データパイプラインの作成
必要なデータセットのアップロードが完了したので、次にデータセットのデータパイプラインを作成します。
-
左メニューのDatasetsコンポーネントに移動し、Cancer_detection_Aデータセットをクリックします。
-
データパイプラインの詳細ページが表示されます。Create Pipelineをクリックします。
-
パイプライン名に「Pipeline_A」と入力し、Create Pipelineをクリックします。
以下のスクリーンショットに示すように、Pipeline Builderインターフェースが開きます。
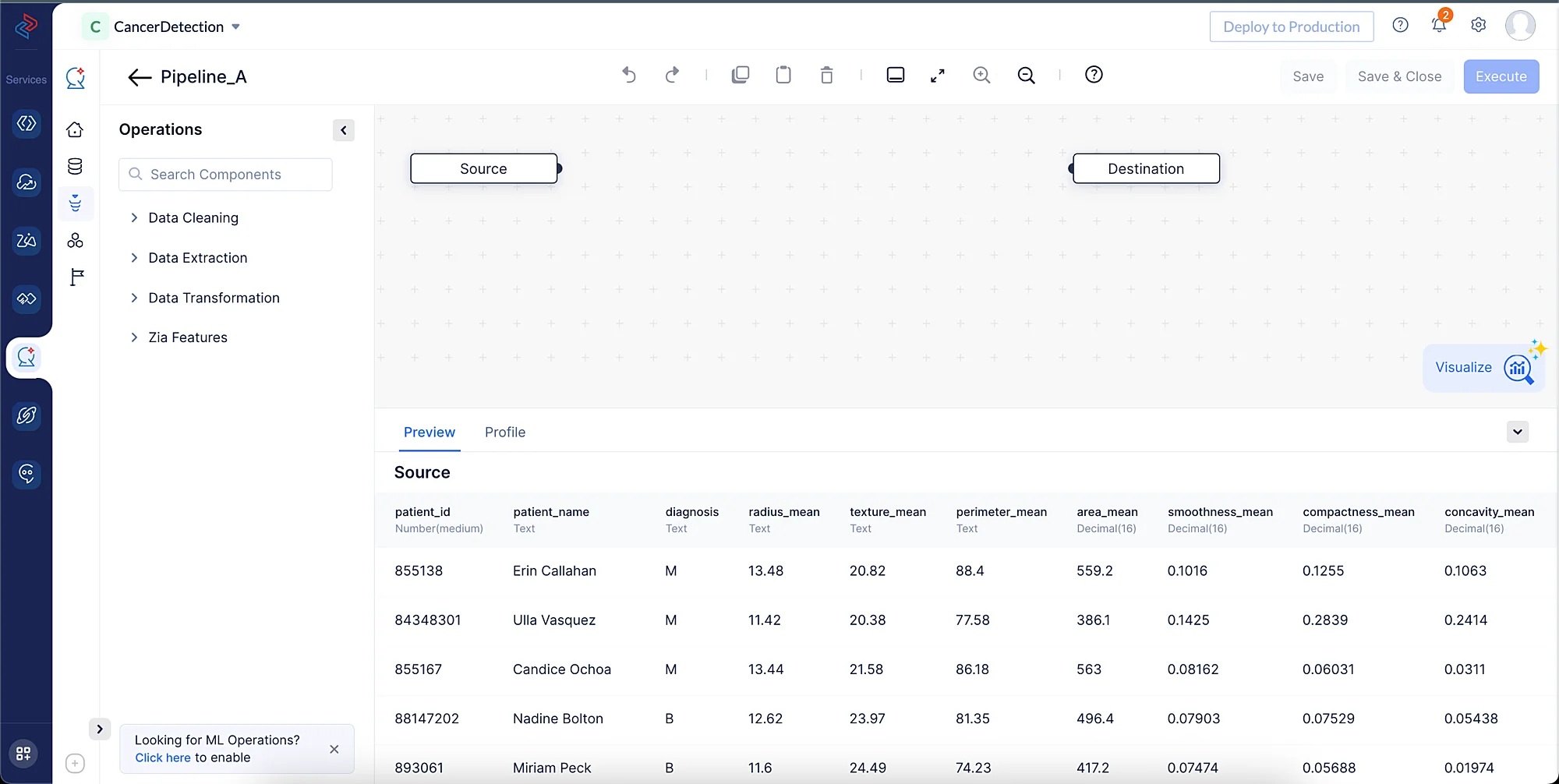
データセットのクリーニング、精製、変換を行い、データパイプラインを実行するために、以下の一連のデータ前処理操作を実行します。これらの操作はそれぞれ、パイプラインの構築に使用される個別のデータノードを含みます。
