Implementación
Esta sección solo cubre el trabajo con OCR en la consola de Catalyst. Consulta las secciones de documentación del SDK y la API para implementar Zia OCR en el código de tu aplicación.
Como se mencionó anteriormente, puedes acceder a las plantillas de código que te permitirán integrar OCR en tu aplicación de Catalyst desde la consola, y también probar la función subiendo imágenes y documentos de muestra y obteniendo el texto reconocido.
Acceder a Optical Character Recognition
Para acceder a Optical Character Recognition en tu consola de Catalyst:
- Navega a Zia services en el panel izquierdo de la consola de Catalyst y haz clic en OCR para acceder a la función.
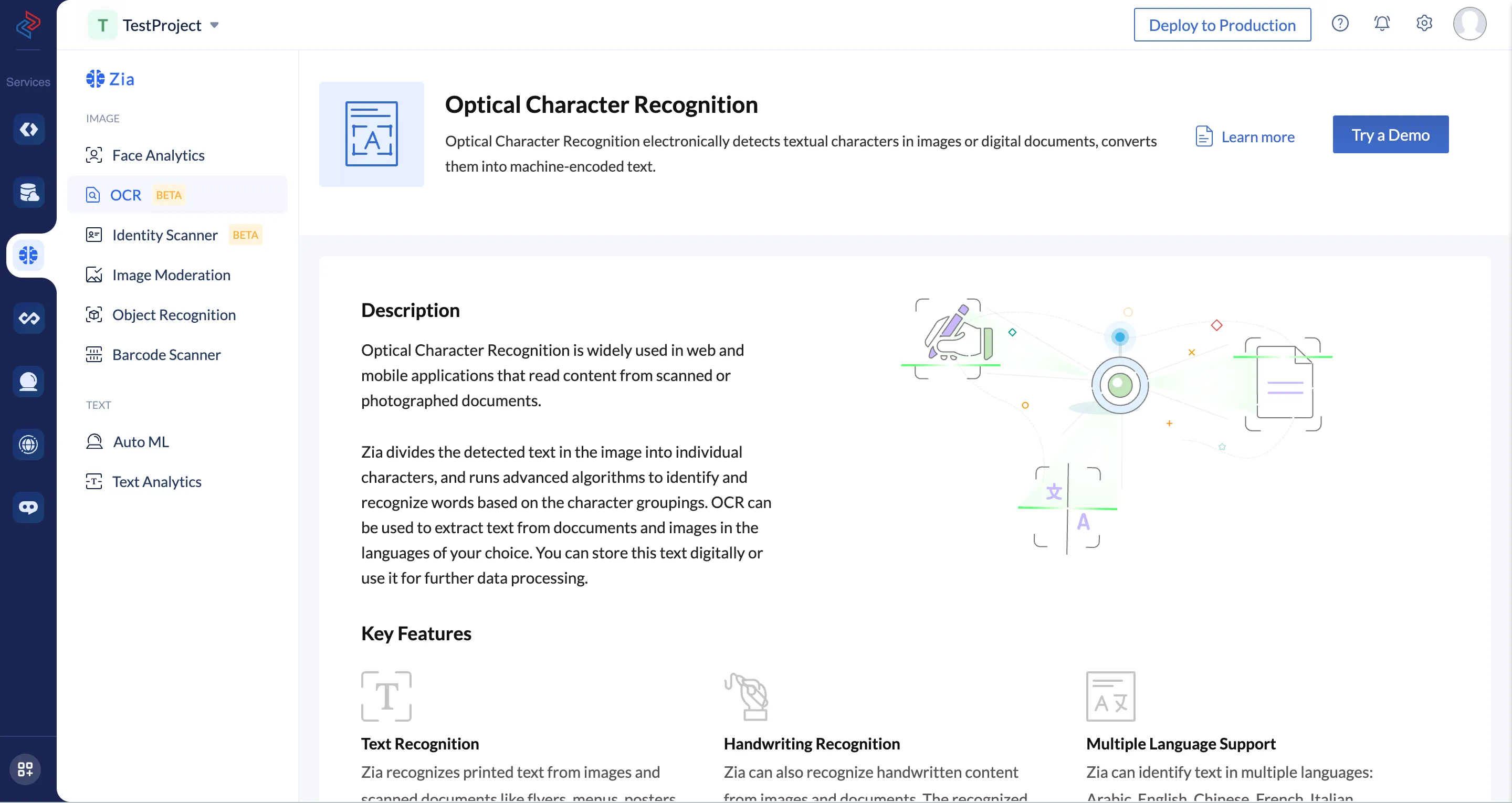
- Haz clic en Try a Demo en la página de la función Optical Character Recognition.
