RAG
What is Retrieval-Augmented Generation (RAG)?
To understand RAG, let’s consider a simple analogy: A user contacts tech support with an error code—“7C05”—displayed on their printer. Though experienced, the support agent hasn’t encountered that specific code before. Instead of making an educated guess, the agent consults the official troubleshooting manual for that particular printer model to find an accurate solution. In this scenario, the agent represents the language model, and the manual represents the external knowledge source that RAG retrieves, allowing the agent to respond correctly without needing prior exposure to that exact issue.
In technical terms, RAG is an advanced technique that enhances the accuracy, relevance, and reliability of large language model (LLM) outputs by incorporating information retrieved from authoritative, external knowledge sources. Rather than relying solely on the data available during training, RAG enables a model to consult up-to-date and domain-specific content at the time of inference, grounding its responses in verifiable and contextually appropriate information.
LLMs are built upon neural network architectures and trained on vast volumes of textual data. Their performance is largely driven by billions of parameters, which capture generalized patterns in human language. This parameterized knowledge equips LLMs to perform a wide range of tasks, such as answering questions, translation, and text completion with impressive fluency. However, these models can be limited when asked to generate responses that require specific, detailed, or time-sensitive information beyond their training scope.
RAG addresses this limitation by optimizing the generative process to retrieve relevant content from a curated knowledge base first—such as internal company documents, domain-specific databases, or trusted online sources—and then generate responses that are both informed and contextually grounded. This particular approach does not require any retraining of the base model, which makes it a cost-effective and scalable method for tailoring LLM capabilities to specific organizational needs or specialized domains.
Benefits of RAG
RAG offers a range of significant advantages that enhance the effectiveness, flexibility, and trustworthiness of generative AI solutions, particularly for organizations looking to implement domain-specific intelligence without the overhead of retraining large models.
Cost-efficient deployment
Most chatbot and AI application development begins with foundation models such as large language models (LLMs) trained on extensive, generalized datasets and typically accessed via APIs. Tailoring these models through retraining to accommodate organizational or industry-specific content is often prohibitively expensive and resource-intensive. RAG provides a more scalable and economical alternative. By enabling the model to retrieve and reference external data during inference, RAG enables businesses to integrate specific knowledge without modifying the underlying model, which makes generative AI solutions more attainable and cost-effective.
Access to timely, dynamic information
Maintaining up-to-date responses is a major challenge for static models, as their training data quickly becomes outdated. RAG addresses this issue by allowing the users to feed the model with continuously updated information sources. Whether it’s the latest scientific research, breaking news, or real-time social media feeds, RAG equips generative AI models with access to current data. This ensures responses remain relevant and accurate, even in rapidly evolving domains.
Improved transparency and user trust
One of the key strengths of RAG is its ability to provide source-based answers. By referencing external documents and including citations, it offers transparency into where the information originated. Users can review these sources to verify the content or explore further, enhancing their trust in the system. This traceability makes generative AI responses not only more credible but also more aligned with compliance or quality assurance standards in regulated industries.
Applications of RAG
Retrieval-Augmented Generation (RAG) is increasingly being adopted across industries to enhance the capabilities of large language models (LLMs), especially in areas requiring domain-specific knowledge, real-time information, or transparent outputs. Below are several key application areas where RAG delivers significant impact:
Enterprise knowledge assistants
Enterprises are increasingly turning to RAG-based assistants to streamline internal knowledge access for employees. These AI-powered tools are designed to query structured and unstructured data from company-specific repositories, such as internal wikis, SOPs, HR guidelines, compliance checklists, IT documentation, and onboarding materials. Unlike static chatbots, which rely on predefined rules or outdated training data, RAG dynamically fetches the most relevant documents, ensuring employees receive accurate, up-to-date, and policy-aligned responses. This leads to higher productivity, reduced dependency on support teams, and a unified source of truth across departments.
Customer support automation
Customer service platforms can significantly elevate the user experience by integrating RAG to deliver more intelligent and context-aware interactions. By retrieving content directly from product manuals, troubleshooting guides, warranty documents, and helpdesk knowledge bases, RAG-powered chatbots can resolve customer queries more effectively—even those related to recently launched or rarely encountered products. This eliminates the constant need to retrain models on new content and enables scalable support operations with minimal human intervention. The inclusion of traceable sources also builds customer trust and increases customer satisfaction.
Legal and regulatory research
Legal professionals operate in a domain where accuracy, citation, and traceability are paramount. RAG-based tools empower legal teams by enabling direct retrieval of clauses from statutes, prior case law, government policies, or internal compliance documents. Instead of sifting through voluminous texts manually, users can obtain concise summaries, cross-referenced with the original documents for legal soundness. These applications are especially useful in drafting legal opinions, conducting regulatory audits, or preparing responses for compliance reviews, ensuring that every output is grounded in verifiable legal context.
Healthcare and medical decision support
In the healthcare sector, timely and evidence-based decision-making can directly impact patient outcomes. RAG systems support clinicians, researchers, and administrators by referring to data from medical sources such as treatment guidelines and institutional clinical records. By incorporating relevant information into its responses, an RAG model can assist with clinical decision support, patient-specific care recommendations, diagnostic differentials, or drug interactions, all while citing source material. This approach enhances confidence in AI-driven recommendations.
Scientific research and technical writing
RAG plays a vital role in accelerating research workflows and ensuring content precision in technical writing. Researchers can query expansive academic databases to summarize the state of the art, generate literature reviews, or validate hypotheses with current findings. Similarly, technical writers can use RAG to draft product documentation based on the latest data and user manuals. Whether summarizing scientific developments or drafting reports, RAG ensures the generated content is supported by reliable, domain-specific sources, and thereby maintains both accuracy and credibility.
How does RAG work?
