Create a data pipeline
Now that we have uploaded the dataset, we will proceed with creating a data pipeline with the dataset.
- Navigate to the Datasets component in the left menu. There are two ways to create a data pipeline:
- You can click on the dataset and then click Create Pipeline in the top-right corner of the page.
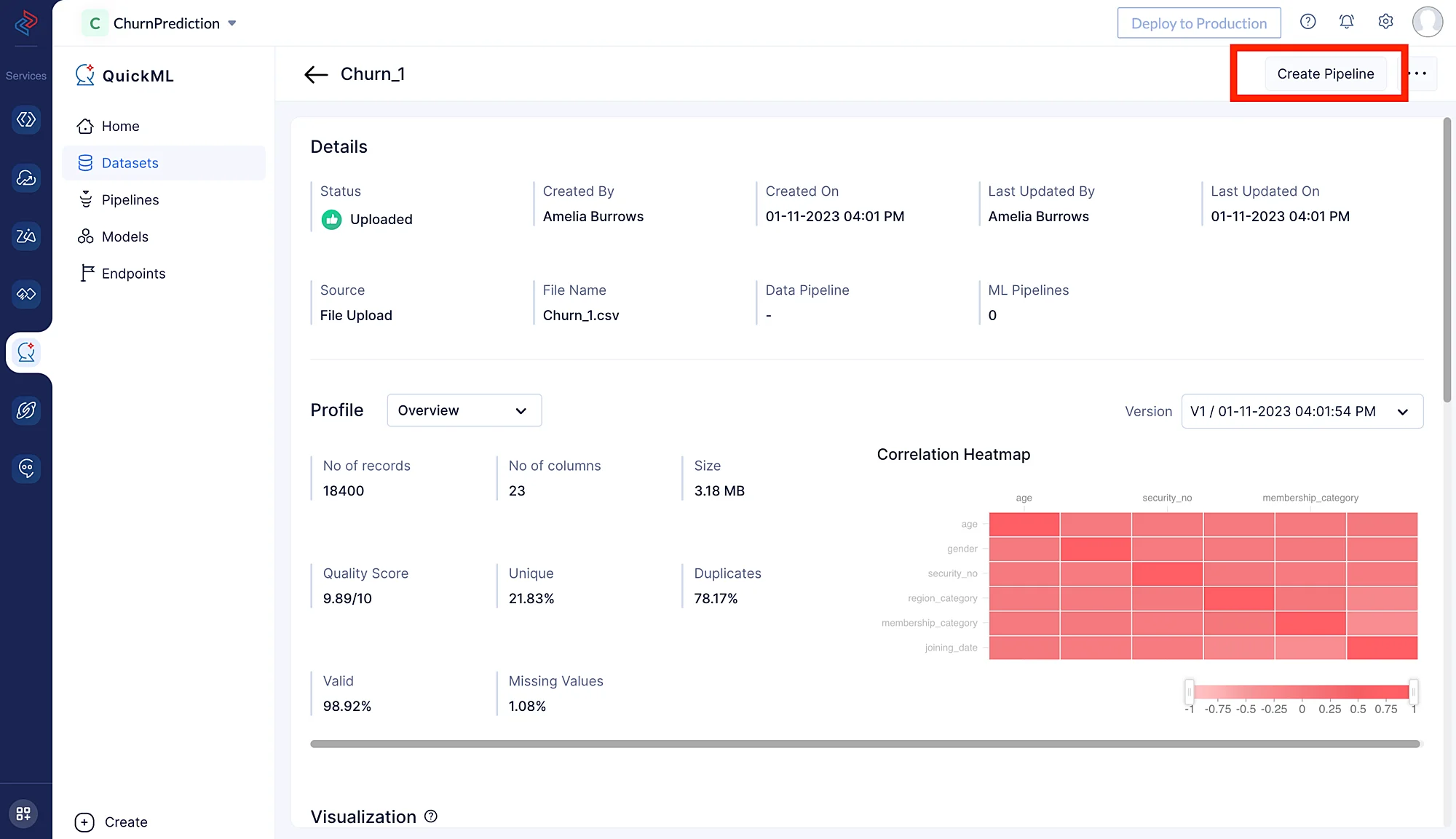
- You can click on the pen icon located to the left of the dataset name, as shown in the image below.
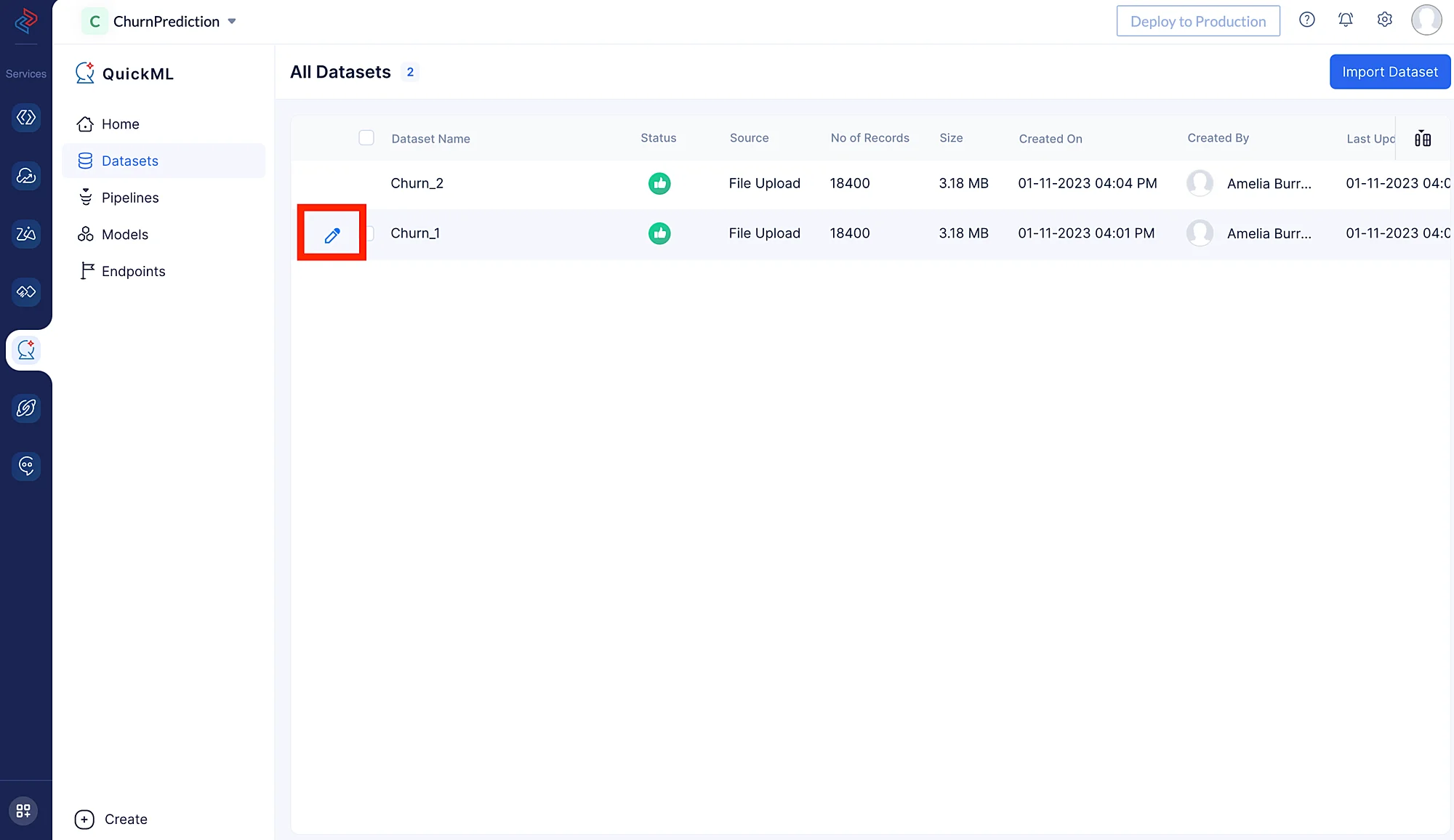
Here, we are uploading the Churn_1 dataset for preprocessing. Churn_2 will be added to this dataset in the upcoming preprocessing steps.