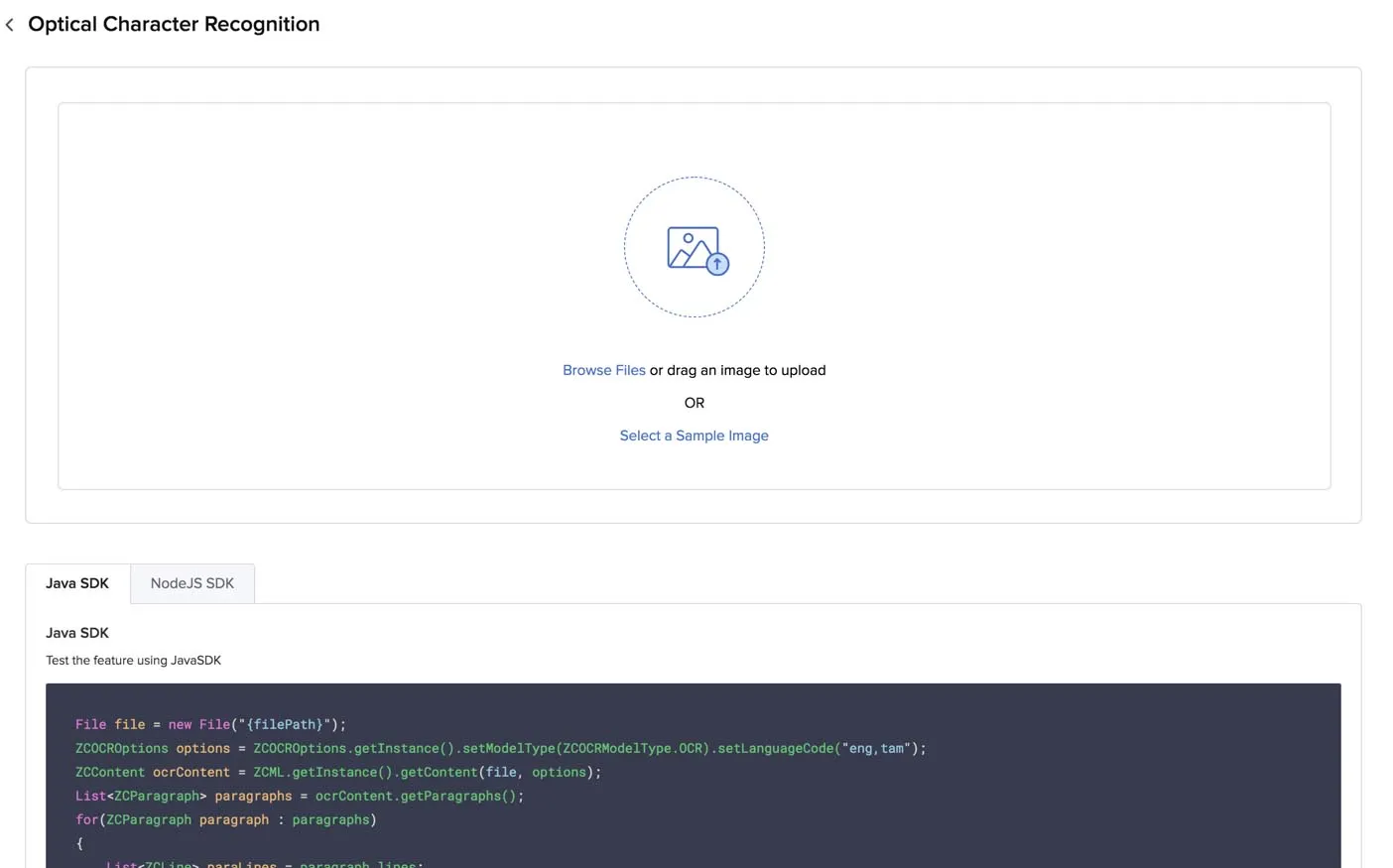
Probar Optical Character Recognition en la consola de Catalyst
Puedes probar OCR seleccionando una imagen o archivo PDF de muestra de Catalyst o subiendo tu propio archivo.
Para procesar un archivo de muestra y obtener los resultados:
- Haz clic en Select a Sample Image en el cuadro.