2つのデータセットがあるため、トレーニングプロセスの前にまずそれらをマージする必要があります。2つのデータセットをマージするには、以下の手順に従ってください。
-
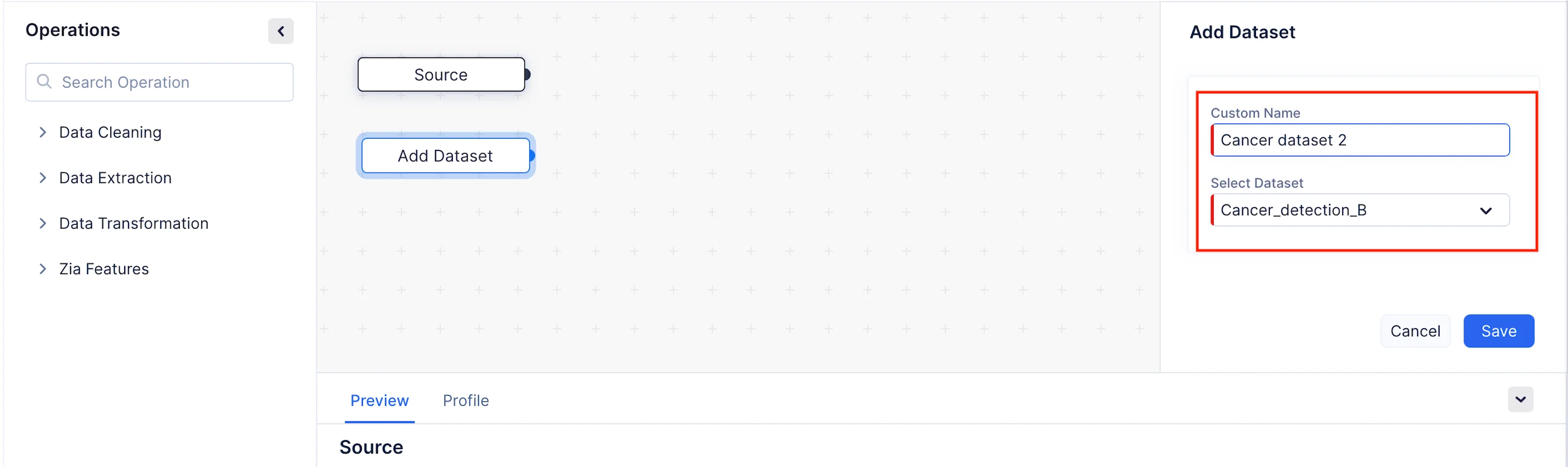
Operationsメニューで、Data Extractionコンポーネントを展開します。以下のスクリーンショットに示すように、Add DatasetノードをPipeline Builderにドラッグ&ドロップします。Custom Nameセクションでノードのカスタム名を設定できます。ここではCancer dataset 2としています。
-
