異常検知
はじめに
異常検知は、データセット内の期待される動作から大幅に逸脱するデータポイント、イベント、またはパターンを特定するプロセスです。これらの異常な観測値は外れ値とも呼ばれ、不正行為、機器の故障、サイバーセキュリティの脅威、消費者行動の予期しない変化などの重大な状況を示す可能性があります。
QuickMLでは、異常検知に教師なし学習アルゴリズムを広く使用しています。アルゴリズムは事前定義されたラベルに依存せず、正常性のパターンを学習します。何が異常を構成するかを明示的に指示されるのではなく、アルゴリズムは正常な動作の理解を構築し、通常の期待範囲内に収まらないデータポイントを強調します。これにより、異常検知は異常がまれである場合、ラベルが利用できない場合、または正常なパターンが非常に動的な場合に特に価値があります。
クレジットカード取引のデータセットを想像してください。ほとんどの取引は金額、頻度、場所の観点から典型的なパターンに従います。しかし、外国での突然の高額購入は異常としてフラグ付けされる可能性があります。この異常をリアルタイムで検出することで、不正行為を防止し、顧客を保護し、金融機関のコストを節約できます。
異常検知のビジネスインパクト
異常検知は、組織が資産を保護し、運用を改善し、意思決定を強化することを可能にする、ビジネスクリティカルなプロセスです。異常検知が業界全体で不可欠な主要な理由は以下のとおりです:
-
不正検出:金融やeコマースでは、異常はしばしば不正行為に対応します。たとえば、顧客の通常の支出行動と比較して、外国からの異常に高額な購入は、クレジットカード詐欺の初期兆候である可能性があります。これらのパターンをリアルタイムで特定することで、経済的損失を防止し、顧客の信頼を守ります。
-
予知保全:製造業や産業環境では、機械がセンサーデータを継続的に生成します。振動、温度、圧力の読み取り値の異常を検出することで、機械的な摩耗や故障の初期兆候を示すことができます。これらの異常を故障に至る前に予測して対処することで、ダウンタイムとメンテナンスコストを大幅に削減できます。
-
サイバーセキュリティとネットワーク保護:異常検知は、システムログ、ネットワークトラフィック、ユーザーアクティビティにおける不規則性を特定するのに役立ちます。これらはサイバー攻撃、データ侵害、不正アクセスを示す可能性があります。たとえば、ログイン試行やデータ転送量の突然の急増は、即座の対応が必要なセキュリティ脅威を明らかにする可能性があります。
-
ヘルスケアとライフサイエンス:ヘルスケアでは、異常検知は患者のバイタル、検査結果、医療画像データを監視して潜在的な健康リスクをフラグ付けできます。たとえば、酸素飽和度の突然の低下や不規則な心拍パターンは、状態が重篤になる前に医師に介入を警告できます。
-
運用インサイトと意思決定支援:組織は異常検知を使用して、効率を改善し意思決定をサポートする隠れたインサイトを発見できます。たとえば、ウェブサイトトラフィックの異常な急増は、マーケティングキャンペーンの成功や予期しない顧客の関心を明らかにする可能性があります。
データ異常の原因
データ異常は、データの性質と収集環境に応じてさまざまな根本原因から発生する可能性があります。主な要因は以下のとおりです:
-
人的エラー:手動データ入力のミス、不正確なラベリング、システムの不適切な設定により、容易に不規則性が導入される可能性があります。たとえば、小数点の誤配置や不正確な日付形式は、分析結果を大幅に歪める可能性があります。レコードの更新忘れやエントリの重複などの単純な見落としも、異常なデータポイントにつながる可能性があります。
-
システム障害:ハードウェアの故障、ソフトウェアの不具合、システム間の通信障害により、データが破損または歪む可能性があります。たとえば、データ送信中の一時的なネットワーク障害により、不完全または重複したエントリが生じる可能性があります。一方、ソフトウェアのバグにより、予期しない値や不整合が生成される可能性があります。
-
不正行為や悪意のある活動:金融、サイバーセキュリティ、eコマースなどの分野では、異常はしばしば潜在的な不正行為や不正アクセスのシグナルとなります。異常に高額な取引、異常なログインパターン、ユーザー行動の突然の変化は、システムを悪用または操作しようとする意図的な試みを示す可能性があります。
-
環境的または外部的変化:経済変動、市場のボラティリティ、季節変化などの外部条件の予期しない変化により、通常のデータパターンが変化する可能性があります。これらのイベントは、確立されたトレンドからの一時的または永続的な逸脱を引き起こす新しい変数を導入します。
異常検知の種類
異常は、データの性質とコンテキストに応じていくつかのタイプに分類できます。以下のセクションでは、各タイプを対応する可視化と概念的な例とともに詳細に説明します。
- ポイント異常
ポイント異常は、単一の観測値がデータの残りの部分から大幅に逸脱する場合に発生します。これらは最も一般的な異常であり、通常は検出が容易です。
たとえば、クレジットカード取引のデータセットで、突然の高額取引がユーザーの以前の支出行動と一致しない場合、ポイント異常としてフラグ付けされる可能性があります。
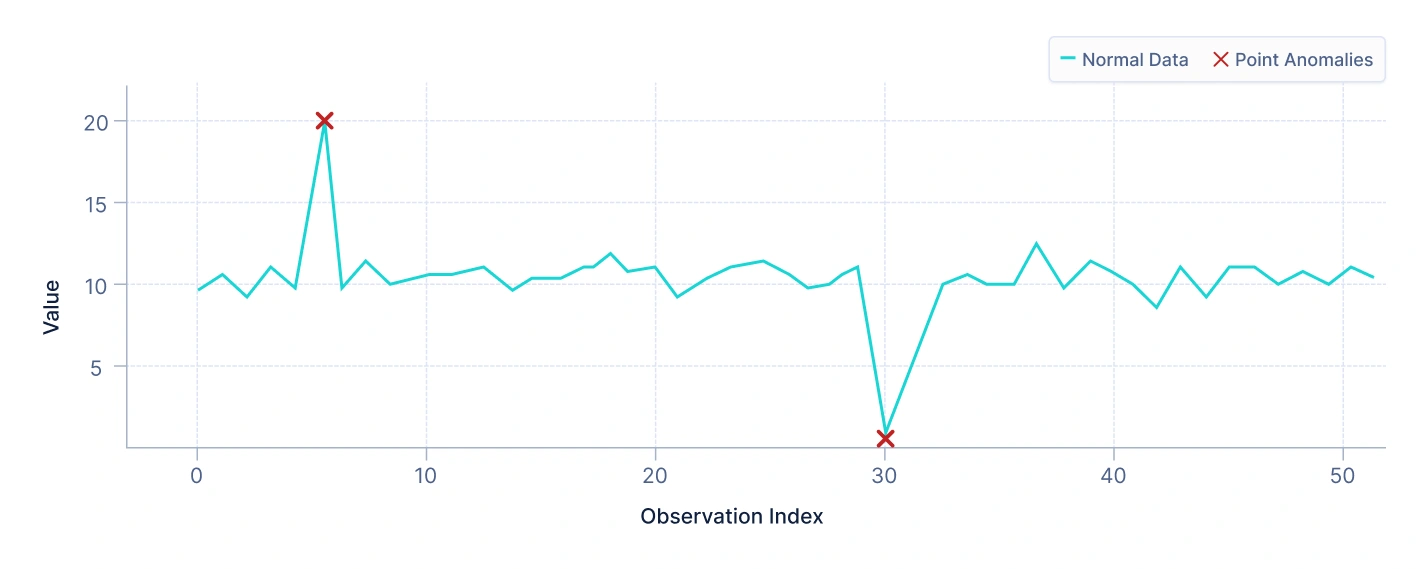
