Crear Pipeline de ML
En esta sección, construiremos un modelo de ML de predicción usando los conjuntos de datos preprocesados en la sección anterior. Los conjuntos de datos serán la entrada al ML Pipeline Builder que te permite definir la arquitectura del modelo y seleccionar una columna objetivo para la predicción.
Para crear un pipeline de ML:
-
Navega al componente Pipelines en el menú izquierdo y haz clic en Create Pipeline.
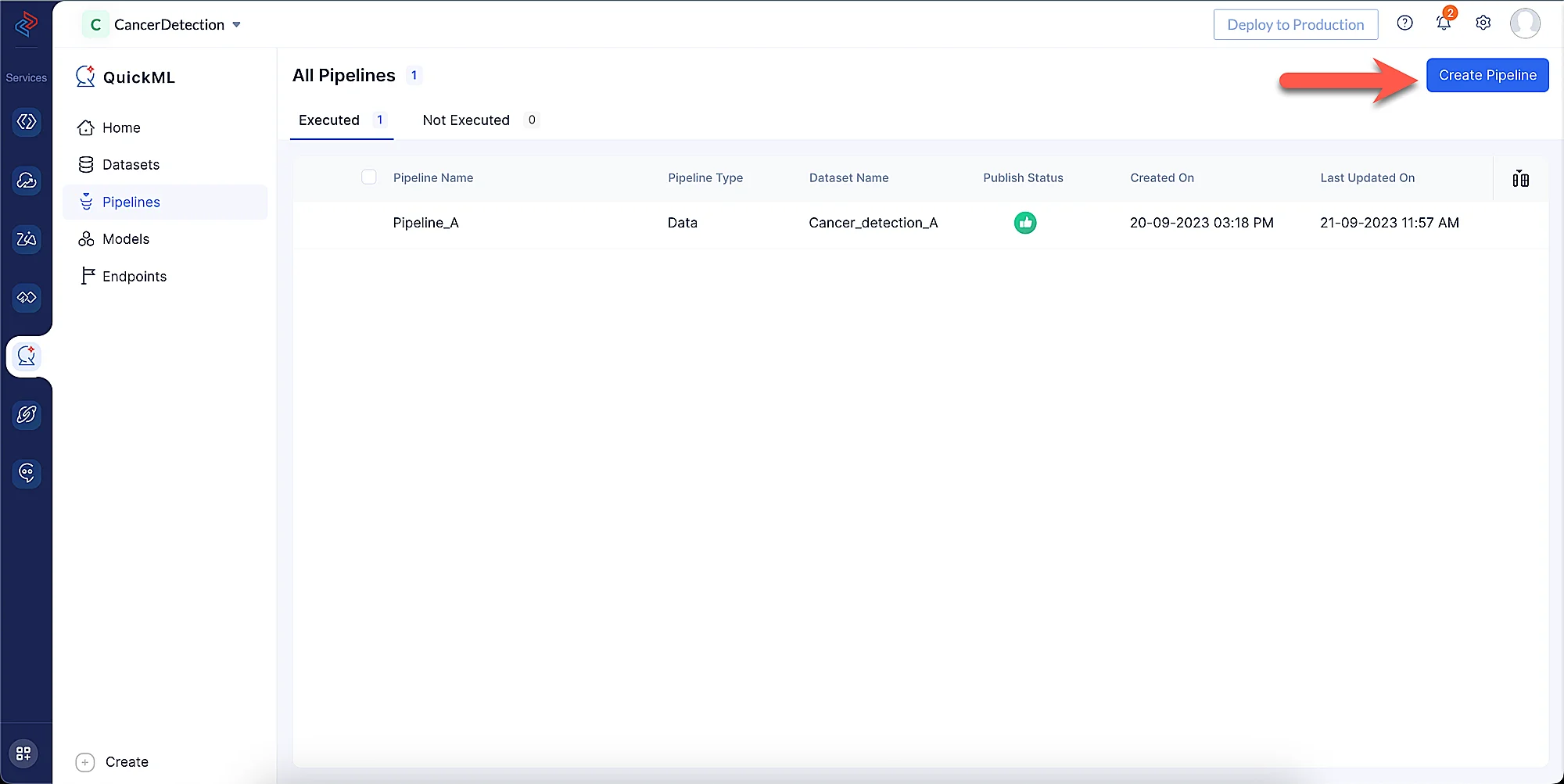
-
En la ventana emergente que aparece, selecciona Prediction como tipo de pipeline y proporciona el nombre del pipeline como “Pipeline_B” y elige el conjunto de datos de entrada como Cancer_detection_A. En nuestro caso, la columna objetivo debe ser “diagnosis”. El nombre del modelo se completará automáticamente basado en el nombre del pipeline. Haz clic en Create Pipeline.
