Create Data Pipeline
Now that we have uploaded the required datasets, we will proceed with creating a data pipeline for them.
-
Navigate to the Datasets component in the left menu and click Cancer_detection_A dataset.
-
The data pipeline details page will be displayed. Click Create Pipeline.
-
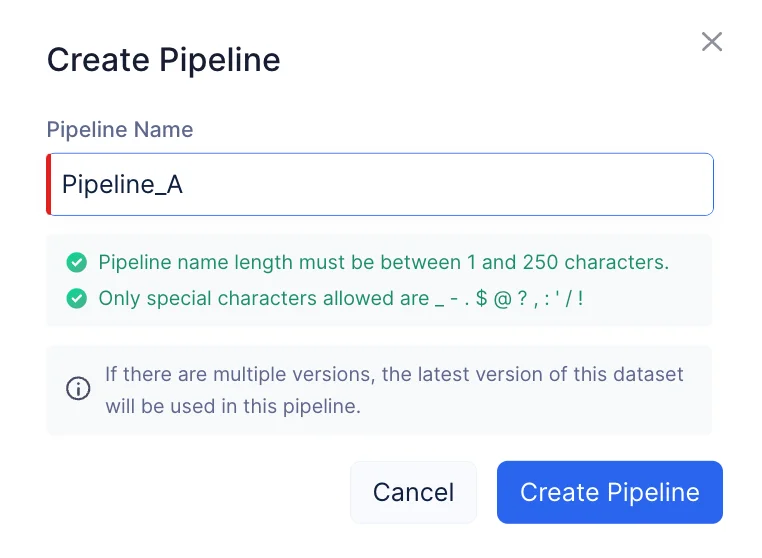
Provide the name of the pipeline as “Pipeline_A” and click Create Pipeline.
The Pipeline Builder interface will be opened, as shown in the screenshot below.
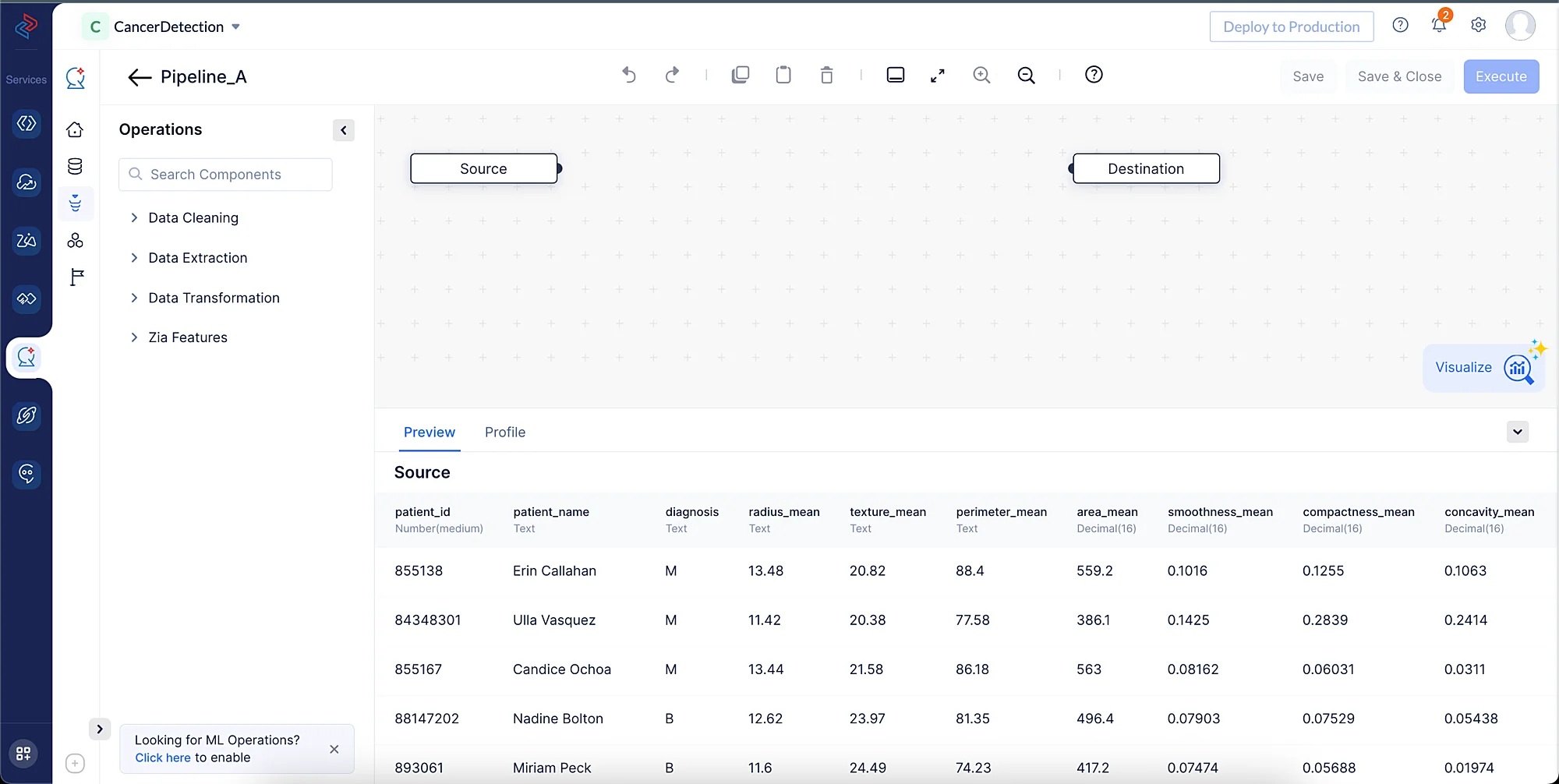
We will be performing the following set of data preprocessing operations in order to clean, refine, and transform the datasets, then execute the data pipeline. Each of these operations involves individual data nodes that are used to construct the pipeline.