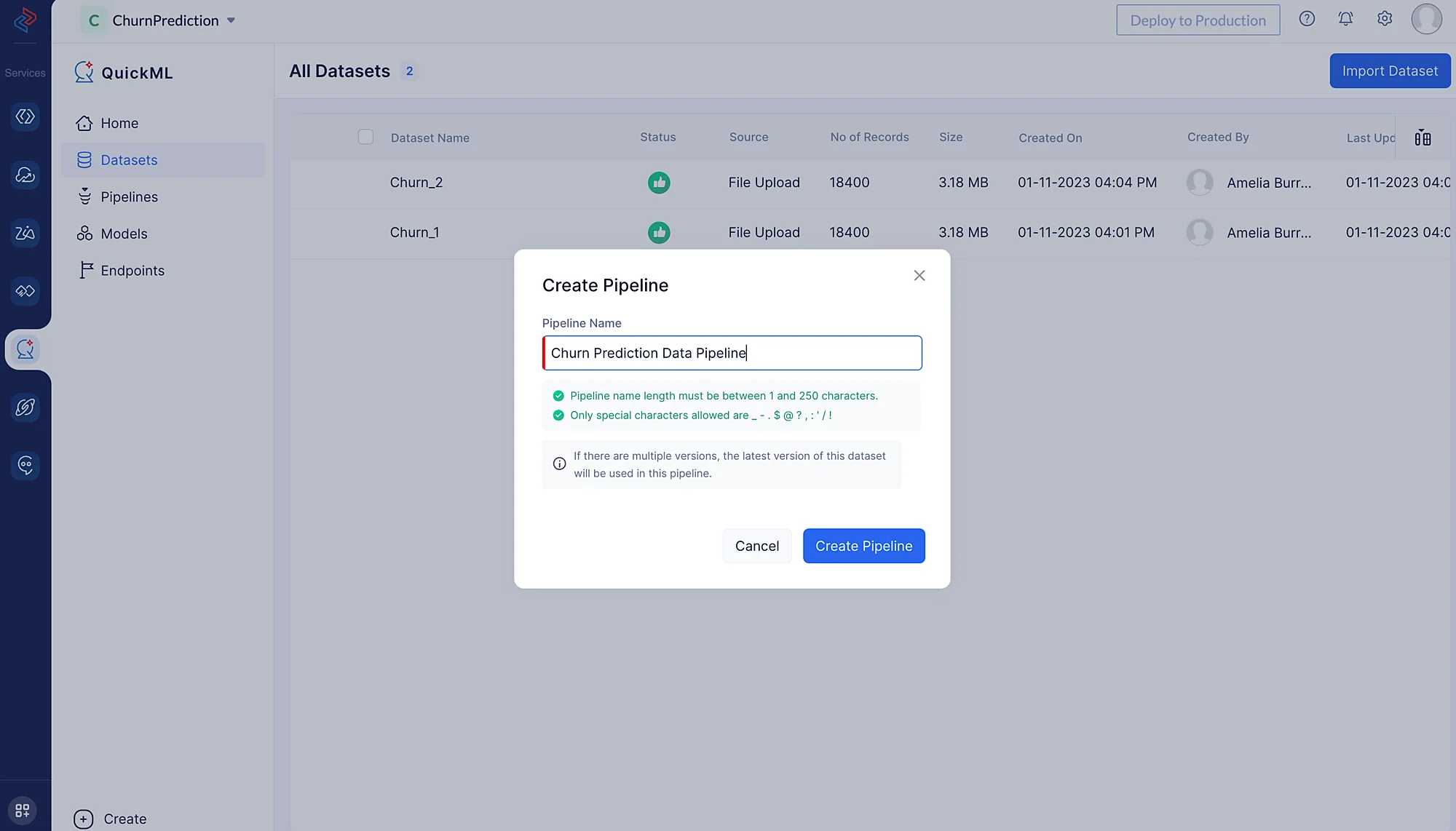
- Name the pipeline “Churn Prediction Data Pipeline” and click Create Pipeline.
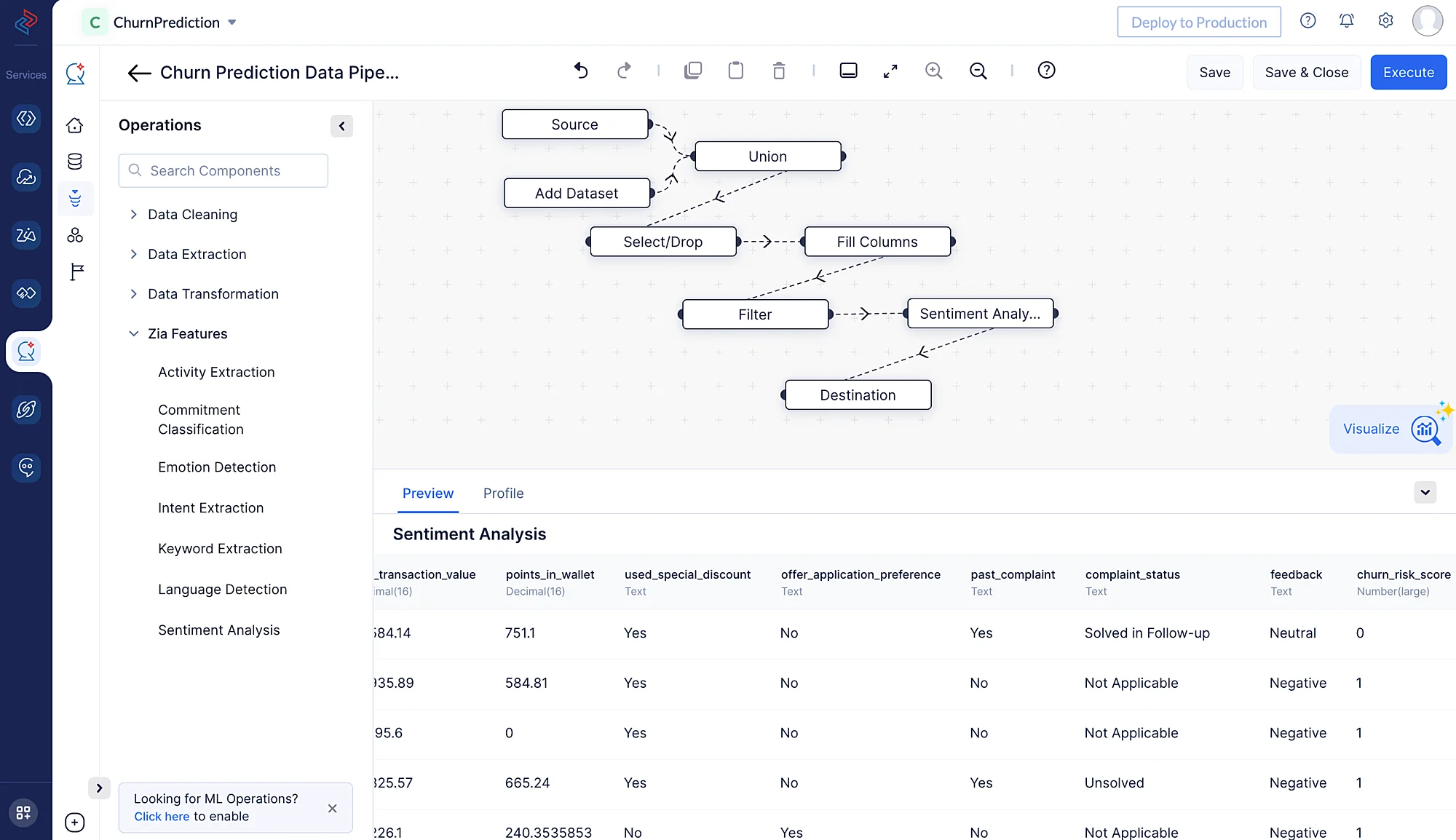
The pipeline builder interface will open as shown in the screenshot below.
