Periodic Sync
Periodic sync helps reduce the manual effort required to import data repeatedly from the same data connector at multiple intervals. By configuring sync, users can automate the data import process according to their chosen periodicity, minimizing the need for manual intervention.
In QuickML, data sync can be configured using Sync Frequency, with various periodic interval options, including daily, weekly, monthly, yearly, and custom frequencies set in hours and minutes, with a minimum of 6 hours to a maximum of 23:59 hour intervals.
Benefits of Using Periodic Sync in QuickML
- Reduces Manual Interference: Users do not need to be available during the import process.
- Time-Saving: Automating data import saves time spent on configuring the data connectors each time data needs to be imported.
- Consistency: Ensures data is consistently updated within the QuickML platform, maintaining accuracy and reliability.
- Better Model Performance: Having the latest data available helps in periodically training the model; the latest data ensures better and more consistent model performance, resulting in reliable predictions.
- Efficiency: Reduces the risk of errors associated with manual data imports.
- Flexible Interval Options: QuickML offers a range of scheduling options to meet different data import and update needs.
Where to configure the sync frequency
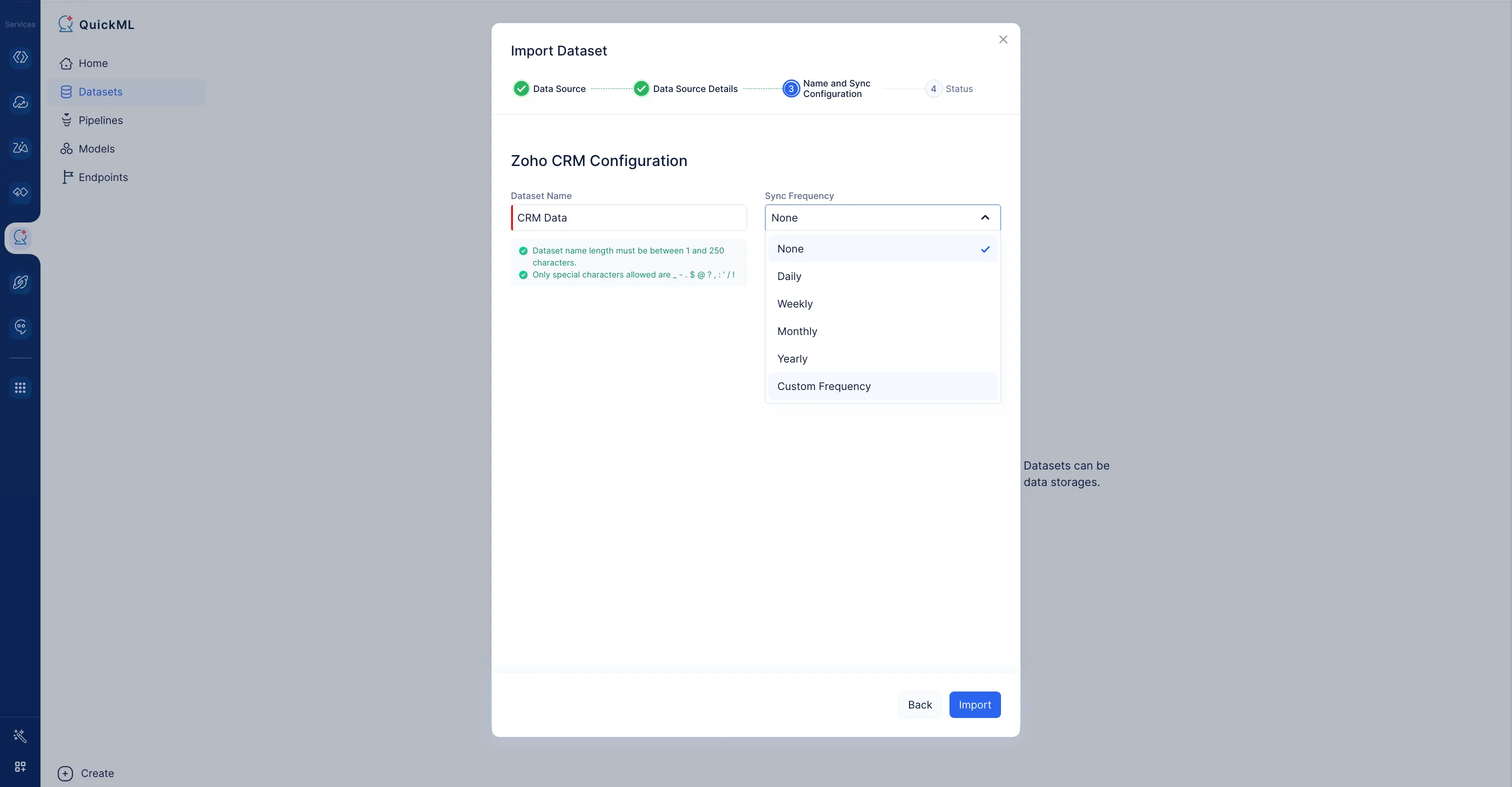
During data import:
We can set the periodic sync frequency during the data import from any of these data connectors object storages, Zoho apps, and Databases.