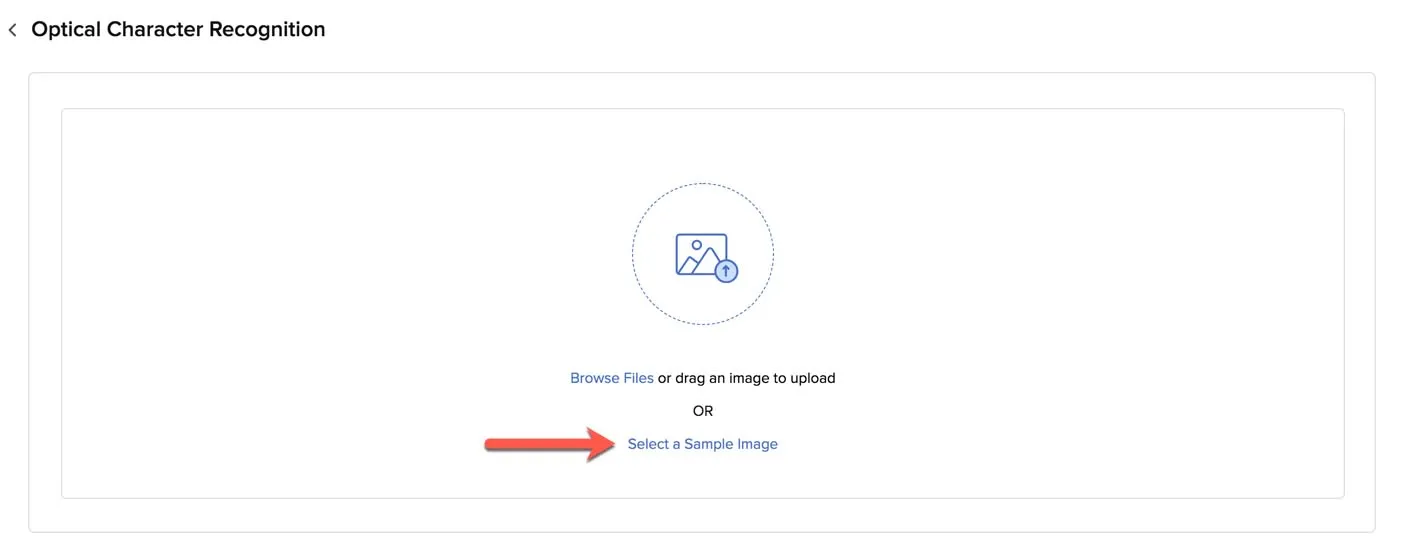
- Selecciona una imagen o un archivo PDF de las muestras proporcionadas.

OCR procesará el archivo, detectará e identificará el contenido textual en él. Dado que es un archivo de muestra, el idioma del texto y el tipo de modelo son proporcionados por Catalyst automáticamente.
El texto reconocido se muestra en la consola en la sección Result.
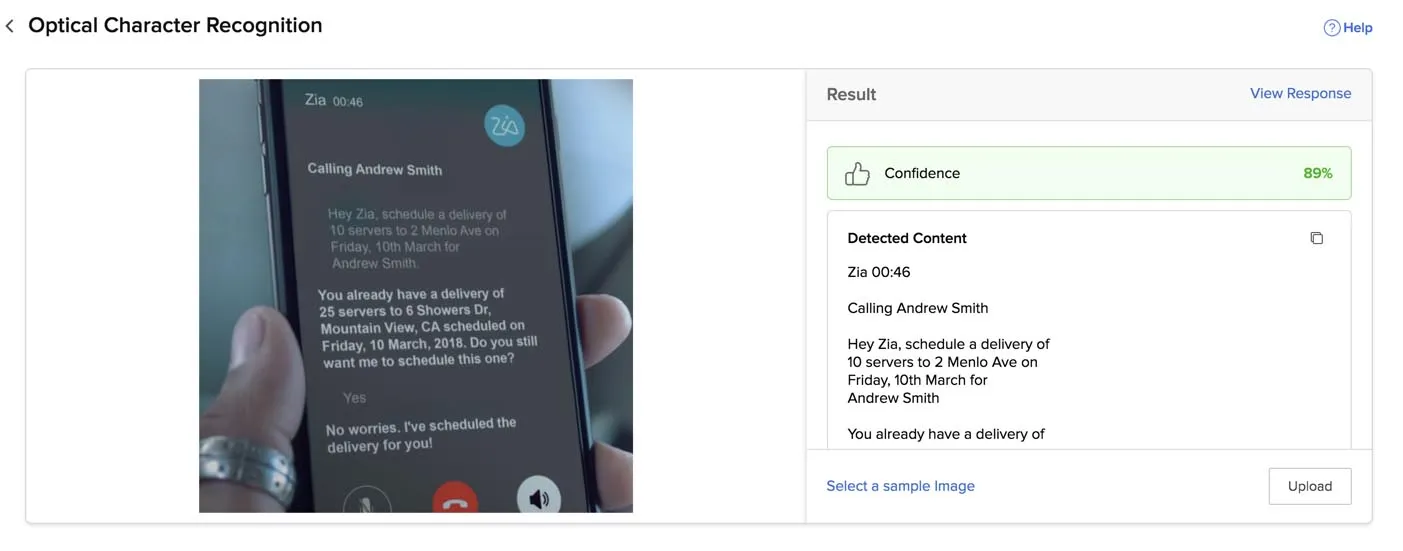
Puedes ver la respuesta JSON haciendo clic en View Response.