Since we have two datasets, we will first need to merge them before the training process. Please make sure to follow the below listed steps to merge the two datasets:
-
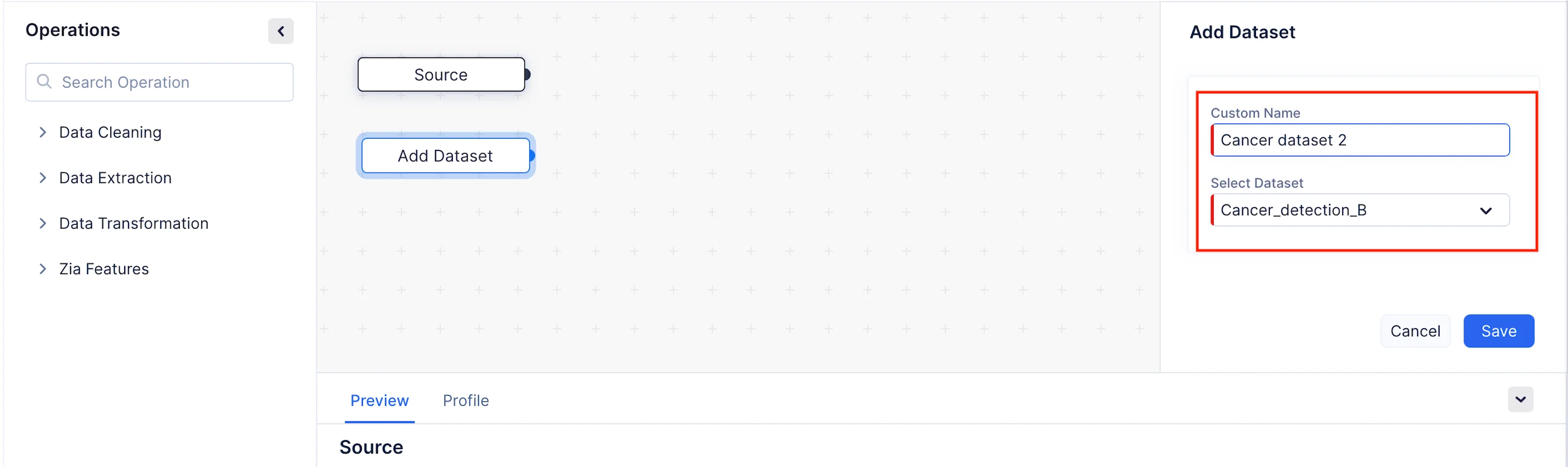
In the Operations menu, expand the Data Extraction component. Drag and drop the Add Dataset node into the Pipeline Builder, as shown in the screenshot below. Custom name for the node can be given in the Custom Name section. Here we have given as Cancer dataset 2.
-
We will now configure the details of the node in the Add Dataset section on the right panel. In our case, we will need to merge the Cancer_detection_B dataset with the Cancer_detection_A dataset. Choose Cancer_detection_B from Select Dataset dropdown and click Save.
-
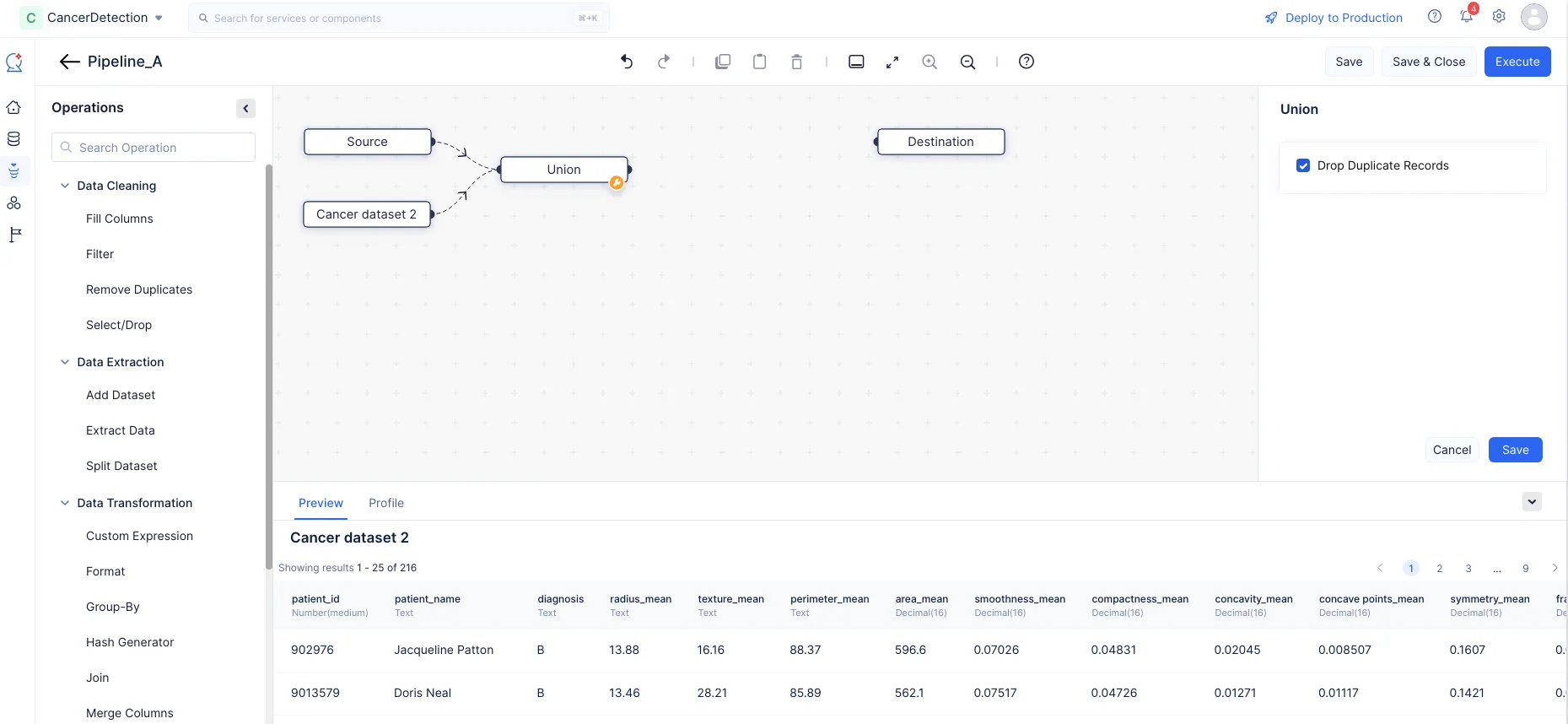
Expand the Data Transformation component, drag and drop the Union node into the Pipeline Builder. Make a connection between the nodes as shown in the screenshot below by joining the links between the two nodes.