次に、右パネルのAdd Datasetセクションでノードの詳細を設定します。今回のケースでは、Cancer_detection_BデータセットをCancer_detection_Aデータセットとマージする必要があります。Select DatasetドロップダウンからCancer_detection_Bを選択し、Saveをクリックします。
-
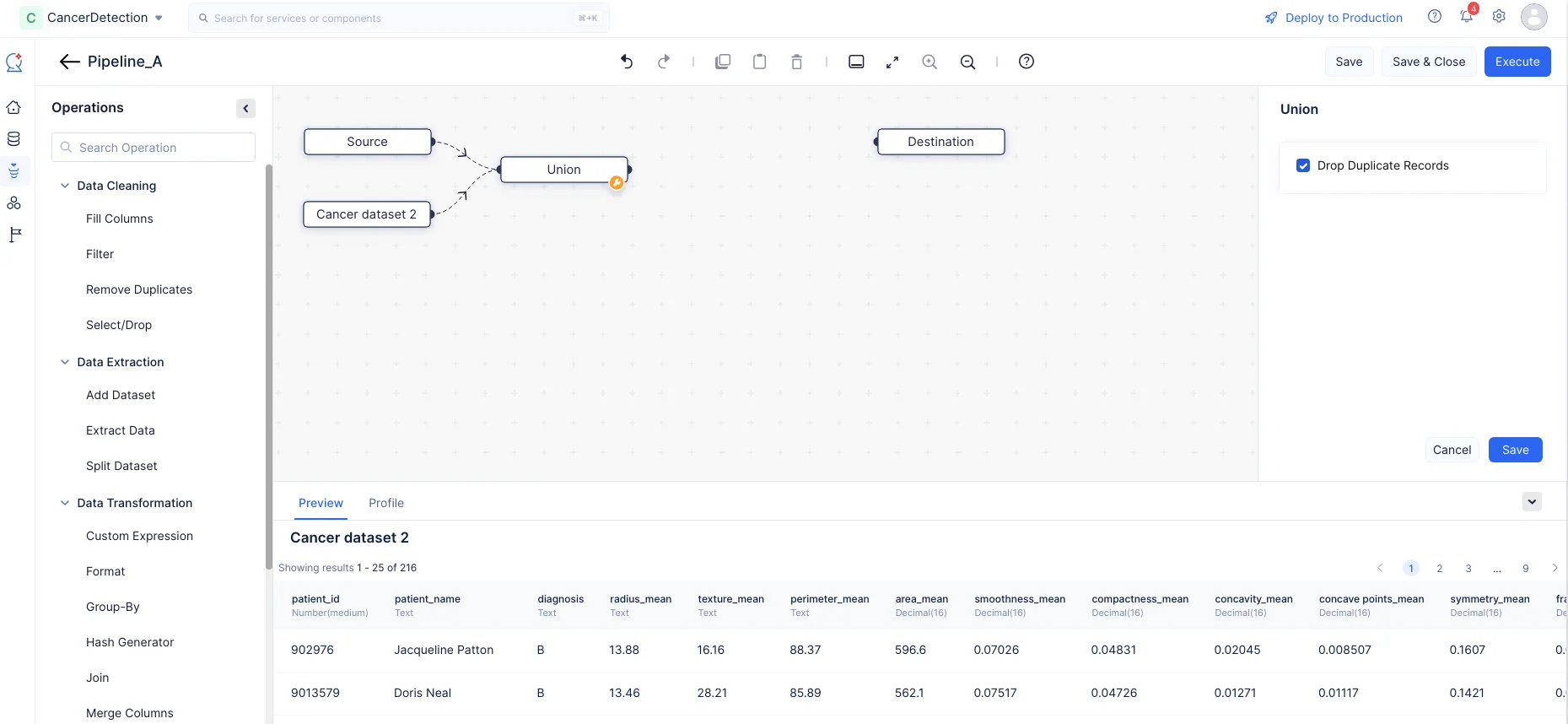
Data Transformationコンポーネントを展開し、UnionノードをPipeline Builderにドラッグ&ドロップします。以下のスクリーンショットに示すように、2つのノード間のリンクを結合してノード間の接続を作成します。
-
右パネルのUnionセクションで、Drop Duplicate Recordsを選択し、Saveをクリックします。
データセットの結合後、マージされたデータセットからトレーニングに必要なフィールドを選択する必要があります。
