データ変換
データ変換とは、データをあるフォーマットや構造から別のフォーマットや構造に変換するプロセスです。
-
日時変換
日付を含むカラムから、日付、年、月などの日時特徴量を抽出するために使用します。
ユースケース1: 小売企業が製品の売上を時系列で追跡したい場合。日時変換を使用して、売上トランザクションのリストから日付、月、年を抽出できます。
ユースケース2: 運送会社が、過去の配送リストから日付、時刻、場所を抽出して配送ルートを最適化するためにDateTime変換を使用できます。
入力サンプル:
dt 2021-11-29 11:52:59 出力サンプル:
dt_day_of_week 1 dt_date_no 29 dt_year_no 2021 dt_month_no 11 dt_business_day 1 dt_week_no_year 48 dt_day_of_year 333 dt_AM_PM AM dt_quarter_year 4 -
メール変換
メールアドレスを含むカラムから、ユーザー名、ドメイン、サフィックスなどの特徴量を抽出するために使用します。
ユースケース1: 営業チームが、メールアドレスのリストからユーザー名とドメイン名を抽出し、見込み顧客へのメールアウトリーチをパーソナライズできます。
ユースケース2: フィッシングメールを特定するために、セキュリティチームは不審とフラグ付けされたメールアドレスのリストからドメイン名やサフィックスなどの特徴量が必要です。
入力サンプル:
mail abc@zylker.com 出力サンプル:
mail_first mail_middle mail_last abc zylker com -
データ抽出
データ抽出コンポーネントは、正規表現パターンを使用してテキストカラムから情報を取得します。これらのパターンには、さまざまな日付形式、メールアドレス、テキストカラムに埋め込まれた数値などが含まれます。
例:
車価格予測データセットで、名前カラムから車の製造年を抽出するために、同じカラムにPOSIX正規表現パターン /d{4} を適用します。POSIX正規表現パターンの例:
- 日付形式: \d{4}-\d{2}-\d{2}
- メール: [a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+
- 数値: \d+
-
Format
ユーザーが選択した関数に基づいてデータセットのカラム値を変更するために使用します。カラムのデータ型に基づいて関数が表示されます。
例:
患者データセットで、絶対値関数を使用してageカラムをフォーマットします。ageカラムには負の値がなくなります。 -
Group By
1つ以上のカラムの値に基づいて行をグループに分割するために使用します。カラムに対して少なくとも1つの集計関数を指定することが必須です。ユーザーはHAVING条件を設定してグループ化されたデータセットをフィルタリングすることもできます。
例:
例:従業員給与データセットで、部門ごとにデータをグループ化して各部門に支払われた給与を合計できます。これにより、各部門の給与総支出を確認できます。HAVINGセクションでは、これらのグループをフィルタリングして、給与総額が50,000を超える部門のみを含めることができます。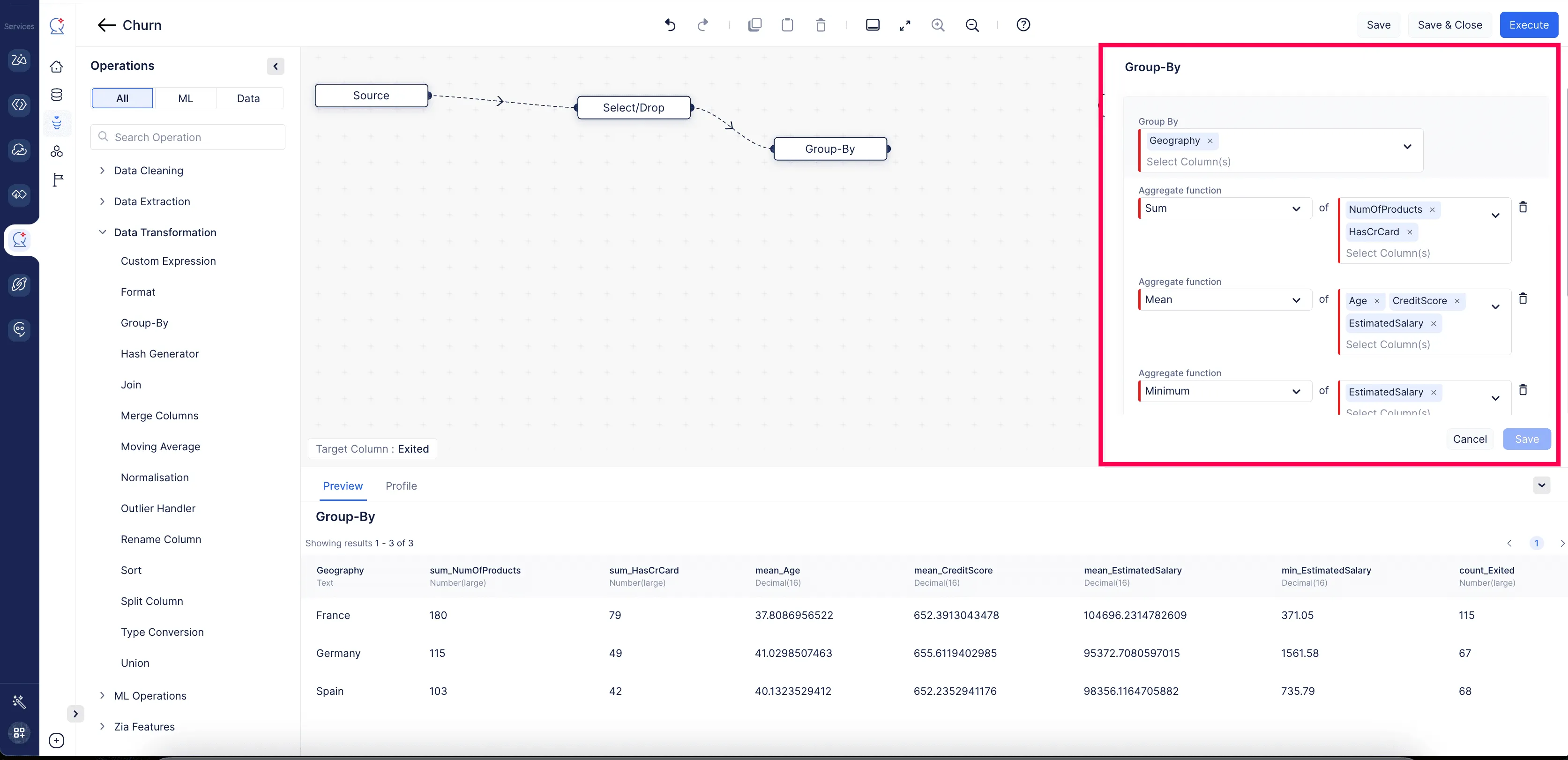