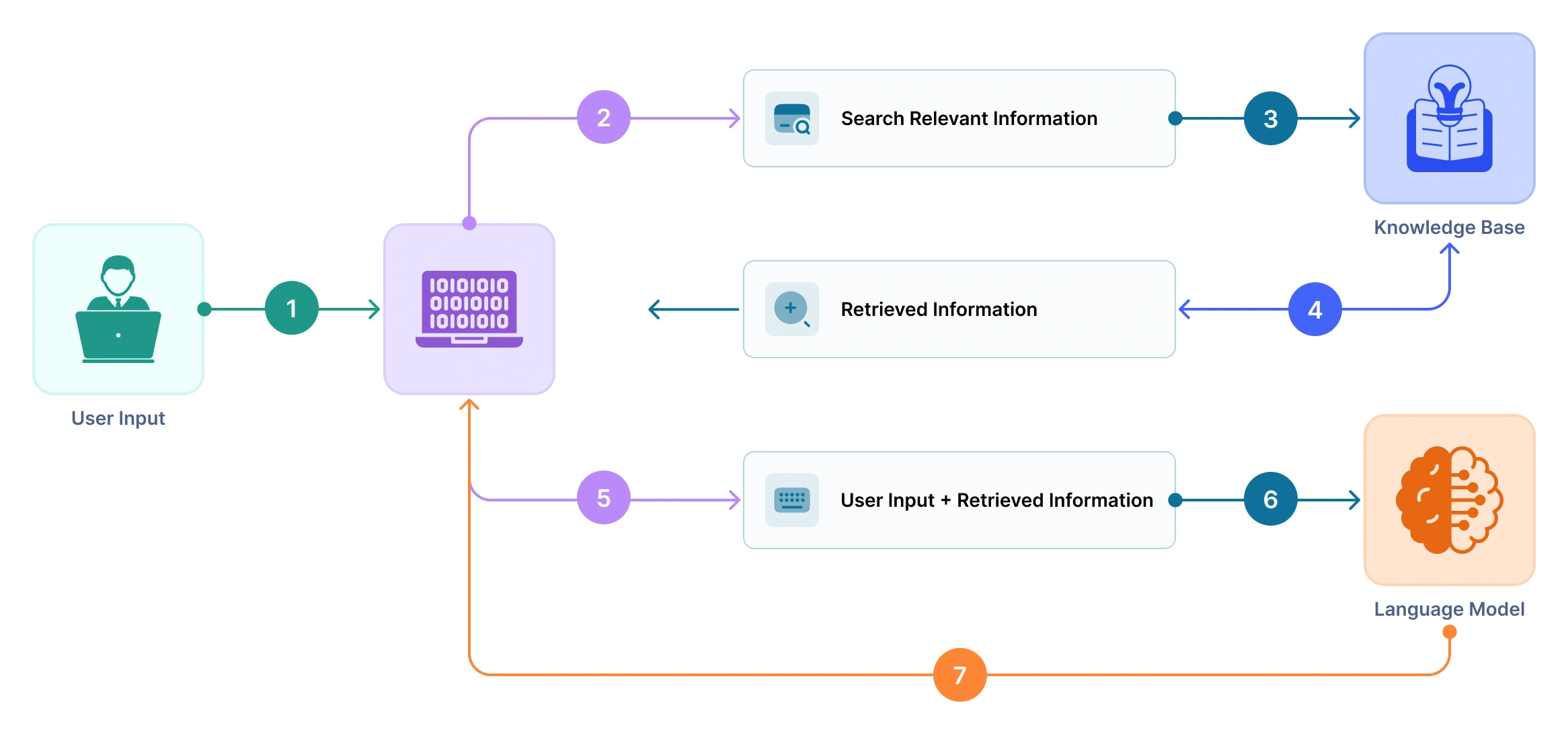
RAG integrates two key processes: retrieval and generation. Instead of relying solely on the knowledge encoded during a language model’s training, RAG supplements it by dynamically pulling in relevant information from external sources (like databases, documents, or knowledge bases) at inference time. This approach enables the model to deliver responses that are more accurate, current, and contextually appropriate.
Here’s a simplified flow of how RAG works:
-
User input/query: The process begins when a user inputs a question or prompt.
-
Retrieval: The system uses the query to search a large external knowledge source (e.g., vector database, document store, or search index) to retrieve the top-k most relevant pieces of information (often called “passages” or “contexts”). This is typically done using semantic search powered by embeddings.
-
Fusion/contextualization: The retrieved passages are then passed along with the original query to a language model. These passages provide context that grounds the generation in factual or domain-specific knowledge.
-
Generation step: The language model (e.g., a transformer-based LLM) takes both the query and the retrieved documents as input and generates a coherent and informed response.
-
Citation/traceability: Since RAG models rely on actual documents for answers, they can provide traceable references or links to the source material, increasing transparency and trust.
What makes RAG in QuickML unique?
QuickML’s RAG is designed to offer a seamless, secure, and transparent experience when generating responses powered by a knowledge base. Here’s what sets RAG in QuickML apart:
-
Once a response is generated, a detailed response breakdown becomes available. This breakdown indicates which parts of the retrieved documents were referenced during the generation process and clearly shows the origin of the supporting information. It enhances transparency by allowing you to see exactly which documents contributed to the final output
-
QuickML’s RAG implementation leverages the Zoho ecosystem—such as WorkDrive and Zoho Learn—to import relevant documents into the knowledge base seamlessly. This integration ensures that the most accurate and context-specific information is always available to support your queries.
Available models in QuickML’s RAG
RAG in QuickML leverages the Qwen 2.5 14B Instruct model to deliver contextual and relevant responses. Qwen 2.5 14B Instruct is a highly capable AI model engineered to perform a diverse range of language tasks with consistency and precision. Trained on large-scale, high-quality datasets, it delivers reliable outcomes and demonstrates strong performance across multiple benchmarks. What sets Qwen 2.5-14B-Instruct apart is its ability to quickly adapt and respond to dynamic real-world scenarios, making it exceptionally suited for enterprise and production-grade applications.
