LLM サービング
大規模言語モデル(LLM)の概要
**大規模言語モデル(LLM)**は、書籍、ウェブサイト、記事などの膨大なデータから学習したパターンに基づいて、人間のようなテキストを生成するよう訓練された高度なAIシステムです。特にTransformerニューラルネットワークアーキテクチャを活用する深層学習技術を利用しており、入力のシーケンス全体を並列処理します。これは、入力を順次処理していた初期のモデル(Recurrent Neural Networks(RNN)など)とは異なります。この並列処理により、GPUを効率的なトレーニングに使用でき、プロセスを大幅に加速します。このトレーニングには通常、教師なし学習または自己教師あり学習が含まれ、モデルはデータ内のパターン、文法、コンテキストを認識することで文中の次の単語を予測することを学習します。
LLMの仕組み
大規模言語モデル(LLM)の動作方法の基本的な側面は、単語の表現方法にあります。初期の機械学習モデルは、個々の単語を表現するために単純な数値テーブルに依存しており、単語間の関係、特に類似した意味を持つ単語間の関係を捉えることが困難でした。この制限は、ワードエンベディングと呼ばれる多次元ベクトルの導入によって解決されました。これらのエンベディングは、意味的または文脈的に類似した単語が互いに近くに配置されるベクトル空間に単語をマッピングします。
これらのエンベディングを使用して、Transformerはエンコーダーを使用してテキストを数値形式に変換し、モデルがコンテキスト、意味、および言語的関係(同義語や文法的役割など)を把握できるようにします。この処理された理解は、デコーダーによって使用され、意味のある一貫性のあるテキストを生成し、LLMが自然言語の構造と流れを反映した応答を生成できるようにします。
LLMの応用
LLMは、さまざまな業界にわたるリアルタイムのAI搭載ソリューションを可能にします。LLMが大きなインパクトを与えている主要な応用分野は以下のとおりです:
チャットボットとバーチャルアシスタント
LLMは、カスタマーサービス、eコマース、エンタープライズサポートで使用されるAI駆動のチャットボットとバーチャルアシスタントを支えています。これらのアシスタントは、顧客の問い合わせに対応し、自動応答を提供し、トラブルシューティングを支援できます。企業はこれらを活用してユーザー体験を向上させ、応答時間を短縮しています。
コンテンツ生成と要約
組織はLLMを活用して、記事、レポート、製品説明などの高品質なコンテンツを生成しています。さらに、LLMは長いドキュメントやニュース記事を簡潔で読みやすい形式に要約し、ユーザーの時間と労力を節約します。
コード生成とデバッグ
開発者は、複数のプログラミング言語でのコードの記述、最適化、デバッグを支援するLLMの恩恵を受けています。これらのモデルは、即座にコード提案と説明を提供することでソフトウェア開発を効率化し、開発時間を短縮します。
言語翻訳とローカライゼーション
LLMは、企業や個人にリアルタイムで文脈認識的な翻訳を提供することで翻訳サービスを強化します。これは、異なる言語を話す人々の間のシームレスなインタラクションを可能にするグローバルコミュニケーションに特に有用です。
画像とテキスト分析(マルチモーダルAI)
Qwen 2.5 - 7B Vision Languageなどの高度なマルチモーダルLLMは、テキストと画像の両方を処理します。これらのモデルは、画像を記述し、オブジェクトを認識し、視覚的な質問に答えることができます。ヘルスケア、アクセシビリティ、デジタルコンテンツモデレーションなどの業界では、自動化と意思決定の強化のためにこれらの機能を使用しています。
