RAG
Retrieval-Augmented Generation(RAG)とは?
RAGを理解するために、簡単な例えを考えてみましょう。ユーザーがプリンターに表示されたエラーコード「7C05」についてテクニカルサポートに連絡します。経験豊富なサポート担当者ですが、その特定のコードに遭遇したことはありません。推測する代わりに、担当者はそのプリンターモデルの公式トラブルシューティングマニュアルを参照して正確な解決策を見つけます。このシナリオでは、担当者が言語モデルを表し、マニュアルがRAGが取得する外部知識ソースを表しており、担当者はその正確な問題に事前に触れることなく正しく応答できます。
技術的に説明すると、RAGは、権威のある外部知識ソースから取得した情報を組み込むことで、大規模言語モデル(LLM)の出力の精度、関連性、信頼性を向上させる高度な技術です。トレーニング中に利用可能なデータのみに依存するのではなく、RAGにより推論時にモデルが最新のドメイン固有のコンテンツを参照でき、検証可能で文脈的に適切な情報に基づいた応答を生成します。
LLMはニューラルネットワークアーキテクチャ上に構築され、膨大な量のテキストデータでトレーニングされています。その性能は主に数十億のパラメータによって駆動され、人間の言語における一般化されたパターンを捉えます。このパラメータ化された知識により、LLMは質問応答、翻訳、テキスト補完など、幅広いタスクを印象的な流暢さで実行できます。しかし、これらのモデルは、トレーニング範囲を超える特定の、詳細な、または時間に敏感な情報を必要とする応答の生成を求められた場合、制限される可能性があります。
RAGは、キュレーションされた知識ベース(社内文書、ドメイン固有のデータベース、信頼できるオンラインソースなど)から関連コンテンツをまず取得し、その後情報に基づいた文脈的に根拠のある応答を生成するよう生成プロセスを最適化することで、この制限に対処します。このアプローチはベースモデルの再トレーニングを必要としないため、特定の組織ニーズや専門分野にLLM機能をカスタマイズするためのコスト効率が高くスケーラブルな方法です。
RAGの利点
RAGは、生成AIソリューションの有効性、柔軟性、信頼性を向上させる重要な利点を提供します。特に、大規模モデルの再トレーニングのオーバーヘッドなしにドメイン固有のインテリジェンスを実装しようとする組織にとって有益です。
コスト効率の高いデプロイ
ほとんどのチャットボットやAIアプリケーション開発は、広範な汎用データセットでトレーニングされ、通常APIを通じてアクセスされるLLMなどの基盤モデルから始まります。組織または業界固有のコンテンツに対応するためにこれらのモデルを再トレーニングしてカスタマイズすることは、多くの場合、法外に高コストでリソース集約的です。RAGは、よりスケーラブルで経済的な代替手段を提供します。推論時にモデルが外部データを取得して参照できるようにすることで、RAGにより企業は基盤モデルを変更することなく特定の知識を統合でき、生成AIソリューションをより実現可能でコスト効率の高いものにします。
タイムリーで動的な情報へのアクセス
最新の応答を維持することは、トレーニングデータがすぐに古くなるため、静的モデルにとって大きな課題です。RAGは、継続的に更新される情報ソースをモデルに供給できるようにすることで、この問題に対処します。最新の科学研究、ニュース速報、リアルタイムのソーシャルメディアフィードなど、RAGにより生成AIモデルは現在のデータにアクセスできます。これにより、急速に変化する分野でも応答が関連性があり正確であり続けることが保証されます。