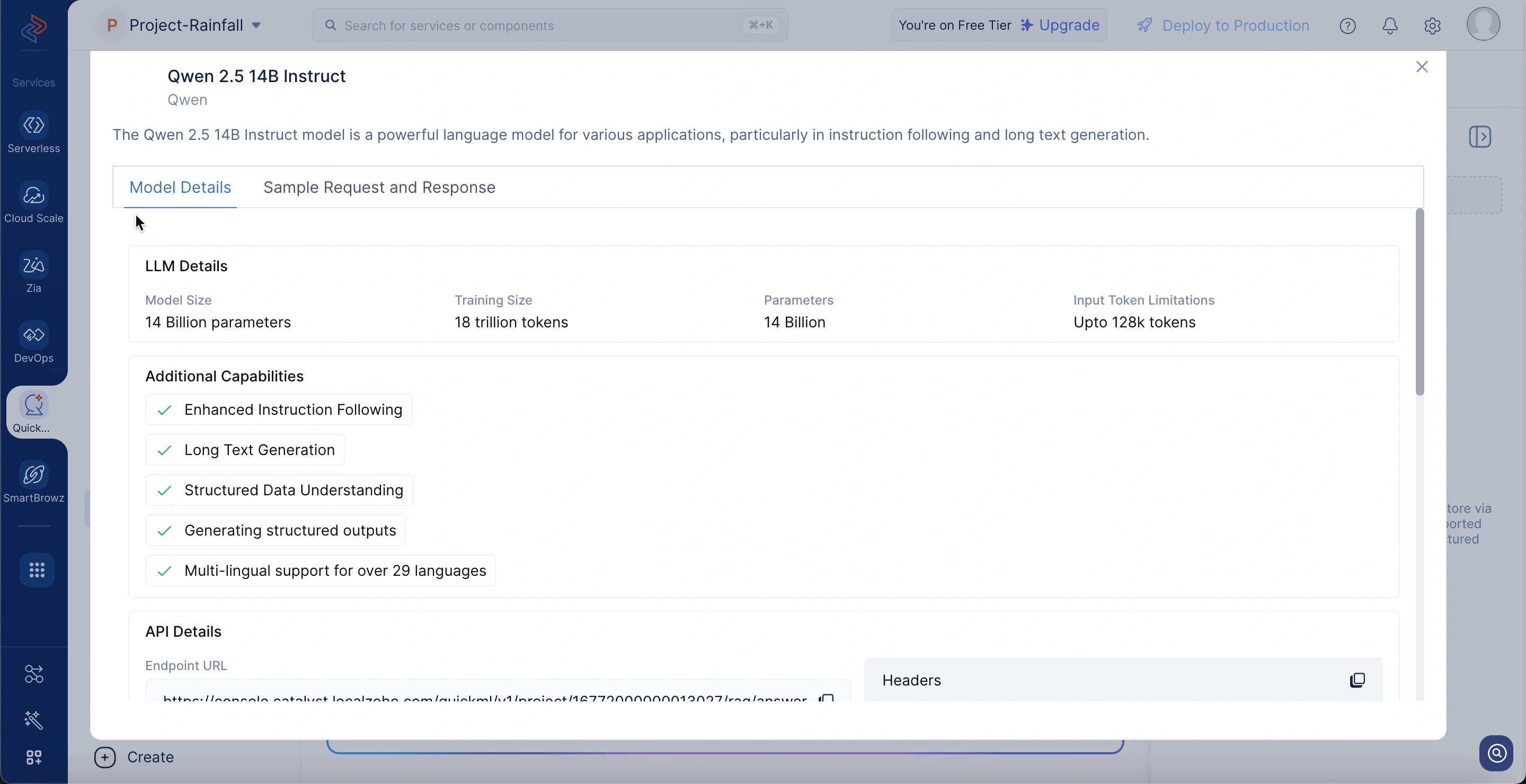
Qwen 2.5 14B Instruct model details
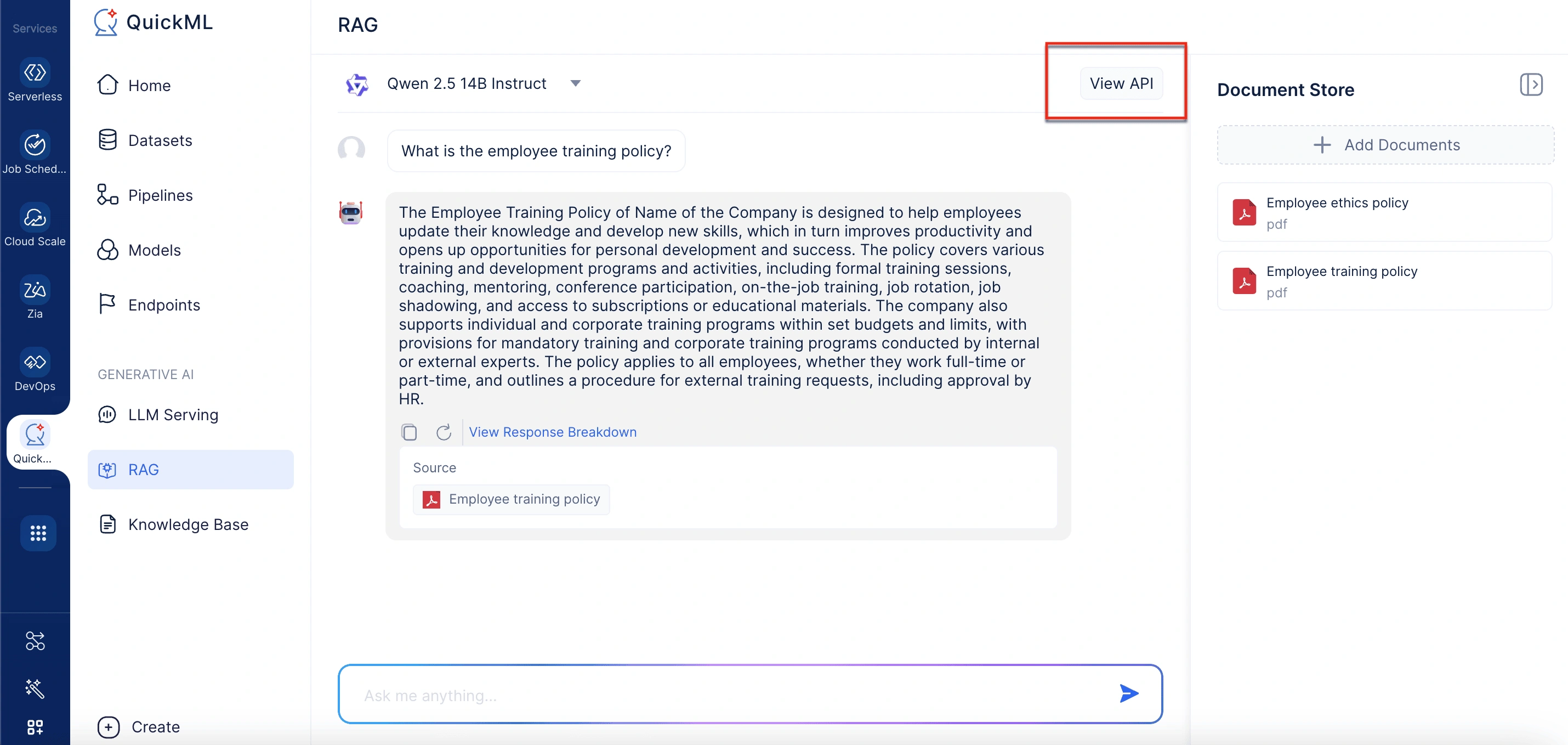
To view the model’s details, go to the RAG tab and click on the View API option in the top-right corner of the chat interface. The model details include:
-
Model size: Comprises 14 billion parameters, enabling sophisticated comprehension and language generation capabilities.
-
Training size: Trained on 18 trillion tokens to ensure extensive coverage across a wide range of domains.
-
Parameters: Utilizes 14 billion trainable weights for generating nuanced and highly relevant responses.
-
Input token limitations: Supports 128K tokens with input context length, allowing for deep context and long document references during RAG execution.
-
Endpoint URL: This is the URL used to send API requests.
-
OAuth Scope: QuickML.deployment.READ; defines the access level required to use the deployment.
-
Authentication: OAuth is used to verify the client identity securely.
-
HTTP method: POST; all API calls must be made via the POST method.
-
Headers: Include required metadata and the authorization token to authenticate requests.
-
Sample request: A predefined JSON format shows how to structure your input prompt.
-
Sample response: Displays the model’s output, including contextually grounded text generated based on both the prompt and the retrieved information from KB documents. You can refer to the Integrating RAG into your applications section for the steps to integrate the model into your application.