LLM Servingの理解
LLM Servingは、大規模言語モデル(LLM)をデプロイして実行し、予測や応答のリアルタイムリクエストを処理できるようにすることを意味します。LLMがトレーニングされると、テキスト生成、質問応答、言語翻訳、大規模データセットの理解・分析など、さまざまなタスクの実行に使用できます。
LLM Servingの目的
LLM Servingの主な目的は、トレーニング済みモデルとその実世界での使用との間のギャップを埋めることです。これにより、組織は以下を実現できます:
-
本番環境でのAIモデルの運用化
-
リアルタイムの同時リクエストに対応するためのスケーラビリティと信頼性の確保
-
製品、ツール、ビジネスプロセスへのシームレスな統合
-
LLMを研究ツールから、ビジネス成果を推進する実用的で使用可能なシステムへの変換
LLM Servingのアーキテクチャ
適切に構造化されたアーキテクチャにより、LLMサービングシステムが効率的に動作し、迅速に応答することが保証されます。通常、以下のレイヤーで構成されます:
-
クライアントレイヤー:質問やテキスト入力など、ユーザーやアプリケーションからのリクエストを受信します。
-
APIレイヤー:リクエストをLLMが理解できる形式に変換し、モデルに送信します。
-
モデルレイヤー:LLMを実行し、リクエストを処理して応答を生成します。
-
データレイヤー:入出力データを処理し、モデルとユーザー間のスムーズなデータフローを確保します。
QuickMLにおけるLLM Servingの独自機能
QuickMLにより、チャットインターフェース内でさまざまな大規模言語モデル(LLM)を簡単に使用できます。ユーザーはニーズに応じて異なるモデルを選択し、リアルタイムの応答を取得できます。
限定的または固定的なパラメータチューニングしか提供しない多くの競合プラットフォームとは異なり、QuickMLは広範なカスタマイズオプションを提供し、より高い柔軟性と制御を保証します。QuickMLが際立つ点は以下のとおりです:
-
応答を簡単に微調整:ユーザーフレンドリーなインターフェース内で、創造性、一貫性、出力の長さを直接調整できます。
-
シームレスなモデル切り替え:単一のチャットインターフェース内で複数のLLMモデルを簡単に切り替え、ニーズに最適なモデルを見つけることができます。
-
簡単な統合:提供されたエンドポイントURLを使用して、スムーズでスケーラブルな実装のためにモデルをサードパーティアプリケーションにデプロイできます。
-
最適化されたパフォーマンスとコスト管理:不要なトークン使用を最小限に抑えるよう応答をカスタマイズし、速度とコスト効率の両方を最適化します。
-
アクセシビリティの向上:複雑なセットアップは不要です。QuickMLにより、非技術ユーザーでも高度なAI機能にアクセスできます。
LLM Servingで利用可能なモデル
以下は、QuickMLで利用可能なモデルの一部と、その機能およびユースケースです。
Qwen 2.5 -14B Instruct
質問応答、テキスト要約、コンテンツ生成などの汎用タスク向けに設計された、軽量ながら効率的な言語モデルです。
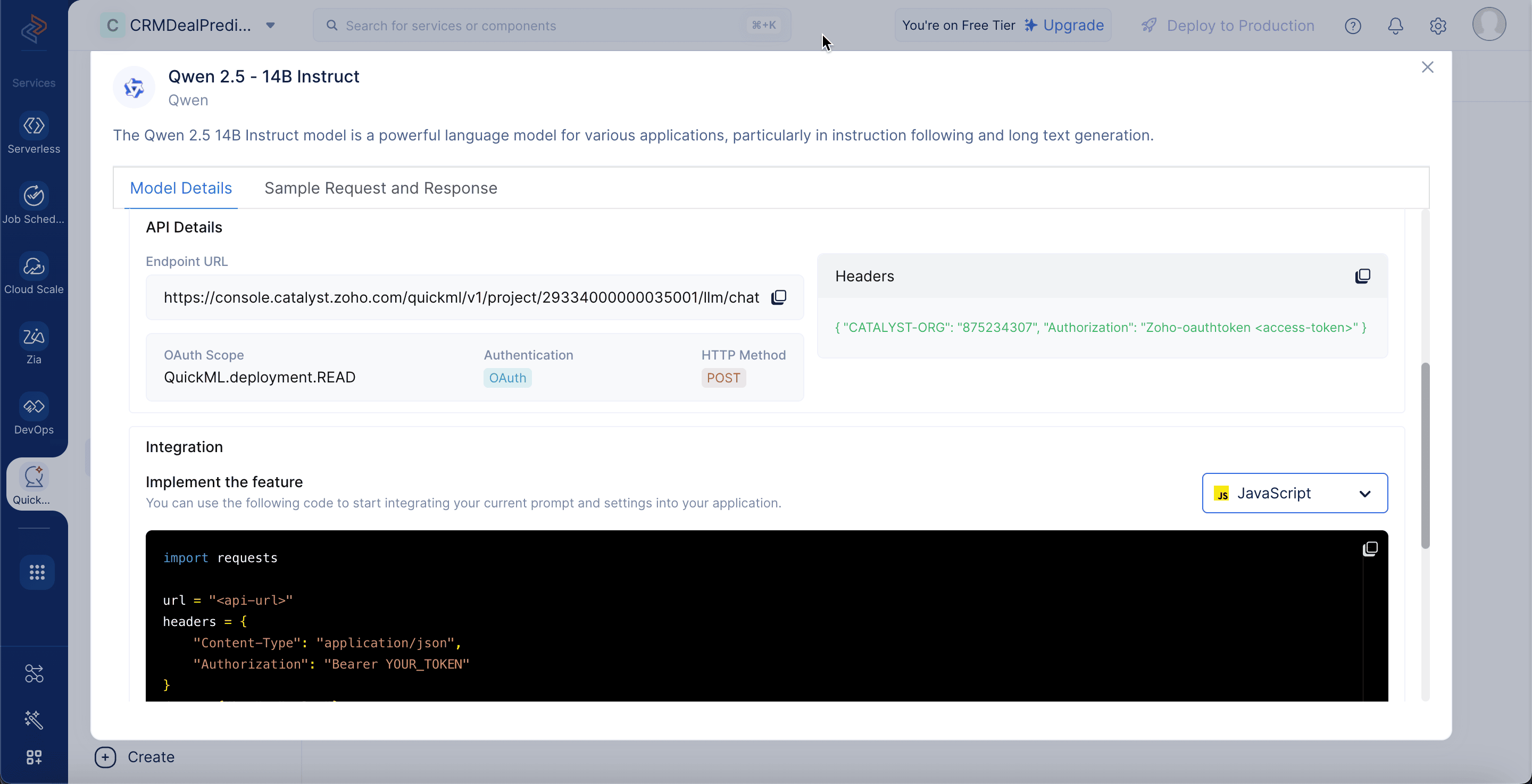
Qwen 2.5 - 14B Instructモデルの詳細