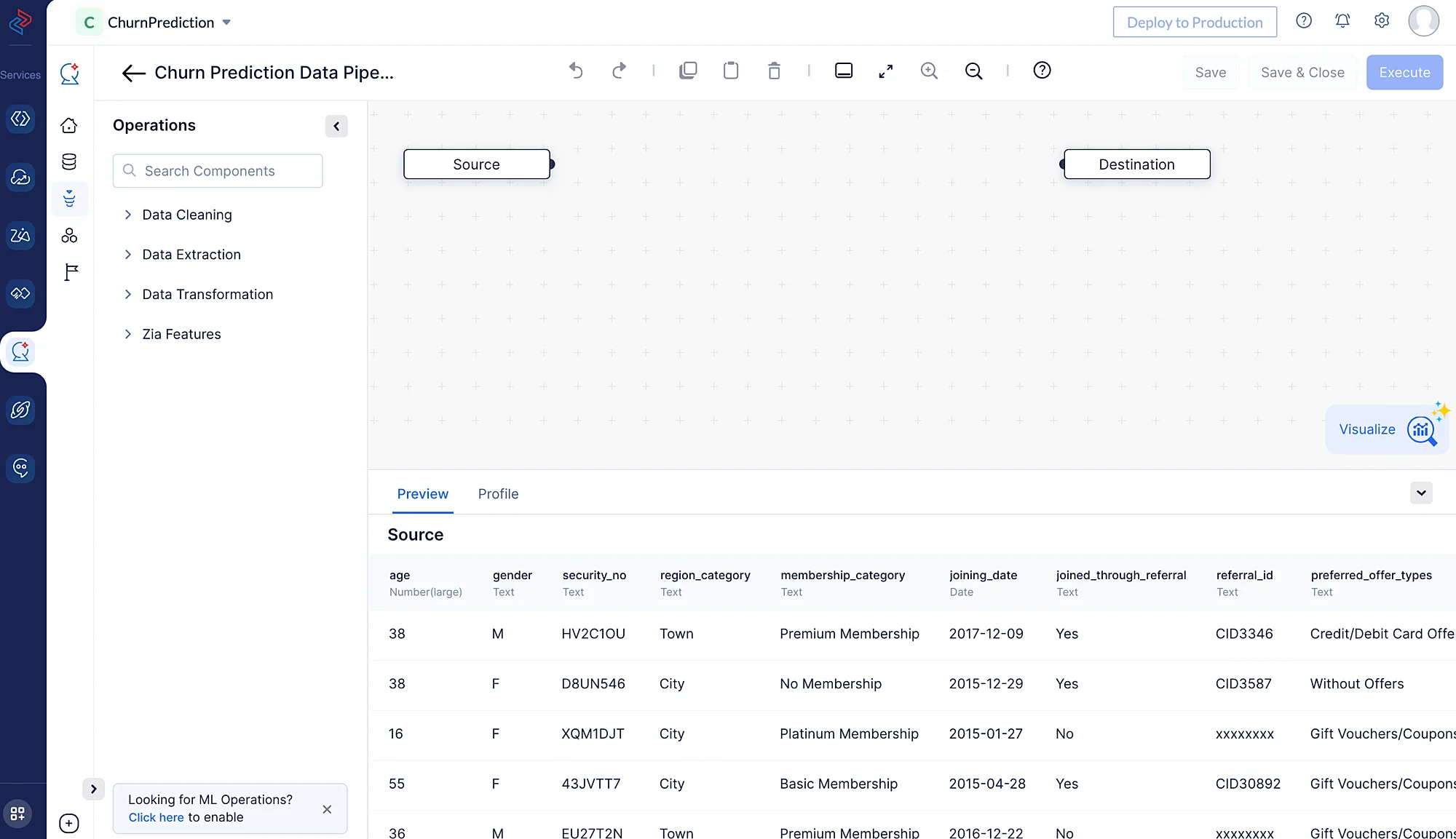
We will be performing the following set of data preprocessing operations in order to clean, refine, and transform the datasets, and then execute the data pipeline. Each of these operations involve individual data nodes that are used to construct the pipeline.
Data preprocessing with QuickML
-
Combining two datasets
With the aid of the in QuickML, we can add a new dataset (please note that you must first upload the dataset you wish to add). Here, we are adding the Churn_2 dataset to merge with the existing dataset, Custom name for the node can be given in the Custom Name section, here we have didn’t change the default name Add dataset. Then click the Save button.
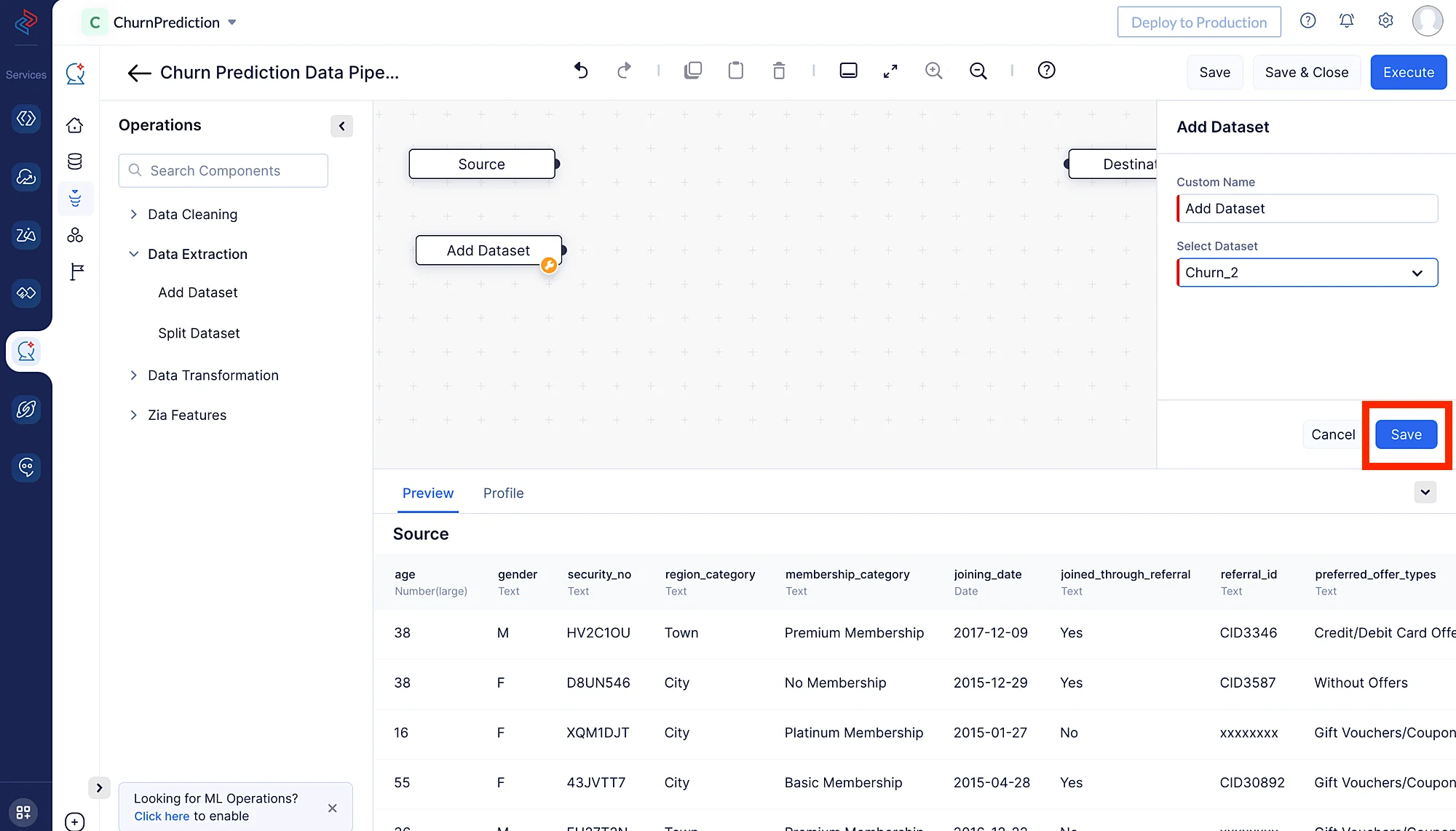
- Click Data Extraction in the left panel, and choose Add Dataset node. This will help you to add a new dataset(Churn_2) to the pipeline.