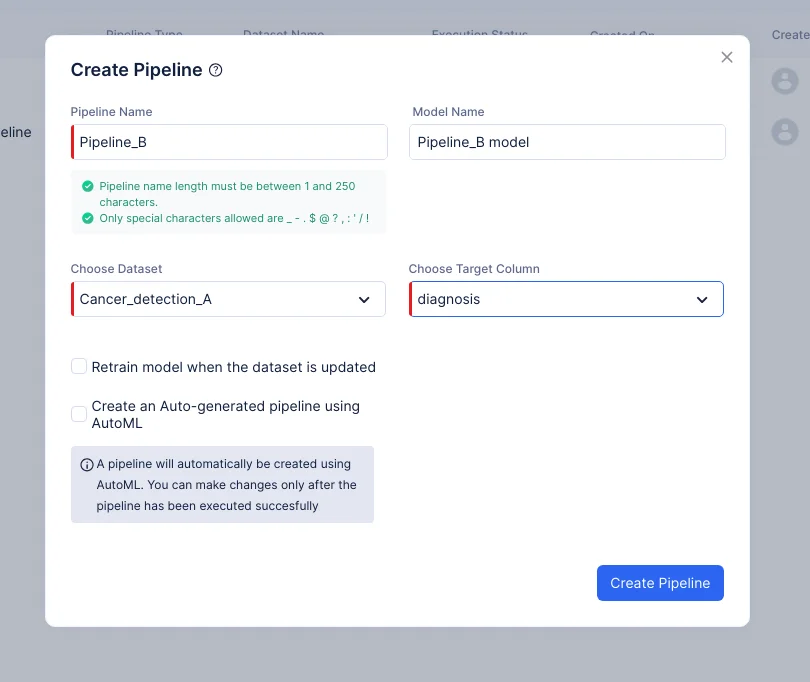
-
Se mostrará la página de detalles del pipeline, como se muestra en la captura de pantalla a continuación.
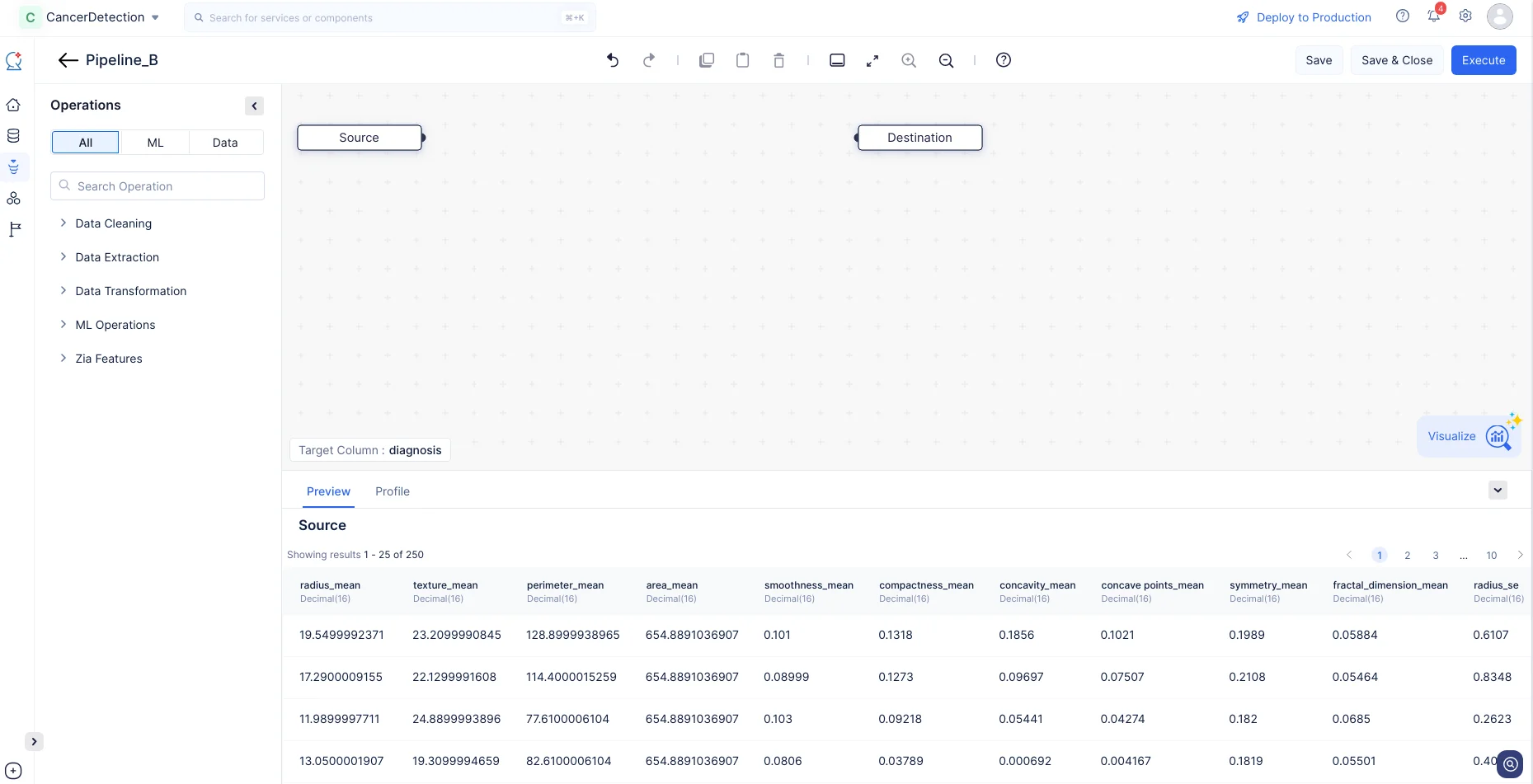
Ahora que hemos creado nuestro pipeline de ML, procederemos a configurar el pipeline definiendo los nodos en la interfaz del ML Pipeline Builder.
Conversión de Tipo de Datos
Dado que nuestra columna objetivo “diagnosis” contiene datos categóricos de tipo String, la codificaremos para los estándares de entrenamiento de ML.