解釈:上記のプロットは、いくつかのデータポイントが主要なデータクラスターから遠く離れた位置にあることを示しています。これらの孤立したデータポイントは、正常なデータポイントの大部分と大幅に異なるため、ポイント異常の明確な例です。
- コンテキスト異常
コンテキスト異常は、特定のコンテキスト内でのみ異常と見なされる観測値です。このタイプの異常は、同じ値がある条件下では正常であるが、他の条件下では異常である可能性があるデータセットで特に一般的です。
たとえば、10°Cの気温は冬には正常ですが、夏には異常となります。同様に、オンラインストアは休日のセール中に多数の購入を見ることがありますが、通常の日に同じ数は疑わしい活動を示す可能性があります。
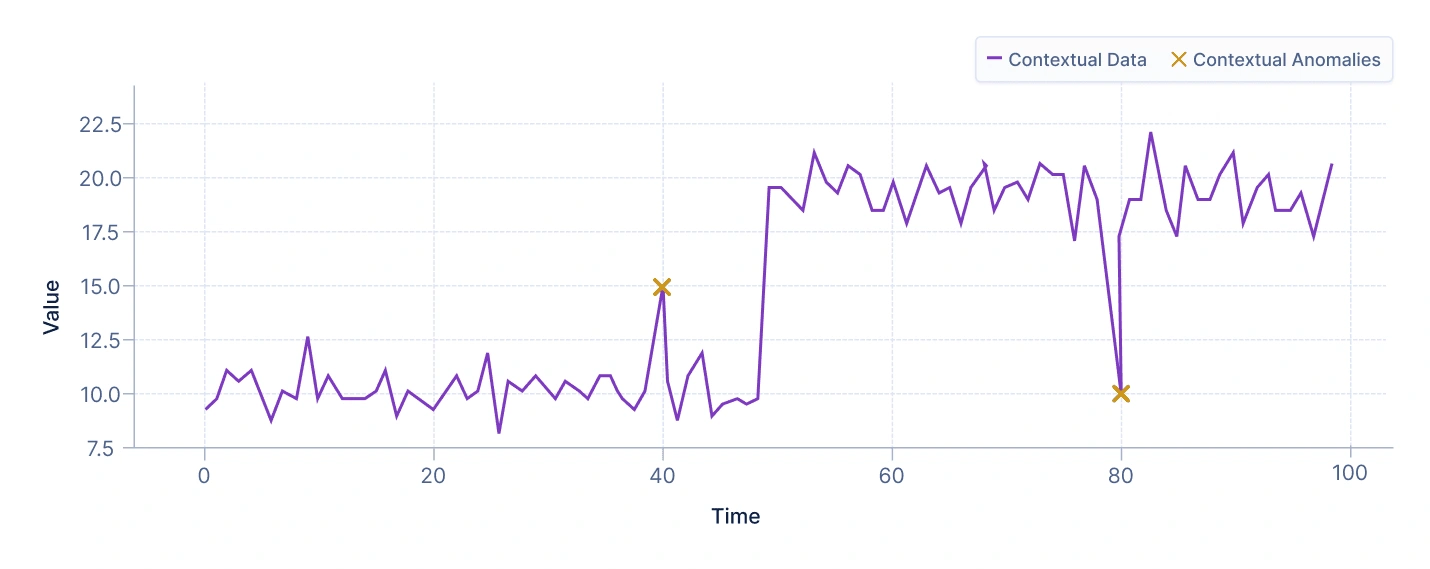
解釈:プロットは、2つの異なるコンテキストを示しており、それぞれが別々のデータポイントのクラスターで表されています。これらのクラスターは、データが正常に振る舞う異なるパターンまたは環境を反映しています。強調されたポイントはクラスターの1つの近くにあり、データセット全体と比較するか、別のクラスターのコンテキストで評価すると正常に見えます。しかし、自身のクラスター内では(ローカルコンテキストにおけるポイントの特定の特性と分布と比較して分析すると)、そのポイントは異常として目立ちます。この状況は、観測値がより広いまたは異なるコンテキストでは正常に見えるかもしれないにもかかわらず、特定のコンテキストまたは条件下でのみ異常と見なされるコンテキスト異常を強調しています。
- 集団異常
集団異常は、関連するデータポイントのグループが全体として異常に振る舞う場合に発生し、個々のポイントは正常に見える場合でも発生します。
たとえば、株式市場データにおいて、企業の株価が連続数日にわたって一貫して下落する場合、このパターンが通常の変動から逸脱する場合、集団異常を表す可能性があります。
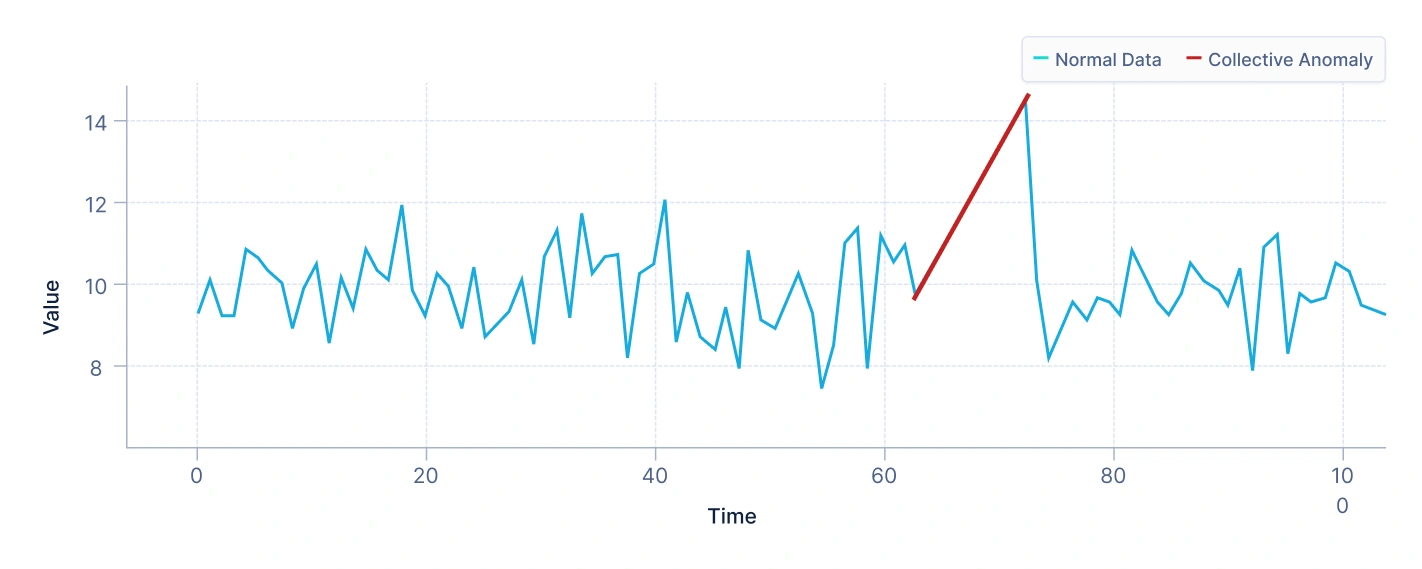
解釈:上記のプロットは、大部分のデータとは別に明確なクラスターを形成する小さなポイントグループを示しています。このグループ内の各ポイントは個別に評価すると正常に見える場合がありますが、その集団的な行動は全体的な分布から大幅に逸脱するパターンを明らかにします。これは集団異常の存在を示しており、異常は個々のデータポイントからではなく、互いの関係およびデータセットの残りの部分との関係から生じます。
異常検知のカテゴリ
QuickMLでは、異常検知には2つの広いカテゴリがあります:時系列異常検知と非時系列異常検知です。これらの各アプローチは、時間がデータの構造に役割を果たすかどうかに応じて、異なるタイプのデータセットでの外れ値の特定に焦点を当てています。
時系列と非時系列の異常検知の違いを示す比較表は以下のとおりです:
| 特徴 | 時系列異常検知 | 非時系列異常検知 |
|---|---|---|
| データ構造 | データポイントは時間でインデックス付けされ、順序に従います。 | データポイントは時間でインデックス付けされず、独立した観測として扱われます。 |
| 時間的依存性 | 時間的依存性、トレンド、季節性を考慮するアルゴリズムが必要です。 | データポイントは独立しており、時間的関係はないと仮定します。 |
| 検出方法 | 実際の値を過去のパターンまたは予測と比較して異常を検出します。 | 特徴空間でのデータポイント間の類似性または距離を評価して異常を検出します。 |
| 影響要因 | 季節性、トレンド、時間における長期的な依存性の影響を受けます。 | 特徴間の関係と複数の変数にわたるデータ分布の影響を受けます。 |
| 一般的なアルゴリズム | ARIMA、LSTM Autoencoders、Prophet、Isolation Forest(時間ベース)。 | Isolation Forest、One-Class SVM、DBSCAN、LOF。 |
| ユースケースの例 | 株価、機械センサーの読み取り値、ネットワークパフォーマンスの時系列監視。 | 不正取引、欠陥製品、異常な顧客行動の検出。 |
| 主要な焦点 | 時間経過に伴うパターンの逸脱に焦点を当てます。 | 時間を考慮せずに特徴ベースの外れ値に焦点を当てます。 |
時系列と非時系列の異常検知の主要な違いを理解したところで、より明確で包括的な理解を得るために、それぞれのアプローチを詳細に見ていきましょう。
時系列異常検知
時系列異常検知は、各データポイントが特定のタイムスタンプに関連付けられた、順序的に収集・整理されたデータを扱います。このタイプのデータは、株価、サーバーパフォーマンス指標、センサーの読み取り値、ウェブサイトトラフィックなど、値が時間とともにどのように変化するかを反映します。時間はデータセットの固有の部分であるため、異常の検出にはトレンド、季節性、突然の逸脱などの時間的パターンの分析が含まれます。
時系列異常検知では、システムの動作が過去のパターンと比較して予期せず変化する瞬間を特定することが目標です。これらの異常は、突然のスパイク、急激な低下、またはデータの通常のリズムから外れる不規則な変動として現れることがあります。