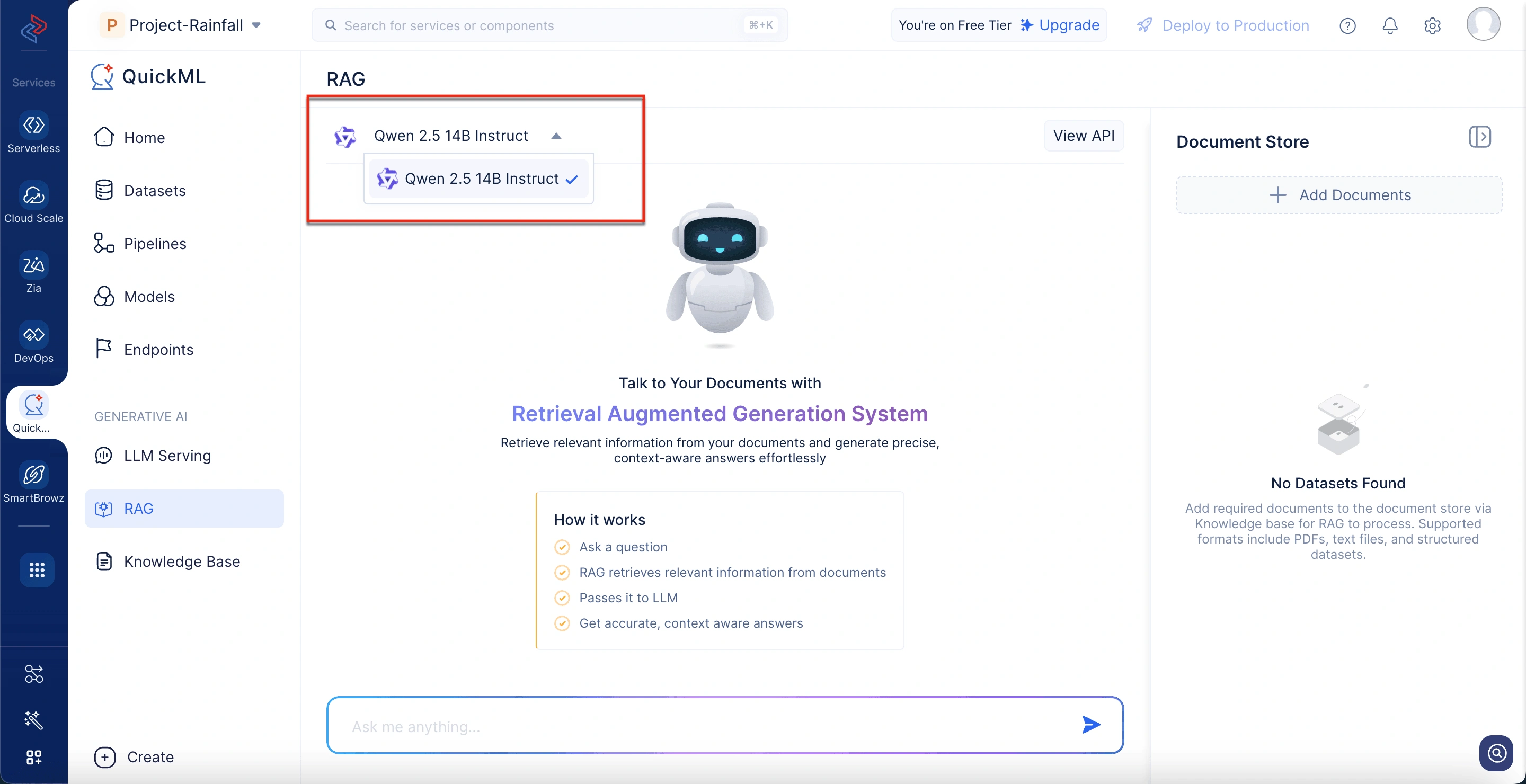
Understanding the RAG interface in QuickML
The RAG feature in QuickML enables you to get document-based responses using Qwen 2.5 14B Instruct. The interface is designed to make it easy to upload documents, ask questions, and trace the source of each response. Here’s a breakdown of how it looks.
Model selection
At the top of the chat panel, users can select the available model. Currently, Qwen 2.5 14B Instruct is supported for RAG-based conversations. This model is optimized for generating grounded and context-aware responses from uploaded documents.
Chat interface (conversation panel)
At the center is the core interaction space where you enter your queries and view responses. Each AI-generated answer is threaded beneath the user input and can include:
- Action icons for copying or regenerating the response
- A “View Response Breakdown” option, which gives insights into how the answer was generated and from which documents
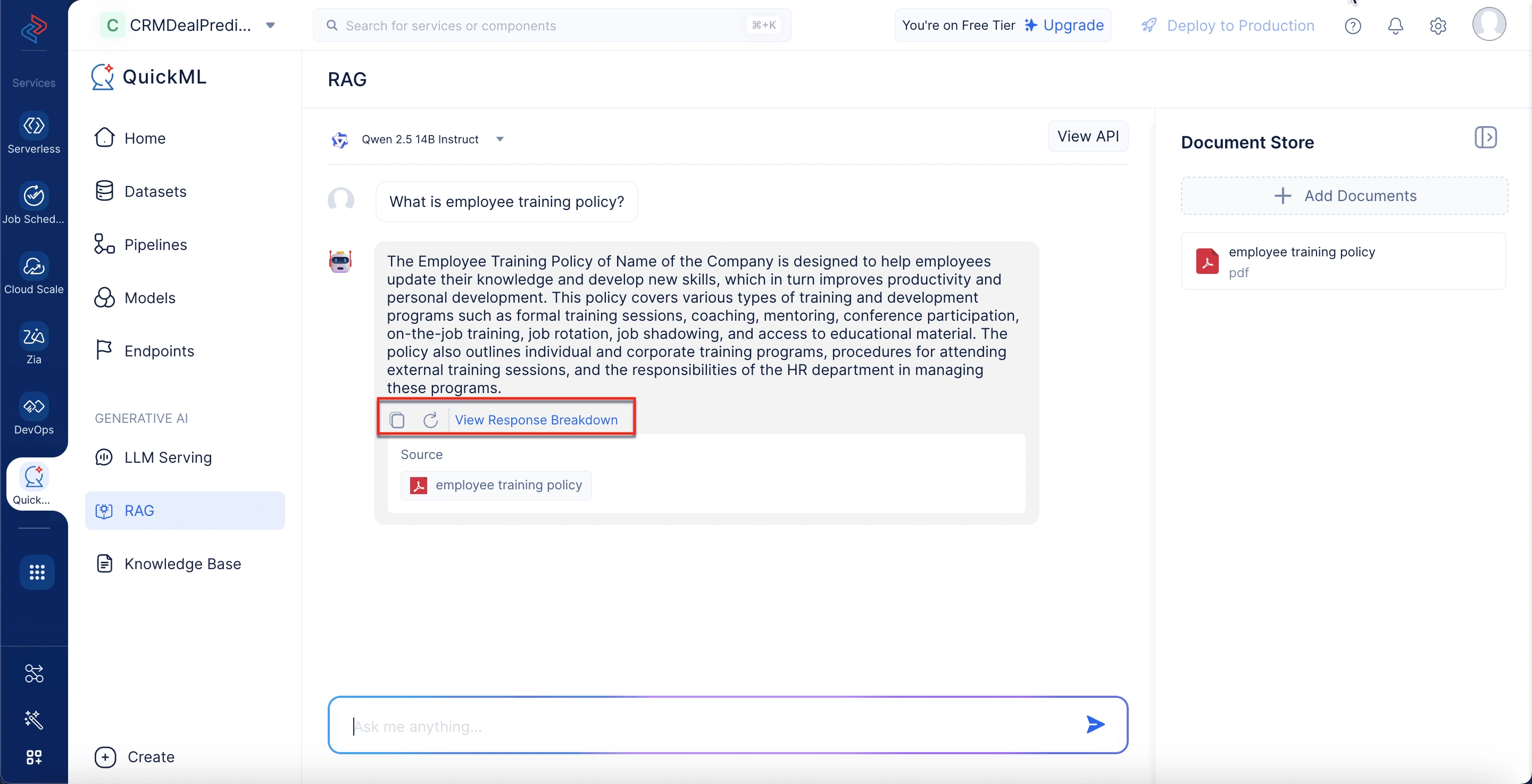
Response breakdown panel
When you click on “View Response Breakdown”, a pop-up window appears, offering detailed insights:
-
Thought process: Shows the specific content snippets referenced during answer generation, along with their corresponding sources and document IDs.