- En el menú Operations, navega a ML operations->Encoding->Label Encoder. Arrastra y suelta el nodo Label Encoder en la interfaz del ML Pipeline Builder. La codificación de etiquetas solo puede aplicarse a la columna objetivo. Por lo tanto, se ejecuta automáticamente.
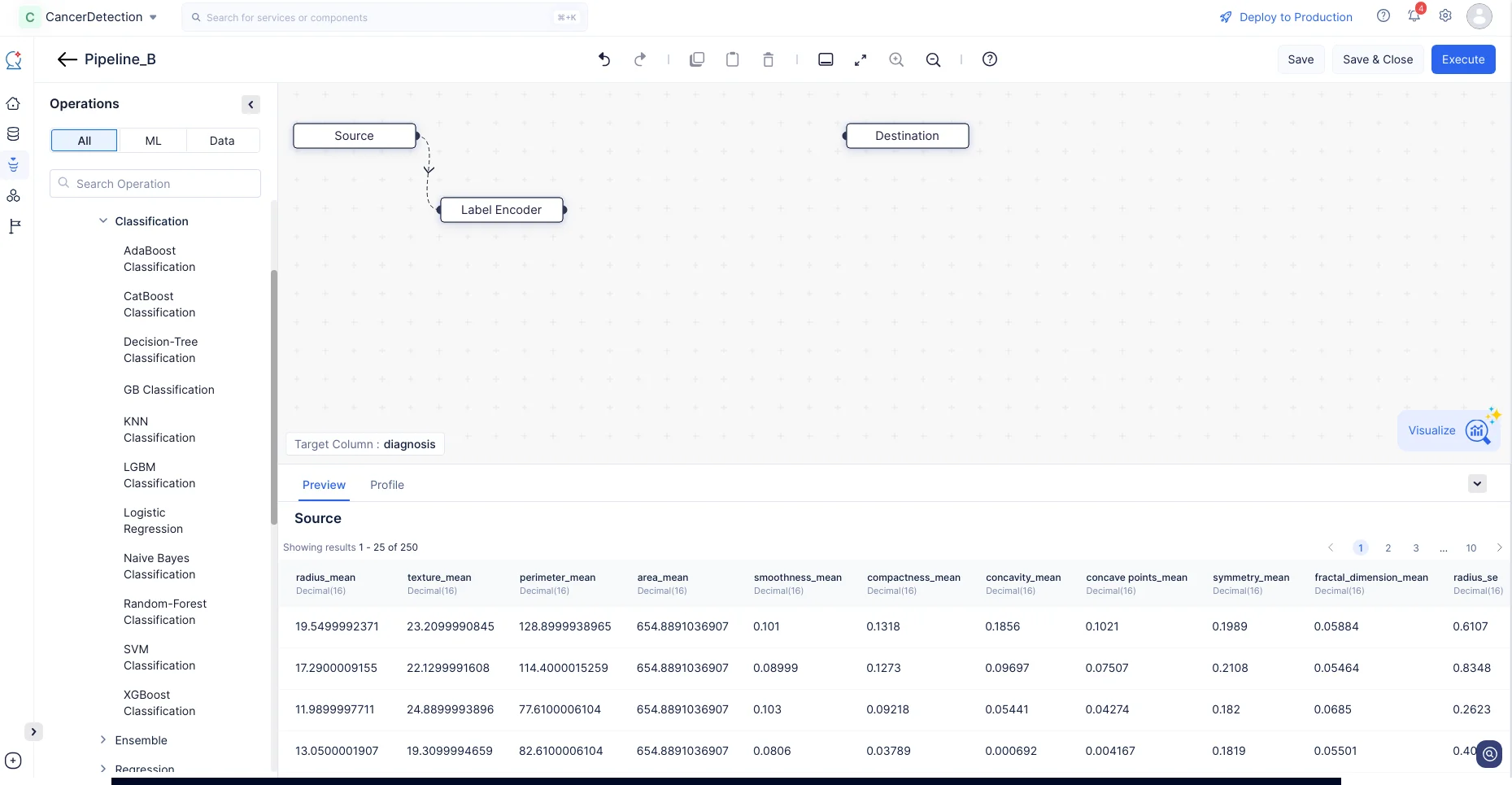
Esta operación convertirá los valores de la columna de tipo String a Integer, manteniendo el orden y preservando la precisión de los datos.
Ajuste de Hiperparámetros