After the data import:
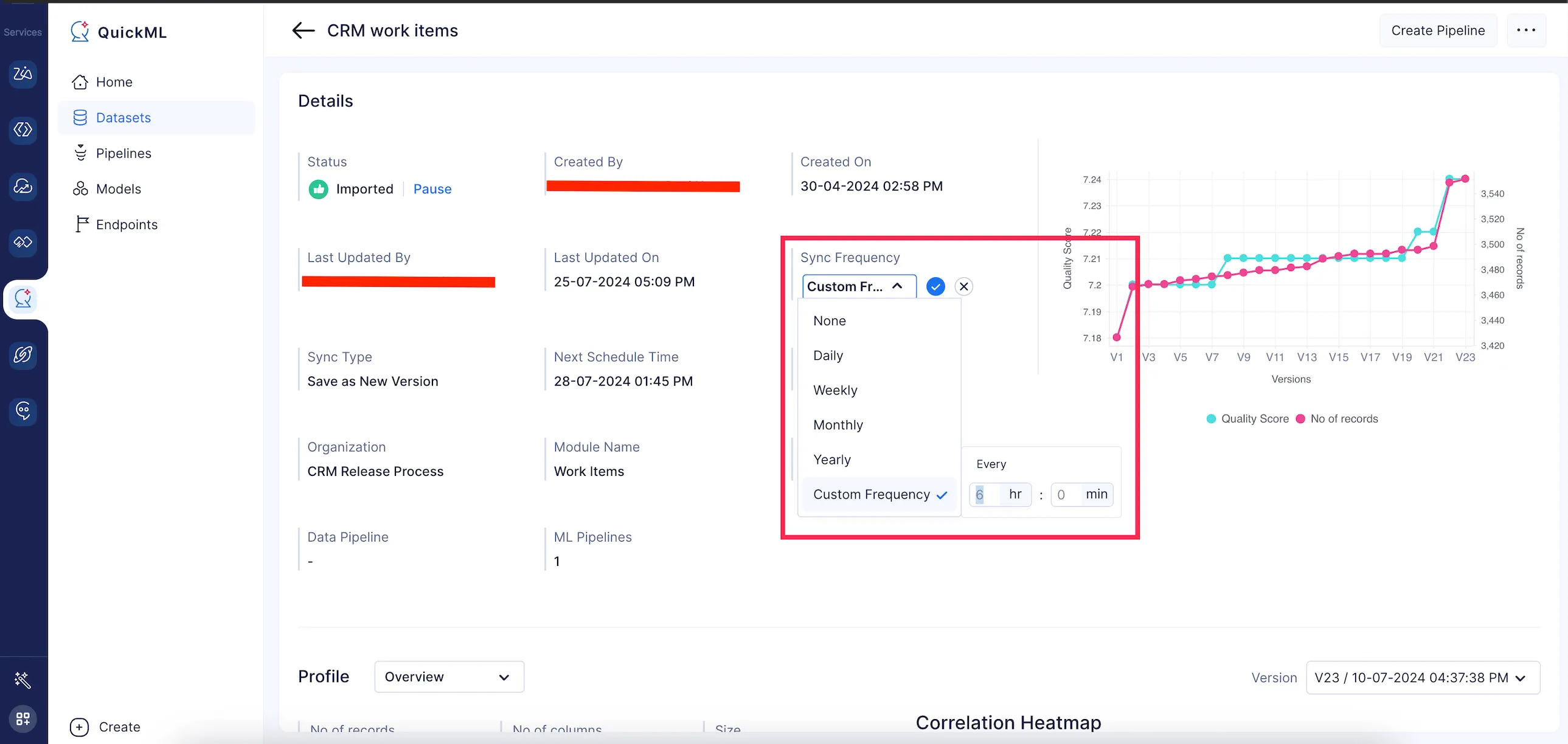
In the dataset details page, there is a sync frequency field that conveys the chosen sync configuration from the data import stage. However, the user can modify the configuration as needed using the drop-down options, as shown below.