モデルの詳細を表示するには、LLM Servingタブに移動し、Modelsを選択して、Qwen 2.5 - 14B Instructモデルを選択します。モデルの詳細には以下が含まれます:
-
モデルサイズ:モデルは140億のパラメータで構成されており、高レベルの言語理解と生成を可能にします。
-
トレーニングサイズ:18兆トークンの大規模データでトレーニングされており、多様なドメインにわたる幅広い知識カバレッジを提供します。
-
パラメータ:モデルは140億の学習可能な重みを使用して、正確で文脈認識的な応答を生成します。
-
入力トークン制限:最大128,000トークンの入力をサポートしており、非常に大きなコンテキストやドキュメントの処理が可能です。
-
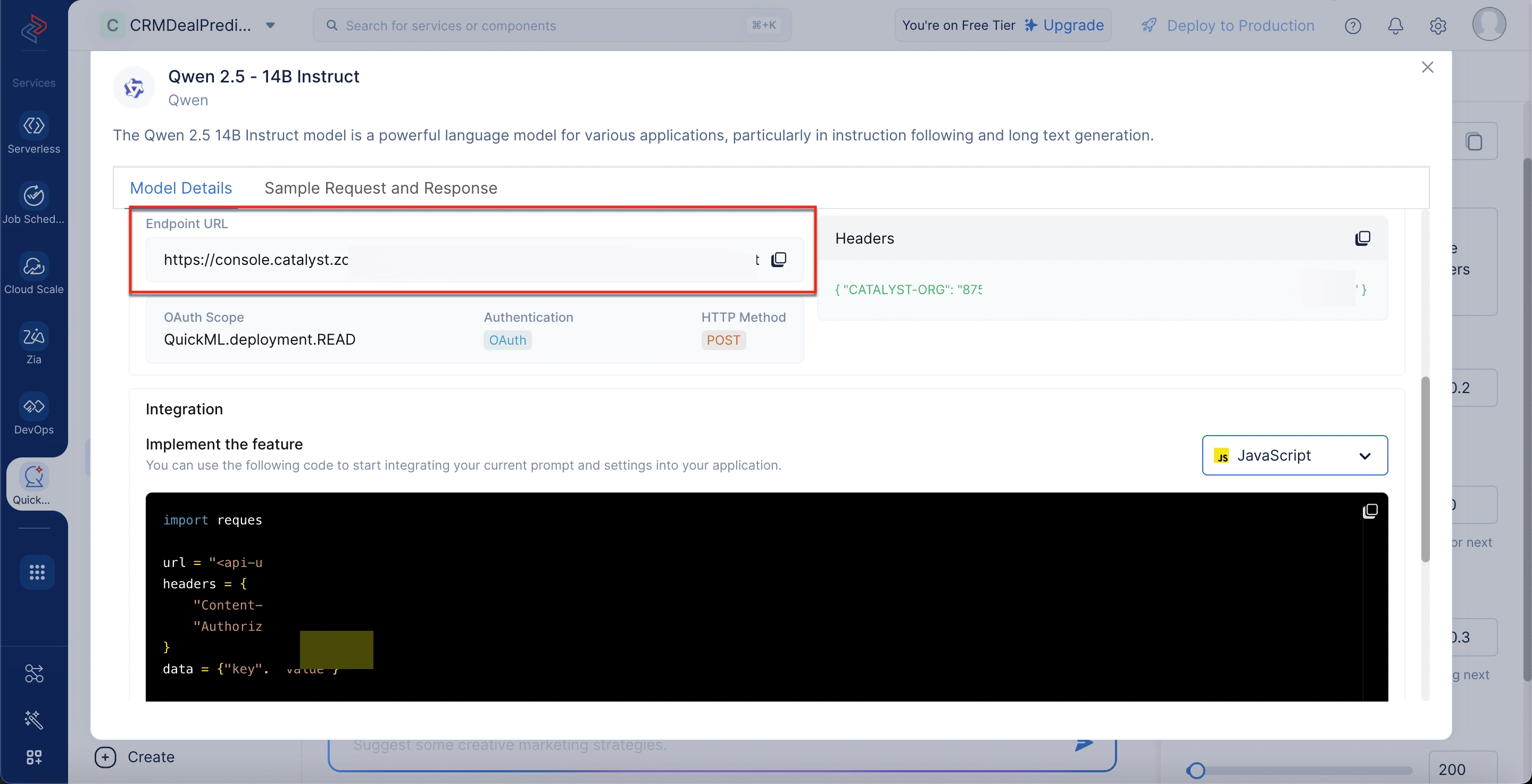
エンドポイントURL:モデルにプロンプトを送信するために使用するAPIアドレスです。
-
OAuthスコープ:モデルにアクセスするために必要な権限レベルです。
-
認証:ユーザーIDを検証するための方法としてOAuthを指定します。
-
HTTPメソッド:APIリクエストはPOSTメソッドを使用して行う必要があることを示します。
-
ヘッダー:認証のために、組織IDとOAuthトークンを含むメタデータが必要です。
-
統合セクション:アプリケーションとモデルを接続するためのサンプルコードを提供します。
-
サンプルリクエスト1:top_p、temperature、max_tokensなどのパラメータとともに、Qwen 2.5 - 14B Instructモデルにプロンプトを送信する方法を示すサンプル入力JSON形式です。
-
サンプルレスポンス1:プロンプトに基づいてモデルが生成した応答を含む出力JSON形式です。
-
考えられるエラーレスポンス:400(Bad Request)や500(Internal Server Error)などの一般的なHTTPステータスエラーを一覧表示します。
-
サンプルエラーレスポンス:失敗したAPI呼び出しのデバッグのために、コード、メッセージ、オプションの理由を含む構造化されたエラーメッセージです。
モデルをアプリケーションに統合する手順については、LLMをアプリケーションに統合するセクションを参照してください。
Qwen 2.5 - 7B Coder
コード生成、デバッグ、説明などのプログラミング関連タスクに特化して構築されたモデルです。
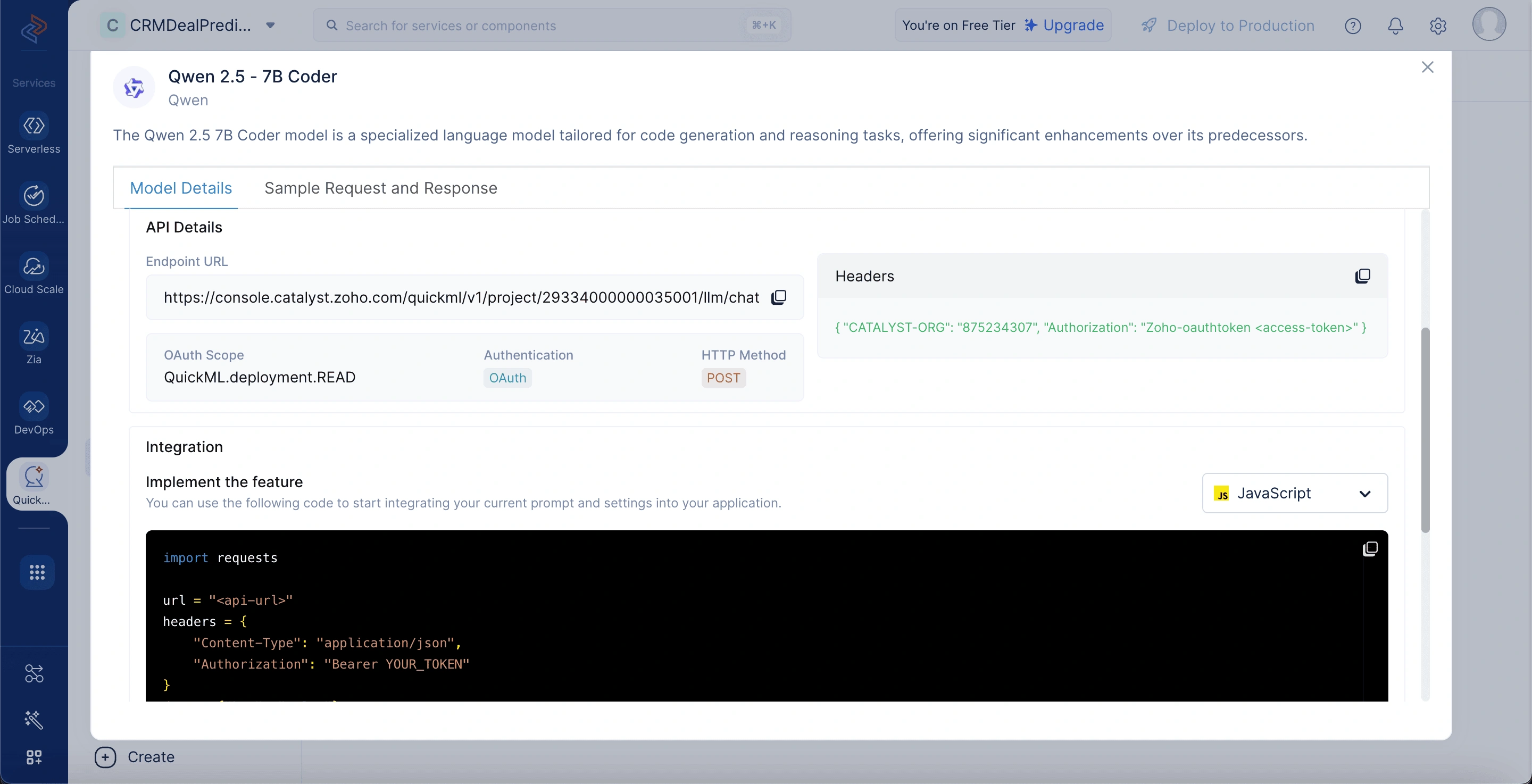
Qwen 2.5 - 7B Coderモデルの詳細
モデルの詳細を表示するには、LLM Servingタブに移動し、Modelsを選択して、Qwen 7Bモデルを選択します。モデルの詳細には以下が含まれます:
-
モデルサイズ:モデルは70億のパラメータで構成されており、自然言語の理解と生成において優れた性能を発揮します。
-
トレーニングサイズ:5.5兆トークンでトレーニングされており、幅広いドメイン知識と文脈理解を可能にします。
-
パラメータ:モデルは70億の学習可能な重みを使用して、インテリジェントで文脈認識的な応答を生成します。
-
入力トークン制限:最大128,000トークンの入力をサポートしており、長いコードや複雑な命令の処理に適しています。
-
追加機能:コード生成、推論、拡張コンテキスト理解などの機能を備えています。
-
エンドポイントURL:デプロイされたモデルにリクエストとプロンプトを送信するために使用するAPIエンドポイントです。
-
OAuthスコープ:モデルとインタラクションするために必要なアクセスレベルを定義します(QuickML.deployment.READ)。