時系列異常検知手法は、過去のトレンドから学習して将来の期待値を予測する予測モデルを使用することが多いです。実際の観測値が予測値から大幅に逸脱した場合、システムはそれを異常としてフラグ付けします。
時系列異常検知の背景にある直感的理解
時系列データセットでは、観測値は時間順に並べられており、各データポイントは以前の値に依存する場合があります。異常の検出には、特徴間の関係に加えて、時間的パターン、トレンド、季節性の理解が含まれます。目標は、期待される時間的動作から逸脱するポイントまたは期間を特定することです。
-
時間的パターンの視点:各観測値はシーケンスの一部であり、正常なポイントはトレンド、季節的なサイクル、繰り返しの変動など、時間経過に伴う予測可能なパターンに従います。異常はこれらのパターンを破り、期待される動作から逸脱する異常なポイントまたはシーケンスとして目立ちます。
-
トレンドと季節性の考慮:確立されたトレンドからの突然のスパイク、低下、シフトはしばしば異常を示します。逸脱は期待される季節パターンに違反する場合にのみ異常となる可能性があるため、季節変化を考慮することが不可欠です。たとえば、高い売上値はホリデーシーズンには正常ですが、典型的なオフシーズンには異常である可能性があります。トレンドと季節性を適切にモデリングすることで、システムは期待される変動と真の異常を区別できます。
-
コンテキスト依存性:時間ベースのコンテキストは重要です。同じ値がある時点では正常であるが、周囲のシーケンスに応じて別の時点では異常である可能性があるためです。さらに、複数の時間依存変数間の関係は、単一の系列を単独で分析した場合には明らかにならない異常を明らかにする可能性があります。これらの多変量時間依存性を考慮することで、複数の要素が一緒に観測された場合にのみ出現するパターンを捉えることで、検出精度が向上します。
-
時間経過に伴う密度と分布:異常は、期待される時間分布内の低確率領域で発生することが多いです。予測範囲や過去のベースラインから遠く離れたポイントは異常としてフラグ付けでき、ガウス過程や過去の分布モデリングなどの確率的アプローチによりこれらの逸脱を定量化できます。時間経過に伴う観測の期待密度を理解することで、モデルは各ポイントが通常の時間的動作と比較してどの程度起こりにくいかを反映する異常スコアを割り当てることができます。
時系列異常検知の主要成功基準
時系列異常検知は、時間経過に伴うデータポイントのシーケンスに焦点を当てます。成功は、時間的パターン、トレンド、季節性を捉えながら、解釈可能でアクションにつながるインサイトを提供することにかかっています。成功の主要基準は以下のとおりです:
-
時間データの理解:トレンド、季節性、短期および長期の依存性を正確にモデリングします。品質データの準備:欠損タイムスタンプ、不規則な間隔、一貫性のないサンプリングレートを処理します。
-
効果的な特徴量エンジニアリング:時間的動作を捉えるために、ラグ特徴量、移動統計量(平均、分散)、差分、フーリエ変換を含めます。
-
代表的な過去のパターン:誤検出を減らすために、トレーニングデータが稀な季節パターンを含む通常の時間変動を反映していることを確認します。
-
堅牢なモデル選択:時間的依存性、トレンド、季節性を捉えることができるアルゴリズムを選択します。たとえば、ARIMA、AutoRegressor、Auto ARIMA、SARIMAなどです。
時系列異常検知のビジネス応用
時系列異常検知は業界全体で幅広い応用があり、値が時間とともにどのように変化するかを監視することで、組織が異常なパターンを特定し、障害を防止し、データ駆動型の意思決定を行うのに役立ちます。
-
金融と銀行業
金融と銀行業における時系列異常検知は、不正行為やその他の不規則な活動を示す可能性のある異常なパターンについて、取引のシーケンスを監視するために使用されます。送金の突然のスパイク、異常な取引行動、非典型的な口座活動をリアルタイムでフラグ付けでき、銀行や金融機関が疑わしい行動を迅速に調査できるようにします。取引の時間的パターンを分析することで、モデルは正当な季節的または循環的な活動と、注意が必要な真の異常を区別できます。
-
IoTと産業運用
IoTと産業運用では、時系列異常検知は機器と生産プロセスの監視に重要な役割を果たします。時間経過とともに収集されたセンサーの読み取り値は、機械の故障の初期兆候、パフォーマンスの逸脱、生産ラインの非効率性を明らかにする可能性があります。これらの異常を早期に特定することで、組織は故障が発生する前に予知保全をスケジュールし、ダウンタイムを削減し、最適な運用効率を維持できます。不規則な時間パターンの検出は、コストのかかる中断を防止し、機器の寿命を確保するのにも役立ちます。
-
小売とeコマース
時系列異常検知は、小売やeコマースでも売上、返品、ウェブサイトのアクティビティを時間経過とともに監視するのに価値があります。これらの指標の突然の低下やスパイクは、運用上の問題、顧客行動の変化、不正行為を示す可能性があります。時間パターンを分析することで、企業は通常の季節変動と真の異常を区別し、予期しないイベントへの迅速な対応、顧客体験の向上、運用意思決定の最適化を可能にします。
時系列における単変量vs多変量予測