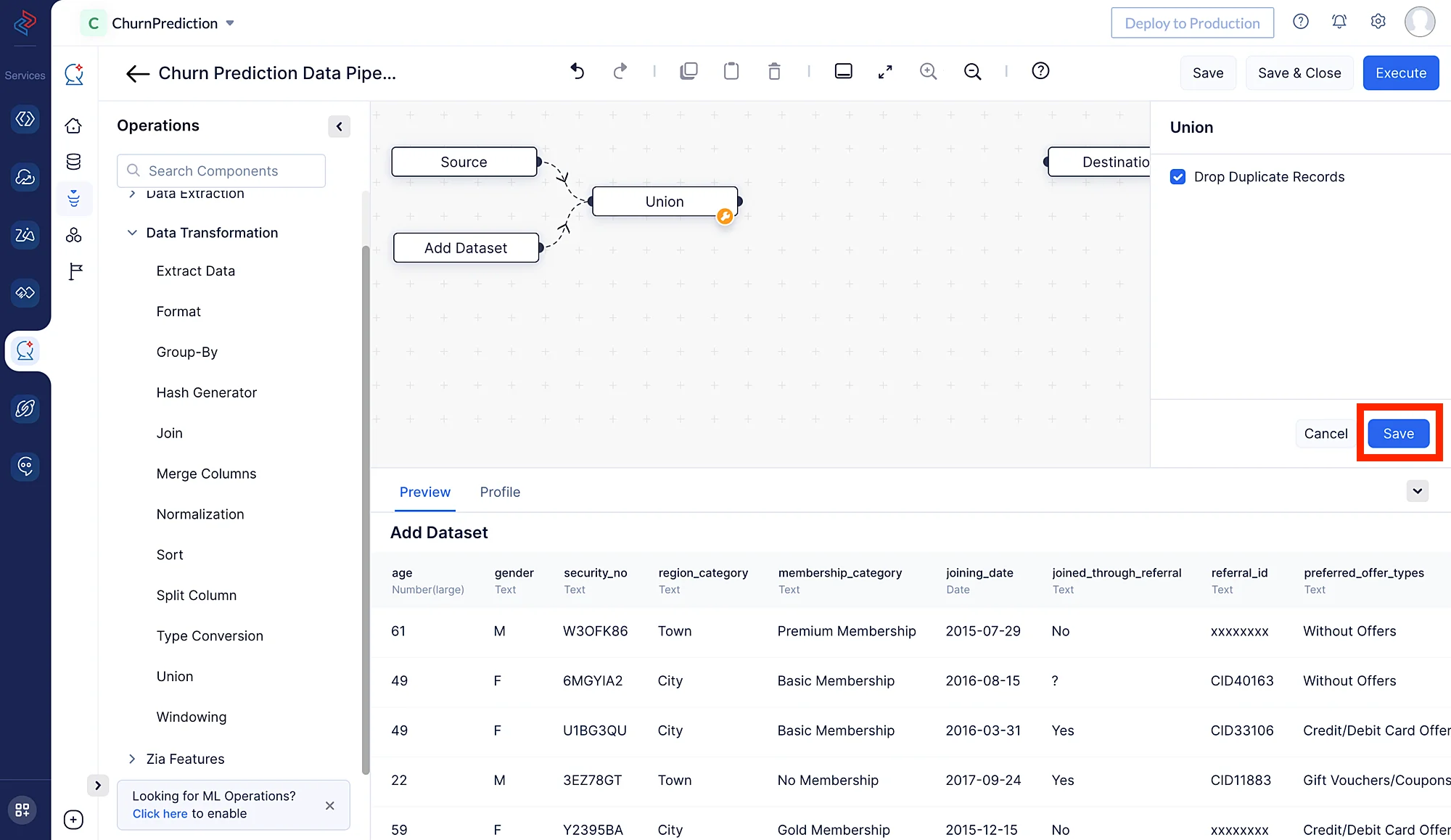
- Select Data Transformation in the left panel and choose Union node. Then make a connection between the nodes by joining the links between the two nodes. This will help to combine these two supplied datasets, Churn_1 and Churn_2, into a single dataset.
- If any duplicate records exist in either dataset, be careful to tick the box labeled “Drop Duplicate Records” while performing the operation. Then click the Save button. It will remove the duplicate records from both datasets.
-
Select/drop columns
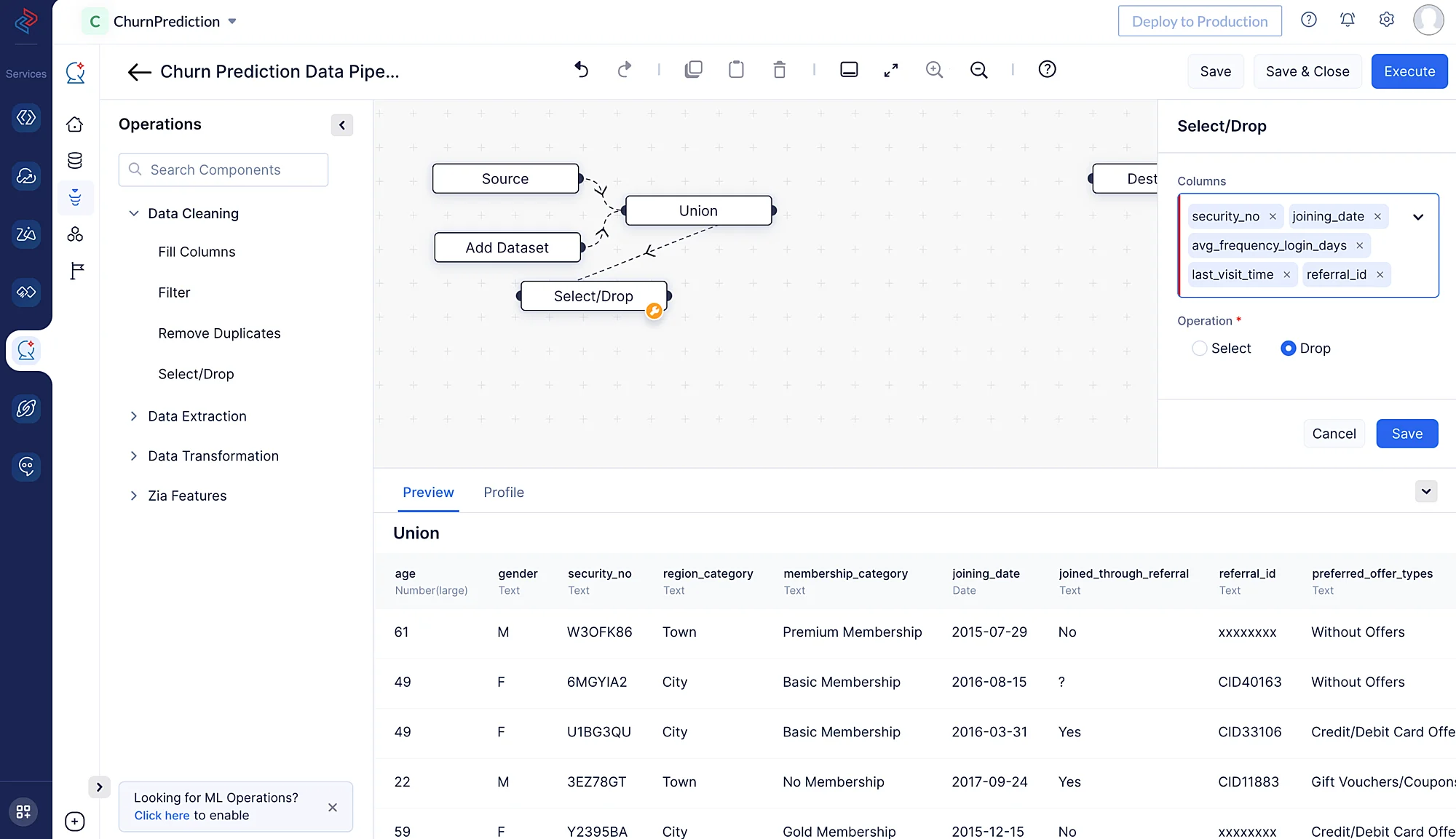
Selecting or dropping columns from a dataset is a common data preprocessing step in data analysis and machine learning. The choice to select or drop columns depends on the specific objectives and requirements of your analysis or modelling task. The columns we don’t need for our model training from this dataset are “security_no”, “joining_date”, “avg_frequency_login_days”, “last_visit_time” and “referral_id” in the provided datasets. Using QuickML, you may quickly choose the necessary fields from the dataset for model training using the Select/Drop node from the Data Cleaning component.