-
Citations: Lists down the documents used and highlights the exact sections that are used to generate the response.
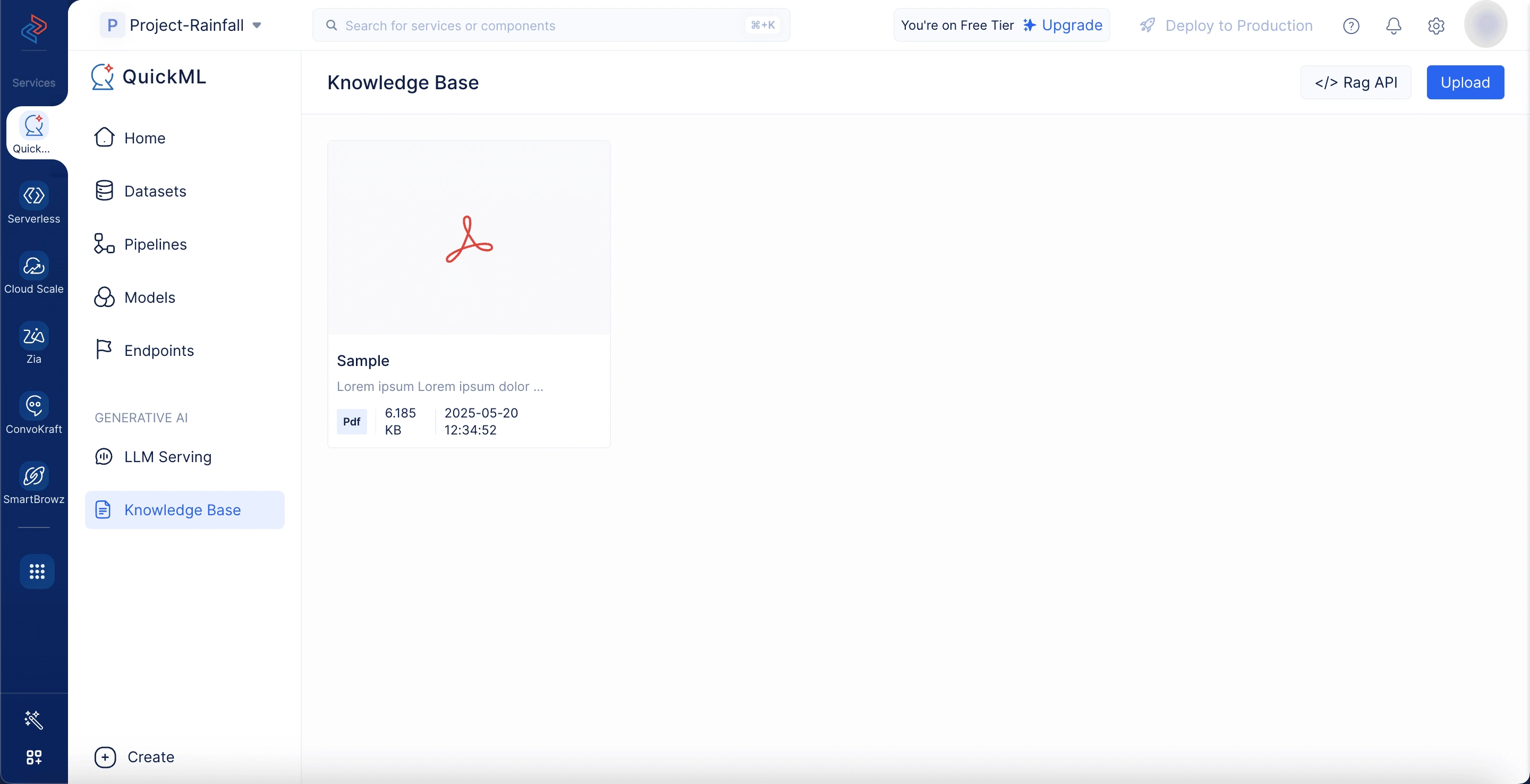
Document store
On the right side of the interface, the document store lists all documents currently active for retrieval. Each document shows its name, format, and size. Users can include relevant documents for response generation from the knowledge base by selecting the Add Documents option.
