カスタムコード
カスタムコード操作
QuickMLパイプラインのカスタムコード操作により、開発者はモデルトレーニングプロセスに独自のロジックを組み込むことができます。テンプレートで提供されるPythonクラスを実装することで、データの変換方法、特徴量の処理方法、さらには使用する機械学習アルゴリズムをカスタマイズできます。
この機能は、3つの異なるコンポーネントに分かれています:
- Custom Data Transformation
- Custom ML Transformation
- Custom Algorithm
各コンポーネントは機械学習ライフサイクルにおいて固有の役割を果たし、ユーザーが実装すべき事前定義されたメソッドシグネチャを備えています。
Custom Data Transformation
Custom Data Transformationは、カスタムロジックを使用して、データクリーニング、変換、生データの抽出などの操作を実行し、データを最適化するために使用されます。カラムの削除、フォーマット変換、スケーリングなど、モデルトレーニングと予測の両方のステージで一貫性を保つ必要がある前処理ステップに特に有用です。カスタマイズされたコードは、データ前処理中の複雑な要件を処理し、transform() メソッドで実装されます。このメソッドはDataFrameオブジェクトを受け取って返し、トレーニングと推論の両方で実行されます。
以下のサンプルコードでは、Custom Data Transformationノードがモデルトレーニングまたは予測に使用される前にデータを前処理します。データセットから「Glucose」カラムを削除し、無関係またはバイアスの原因となる可能性のある特徴量がモデルの学習や予測に影響を与えないようにします。
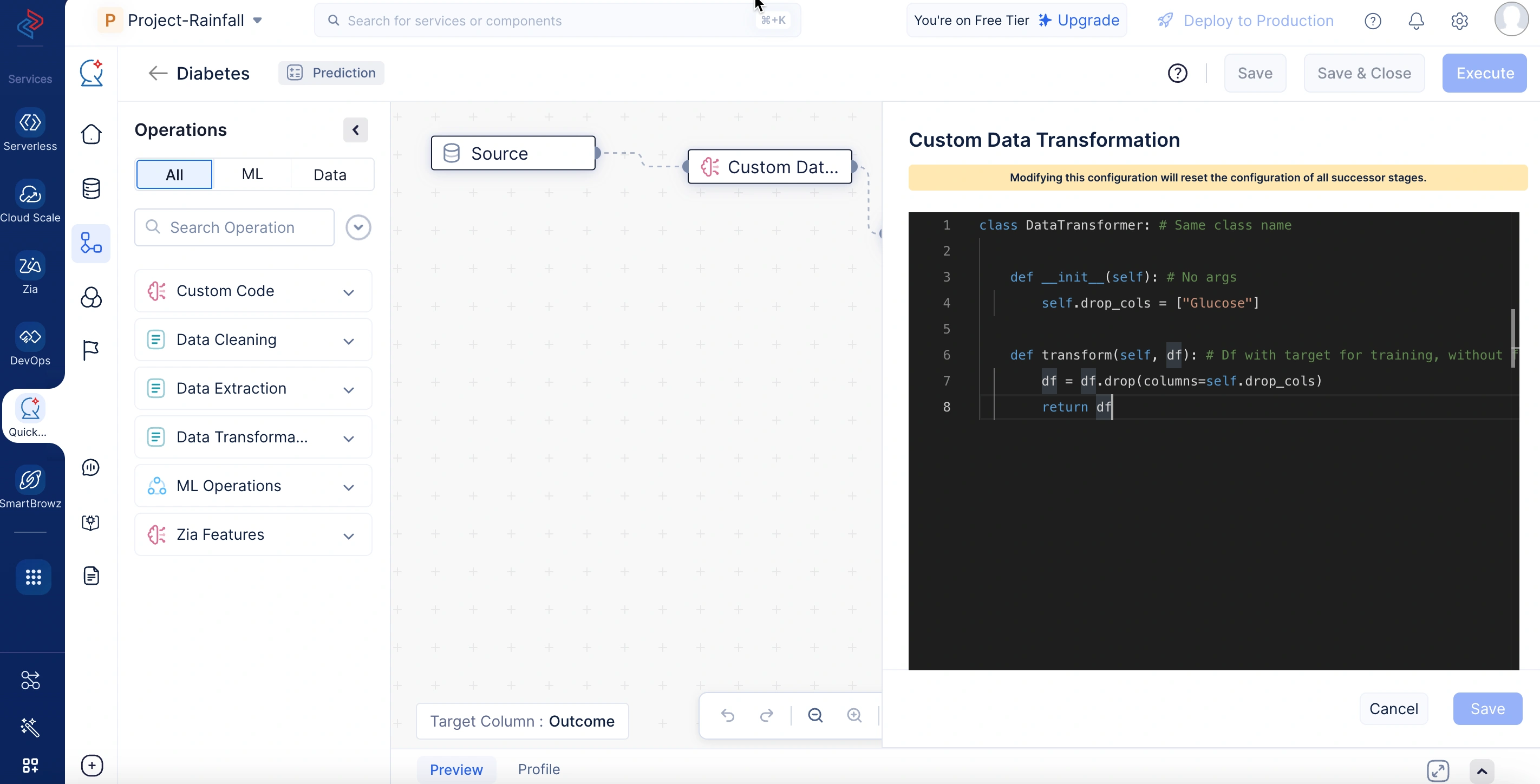
Custom ML Transformation
MLモデル開発ライフサイクルにおいて、Custom ML Transformation操作は、カスタムロジックを使用してユースケースに特化した特徴量エンジニアリングタスクを実行する前処理ステップで使用されます。これらの変換は、欠損値補完、特徴量エンコーディング、正規化など、トレーニングデータから学習し、予測時に同じ変換を一貫して適用する必要がある操作の処理に最適です。これは、トレーニングデータから必要なパラメータを学習するfit() メソッドと、学習したパラメータを適用して新しいデータを前処理するtransform() メソッドによって実現されます。両方のメソッドはDataFrameオブジェクトを受け取って返します。
以下のサンプルコードでは、Custom ML Transformationノードがデータ前処理ステップの一環として欠損値補完を処理します。トレーニング中に各数値カラムの平均値を計算して保存します。その後、予測または推論時に、保存された平均値を使用してそれらのカラムの欠損値を補完し、トレーニングフェーズと予測フェーズ間の一貫性を確保します。