透明性とユーザー信頼の向上
RAGの主要な強みの1つは、ソースに基づいた回答を提供する能力です。外部文書を参照し引用を含めることで、情報の出所に関する透明性を提供します。ユーザーはこれらのソースを確認してコンテンツを検証したり、さらに探索したりでき、システムへの信頼を高めます。このトレーサビリティにより、生成AIの応答はより信頼性が高くなるだけでなく、規制産業のコンプライアンスや品質保証基準にもより適合します。
RAGの応用
Retrieval-Augmented Generation(RAG)は、特にドメイン固有の知識、リアルタイム情報、または透明な出力を必要とする分野で、LLMの機能を強化するために業界全体でますます採用されています。以下は、RAGが重要なインパクトをもたらす主な応用分野です:
エンタープライズナレッジアシスタント
企業は、従業員の社内知識アクセスを効率化するためにRAGベースのアシスタントに注目しています。これらのAI搭載ツールは、社内Wiki、SOP、人事ガイドライン、コンプライアンスチェックリスト、ITドキュメント、オンボーディング資料など、企業固有のリポジトリから構造化データと非構造化データをクエリするよう設計されています。事前定義されたルールや古いトレーニングデータに依存する静的チャットボットとは異なり、RAGは最も関連性の高いドキュメントを動的に取得し、従業員が正確で最新のポリシーに準拠した応答を受け取ることを保証します。これにより、生産性の向上、サポートチームへの依存度の低減、部門間での統一された情報源が実現されます。
カスタマーサポートの自動化
カスタマーサービスプラットフォームは、RAGを統合してよりインテリジェントで文脈認識的なインタラクションを提供することで、ユーザー体験を大幅に向上させることができます。製品マニュアル、トラブルシューティングガイド、保証書、ヘルプデスクナレッジベースからコンテンツを直接取得することで、RAG搭載のチャットボットは、最近発売された製品やまれに遭遇する製品に関するものを含め、顧客の問い合わせをより効果的に解決できます。これにより、新しいコンテンツでモデルを常に再トレーニングする必要がなくなり、最小限の人的介入でスケーラブルなサポート運用が可能になります。追跡可能なソースの含有も顧客の信頼を構築し、顧客満足度を向上させます。
法律・規制調査
法律の専門家は、正確性、引用、トレーサビリティが最重要の分野で活動しています。RAGベースのツールは、法令の条項、先行判例、政府の政策、社内コンプライアンス文書から直接取得できるようにすることで、法務チームを支援します。膨大なテキストを手動で調べる代わりに、ユーザーは法的な健全性のために元の文書と相互参照された簡潔な要約を取得できます。これらのアプリケーションは、法的意見の起草、規制監査の実施、コンプライアンスレビューへの回答の準備に特に有用であり、すべての出力が検証可能な法的文脈に基づいていることを保証します。
ヘルスケアおよび医療意思決定支援
ヘルスケア分野では、タイムリーでエビデンスに基づいた意思決定が患者の転帰に直接影響を与える可能性があります。RAGシステムは、治療ガイドラインや施設の臨床記録などの医療ソースからのデータを参照することで、臨床医、研究者、管理者を支援します。関連情報を応答に組み込むことで、RAGモデルは臨床意思決定支援、患者固有のケア推奨、鑑別診断、薬物相互作用を支援し、すべてソース資料を引用します。このアプローチにより、AI駆動の推奨に対する信頼性が向上します。