-
In the Union section on the right panel, choose to Drop Duplicate Records and click Save.
After combining the datasets, we will need to select the required fields in the merged dataset to train them further.
-
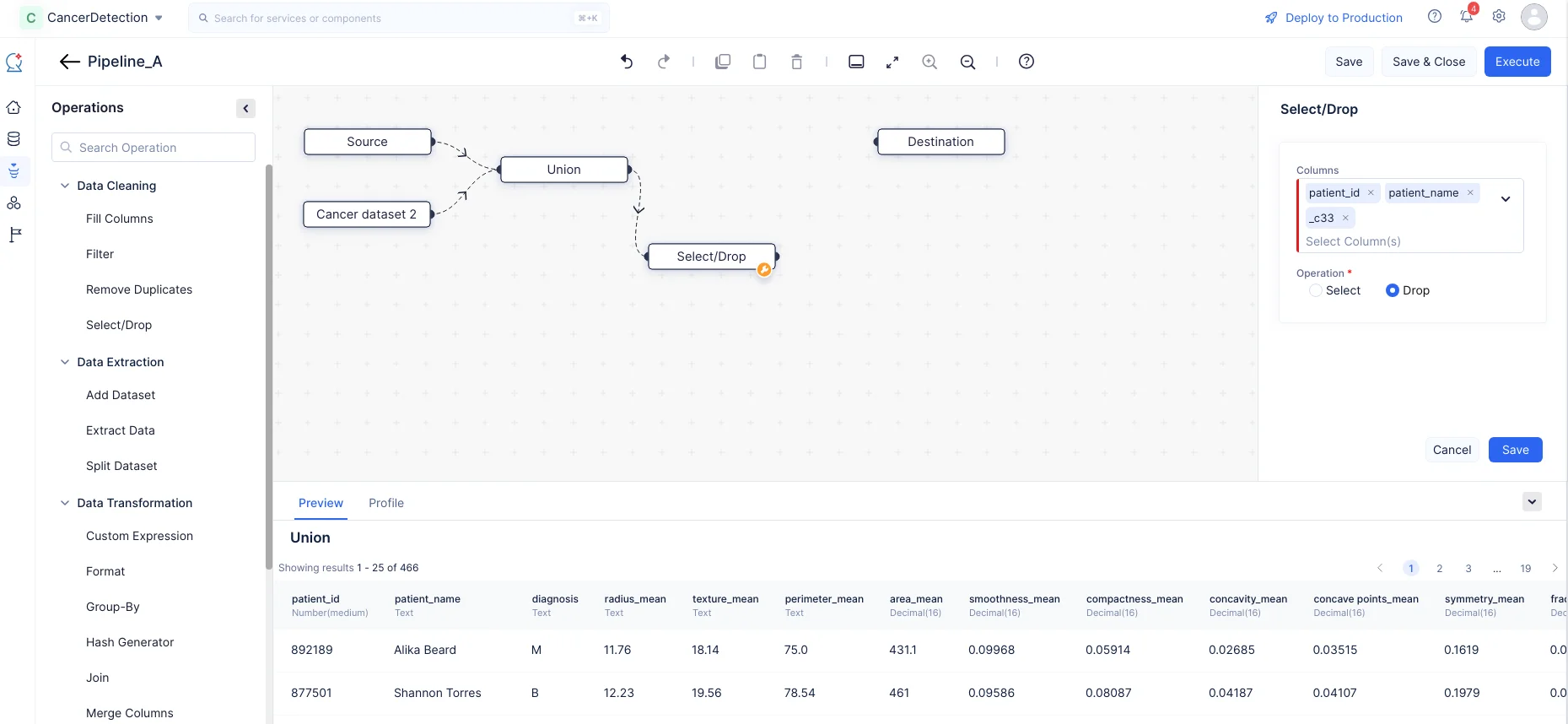
Expand the Data Cleaning component in the Operations menu. Drag and drop the Select/Drop node in the Pipeline Builder and make a connection with the Union node.
-
In the Select/Drop section on the right panel, select the “patient_id”, “patient_name” and “_c33” columns, choose the operation “Drop” to drop the columns from the merged dataset, then click Save. In our case, these columns are generic, serving no purpose to be trained further, so we are removing them.
For the mismatched datatypes in the columns of the datasets, we will be using the Type conversion node to convert the data into the appropriate types. You can view the columns and their datatypes in the Preview tab of the Pipeline details page.
