械学習の一分野であり、事前定義されたラベルや結果なしで動作します。正しいグループ分けが何であるかを指示されるのではなく、アルゴリズムがデータ内の隠れた構造を独自に発見します。これにより、クラスタリングは大規模で整理されていないデータセットを扱う際に特に価値があり、パターンの検出、自然なグループ分けの発見、複雑な情報のより理解しやすいセグメントへの簡素化に役立ちます。
本質的に、クラスタリングは「どのデータポイントが互いに類似しているか?」という問いに答えます。顧客セグメンテーション、画像認識、異常検知、ドキュメント分類など、多くの分野に適用できます。
クラスタリングの背景にある直感的理解
クラスタリングの種類やアルゴリズムに入る前に、クラスタリングの直感的な理解から始めましょう。映画視聴者のデータセットがあり、各視聴者がジャンルごとの視聴映画数、平均評価、視聴頻度など複数の属性で記述されているとします。どの視聴者が似たような好みを持っているかは事前にはわかりません。
クラスタリングアルゴリズムを適用することで、各視聴者はすべての特徴にわたる全体的な類似性に基づいてクラスターに割り当てられます。最終的に、視聴者の自然なグループ分けが視覚的に確認できます。あるクラスターにはアクションやスリラー映画のファンが含まれ、別のクラスターにはコメディ愛好者、さらに別のクラスターにはロマンスやドラマを好む視聴者が含まれるかもしれません。アルゴリズムは、どの視聴者が類似しているかを一度も指示されることなく、視聴者行動の隠れたパターンを発見しています。
クラスタリング分析の主要成功基準
クラスタリングは本質的に反復的かつ探索的であり、ドメインの専門知識と人間の判断を必要とします。教師あり学習とは異なり、ラベル付けされた結果がないため、精度やRMSEなどの従来の指標を使用してパフォーマンスを評価することはできません。このため、クラスタリングモデルの評価は主観的であり、ビジネス目標に依存します。
成功の主要基準は以下のとおりです:
-
解釈可能性:ポイントがなぜグループ化されたかを説明できますか?
-
ビジネスの有用性:クラスタリングの出力はアクションにつながるインサイトを提供しますか?
-
知識の発見:データ内の新しいパターンや隠れた構造を発見しましたか?
クラスタリングの成功は、アルゴリズムの出力とドメイン知識を組み合わせてクラスターを精緻化し、意味のあるインサイトを抽出することから生まれることが多いです。
クラスタリングのビジネス応用
クラスタリングは、データ内の自然なグループ分けを明らかにし、ビジネスが行動を取れるようにするため、以下のような幅広い業界で応用されています。
小売とマーケティング
クラスタリングは、小売やマーケティングで顧客を予算重視の購入者、季節的な購入者、プレミアム顧客などのグループにセグメント化するために広く使用されています。これらのインサイトにより、企業はターゲットを絞ったキャンペーンを実施し、ロイヤルティプログラムを設計し、頻繁に一緒に購入される商品を特定して店舗レイアウトを最適化することもできます。