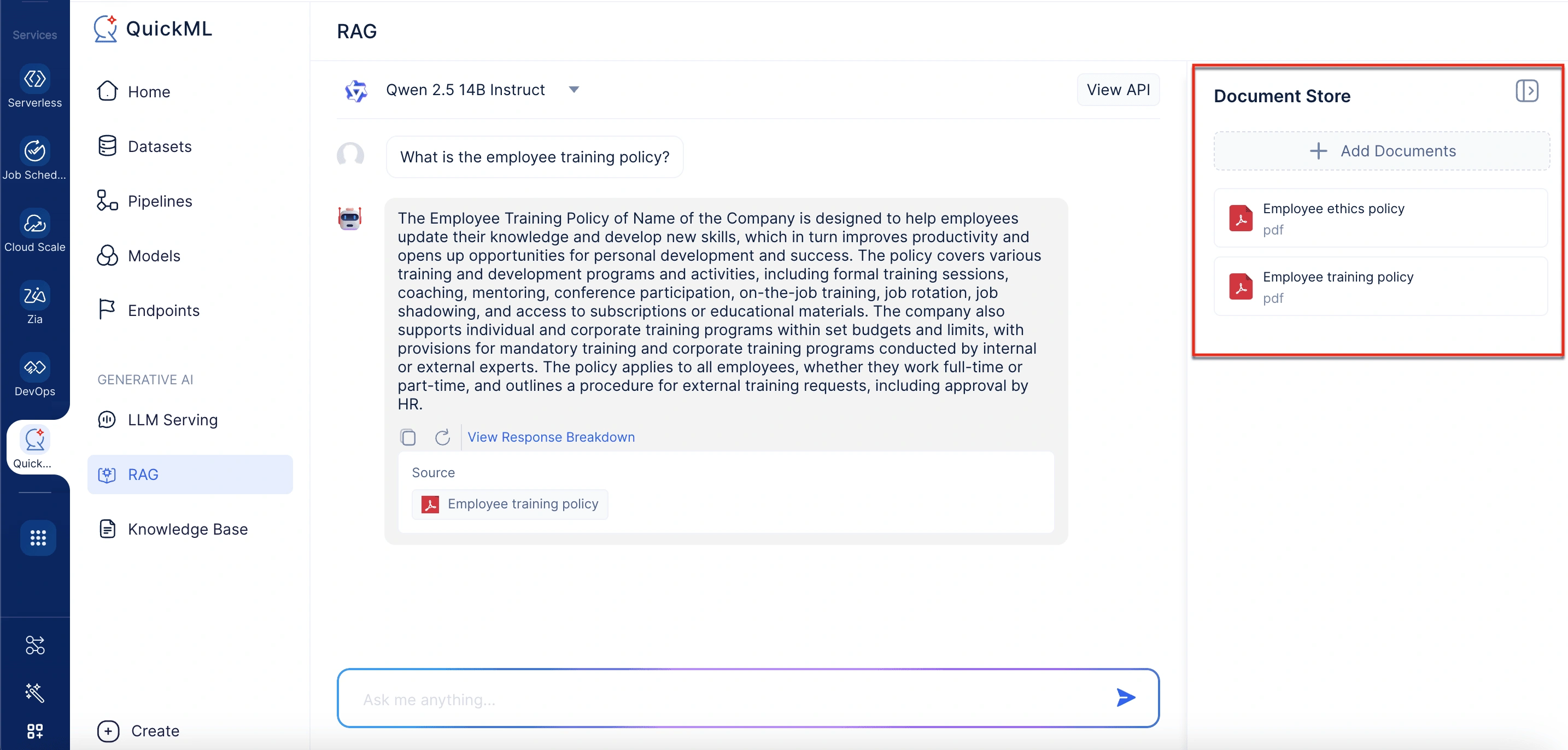
Adding documents
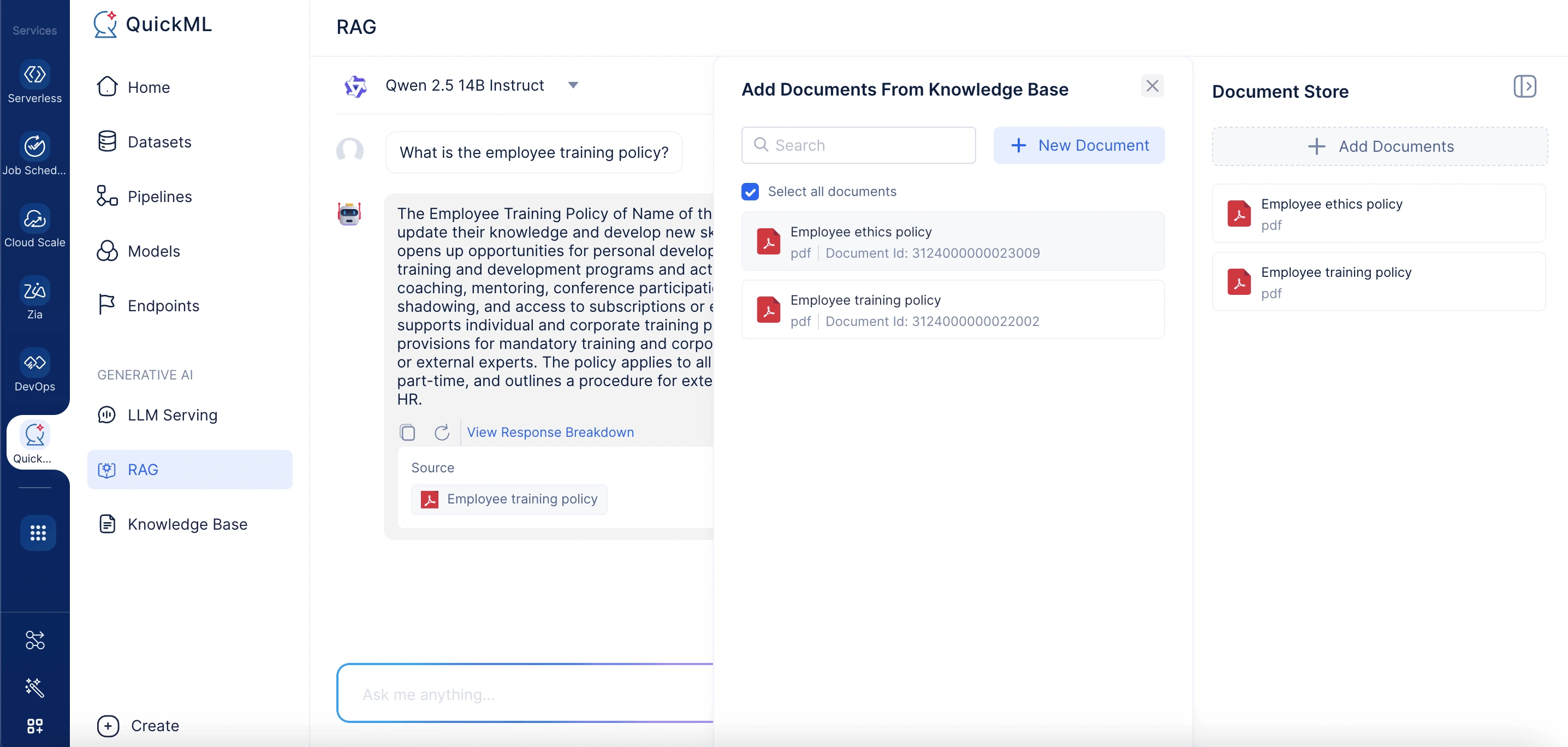
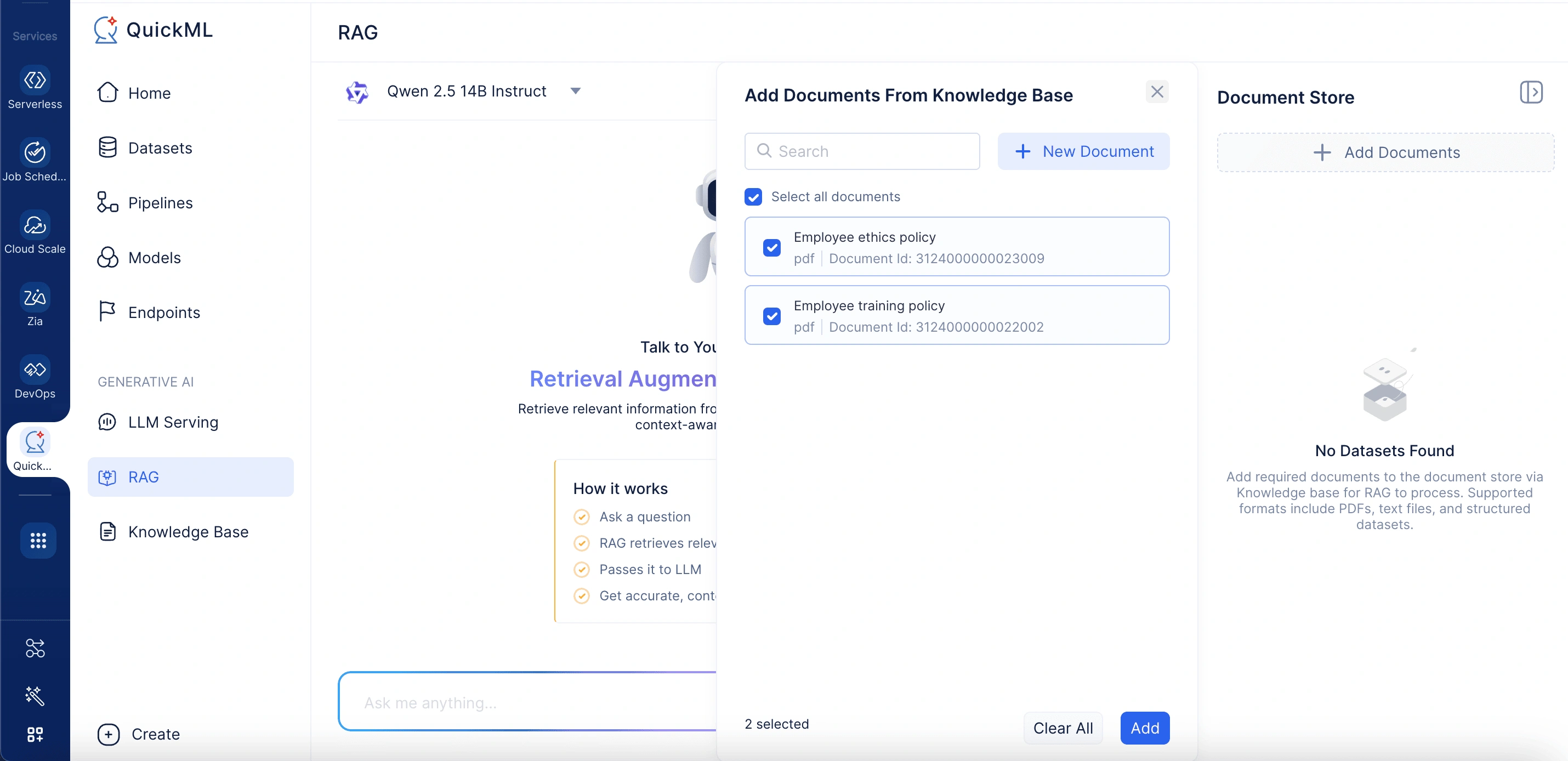
Clicking Add Documents opens a panel labeled Add Documents From Knowledge Base. Here, users can either select existing documents or upload new ones. The