-
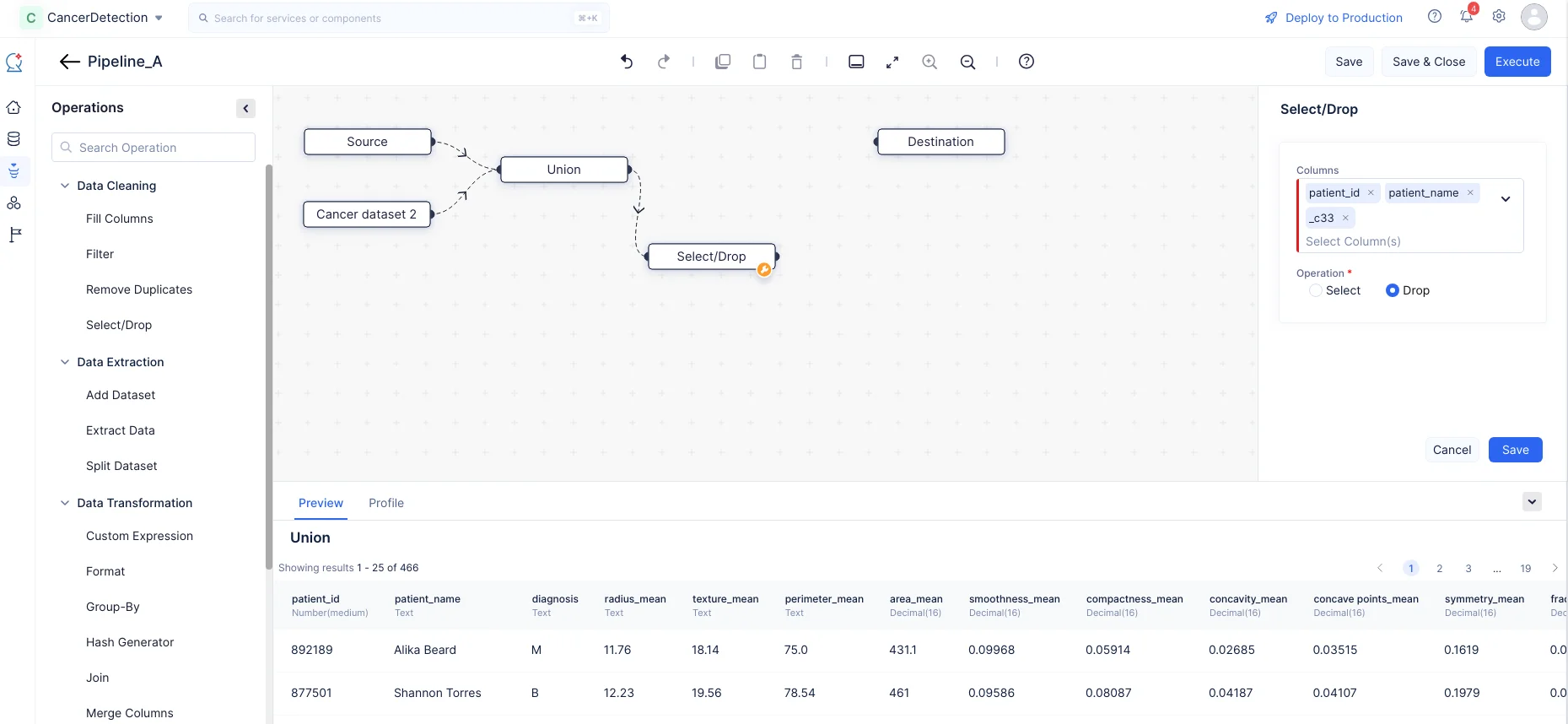
OperationsメニューのData Cleaningコンポーネントを展開します。**Select/Drop**ノードをPipeline Builderにドラッグ&ドロップし、Unionノードと接続します。
-
右パネルのSelect/Dropセクションで、「patient_id」、「patient_name」、「_c33」列を選択し、操作として「Drop」を選択してマージされたデータセットからこれらの列を削除し、Saveをクリックします。今回のケースでは、これらの列は汎用的なもので、さらなるトレーニングに必要ないため削除します。
データセットの列でデータ型が一致しない場合、Type conversionノードを使用してデータを適切な型に変換します。パイプライン詳細ページのPreviewタブで列とそのデータ型を確認できます。