科学研究およびテクニカルライティング
RAGは、研究ワークフローの加速とテクニカルライティングにおけるコンテンツの正確性の確保に重要な役割を果たします。研究者は、広範な学術データベースをクエリして最新技術を要約したり、文献レビューを生成したり、現在の知見で仮説を検証したりできます。同様に、テクニカルライターはRAGを使用して、最新のデータやユーザーマニュアルに基づいた製品ドキュメントを起草できます。科学的発展の要約でもレポートの起草でも、RAGは生成されるコンテンツが信頼できるドメイン固有のソースに裏付けられていることを保証し、正確性と信頼性の両方を維持します。
RAGの仕組み
RAGは、取得と生成の2つの主要なプロセスを統合しています。言語モデルのトレーニング中にエンコードされた知識のみに依存するのではなく、RAGは推論時に外部ソース(データベース、ドキュメント、ナレッジベースなど)から関連情報を動的に取り込むことで補完します。このアプローチにより、モデルはより正確で最新の、文脈的に適切な応答を提供できます。
RAGの動作の簡略化されたフローは以下のとおりです:
-
ユーザー入力/クエリ:プロセスは、ユーザーが質問やプロンプトを入力するところから始まります。
-
取得:システムはクエリを使用して、大規模な外部知識ソース(ベクターデータベース、ドキュメントストア、検索インデックスなど)を検索し、最も関連性の高い上位K個の情報(「パッセージ」や「コンテキスト」と呼ばれることが多い)を取得します。これは通常、エンベディングを活用したセマンティック検索を使用して行われます。
-
融合/コンテキスト化:取得されたパッセージは、元のクエリとともに言語モデルに渡されます。これらのパッセージは、事実やドメイン固有の知識に基づいて生成を根拠づけるコンテキストを提供します。
-
生成ステップ:言語モデル(TransformerベースのLLMなど)は、クエリと取得されたドキュメントの両方を入力として受け取り、一貫性のある情報に基づいた応答を生成します。
-
引用/トレーサビリティ:RAGモデルは回答のために実際のドキュメントに依存するため、ソース資料への追跡可能な参照やリンクを提供でき、透明性と信頼性を高めます。
QuickMLのRAGの独自性
QuickMLのRAGは、ナレッジベースに基づく応答生成時に、シームレスで安全かつ透明な体験を提供するよう設計されています。QuickMLのRAGが際立つ理由は以下のとおりです:
-
応答が生成されると、詳細な応答の内訳が利用可能になります。この内訳は、生成プロセス中にどの取得ドキュメントの部分が参照されたかを示し、サポート情報の出所を明確に表示します。最終出力にどのドキュメントが寄与したかを正確に確認できるため、透明性が向上します。
-
QuickMLのRAG実装は、WorkDriveやZoho Learnなどのzohoエコシステムを活用して、関連ドキュメントをナレッジベースにシームレスにインポートします。この統合により、クエリをサポートするための最も正確で文脈固有の情報が常に利用可能になります。
QuickMLのRAGで利用可能なモデル
