QuickMLにおけるデータ前処理技術
QuickMLは、主要なデータ前処理技術を3つの主要カテゴリに分けて提供しています。
- データクリーニング
- データ変換
- データセット抽出
以降のスライドに記載されているすべての操作は、パイプライン構築プロセスのステージとして利用でき、ユーザーがより優れた機械学習モデルを作成するのに役立ちます。
データクリーニングとは、データセット内の不正確、破損、不適切なフォーマット、重複、または不完全なデータを修正または削除するプロセスです。データが不正確な場合、結果やアルゴリズムは信頼性を欠きます。
-
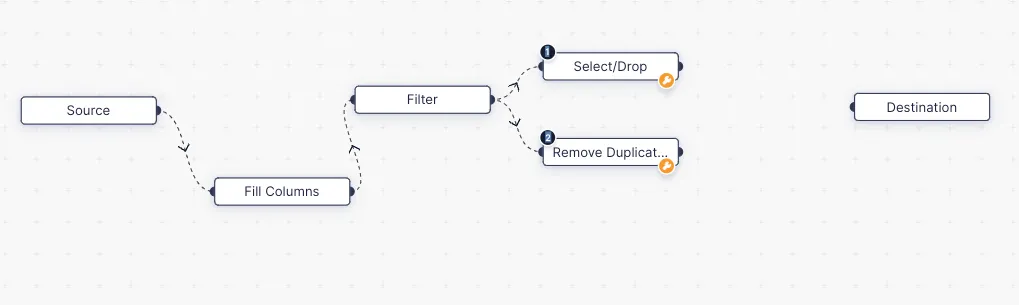
Fill Columns
特定のカラムの値を、ユーザーが設定した条件に基づいて変更するために使用します。設定で条件が指定されていない場合、そのカラムのすべての値がユーザー指定の値またはメソッドで置き換えられます。
例:
患者の名前、年齢、住所、投票資格などの詳細を含む国の人口データについて、18歳以上のすべての人の投票資格カラムを「yes」として埋めることができます。 -
Filter
設定で条件を適用して、前処理が必要なデータセットからデータを抽出するために使用します。条件に一致しないデータも前処理に使用できます。
例: -
Remove duplicates
データセット内の重複行を削除するために使用します。重複行の削除方法も制御できます。
例:
学生IDが101の重複行がインデックス1、5、7に5つある学生データセットの場合。 保持の優先オプション:
First - 出力データセットにはインデックス1の行のみが残り、インデックス5と7の行は削除されます。
Last - 出力データセットにはインデックス7の行のみが残り、インデックス1と5の行は削除されます。
None - 出力データセットには重複行がなくなり、インデックス1、5、7の行はすべて削除されます。 -
Select or Drop
データセットのカラムの選択またはドロップの両方を行うために使用します。データセットから2つのカラムのみが必要な場合は、ドロップダウンから必要な2つのカラムを選択し、select操作を選択します。カラムのドロップには、drop操作を選択します。
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us