-
Filling columns in dataset with values
Using the Fill Columns node in QuickML, we can easily fill the column values based on any certain condition. We can fill the null values or non-null values based on our requirements. Here we are filling the columns “joined_through_referral” and “medium_of_operation” by filling the columns with a custom value “Not mentioned” for the rows with the “?”. For the column “points_in_wallet,” we are replacing the empty values with a custom value of “0”.
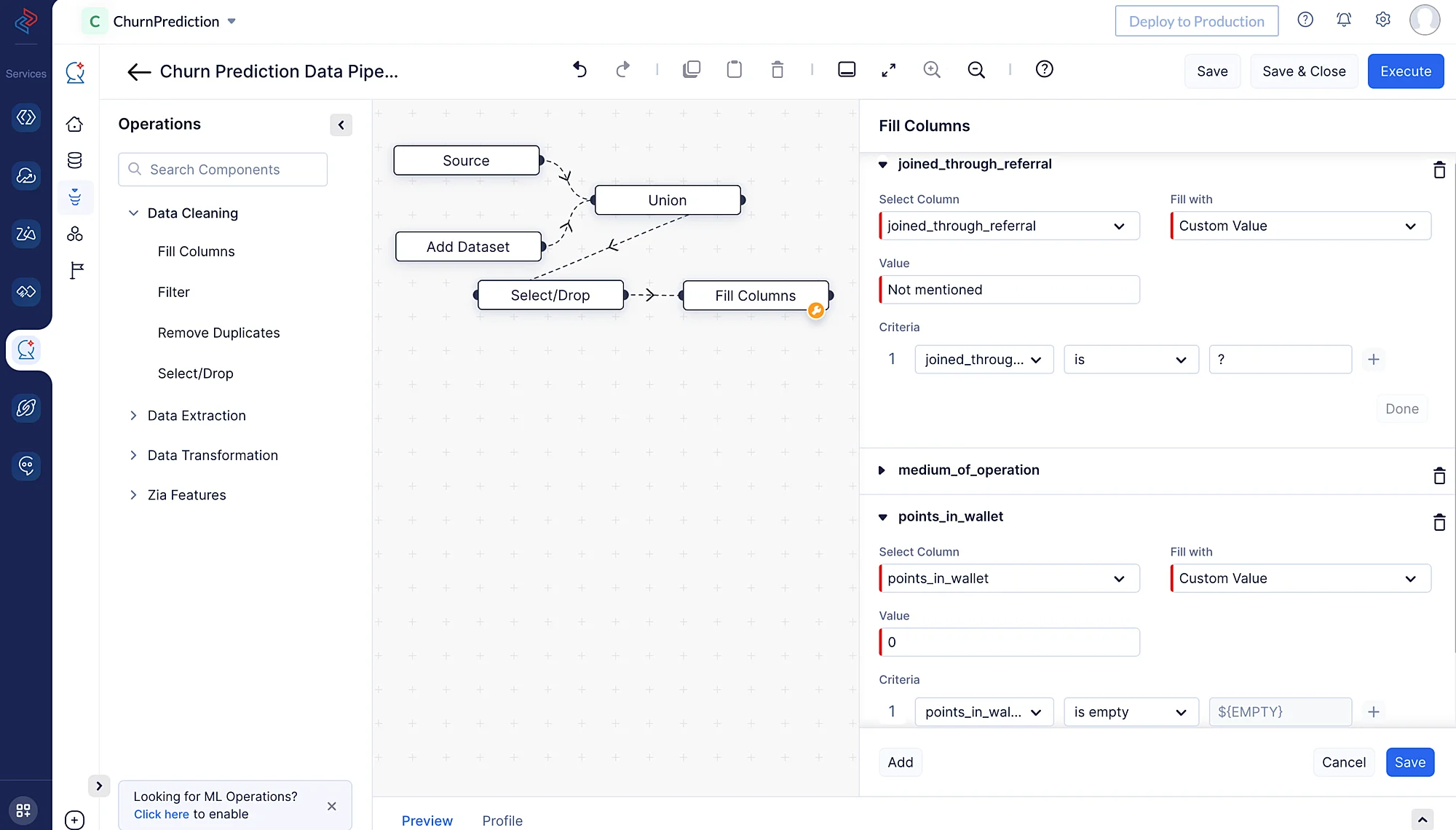
From the drop-down menu, choose the appropriate data type for the column.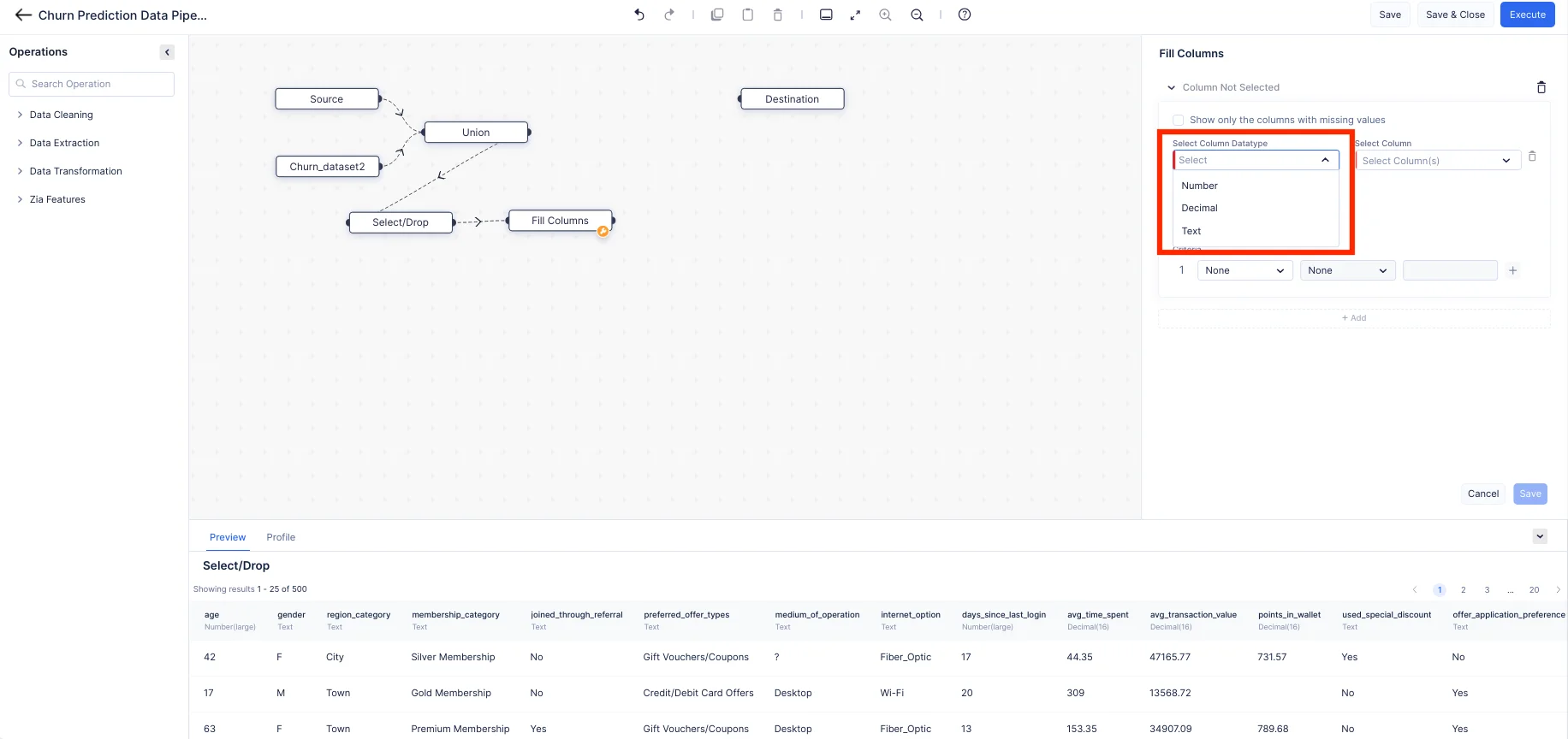