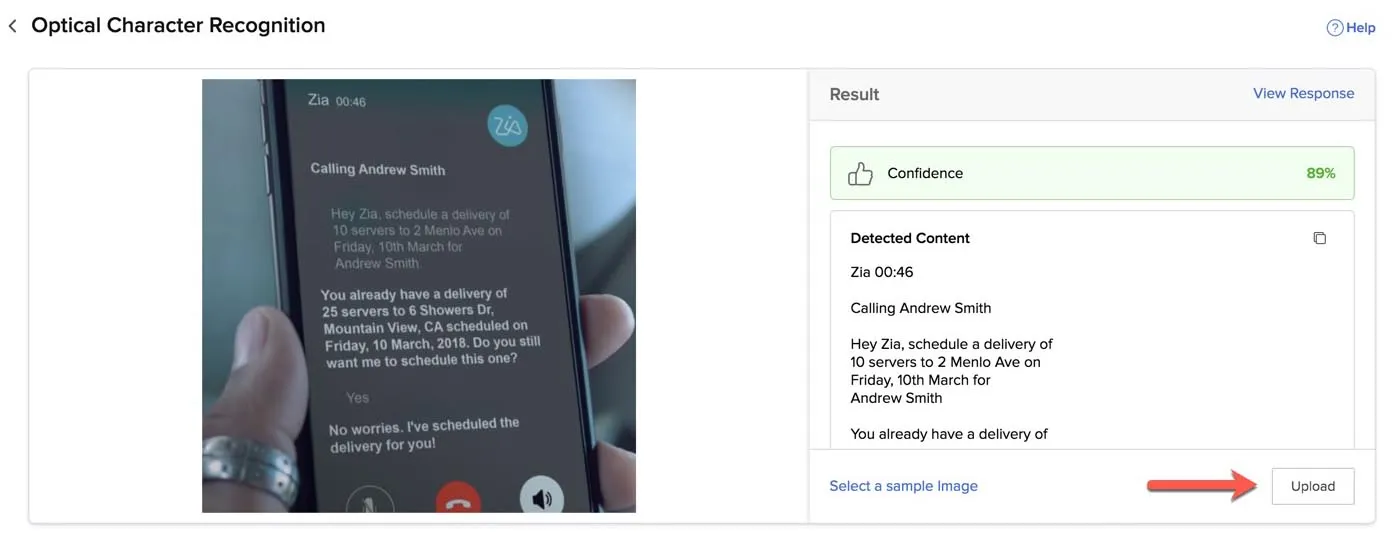
Para subir tu propia imagen o archivo PDF con texto:
-
Haz clic en Upload en la sección Result.