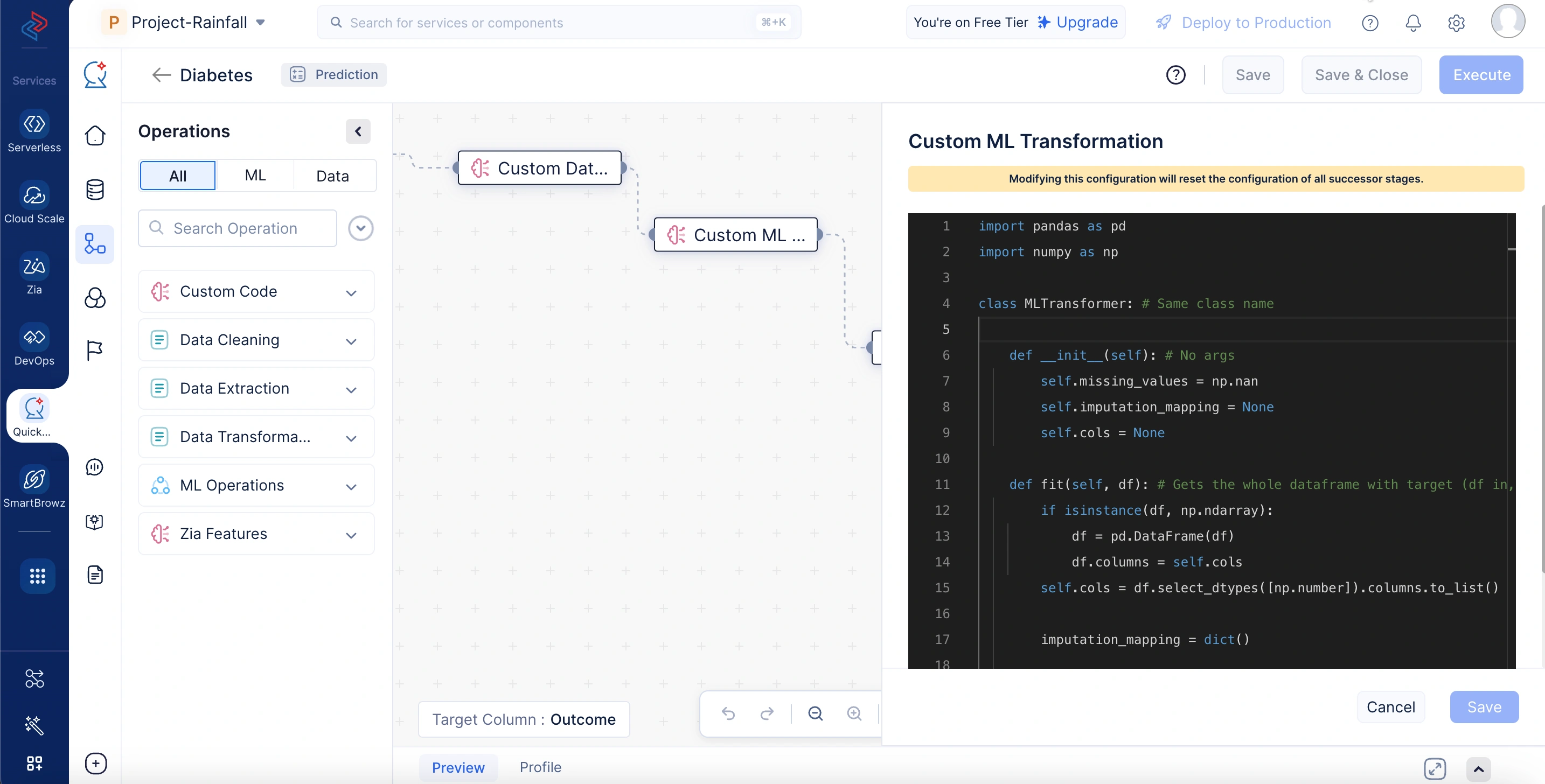
Custom Algorithm
カスタムMLモデルを組み込み、そのトレーニング、予測、評価ロジックを定義できます。これにより、使用するアルゴリズムとそのパフォーマンス評価方法を完全に制御できます。fit、predict、get_evaluation_metrics関数があります。fitはモデルトレーニング時に実行され、predictは予測時に実行され、get_evaluation_metricsはモデルトレーニング後に評価指標を生成するために実行されます。get_evaluation_metrics() メソッドから返される指標は、モデル詳細ページの評価指標セクションに表示されます。
Custom Algorithm操作は、特定のビジネスユースケースに合わせたカスタムアルゴリズムの適用を指します。ユーザーがカスタムMLモデルを組み込み、独自のトレーニング、予測、評価ロジックを定義できます。このアプローチにより、使用するアルゴリズムとそのパフォーマンス評価方法を完全に制御できます。標準的な事前定義アルゴリズムの拡張として捉えることができ、ドメイン固有のルールを使用した独自のモデリング問題の解決を可能にします。
この操作には3つの主要なメソッドが含まれます:
- fit() — モデルトレーニング中に実行され、データから学習します
- predict() — 予測時に実行され、出力を生成します
- get_evaluation_metrics() — トレーニング後に実行され、評価指標を計算して返します