時系列異常検知では、分析されるデータは時間経過で追跡される変数の数に応じて単変量または多変量のいずれかになります。QuickMLでは、モデルが適切に適用されるようにデータをこのように分類しています。単変量予測は単一変数のトレンドに対してよりシンプルで計算効率が高く、多変量予測は複数の特徴間のインタラクションから生じる異常が単変量アプローチでは見逃される可能性がある場合に必要です。この区別により、正確な異常検知のために適切なモデリング戦略と特徴表現を選択するのに役立ちます。
時系列分析での異常の検出と解釈方法に直接影響するため、単変量データと多変量データの違いを理解することが重要です。
| 特徴 | 単変量データ | 多変量データ |
|---|---|---|
| 定義 | 時間経過で単一の変数を追跡します。 | 時間経過で複数の相互関連する変数を追跡し、他の関連変数への依存性を考慮しながら単一のターゲット変数を予測します(多変量予測)。従来の予測モデルと同様の動作をします。 |
| 焦点 | 1つの指標のトレンド、季節性、変動を監視します。 | 複数の指標のパターンとインタラクションを同時に監視します。 |
| 異常検知 | 単一変数の期待される動作からの逸脱をフラグ付けします。 | 変数間の関係における不規則性に基づいて異常をフラグ付けし、単独では現れないパターンを捉えます。 |
| 複雑さ | よりシンプルで計算効率が高いです。 | より複雑で、変数間の依存性とインタラクションのモデリングが必要です。 |
| ユースケース | ウェブサイトトラフィック、日次売上、電力消費、収益監視。 | 小売分析(売上vsマーケティング支出)、株式市場分析(価格、出来高、ボラティリティ)、ヘルスケア監視(心拍数、血圧、酸素レベル)。 |
| 強み | 実装と解釈が容易。単一指標の監視に適しています。 | 変数のインタラクションから生じる微妙な異常を検出。複雑なパターンを捉えます。 |
時系列異常検知の動作方法
最も広く使用されている予測ベースの手法の1つであるARIMA(AutoRegressive Integrated Moving Average)モデルを使用して、時系列異常検知を見ていきましょう。
-
時系列データの理解
プロセスは、各値が特定のタイムスタンプにリンクされた順次データポイントの収集から始まります。たとえば、日次ウェブサイト訪問数、1時間ごとの気温読み取り値、分単位の株価などです。時間が重要な要素であるため、トレンド(全体的な成長または減少)や季節性(繰り返しのサイクル)などのパターンを特定することが重要です。
-
予測モデルのトレーニング
ARIMAは過去の時系列データから学習し、その基礎となるパターンを理解します。3つのコンポーネントを組み合わせます:
- AR(自己回帰):過去の値を使用して将来の値を予測します。
- I(和分):トレンドを除去してデータを定常にします。
- MA(移動平均):過去の予測誤差を使用して予測を精緻化します。
モデルは、データが通常時間経過とともにどのように振る舞うかを捉えるようトレーニングされます。
-
予測値の生成
トレーニング後、ARIMAは過去のパターンに基づいて次のデータポイントがどのようになるべきかを予測します。各タイムスタンプについて、モデルは期待される(予測された)値と正常な変動範囲を表す信頼区間を生成します。
-
実測値vs予測値の比較
データセットからの実際の観測値がモデルの予測値と比較されます。観測値が期待される範囲(たとえば、予測信頼帯よりもはるかに高いまたは低い)から大きく外れている場合、それは異常なポイントと見なされます。
-
異常の検出と報告
時系列全体が分析されると、システムは大幅な逸脱が発生したタイムスタンプをフラグ付けします。たとえば、ネットワークトラフィックの突然のスパイクはサイバー攻撃を示す可能性があります。出力は通常、これらのタイムスタンプを強調し、さらなる調査のために検出された異常の数を表示します。
例:企業がウェブサイトの1時間ごとのトラフィックを監視しているとします。ARIMAは次の1時間に約1,200 ± 100訪問があると予測しますが、実際のカウントが突然400に低下しました。この値は期待される範囲から大きく外れているため、システムはそれを異常としてフラグ付けし、企業にサーバークラッシュや接続問題などの潜在的な原因の調査を促します。
時系列異常検知パイプラインを構築する手順
QuickMLでは、時系列異常検知はSmart Builderを通じて実装されます。これは、時間経過に伴う観測が行われるデータセット向けに特別に設計されています。Smart Builderは、このプロセスを4つの主要ステージ(Source → Preprocessing → Algorithm → Destination)に構造化します。
ステージ1:Source
パイプラインは、株価、機械センサーの読み取り値、日次売上などの時系列データセットの取り込みから始まります。これらのデータセットは順次的であるため、正しい時間ベースの入力を選択することで、システムが過去のパターンに対して異常を検出できるようになります。
ステージ2:Preprocessing
Smart Builderは、異常検知のために生の時間ベースデータを自動的に準備します。
