Introduction to NLP in Text Analytics
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) that enables the machines the ability to understand, interpret, and generate human language in way that is meaningful and useful. WIth the enormous amounts of textual data getting generated everyday, NLP blends computational linguistics, machine learning, and deep learning to allow machines to process natural language data and extract valuable insights from it, in turn generating value to businesses. Natural language processing enhances the user experience by proactively addressing data-driven concerns and challenges faced by business users, thereby adding significant value to the business.
Why is it popular?
NLP’s popularity is driven by its ability to make sense of complex human language and apply it to real-world problems, making interactions with technology more natural and intuitive. Key reasons for its increasing popularity include:
- Extracting Insights from Data: Businesses collect vast amounts of textual data from various sources like social media, articles, product reviews, feedback, legal documentation, etc. They need to understand what customers or users are talking about their products or services. NLP provides efficient ways to process, analyze, and extract valuable insights from this large, unstructured data.
- User-Centric Applications: With the advent of NLP, businesses rely on virtual assistants, chatbots, and automated customer service systems to address user queries faster and efficient manner.
- Translation Capabilities: NLP enables machine translation, facilitating communication across languages and helping to remove language barriers in society.
- Summarization Capabilities: Lengthy documents can be converted into short summaries for quick reading, saving time and effort.
These are just a few applications, with more innovations emerging every day.
Business applications
NLP enables various applications in business environments by utilizing NLP tasks to help companies automate processes and extract actionable insights from large datasets. Let’s looks at a few NLP tasks and their real-time business applications.
NLP Tasks
Tasks refer to specific objectives or problems that an NLP model is designed to perform or solve. Each task is focused on addressing a particular aspect of processing or analyzing natural language.
Examples of NLP Tasks
Tasks that could be performed using QuickML’s Text analytics builder include:
- Spam detection: Spam classification is the binary classification model, where the purpose is to classify the emails received as spam or not. The spam detection model takes the email, subject, sender details, and so on as input to the model and generates the probability the email being spam. Based on the threshold, it will classify the email as spam or not spam. Text classification tasks: Various other tasks that come under text classification similar to Spam classification for emails are intent detection, commitment classification, and emotion detection and tonality identification fall under the text classification tasks.
- Language detection: Language detection is a fundamental step applied in various NLP applications like language translation, grammar correction, and text-to-speech. Detecting the language used to search for web content and return the results in the same language or used in chatbots/translation tools to provide response in the same language.
- Sentiment Analysis: Determines the sentiment tone (positive, negative, or neutral) of a piece of text. In general, the input to a sentiment classification model would be a piece of text, and the output is the sentiment that is expressed in the text. In a real-world scenario, sentiment classification would be helpful for businesses to find out what their customers are feeling about their products using the product reviews and understand the negatively impacting areas.
Tasks that can be performed using Zia features in QuickML are: Zia Features
The following tasks can be performed using Catalyst Zia services:
- Named Entity Recognition (NER): Detectis proper nouns, such as names of people, places, and organizations.
- Keyword extraction: A technique in NLP to identify and extract the most relevant keywords from text data, helping capture the main topics and, in turn, aiding in summarising information, indexing, and categorising documents.
NLP applications
Applications refer to the practical, real-world usecases of NLP models. An application is often built using one or more NLP tasks to solve broader, end-user problems or provide services.
Examples of NLP Applications:
- Sentiment Analysis Tools: Uses sentiment extraction, tonality, and emotion identification tasks to gauge public opinion. It is crucial for businesses and brands that place a large value on understanding customer experiences. It can be implemented for the following purposes:
- Gauging and monitoring sentiments expressed by customers in social media platforms and opinion surveys
- Automating the analysis of customer feedbacks and reviews and reducing the manual workload involved.
- Identifying and addressing critical situations in real-time by the automated monitoring of negative sentiments
- Email Spam Filters: Spam filters leverage tasks like spam classification to identify and filter unsolicited or unwanted emails, automatically moving them to the spam folder. This improves the user experience by reducing inbox clutter, saving time, and minimizing the risk of exposure to phishing attempts, fraudulent schemes, and other harmful scams.