Para cualquier modelo de ML, es obligatorio implementar un algoritmo de ML con base en el cual el modelo será entrenado. En este tutorial, implementaremos el algoritmo de clasificación logística para configurar los parámetros de ajuste del modelo de ML y asegurar que esté optimizado para nuestro conjunto de datos preprocesado.
-
En el menú Operations, expande ML operations->Algorithm->Classification->Logistic Regression. Arrastra y suelta el nodo Logistic Regression en el Pipeline Builder. El nodo se conectará al nodo Destination automáticamente. Realiza una conexión con el Label Encoder y el nodo Logistic Regression.
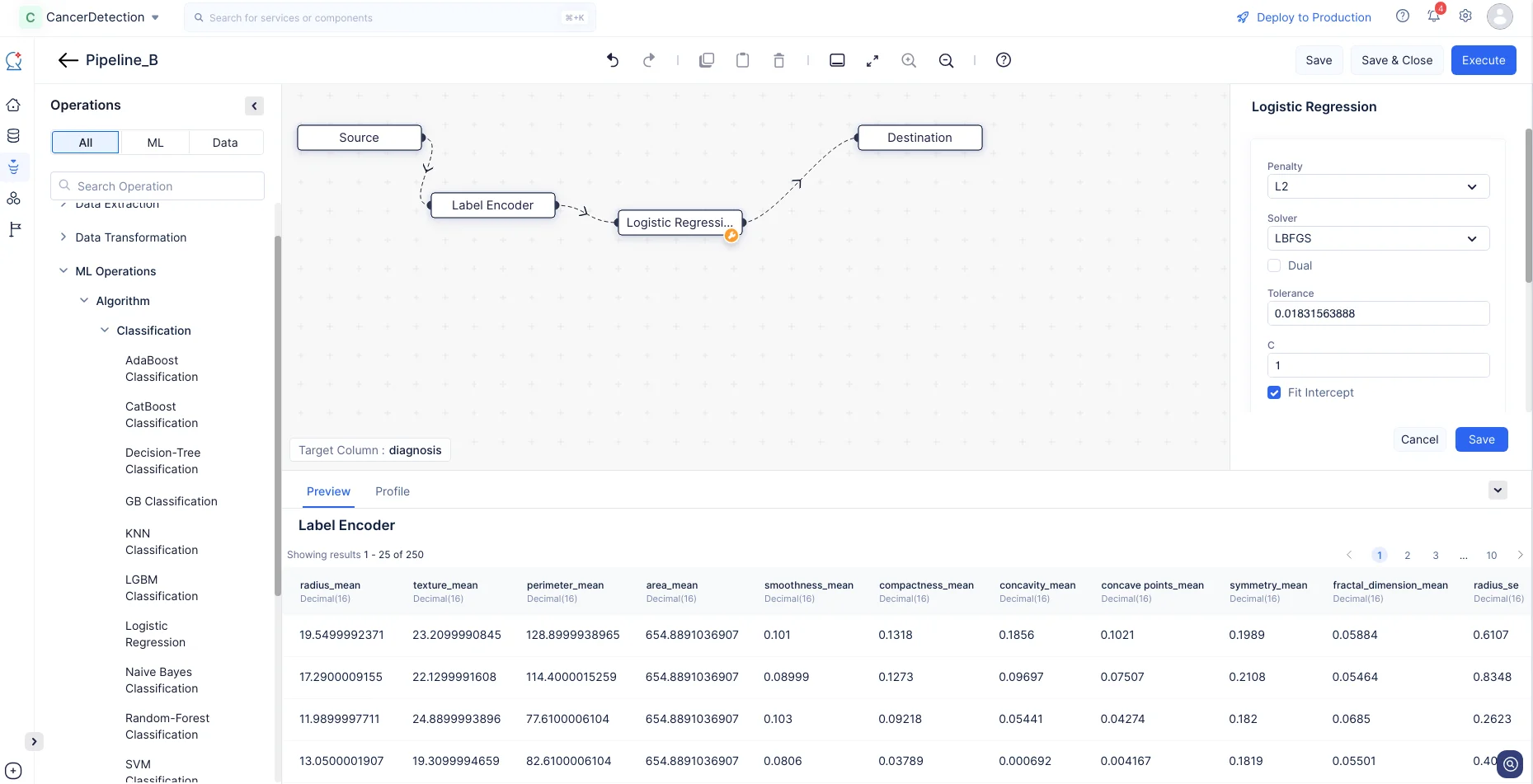
-
Para el nodo Logistic Regression, usaremos la configuración predeterminada y haremos clic en Save.
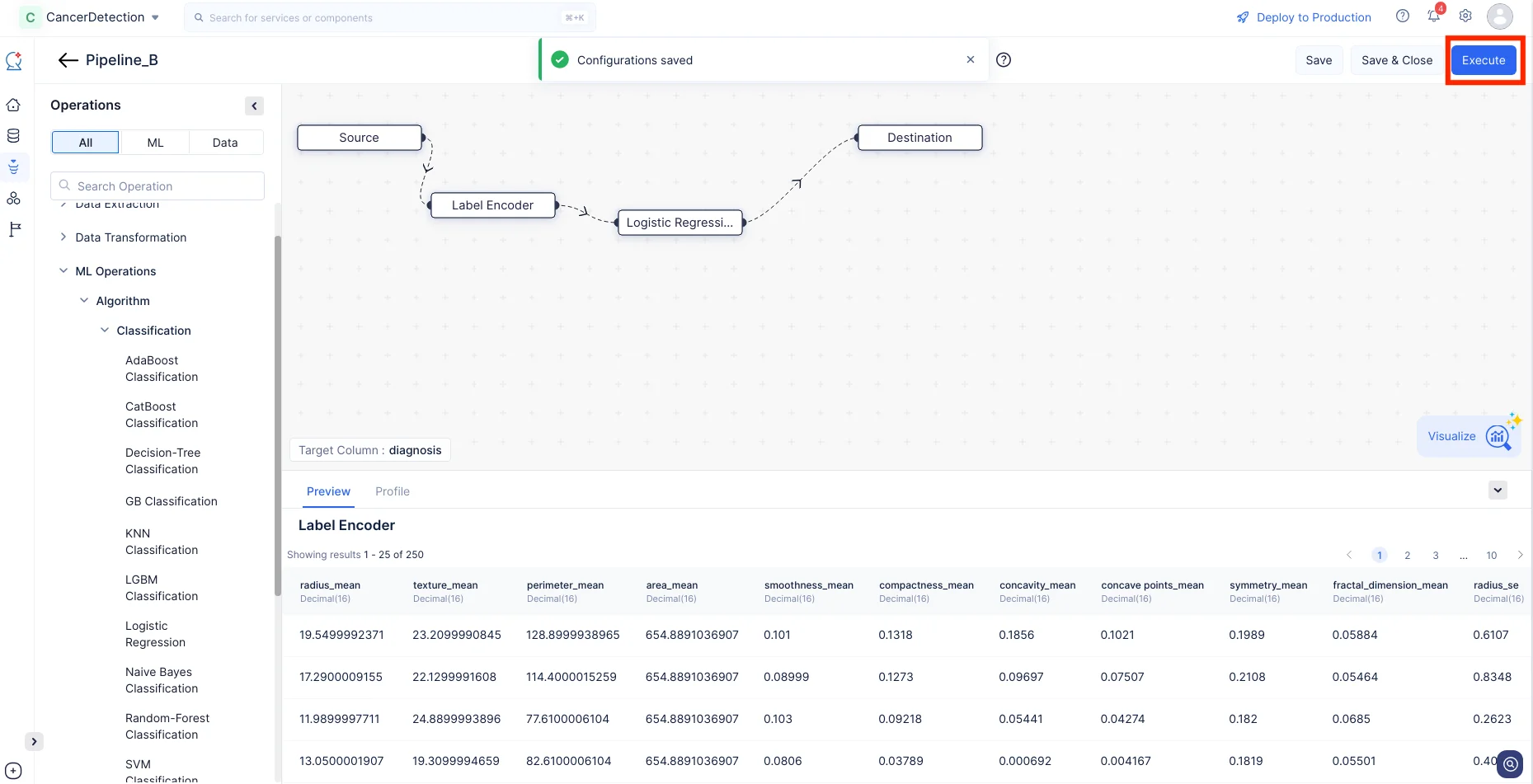
Ahora hemos completado las conexiones y configuraciones de nodos requeridas. Podemos proceder a ejecutar el pipeline haciendo clic en Execute para su posterior evaluación y despliegue.