頻度:時系列データセットの場合、データは一定の頻度(日次、週次など)にリサンプリングされます。この標準化により、不規則なタイムスタンプによって歪められるのではなく、均一な間隔で異常が検出されることが保証されます。
補完:データセット内の欠損値は補完によって処理されます。このステップがないと、ギャップが異常として誤解されたり、真のパターンを認識するモデルの能力が歪められたりする可能性があります。
変換:変換により、トレンドやスケールの影響によって隠されるのではなく、異常がより明確に際立つようにデータセットが調整されます。Smart Builderでは、このステップを直接設定でき、ユーザーには差分とべき乗変換の2つの主要オプションがあります。
-
差分:差分は、時系列の連続する観測値間の差を計算することで機能します。このプロセスは、系列のレベルの変化を除去することで平均を安定化させ、トレンドと季節性を効果的に削減または排除するのに役立ちます。差分の次数は、非定常系列を定常系列に変換するためにこの操作を何回適用するかを指定します。QuickMLでは、最大5次までの差分を指定できます。5次の差分後も系列が非定常のままである場合、利用可能なべき乗変換方法のいずれかを適用して分散をさらに安定化し、系列を異常検知に適したものにすることができます。
-
べき乗変換:分散を安定化し、歪んだデータ分布を正規化します。これは、生データの値が非常に異なるスケールに分散している場合に特に有用で、小さい値の異常を検出しにくくします。QuickMLで利用可能なべき乗変換オプションは以下のとおりです:
- 対数変換:大きな値を圧縮し、小さな値を広げるために対数スケールを適用します。これにより、極端な外れ値によって隠される可能性のある異常が明らかになります。
- 平方根変換:中程度の歪みを扱う際に有用です。高い値の影響を軽減しながら、小さな値間の相対的な差を維持します。
- Box-Cox変換:分散を安定化しデータセットを正規化するための最適なべき乗パラメータ(λ)を自動的に決定する柔軟なオプションです。値が厳密に正で分布が大きく歪んでいる場合に特に効果的です。
- Yeo-Johnson変換:Box-Coxに似ていますが、ゼロまたは負の値でも動作するため、厳密に正でないデータセットに対してより汎用性があります。
ステージ3:Algorithm
前処理が完了すると、Smart BuilderはIsolation ForestやOne-Class SVMなどの時系列異常検知用に設計されたアルゴリズムを適用します。これらのモデルは正常な時間的動作を学習し、突然のスパイク、低下、不規則なシーケンスとして現れる逸脱を潜在的な異常としてフラグ付けします。
ステージ4:Destination
最後に、Smart Builderはサポートメトリクスと可視化とともに異常を出力します。これらの結果により、ユーザーはフラグ付けされた異常を検証し、コンテキストを解釈し、タイムリーなアクションを取ることができます。システムは、より迅速な意思決定のためにアクセスしやすい形式で異常が提示されることを保証します。
非時系列異常検知
非時系列異常検知は、固有の時間的順序を持たないデータを扱います。つまり、個々のデータポイントは時間やシーケンスから独立しています。各観測値は、連続するタイムラインの一部ではなく、独立したインスタンスとして扱われます。例としては、クレジットカード取引、医療記録、ネットワークパケット、製品レビュー、製造測定値があります。
非時系列異常検知では、データセットの大部分と異なる動作をするデータポイントを特定することが目標です。時間コンポーネントがないため、非順次データでの異常検出は、時間的パターンではなく空間的、関係的、または統計的パターンに焦点を当てます。手法はデータの分布と構造を分析し、各ポイントが正常な母集団からどの程度逸脱しているかを測定します。
非時系列異常検知の背景にある直感的理解
非時系列データセットでは、観測値は静的であり、時間から独立しています。異常の検出には、複数の特徴間の関係の理解が含まれます。目標は、正常な動作と異常な動作を分離する境界を定義することです。
-
特徴空間の視点:各観測値は高次元空間のポイントとして可視化できます。正常なポイントは一緒にクラスター化し、異常はこれらのクラスターから遠く離れた位置にあります。
-
密度ベースの思考:異常はデータポイントがほとんど存在しない低密度領域で発生することが多いです。アルゴリズムはこの直感を使用して異常スコアを割り当てます。
-
多変量依存性:複数の特徴間の関係を考慮する必要があります。ポイントは個々の次元に沿っては正常に見えるかもしれませんが、他の特徴と組み合わせると異常になる可能性があります。
-
コンテキスト認識:カテゴリカルまたはグループ化されたデータでは、正常性はグループ間で異なる場合があります。この文脈的な変動を理解することは、正確な検出に不可欠です。
非時系列異常検知の主要成功基準
非時系列異常検知は、時間経過のシーケンスではなく、静的または独立したデータポイントに焦点を当てます。成功は、これらの静的データセット内の異常パターンを正確に特定し、特徴間の関係を理解し、解釈可能でアクションにつながるインサイトを提供することにかかっています。成功の主要基準は以下のとおりです:
-
品質データの準備:データがクリーンで一貫性があり、正常な動作を代表していることを確認します。
-