このデータセットでは、「texture_mean」、「radius_mean」、「perimeter_mean」列に小数値が含まれていますが、String型として格納されています。変換プロセスを実行するには、以下の手順に従ってください。
-
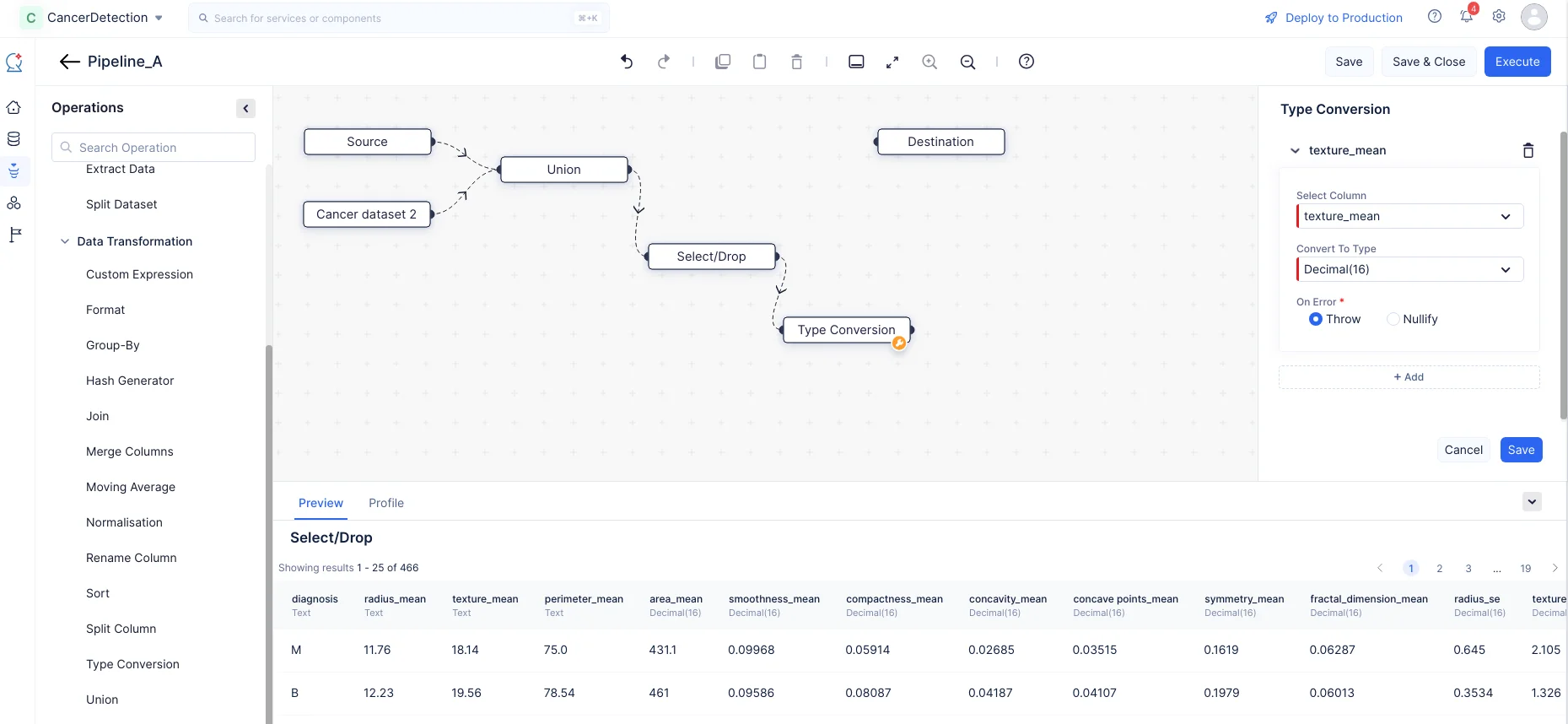
OperationsメニューのData Transformationコンポーネントを展開します。以下のスクリーンショットに示すように、Type ConversionノードをPipeline Builderにドラッグ&ドロップし、Select/Dropノードと接続します。
-
右パネルのType Conversionセクションで、列としてtexture_meanを選択し、Convert To Type入力をドロップダウンメニューからDecimal(16)に設定します。