QuickMLのRAGは、Qwen 2.5 14B Instructモデルを活用して、文脈的で関連性の高い応答を提供します。Qwen 2.5 14B Instructは、一貫性と精度を持って多様な言語タスクを実行するよう設計された高性能AIモデルです。大規模で高品質なデータセットでトレーニングされており、信頼性の高い結果を提供し、複数のベンチマークで優れた性能を発揮します。Qwen 2.5-14B-Instructが際立つのは、動的な実世界のシナリオに素早く適応して応答する能力であり、エンタープライズおよび本番グレードのアプリケーションに特に適しています。
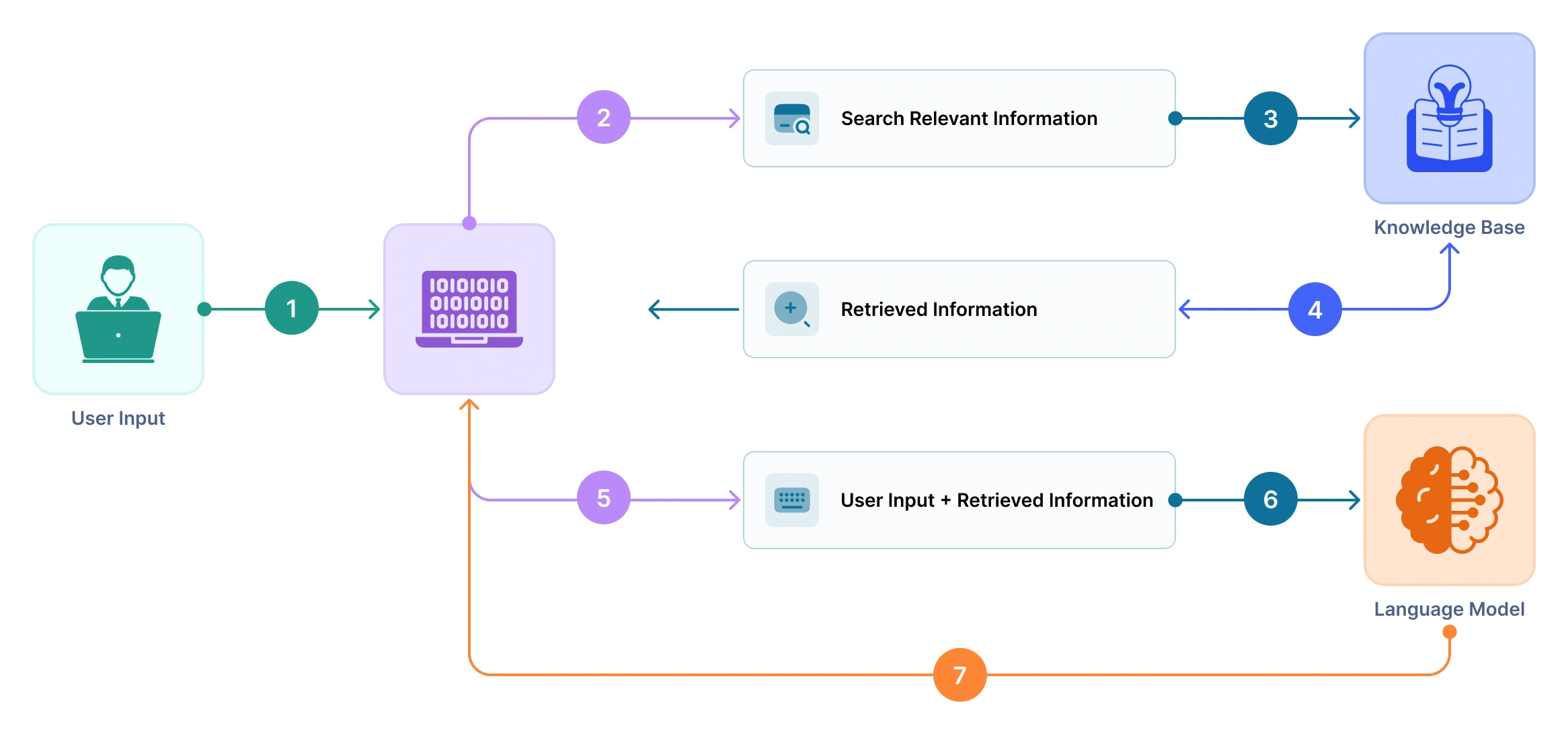
Qwen 2.5 14B Instructモデルの詳細
モデルの詳細を表示するには、RAGタブに移動し、チャットインターフェースの右上隅にあるView APIオプションをクリックします。モデルの詳細には以下が含まれます:
-
モデルサイズ:140億のパラメータで構成されており、高度な理解と言語生成能力を可能にします。
-
トレーニングサイズ:幅広いドメインの広範なカバレッジを確保するために、18兆トークンでトレーニングされています。
-
パラメータ:ニュアンスのある非常に関連性の高い応答を生成するために、140億のトレーニング可能な重みを使用しています。
-
入力トークン制限:入力コンテキスト長として128Kトークンをサポートしており、RAG実行中の深いコンテキストと長いドキュメント参照が可能です。
-
エンドポイントURL:APIリクエストを送信するために使用するURLです。
-
OAuthスコープ:QuickML.deployment.READ;デプロイメントを使用するために必要なアクセスレベルを定義します。
-
認証:OAuthを使用してクライアントIDを安全に検証します。
-
HTTPメソッド:POST;すべてのAPI呼び出しはPOSTメソッドで行う必要があります。
-
ヘッダー:リクエストを認証するために必要なメタデータと認証トークンを含みます。
-
サンプルリクエスト:入力プロンプトの構造化方法を示す事前定義されたJSON形式です。
-
サンプルレスポンス:プロンプトとKBドキュメントから取得された情報の両方に基づいて生成された、文脈的に根拠のあるテキストを含むモデルの出力を表示します。
モデルをアプリケーションに統合する手順については、RAGをアプリケーションに統合するセクションを参照してください。
QuickMLにおけるRAGインターフェースの理解
QuickMLのRAG機能により、Qwen 2.5 14B Instructを使用してドキュメントベースの応答を取得できます。インターフェースは、ドキュメントのアップロード、質問、各応答のソースの追跡を容易にするよう設計されています。以下に、その構成について説明します。
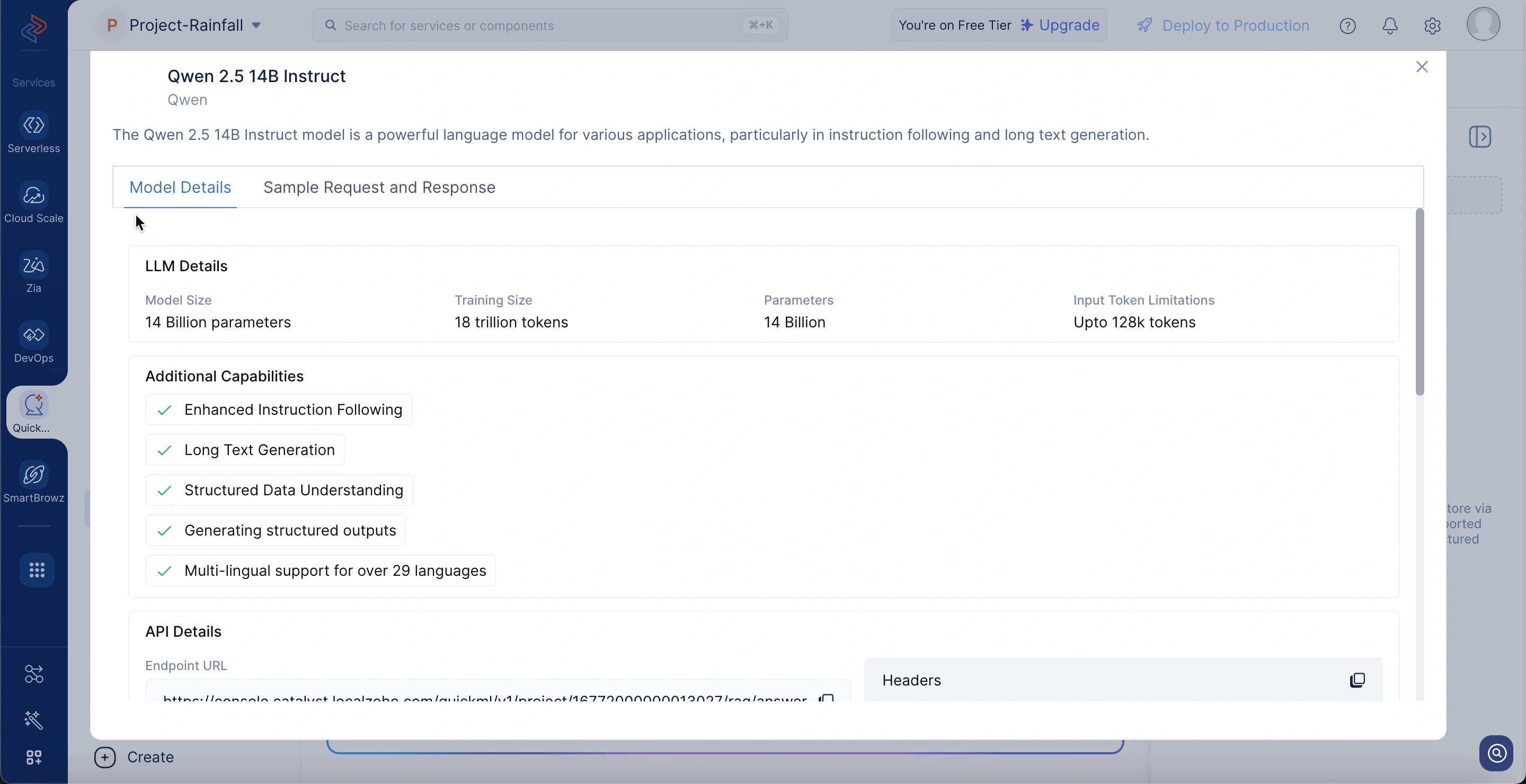
モデル選択
チャットパネルの上部で、利用可能なモデルを選択できます。現在、RAGベースの会話にはQwen 2.5 14B Instructがサポートされています。このモデルは、アップロードされたドキュメントから根拠のある文脈認識的な応答を生成するよう最適化されています。
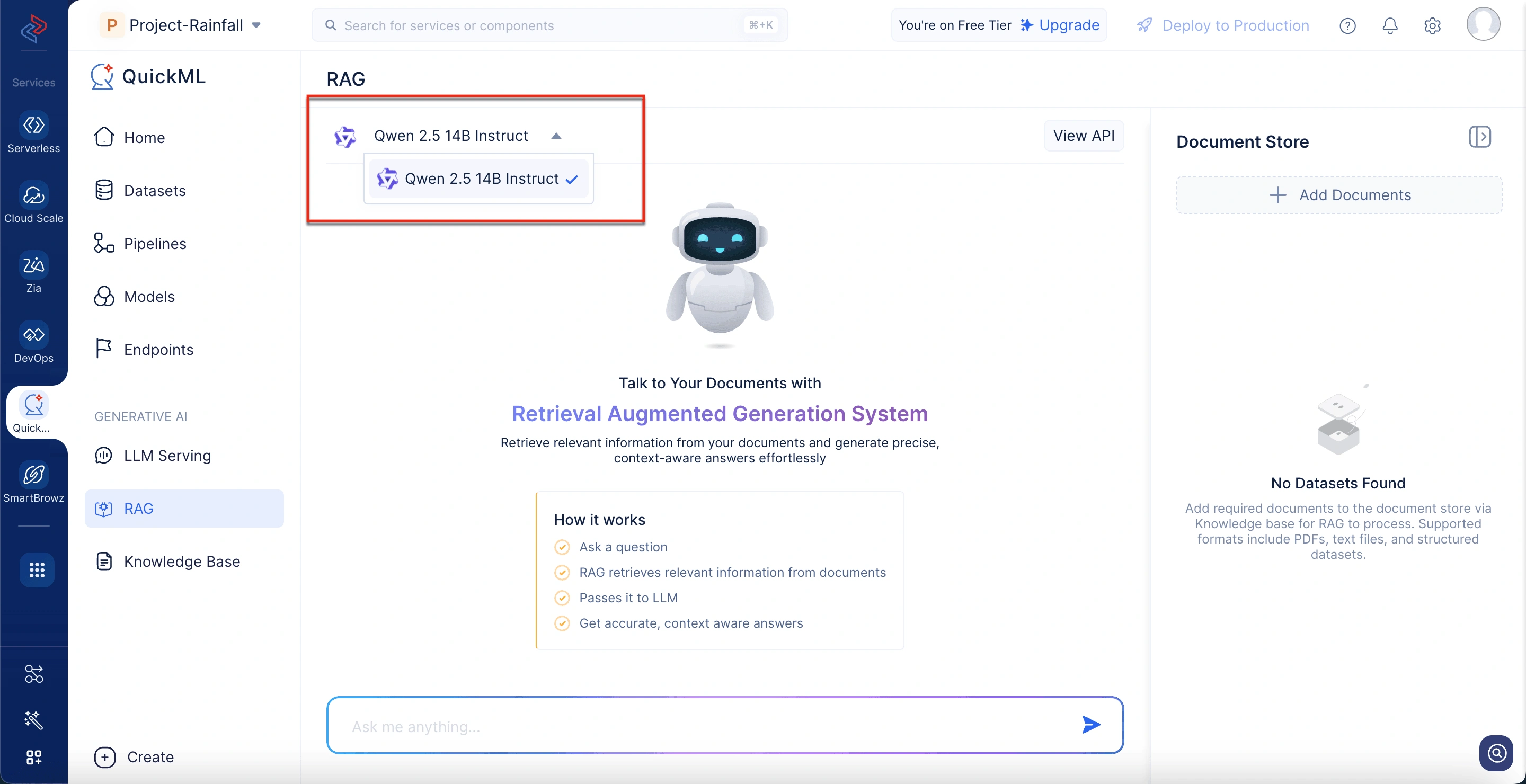
チャットインターフェース(会話パネル)
中央にはコアインタラクションスペースがあり、クエリを入力して応答を確認できます。AI生成された各回答はユーザー入力の下にスレッド表示され、以下を含むことができます:
- 応答のコピーまたは再生成のためのアクションアイコン