Click on the “+” button to add multiple criteria, then click on the Save button once the criteria is selected.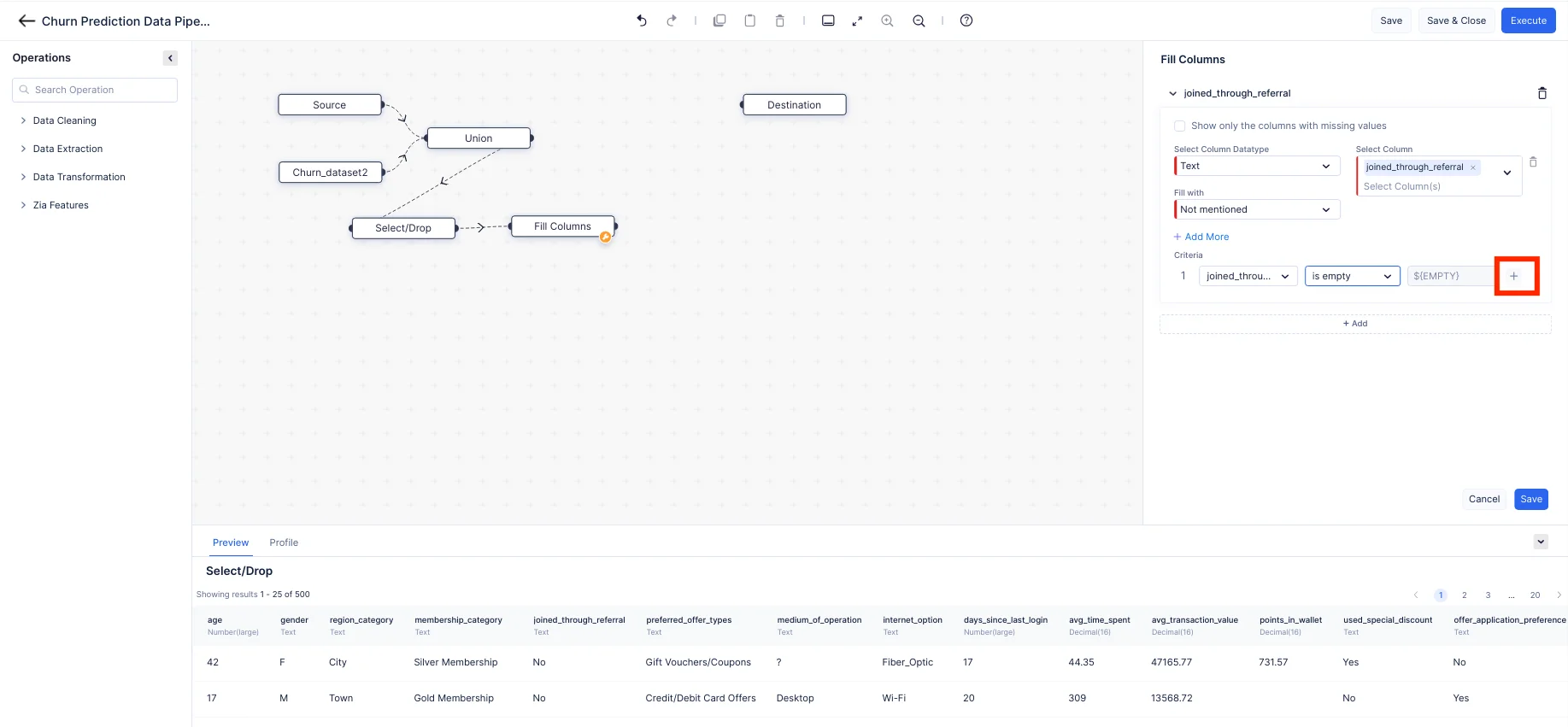
-
Filter Data
Filtering a dataset typically involves selecting a subset of rows from a DataFrame that meet certain criteria or conditions. Here we are using the Filter node from the Data Cleaning session to filter the “days_since_last_login”, “avg_time_spent,” and “points_in_wallet” columns whose values are greater than or equal to “0” and for columns “preferred_offer_types” and “region_category” that have non-empty values using the Filter node from the Data Cleaning session.