Creating data pipeline:
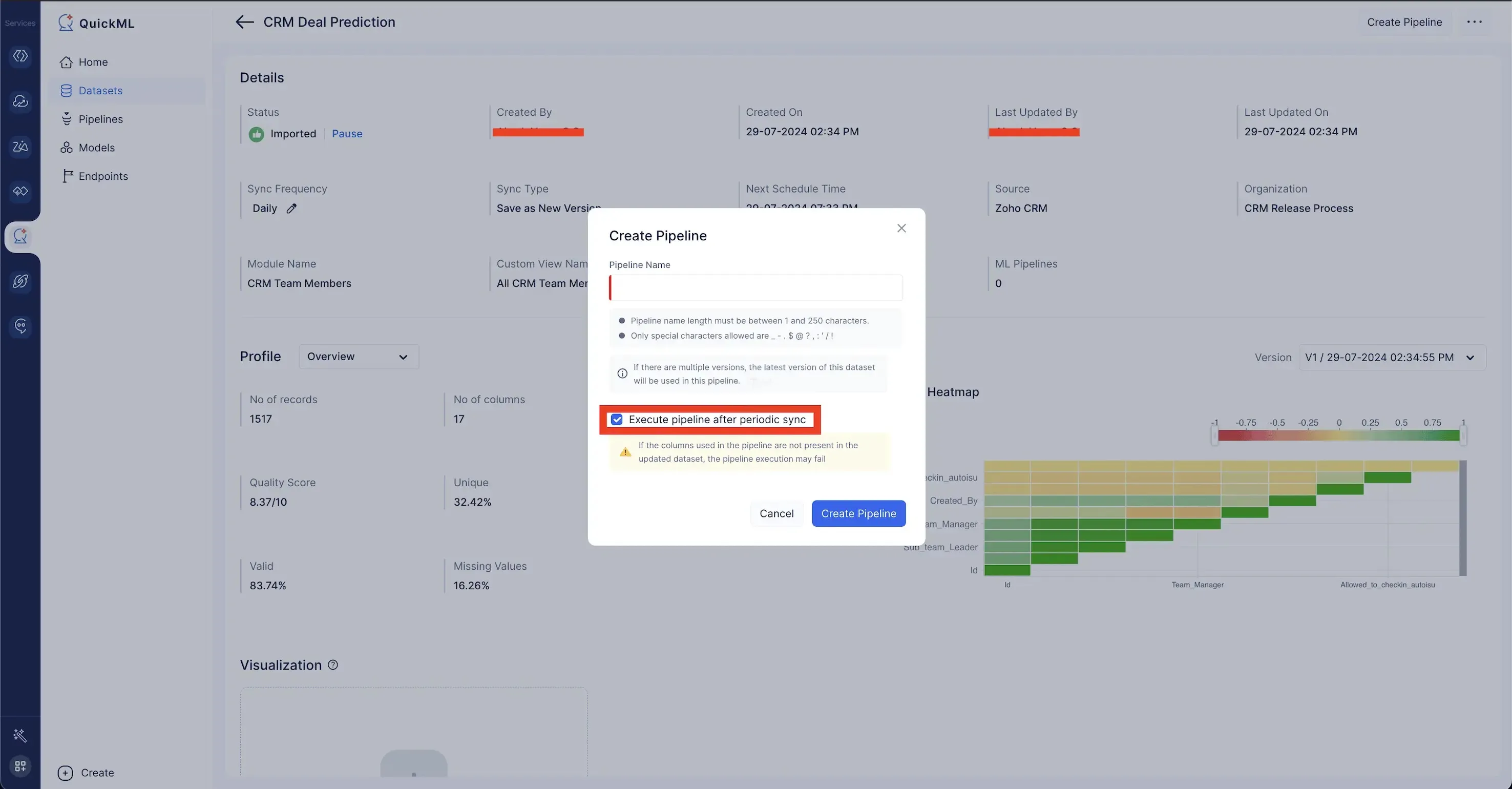
While creating the data pipeline for a periodic sync-enabled dataset, kindly make sure to enable the Execute pipeline after periodic sync option. This ensures that after every sync, the data pipeline will rerun and produce the next version of the transformed data.