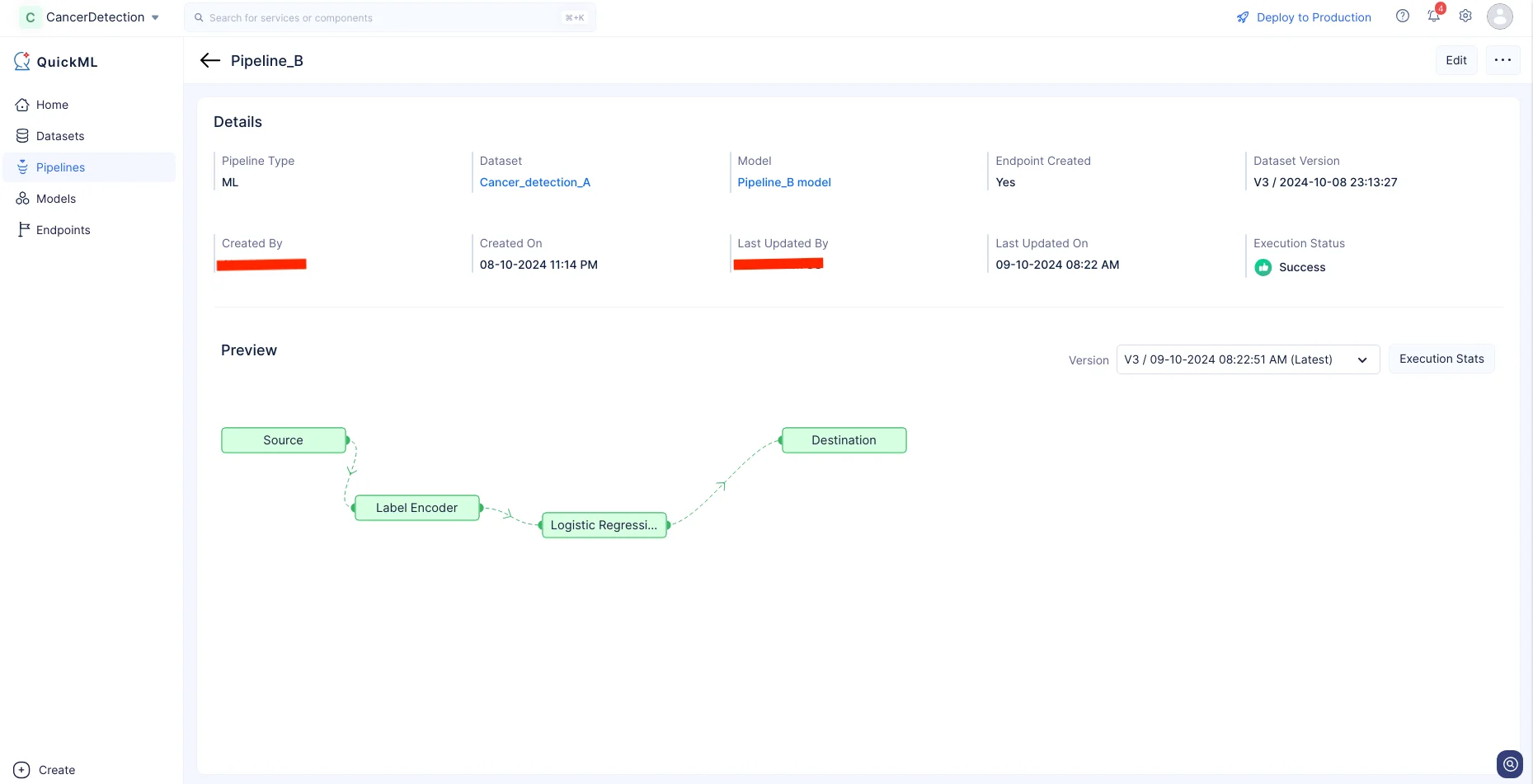
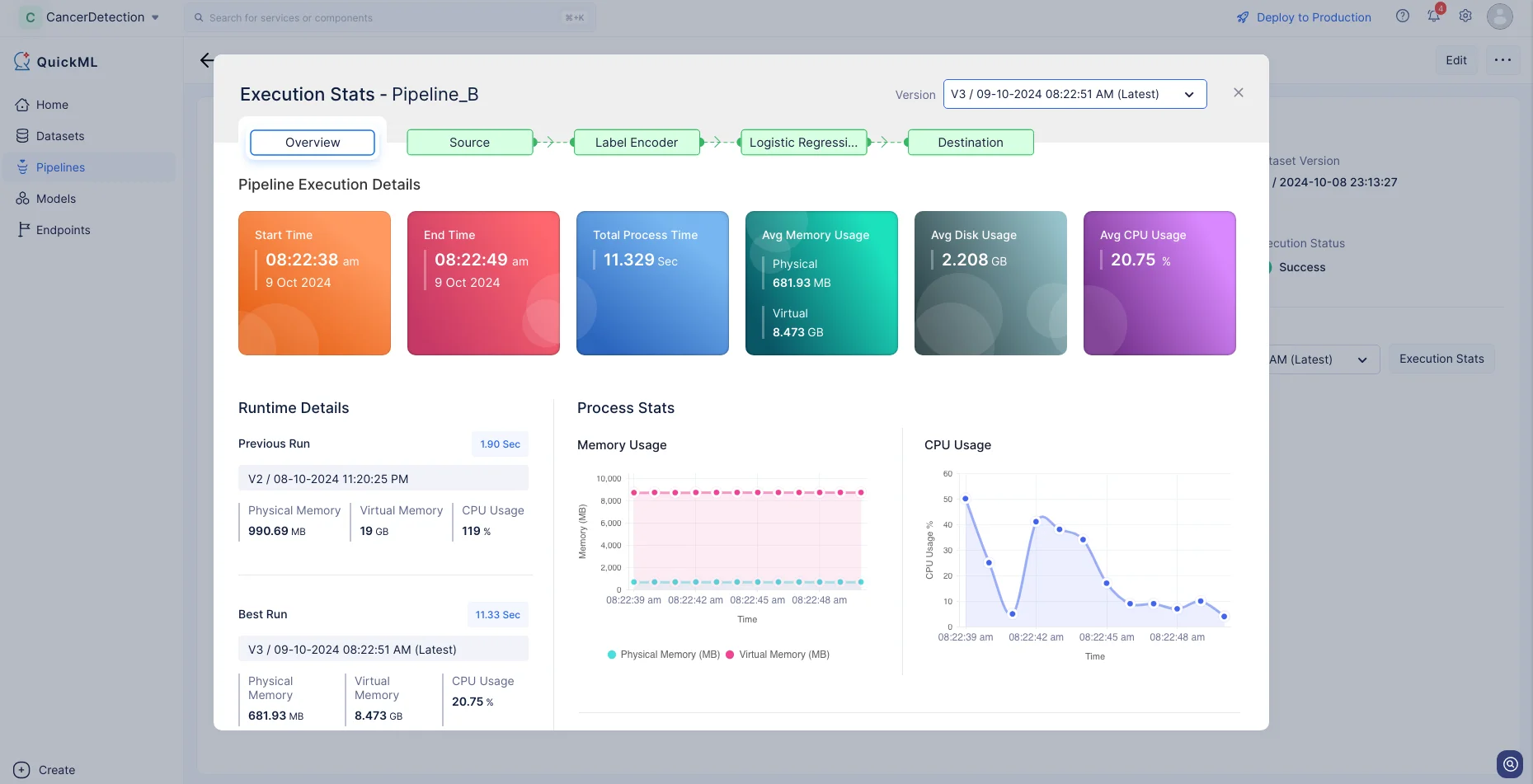
Haz clic en Execution Stats para ver más detalles sobre cada etapa de la ejecución en detalle.