効果的な特徴量エンジニアリング:動作の意味のある変動を捉える特徴を選択します。数値属性とカテゴリカル属性を組み合わせることで、正常性のより豊かな表現が提供されます。
-
代表的な正常サンプル:トレーニングデータは正当なパターンの全範囲をカバーし、有効な変動の異常としての誤分類を防ぐ必要があります。
-
堅牢なモデル選択:選択されたアルゴリズムは、ノイズ、外れ値、異なるデータ分布を処理できる必要があります。
非時系列異常検知のビジネス応用
非時系列異常検知は、通常のパターンから逸脱する異常なデータポイントや動作を特定するために多くの業界に適用されています。このタイプのデータは時間に依存しないため、組織がまれなまたは疑わしいイベントを検出し、幅広い運用にわたる意思決定を強化するのに役立ちます。
-
ヘルスケア
ヘルスケアでは、非時系列異常検知は、エラー、まれな疾病、保険請求における潜在的な不正行為を示す可能性のある異常な患者記録や診断結果を見つけるために使用されます。たとえば、単一の患者に対する異常に多い処置数や、通常の範囲から大きく逸脱する医療検査結果は、さらなるレビューのためにフラグ付けできます。これらの不規則性の検出は、患者の安全性の向上、請求詐欺の削減、医療システムにおけるデータ精度の維持に役立ちます。
-
人事と採用
人事と採用では、異常検知は予期しない給与水準、一貫性のないパフォーマンス指標、不規則な応募パターンなど、異常な従業員データの特定に役立ちます。これらの外れ値の検出は、組織が公平性を維持し、データエラーを検出し、ポリシー違反の可能性を防ぐのに役立ちます。また、優秀な人材や労働力の問題の初期兆候を見つけるのにも役立ちます。
-
サイバーセキュリティ
サイバーセキュリティでは、異常検知は典型的なユーザー行動と異なる疑わしいネットワーク活動やシステムアクセスパターンの特定に役立ちます。たとえば、異常な場所からのログイン試行、不正なデータアクセス、異常なファイル転送は、潜在的なサイバー攻撃やインサイダー脅威を示す可能性があります。ネットワークデータの関係と特性を分析することで、セキュリティシステムは時間ベースのシーケンスに依存せずに、脅威を迅速に検出して対応できます。
非時系列異常検知の動作方法
次に、高次元のテーブルデータに適した一般的な手法であるIsolation Forestアルゴリズムを使用して、非時系列異常検知を理解しましょう。
-
データセットの理解
非時系列データでは、各レコードは複数の特徴を持つ独立した観測として扱われます(たとえば、顧客の年齢、収入、支出スコア)。タイムスタンプや順序はなく、目標は他の大部分のデータと非常に異なるデータポイントを見つけることです。
-
ランダムツリーの構築
Isolation Forestは、データセットをより小さなセクションに繰り返し分割することで、多くのランダムな決定木を作成します。各分割では、特徴と分割値がランダムに選択されます。アイデアは、正常なデータポイントは孤立するためにより多くの分割が必要であるのに対し、異常はまれで異なるため、より少ない分割で素早く孤立するということです。
-
孤立の深さの測定
すべてのデータポイントについて、アルゴリズムはすべてのツリーにわたって孤立させるために必要な平均分割回数(パス長)を計算します。
- ポイントが素早く孤立した場合、それは異常である可能性が高いです。
- 多くの分割が必要な場合、それは正常と見なされます。
-
異常スコアの計算
各レコードについて、平均パス長に基づいて異常スコアが計算されます。1に近い値はより強い異常を示し、0に近い値は正常な動作を示唆します。
-
異常の検出と報告
最後に、モデルは高い異常スコアを持つレコードを外れ値として分類し、データセット内で検出された異常の数を報告します。これらのポイントを調査して、なぜ正常から逸脱しているのかを理解できます。たとえば、不正取引やデータ入力エラーなどです。
例:銀行が顧客取引を分析しているとします。ほとんどの顧客の支出は$50から$500の間ですが、$10,000以上の取引が突然現れます。Isolation Forestは、これらの高額取引を非常に少ない分割で孤立させ、異常としてフラグ付けし、そのような疑わしいケースがいくつ存在するかを報告します。これにより、銀行は潜在的な不正に集中できます。
非時系列異常検知パイプラインを構築する手順
顧客取引、従業員記録、アンケート回答などの非時系列データの場合、異常検知パイプラインはClassic Builderを使用して構築されます。ここでは、データが順次的でないため、周波数の整合と時間的変換はスキップされます。代わりに、Classic Builderはテーブルデータを直接準備し、アルゴリズムを適用して、異常または疑わしいレコードを強調する異常を出力します。
Smart Builderを時系列データに、Classic Builderを非時系列データに分離することで、QuickMLは各異常検知パイプラインがデータセットの固有の構造に合わせてカスタマイズされ、精度と解釈可能性の両方が向上することを保証します。
ステージ1:データ取り込み