-
認証:ユーザーアクセスを安全に検証・承認するためにOAuthを使用します。
-
HTTPメソッド:モデルにデータを送信するにはPOSTメソッドを使用する必要があります。
-
ヘッダー:認証のために組織IDやOAuthトークンなどの必要なメタデータを含みます。
-
統合セクション:アプリケーションでモデルを接続して使用するための、すぐに使用できるコードスニペットを提供します。
-
サンプルリクエスト1:モデル名、temperature、max tokensなどのパラメータを構造化してプロンプトを設定する方法を示します。
-
サンプルレスポンス1:サンプルリクエストに対してモデルが生成した構造化出力を表示します。
-
考えられるエラーレスポンス:400(Bad Request)や500(Internal Server Error)などの一般的なエラーを含み、失敗したリクエストを示します。
-
サンプルエラーレスポンス:トラブルシューティングのために、code、message、reasonフィールドを含むJSON形式のエラーメッセージを表示します。
モデルをアプリケーションに統合する手順については、LLMをアプリケーションに統合するセクションを参照してください。
Qwen 2.5 - 7B Vision Language
画像とテキストの両方を理解できる70億パラメータのビジョン言語モデルです。画像キャプション、ビジュアル質問応答、マルチモーダル推論などのタスク向けに設計されています。
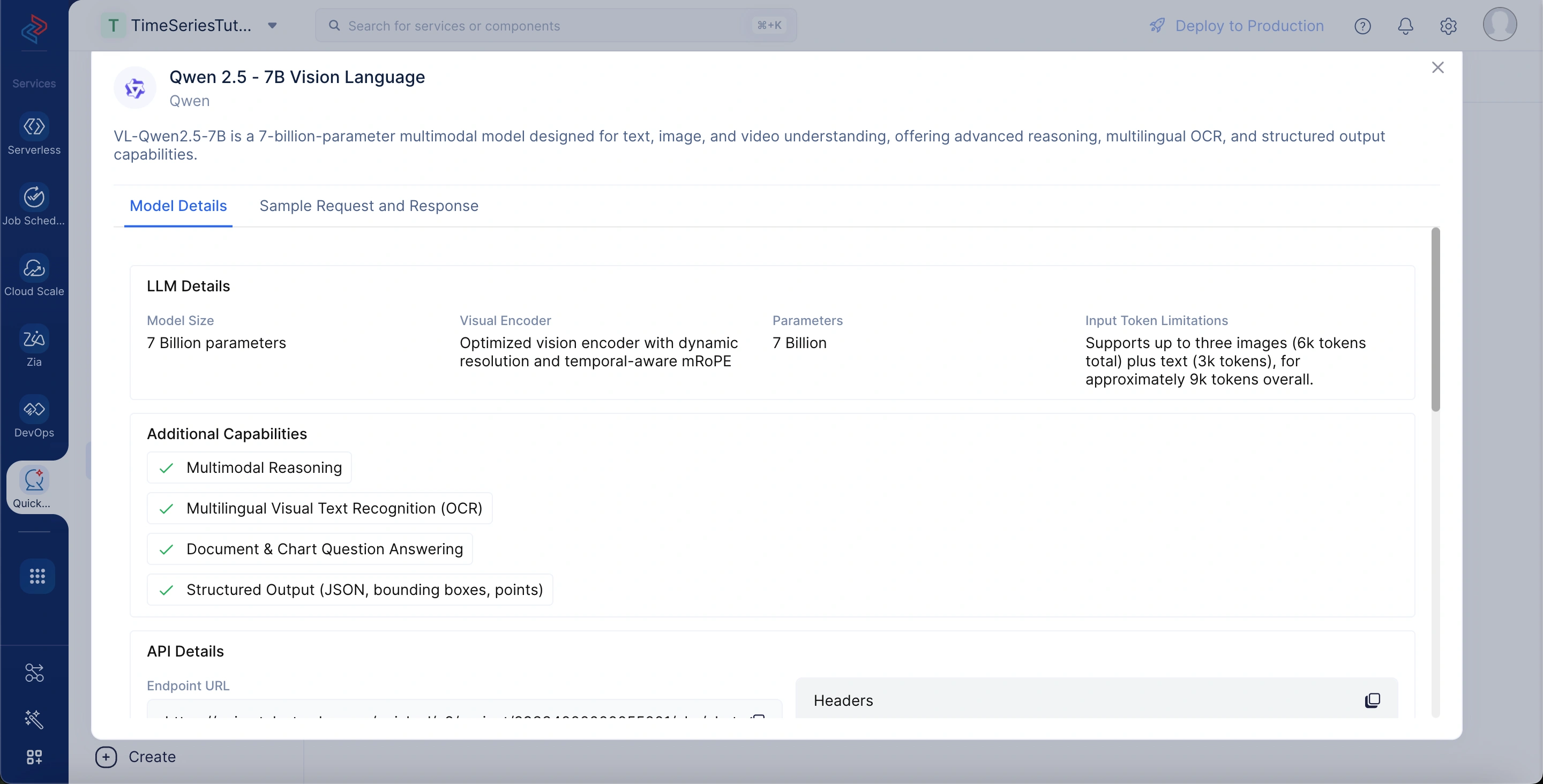
モデルの詳細を表示するには、LLM Servingタブに移動し、Modelsを選択して、Qwen 2.5 - 7B Vision Languageモデルを選択します。モデルの詳細には以下が含まれます:
-
モデルサイズ:コア言語モデルは70億のパラメータで構成されています。
-
ビジュアルエンコーダー:動的解像度と時間認識mRoPEを備えた最適化されたビジョンエンコーダーを使用します。
-
パラメータ:合計70億のトレーニング可能な重みがモデルを駆動します。
-
入力トークン制限:最大3枚の画像(約6kトークン)とテキスト(約3kトークン)をサポートし、合計約9kトークンです。
-
追加機能:マルチモーダル推論、多言語OCR、ドキュメント・チャートの質問応答、構造化出力(JSON、バウンディングボックス、ポイント)を提供します。
-
エンドポイントURL:デプロイされたビジョン言語モデルにテキストと画像のプロンプトを送信するために使用するAPIエンドポイントです。
-
OAuthスコープ:モデルとインタラクションするにはQuickML.deployment.READ権限スコープが必要です。
-
認証:認可されたアクセスのためにOAuth認証で保護されています。
-
HTTPメソッド:モデルにプロンプトとメディアデータを送信するためにPOSTメソッドを使用します。
-
ヘッダー:安全なAPIリクエストのために、組織IDやアクセストークンなどの必須メタデータを含みます。
-
統合セクション:Python、JavaScript、その他の言語での統合用のすぐに使用できるサンプルコードを提供します。
-
サンプルリクエスト1:マルチモーダル入力(テキスト + base64エンコード画像)を示し、system_prompt、top_k、top_p、temperature、max_tokensなどの設定可能なパラメータを含みます。
-