In our dataset, the “texture_mean”, “radius_mean” and “perimeter_mean” column contains decimal values, but it is stored as type String. Please make sure to follow the below listed steps to carry out the conversion process:
-
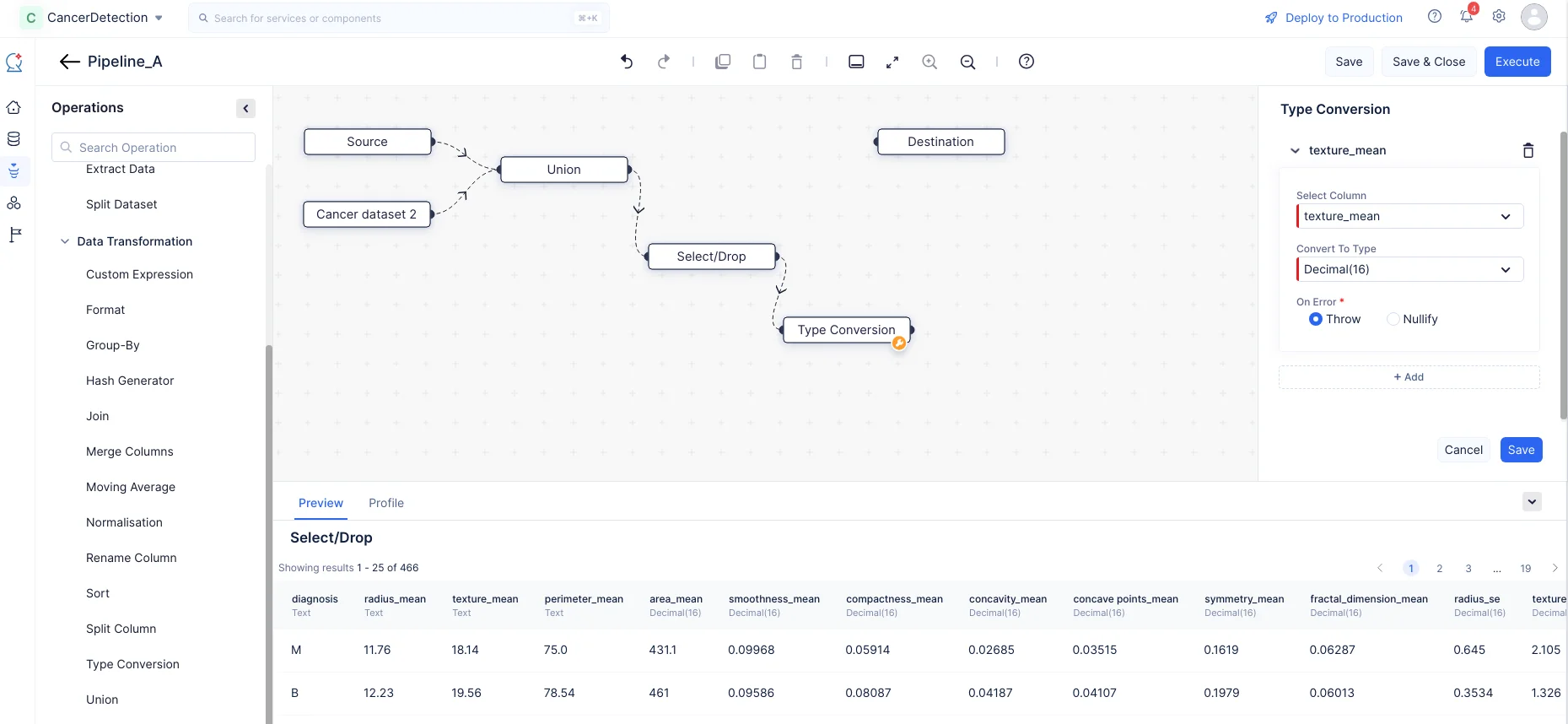
Expand the Data Transformation component in the Operations menu. Drag and drop the Type Conversion node into the Pipeline Builder and make a connection with the Select/Drop node, as shown in the screenshot below.
-
In the Type Conversion section on the right panel, choose the column as texture_mean, and select the Convert To Type input as Decimal(16) from the drop-down menu. Choose between Throw and Nullify in case of any errors. Likewise click on “+ Add” button and type convert “radius_mean” and “perimeter_mean” from Text to Decimal(16).
