Data Storeエクスポート
はじめに
Data Storeエクスポートコマンドの一般的な構文は以下の通りです。
JSON設定ファイルの構造
Data Storeエクスポートコマンドは、入力JSON設定ファイルで定義した条件に一致する、指定したテーブルからレコードを取得します。コマンドにJSONファイルを渡さない場合、または条件を指定しない場合、デフォルトでテーブルのすべてのレコードが読み取られます。
エクスポート操作の要件を指定するサンプルJSON設定ファイルは、コマンド実行時にオプションで渡すことができ、以下に示されています。
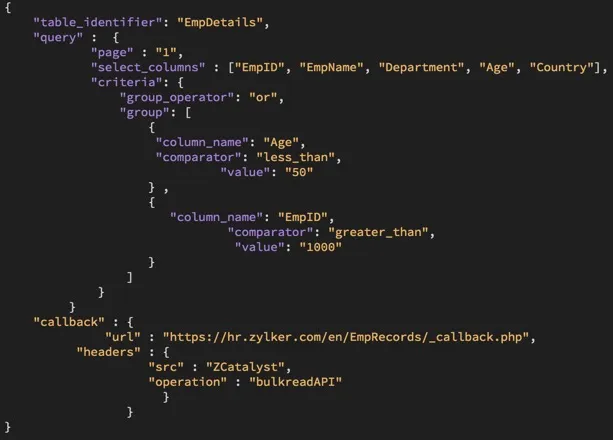
JSON設定ファイルでサポートされているパラメータは以下のように定義されています。
| 属性 | 説明 |
|---|---|
| table_identifier (String、必須) |
データをエクスポートするテーブルの一意のIDまたはテーブル名。–tableオプションを使用してテーブル識別子を渡すこともできます。 |
| query (JSON、任意) |
エクスポートジョブの条件と基準を定義するセクション |
| page (Numerical、任意) |
一括読み取りプロセスの結果として生成されるCSVファイルには、1ページに20万件のレコードが含まれます。 ページ値「1」は、クエリに一致する最初の20万件のレコードがエクスポートされることを示します。ページ値を増やすことで、後続のレコードを取得できます。 たとえば、200,001件目から400,000件目のレコードを取得する場合は、ページ値を「2」と指定する必要があります。 デフォルト値: 1 –pageオプションを使用してページ値を指定することもできます。 |
| select_columns (Array、任意) |
テーブルから取得する必要があるレコードの特定のカラム。カラムを指定しない場合、すべてのカラムが選択されて取得されます。 配列に複数のカラムを含めることができます。 |
| callback (JSON、任意) |
ジョブステータスの自動JSONレスポンスが送信されるコールバックURLのプロパティを定義するセクション |
| url (String、コールバックURLを指定する場合は必須) |
ジョブステータスが変更されるたびに、HTTP POSTメソッドを使用して自動レスポンスが送信されるURL。ジョブの詳細情報はJSONレスポンスの本文に含まれます。 CLIは実行のライブストリームと最終的なジョブステータスも表示します。 |
| headers (String、任意) |
コールバックURLへのJSONレスポンスで渡す必要があるヘッダー ヘッダーは以下のように指定する必要があります: { “{header_name_1}” : “{header_value_1}”, “{header_name_2}” : “{header_value_2}" } 以下同様です。 |
| params (String、任意) |
コールバックURLに追加する必要があるパラメータ パラメータは以下のように指定する必要があります: { “{param_name_1}” : “{param_value_1}”, “{param_name_2}” : “{param_value_2}" } 以下同様です。 |
| criteria (JSON、任意) |
レコードが取得される条件のセット。このセクションに含めるプロパティは以下の表に記載されています。 |
条件プロパティ
| 属性 | 説明 |
|---|---|
| group_operator (String、条件を指定する場合は必須) |
条件グループを結合する演算子。 サポートされている演算子: AND、OR 2つ以上の条件グループを定義する場合、ANDまたはOR演算子を使用できます。たとえば、「column1 equal value 1 AND column2 contains value 2」のような条件を、前のセクションで指定された形式で指定できます。 注意: 両方の演算子の組み合わせは使用できません。1回のコマンド実行ではANDまたはORのいずれかのみ使用できます。 |
| group (JSON、条件を指定する場合は必須) |
このセクションには最大25個の条件セットを含めることができます。サンプルJSONファイルには2つの条件セットが示されています。 注意: 1回の実行では、1つのグループ演算子を持つ1つの全体グループのみ含めることができます。 |
| column_name (String、条件を指定する場合は必須) |
条件を定義するテーブルの特定のカラム名 |
| comparator (String、条件を指定する場合は必須) |
カラム名と条件値を照合する比較演算子 サポートされている比較演算子: equal、not_equal、greater_than、greater_equal、less_than、less_equal、starts_with、ends_with、contains、not_contains、in、not_in、between、not_between 注意:
|
| value (String、条件を指定する場合は必須) |
条件として定義するレコード内の特定カラムの値 |
エクスポートジョブの処理状態
エクスポート操作には3つのジョブ処理状態があります。
- 進行中: インポートコマンドを実行するとすぐにジョブがこの状態に入ります。CLIはjob_idパラメータを表示し、JSONにコールバックURLを設定していない場合は、これを使用して後続のレスポンスのジョブ実行ステータスを手動で確認できます。
コールバックURLを設定している場合、定義した形式でjob_idを含む状態レスポンスがURLにも送信されます。 - 成功: エクスポート操作が成功した場合、Catalystはクエリに一致するレコードを含むCSVファイルをダウンロードできるダウンロードURLを提供します。Catalystでは、CLIを通じて結果ファイルをシステムに直接ダウンロードすることもできます。コールバックURLを設定している場合、このレスポンスもURLに送信されます。
- 失敗: エクスポート操作が失敗した場合、CLIは発生したエラーの詳細を表示します。コールバックURLを設定している場合、このレスポンスもURLに送信されます。
エクスポートオプション
エクスポートコマンドの実行プロセスは、各オプションについてこのセクションで詳しく説明されています。Data Storeエクスポートコマンドは以下のオプションをサポートしています。
--config <path>
–configオプションを使用すると、システム内のJSON設定ファイルのパスを定義できます。
たとえば、以下のようにエクスポート操作を実行してJSONファイルパスを渡すことができます。