サンプルレスポンス1:指定されたドキュメント画像から連絡先情報、スキル、学歴、プロジェクトなどの詳細を抽出する構造化JSON出力を表示します。
-
考えられるエラーレスポンス:400(Bad Request)や500(Internal Server Error)などの標準的なエラーを含みます。
-
サンプルエラーレスポンス:API問題のデバッグに役立つcode、message、reasonを含むJSONを返します。
モデルをアプリケーションに統合する手順については、LLMをアプリケーションに統合するセクションを参照してください。
チャットインターフェースの内訳
QuickMLでLLM Serving機能にアクセスする方法を見る前に、チャットインターフェースの構造について簡単に見てみましょう。
モデル選択
「Chat」タブの左上に位置し、利用可能なLLMモデルから選択できます。同じインターフェース内で素早くモデルを切り替えることができ、チャットインターフェースを離れることなく特定のユースケースに異なるモデルをテストしやすくなります。
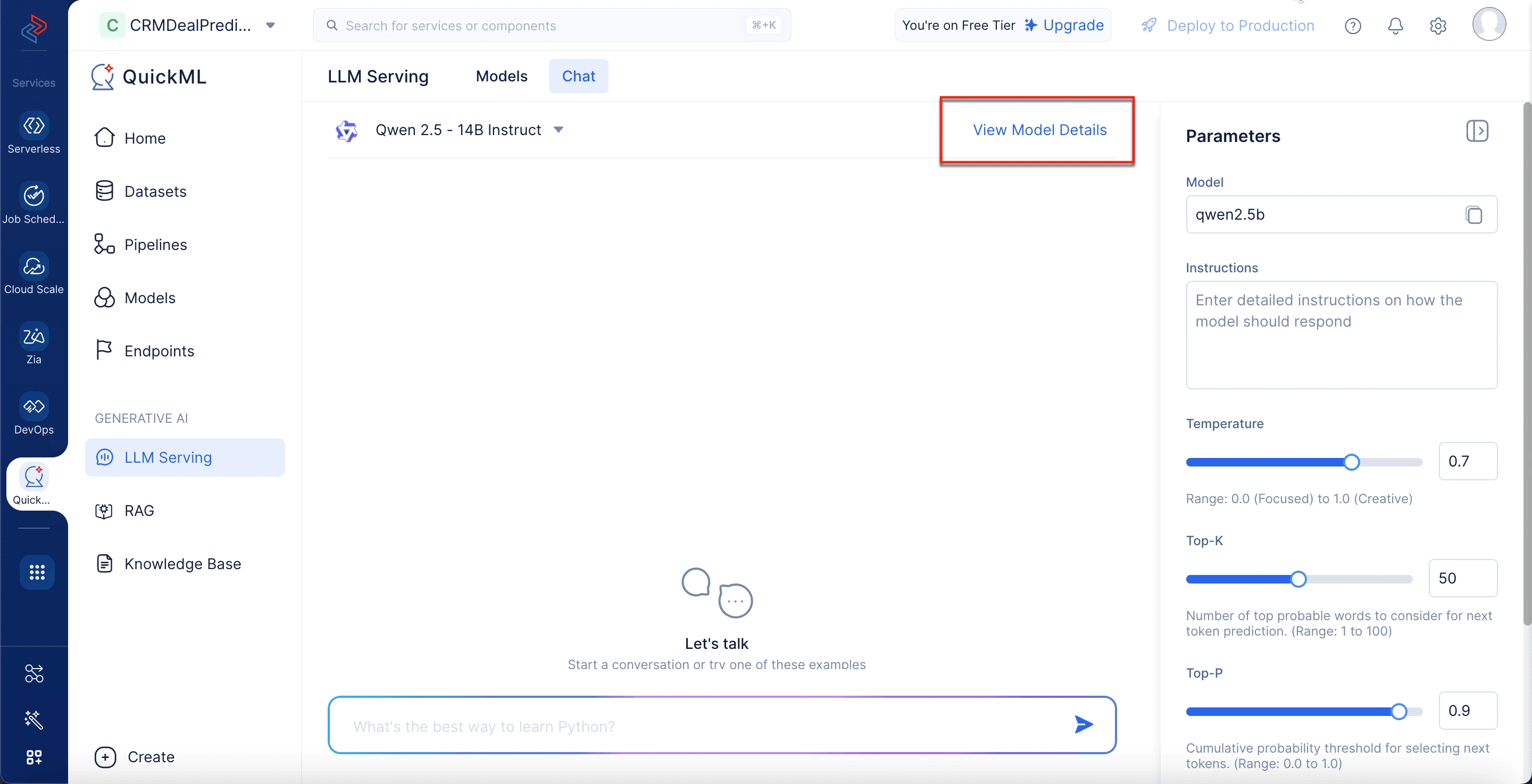
モデル詳細の表示
選択されたモデル名の横にあるView Model Detailsオプションをクリックすると、モデルに関する詳細情報を表示するポップアップウィンドウが開きます。これには、モデルサイズ、入力トークン制限、トレーニングデータ、統合オプションなどが含まれます。モデルの機能と使用方法についてより深いインサイトを提供します。
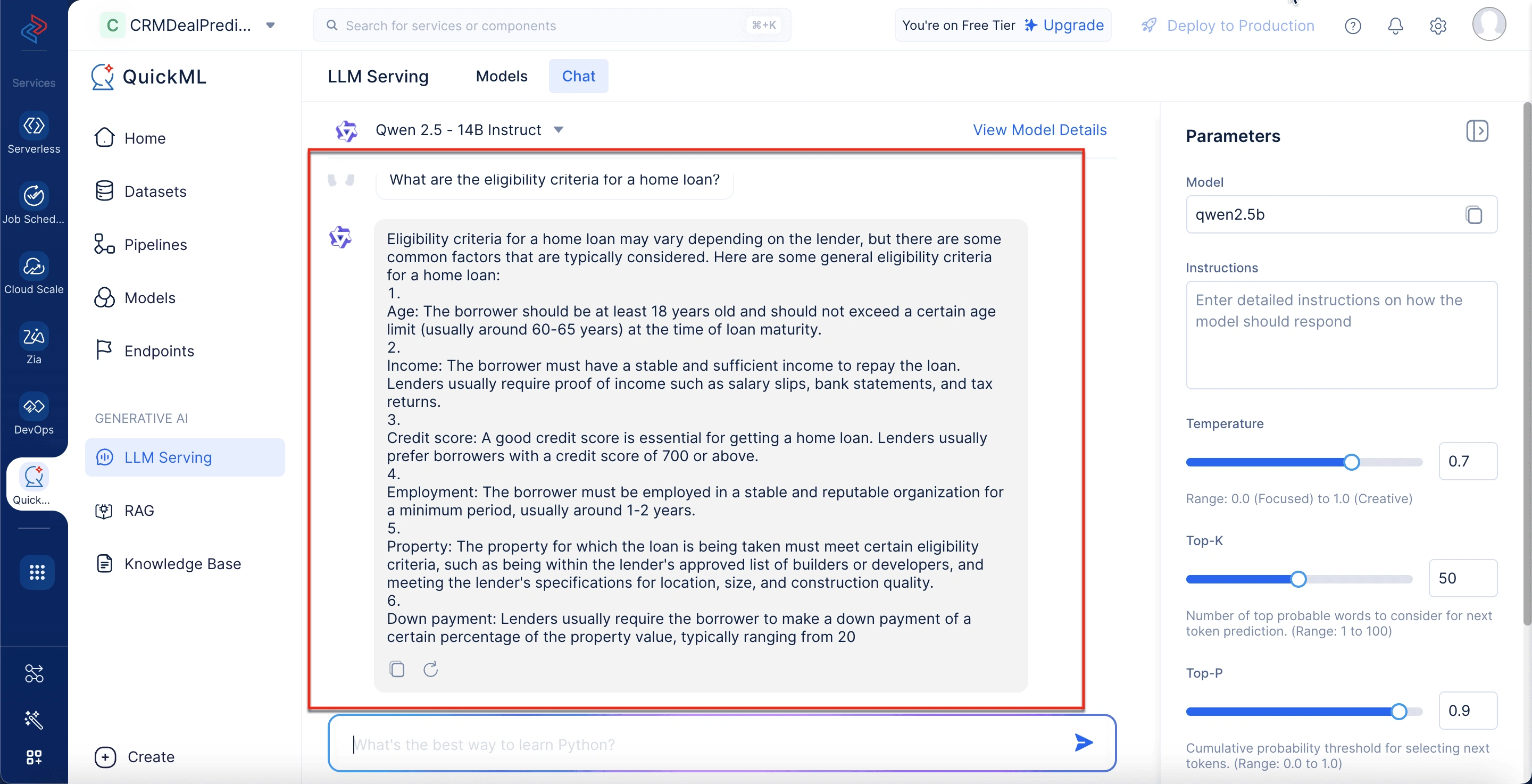
チャットインターフェース(会話パネル)
この中央エリアは、すべてのインタラクションが行われる場所です。プロンプトを入力し、モデルが生成した応答をスレッド形式で表示できます。各応答には、個別の応答のコピーや再生成などのアクションのアイコンが含まれます。
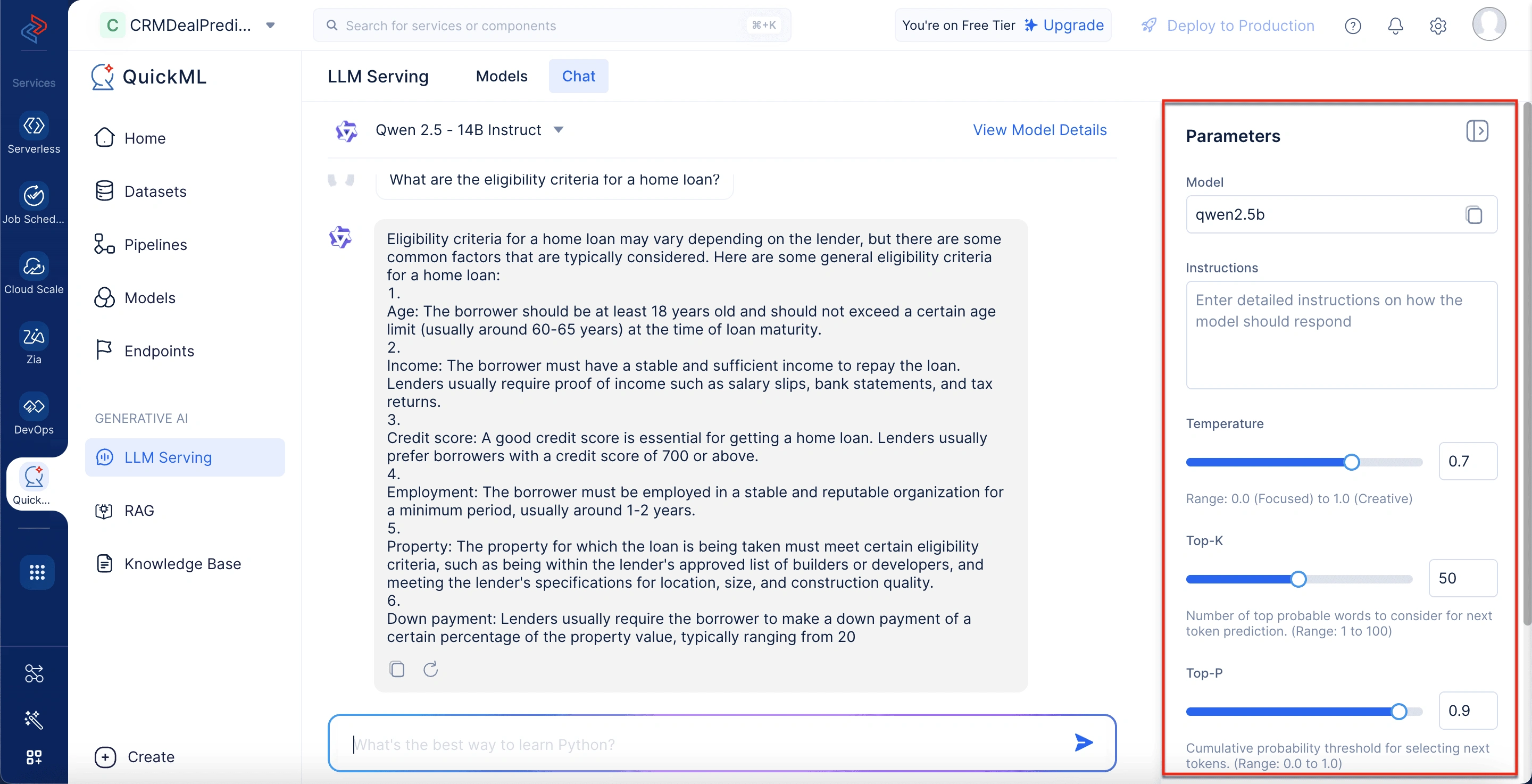
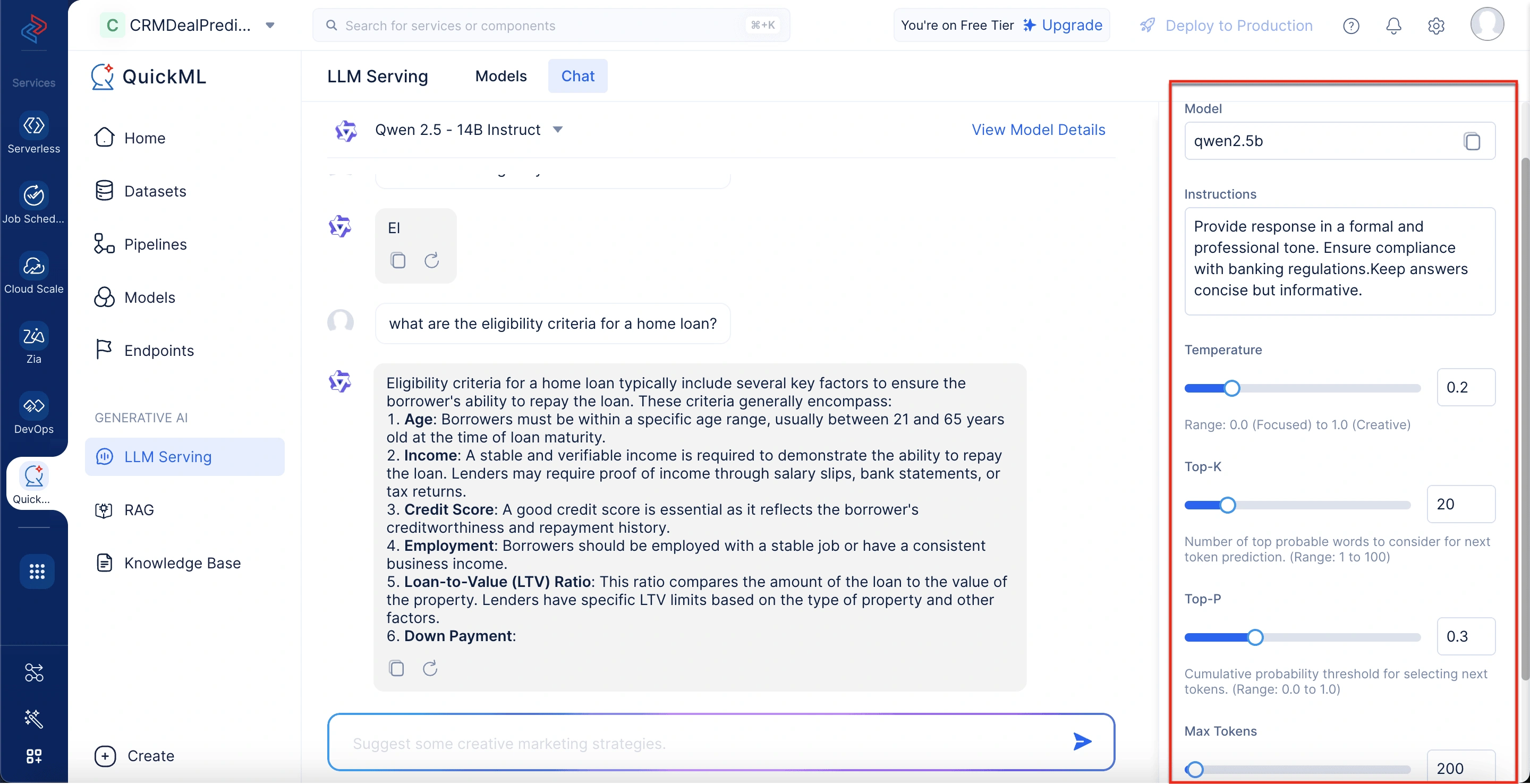
パラメータパネル
右側にあるこのパネルでは、Temperature、Top-K、Top-P、Max Tokensなどのパラメータを調整してモデルの動作を微調整できます。トーン、形式、ドメイン固有の要件を指定するための指示フィールドもあります。これらの設定は、エンタープライズまたはユーザー固有のニーズに出力を合わせるのに役立ちます。
チャットボックス
画面の下部にはチャット入力ボックスがあり、選択された言語モデルとインタラクションするためにプロンプトや質問を入力できるメインエリアです。
LLM Servingのパラメータ
QuickMLは、開発者や企業がさまざまなカスタマイズ可能なパラメータを通じてAIモデルの動作を微調整できる、堅牢で柔軟なLLM(大規模言語モデル)サービング環境を提供します。これらの設定により、モデルが入力をどのように解釈し、応答を生成し、出力を希望するトーン、構造、目的に合わせるかを制御できます。
法律アドバイザーボット、コンテンツ作成ツール、カスタマーサービスアシスタントを構築する場合でも、QuickMLのパラメータ設定オプションにより、アプリケーションが関連性のあるだけでなく、文脈的にカスタマイズされた応答を提供することが保証されます。
ユーザー制御を制限する他のプラットフォームとは異なり、QuickMLは透明性と適応性を優先し、創造性と精度のバランスを取り、理想的な応答の長さを決定し、ドメイン固有のニーズに最も適した方法でモデルを動作させるよう導くことができます。