- 回答がどのように生成されたか、どのドキュメントからかについてのインサイトを提供する「応答内訳を表示」オプション
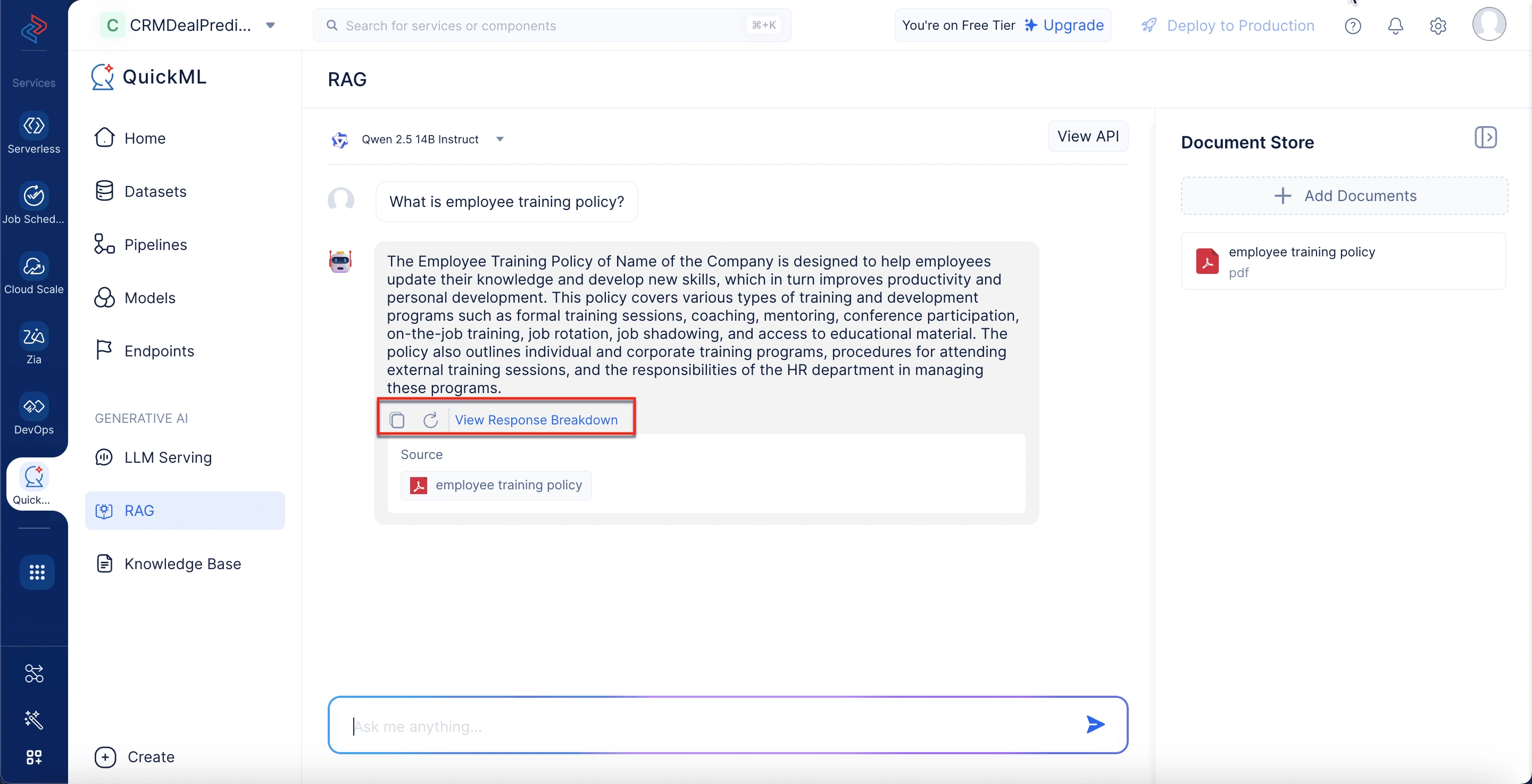
応答内訳パネル
「応答内訳を表示」をクリックすると、詳細なインサイトを提供するポップアップウィンドウが表示されます:
-
思考プロセス:回答生成中に参照された特定のコンテンツスニペットと、それに対応するソースおよびドキュメントIDを表示します。
-
引用:使用されたドキュメントを一覧表示し、応答の生成に使用された正確なセクションを強調表示します。
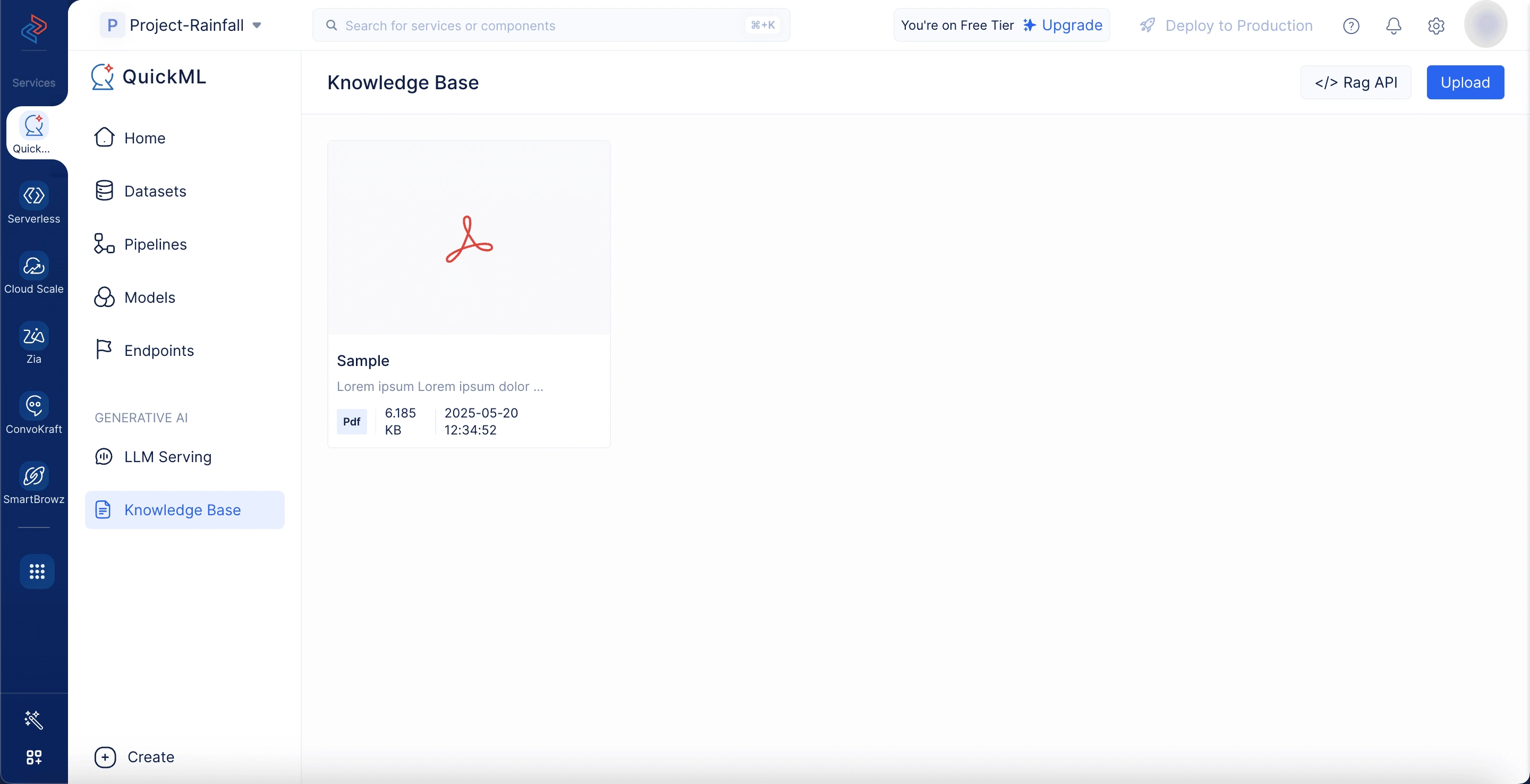
ドキュメントストア
インターフェースの右側には、取得のために現在アクティブなすべてのドキュメントがドキュメントストアに一覧表示されます。各ドキュメントにはその名前、形式、サイズが表示されます。ユーザーは「ドキュメントを追加」オプションを選択して、ナレッジベースから応答生成のための関連ドキュメントを含めることができます。
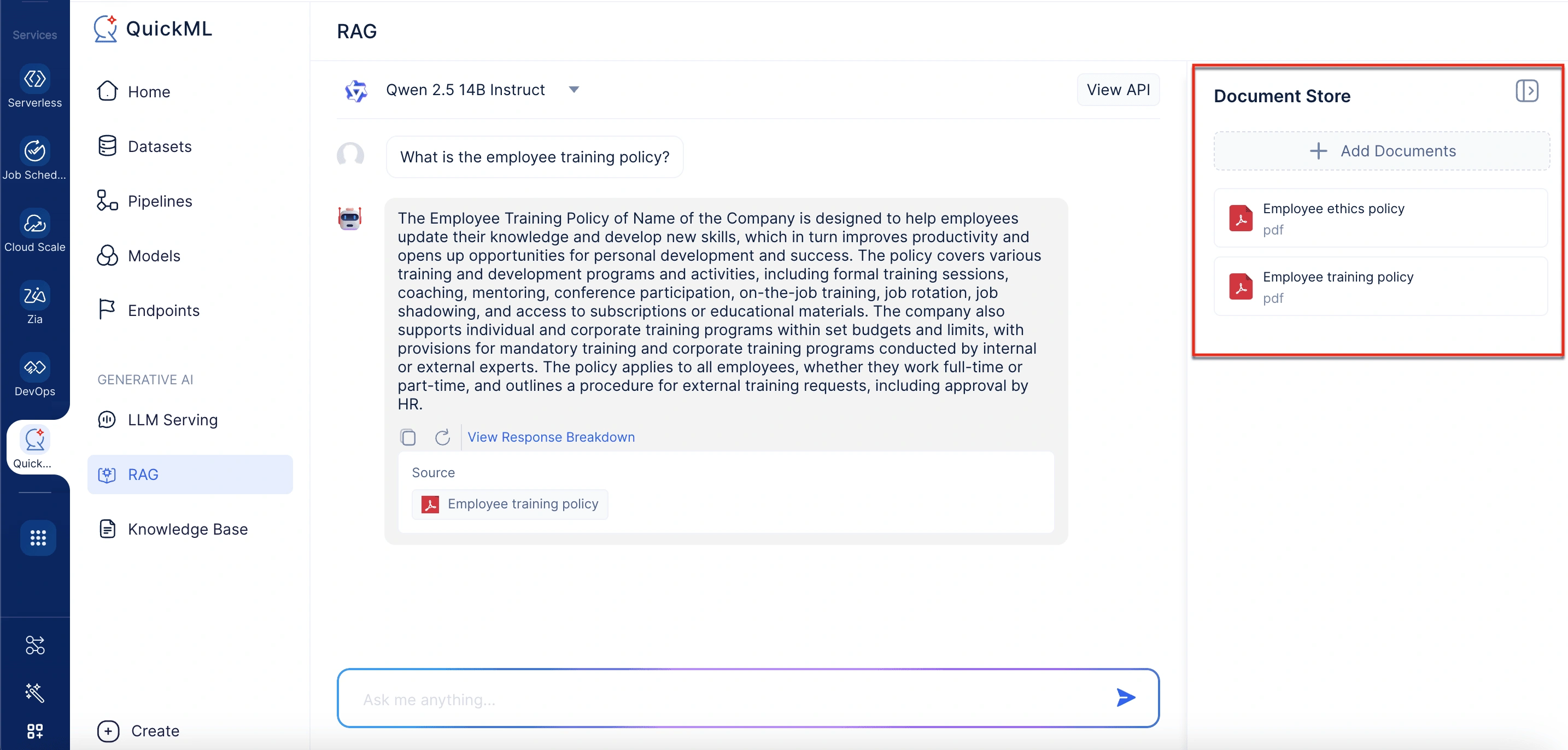
ドキュメントの追加
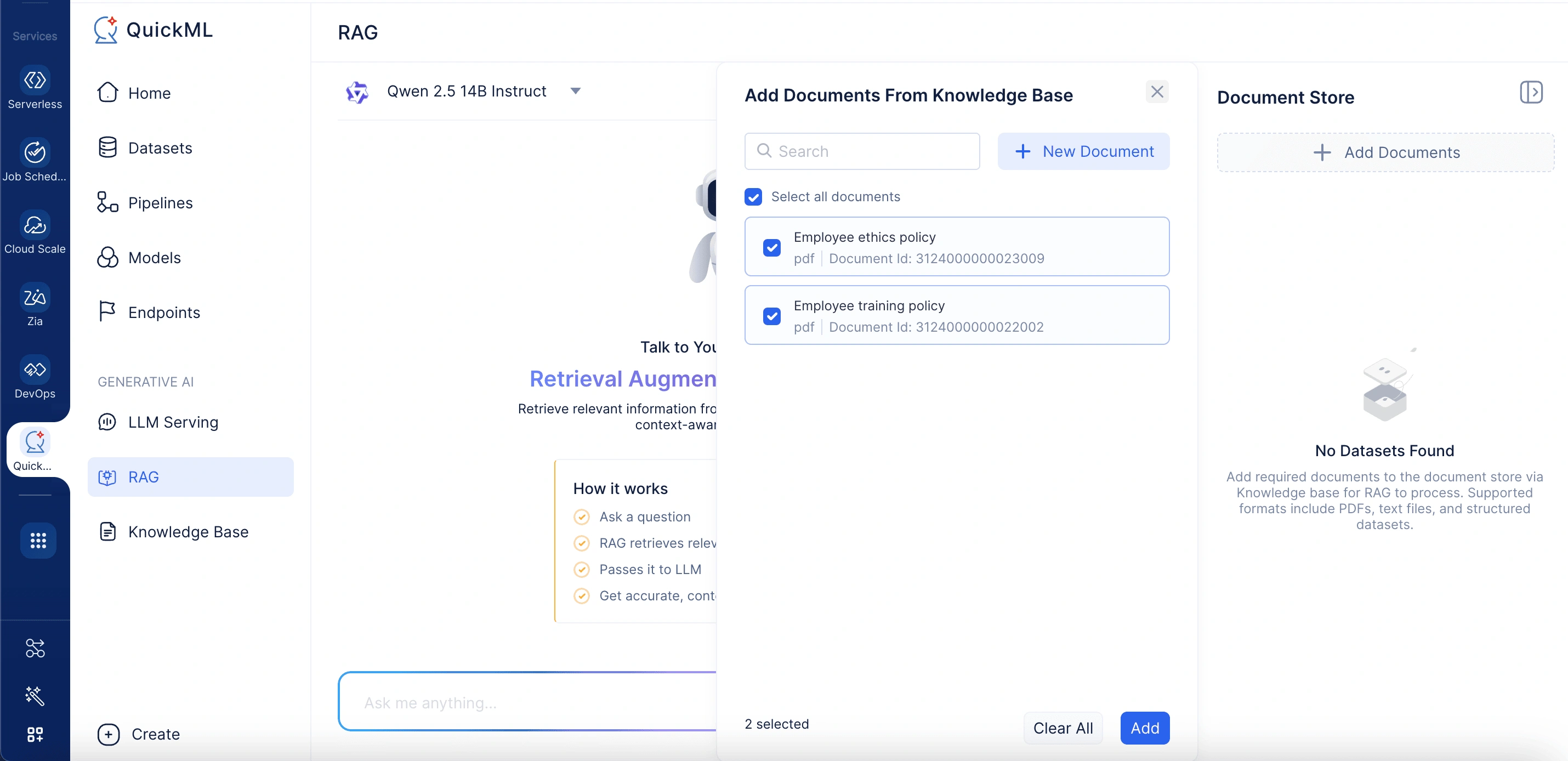
Add Documentsをクリックすると、「Add Documents From Knowledge Base」というラベルのパネルが開きます。ここで、既存のドキュメントを選択するか、新しいドキュメントをアップロードできます。パネルにはナレッジベース内のドキュメントを素早く見つけるための検索バーが含まれています。
-
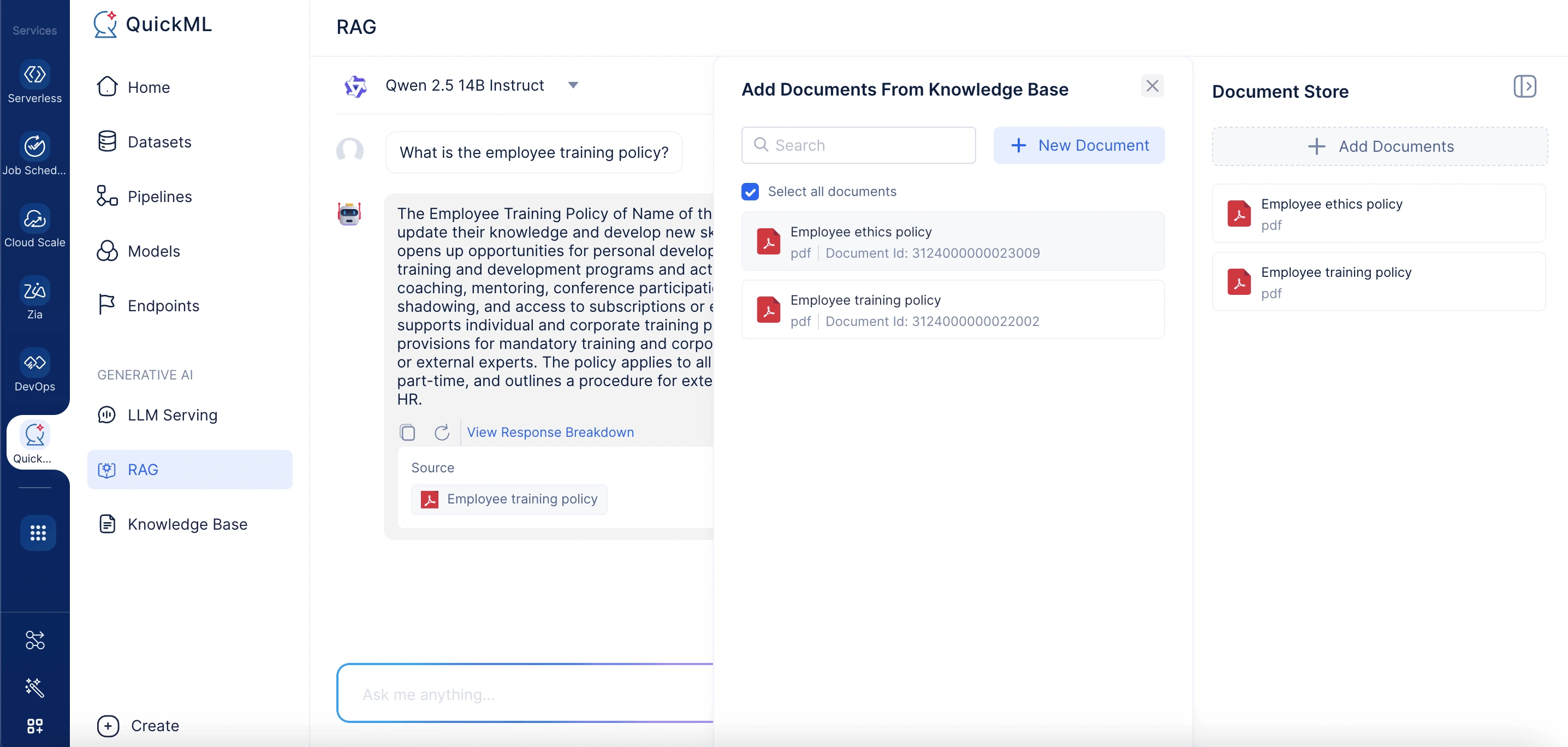
アップロードオプション
新しいドキュメントをアップロードする際、3つの便利な方法がサポートされています:
- デスクトップから:.pdf、.docx、.txtファイルをサポートしており、ファイルあたりのサイズ制限は500KBです。
- WorkDriveから:クラウドストレージからファイルを直接インポートできます。
- Zoho Learnリンク経由:目的のZoho Learn記事のURLを貼り付けてドキュメントをインポートできます。
アップロードされた各ファイルには一意のIDが割り当てられ、会話中の取得に利用可能になります。
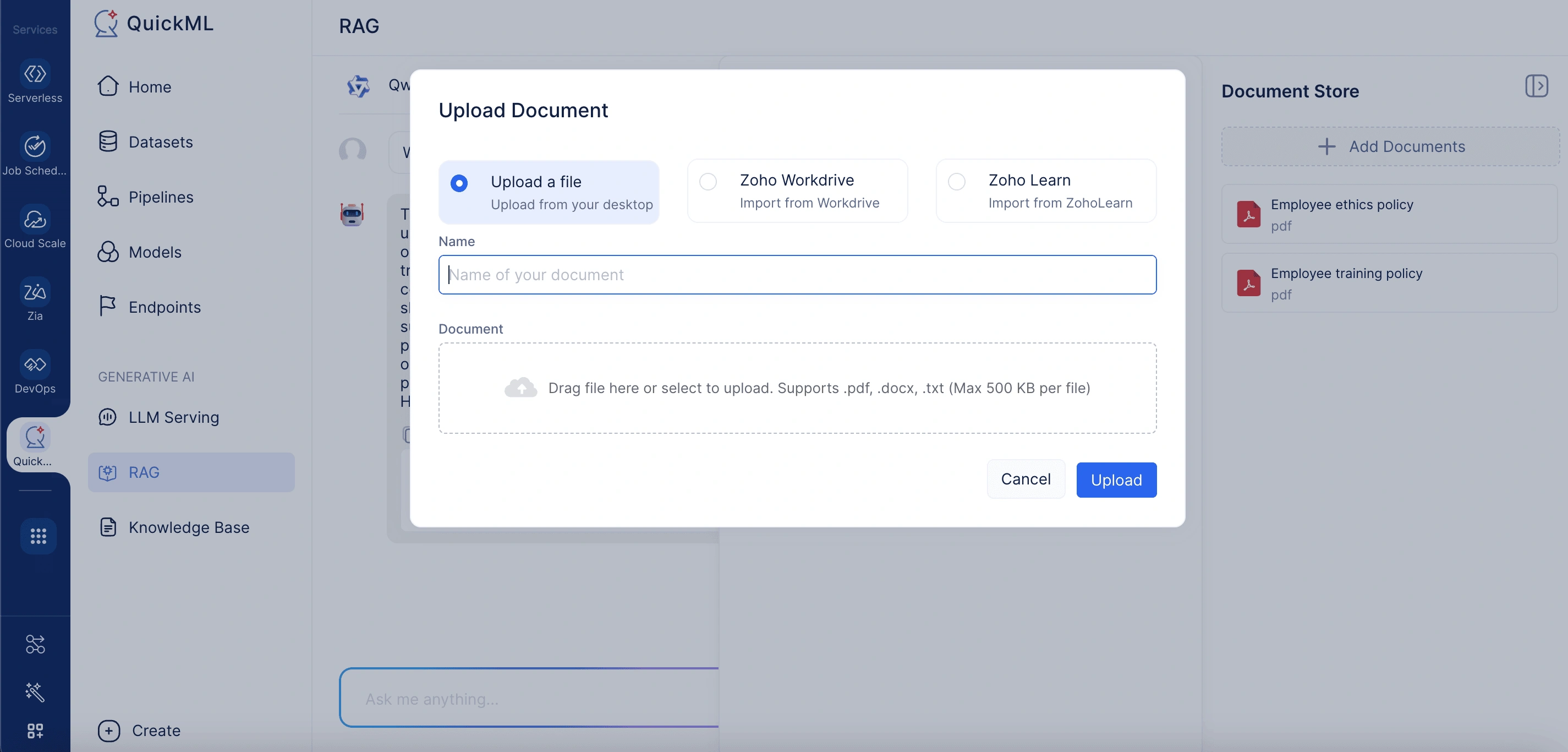
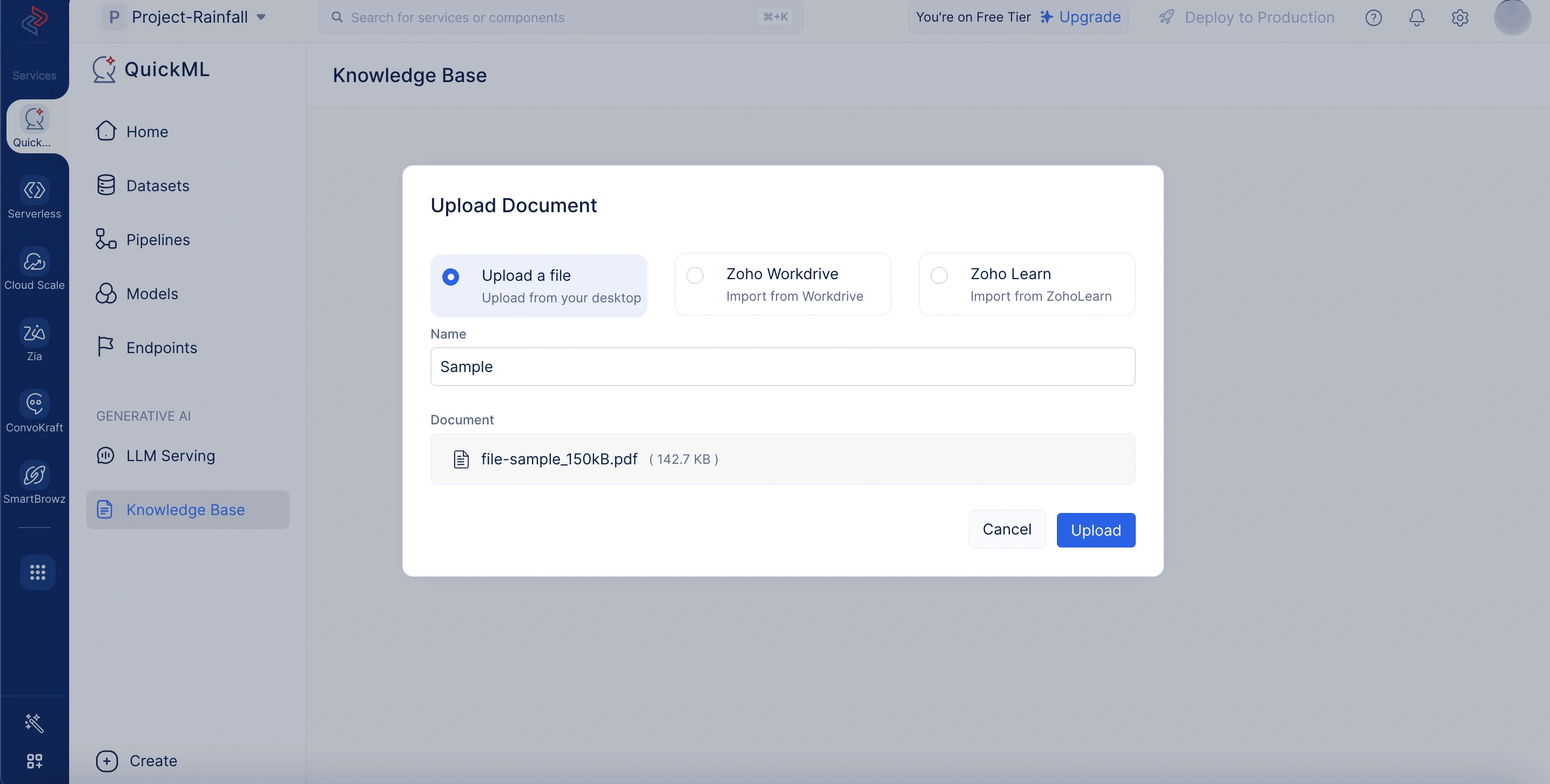
ナレッジベースへのドキュメントのアップロード
「Add Documents From Knowledge Base」パネルにドキュメントが表示されるようにするには、まず関連ファイルをKnowledge Baseリポジトリにアップロードする必要があります。
Add Documents From Knowledge BaseパネルでNew Documentをクリックすると、ドキュメントはナレッジベースに自動的に追加されます。
Knowledge Baseは、文脈認識的な生成に重要なコンテンツをアップロードおよび管理できる集中型ドキュメントリポジトリとして機能します。WorkDriveやZoho LearnなどのZohoエコシステムとの統合により、社内ファイル、マニュアル、FAQ、その他のリソースをシームレスにインポートできます。この設定により、Knowledge Baseが最新かつ包括的に保たれ、ユーザーのクエリに合わせたソースに裏付けられた応答を提供するモデルの能力がサポートされます。