-
Hash Generator
データセット内の1つまたは複数のカラムをハッシュ化するために使用します。ハッシュの生成後、ソースカラムをドロップすることもできます。
-
Join
両方のテーブルの主キーカラムに基づいて、2つのデータセットを1つのデータセットに結合するために使用します。Left、Right、Inner、Outer結合を実行できます。
注意 : このステージではデータセットノードの選択が必要です。
例: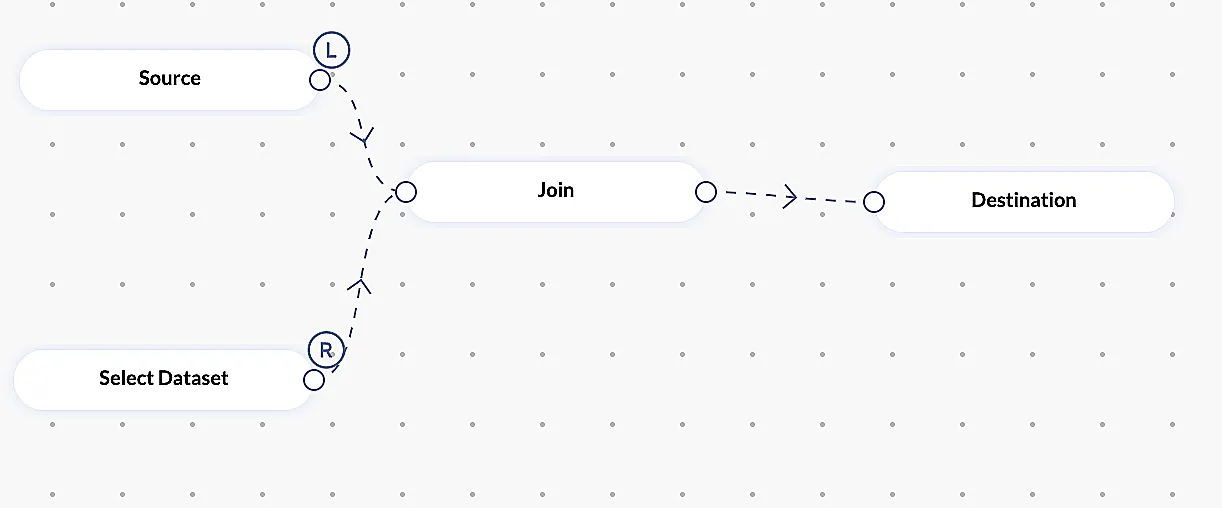
-
Merge Column
ユーザーが指定したセパレーターを使用して、2つ以上のカラムを1つのカラムにマージするために使用します。マージ操作の実行後、ソースカラムをドロップすることもできます。
例:
乗客データセットで、スペースセパレーターを使用してfirst_name、middle_name、last_nameをNameカラムとして結合できます。 -
Normalization
正規化は、異なるスケールや単位の変数をスケーリングして比較するための統計的手法です。このノードは、2つ以上のカラムを正規化するために使用します。
-
Outlier Handler
外れ値とは、データの正規分布から外れるデータポイントのことで、データ分析の結果を歪め、誤った結論につながる可能性があります。Outlier Handlerは、データセットから外れ値を削除するか、データ内の各カラムの上限値、平均値、中央値などのより合理的な値で置き換えるために使用できます。
-
Sort
カラムのセットに基づいてデータセットをソートするために使用します。ソート順序も選択できます。
-
Split Column
ユーザーが指定したセパレーターに基づいて、1つのカラムを2つ以上のカラムに分割するために使用します。出力カラムの数は、ユーザーが指定した出力名に基づいて決定されます。
例:
乗客データセットで、出力カラムテキストボックスにfirst_name、middle_name、last_nameを指定して、Nameカラムを3つのカラムに分割できます。 -
文字列変換
テキストを含むカラムから単語の埋め込み表現を生成するために使用します。
ユースケース1: ユーザーに推奨コンテンツを提供するために、ソーシャルメディア企業が文字列変換を使用して、ユーザーが「いいね」や共有した投稿のテキストから単語の埋め込み表現を取得できます。
ユースケース2: カスタマーサポートチームが、チケットのテキストから文字列変換で生成された単語の埋め込み表現を使用して、顧客が経験している一般的な問題を特定し、カスタマーサポートチケットを分類できます。
-
Type Conversion
カラムの型をユーザーが指定したデータ型に変換するために使用します。設定のOn Errorオプションを使用して、エラーが発生した場合の結果データセットの処理方法を指定できます。Throwはエラー発生時に例外をスローして実行を停止し、Nullifyはエラーが発生した特定のレコードについて元のレコードを返します。