eコマースとオンラインプラットフォーム
eコマースプラットフォームは、パーソナライゼーションのためにクラスタリングに大きく依存しています。閲覧履歴と購入履歴を分析することで、クラスタリングアルゴリズムは類似した行動を持つユーザーをグループ化し、各セグメントに合わせた商品レコメンデーションを生成できます。顧客以外にも、クラスタリングは膨大な商品カタログをカテゴリに整理するのに役立ち、異常な閲覧やレビューパターンは疑わしい活動としてフラグ付けできます。
金融と銀行業
金融セクターでは、クラスタリングは通常の取引クラスターと不正行為を表す可能性のある稀で孤立した外れ値を区別することで、不正検出に重要な役割を果たします。銀行は、支出パターンと収入レベルに基づいて顧客をセグメント化するためにもクラスタリングを使用し、カスタマイズされたクレジットカード、ローンオファー、投資ポートフォリオの設計を可能にします。同様に、アナリストは市場で類似した動きをする株式をグループ化するためにクラスタリングを使用し、ポートフォリオの分散に役立てています。
ヘルスケアとライフサイエンス
ヘルスケアとライフサイエンスもクラスタリング技術の恩恵を受けています。患者記録をグループ化して疾病のサブタイプやハイリスク集団を特定でき、早期介入やパーソナライズされた治療計画をサポートします。遺伝子データや臨床データをクラスタリングすると、隠れた生物学的グループ分けが明らかになることが多く、創薬を加速します。病院は、治療コスト、入院期間、転帰によって患者を分類するためにもクラスタリングを使用し、運営効率の改善に役立てています。
通信とテクノロジー
通信会社は、通話やインターネット使用パターンによる顧客のグループ化などのユーザー行動を理解するためにクラスタリングを適用し、パーソナライズされたデータプランの作成に役立てています。ネットワークトラフィックの異常検出や、請求、ログインの問題、技術的な障害などのカテゴリにサポートチケットを自動的にグループ化してカスタマーサービスを効率化するためにも使用されています。
クラスタリングの動作方法
最も広く使用されている手法の1つであるK-Meansアルゴリズムを使用してクラスタリングを理解しましょう。
ステップ1:クラスター数(k)の選択
プロセスは、アルゴリズムに特定させたいクラスターの数を決定することから始まります。kとして表されるこの数値は、精度と解釈可能性の最適なバランスを推定するのに役立つElbow Methodなどの統計的手法に基づいて決定できます。
ステップ2:セントロイドの初期化
次に、アルゴリズムはデータセットからk個のデータポイントをランダムに選択し、初期クラスターセントロイドとします。これらは、クラスターが形成され始める際の出発参照点として機能します。場合によっては、K-Means++などの改善された初期化方法が使用され、より良い開始位置を選択し、アルゴリズムの収束を速め、より信頼性の高い結果を生成するのに役立ちます。