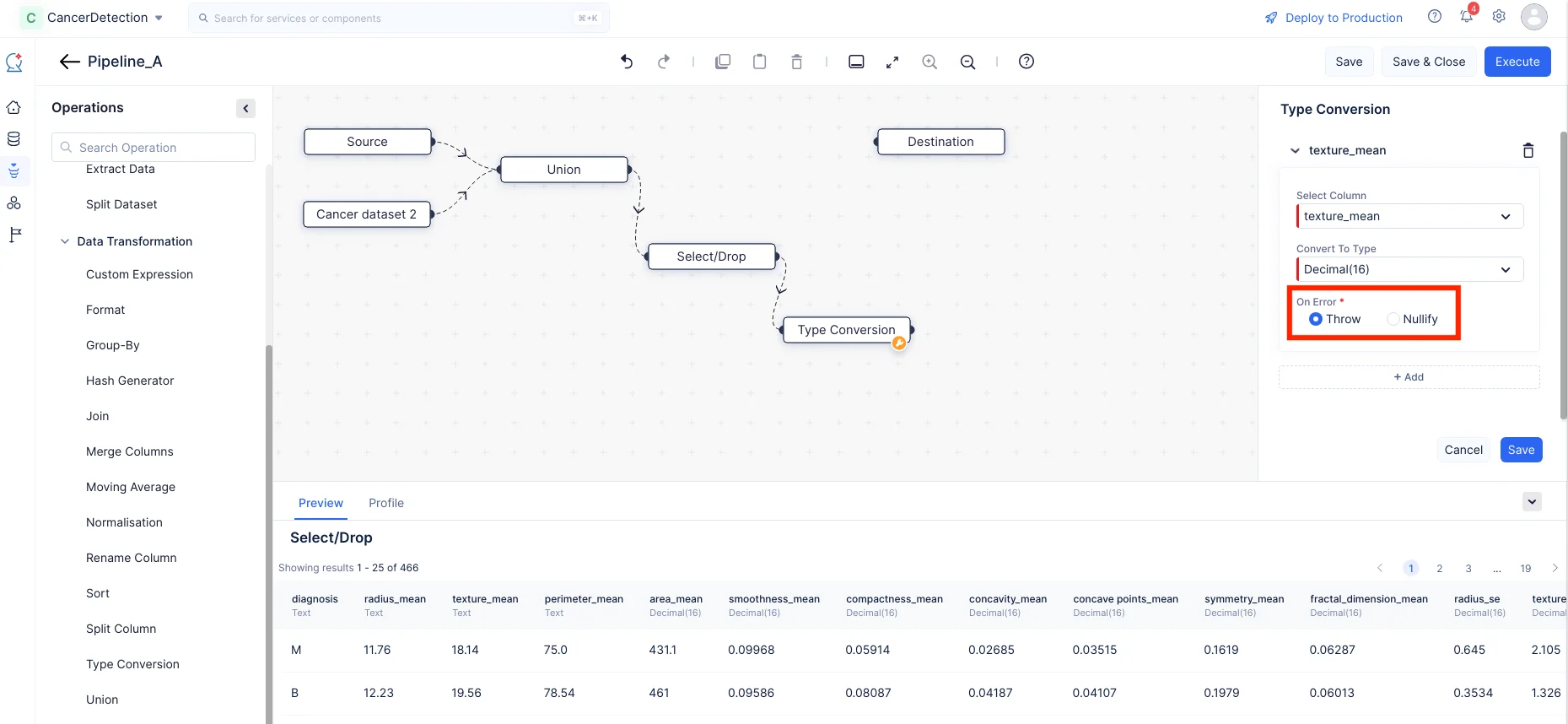
-
Click Save.
As a part of data preprocessing, we will need to check if there are missing values in any of the columns in the datasets and fill them. We will be using the Fill Columns node for executing this operation.
-
Expand the Data Cleaning component in the Operations menu. Drag and drop the Fill Columns node into the Pipeline Builder and make a connection with the Type Conversion node, as shown in the screenshot below.
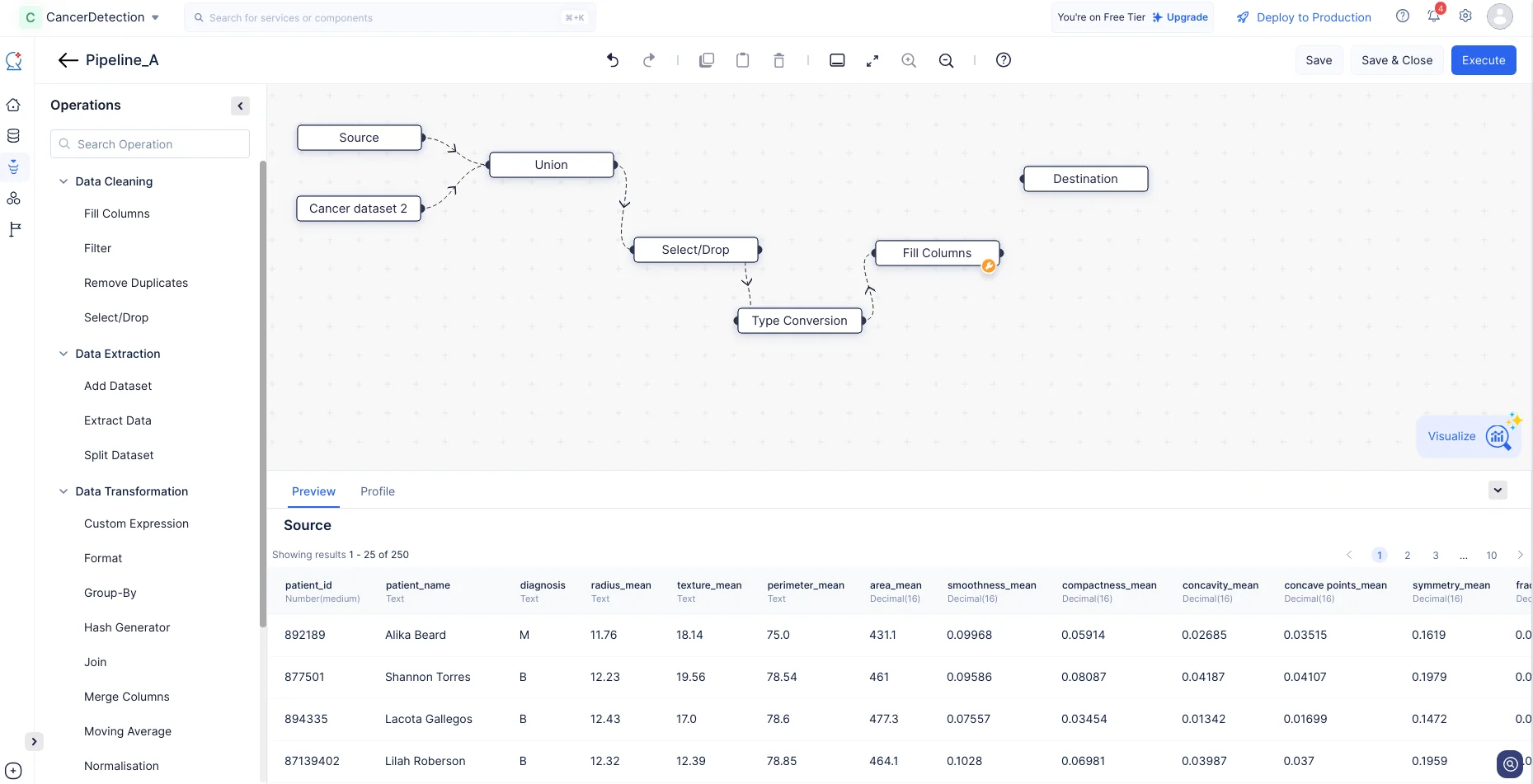
-
Enable Show only the columns with missing values to only select the columns which has empty record, then select the columns which want to be filled with custom value here we select “concavity_se”, and “area_worst” and choose the Fill with input as “Mean” and click Save. This fills the empty values in the column data with the mean value of the particular columns.