Creating ML Pipeline:
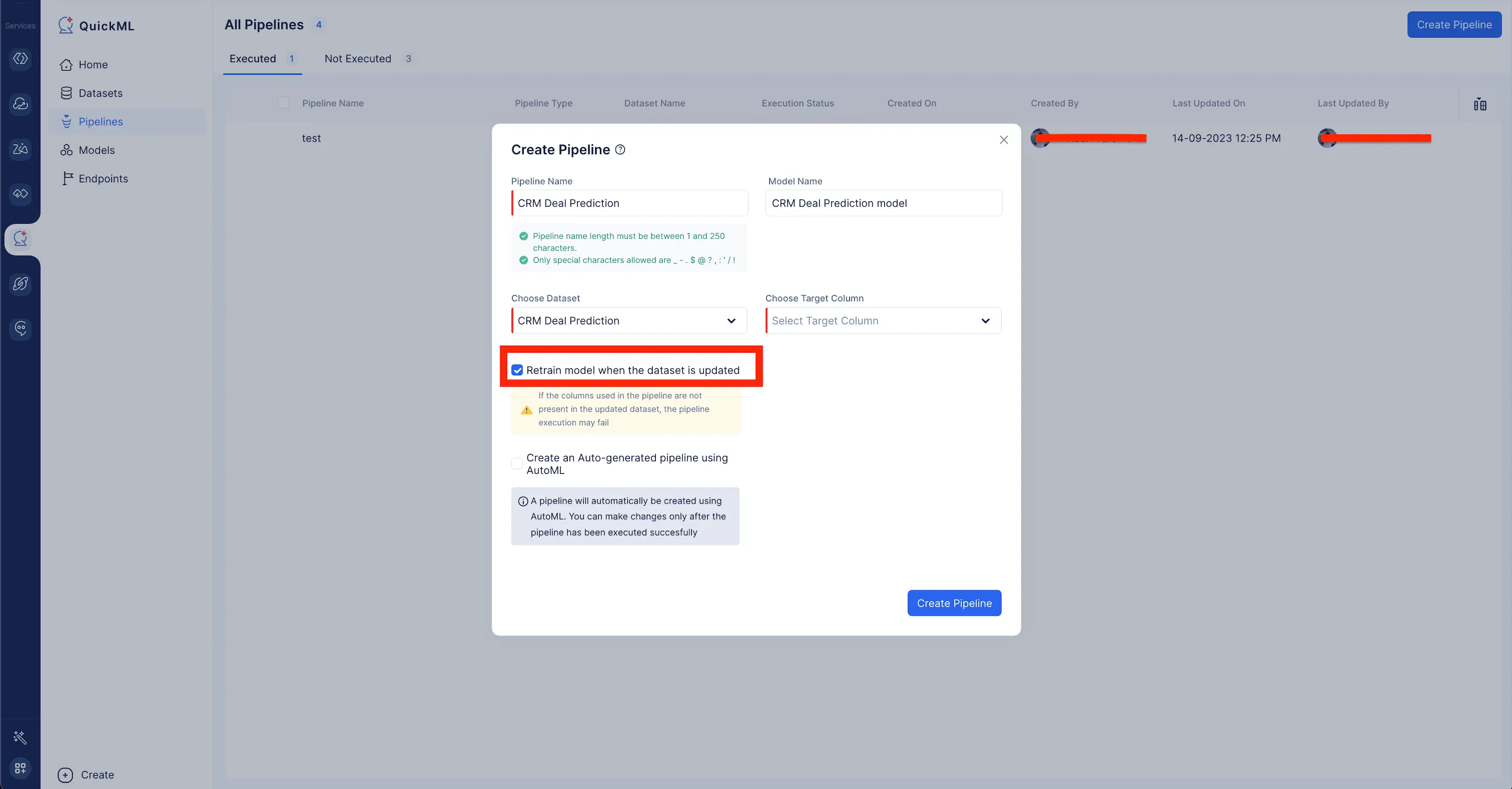
While creating the ML pipeline for a periodic sync-enabled dataset, kindly make sure to enable the Retrain model when the dataset is updated option. This ensures that the model is automatically retrained whenever the dataset is updated.
Last Updated 2025-02-19 15:51:40 +0530 IST
Yes
No
Send your feedback to us