Crear Pipeline de Datos
Ahora que hemos subido los conjuntos de datos requeridos, procederemos a crear un pipeline de datos para ellos.
-
Navega al componente Datasets en el menú izquierdo y haz clic en el conjunto de datos Cancer_detection_A.
-
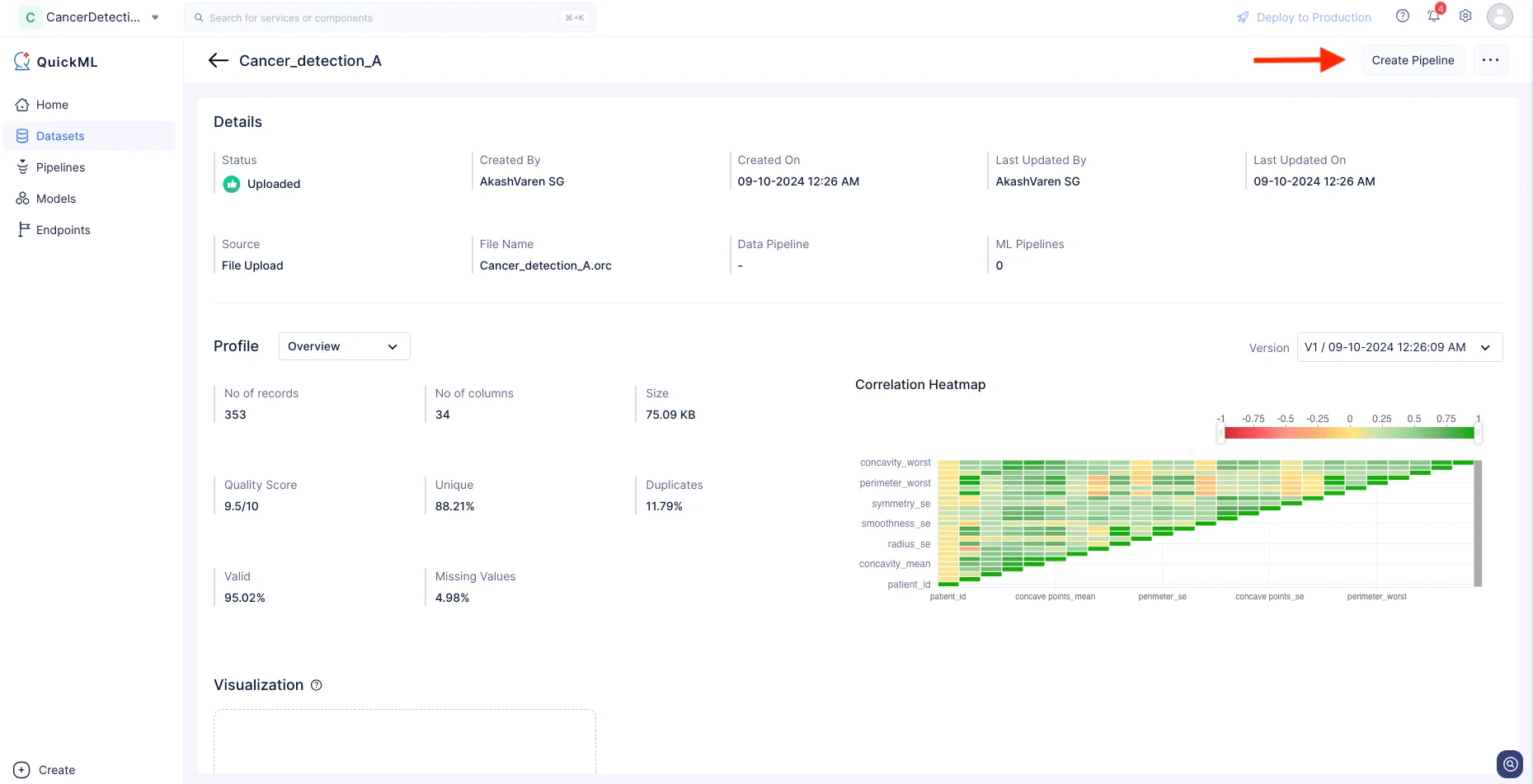
Se mostrará la página de detalles del pipeline de datos. Haz clic en Create Pipeline.
-
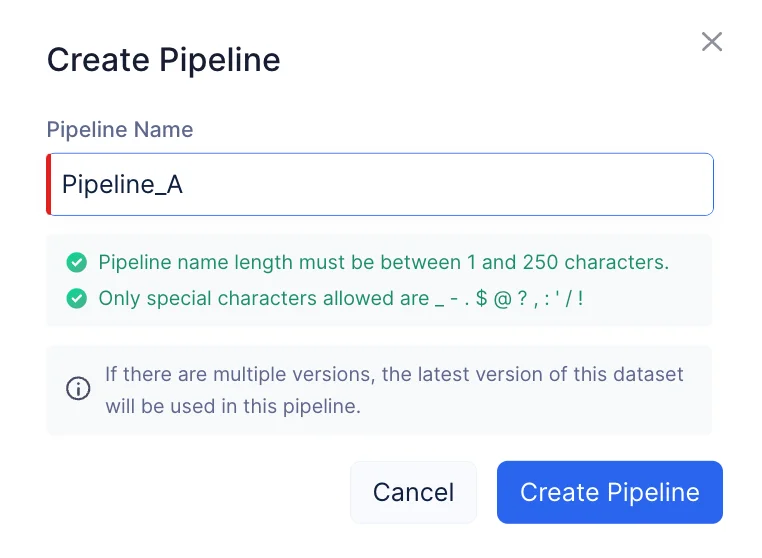
Proporciona el nombre del pipeline como “Pipeline_A” y haz clic en Create Pipeline.
Se abrirá la interfaz del Pipeline Builder, como se muestra en la captura de pantalla a continuación.