ステップ3:データポイントのクラスターへの割り当て
セントロイドが初期化されると、データセット内の各データポイントが、選択された距離メトリック(ユークリッド距離)に基づいて最も近いセントロイドに割り当てられます。ユークリッド距離は、空間内の2点間の距離を測定します。
2点(x1,y1)と(x2,y2)間のユークリッド距離の公式は以下のとおりです:
Distance = √((x1 - x2)² + (y1 - y2)²) ここで(x1,y1)と(x2,y2)は2点の座標です。
このステップにより、データセットがk個のグループに効果的に分割され、各ポイントは最も近いセントロイドを持つクラスターに属します。
ステップ4:セントロイドの更新
すべてのポイントが割り当てられた後、アルゴリズムは各セントロイドの位置を再計算します。これは、同じクラスターに属するすべてのデータポイントの平均を取ることによって行われます。新しい平均値が更新されたセントロイドの位置となり、以前よりもそのクラスターの中心をより正確に表します。
ステップ5:割り当てと更新の繰り返し
ポイントの割り当てとセントロイドの更新のプロセスが反復的に繰り返されます。各イテレーションで、セントロイドは位置をわずかに調整し、アルゴリズムが境界を精緻化するにつれてポイントがクラスター間を移動する場合があります。このサイクルは、クラスターの割り当てが大きく変わらなくなるか、セントロイドの移動が最小限になるまで続きます。
ステップ6:収束の確認
K-Meansは、セントロイドが安定し、イテレーション間で大幅に移動しなくなると収束したと見なされます。あるいは、事前定義された最大イテレーション数に達した場合にプロセスが停止することもあります。この段階で、アルゴリズムはクラスタリングプロセスが完了したと見なします。
ステップ7:最終出力の生成
最終ステップでは、各データポイントにそれが属するグループに対応するクラスターラベル(0、1、2、…、k–1など)が割り当てられます。最終的なセントロイド座標は、これらのクラスターの中心を表します。これらの結果は、顧客セグメンテーションなどのリアルタイムのユースケースに使用できます。
例
理解を深めるために、これらのステップを顧客セグメンテーションの例に適用してみましょう。
オンラインストアを運営しており、月間支出、購入回数、商品の好みなど複数の属性を持つ顧客のデータセットがあるとします。どの顧客が類似した行動を取るかは事前にはわかりません。
K-Meansなどのクラスタリングアルゴリズムを適用した後、各顧客はすべての特徴にわたる全体的な類似性に基づいてクラスターに割り当てられます。結果を可視化するために、データはComponent 1とComponent 2の2つのコンポーネントに次元削減されます。
各顧客は2D散布図上の点になります:
- X軸:Component 1
- Y軸:Component 2
ポイントはクラスターに応じて色分けされます。この可視化により、顧客の自然なグループ分けが容易に確認できます。
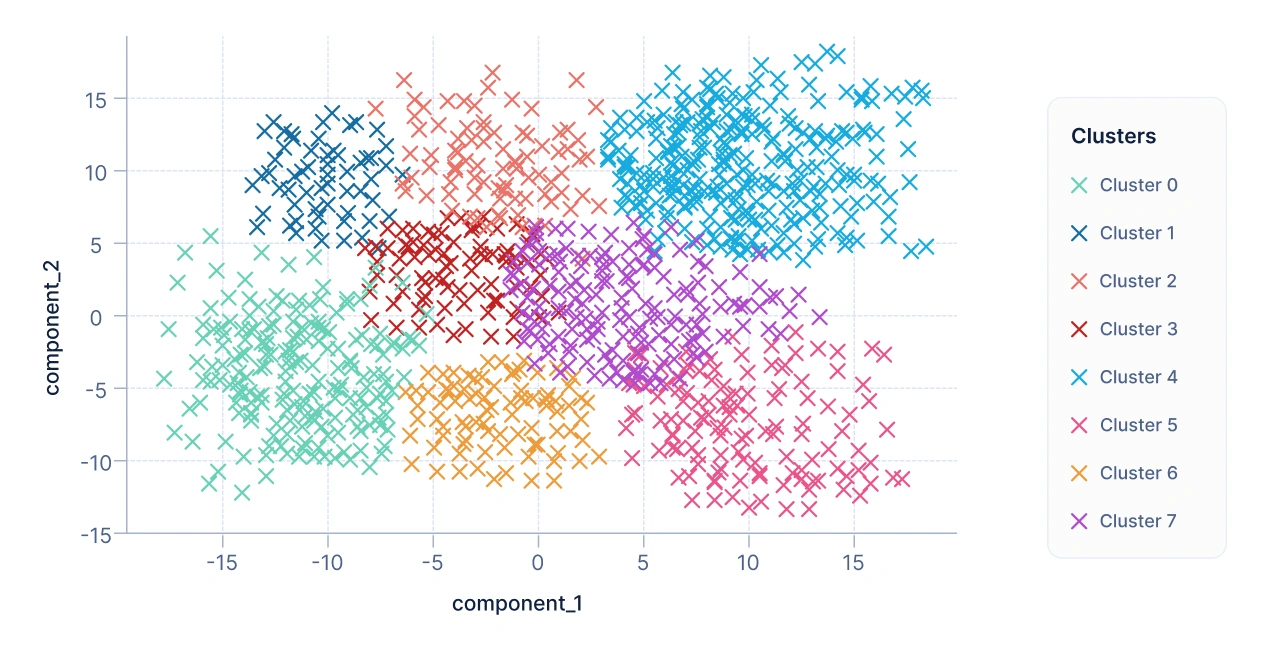
上記のプロットから、形成された各クラスターは類似した属性と関心を持つ顧客のグループを表していることがわかります。企業はこれらの顧客セグメントをターゲットにして収益と利益を増加させることができます。
K-Meansはセントロイドベースのクラスタリングに分類されるアルゴリズムの1つです。QuickMLは、異なるタイプのクラスタリングに分類されるさまざまなアルゴリズムもサポートしています。クラスタリングの種類を見てみましょう。
クラスタリングの種類
クラスタリング手法は、それぞれ独自のアプローチと応用を持つ4つの主要タイプに大別できます。
1. セントロイドベースのクラスタリング:各クラスターを表す中心点(セントロイド)に依存します。データポイントは最も近いセントロイドのクラスターに割り当てられ、データポイントとこれらのセントロイド間の距離を最小化することでクラスターが形成されます。一般的な例は顧客セグメンテーションで、平均月間支出に基づいて購入者を予算、中間価格帯、プレミアムなどのカテゴリにグループ化します。
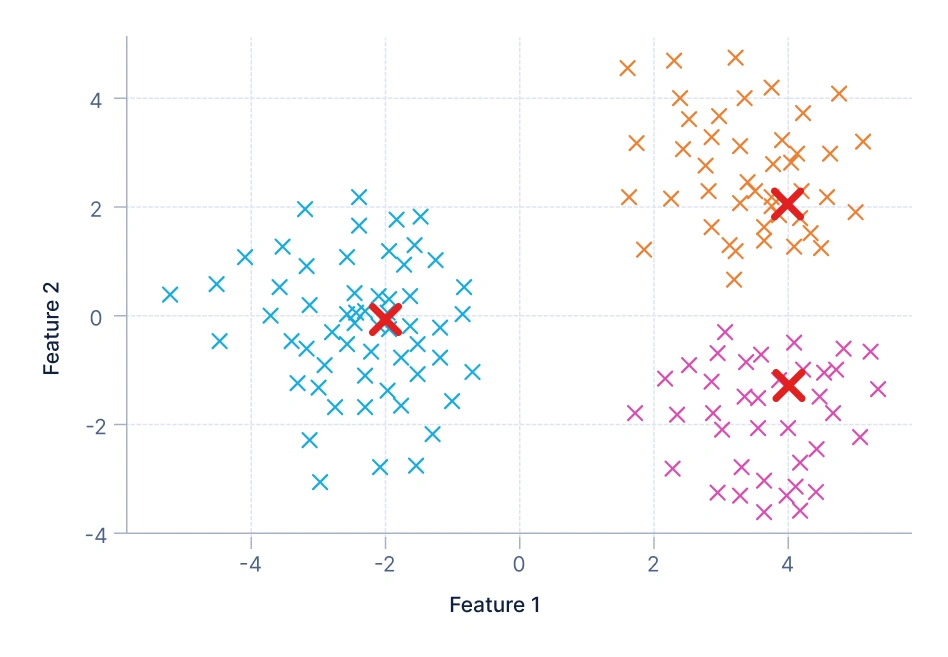
この可視化では、データポイントがセントロイド(赤いXマーカー)の周囲にグループ化されています。各色は異なるクラスターを示し、すべてのポイントは最も近いセントロイドのクラスターに属します。目標は、ポイントと割り当てられたセントロイド間の合計距離を最小化することです。この方法は、クラスターがおおよそ球形で均等なサイズであることを前提としており、単純でよく分離されたデータ分布に適しています。K-MeansやMiniBatchKMeansがセントロイドベースのクラスタリングの例です。
2. メドイドベースのクラスタリング:セントロイドに似ていますが、計算されたセントロイドの代わりに、メドイドと呼ばれる実際のデータポイントをクラスター代表として選択します。これにより、クラスターは実際の観測値に固定されるため、ノイズや外れ値に対してより堅牢になります。たとえば、通信会社は通話行動データから実際の代表的な顧客プロファイルを選択してユーザーをグループ化するために、メドイドベースのクラスタリングを使用する場合があります。
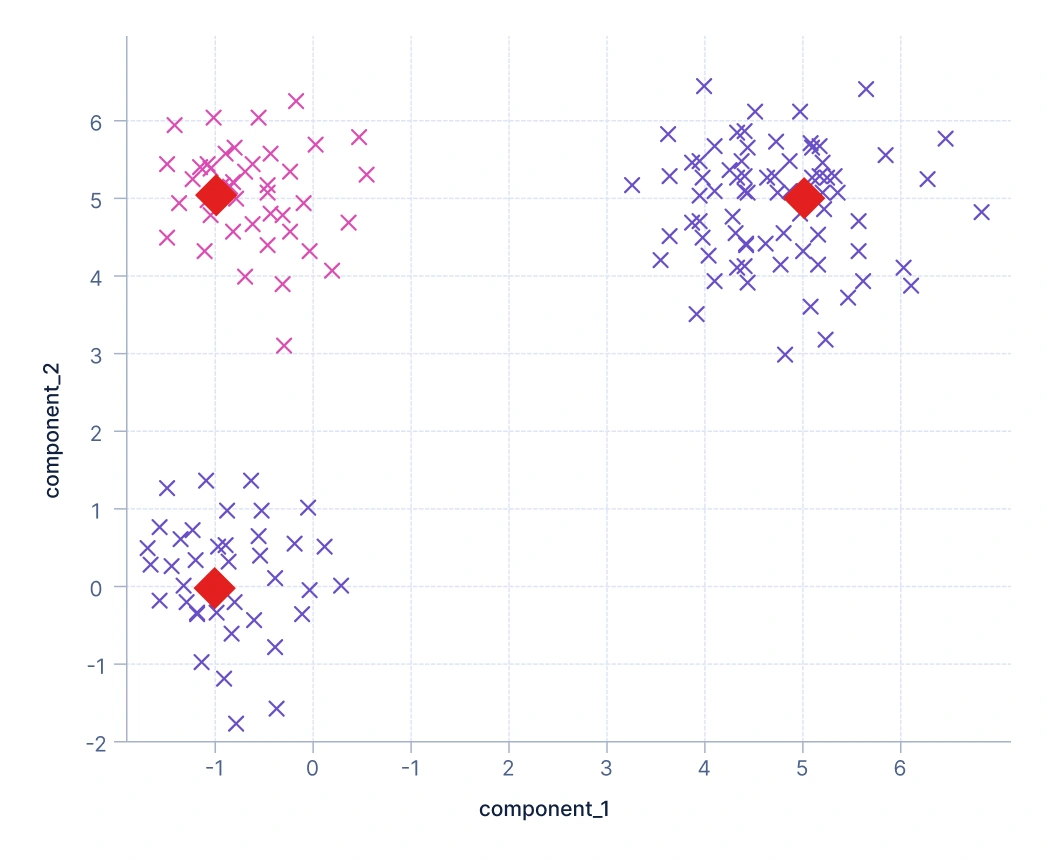
ここでは、クラスターはメドイド(赤いダイヤモンドマーカーで表示される実際のデータポイント)によって表されています。セントロイド(平均値)とは異なり、メドイドはデータセットからの実際の観測値であり、クラスター内の他のポイントとの合計非類似度を最小化します。これにより、極端な値がクラスター中心に与える影響が小さくなるため、ノイズや外れ値に対してより堅牢になります。プロットは、代表的なデータポイントの周囲にクラスターがどのように形成されるかを示しています。K-Medoids、CLARA、CLARANSがこの原則に従うアルゴリズムです。