panel includes a search bar to locate documents in the knowledge base quickly.
-
Upload options
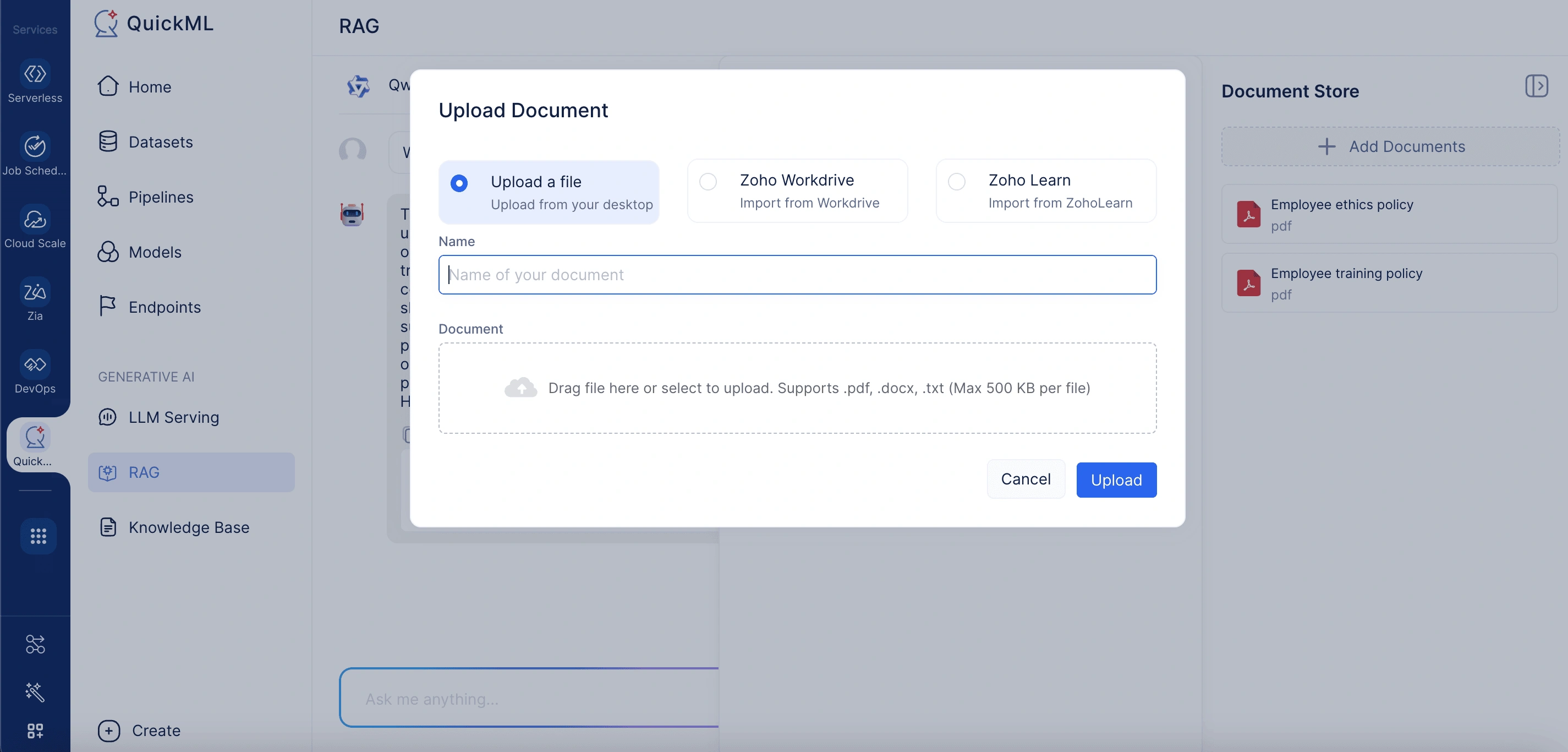
When uploading a new document, three convenient methods are supported:
- From desktop: Supports .pdf, .docx, and .txt files, with a size limit of 500KB per file.