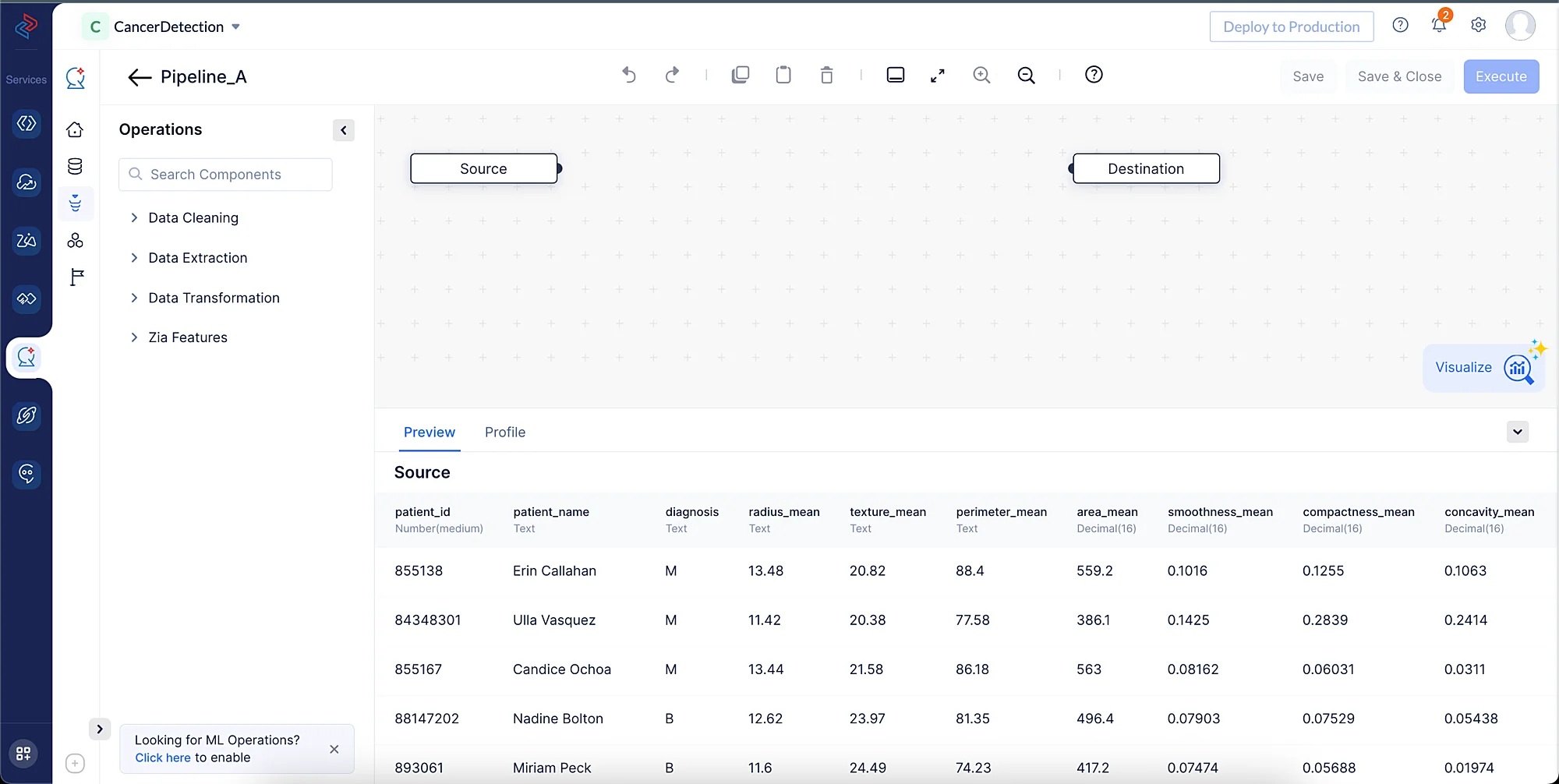
Realizaremos el siguiente conjunto de operaciones de preprocesamiento de datos para limpiar, refinar y transformar los conjuntos de datos, y luego ejecutaremos el pipeline de datos. Cada una de estas operaciones involucra nodos de datos individuales que se usan para construir el pipeline.
Dado que tenemos dos conjuntos de datos, primero necesitaremos fusionarlos antes del proceso de entrenamiento. Asegúrate de seguir los pasos listados a continuación para fusionar los dos conjuntos de datos:
-
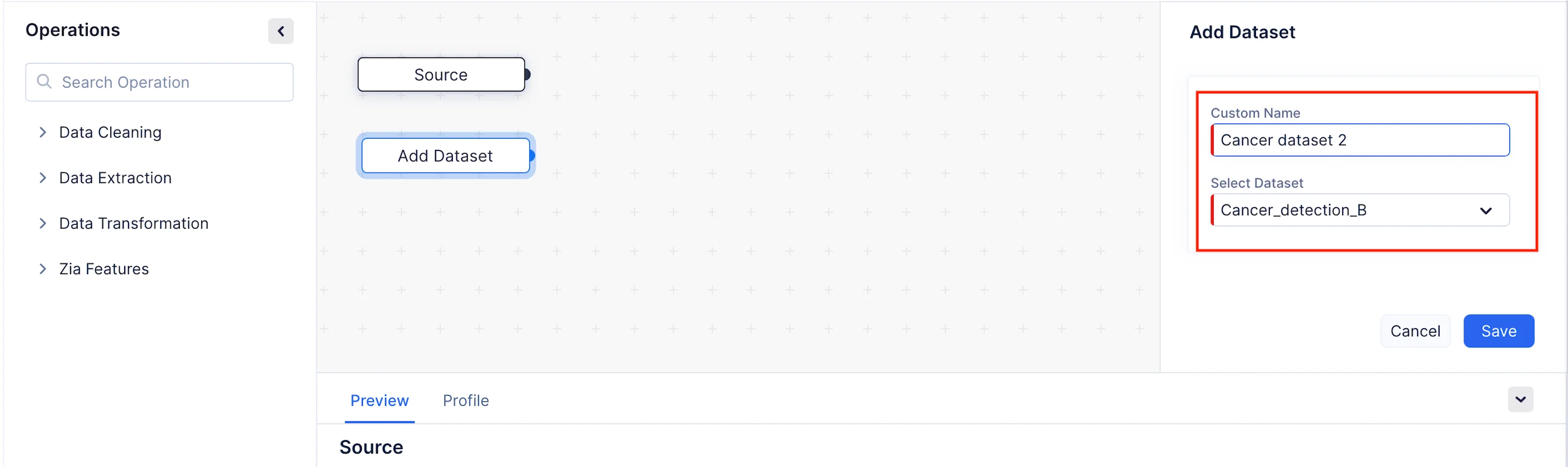
En el menú Operations, expande el componente Data Extraction. Arrastra y suelta el nodo Add Dataset en el Pipeline Builder, como se muestra en la captura de pantalla a continuación. Se puede dar un nombre personalizado para el nodo en la sección Custom Name. Aquí lo hemos nombrado como Cancer dataset 2.