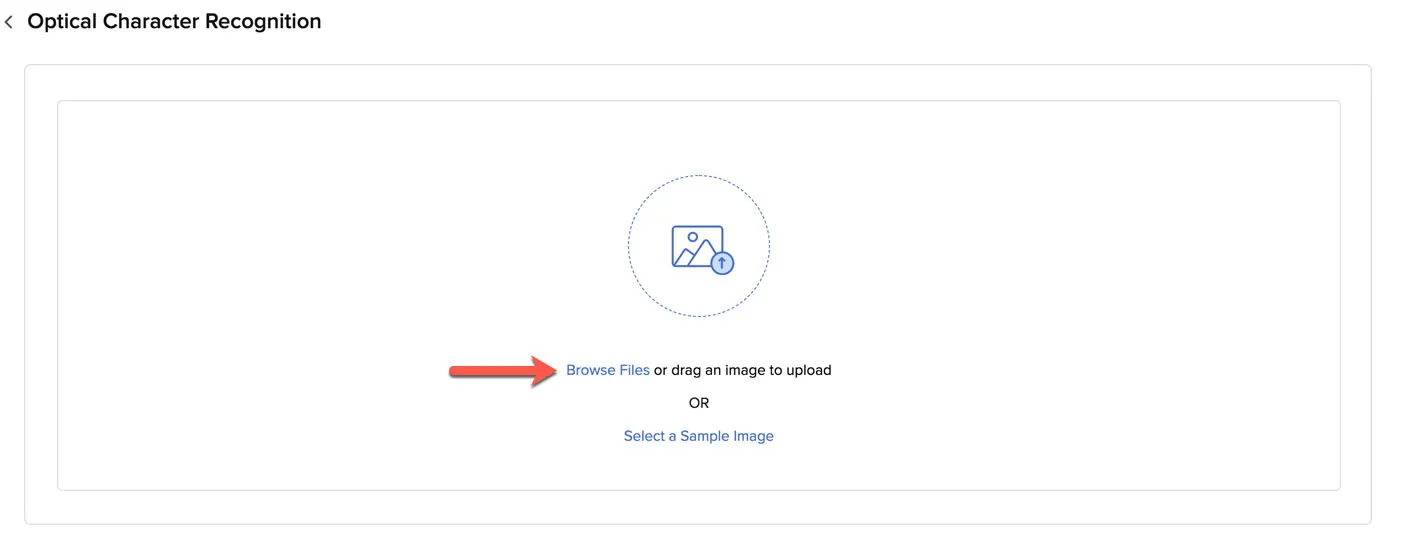
Si estás abriendo Optical Character Recognition después de haberlo cerrado, haz clic en Browse Files en este cuadro.
-
Sube un archivo desde tu sistema local.
-
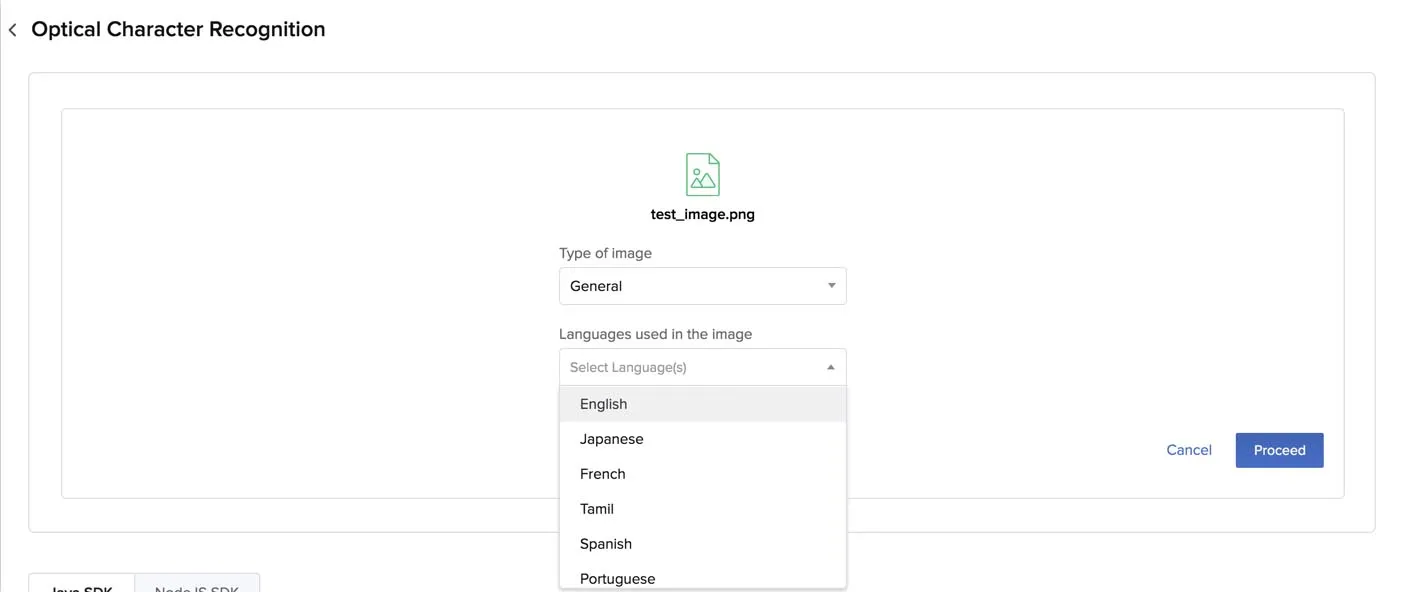
Selecciona el tipo de modelo y los idiomas en el texto del archivo, si los conoces. Puedes seleccionar General para el modelo OCR. Puedes seleccionar múltiples idiomas, si el archivo contiene texto en varios idiomas.