エラーが発生した場合に備えて、ThrowまたはNullifyを選択します。同様に“+ Add”ボタンをクリックして、「radius_mean」と「perimeter_mean」をTextから**Decimal(16)**に型変換します。
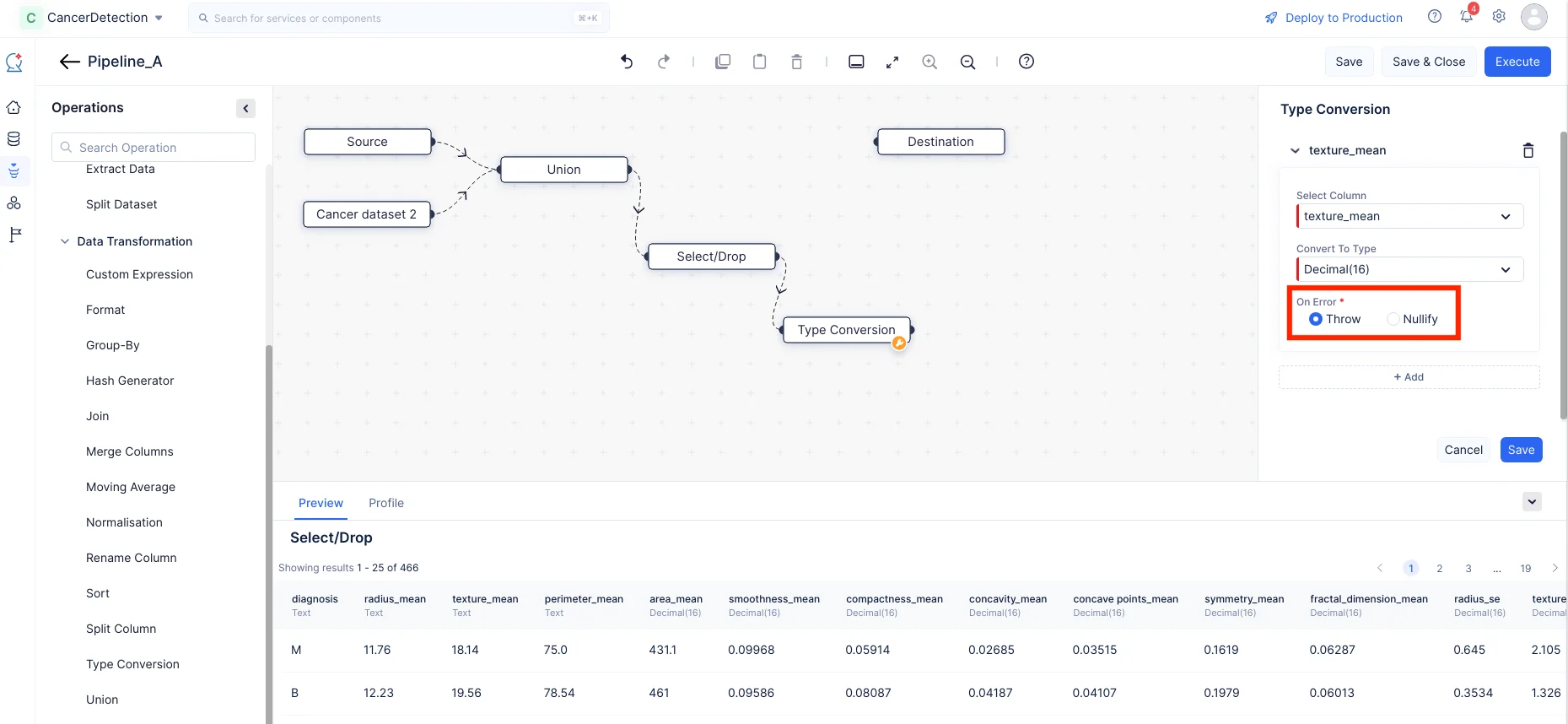
-
Saveをクリックします。
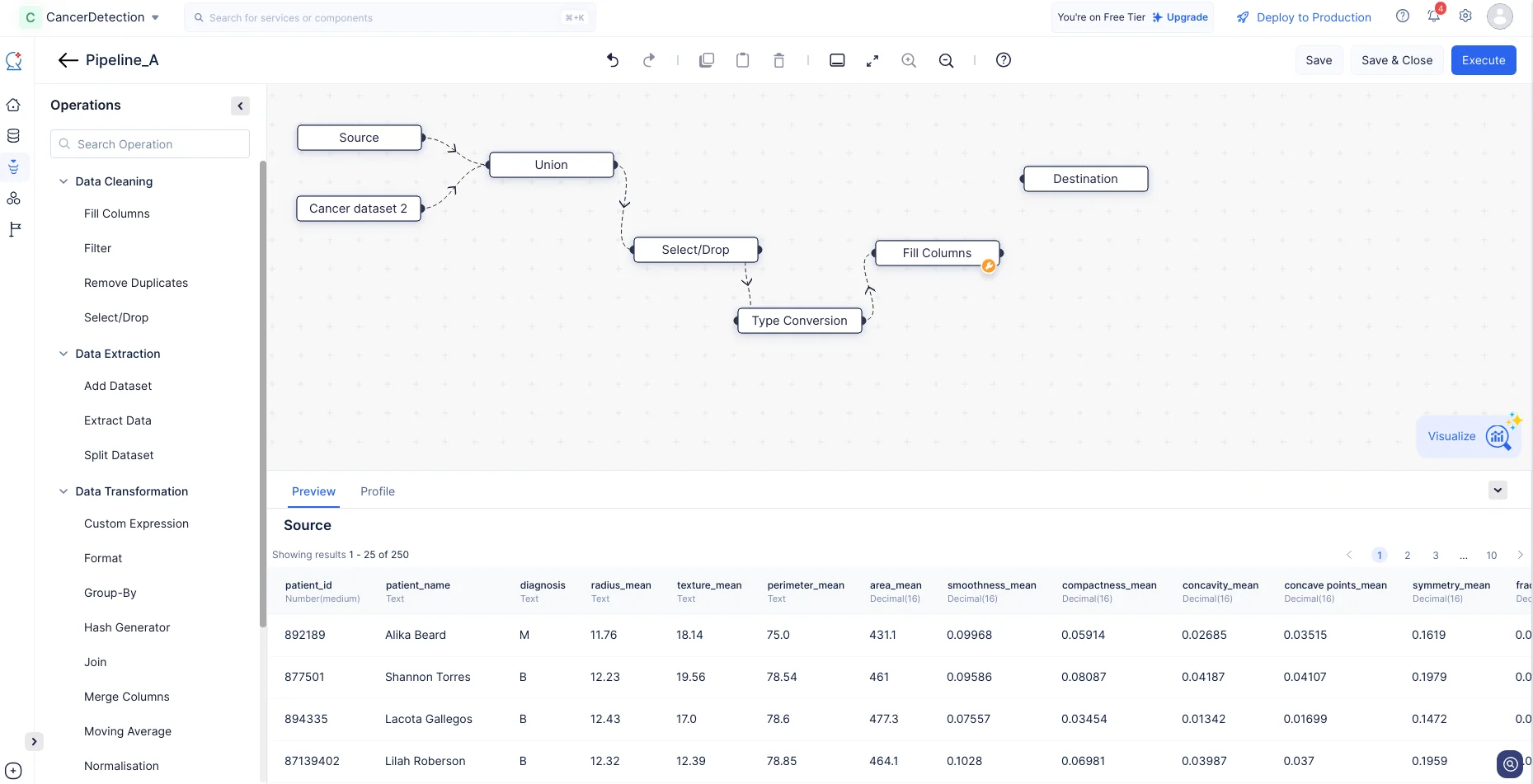
データ前処理の一環として、データセットの列に欠損値がないかを確認し、それらを補完する必要があります。この操作の実行にはFill Columnsノードを使用します。
-