-
Ahora configuraremos los detalles del nodo en la sección Add Dataset en el panel derecho. En nuestro caso, necesitaremos fusionar el conjunto de datos Cancer_detection_B con el conjunto de datos Cancer_detection_A. Elige Cancer_detection_B del menú desplegable Select Dataset y haz clic en Save.
-
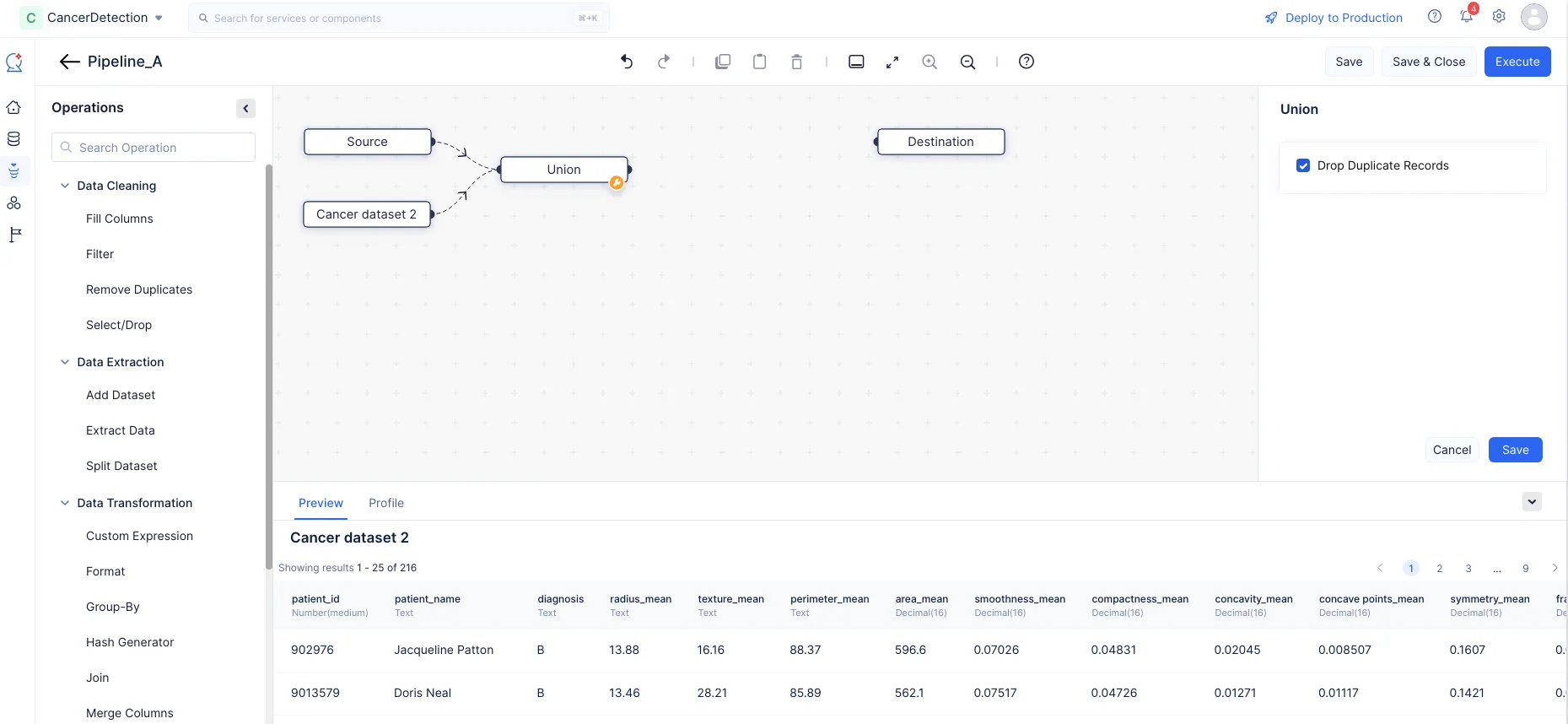
Expande el componente Data Transformation, arrastra y suelta el nodo Union en el Pipeline Builder. Realiza una conexión entre los nodos como se muestra en la captura de pantalla a continuación uniendo los enlaces entre los dos nodos.
-
En la sección Union en el panel derecho, elige Drop Duplicate Records y haz clic en Save.
Después de combinar los conjuntos de datos, necesitaremos seleccionar los campos requeridos en el conjunto de datos fusionado para entrenarlos posteriormente.