-
URL変換
URLを含むカラムから、sub_domain、domain、suffixなどの特徴量を抽出するために使用します。
ユースケース1: マーケティングチームが、ターゲット市場で最も頻繁にアクセスされるWebサイトを特定する必要があります。URL変換を使用して、自社WebサイトのユーザーがクリックしたURLのリストからドメイン名を抽出できます。
ユースケース2: 不正検知チームが、URL変換を使用して、不審とフラグ付けされたURLのリストから悪意のあるWebサイトのドメイン、サブドメイン、サフィックスのリストを特定できます。
入力サンプル:
link https://www.google.in/library?fetch=query#fragment_part 出力サンプル:
link_url_protocol https link_url_domain www.google.in link_url_path /library link_url_query fetch=query link_url_fragment fragment_part link_domain_tld in link_domain_country IN subdomain www -
Union
2つのデータセットを1つのデータセットに結合するために使用します。2つのデータセットを結合した後、重複行をドロップすることもできます。
注意: このステージではデータセットノードの選択が必要です。 -
Windowing
数値カラムでウィンドウ平均操作を実行するために使用します。ユーザーは0より大きいウィンドウ範囲を指定する必要があります。移動平均は、時系列分析および時系列予測で使用されるシンプルで一般的な平滑化手法です。これは時系列データセットに使用できます。
-
Fill Columns
ユーザーが設定した条件に基づいて、特定のカラムの値を変更するために使用します。設定で条件が指定されていない場合、そのカラムのすべての値がユーザー指定の値またはメソッドで置き換えられます。
例:
名前、年齢、住所、投票資格などの患者情報を含む国の人口データセットの場合、18歳以上のすべての人の「eligible for vote」カラムを「yes」に更新できます。 -
Rename
データセット内の任意のカラム名を変更するために使用します。
例:
name、age、address、eligible_for_voteなどのカラムを含むデータセットの場合、eligible_for_voteカラムをvoter_eligibilityにリネームできます。 -
Custom Expression
ユーザーがカスタム式を作成してデータセットの値を操作または計算できます。カスタム式は、新しいカラムの導出、既存データの変換、データに基づく複雑な計算の適用に使用できます。
例:
name、age、address、salaryなどのカラムを含むデータセットの場合、月額給与から年間給与を計算するカスタム式を作成できます。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us