プロセスはデータセットをQuickMLにロードすることから始まります。これが異常検知ワークフローの基盤となります。このステップでは、CSVファイル、リレーショナルデータベース、API、クラウドストレージシステムなどのさまざまなソースからデータをインポートします。非時系列データは時間的順序に依存しないため、各レコードは独立した観測として扱われます。正確で完全なデータ取り込みを確保することは、信頼性の高い異常検知結果に不可欠です。
ステージ2:前処理
データがインポートされると、精度、一貫性、分析の準備を確保するための前処理フェーズを経ます。このステップには、補完や除去による欠損値の処理、ラベルエンコーディングやワンホットエンコーディングによるカテゴリカル変数のエンコーディングが含まれます。効果的な前処理により、異常がデータ品質の問題ではなく真の不規則性を反映することが保証され、検出モデルのパフォーマンスと解釈可能性が向上します。
ステージ3:アルゴリズム選択
前処理後、QuickMLではデータセットの特性と期待される異常の性質に基づいて適切な異常検知アルゴリズムを選択できます。一般的なアプローチには、Isolation Forest、One-Class SVM、Local Outlier Factor(LOF)が含まれます。各アルゴリズムは、正常なデータと異常を区別するために異なる原則を使用します。データセット内の固有のパターンと関係を正確に捉えるために、正しい手法を選択することが重要です。
ステージ4:モデルトレーニングと検出
このステップでは、選択されたアルゴリズムが処理済みデータに対してトレーニングされ、データセットの正常な動作または構造を学習します。トレーニング中、モデルは典型的なパターン、境界、または分布を特定し、その後各インスタンスを評価して学習した規範から大幅に逸脱するものを検出します。
ステージ5:異常レポート
モデルが異常を特定した後、QuickMLはデータセット内で検出された異常の数を表示して結果を要約します。この出力は、トレーニング済みモデルに基づいて通常のパターンから逸脱しているデータポイントの数の明確な概要を提供します。
異常検知の評価指標
以下の評価指標は、異常検知モデルが正常な動作からの逸脱をどの程度うまく特定しているか、および基礎となる予測がどの程度正確であるかを評価するのに役立ちます。これらの指標は、予測誤差、モデルの信頼性、および最終的にフラグ付けされた異常に置くことができる信頼を定量化します。
平均絶対パーセント誤差(MAPE)
内容:MAPEは、モデルの予測値がパーセンテージで実際の観測値からどの程度逸脱しているかを平均的に測定します。実際のデータの大きさに対する予測誤差のサイズを表し、異なるデータセットやスケール間で直感的に解釈しやすいです。この指標は、絶対差ではなくパーセンテージの逸脱でモデルの予測精度を理解する必要がある場合に特に有用です。
直感的理解:
- MAPEが低いほど、モデルの予測が実際の値に近いことを示します。
- MAPEが非常に高い場合、モデルの精度が低いか、実際の値が非常に小さいためパーセンテージ誤差が膨らんでいることを示します。
推論の例:MAPEが**15%**の場合、予測が実際の値から平均15%逸脱していることを意味します。
対称平均絶対パーセント誤差(SMAPE)
内容:SMAPEは、過大予測と過小予測を同等に扱うことでMAPEを改善します。これにより、特にデータセットに小さい値やゼロ値が含まれ、従来のパーセンテージ誤差を歪める可能性がある場合に、より公平でバランスの取れた指標となります。SMAPEは、予測値と実際の値の平均と比較して予測誤差がどの程度大きいかを表し、実際の値がゼロに近い場合でも指標が安定していることを保証します。
直感的理解:
- SMAPEは0%(完璧な予測)から200%(完全に不正確)の範囲です。
- データセットに非常に小さい値やゼロ値が含まれている場合、不釣り合いに大きな誤差を回避するためにMAPEよりも好まれます。
推論の例:SMAPEが**18.68%**の場合、平均的に予測が対称的な方法で実際の値から18.68%逸脱していることを示し、多くの実世界の異常検知タスクにおいてかなり許容できるレベルの誤差です。
平均二乗誤差(MSE)
内容:MSEは予測値と実際の値の間の二乗差の平均を計算します。誤差を二乗することで、大きな逸脱が強調され、大きなミスがスコアにはるかに強い影響を与えます。これにより、MSEはデータセット全体で予測誤差がどの程度大きく変動するかを理解し、大きなコストのかかる誤差を起こしている可能性のあるモデルを特定するのに価値があります。
直感的理解:
- MSEが0は完璧な予測を意味します。
- MSEの値が高いほど、予測誤差のレベルが高いことを示します。
- 誤差が二乗されるため、大きな逸脱が不釣り合いに寄与し、MSEは外れ値に敏感です。
推論の例:提供された出力でMSEが0の場合、モデルの予測が観測値と完全に一致していることを意味し、理想的なケースです。
二乗平均平方根誤差(RMSE)
内容:RMSEはMSEの平方根であり、元のデータと同じ単位で誤差指標を提供するため、より解釈しやすくなります。予測誤差の標準偏差、つまり残差が実際の値の周りにどの程度分散しているかを表します。RMSEは、モデルを比較したり予測の一貫性を評価する際に特に有用です。
直感的理解:
- RMSEは予測変数と同じ単位で表されるため、MSEよりも解釈しやすいです。
- RMSEが低いほど、予測精度が高いことを意味します。