-
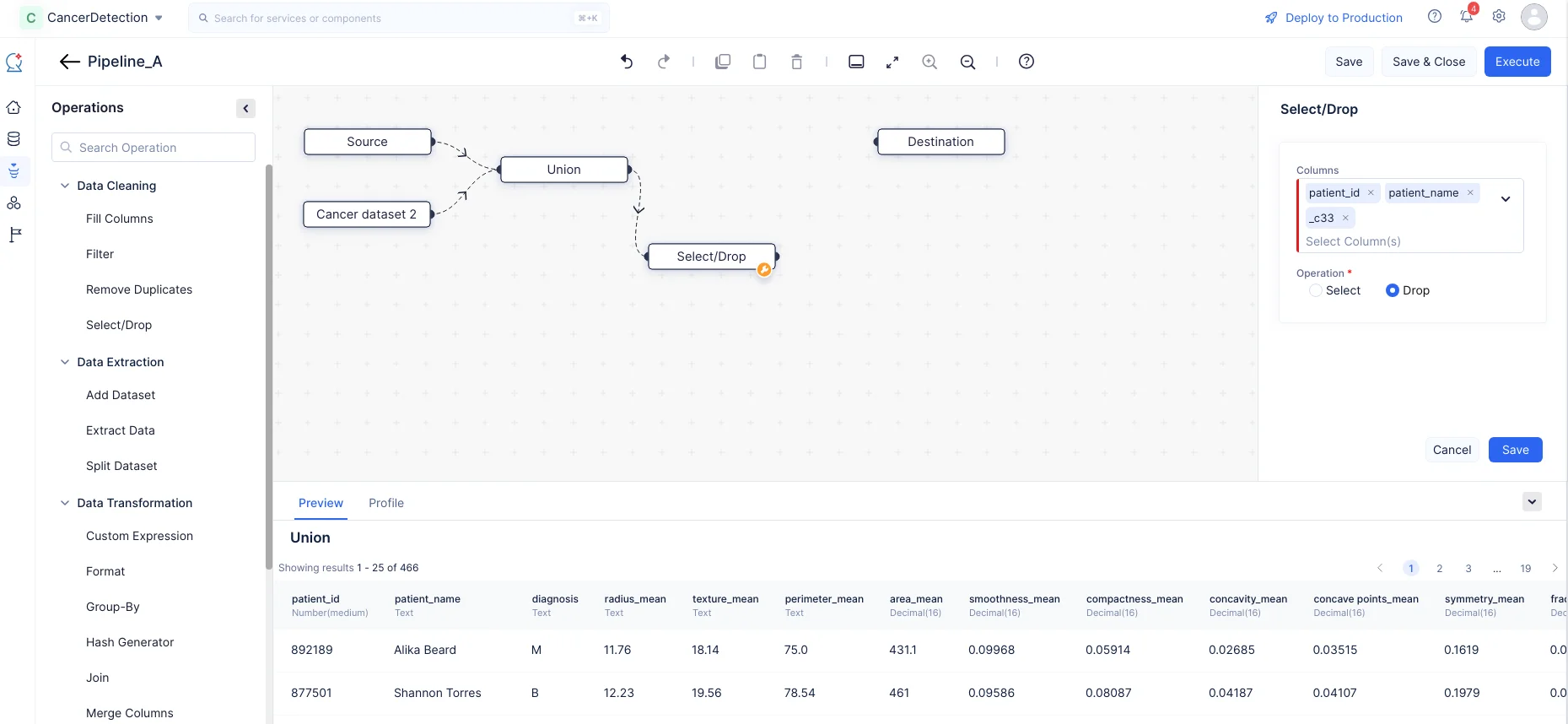
Expande el componente Data Cleaning en el menú Operations. Arrastra y suelta el nodo Select/Drop en el Pipeline Builder y realiza una conexión con el nodo Union.
-
En la sección Select/Drop en el panel derecho, selecciona las columnas “patient_id”, “patient_name” y “_c33”, elige la operación “Drop” para eliminar las columnas del conjunto de datos fusionado, luego haz clic en Save. En nuestro caso, estas columnas son genéricas y no tienen propósito para ser entrenadas posteriormente, por lo que las estamos eliminando.
Para los tipos de datos no coincidentes en las columnas de los conjuntos de datos, utilizaremos el nodo Type Conversion para convertir los datos a los tipos apropiados. Puedes ver las columnas y sus tipos de datos en la pestaña Preview de la página de detalles del pipeline.
En nuestro conjunto de datos, las columnas “texture_mean”, “radius_mean” y “perimeter_mean” contienen valores decimales, pero están almacenadas como tipo String. Asegúrate de seguir los pasos listados a continuación para llevar a cabo el proceso de conversión:
-
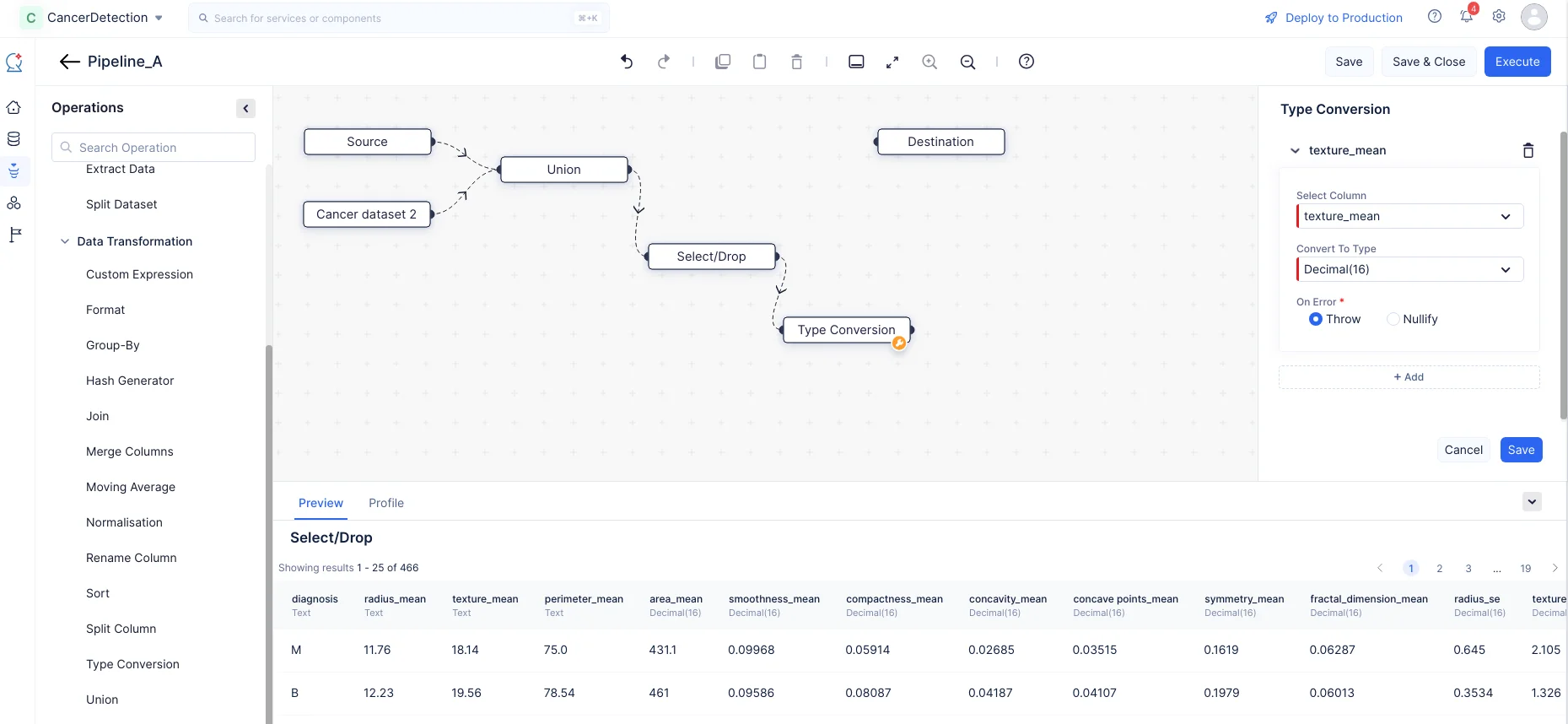
Expande el componente Data Transformation en el menú Operations. Arrastra y suelta el nodo Type Conversion en el Pipeline Builder y realiza una conexión con el nodo Select/Drop, como se muestra en la captura de pantalla a continuación.