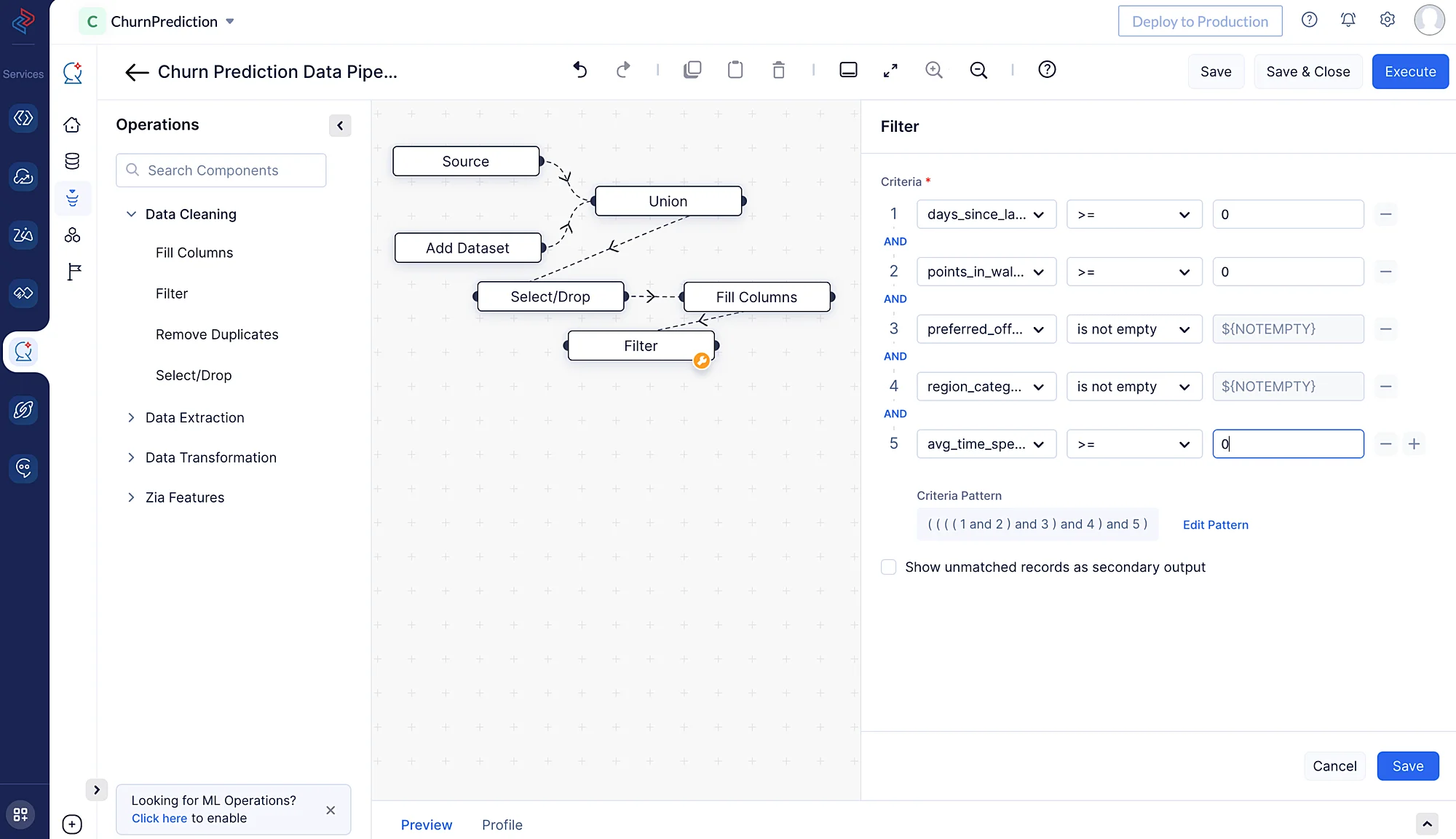
-
Sentiment Analysis
Sentiment Analysis is a technique used to determine the sentiment or emotional tone expressed in a piece of text, such as customer feedback or reviews. The goal of sentiment analysis is to classify the text as positive, negative, or neutral based on the emotions or opinions it conveys. Here we have the column named “feedback” which contains the feedback about the product. We can classify the values of the column as positive, negative, or neutral using the Sentiment Analysis node under Zia Features. Mark the checkbox next to Replace in place if you want to replace the value of the “feedback” column with the result of Sentiment Analysis node.
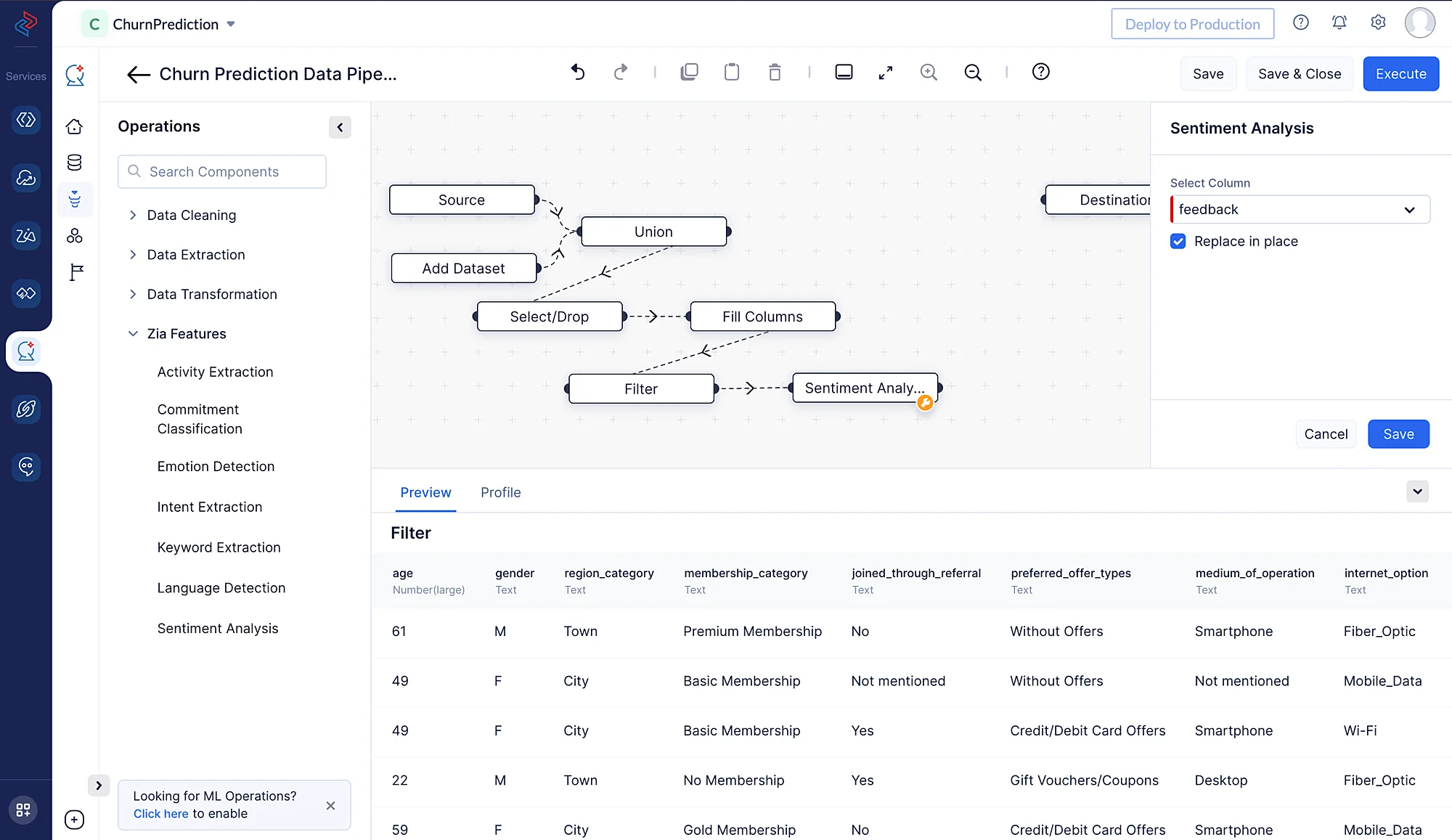
-
Save and Execute
Now, connect the Sentiment Analysis node tothe Destination node. Once all the nodes are connected, click the Save button to save the pipeline. Then click on Execute button to execute the pipeline.