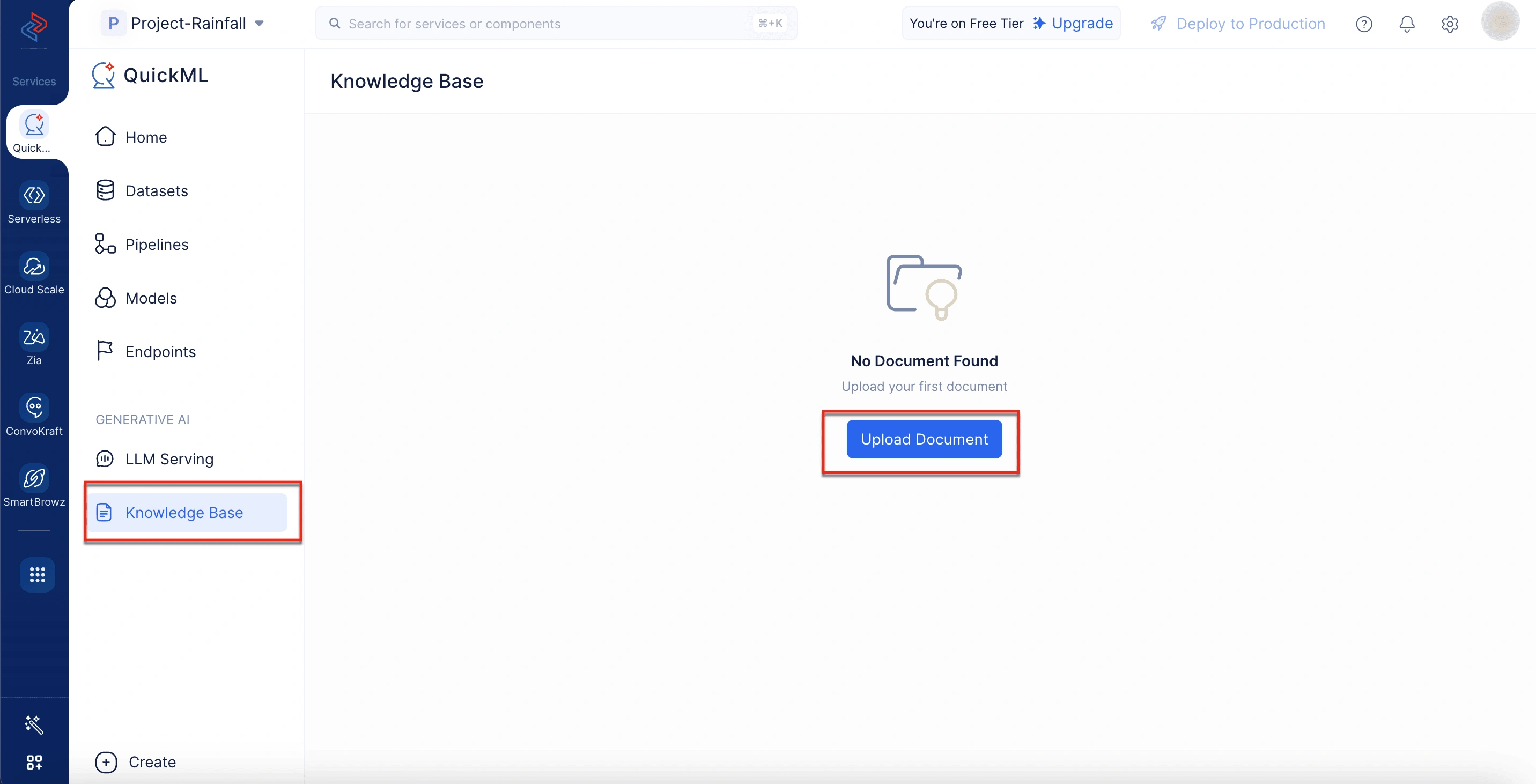
ナレッジベースからドキュメントをアップロードするには
- QuickMLプラットフォームのKnowledge Baseタブに移動します。
- Upload Documentをクリックします。
- 以下のいずれかの方法でドキュメントをアップロードします。
- Upload a fileを選択して、デスクトップからドキュメントをアップロードします。ここでは、名前を入力し、ローカルシステムからアップロードするファイルを選択する必要があります。
- Zoho Workdriveを選択して、WorkDriveからドキュメントをインポートします。ここでは、ドキュメント名とドキュメントのWorkDriveリンクを入力する必要があります。
- Zoho Learnを選択して、Zoho Learnから記事をインポートします。ここでは、ドキュメント名を入力し、記事またはマニュアルのどちらをインポートするかを選択し、記事リンクを入力する必要があります。
- アップロードが完了すると、ドキュメントはナレッジベースリポジトリに表示されます。そこから、ドキュメントを削除したり、ドキュメントIDをコピーしたりできます。
注意:
-
ドキュメントストア内のアップロード済みドキュメントは、目的のドキュメントにカーソルを合わせて削除アイコンをクリックすることで削除できます。
-
特定のナレッジベースドキュメントをドキュメントストアに追加してクエリを送信すると、RAGはそれらの追加されたドキュメントのみを検索対象とします。ドキュメントストアにドキュメントが追加されていない場合、RAGはすべてのアクティブなナレッジベースドキュメント全体を自動的に検索します。これにより、手動でドキュメントを選択しなくても、最も関連性の高い利用可能なコンテンツを使用してクエリに回答されます。
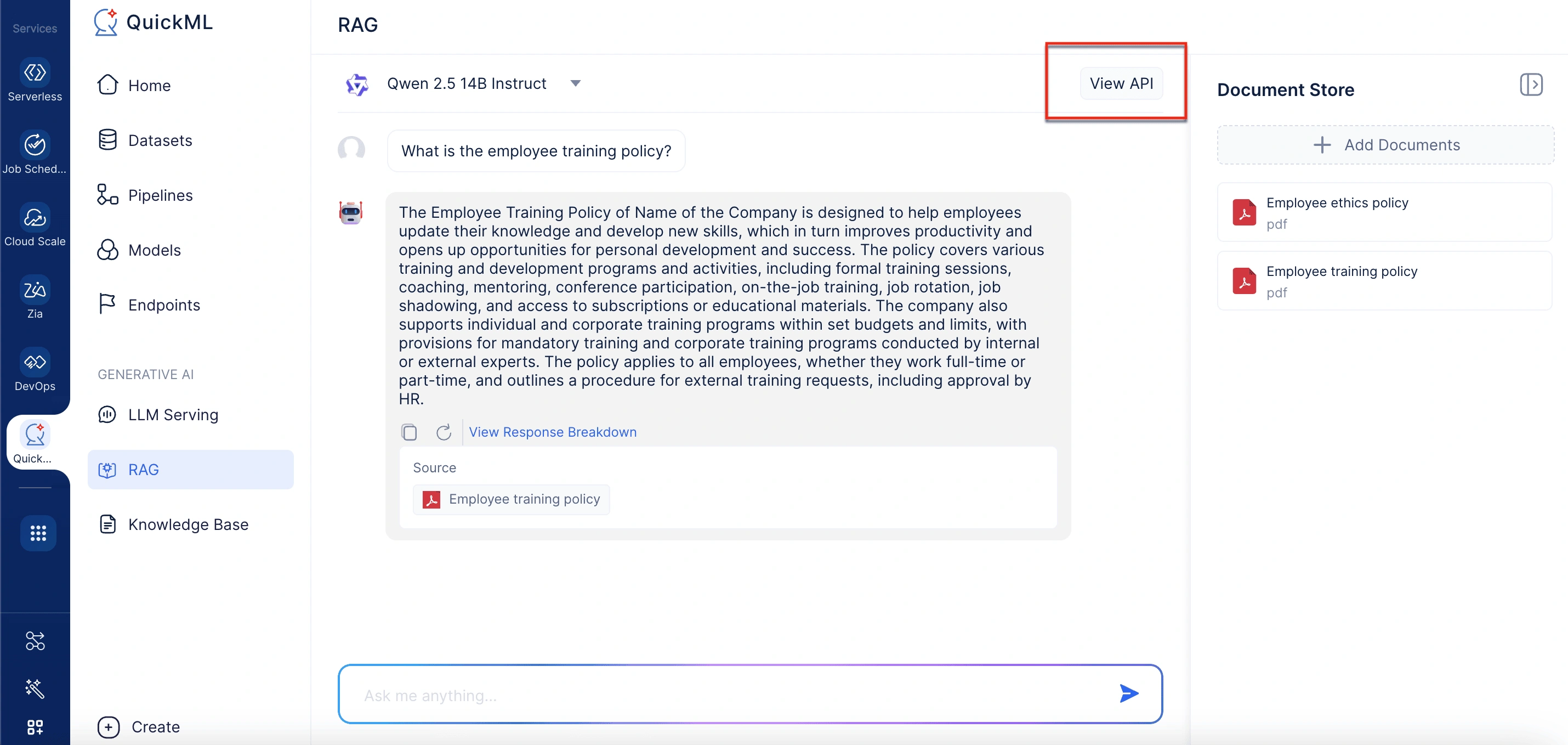
View API
チャットインターフェースには右上隅にView APIオプションも含まれています。これを選択すると、現在のモデルに関する詳細情報(サイズ、トークン制限、エンドポイントURL、認証要件など)を表示するパネルが開きます。
QuickMLにおけるRAGの動作方法
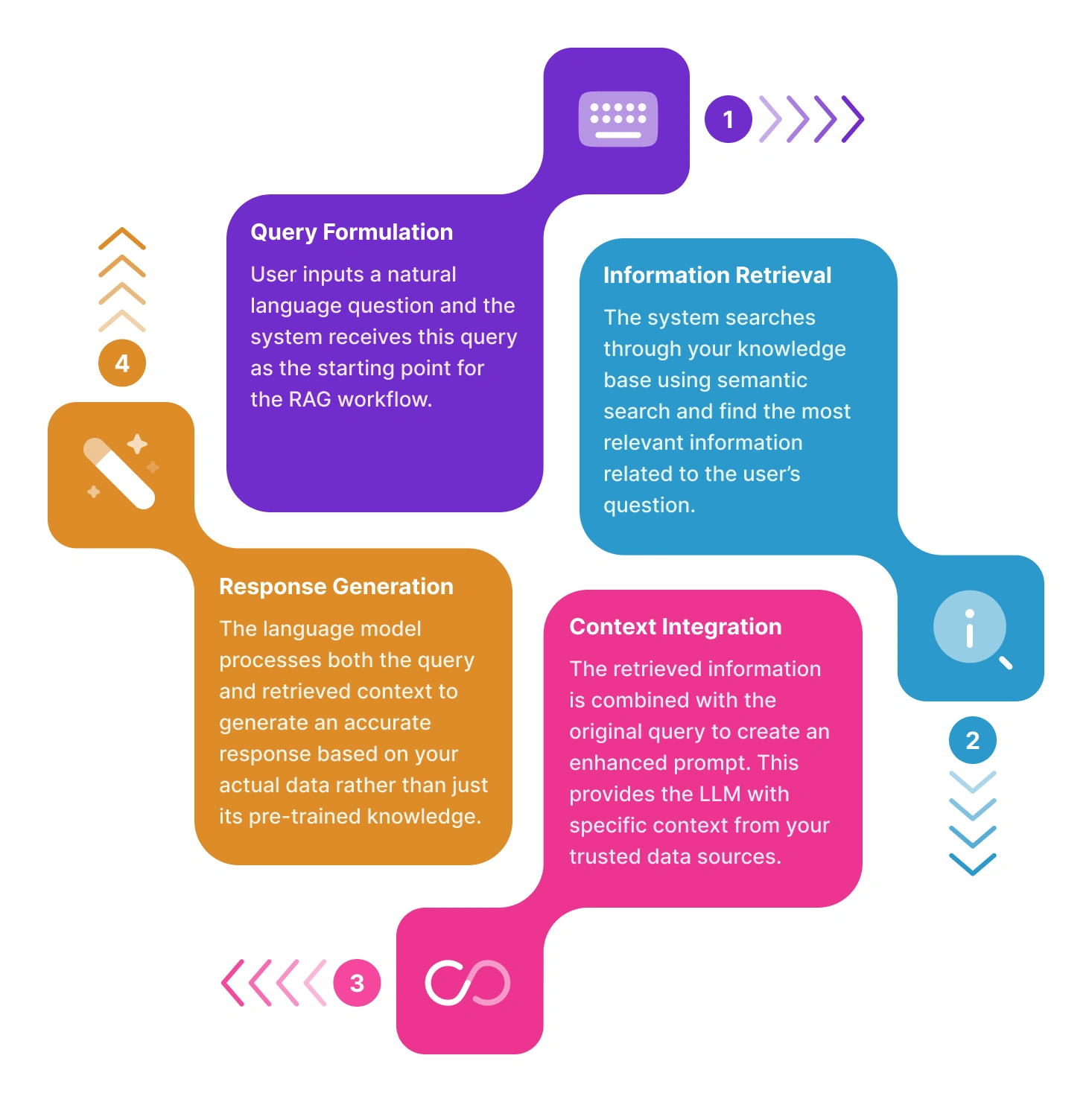
RAGなしでは、大規模言語モデル(LLM)はトレーニングデータのみに基づいて応答を生成します。RAGを使用すると、外部情報取得ステップが導入されてプロセスが強化され、クエリ時にモデルが新鮮で関連性のあるデータにアクセスできるようになります。その動作を簡単に説明します:
質問をする
ユーザーは自然言語クエリを入力することから始めます。たとえば、「当社の返品ポリシーは何ですか?」や「製品ドキュメントの最新の更新を要約してください」などです。このクエリがRAGパイプラインをトリガーする初期入力として機能します。
ドキュメントから関連情報を取得する
言語モデルの事前トレーニング済み知識のみに依存するのではなく、RAGはナレッジベース(社内ファイル、PDFなど)に接続します。高度なエンベディングとセマンティック検索技術を使用して、ユーザーの質問に基づいて最も関連性の高い情報を特定して取得します。
リランキングで結果を洗練する