-
Haz clic en Proceed.
La consola procesará el archivo y mostrará el contenido textual reconocido, y la puntuación de confianza si es del tipo de modelo OCR. Puedes copiar el texto reconocido usando el icono de copiar.
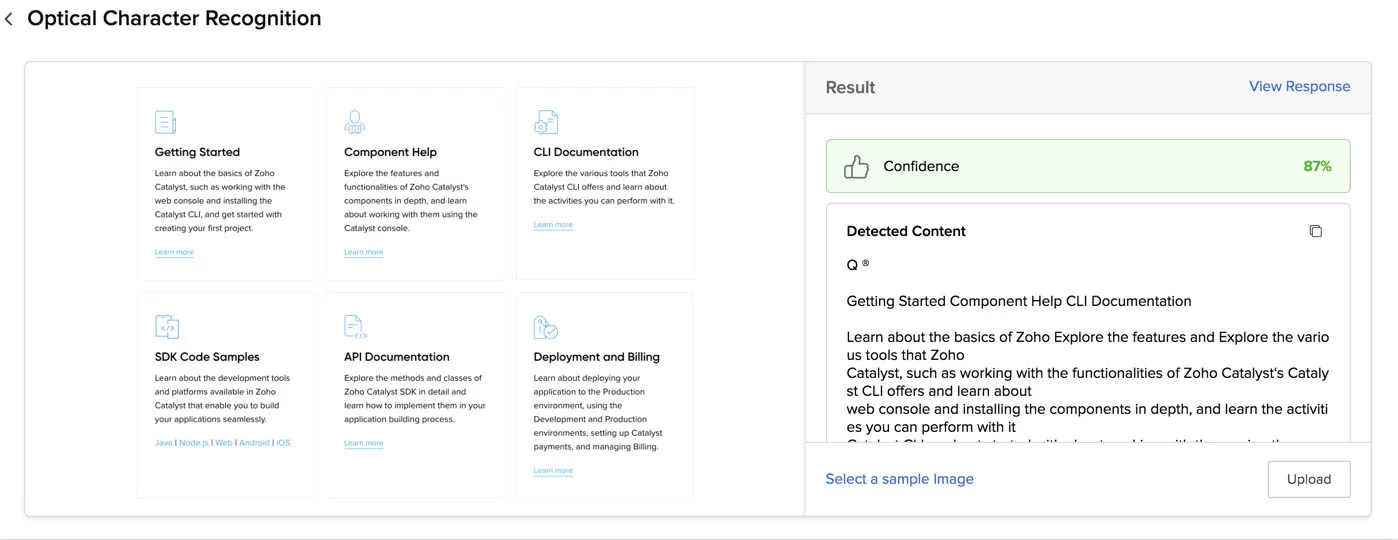
Puedes verificar la respuesta JSON de manera similar.

Acceder a plantillas de código para Optical Character Recognition
Puedes implementar Optical Character Recognition en tu aplicación de Catalyst usando las plantillas de código proporcionadas por Catalyst para las plataformas Java, Node.js y Python.
Puedes acceder a ellas desde la sección debajo de la ventana de pruebas. Haz clic en la pestaña Java SDK, NodeJS SDK o Python SDK, y copia el código usando el icono de copiar. Puedes pegar este código en el código de tu aplicación web o Android donde lo necesites.