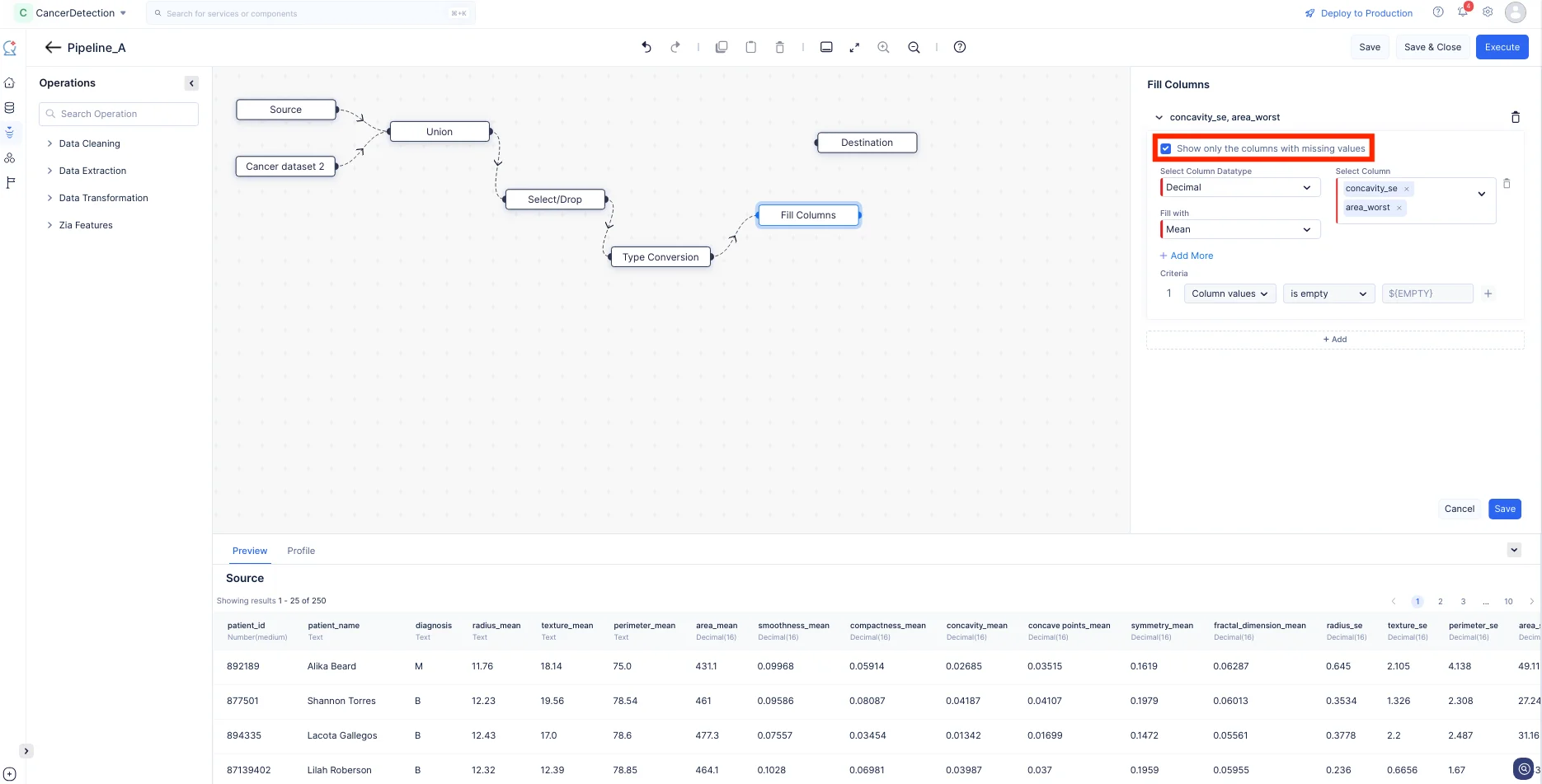
Now, we have configured the required nodes for this tutorial. Finally, make a connection between the last configured node (i.e. Fill Columns) and the Destination node.
Click Execute.