関連ドキュメントが取得されると、選択されたコンテンツをユーザーの意図によりよく整合させるためにリランキングプロセスが適用されます。このステップでは、セマンティック類似性やキーワードの存在などの複数のシグナルを評価して、結果を並べ替え、クエリに対して最も文脈的に適切なコンテンツを表面化させます。
LLMに渡す
取得されたコンテンツは、元のクエリと組み合わされ、拡張プロンプトとしてLLM(Qwen 2.5-14B-Instruct)に送信されます。このステップにより、LLMは文脈固有の情報を読み取り、それを使用して情報に基づいた応答を生成できます。
文脈認識的な回答を生成する
ユーザーのクエリとサポートデータの両方を手にして、LLMは関連性があるだけでなく、実際のソース資料に基づいた応答を作成します。このアプローチにより、応答が検証可能な情報に基づき、ソース資料に整合していることが保証されます。また、ユーザーが回答を元のドキュメントまで遡って追跡でき、透明性を促進しシステムへの信頼を構築します。
重要な注意事項
-
RAG機能は、QuickMLプラットフォームにアクセスできるユーザーが利用できます。
-
チャットはユーザー固有であり、あるユーザーが他のユーザーの会話にアクセスすることはできません。 現在、チャット履歴はサポートされていません。会話はページが更新されるまで表示されます。更新すると、すべてのチャットがクリアされます。
QuickMLでのRAGへのアクセス
RAGは、以下の手順でQuickML内からアクセスできます:
- QuickMLアカウントにログインします。
- Generative AIセクションで、RAGを選択します。
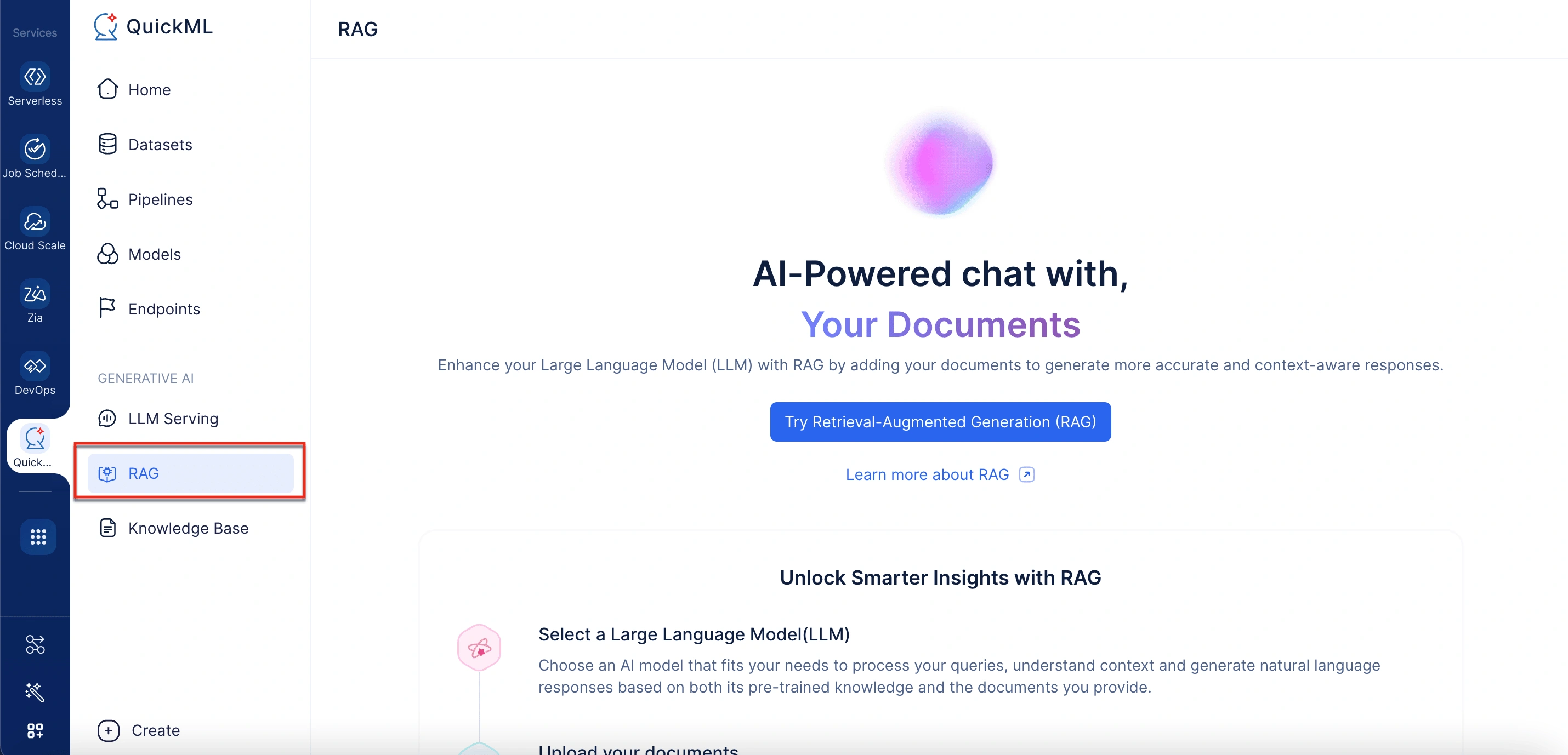
- 右パネルのDocument Storeで、Add Documentsをクリックします。 「Add Documents From Knowledge Base」というラベルのパネルが開きます。
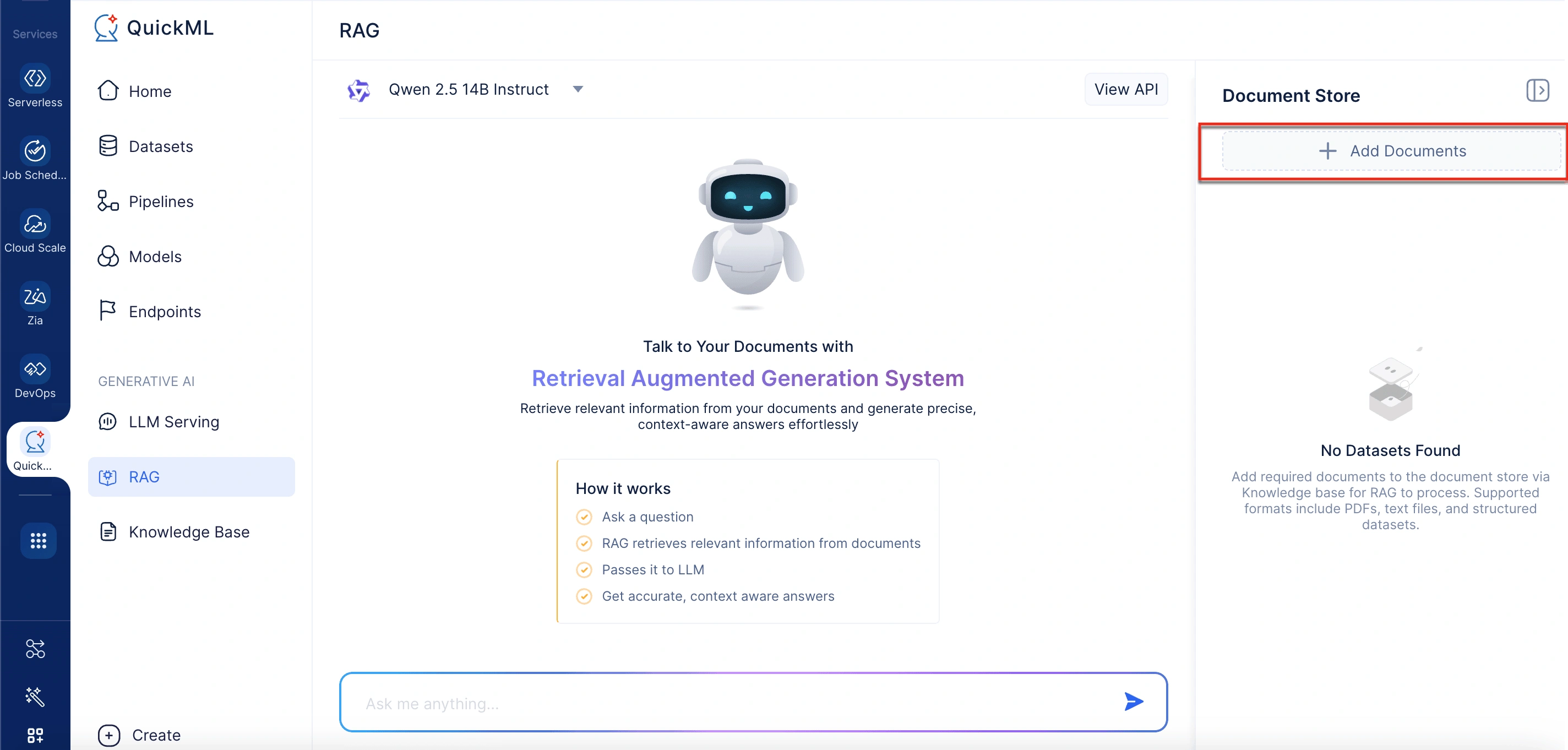
- Add Documents From Knowledge Baseパネルで、既存のファイルを選択するか、New Documentをクリックしてデスクトップ、WorkDrive、またはZoho Learnからアップロードします。
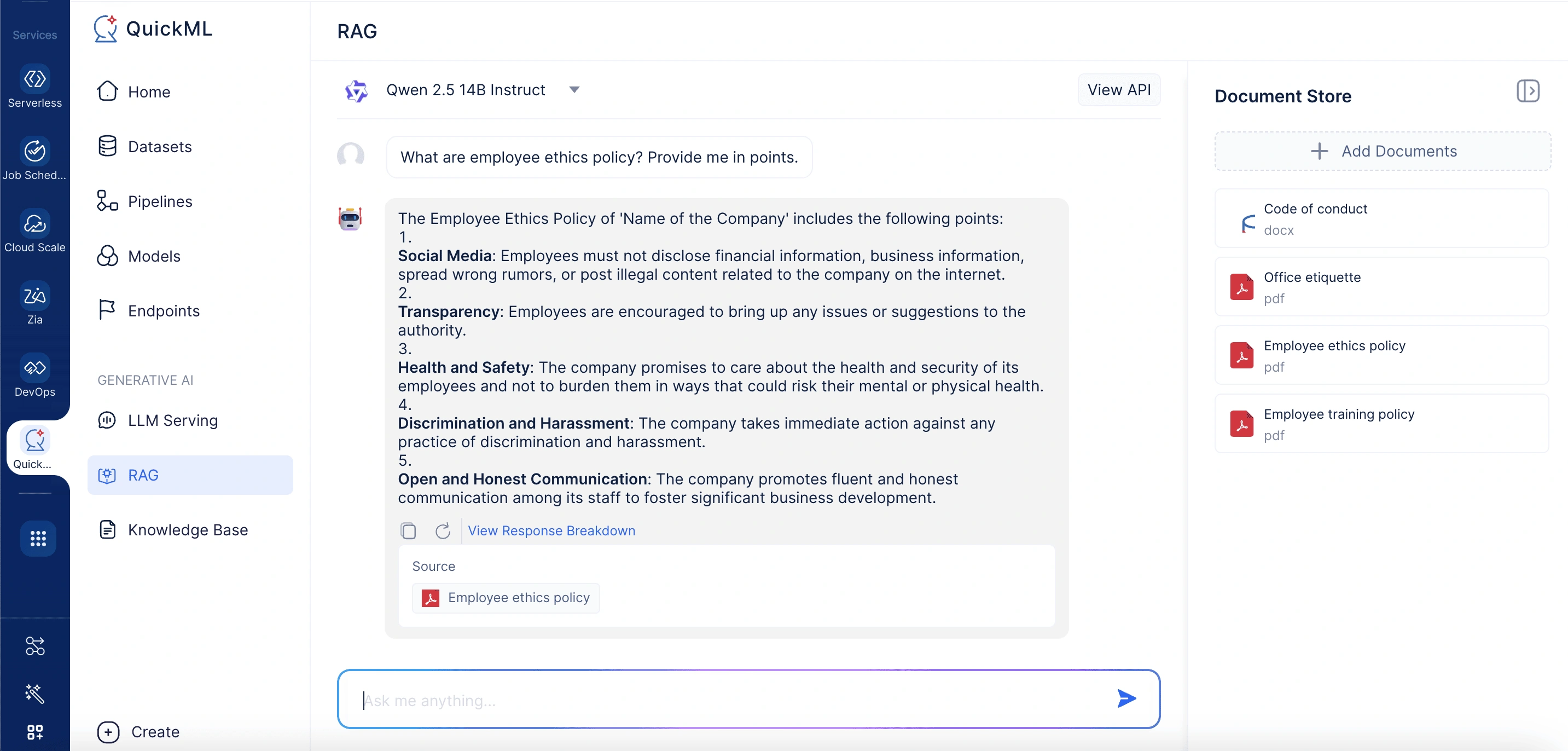
- チャットインターフェースにクエリを入力します。
モデルはナレッジベースから関連情報を取得し、詳細な応答内訳を含む文脈認識的な応答を提供します。
注意:応答はナレッジベースに保存されているドキュメントに基づいて生成されます。モデルがクエリに回答するために必要なデータを確保するため、必要に応じて新しいドキュメントを追加できます。
RAGを実際のビジネスシナリオでどのように使用できるかを理解するために、いくつかのサンプルユースケースを考えてみましょう。
サンプルユースケース1:組織における従業員ポリシーアシスタンスのためのRAGの導入
倫理およびトレーニングポリシーに関する従業員の理解を向上させることを目指す企業は、まず関連するすべてのドキュメント(行動規範、オフィスエチケットポリシー、ハラスメント防止ポリシー、職場行動ガイドライン、必須トレーニングマニュアルなど)を収集し、QuickMLのRAGナレッジベースにアップロードします。RAGチャットインターフェースから、管理者はAdd Documents From Knowledge Baseパネルにアクセスして、ファイルをインポートまたは選択します。アップロードが完了すると、ドキュメントはQwen 2.5 14B Instructがユーザーインタラクション中に参照できる、集中化された構造化されたリポジトリを形成します。