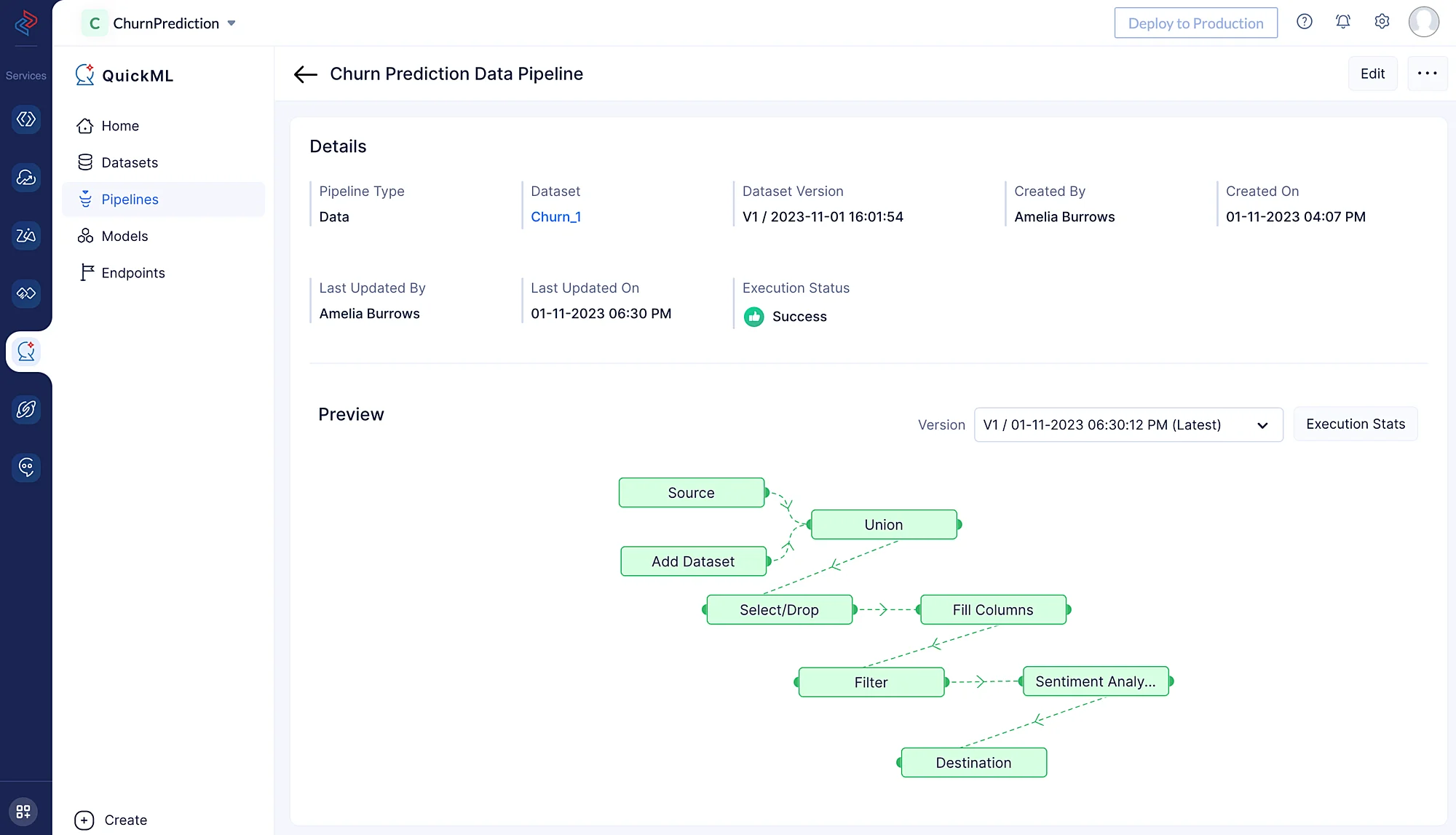
You’ll be redirected to the page below, which shows the executed pipeline with the execution status. We can see here that the pipeline execution was successful.
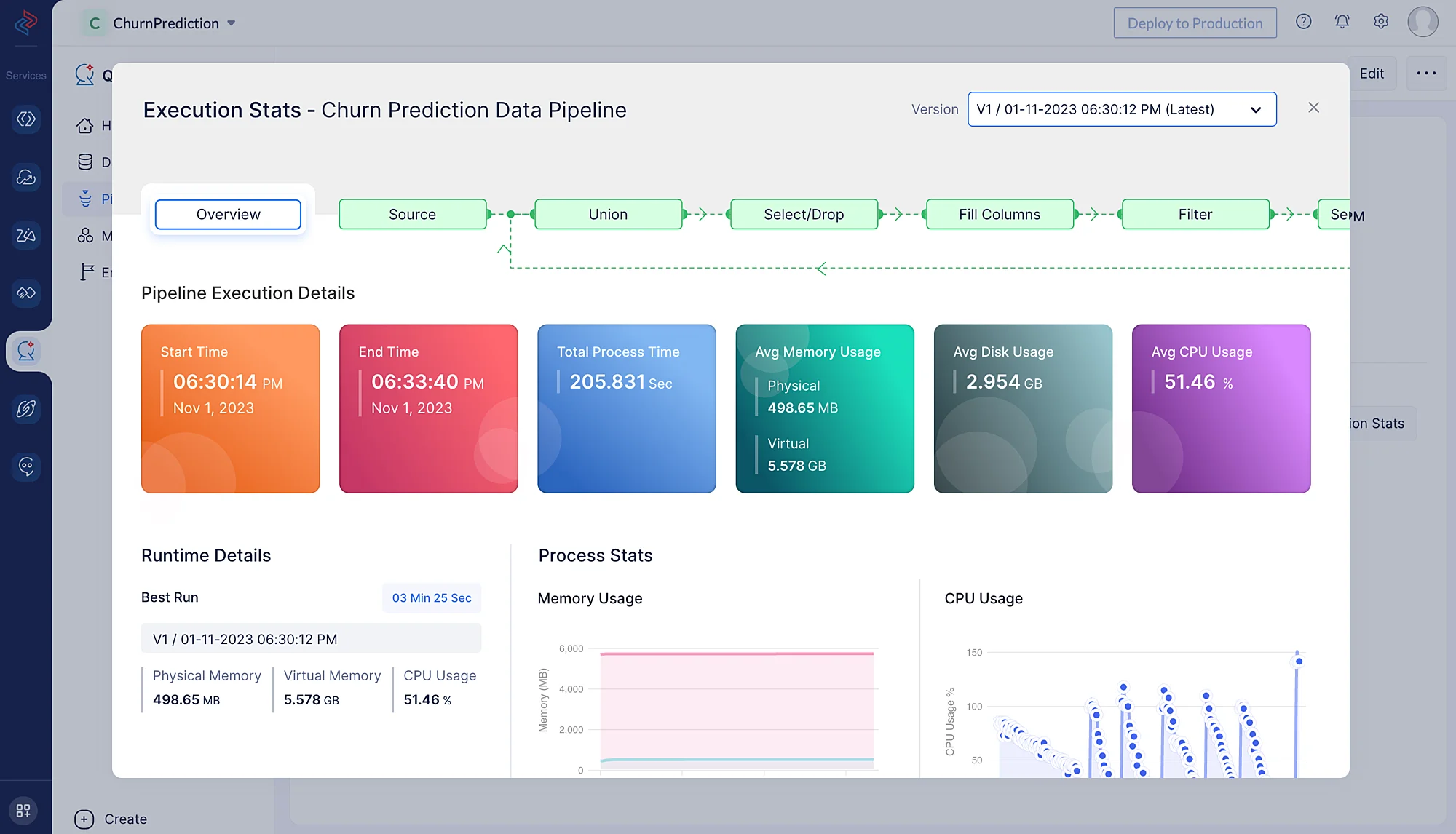
Click on Execution Stats to access more details regarding the compute usage, as shown below.
In this part, we’ve looked at how to process data using QuickML, giving you a variety of effective ways to get your data ready for the creation of machine learning models. This data pipeline can be reused to create multiple ML experiments for varied use cases within your Catalyst project.
Last Updated 2025-03-11 13:27:23 +0530 IST