-
En la sección Type Conversion en el panel derecho, elige la columna como texture_mean y selecciona la entrada Convert To Type como Decimal(16) del menú desplegable. Elige entre Throw y Nullify en caso de errores. De igual manera, haz clic en el botón “+ Add” y convierte el tipo de “radius_mean” y “perimeter_mean” de Text a Decimal(16).
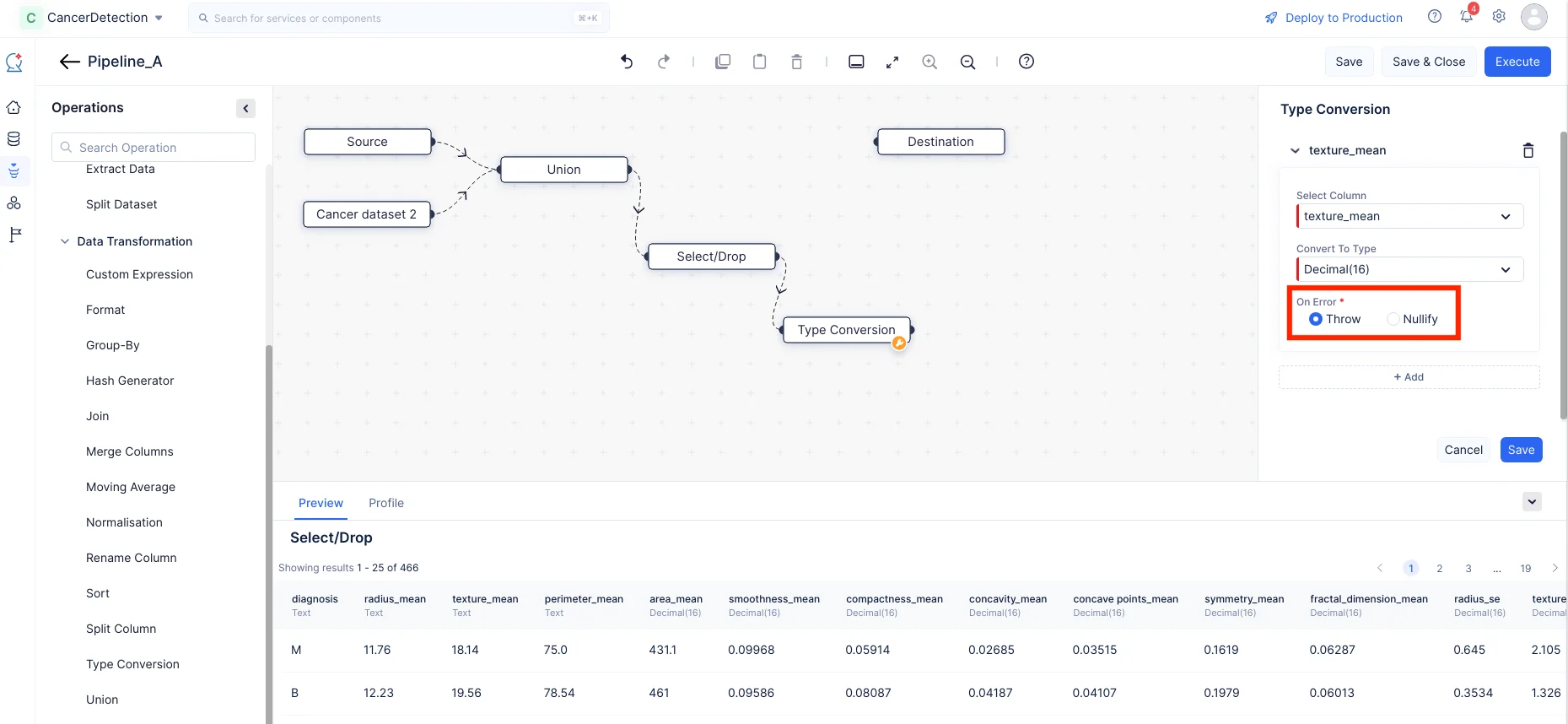
-
Haz clic en Save.
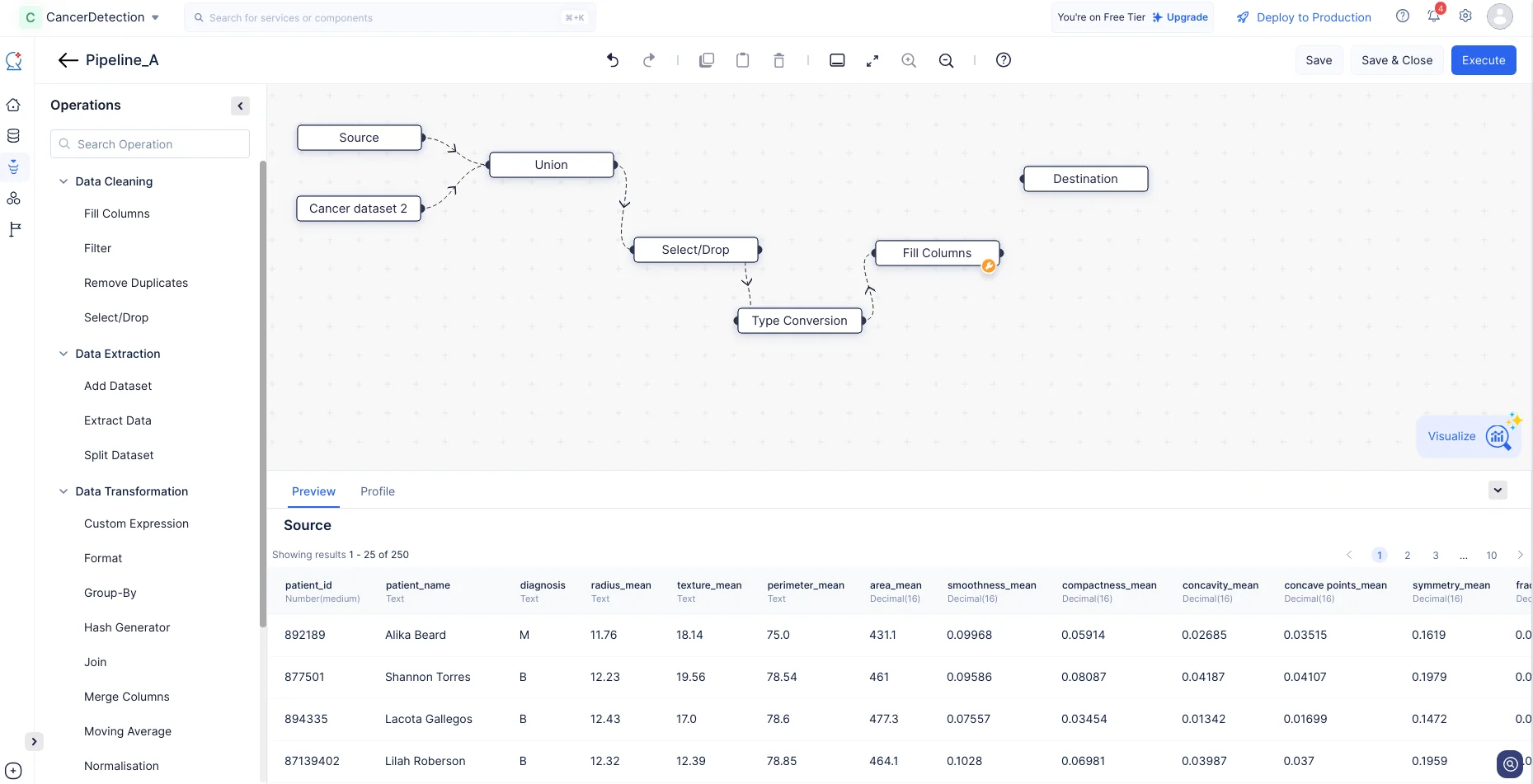
Como parte del preprocesamiento de datos, necesitaremos verificar si hay valores faltantes en alguna de las columnas de los conjuntos de datos y completarlos. Utilizaremos el nodo Fill Columns para ejecutar esta operación.
-