- Customer Feedback analysis: By leveraging multiple NLP tasks such as sentiment analysis and keyword extraction, businesses can gain insights into what customers are saying about their products in reviews or on social media. This enables them to address customer concerns or complaints effectively, ultimately enhancing customer satisfaction and improving the overall experience
- Enhance Customer support efficiency: Tasks like Emotion detection enable businesses to analyze customer interactions with their customer support staff via chats, calls, complaints, feedback or reviews, social media posts, and more. This helps to identify emotions that their customer going through, such as happiness, frustration, or anger upon using their products or services. This helps businesses better understand their customer sentiment, allowing them to respond empathetically, tailor their services, and improve customer relationships. Detecting what their customer feels gives a window to implement proactive measures to address their concerns, resolve their issues, and thereby enhance brand loyalty.
- Customer support at scale: Businesses leverage intent and activity classification tasks to interpret user queries accurately and provide responses accordingly. By automating the resolution of common or basic inquiries, organizations can significantly reduce response times and free up resources for more complex issues. This automation enables customer support to scale efficiently, extending the reach of its support services, and ensuring consistent service delivery. Additionally, virtual assistants are employed to model and deliver responses, further enhancing the speed and quality of support while maintaining a personalized user experience.
An application is essentially a practical implementation where multiple tasks come together to create value for users. While tasks focus on specific language operations, applications focus on solving broader user-centric problems by combining several tasks. These are just a few examples of how NLP tasks are being applied in real-world businesses. With advancements in technology, a plethora of innovative applications continues to emerge, revolutionizing user experiences, streamlining processes, and fostering greater customer loyalty by addressing their needs more effectively
Steps to build a pipeline
QuickML uses classic mode and smart mode pipeline builders to create text analytics models.
The Classic mode features a drag-and-drop pipeline builder interface where a list of data and machine learning operations are available for building NLP models. These nodes can be used to drag and drop into the builder to build the machine learning pipeline, which, upon execution, generates an NLP model.
The Smart mode provides a prebuilt template for building NLP models, designed to simplify the model development process from data preprocessing, Feature Extraction, to model selection. With this prebuilt template, stages are predefined, and users are presented with various parameters to configure operations at each stage. This template removes the ambiguity of which operation to use and when, to build NLP model and streamlines the model-building process.
Build a Model Using Smart Builder
Building text-based machine learning models follows a similar process to other ML models, involving similar steps from data pre-processing, algorithm selection, and tuning the model. However, NLP models differ in the sequence of applying specific text-based operations. This sequence is crucial to build a model, as it ensures that the text data is transformed and processed in the most effective way before applying machine learning algorithms.
In the Smart Mode of model building, the pipeline builder is streamlined into three main steps:
- Pre-processing: In this step, raw text data is cleaned and prepared for further analysis. This involves operations such as tokenization, case conversion, stemming and lemmatization, stopword and noise removal, and normalization.
- Feature Extraction: This step involves converting the text data into numerical features that can be understood by machine learning algorithms. Techniques like TF-IDF, word embeddings, and bag-of-words are commonly used.
- Algorithm Selection: In the final step, a suitable algorithm is chosen from the available supervised or unsupervised learning algorithms based on the use case. The model is then trained using the pre-processed data from the feature extraction step.
Each step in the Smart Mode Pipeline Builder comes with configurable stages/operations that allow you to configure the operations to your specific NLP problem.
Let’s deep dive into each step and explore the stages/operations available in them:
Stage 1: Preprocess
Text data is usually raw, so it’s important to process the data before feeding it into any algorithm to improve performance. In our smart builder, textual data pre-processing stage has 7 operations where the first six operations work on the textual data and the final operation Label Encoding applied on the target column of the labeled datasets. The output of this stage is passed on to the Feature extraction stage, where the entire text data is converted to numerical format.