利用可能なパラメータの内訳は以下のとおりです:
モデル名
modelフィールドでは、簡単な参照とデプロイのためにモデル名をコピーできます。
指示
Instructionsフィールドボックスに詳細な指示を入力して、モデルの応答スタイルとコンテンツ生成アプローチを導くことができます。これにより、特定のアプリケーションに対する出力の関連性と一貫性が向上します。
たとえば、法律事務所は「該当する場合は引用を含む正式な法的トーンで応答を提供してください。」のような指示を入力し、AI生成コンテンツがコンプライアンスと専門基準に沿うことを保証できます。
Temperature
モデルの応答の創造性レベルを制御します:
- 低い値(例:0.0 - 0.3):より決定論的で正確な応答。
- 高い値(例:0.7 - 1.0):変動性と創造性が増加し、応答がより多様で魅力的になります。
たとえば、金融機関がTemperatureを0.2に設定すると「連邦準備制度理事会は金利を0.25%引き上げました。」のような正確な応答が得られ、0.8に設定すると「連邦準備制度理事会の最近の0.25%の利上げは、インフレを抑制することを目的としており、住宅ローンやローン金利に影響を与えます。」のような応答が生成される可能性があります。
Top-K
次のトークン予測で考慮される上位の確率的な単語の数を決定します:
- 低い値(例:10 - 20):より予測可能で制御された応答を生成します。
- 高い値(例:50 - 100):生成されるテキストの多様性とバリエーションを高めます。
たとえば、企業のHRチャットボットでTop-Kを10に設定すると「私たちは採用プロセスにおいて多様性を重視しています。」のような標準的な応答が生成される可能性がありますが、50に設定すると「[Company Name]では、多様性は採用プロセスの中核にあり、イノベーションとインクルーシブ性を育んでいます。」のような、より豊かで魅力的な応答が可能になります。
Top-P
Top-Pサンプリングは、一般的に0.0 - 1.0の範囲のNucleusサンプリングとも呼ばれます。このパラメータは、次のトークン選択の累積確率しきい値を設定します:
- 低い値(例:0.1 - 0.3):非常に決定論的な応答を生成します。
- 高い値(例:0.8 - 0.9):一貫性を維持しながら、より多様なテキスト生成を可能にします。
たとえば、カスタマーサポートAIでTop-P設定を0.3にすると「ご注文は3日以内に届きます。」のような直接的な応答が生成される可能性がありますが、0.9にすると「ご注文は3日以内に届く予定です。まもなく追跡の更新情報をお届けします!さらにサポートが必要な場合はお知らせください。」のような応答になる可能性があります。
Max tokens
モデルが応答で生成できるトークンの最大数(1〜4096)を定義します。QuickMLでは応答の長さを正確に制御でき、コストとレイテンシーを最適化します。
たとえば、コンプライアンスチームがMax Tokensを50に設定すると「GDPRはEU市民のデータ保護を義務付けています。」のような簡潔な規制要約が保証され、500に設定すると主要な規定とコンプライアンス措置を詳述する包括的な法的分析が生成される可能性があります。
QuickMLにおけるLLM Servingの動作
-
ユーザーがQuickMLのLLMサービングチャットインターフェースでリクエストを送信すると、選択されたモデル(Qwen 2.5 - 14B Instructなど)が入力を処理します。