推論の例:RMSEが0.0041の場合、平均的に予測誤差が非常に小さく、実際の値に近いことを示します。
平均二乗対数誤差(MSLE)
内容:MSLEは予測値と実際の値の対数の二乗差を測定します。絶対差ではなく相対誤差を強調するため、複数のスケールにまたがるデータや指数関数的な成長(人口、売上、ウェブトラフィックなど)を含むデータに最適です。MSLEは実際の値に比例的に近い予測を報奨し、過大予測よりも過小予測をより強くペナルティとして課します。これは、スパイクを見逃すことが過大予測よりも深刻な場合に有用です。
直感的理解:
- MSLEは過大予測よりも過小予測をより強くペナルティとして課します。
- データが複数の桁にまたがる場合(指数関数的な成長パターンなど)に最適です。
推論の例:MSLEが0の場合、対数スケールでの予測値と実際の値の完全な一致を示し、重大な過小または過大予測がないことを意味します。
二乗平均平方根対数誤差(RMSLE)
内容:RMSLEはMSLEの平方根であり、相対的な予測精度への焦点を維持しながら、解釈しやすくなります。大きな外れ値に過度に影響されることなく、モデルの予測が実際の値からどの程度異なるかをパーセンテージのような形で評価するのに役立ちます。RMSLEは、相対的な成長や比例的な差異が正確な数値精度よりも重要な問題に特に有用です。
直感的理解:
- RMSLEは大きな絶対誤差に対する感度は低いですが、相対的な精度を強調します。
- パーセンテージの差異が生の差異よりも重要な場合に特に有用です。
推論の例:RMSLEが0.0041の場合、対数スケールでの予測誤差が非常に低く、高品質な予測が確認されます。
異常の数
内容:この指標は、データセットの処理後にモデルによって異常としてフラグ付けされたデータポイントの数を表します。システムが正常な動作からの逸脱をどの程度頻繁に検出するかの直接的な指標を提供します。
直感的理解:
- 非常に多い異常の数は、モデルが過度に敏感である可能性(多くの誤検出)を示す場合があります。
- 非常に少ない数は、モデルが厳しすぎて意味のある異常を見逃している可能性を意味します。
推論の例:モデルが42の異常を検出した場合、それらが需要の突然のスパイクやセンサーの障害などの意味のあるイベントに対応しており、ランダムノイズではないことを確認するためにレビューできます。
これらの指標を一緒に使用する方法
単一の指標だけではモデルのパフォーマンスの全体像は語れません。予測誤差指標(MAPE、SMAPE、MSE、RMSE、MSLE、RMSLE)は、モデルが通常の動作をどの程度正確に予測しているかを示し、異常の数はモデルがどの程度頻繁に逸脱をフラグ付けしているかを示します。これらを総合的に使用して、全体的な見方を得てください。
例:モデルのRMSEが0.0041、MAPEが15%で、データセット内で42の異常を検出したとします。低いRMSEと適度なMAPEは予測が実際の値に非常に近いことを示し、異常の数は妥当であり、モデルが正確で適切に敏感であることを示唆します。代わりにモデルが300の異常をフラグ付けした場合、過度に敏感で多くの誤検出を生成していると疑われる可能性があります。
これらの指標を一緒に解釈することで、予測精度と意味のある異常検知のバランスを取り、アクションにつながるインサイトに対する信頼を得ることができます。
異常の視覚的評価
視覚的評価は、時系列異常検知モデルのパフォーマンスを検証するための重要なステップです。予測された異常を実際の時系列動作と比較することで、モデルの出力の定性的な評価が可能になります。この可視化により、ユーザーは以下のことができます:
- 検出された異常がデータの実際の変化と一致しているかを素早く検証する。
- 誤報または見逃した異常を特定する。
- 異なる時間セグメントとトレンドにわたるモデルの信頼性に関するインサイトを得る。
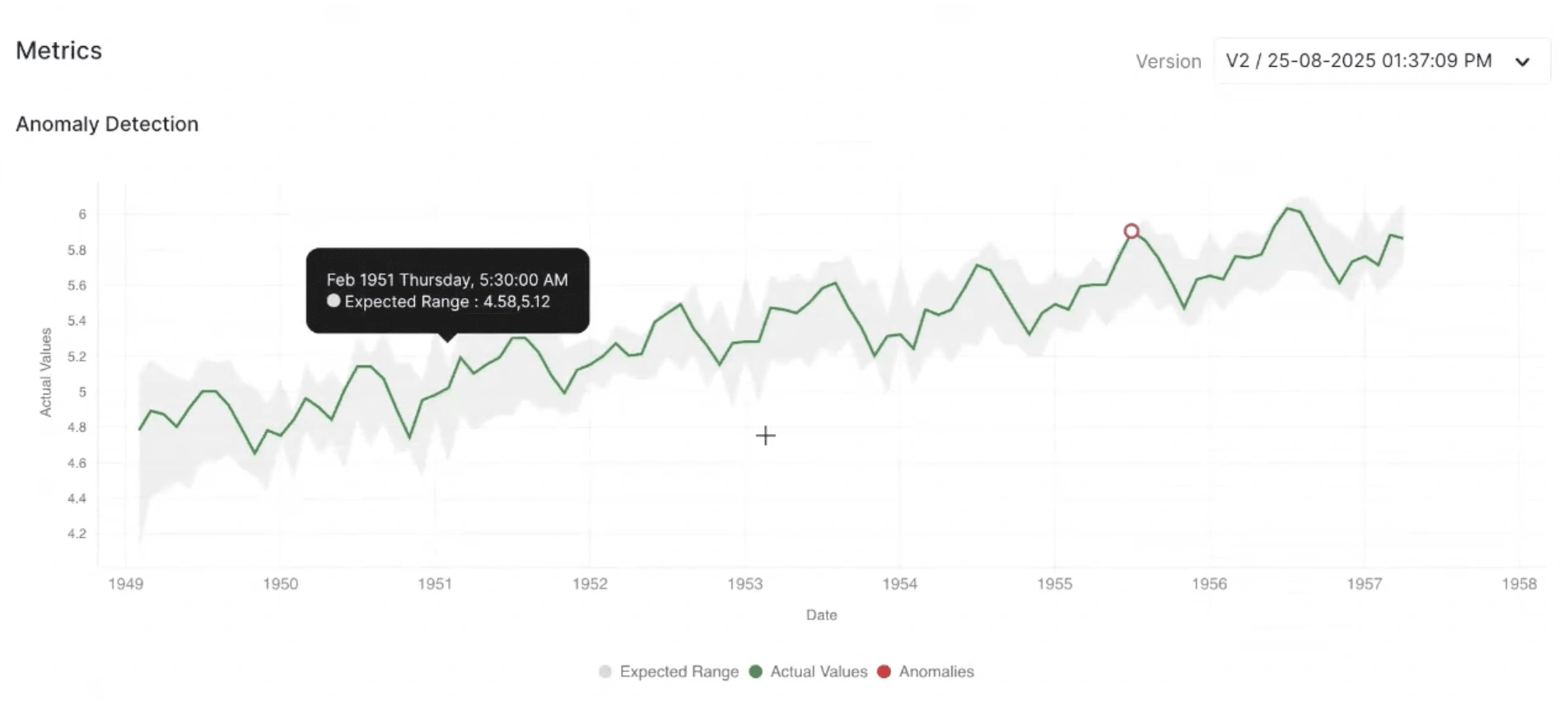
内容:この可視化は、モデルが時系列データセット内の異常をどのように特定するかを示しています。チャートは時間経過に伴う実際のデータ値をプロットし、期待される(正常な)範囲を強調し、大幅に逸脱するポイントを異常としてマークします。
直感的理解:
- 緑の線:時間経過に伴う実際の観測値を表します。
- 灰色の網掛け領域:モデルに基づく正常な動作の期待または予測範囲を示します。
- 赤い丸:実際の値が期待範囲から大幅に逸脱した、異常として検出されたポイントを強調します。
- 赤い異常ポイントが灰色の期待範囲外の明確なスパイク、低下、逸脱と一致している場合、モデルが異常なパターンを正確に捉えていることを示します。
- 少数のよく配置された異常は、モデルが安定して正確であることを示唆します。
- 正常な領域内に頻繁またはランダムな異常ポイントがある場合、しきい値が過度に敏感であるか、検出にノイズがある可能性を示します。
例:系列の鋭いピーク(値の突然の増加など)で異常が現れる場合、それは真の外れ値や予期しないイベントを示唆します。通常の変動中に異常が現れる場合、誤検出を減らすためにモデルのしきい値調整が必要な可能性を示します。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us