3. 密度ベースのクラスタリング:データポイントの密な領域を特定してクラスターとして扱い、密度の低い領域をセパレータとする異なるアプローチを取ります。その強みの1つは外れ値の自然な検出であり、密な領域に属さないポイントはノイズとしてマークされます。典型的な応用は金融詐欺検出であり、密な領域は通常の支出行動に対応し、まばらなまたは孤立したポイントは疑わしい取引を示します。
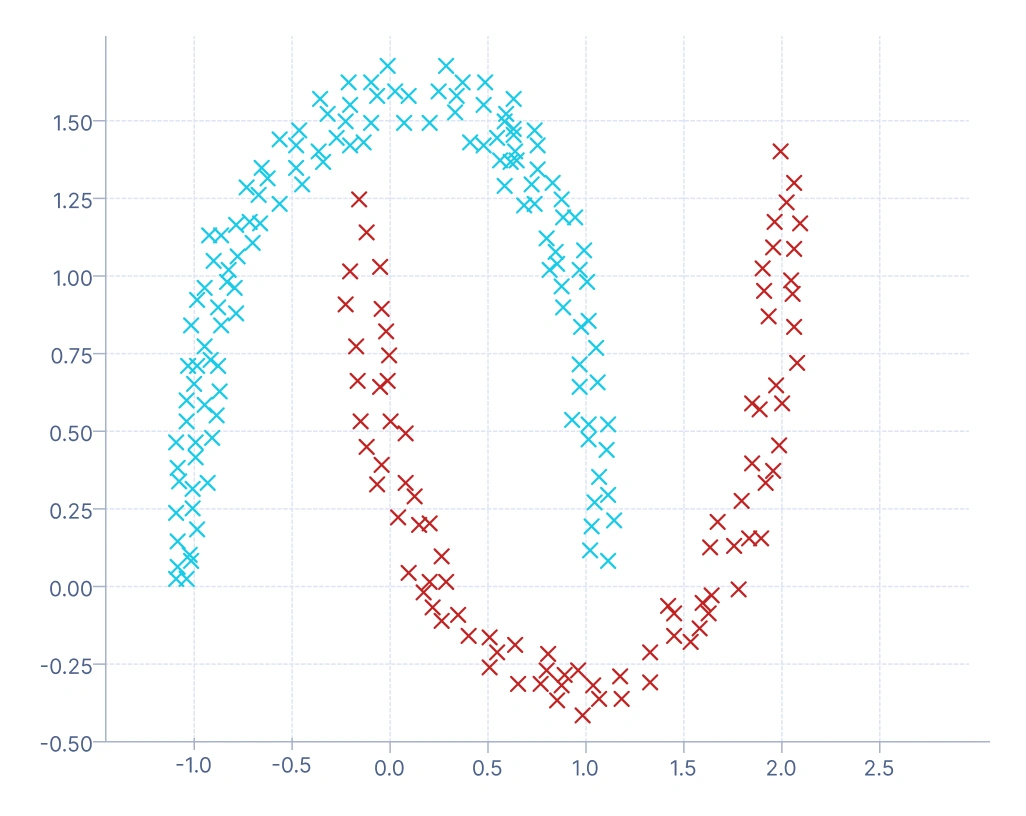
このプロットでは、データ密度の高い領域に基づいてクラスターが形成されています。アルゴリズムは近くにあるポイントをグループ化し、低密度領域のポイントをノイズとしてラベル付けします(DBSCANでは-1などの異なる色でマークされることが多い)。このアプローチは、セントロイドやメドイドベースの方法では困難な複雑で非球形のクラスター形状(湾曲した「two moons」パターンなど)を捉えることができます。不規則な境界を持つデータセットや外れ値の検出が重要な場合(不正や異常検知など)に最適です。
4. モデルベースのクラスタリング:データが基礎となる確率分布の混合から生成されたと仮定し、ハードラベル(K-Meansのように各データポイントが正確に1つのクラスターに割り当てられる)ではなく、クラスターメンバーシップの確率を割り当てます。この確率的フレームワークは、重複する音声パターンをガウス分布の混合としてモデル化できる音声認識などの複雑なドメインで特に有用です。
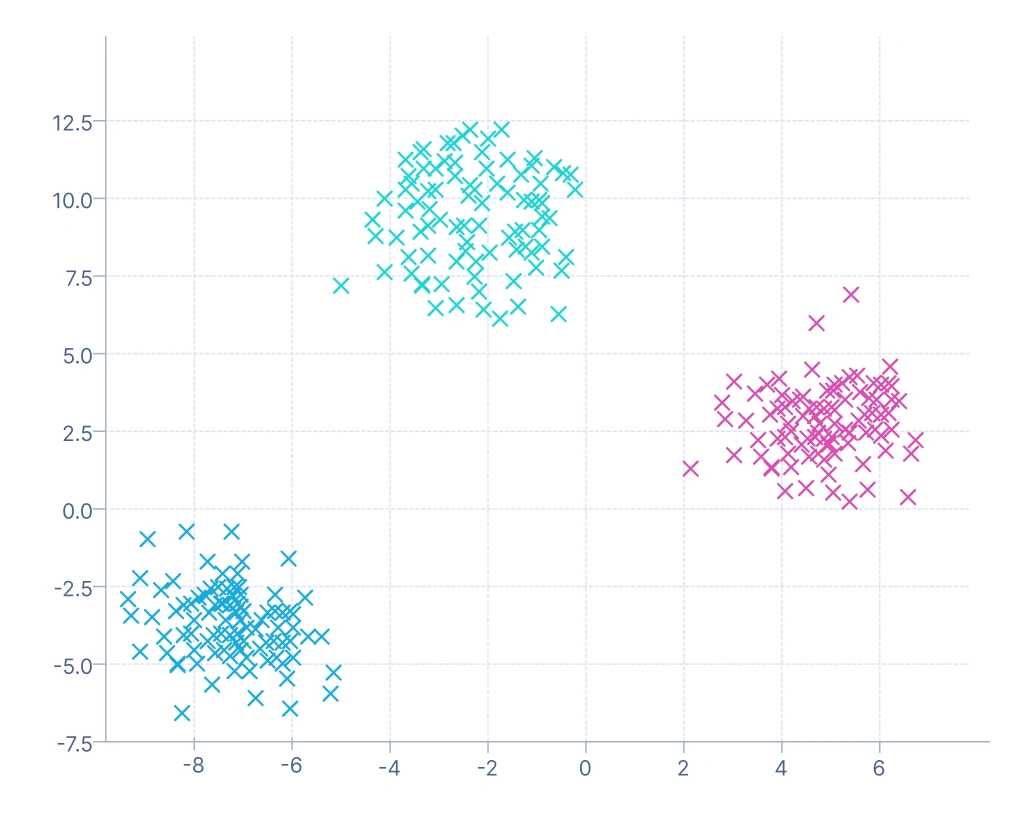
この可視化は、データをガウス分布の混合としてモデル化して形成されたクラスターを示しています。各クラスターは1つのガウスコンポーネントに対応し、データポイントには確率的なメンバーシップがあります。つまり、ポイントは部分的に複数のクラスターに属することができます。色は各ポイントの最も可能性の高いクラスター割り当てを示します。この方法は、K-Meansよりも重複する楕円形のクラスターをよりよく処理し、より複雑で連続的なデータ分布に適しています。
QuickMLでクラスタリングパイプラインを構築する手順
QuickMLでのクラスタリングパイプラインの構築にはClassic Builderを使用し、クラスターの正確な特定とアクションにつながるインサイトを確保します。
ステップ1:データ取り込み
プロセスはデータセットをQuickMLにロードすることから始まります。これがクラスタリングワークフローの基盤となります。このステップでは、CSVファイル、データベース、クラウドストレージシステムなどのさまざまなソースからデータをインポートします。
