Data Preprocessing Techniques in QuickML
QuickML provides major data preprocessing techniques divided into three main categories.
- Data Cleaning
- Data Transformation
- Dataset Extraction
All the operations listed in upcoming slides are available as stages in the pipeline building process that helps the user to create better Machine learning models.
Data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset. If data is incorrect, outcomes and algorithms will be unreliable.
-
Fill Columns
This is used to change the values of the specific column based on the criteria set by the user. If the criteria is not specified in the configuration, then all the values in that column will be replaced by the user-specific value / method.
Example:
For population data of a country which contains patient details like name, age, address,eligible for vote etc., We can fill in the eligible for vote column as yes for all people whose age is greater than 18 as criteria. -
Filter
This is used to extract the data from the dataset that we need to preprocess by applying criteria in the configuration. We are also able to use not satisfied data for preprocessing
Example:-
Single Output Filter:
In student dataset, if we only require CSE department data, we can set criteria as dept=CSE, which will reduce data that we need to preprocess. -
Double output Filter:
If it is required to preprocess both boys and girls data of the student dataset in a different flow, we can use the “Show unmatched records as secondary output” checkbox in configuration. This will be helpful if you wanted to do some special operation or process for unmatched data from the filter node.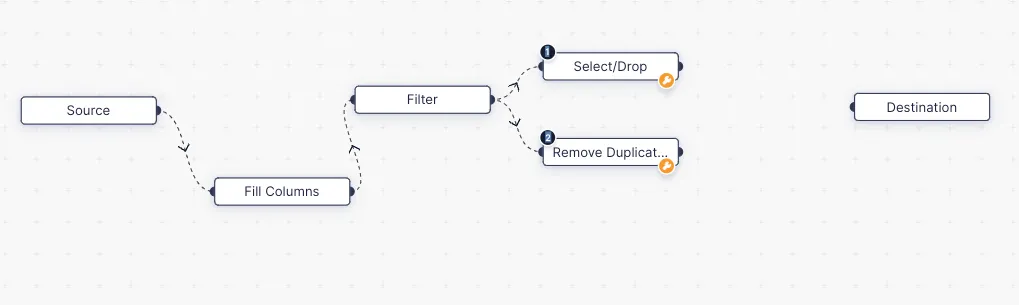
-
-
Remove duplicates
It is used to remove the duplicate rows in the dataset. We can also control how duplicate rows need to be removed.
Example:
For a student dataset which had five duplicate rows with student ID 101 at index 1,5,7. Keep preference option:
First - Output dataset will have only row at index 1, other rows at index 5 & 7 will be removed.
Last - Output dataset will have only row at index 7, other rows at index 1 & 5 will be removed.
None - Output dataset will have no duplicate rows, rows at index 1,5 & 7 will be removed. -
Select or Drop
This is used to do both select or drop columns in dataset. If a user needs to have only two columns from dataset, can simply select the required two columns from drop down and choose select operation. For dropping columns, choose drop operation.
Last Updated 2025-09-30 16:23:20 +0530 IST
Yes
No
Send your feedback to us