Let’s look at the operations in the preprocessing stage.
a. Case conversion
Convert raw text data with different cases to a common desired case (lower case in general). This would help in reducing sparsity (without common casing “NLP, Nlp, nlp” would be considered as three different words).
b. Tokenization
Tokenization is breaking the textual data down into further smaller units. For instance, paragraphs can be segmented into sentences, sentences into words, and words into individual characters, allowing to uncover patterns or insights that are not visible in larger segments.
In QuickML, tokenization of sentences can be performed at both the word and character levels. After tokenization applied on the data at theWord level, subsequent operations (Stemming & lemmatization, Stop words removal, Noise Removal, Normalization) can be applied to the data as needed.
However, at the Character level, only the Noise removal operation alone can be applied to the tokenized data.
Tokenization stages: Text : Sentences ➔ words ➔ characters
c. Stemming and Lemmatization
Both techniques reduce words to their root forms, helping normalize word variations for more consistent analysis. Stemming trims trailing characters to obtain its root form, which may not always be a proper word. Lemmatization, however, reduces words to their dictionary form by considering context, resulting in a proper word with accurate meaning.
The key difference is that stemming is faster but less precise, while lemmatization is more accurate but slower, as it relies on vocabulary and grammar.
Sample:
| Words | Stem word | Lemmatized word |
|---|---|---|
| Studying, Studies, Studied |
Studi | Study |
| Running, Runner, Runs | Run or Runn | Run |
| Changing | Chang | Change |
d. Stop word removal
Languages have many filler words that do not provide any significant use during training. By removing them, we can make our model to focus more on important words. Articles, prepositions, and so on etc come under the stop words category.
e. Noise removal
Removing unwanted words or parts of text depending on the feature in hand. Example: sentiment classification in NLP does not require the email addresses. It could be done using regex or having a list of noise words. Additional spaces, special characters, and digits could also be considered as noise.
f. Normalization
Converting different formats of text into a standard format. Example: The words USA, usa, United states of America, The united states of America, the usa to usa. This could be achieved using dictionary mapping. Noise removal can also be considered as a part of text normalization.
| Raw | Normalized |
|---|---|
|
2moro 2mrrw 2morrow 2mrw tomrw |
tomorrow |
| b4 | before |
| otw | on the way |
| :) :-) ;) |
smile |
g. Label Encoding
Label encoding is a method used to transform categorical variables into numerical values by assigning a unique integer to each category. It helps machine learning algorithms to process categorical data effectively. In the context of text data, the target label represents a categorical variable with various classes that can be converted into numeric form to train the model effectively.
Now, our text data is cleaned and ready to be transformed into word vectors using the vectorization techniques available in the feature extraction stage below.
Stage 2: Feature Extraction
Textual data cannot be fed directly fed into an algorithm; it must first be converted into a numerical format. There are several methods for this conversion, known as vectorization techniques, which can also be used to extract additional features from the vectorized data. In this context, each word, sentence, or character presented to a model is treated as a feature.
That being said, in QuickML, text -to-number conversion happens using the techniques below. This is the process of transforming textual data into numerical format that captures the semantic meaning of words or phrases.
Techniques available in QuickML includes:
a. Bag Of Words (BOW)
Bag of words, create a vocabulary of unique words present in the whole text corpus. Each sentence is then represented as a vector, does mapping based on the presence of these words, with the values representing the frequency of occurrence of each word within that sentence.
Example:
Below is an example showcasing the vectorized representation of the Bag of Words
model for the following sentences:
S1. Machine learning solves real world problems
S2. NLP popularity is rising
S3. Language translation is NLP task
Bag of Words Table representation:

Rows represent the sentences provided, and columns represent each word in these sentences, and values represent the frequency of occurrence of the specific word in each sentence.