従業員が*「従業員の倫理ポリシーとは何ですか?」*のような質問をすると、QuickMLのRAGシステムはアップロードされたポリシー全体でセマンティック検索を実施し、最も関連性の高い情報を取得してクエリと組み合わせます。このコンテキストがQwen 2.5 14B Instructに送信され、簡潔で文脈的に正確な回答が生成されます。ユーザーは、応答の生成にどのドキュメントおよび具体的なセクションが使用されたかの詳細な内訳も確認でき、提供される情報の透明性と信頼性が確保されます。
サンプルユースケース2:SaaSプラットフォームにおけるRAGによるカスタマーサポートの強化
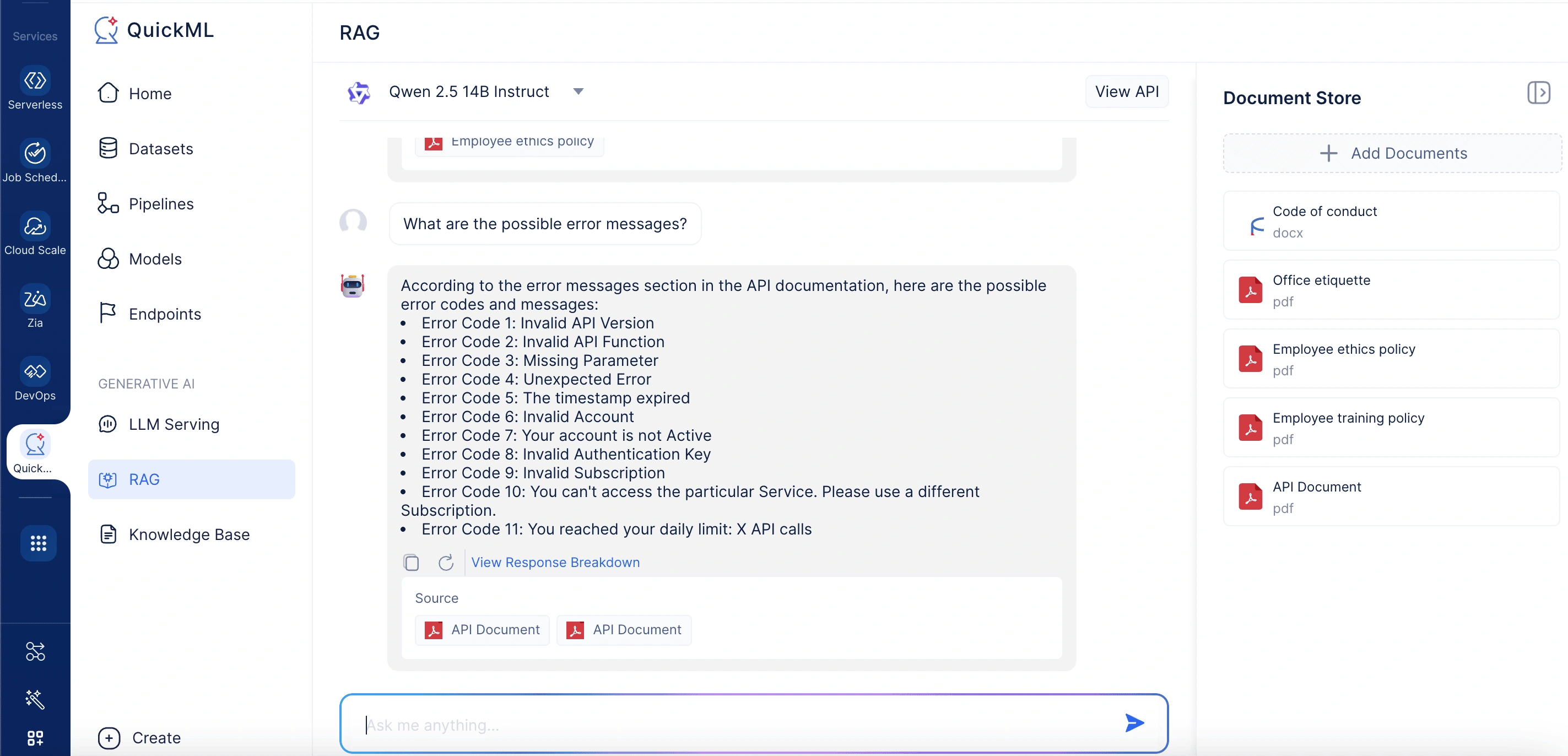
カスタマーサポート体験を向上させることを目指すSaaS企業は、RAGを活用してインテリジェントなヘルプアシスタントを構築します。サポートチームは、関連するすべてのリソース(製品FAQ、ユーザーマニュアル、トラブルシューティングガイド、リリースノート、APIドキュメント)を収集し、QuickML内のRAGナレッジベースにアップロードします。RAGチャットインターフェースを通じて、管理者はAdd Documents From Knowledge Baseパネルを使用してこのコンテンツでドキュメントストアを充填し、各製品リリースに合わせて最新の状態に保ちます。セットアップが完了すると、RAGシステムは中央サポートリポジトリとなります。
ユーザーが*「考えられるエラーメッセージは何ですか?」*のようなクエリを送信すると、システムはドキュメントストアを意味的に検索して最も関連性の高い情報を取得し、クエリとサポートコンテキストの両方を言語モデルに転送します。モデルは、正確なドキュメントセクションを参照しながら、正確でわかりやすいソリューションを生成します。ユーザーは透明性とさらなる読書のために応答の背後にあるソース資料を確認でき、チケット量の削減とセルフサービスの有効性の向上につながります。
RAGをアプリケーションに統合する
提供されたエンドポイントURLを使用して、QuickMLのRAGをアプリケーションに統合できます。これにより、企業はカスタマーサポートツール、社内チャットボット、ドキュメント自動化システムに、コンテキストリッチなAI機能を付加できます。
安全で効率的な統合を実現するため、QuickMLはアクセストークン生成のためのOAuthベースの認証をサポートしています。OAuthアプリケーションの種類とアクセストークンの生成・管理に必要な手順の詳細については、このドキュメントを参照してください。
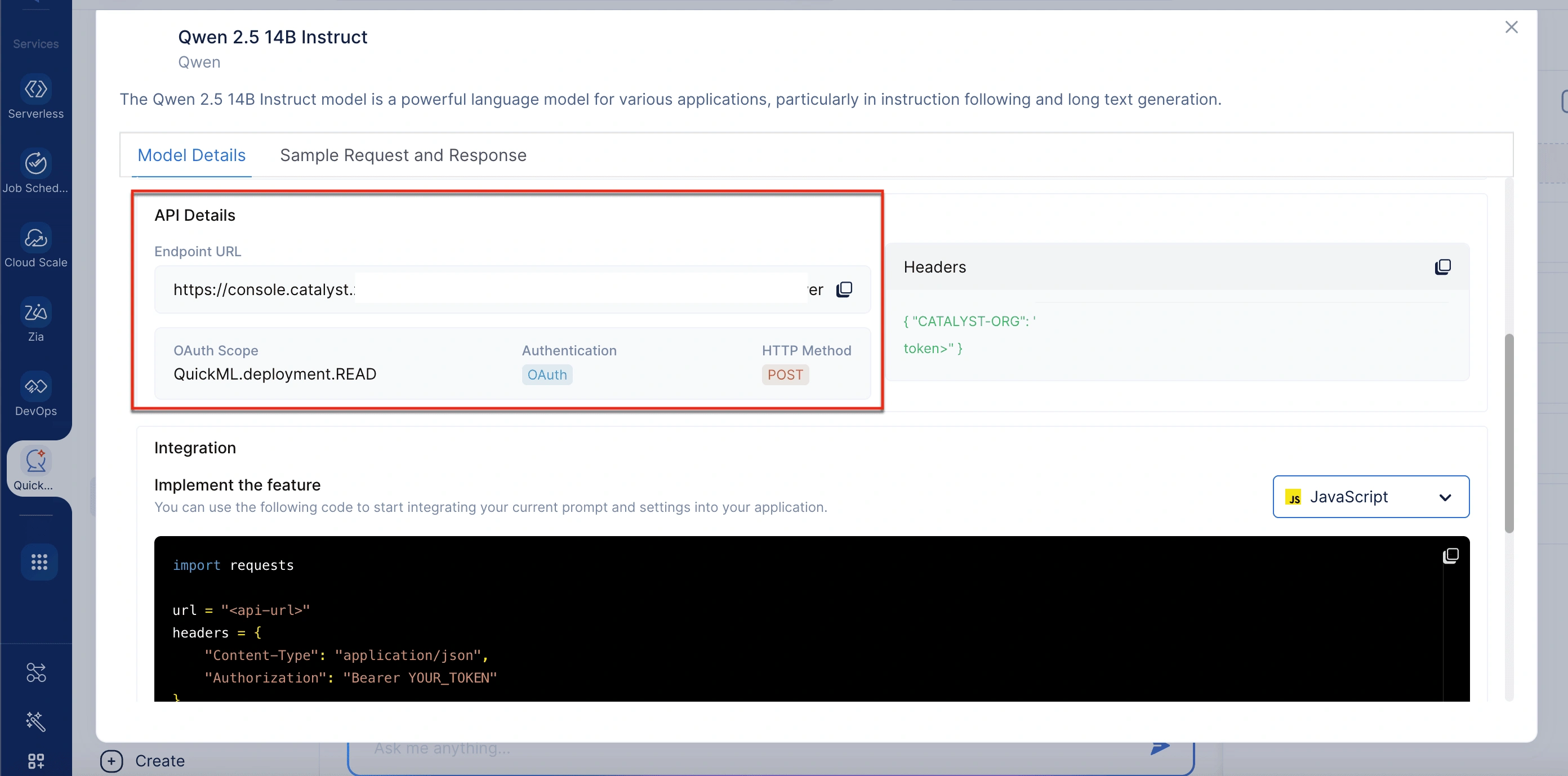
エンドポイントURLを取得するには
- QuickMLのGenerative AIセクションに移動します。
- RAGタブを選択します。
- チャットインターフェースの右上隅にあるView APIオプションをクリックします。
- Model Detailsポップアップウィンドウで、API DetailsセクションまでスクロールしてエンドポイントURLを取得します。
最終更新日 2026-02-23 18:09:41 +0530 IST
Yes
No
Send your feedback to us