ステップ2:前処理
データが取り込まれると、品質と一貫性を確保するための前処理フェーズを経ます。このステップには、補完や除去による欠損値の処理、ラベルエンコーディングやワンホットエンコーディングなどの手法によるカテゴリカル変数のエンコーディング、データ品質とモデルパフォーマンスを向上させるためのデータ変換技術の適用が含まれます。効果的な前処理はバイアスを低減し、距離ベースのアルゴリズムがすべての特徴を公平に扱うことを保証することで、クラスタリングの精度を向上させます。
ステップ3:アルゴリズム選択
前処理後、QuickMLではデータ特性と望む結果に基づいて適切なクラスタリングアルゴリズムを選択できます。K-Means、DBSCAN、BIRCH、Gaussian Mixture Models(GMM)などのアルゴリズムを、データセットがよく分離された、密度ベースの、または確率的なクラスター構造を持つかに応じて適用できます。正しいアルゴリズムの選択は、異なる方法がデータ内の異なるタイプの関係と構造を捉えるため、非常に重要です。
ステップ4:モデルトレーニング
このステップでは、選択されたアルゴリズムが処理済みデータに適用され、自然なグループ分けを特定します。モデルは、定義された類似性または距離の尺度に基づいて類似するデータポイントを同じクラスターに割り当てることで反復的に学習します。K-Meansのクラスター数やDBSCANのイプシロン値などの主要パラメータが微調整され、意味のある安定した結果が生成されます。このフェーズの結果は、データセット内の隠れたパターンと構造を明らかにする独自のデータクラスターの特定です。
ステップ5:クラスター評価
クラスターが形成された後、QuickMLはさまざまな統計指標を使用してその品質と妥当性を評価します。一般的に使用される指標には、各データポイントがクラスター内にどの程度適合しているかを測定するSilhouette Score、クラスターのコンパクトさと分離を評価するCalinski-Harabasz Score、平均クラスター類似性を評価するDavies-Bouldin Scoreが含まれます。これらの評価指標は、クラスタリング結果が実用的なアプリケーションに対して解釈可能で信頼性があるかどうかを判断するのに役立ちます。
クラスタリング評価指標
以下の評価指標は、グループがどの程度分離されているか、どの程度コンパクトか、クラスターがデータ内の意味のある類似性を明らかにしているかなど、クラスタリングモデルのパフォーマンスのさまざまな側面に関するインサイトを総合的に提供します。教師あり学習とは異なり、クラスタリングには事前定義されたラベルがないため、これらの指標はクラスターの品質を判断するためのガイド指標として機能します。
QuickMLでクラスタリングモデルの評価に一般的に使用される指標について説明します:
1. Silhouette Score
