データプロファイラーとビューアー
データプロファイリングとは?
データプロファイリングとは、生データをレビューし、その構造、内容、相互関係を理解し、分析的な洞察の機会を特定するプロセスです。
データ前処理の実行、データ可視化の実行、データ品質スコアの改善において重要です。また、使用されているデータに関する全体的なインテリジェンスを提供することで、分析の改善にも役立ちます。
データプロファイリングの活用例:
- データ前処理: 欠損値、ユニーク値と重複値、一貫性のないデータフォーマットを特定し、分析のためのデータのクリーンアップと準備に役立ちます。
- データ可視化: データプロファイリングにより、データの実際の分布を理解し、外れ値を特定できるため、より正確で有益なデータ可視化を作成できます。
- データ品質スコアの改善: データ品質の問題を特定して修正することで、データプロファイリングはさらなる分析のためのデータの信頼性向上に役立ちます。
データプロファイリングには、以下のような多様な活動が含まれます:
- 数値カラムの最小値、最大値、平均値などの統計情報の収集
- データ型の収集とデータ内の繰り返しパターンの特定
- データの冗長性と品質の把握
- 表形式データのテーブル間分析の実施
QuickMLにおけるデータプロファイリング
QuickMLのデータセットモジュールにアップロードされたデータは、自動的にデータプロファイリングセクションを通過し、データに関する豊富な理解と価値ある洞察を提供します。
-
レコード数、ユニーク値とパーセンテージ: QuickMLは、データの各カラムにおけるユニーク値と重複値の数、およびそれぞれの合計に対するパーセンテージを検出し、行とカラムの効率的な更新に活用できます。
-
データ型と可視化: QuickMLデータプロファイラーは、データセット内の各特徴量のデータ型を正確に識別し、データに関する明確な洞察を得るために分布を可視化します。
-
欠損値: QuickMLデータプロファイラーは、空白値やnull値などの欠損値の数とパーセンテージを取得し、データサイエンティストが適切な値を設定するのに役立ちます。
-
統計情報: QuickMLデータプロファイラーは、数値カラムとカテゴリカラムに対して以下の統計データを生成します:
| 数値カラム | 合計、最小値、最大値、平均値、中央値、標準偏差、分散、低・中・高パーセンタイル | カテゴリカラム | ユニーク値、重複値 |
|---|
-
データセットバージョニングと品質スコア QuickMLは、同じデータの複数バージョンをプロファイリングし、各バージョンの品質スコアを生成できます。データプロファイルは、データセット詳細ページのバージョンオプションを使用していつでも表示できます。
-
相関ヒートマップ データプロファイラーは、データセットのすべてのバージョンに対して相関ヒートマップを生成し、特徴量間の相互関係と、それらが互いにおよびターゲット特徴量とどの程度関連しているかを可視化します。

QuickMLにおけるデータビューアー
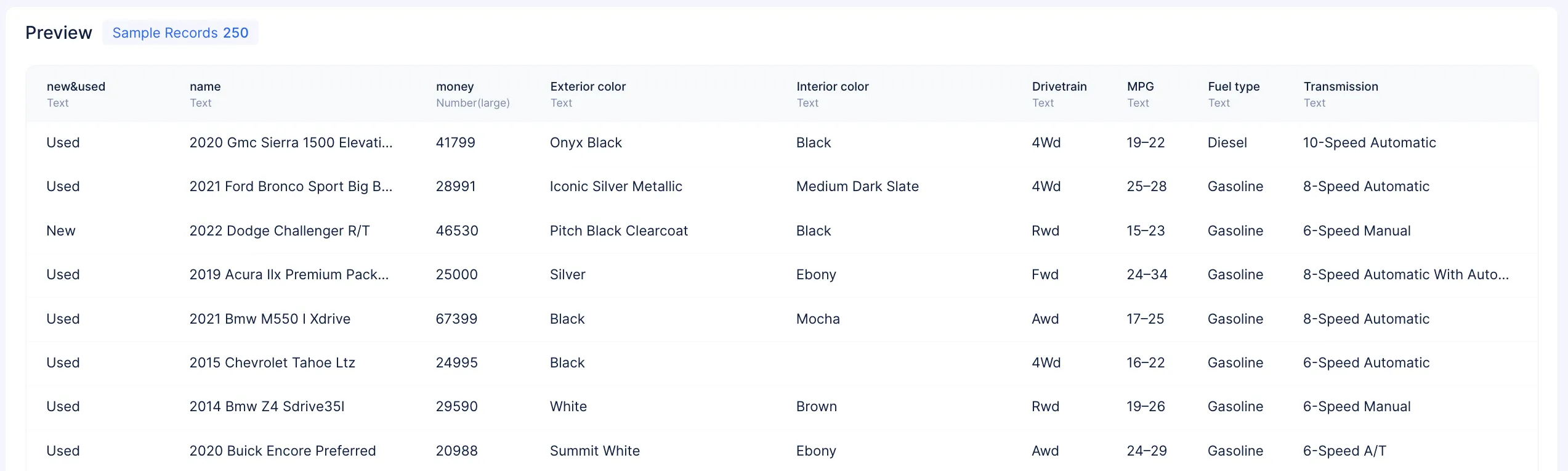
データセット詳細ページでは、元のデータセットから250レコードをサンプリングしてデータプレビューが生成され、各特徴量のデータ型を特定するのに役立ちます。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us