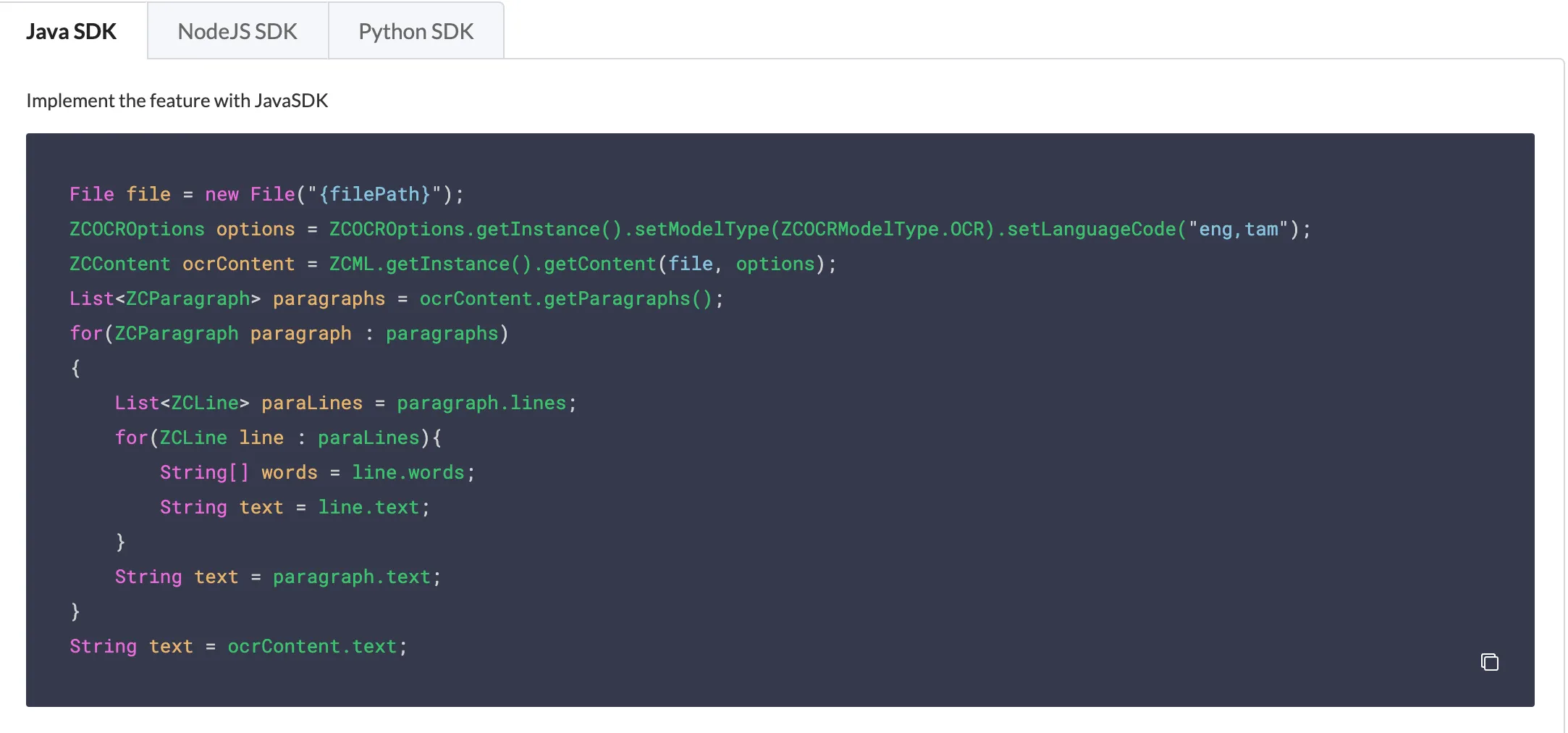
En Java, puedes procesar el archivo de entrada como un nuevo File, especificar el tipo de modelo usando ZCOCRModelType y los idiomas usando setLanguageCode. Consulta la documentación de la API para las claves de los idiomas y tipos de modelo soportados.
Como se mencionó anteriormente, puedes formatear la respuesta JSON que recibes. El código Java te permite obtener párrafos específicos, líneas individuales en un párrafo o palabras individuales en una línea.