以下のサンプルコードでは、Custom Algorithmノードがカスタムアルゴリズムを使用してMLモデルを構築します。LightGBM分類器を使用して、入力データセットをトレーニングセットとテストセットに分割し、トレーニングデータでモデルをトレーニングして、トレーニング済みモデルインスタンスを保存します。予測時には、トレーニング済みモデルを使用して未知のデータに対する出力を生成します。トレーニング後、テストデータに対して精度、適合率、再現率、F1スコアの指標を使用してモデルを評価し、パフォーマンス分析のために辞書として返します。
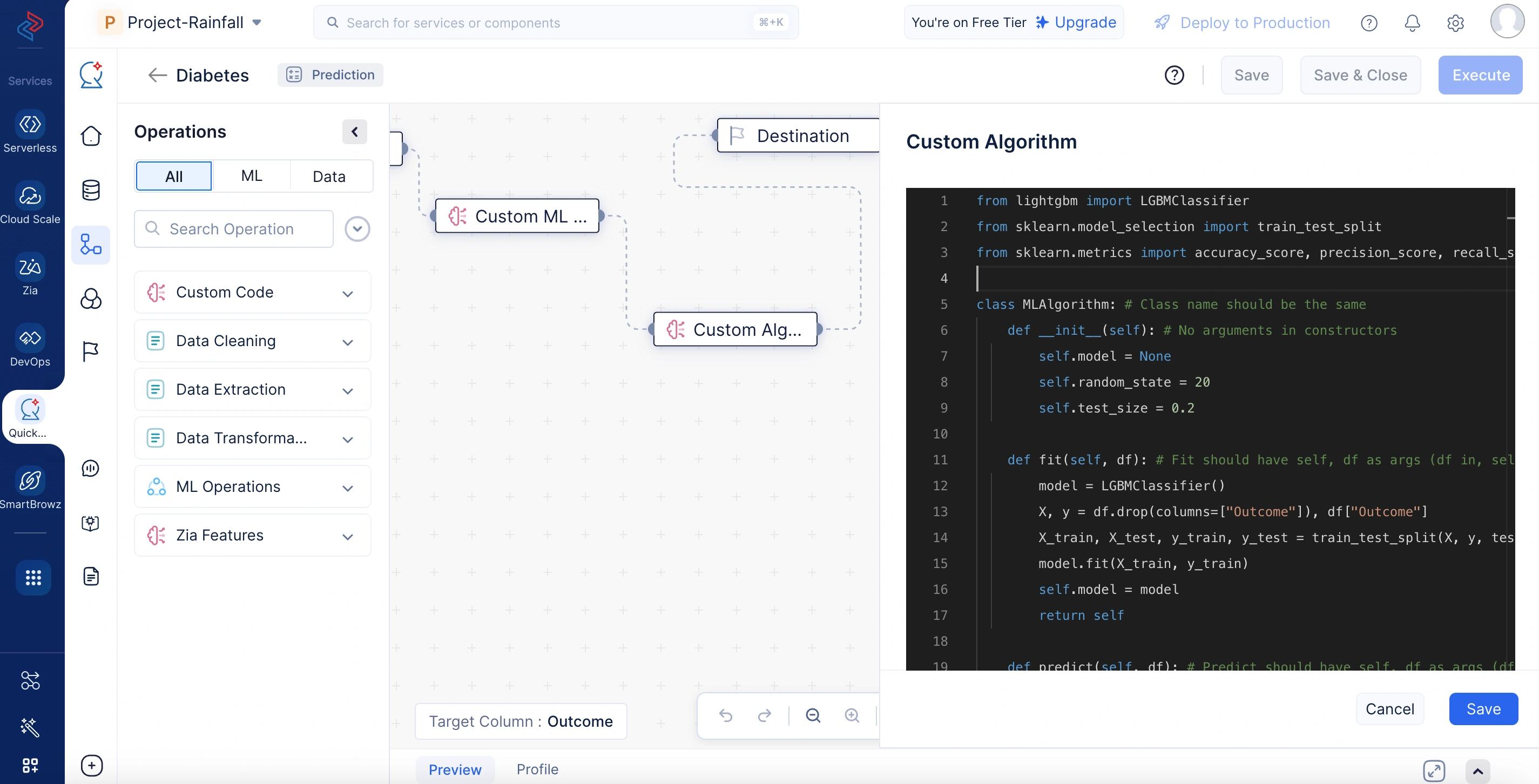
importがサポートされているPyライブラリの一覧:
numpy, scipy, pandas, xgboost, catboost, lightgbm, sklearn, tld, patsy, tensorflow, statsmodels, tldextract, huggingface_hub, sentence_transformers, imbalanced_learn, hyperopt, shap, lime, transformers, pmdarima, lightfm, LibRecommender, subseq
最終更新日 2026-03-05 11:43:24 +0530 IST
Yes
No
Send your feedback to us