Expande el componente Data Cleaning en el menú Operations. Arrastra y suelta el nodo Fill Columns en el Pipeline Builder y realiza una conexión con el nodo Type Conversion, como se muestra en la captura de pantalla a continuación.
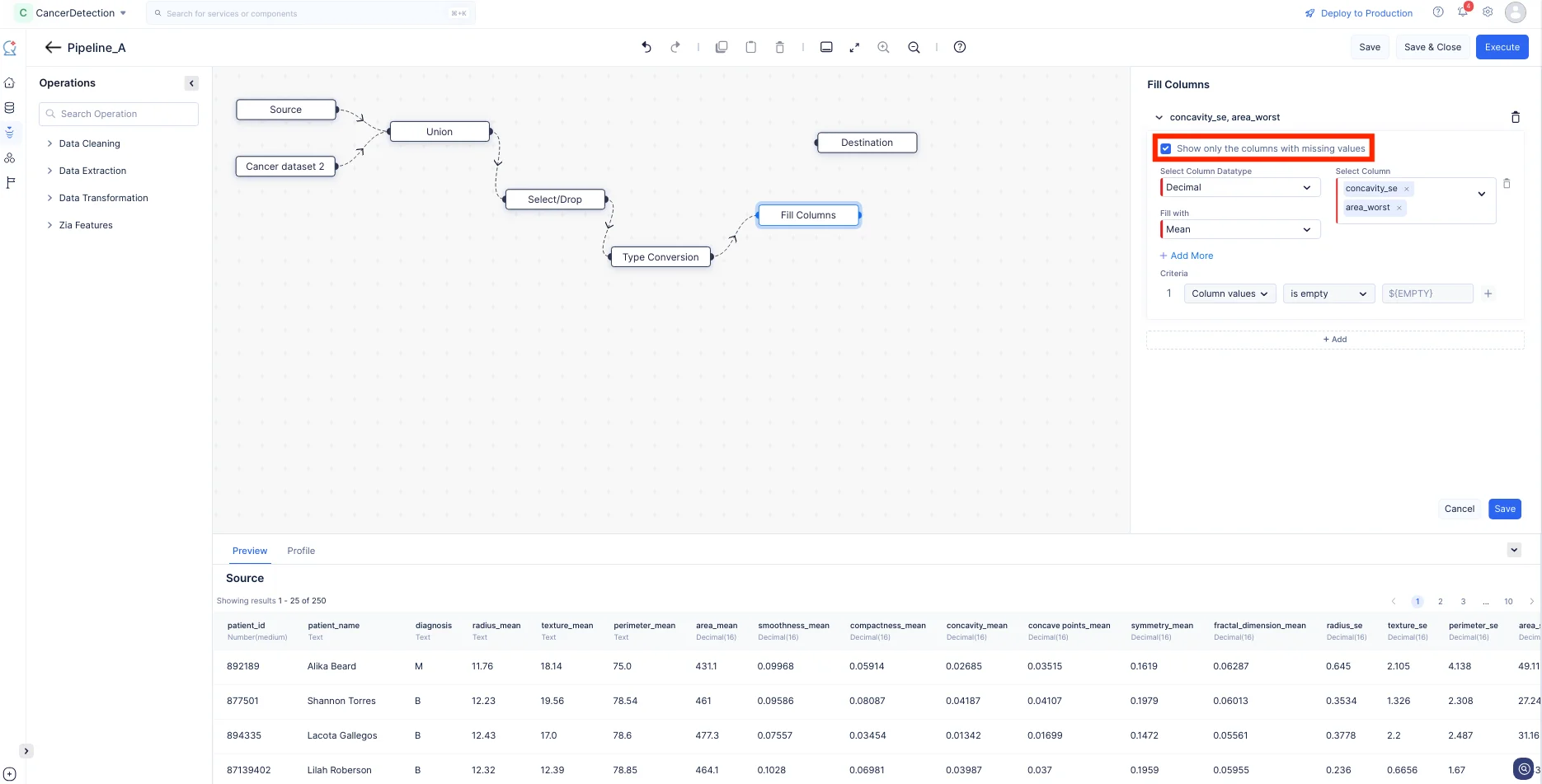
-
Habilita Show only the columns with missing values para seleccionar solo las columnas que tienen registros vacíos, luego selecciona las columnas que deseas completar con un valor personalizado, aquí seleccionamos “concavity_se” y “area_worst”, elige la entrada Fill with como “Mean” y haz clic en Save. Esto completa los valores vacíos en los datos de la columna con el valor medio de las columnas particulares.