-
モデルはクエリのコンテキスト、意図、意味を分析して、関連性のある一貫した応答を生成します。
-
応答はモデルのトレーニングデータに基づいて作成され、精度と文脈的な関連性が確保されます。
-
ユーザーはクエリを精緻化したり、モデルパラメータを調整して応答のスタイル、トーン、詳細レベルに影響を与えることができます。

注意すべきポイント:
-
LLMサービング機能は、QuickMLプラットフォームにアクセスできるユーザーが利用できます。
-
QuickMLチャットインターフェース内で複数のLLMモデルをシームレスに切り替えることができます。
-
現時点では、以前のチャット会話を消去したり、新しいチャットウィンドウを開いたりすることはできません。すべての会話は同じチャットインターフェース内に残ります。
-
チャットはユーザー固有であり、あるユーザーが他のユーザーの会話にアクセスすることはできません。
-
Qwen 2.5 - 7B Vision Languageモデルを使用して、画像をアップロードしてクエリを入力し、応答を生成できます。
-
QuickMLのLLMサービングは、モデルトレーニングにユーザーのデータを使用しません。すべての応答は事前トレーニング済みデータに基づいて生成されます。
QuickMLでのLLM Servingへのアクセス
LLM Servingは、以下の手順でQuickMLからアクセスできます:
- QuickMLプラットフォームにログインします。
- Generative AIセクションで、LLM Servingを選択します。
- Chatタブに移動します。
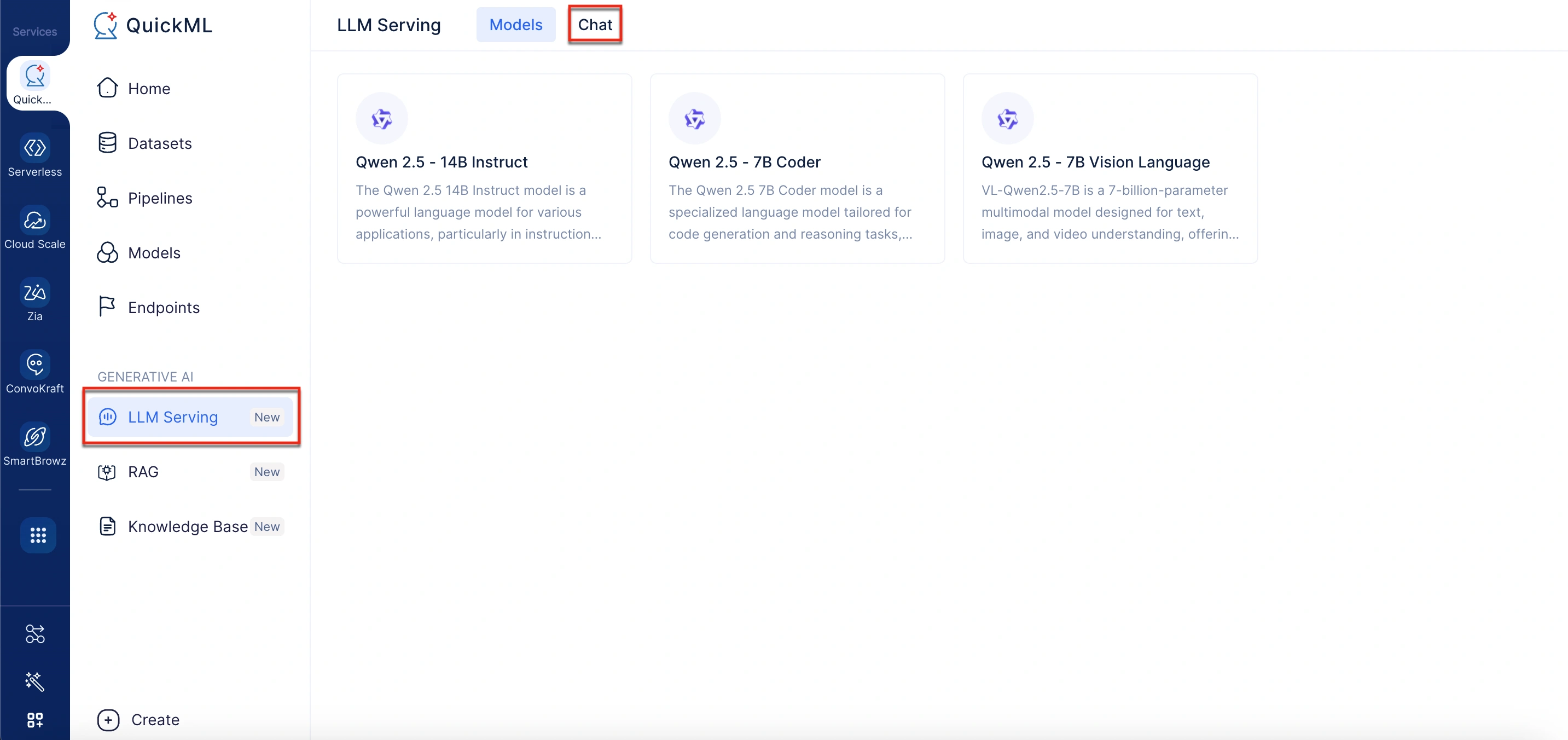
- ドロップダウンから目的のLLMモデルを選択します。
- Qwen 2.5 - 14B Instruct、Qwen 2.5 - 7B Coder、またはQwen 2.5 - 7B Vision Languageのいずれかを選択できます。
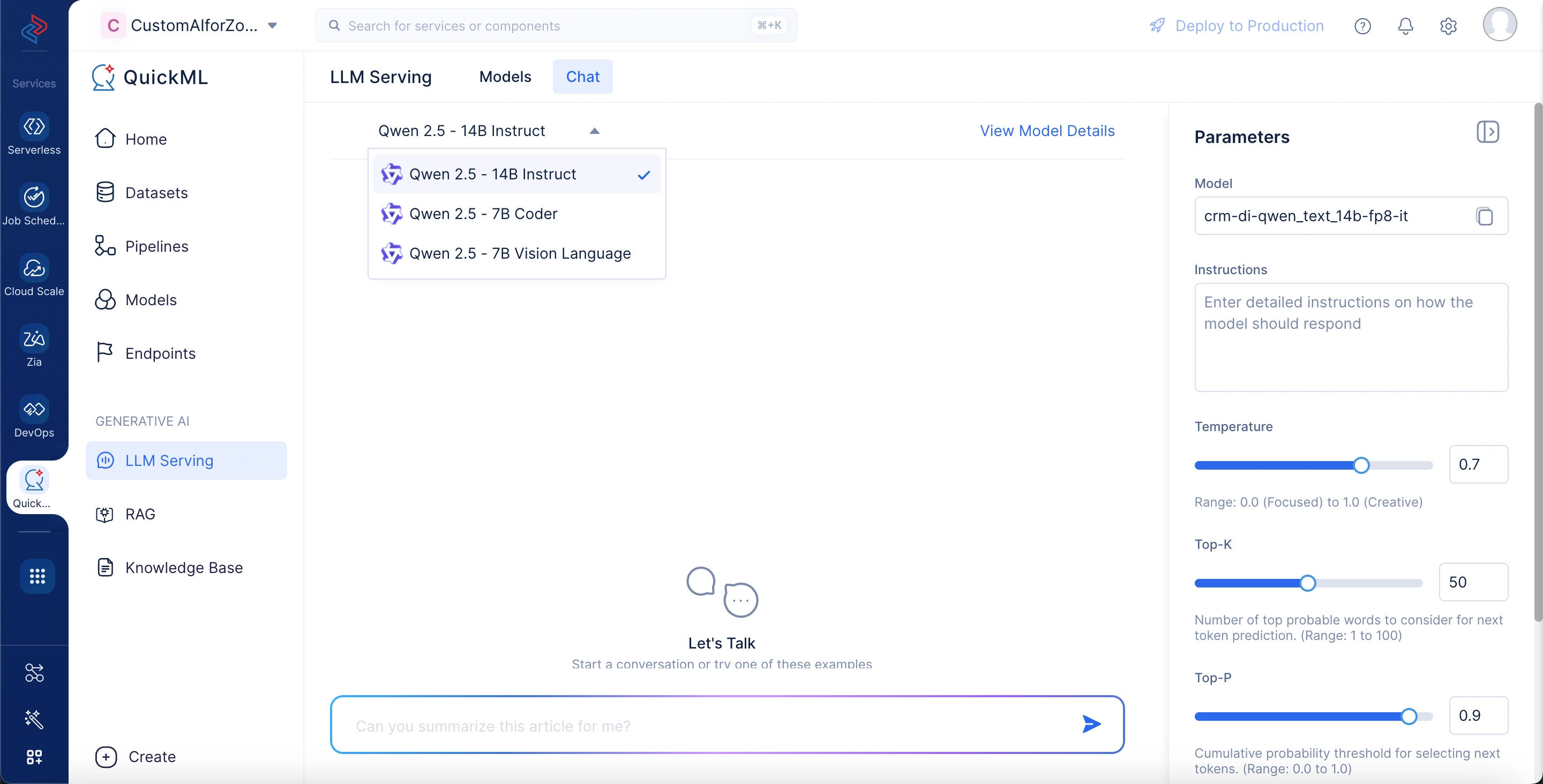
- チャットインターフェースにクエリの入力を開始します。
注意: チャットインターフェースはデフォルトのパラメータ設定に基づいて応答を生成します。ただし、要件に合わせて必要に応じて設定を調整できます。
パラメータ設定を構成するには
- Generative AIセクションで、LLM Servingタブを選択します。
- Chatタブに移動します。
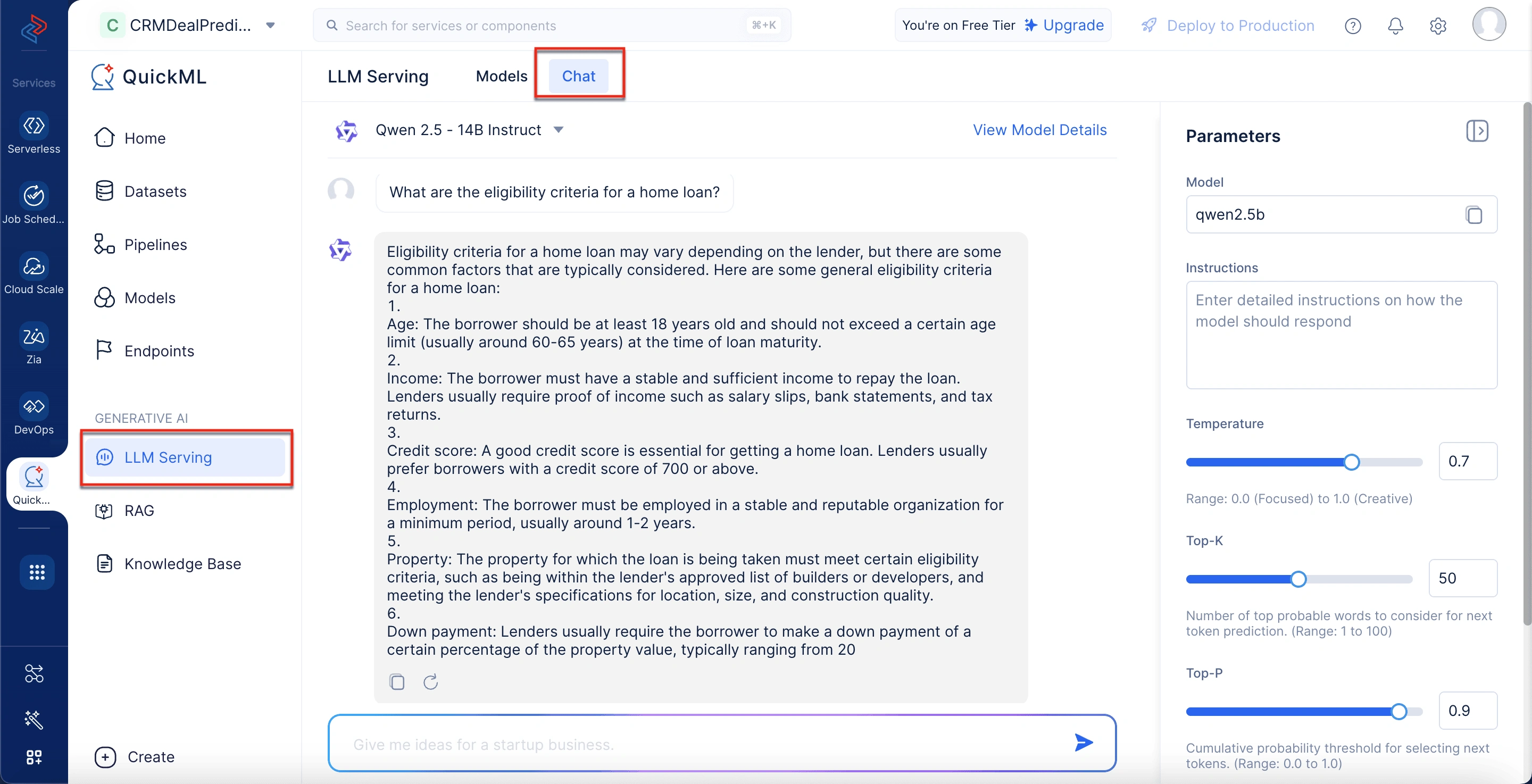
- 右パネルのParametersで、以下を設定します:
- モデルの動作方法に関する詳細な指示を入力します。
- Temperatureを調整してモデルの応答の創造性レベルを制御します。
- Top-Kフィールドで次のトークン予測に考慮される上位の確率的な単語の数を調整します。
- Top-Pフィールドで次のトークン選択の累積確率しきい値のパラメータを設定します。
- Max Tokensフィールドでモデルが応答ごとに生成するトークンの最大数を定義します。
- Saveをクリックします。
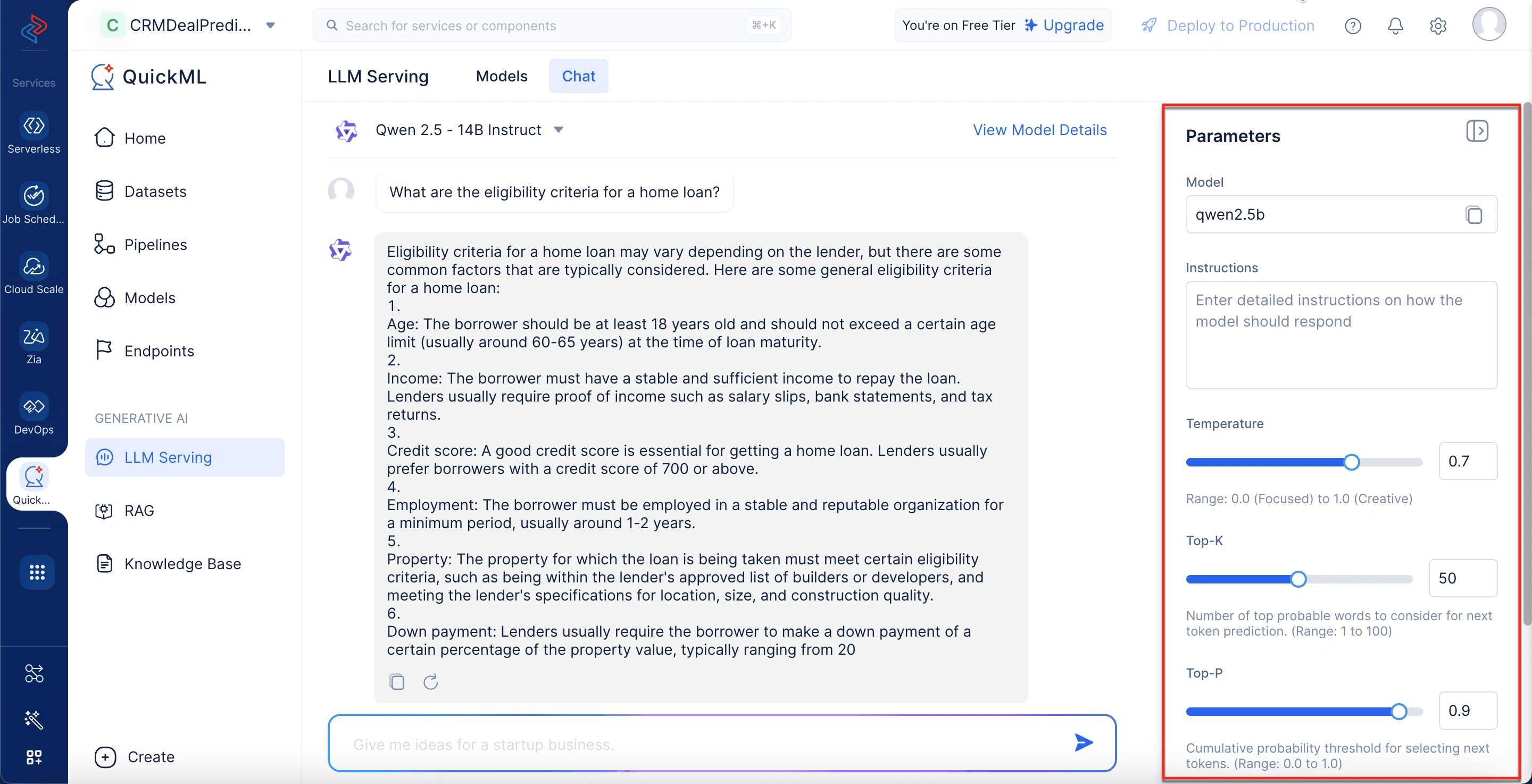
これらのパラメータを実際のビジネスシナリオでどのように設定できるかを理解するために、サンプルユースケースを考えてみましょう。
金融機関のカスタマーサポートチャットボットのパラメータ設定
ユースケース:
銀行が一般的な銀行業務の問い合わせで顧客を支援しながら、応答が正確、簡潔で、規制ガイドラインに沿っていることを保証したいと考えています。
ステップ1:最適なパフォーマンスのためのパラメータ調整
| パラメータ | 設定 | 理由 |
|---|---|---|
| Model | Qwen 2.5 -14B Instruct | 精度と効率のバランスに優れているため選択されています。 |
| Instructions | フォーマルでプロフェッショナルなトーンで応答を提供してください。銀行規制への準拠を確保してください。回答は簡潔でありながら有益にしてください。 | 顧客対応の一貫性を確保します。 |
| Temperature | 0.2 | 応答を事実に基づかせ、不要な創造性を回避します。 |
| Top-K | 20 | 単語選択を最も関連性の高い選択肢に制限し、変動性を低減します。 |
| Top-P | 0.3 | 応答を集中的で予測可能に保ち、規制コンプライアンスを確保します。 |
| Max Tokens | 200 | 明確さのために十分な詳細を維持しながら、過度に長い応答を防止します。 |
ステップ2:チャットインターフェースとの対話
パラメータが設定されると、チャットボットは使用可能になります。以下にインタラクションの例を示します:
ユーザー:“住宅ローンの資格基準は何ですか?”
チャットボットの応答(Qwen 2.5 - 14B Instruct、調整済みパラメータ使用):住宅ローンの資格基準には通常、借り手のローン返済能力を確保するためのいくつかの主要な要素が含まれます。これらの基準には一般的に以下が含まれます:
- 年齢:借り手はローン満期時に通常21歳から65歳の特定の年齢範囲内である必要があります。
- 収入:ローンの返済能力を証明するために、安定した検証可能な収入が必要です。貸し手は給与明細、銀行取引明細書、または確定申告書による収入の証明を要求する場合があります。
- クレジットスコア:借り手の信用力と返済履歴を反映するため、良好なクレジットスコアが不可欠です。
- 雇用:借り手は安定した仕事に就いているか、一貫したビジネス収入があるべきです。
- ローン対価値比率(LTV):この比率はローン額と物件価値を比較します。貸し手は物件の種類やその他の要因に基づいて特定のLTV制限を設けています。
LLMをアプリケーションに統合する
QuickMLプラットフォーム内でLLMモデルを利用するだけでなく、提供されたエンドポイントURLを使用して独自のアプリケーションにシームレスに統合できます。これにより、企業はカスタマーサポートボット、コンテンツ自動化ツール、データ分析アプリケーションなど、さまざまなビジネスプロセスにAI搭載の応答を組み込むことができます。
安全で効率的な統合を実現するため、QuickMLはアクセストークン生成のためのOAuthベースの認証をサポートしています。OAuthアプリケーションの種類とアクセストークンの生成・管理に必要な手順の詳細については、このドキュメントを参照してください。
エンドポイントURLを取得するには
- QuickML内のGenerative AIセクションに移動します。
- LLM Servingタブを選択します。
- Modelsタブで、目的のモデルを選択します。
- Model Detailsポップアップウィンドウで、API DetailsセクションまでスクロールしてエンドポイントURLを取得します。
最終更新日 2026-03-30 13:40:30 +0530 IST
Yes
No
Send your feedback to us