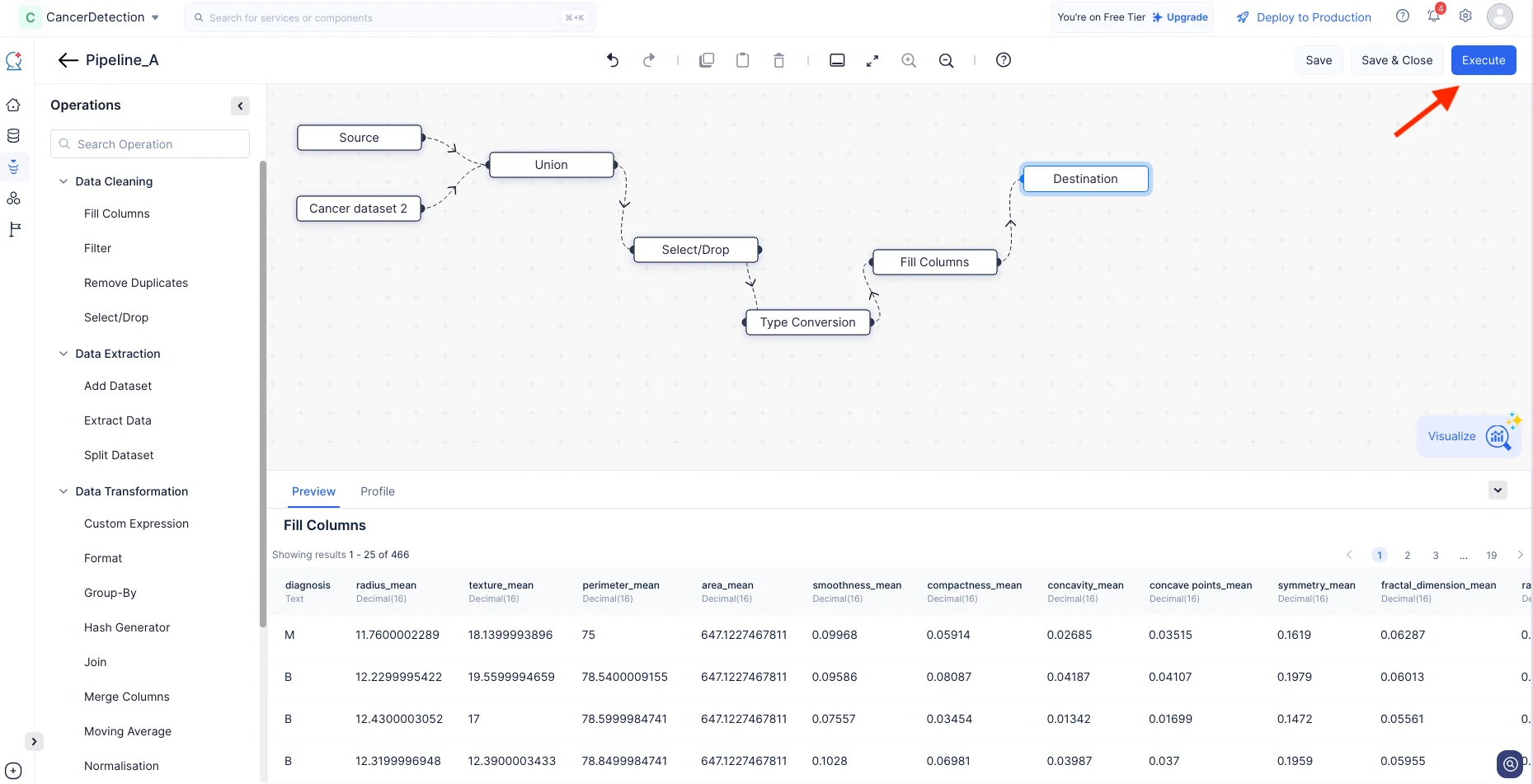
The data pipeline will start execution and the status of the execution will be displayed on the pipeline details page as shown in the screenshot below. Once the pipeline has completed execution, the execution status will indicate “Success”.
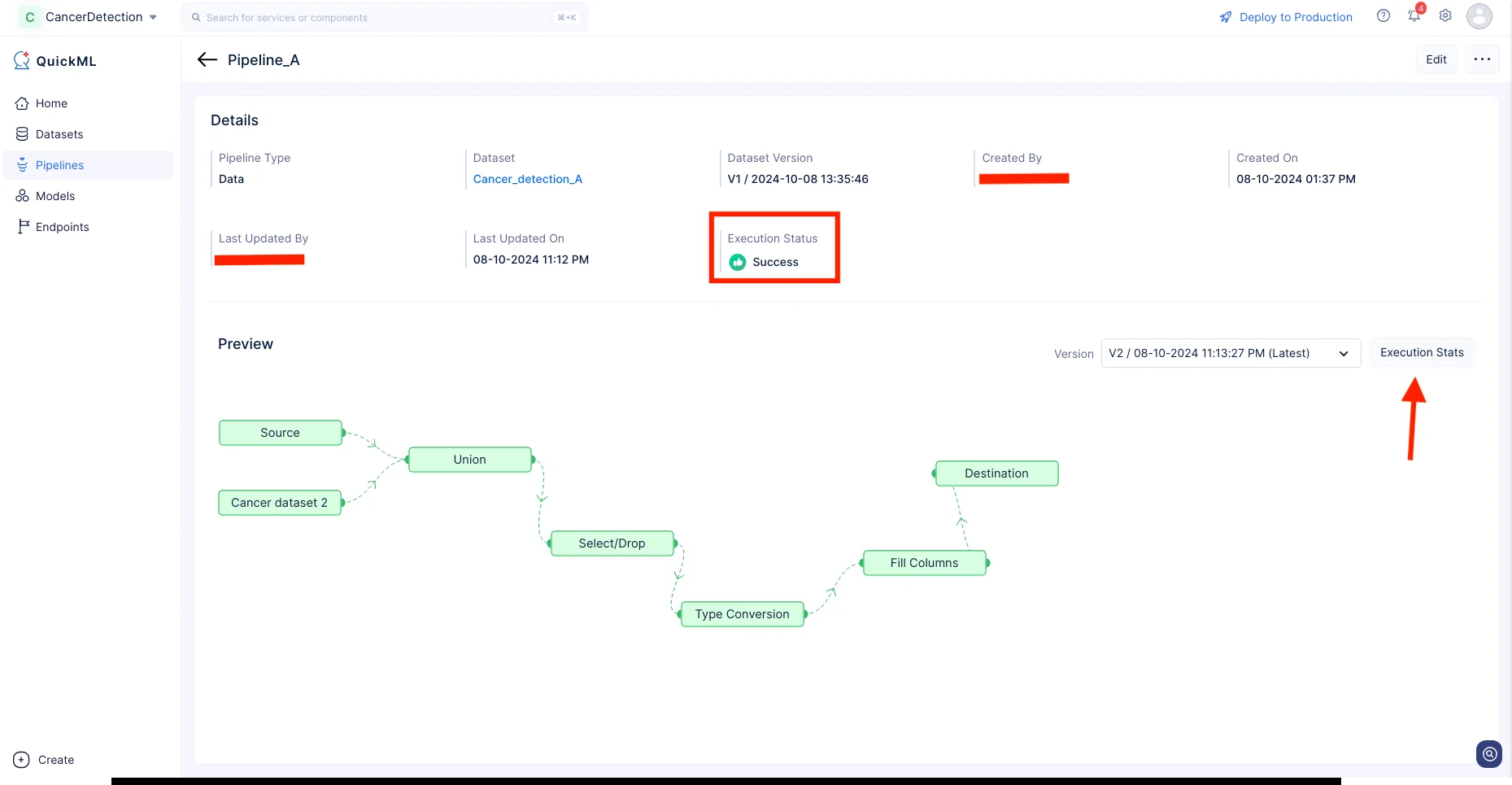
Click Execution Stats to view more details about each stage of the execution in detail.