OperationsメニューのData Cleaningコンポーネントを展開します。以下のスクリーンショットに示すように、Fill ColumnsノードをPipeline Builderにドラッグ&ドロップし、Type Conversionノードと接続します。
-
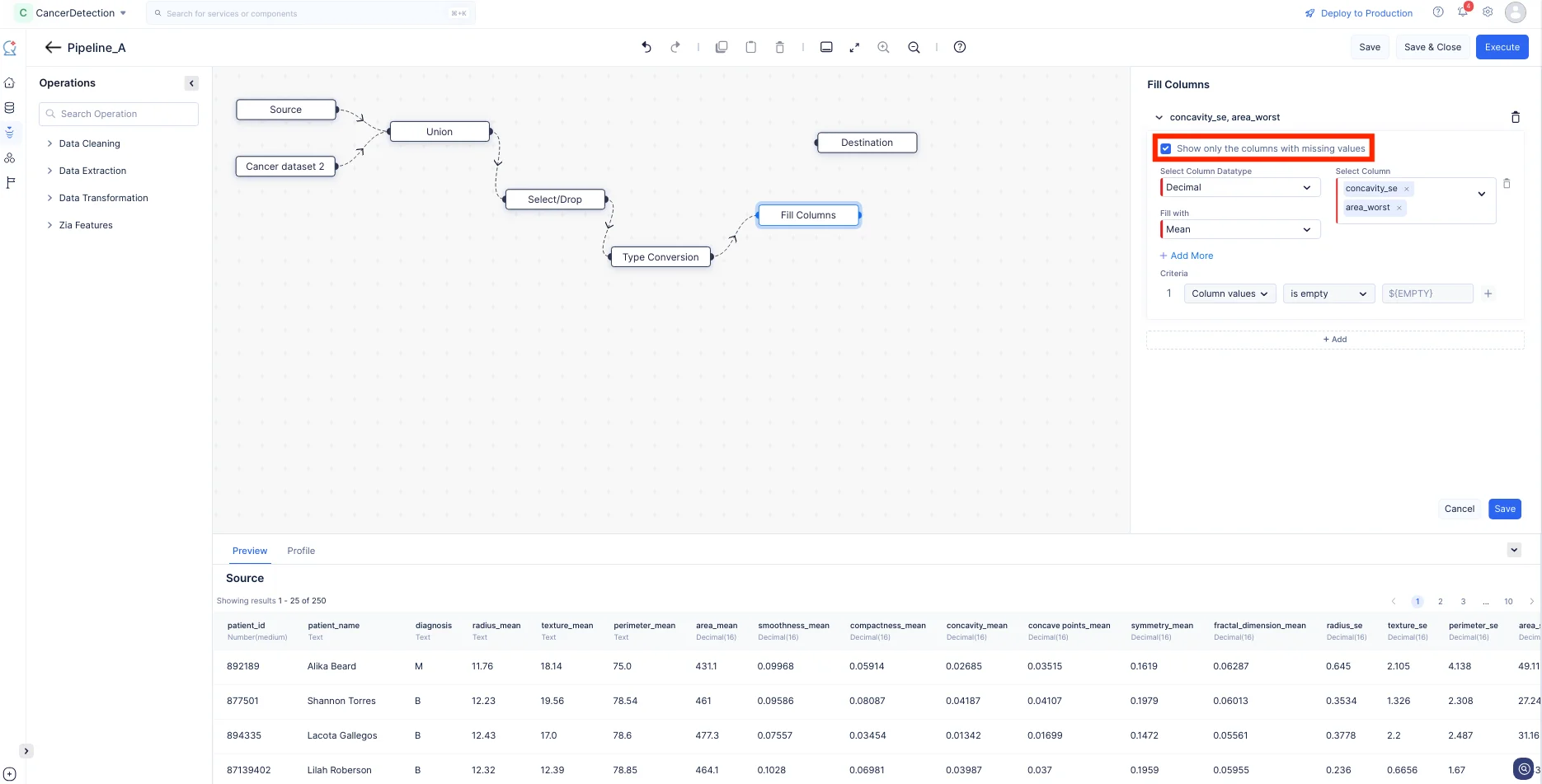
Show only the columns with missing valuesを有効にして空のレコードがある列のみを選択し、カスタム値で補完する列として「concavity_se」と「area_worst」を選択し、Fill with入力を「Mean」に設定してSaveをクリックします。これにより、列データの空の値がその列の平均値で補完されます。
これで、このチュートリアルに必要なノードの設定が完了しました。最後に、最後に設定したノード(Fill Columns)とDestinationノードを接続します。