Ahora, hemos configurado los nodos requeridos para este tutorial. Finalmente, realiza una conexión entre el último nodo configurado (es decir, Fill Columns) y el nodo Destination.
Haz clic en Execute.
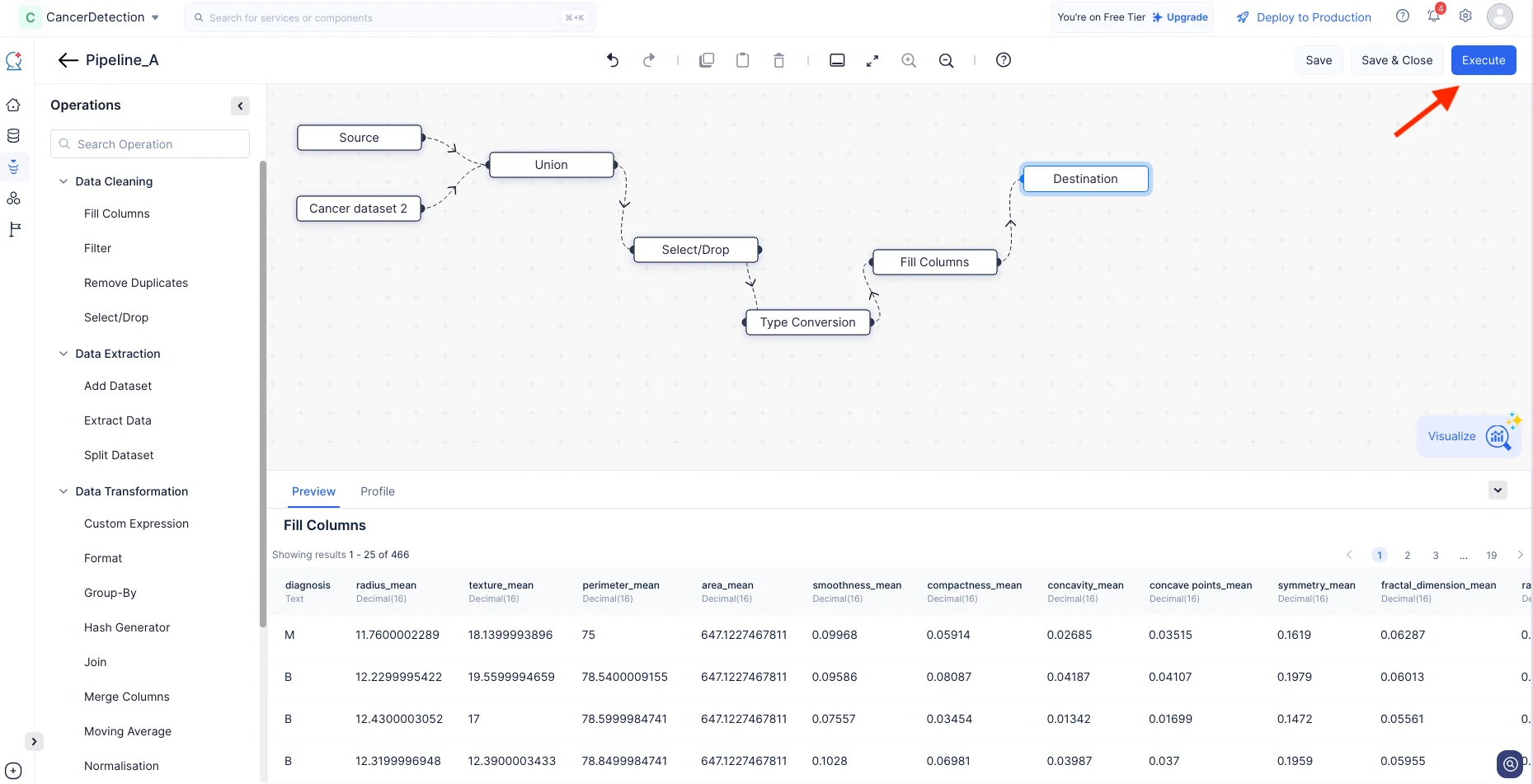
El pipeline de datos comenzará la ejecución y el estado de la ejecución se mostrará en la página de detalles del pipeline como se muestra en la captura de pantalla a continuación. Una vez que el pipeline haya completado la ejecución, el estado de ejecución indicará “Success”.