Tras la ejecución exitosa del Pipeline de ML, el modelo de predicción se crea y se mostrará en la sección Models.
Puedes ver los detalles del modelo en la página de detalles de Models haciendo clic en el nombre del modelo.
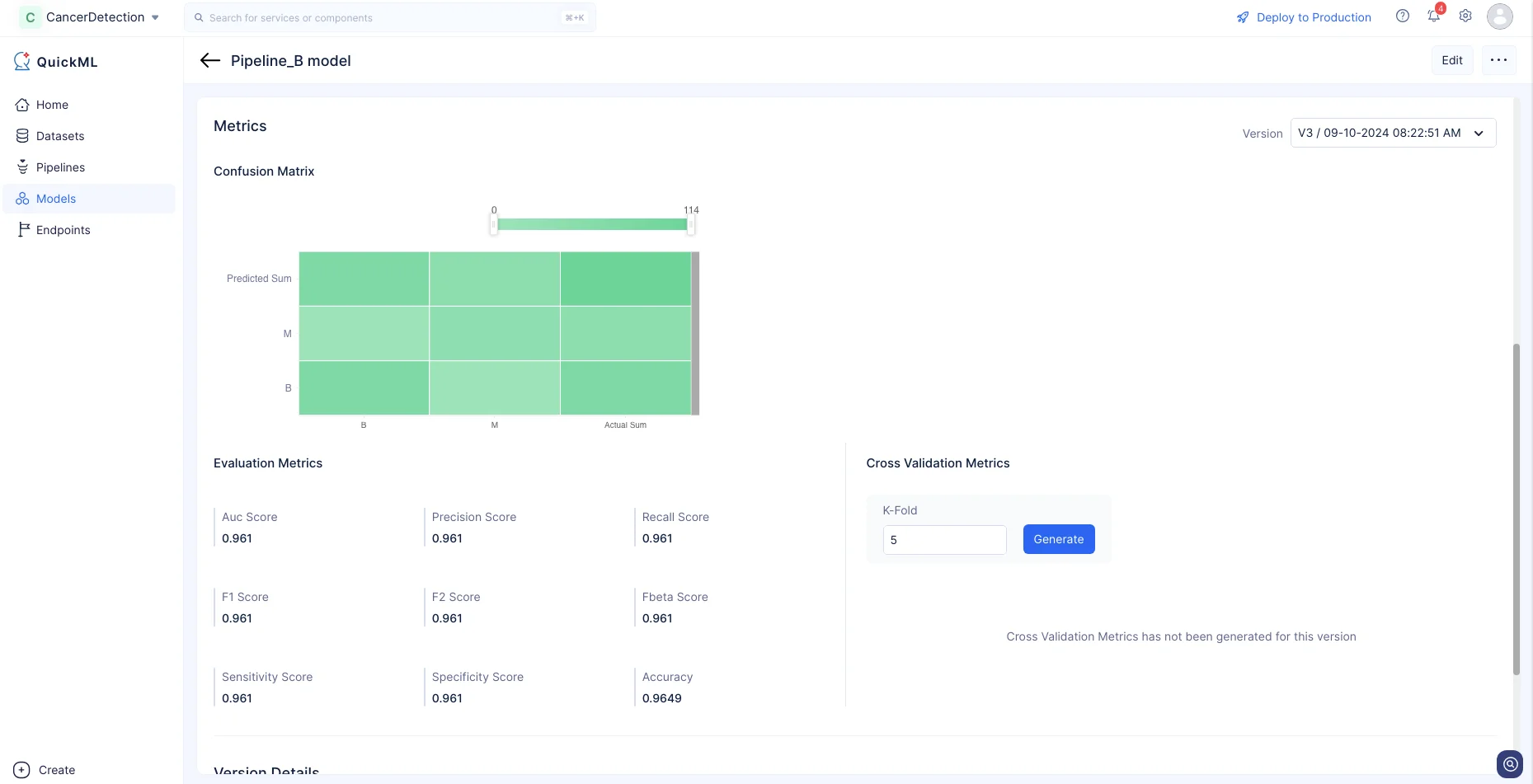
Adicionalmente, la precisión del modelo generado puede evaluarse y visualizarse en la sección Metrics de la página de detalles de Models. Esto proporciona información valiosa sobre el rendimiento y la efectividad del modelo para hacer predicciones sobre los datos.
Última actualización 2026-03-20 21:51:56 +0530 IST