Executeをクリックします。
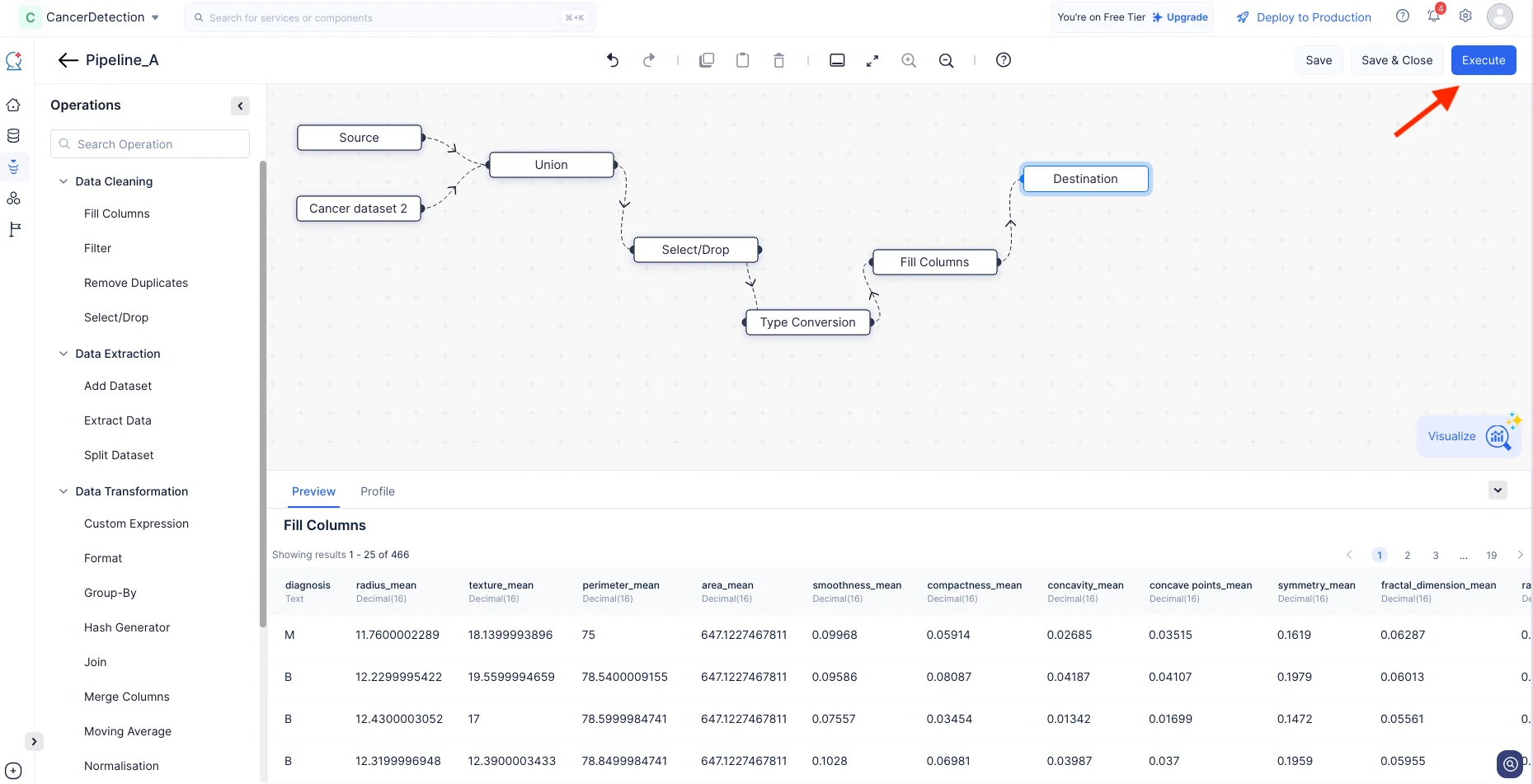
データパイプラインの実行が開始され、以下のスクリーンショットに示すように、パイプライン詳細ページに実行ステータスが表示されます。パイプラインの実行が完了すると、実行ステータスに「Success」と表示されます。
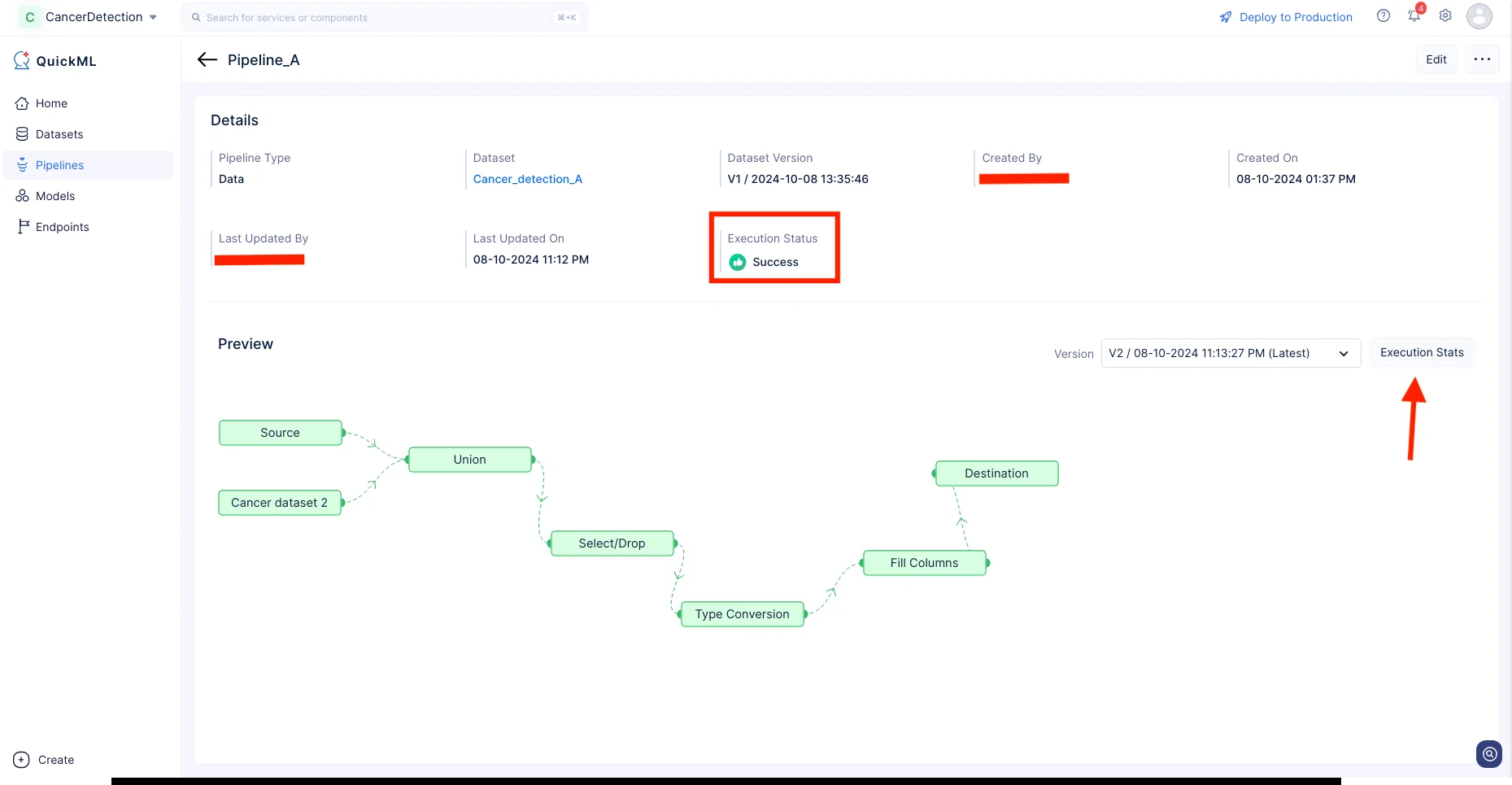
Execution Statsをクリックすると、各実行ステージの詳細を確認できます。
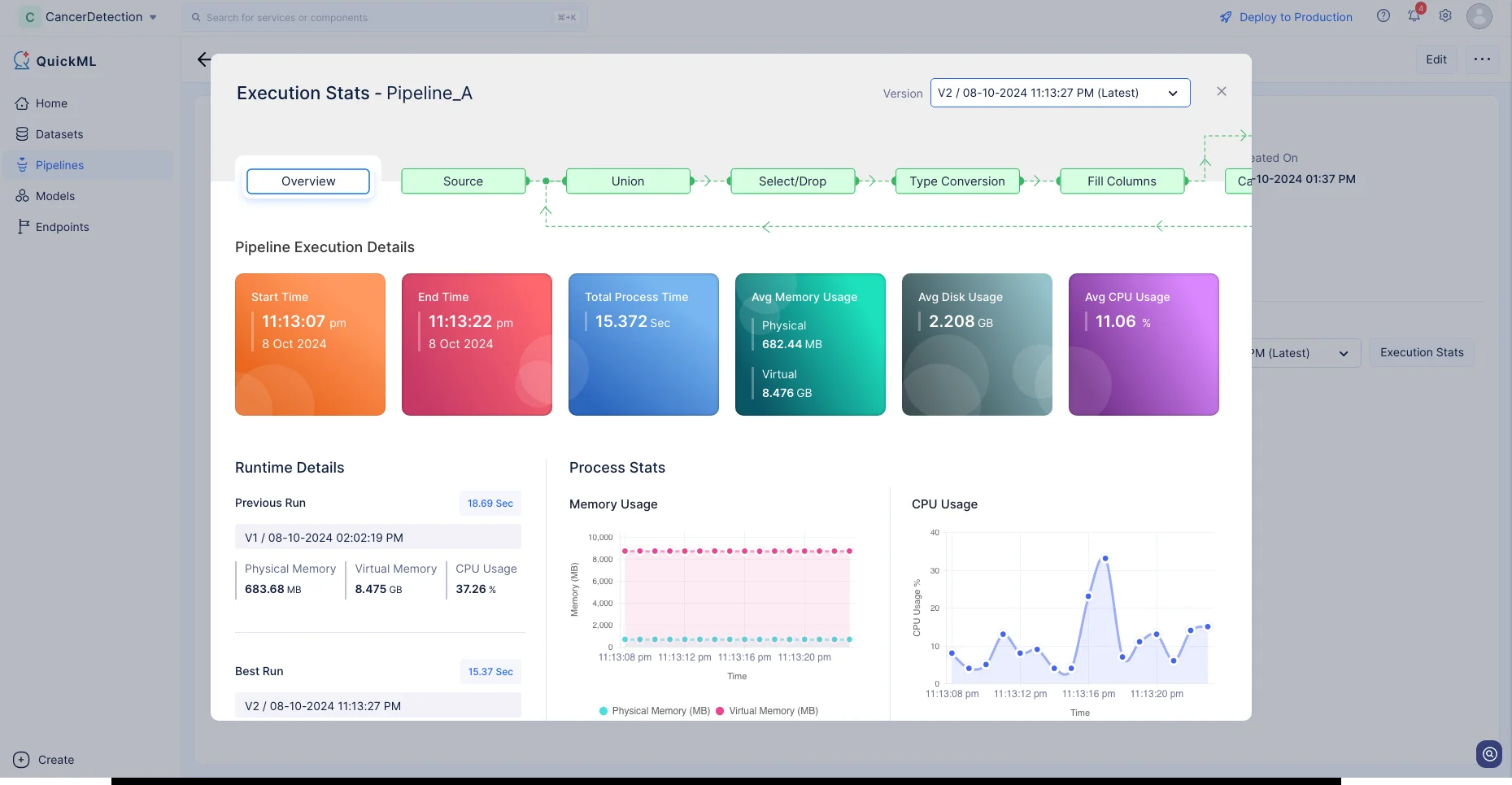
これで、MLモデルを開発するためのデータセットの準備が完了しました。次のセクションでは、MLパイプラインの作成について詳しく説明します。
最終更新日 2026-02-23 18:09:41 +0530 IST