Cancer Detection
Introduction
This tutorial will help you build a machine learning model using Catalyst QuickML, which analyzes and predicts breast cancer. We will provide you with sample medical datasets that can be used as data sources to the model.
In this tutorial, we will first preprocess the datasets to ensure that the data is clean and ready for training. Next, we will be constructing a data pipeline to handle data transformation and a ML pipeline to train and evaluate the model. Finally, we will create an endpoint for the trained model, which allows external applications to interact with the model and receive real-time predictions for breast cancer.
The Cancer Detection ML model is built using the following Catalyst service:
Catalyst QuickML : Using this service, we will first preprocess the sample dataset by implementing node operations on them and constructing the data pipeline. This preprocessed data will be used to a create ML model by executing ML algorithms. Finally, the Cancer Detection ML model can be accessed by external applications using the endpoint URL generated in QuickML.
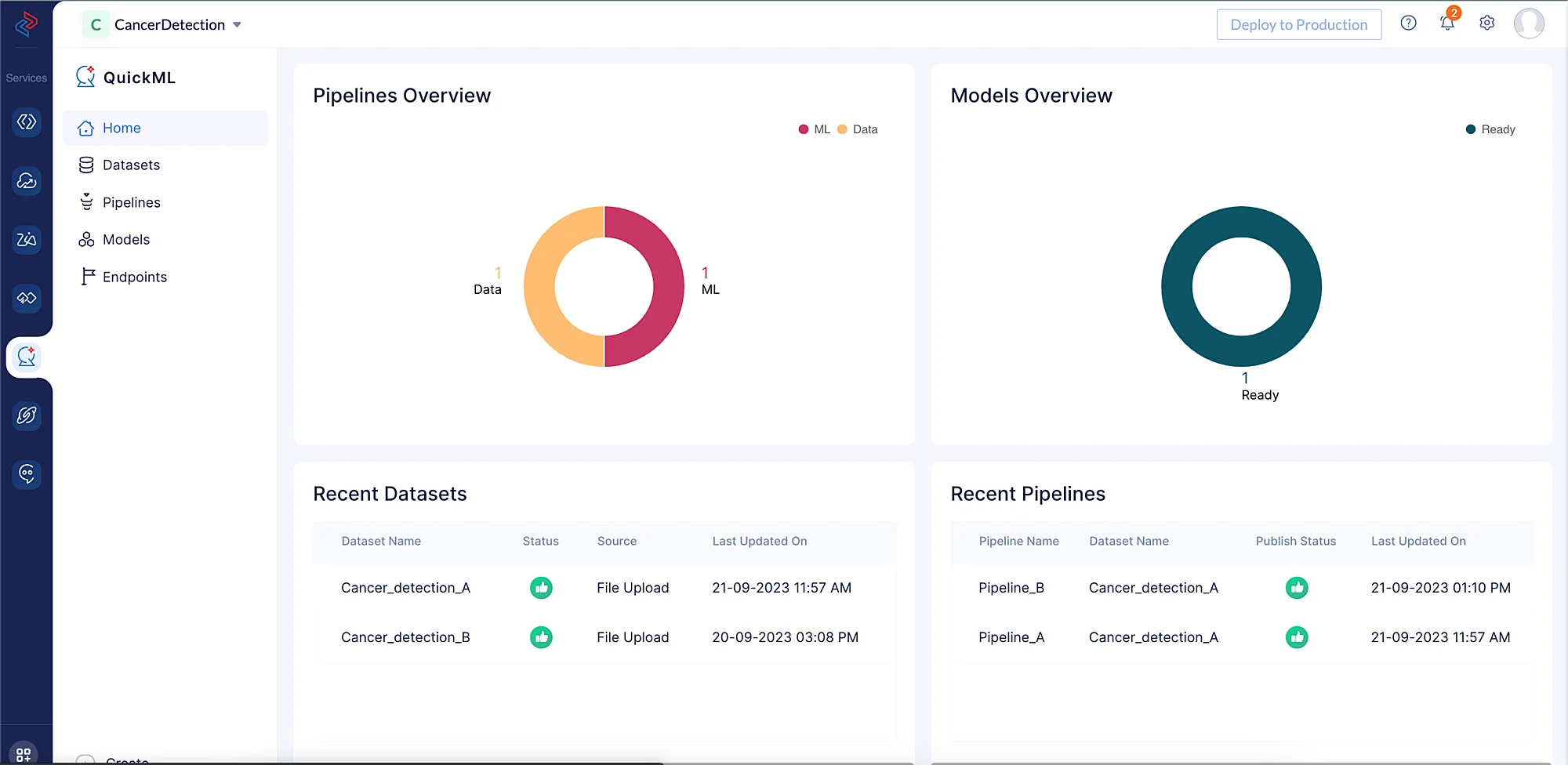
The final output after creating all the required data and ML pipelines in the Catalyst console will look like this:
Last Updated 2025-10-29 12:32:36 +0530 IST