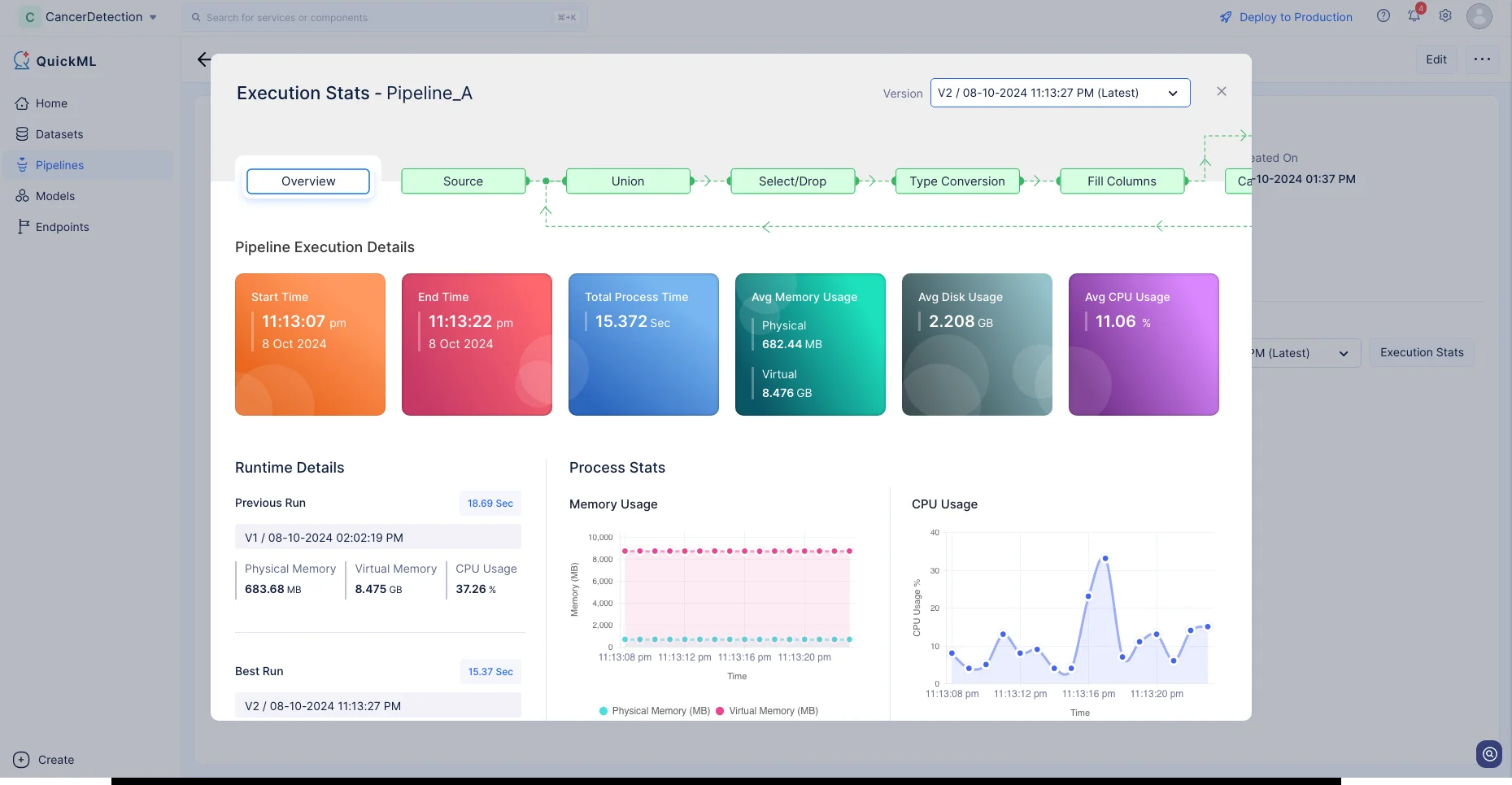
We have now prepared our dataset to develop the ML model. We will be discussing more about the ML pipeline creation in the next section.
Last Updated 2025-10-29 12:32:36 +0530 IST