Vector Representation: Each sentence is represented as a vector by having word counts from the BoW table. Vector length is equal to the number of unique words in the vocabulary. Below is the vectorized representation of the three sentences above. Sentence 1 → [ 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]
Sentence 2 → [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0]
Sentence 3 → [0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1]
BoW model represents text data as vectors and each word in the text corpus as a feature. It simplifies the data for modelling but fails to capture the sanctity of the order of words and its contextual meaning.
b. TF-IDF (Term Frequency - Inverse Document Frequency)
TF-IDF quantifies the importance of each word in the corpus and allows to extract important features from the text data that are helpful in training the model for better performance. The higher the TF-IDF score, the more important the word is, and vice versa.
It can be calculated in three steps.
Step1: Term Frequency (TF) measures how frequently a term appears in a document relative to the total number of unique words in that document.
Term Frequency of a word (TF) = Number of times a word appears in a document / Total number of unique words in the document
Step2: Inverse Document Frequency (IDF) measures how important a term is across the documents.
IDF of a word= log(N/n), where, N is the total number of documents and n is the number of documents a word has appeared in.
Step 3: Calculate TF-IDF score
TF-IDF = TF * IDF
The IDF of less commonoccurring words will be high and low for common words. Thus, words like ’the, is, a’ etc. will have a low importance, and higher importance could be given to actual document specific words.
Example:
Let’s use the sample example from Bag of Words:
S1. Machine learning solves real world problems
S2. NLP popularity is rising
S3. Language translation is NLP task
Step 1: Calculate Term Frequency (TF)
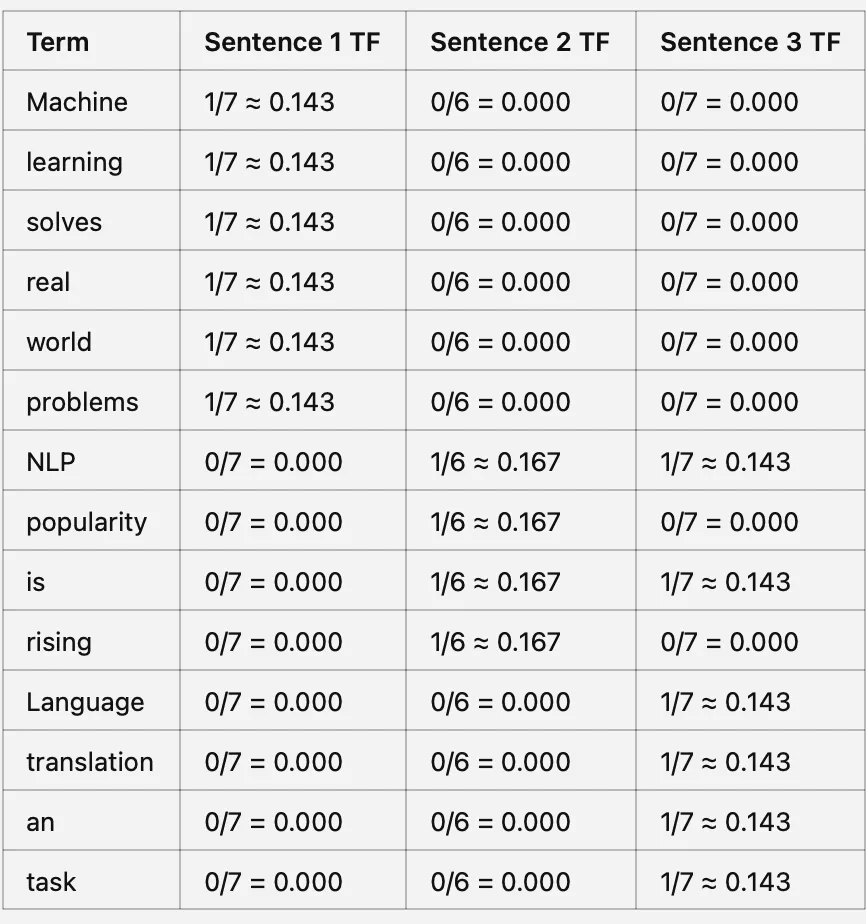
Step 2: Calculate IDF score
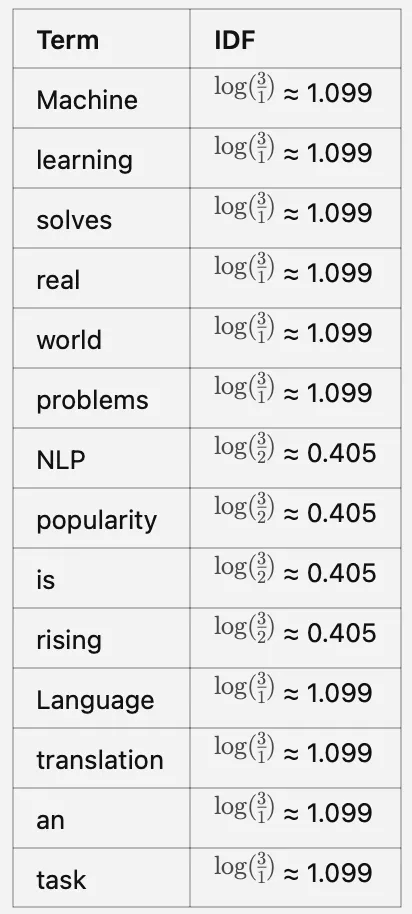
Step 3: Calculate TF-IDF
Multiply TF by IDF for each term in each sentence
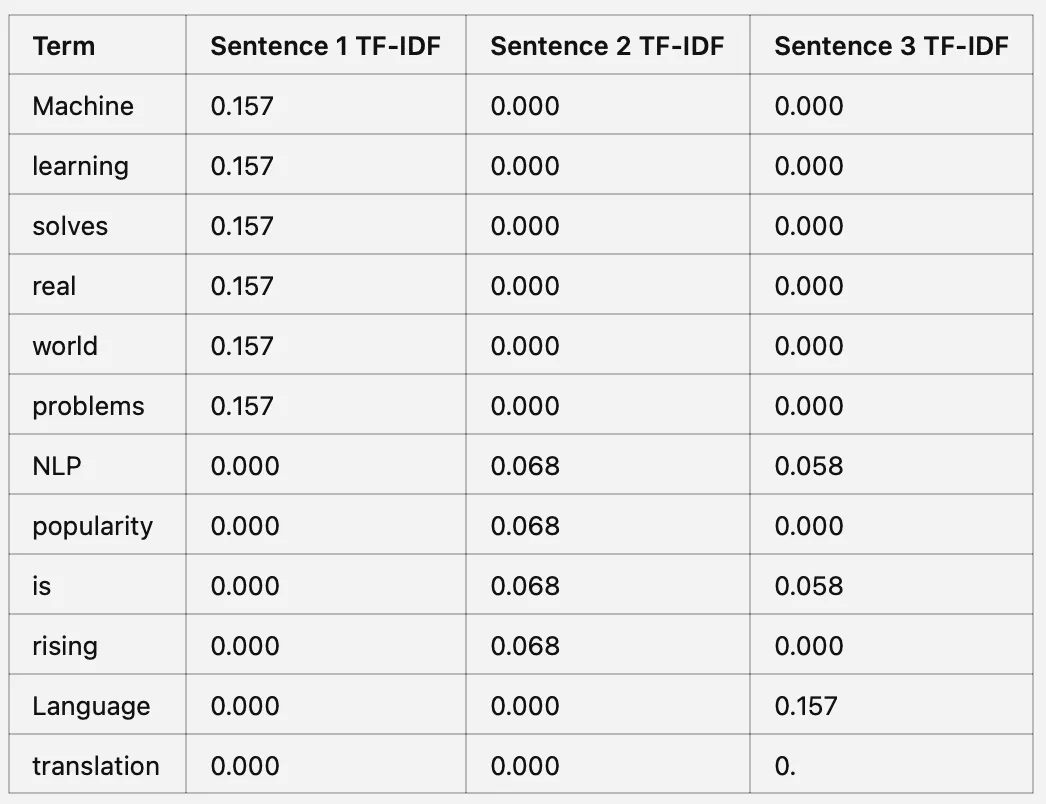
Key insights from the example includeare:
High TF-IDF values indicate that a term is important in a specific sentence and not common across all sentences.