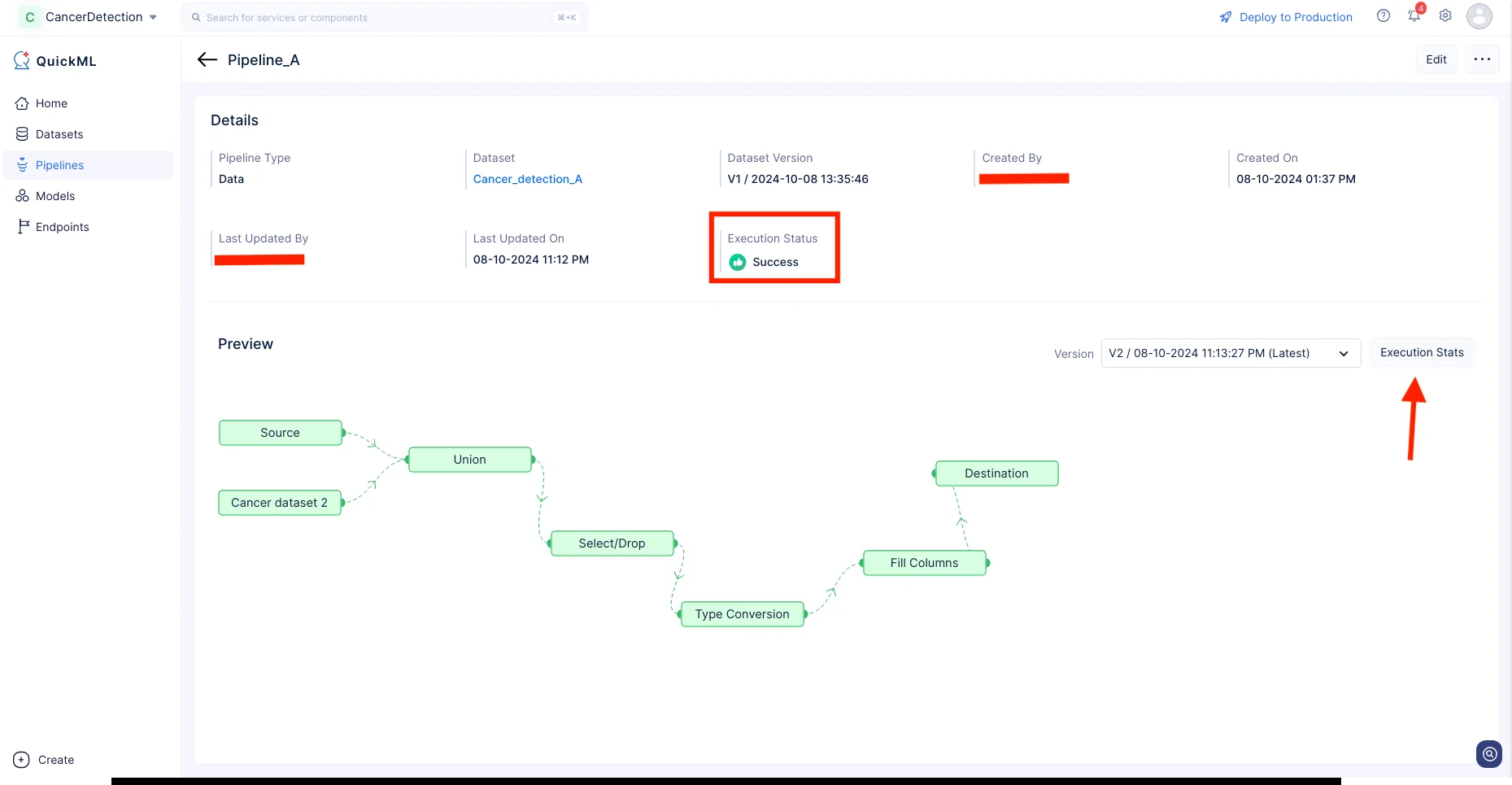
Haz clic en Execution Stats para ver más detalles sobre cada etapa de la ejecución en detalle.
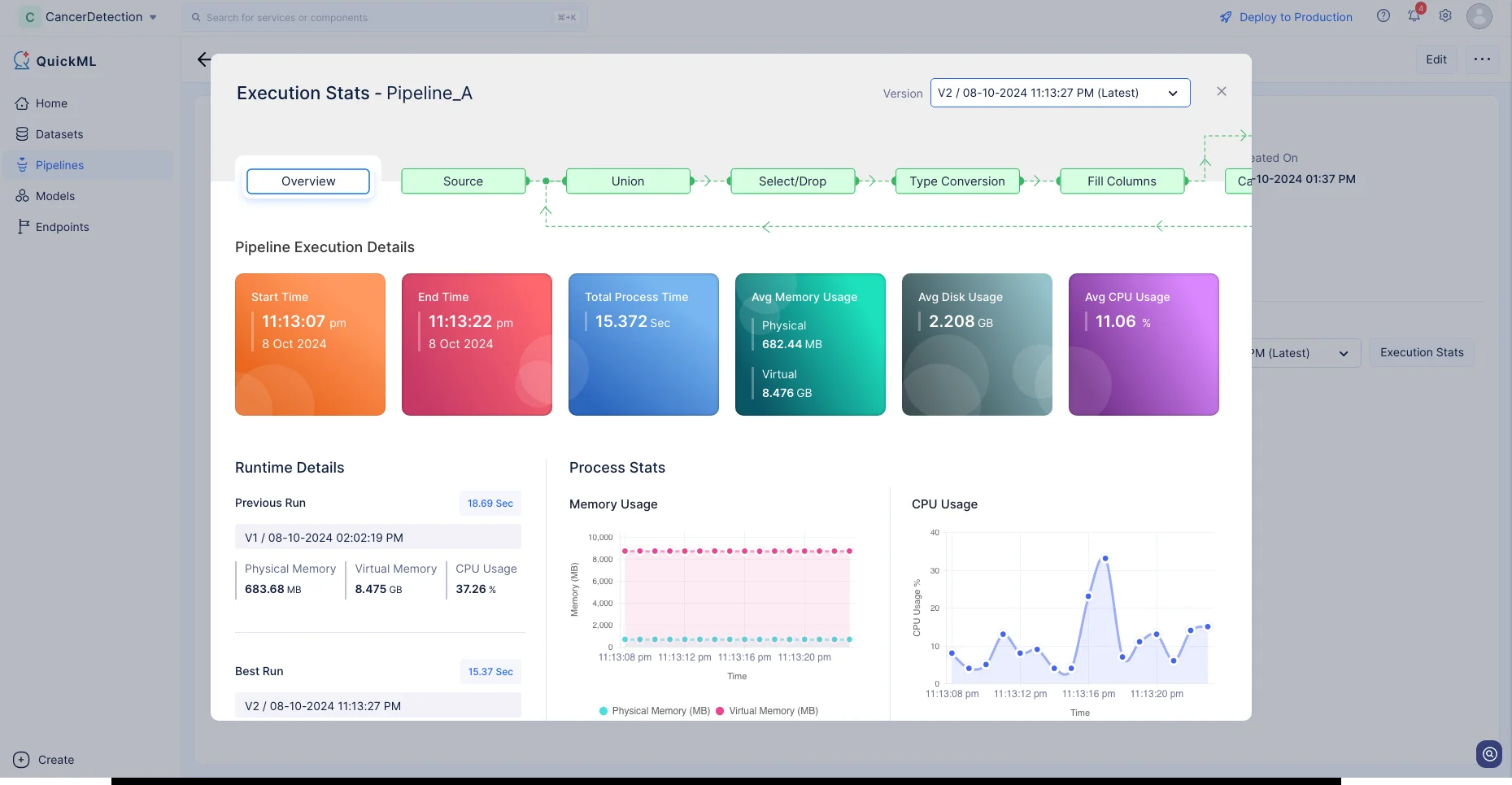
Ahora hemos preparado nuestro conjunto de datos para desarrollar el modelo de ML. Discutiremos más sobre la creación del pipeline de ML en la siguiente sección.
Última actualización 2026-03-20 21:51:56 +0530 IST