内容:データポイントが自身のクラスターと他のクラスターに対してどの程度類似しているかを測定します。
直感的理解:
- Silhouette scoreは-1から+1の範囲です。
- 高いスコア(+1に近い)は、データポイントが適切にクラスタリングされており、密なグループ分けと他のクラスターからの明確な分離があることを示します。
- 0に近いスコアは、クラスターの重複またはクラスター間の境界上にあるポイントを示唆します。
- 負のスコア(-1に近い)は、ポイントが誤ったクラスターに割り当てられているか、クラスターが大幅に重複しているクラスタリングの品質の悪さを示します。
推論の例: Silhouette scoreが0.52の場合、クラスターはかなり良好に形成され分離されていますが、データポイント間にはまだ一部重複があることを意味します。
2. Calinski-Harabasz Score
内容:クラスター間の距離(クラスター間分散)と各クラスター内のポイントの密度(クラスター内分散)を比較するスコアです。
直感的理解:
- スコアは非有界で-∞から+∞の範囲です(高いほど良い)。
- 高いスコアは、クラスターが内部でコンパクトであり、他のクラスターからよく分離されていることを示します。
- 低いスコアは、クラスターが内部で広がっているか、明確に分離されていないことを示唆します。
推論の例: Calinski-Harabasz scoreが950の場合、クラスターが比較的密で明確に区分されており、良好な分離構造を示していることを示唆します。
3. Davies-Bouldin Score
内容: クラスター内距離とクラスター間分離の比率に基づいて、クラスター間の平均類似性を測定します。
直感的理解:
- スコアは-∞から+∞の範囲です(低いほど良い)。
- 低いスコアは、クラスターがより明確で重複が少ないことを意味します。
- 高いスコアは、クラスター間に顕著な類似性があり、分離が不十分であることを示唆します。
推論の例: Davies-Bouldin scoreが0.60の場合、クラスターはかなり良好に分離されていますが、完全には区別されておらず、一部の重複がまだ存在することを示します。
4. クラスター数
アルゴリズムがデータセット内で特定した異なるグループの数を示します。
推論の例: モデルが3つのクラスターを出力する場合、データセットが3つの異なるグループ(たとえば、予算型、中間価格帯、プレミアム型の3種類の顧客セグメント)に意味を持って分割できることを示唆します。
クラスターの視覚的評価
数値スコアに加えて、クラスター評価はQuickMLでの可視化を通じても行うことができます。クラスター分布とクラスタープロットは、データ内のバランス、分離、構造について直感的な理解を提供します。
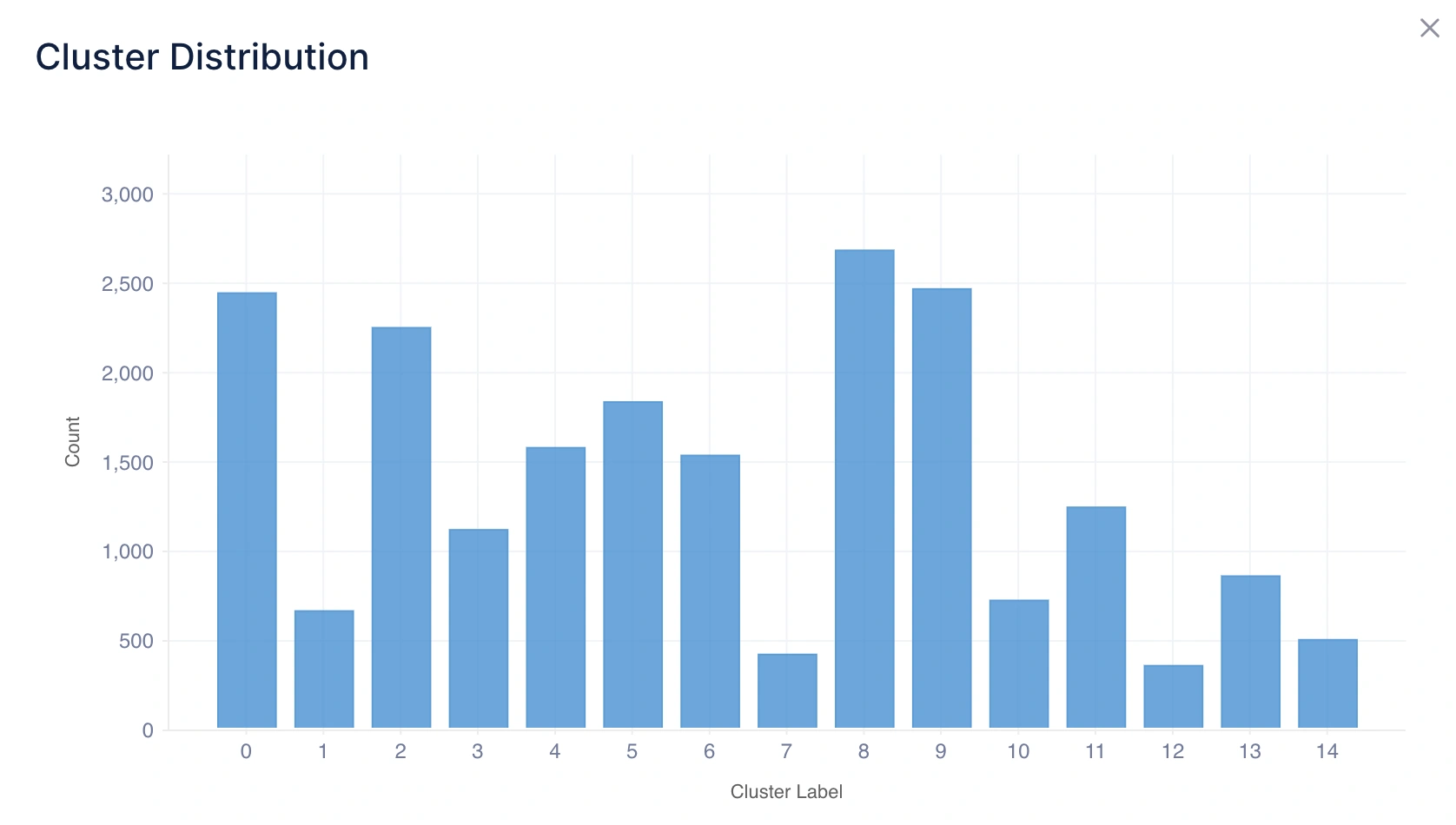
1. クラスター分布
内容: ヒストグラムチャートを使用して各クラスターに含まれるデータポイントの数を表示します。