Low TF-IDF values suggest that a term is either common across sentences or not unique to any single sentence.
TF-IDF highlights the words important for understanding the context in the corpus. It showcases how some words or terms are important in a specific text than others.
c. Word2Vec
Word2Vec is a pre-trained word embedding model that generates numerical vectors (embeddings) for words based on their semantic and contextual relationships. It is trained on a large text corpus to ensure that words with similar meanings or contexts have embedding vectors that are close in the vector space. These relationships can be quantified using cosine similarity, where a higher score indicates greater similarity.
Example:
Words like “king” and “queen” will have vectors that are close to each other, reflecting their shared context of royalty. Similarly, “man” and “woman” will have vectors that capture their relationship and shared meaning, demonstrating Word2Vec’s ability to model semantic relationships effectively.
d. GloVe
GloVe (Global Vectors for Word Representation) is a pre-trained word embedding model similar to Word2Vec that generates embedding vectors for given words. It is a count-based model that produces embeddings by factorising a word co-occurrence matrix derived from the entire corpus. GloVe captures global statistical information by analyzing how frequently words co-occur across the corpus. Unlike Word2Vec, which uses a predictive approach based on local context, GloVe relies on global co-occurrence statistics for training. It differs from Word2Vec in the method of training.
Example:
In GloVe, words like “king” and “queen” will have similar vectors, reflecting their semantic relationship (e.g., royalty). Additionally, GloVe excels at capturing analogical relationships.
For instance:
king - man + woman ≈ queen
This analogy represents the transformation: The relationship between “king” and “man” (which can be thought of as “king is to man as queen is to woman”) is mathematically captured by subtracting “man” from “king” and adding “woman.” The result is “queen”, meaning that the model understands that just as king is to man, queen is to woman.
This means the vector difference between “king” and “man” is similar to the difference between “queen” and “woman”, illustrating GloVe’s ability to model both meaning and relationships effectively.
Stage 3: Algorithms & Modelling
Text data is fed to algorithms in a vectorized form to generate an NLP model. The NLP models could be broadly classified into supervised and unsupervised learning models. In QuickML, we have algorithms that use labelled data to build supervised learning models.
The algorithms include:
Model Evaluation metrics
NLP also has the common evaluation metrics like accuracy, precision, f1 score, etc.
i. Log-Loss score
Log-loss, also known as logistic loss or cross-entropy loss, is a commonly used evaluation metric in natural language processing (NLP) models, especially for binary and multi-class classification tasks. Log-loss quantifies the difference between the predicted probabilities and the actual class labels. Prediction probability of data record is the probability that the model has to predict for each class that it classified under.
Actual class label is the true class that the data record belongs to. Log loss score indicates how close the prediction probability to the actual class label is. The more the predicted possibility values are diverged from actual values, the higher the lob loss score.
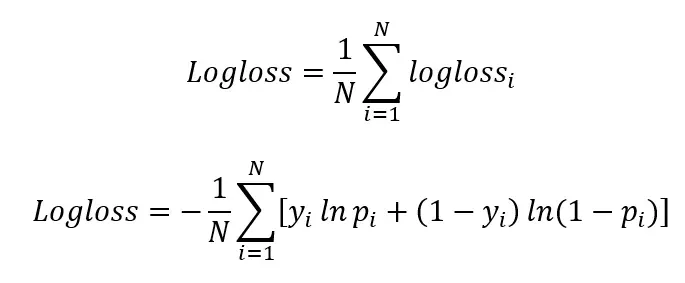
where
i is the given observation/record,
y is the actual/true value,
p is the prediction probability, and
ln refers to the natural logarithm (logarithmic value using base of e) of a number
N is the number of observations
It measures the performance of a classification model whose output is a probability value between 0 and 1. The lower the log-loss score, the better the model is fit, and the higher the performance. A model with a log-loss score of 0 has the perfect skill to predict.