CLIは自動的にジョブの実行をスケジュールし、「進行中」としてマークします。job_idとともに実行プロセスのライブストリームを表示します。
ジョブが正常に実行された場合、CLIは結果ファイルをシステムにダウンロードするよう求めます。「y」と入力し、Enterを押してダウンロードします。

結果ファイルを含むZIPファイルがプロジェクトディレクトリにダウンロードされます。

Catalystが提供するダウンロードURLを使用して、CLIで作業していないときでも結果ファイルをダウンロードできます。APIコマンドとして実行する必要があります。
CSV結果ファイルには、エクスポートジョブクエリに一致するすべてのレコードの一覧が含まれます。
--table <name|id>
--tableオプションを使用すると、レコードを読み取るテーブルのテーブル名またはテーブルIDを指定できます。
前述の通り、JSONファイルでテーブル識別子を指定しない場合、またはコマンド実行時にJSONファイルを渡さない場合は、このオプションを使用して指定する必要があります。
Catalystは、JSONファイルで指定されたテーブルよりも、オプションで指定されたテーブルを優先します。どちらにもテーブルが指定されていない場合、CLIはコマンド実行中にエラーメッセージを表示します。
たとえば、以下の方法でテーブル識別子を指定できます。
CLIはエクスポート操作を実行し、指定されたテーブルからレコードを一括読み取りし、同じ方法で結果を提供します。
--page <page>
JSONパラメータのセクションで説明したように、テーブルから取得するレコードの範囲を示すページ値を指定できます。
たとえば、以下のコマンドを実行して200,001件目から400,000件目のレコードを取得できます。
--production
--productionオプションを使用すると、Catalystプロジェクトの本番環境でエクスポート操作を直接実行できます。このオプションを使用すると、本番環境のテーブルからレコードが一括読み取りされます。
最終更新日 2026-02-23 18:09:41 +0530 IST
Yes
No
Send your feedback to us