直感的理解:
- バランスの取れた分布は、クラスターが比較的均等なサイズであることを意味し、自然なグループ分けを示すことが多いです。
- アンバランスな分布は、1つ以上のクラスターがサイズで支配的であることを意味し、実世界の支配性(例:ほとんどの顧客が1つのセグメントに属する)またはクラスタリング手法の制限を示唆する場合があります。
推論の例: Cluster 0に600ポイント、Cluster 1に150ポイント、Cluster 2に30ポイントがある場合、大部分のデータポイントがCluster 0に属し、Cluster 1と2はより小さなニッチグループを表すことを示唆します。
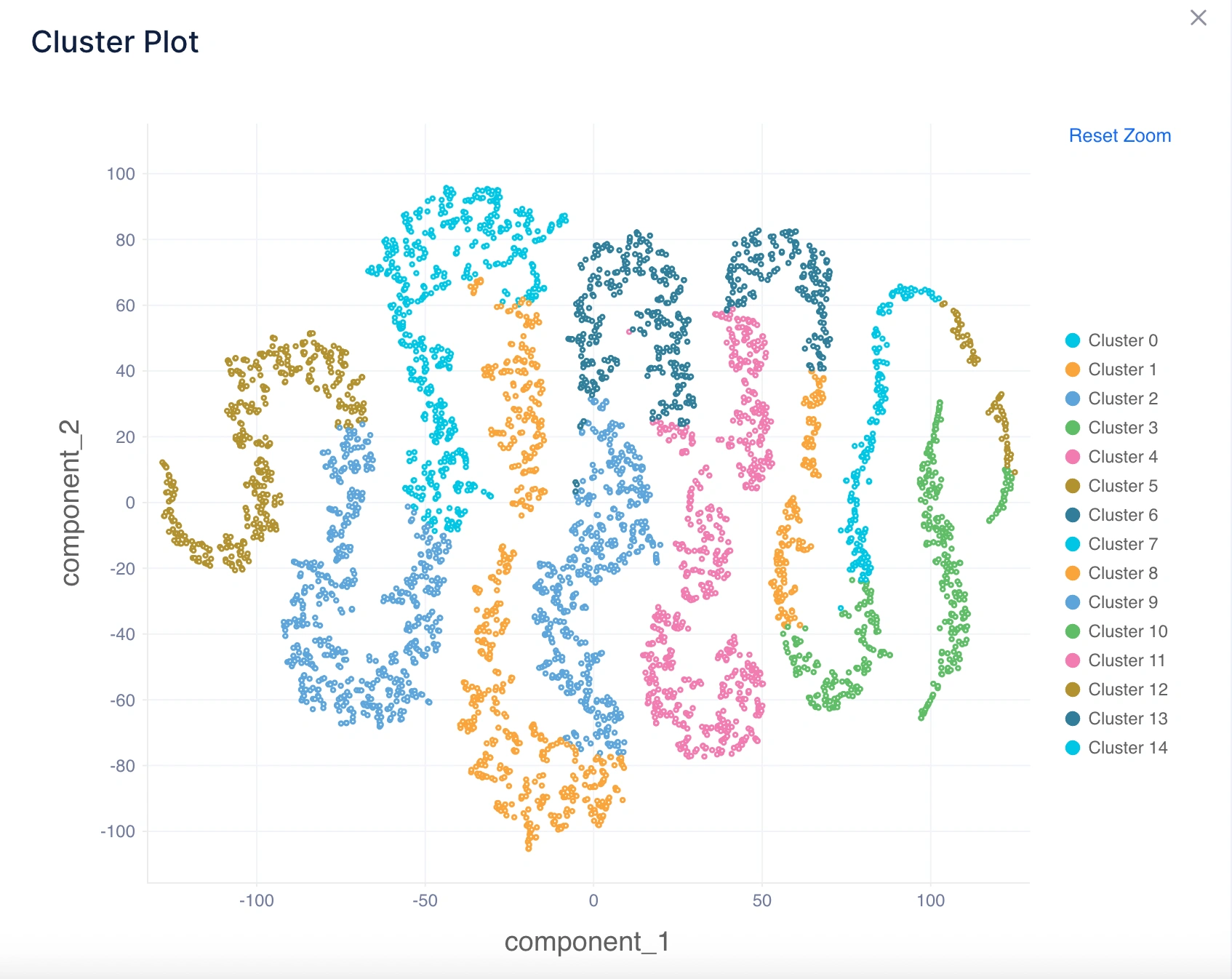
2. クラスタープロット
内容: 散布図を使用して、低次元空間でクラスターがどのように分離されているかを可視化します(通常、次元削減のためにPCAまたはt-SNEを使用)。
直感的理解:
- プロット内でよく分離されたクラスターは、クラスタリングアルゴリズムの良好なパフォーマンスを示します。
- 重複するクラスターは、割り当ての曖昧さを示唆し、アルゴリズムがグループを明確に分離するのが困難であったことを意味します。
推論の例: プロットに明確な境界を持つ視覚的に識別可能なグループが表示される場合、アルゴリズムが意味のあるクラスターを特定したことが確認されます。グループが大幅に重複している場合、異なるアルゴリズム(不規則な形状のためのDBSCANなど)をテストする必要があることを示唆します。
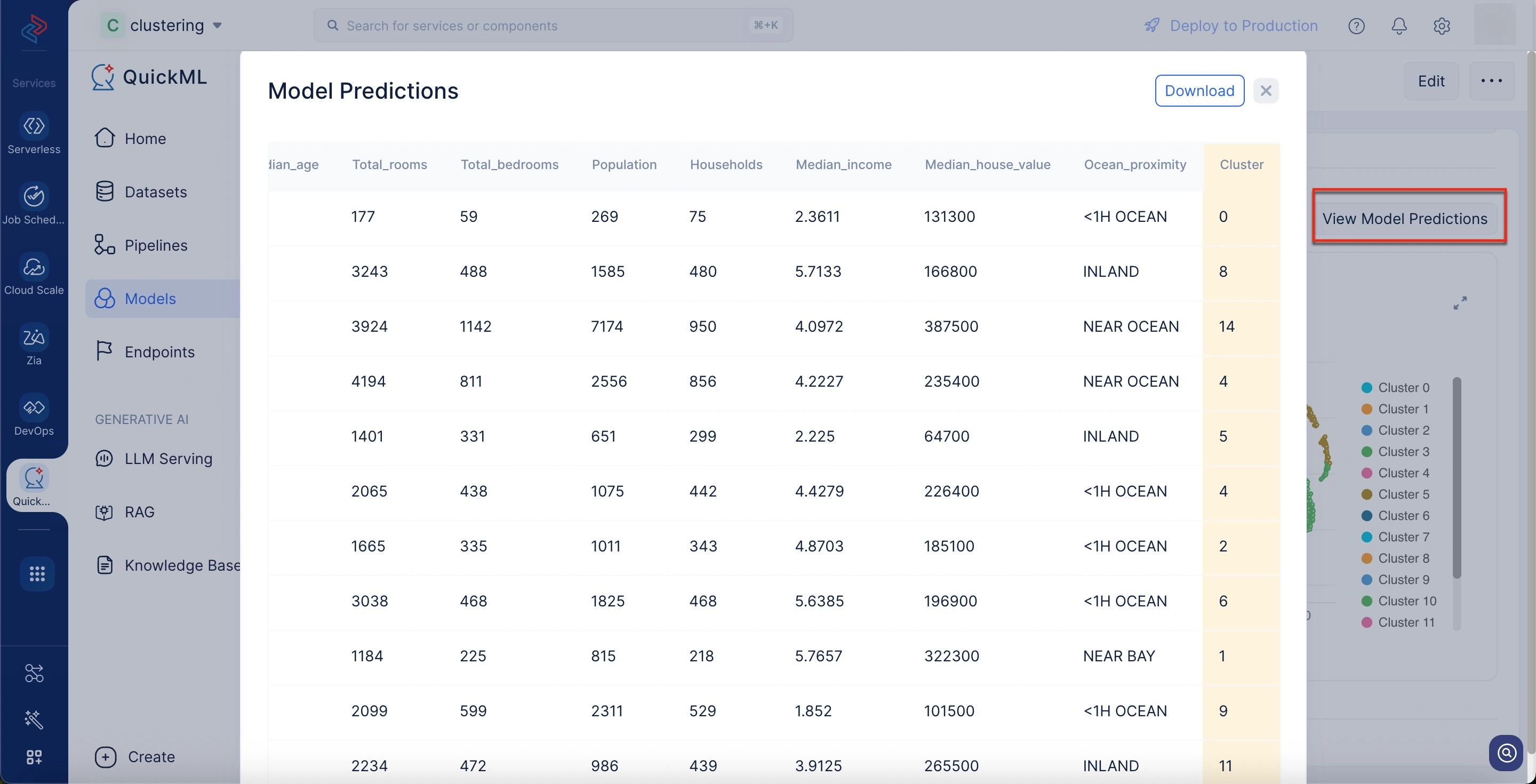
3. モデル予測のダウンロード
内容: データセット全体に対するモデルのクラスタリング結果をエクスポートできます。各データポイントには、それが属するクラスターのラベルが付けられます。
利点:
- データポイントからクラスターへの直接的なマッピングを提供し、QuickML外での個別の割り当て分析が容易になります。
- クラスタープロファイリング、外部データとの相互参照、ターゲットを絞ったアクション(特定の顧客セグメントへのマーケティングなど)などの下流分析が可能になります。
- どのデータポイントがどのクラスターに割り当てられたかを正確に確認できるため、透明性とトレーサビリティを提供し、検証とレポートに役立ちます。
モデル予測をダウンロードするには
- 目的のモデル詳細ページに移動します。
- Visualizationsセクションまでスクロールします。
- クラスタープロットチャートの上にあるView Model Predictionsボタンをクリックします。
Model Predictionsポップアップウィンドウが表示され、予測をダウンロードできます。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us