For example:
In spam classification, the actual class of an email is “Spam.” The predicted probability for the email being “Spam” is 0.78, and for being “Not-Spam,” it is 0.22. The negative natural logarithm of the predicted probability for the correct class (Spam) is 0.2485, which represents the log-loss score for that particular record. The log-loss score of the
model is calculated as the average of the negative natural logarithm of the predicted probabilities for the correct classes across all records
ii. AUC-ROC Curve
The Area under the Receiver Operating Characteristic (AUC-ROC) curve is a machine learning metric that measures how well a classification model is performing. AUC represents the area under ROC curve, where ROC is a graph that plots the True Positive Rate (TPR) against the False Positive Rate (FPR) at different classification thresholds.
True Positive (TP) and False Positive (FP) are terms used in the confusion matrix to evaluate the performance of classification models.
- True Positive Rate (TPR), also called sensitivity or recall, measures the proportion of actual positive records that are correctly identified by the model.
- False Positive Rate (FPR) measures the ratio of actual negative records that are incorrectly classified as positive.
Specificity measures the actual negative instances that are correctly identified by the model.
A visual interpretation of AUC - ROC curve is below. An ROC is the plot between TRP and FPR across all possible thresholds where as AUC is the entire area under the ROC Curve.
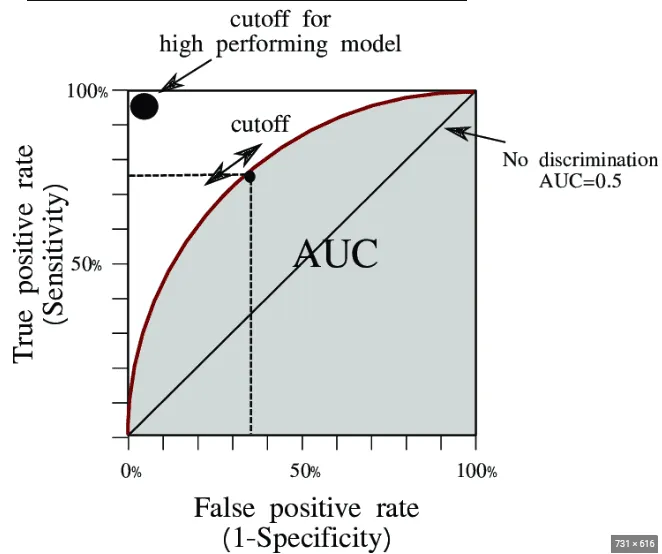
The AUC (Area Under the Curve) score ranges from 0 to 1, with higher scores indicating better model performance.
-
An AUC of 1 signifies a perfect model, where the ROC (Receiver Operating Characteristic) curve forms a complete right-angle path, achieving 100% sensitivity (True Positive Rate) with 0% False Positive Rate.
-
An AUC of 0.75 indicates that the model has a good ability to distinguish between positive and negative classes 75% of the time, showing better performance but still leaving room for improvement.
-
An AUC of 0.5 suggests the model performs no better than random guessing, which is the least desirable outcome.
A higher AUC score always reflects better model discrimination between classes.
Visualizations
Wordcloud
A Word Cloud is a visual representation of the most frequently occurring words in a text corpus. The size of each word in the word cloud reflects its frequency of occurrence. Word clouds are commonly used to identify quickly and highlight the most prominent keywords or phrases in large text datasets, making it easier to communicate the key terms or concepts being discussed.
Example: Let’s take an example of an excerpt from “The Chronicles of Narnia: The Lion, the Witch, and the Wardrobe”.

Let’s analyze the word cloud below generated for that provided text to identify the frequent and significant words used.

With this word cloud, we can quickly extract important keywords, gain insights, and understand the overall context of the text in a visually engaging and time-efficient manner.
Last Updated 2025-02-19 15:51:40 +0530 IST
Yes
No
Send your feedback to us