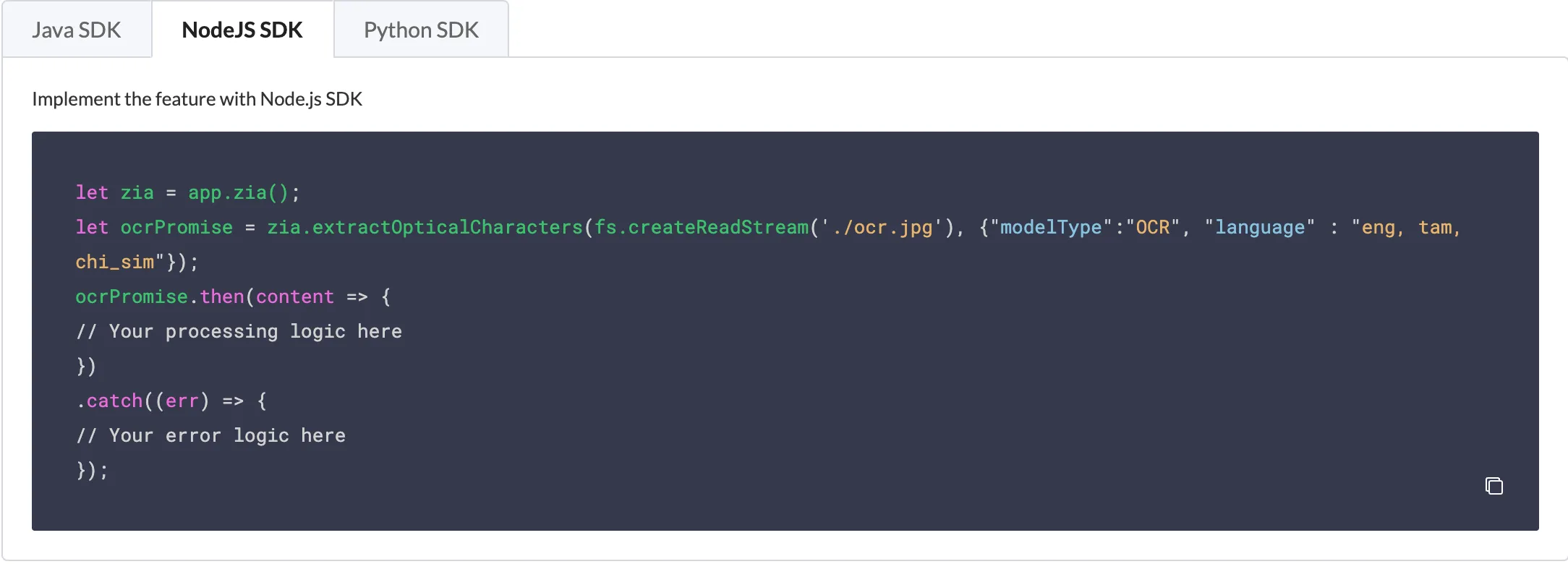
El código de Node.js procesa el archivo de entrada como el objeto ocrPromise. Puedes proporcionar el nombre del archivo de entrada, establecer el tipo de modelo usando modelType y los idiomas usando language.
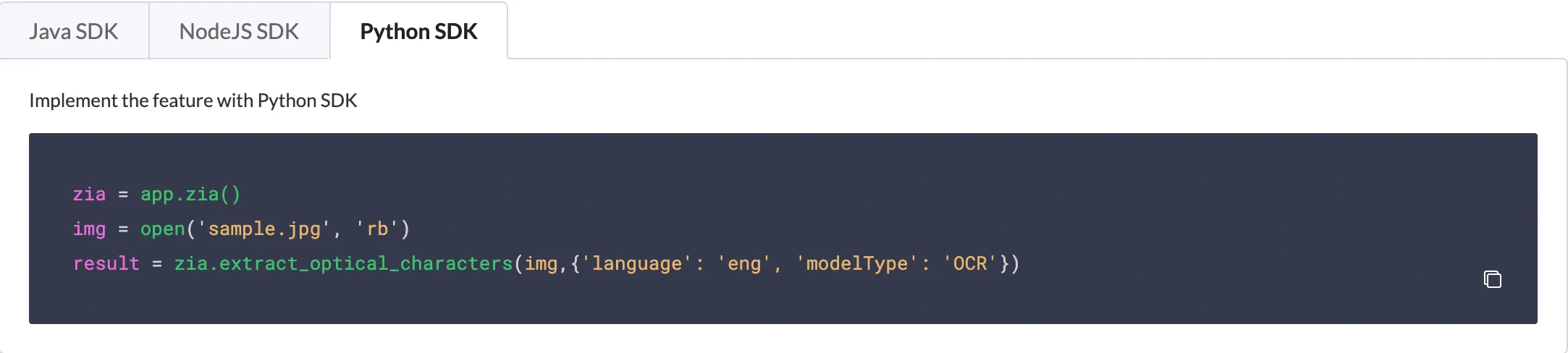
Para Python, debes pasar la ruta del archivo, el tipo de modelo y los idiomas como argumentos al método extract_optical_characters(). Sin embargo, los valores del tipo de modelo e idioma son opcionales. Por defecto, se pasa como el tipo de modelo OCR, y los idiomas se detectan automáticamente si no se especifican.
Última actualización 2026-03-20 21:51:56 +0530 IST
Yes
No
Send your feedback to us