- From WorkDrive: Allows users to import files directly from cloud storage.
- Via Zoho Learn link: Enables document import by pasting the URL of the desired Zoho Learn article.
Each uploaded file is assigned a unique ID and becomes available for retrieval during conversations.
Uploading the documents to the knowledge base
To ensure that documents appear in the Add Documents From Knowledge Base panel, relevant files must first be uploaded to the Knowledge Base repository.
Please note that, upon clicking on New Document in the Add Documents From Knowledge Base panel, the documents would get automatically added to the knowledge base.
The Knowledge Base functions as a centralized document repository where users can upload and manage content critical for context-aware generation. Integration with Zoho ecosystems like WorkDrive and Zoho Learn enables seamless import of internal files, manuals, FAQs, and other resources. This setup ensures that the Knowledge Base remains current and comprehensive, supporting the model’s ability to provide source-backed responses tailored to user queries.
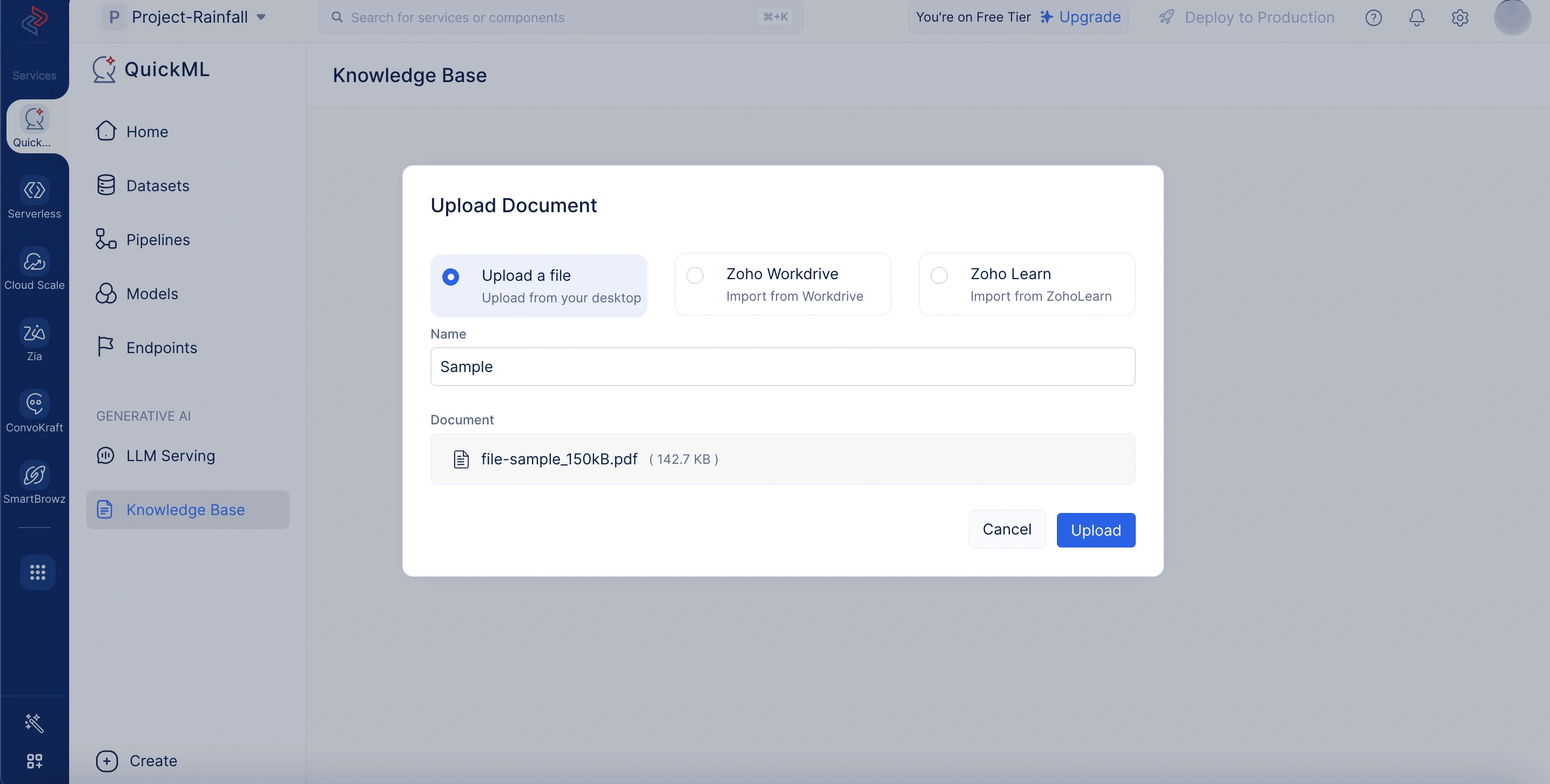
To upload documents from the knowledge base
- Navigate to the Knowledge Base tab in the QuickML platform.
- Click Upload Document.
- Choose any of the following ways to upload the document,
- Select Upload a file to upload the document from your desktop. Here, you have to enter the name and select the file to upload from your local system.
- Select Zoho Workdrive to import the document from workdrive. Here, you have to provide the document name and workdrive link of your document.
- Select Zoho Learn to import an article from Zoho Learn. Here, you have to enter the document name, select whether you’re importing an article or a manual, and provide the article link.
- Once uploaded, the document will appear in the knowledge base repository. From there, you can delete it or copy the document ID as needed.
Notes:
-
Uploaded documents in the document store can be deleted by hovering over the desired document and clicking the Delete icon.
-
When a query is submitted with specific knowledge base documents added to the document store, RAG limits its search to only those added documents. If no documents are added to the document store, RAG automatically searches across all active knowledge base documents. This ensures that the query is answered using the most relevant available content without requiring manual document selection.
View API
The chat interface also includes a View API option in the top-right corner. Selecting this opens a panel that displays detailed information about the current model, such as its size, token limits, endpoint URL, and authentication requirements.
How RAG works in QuickML
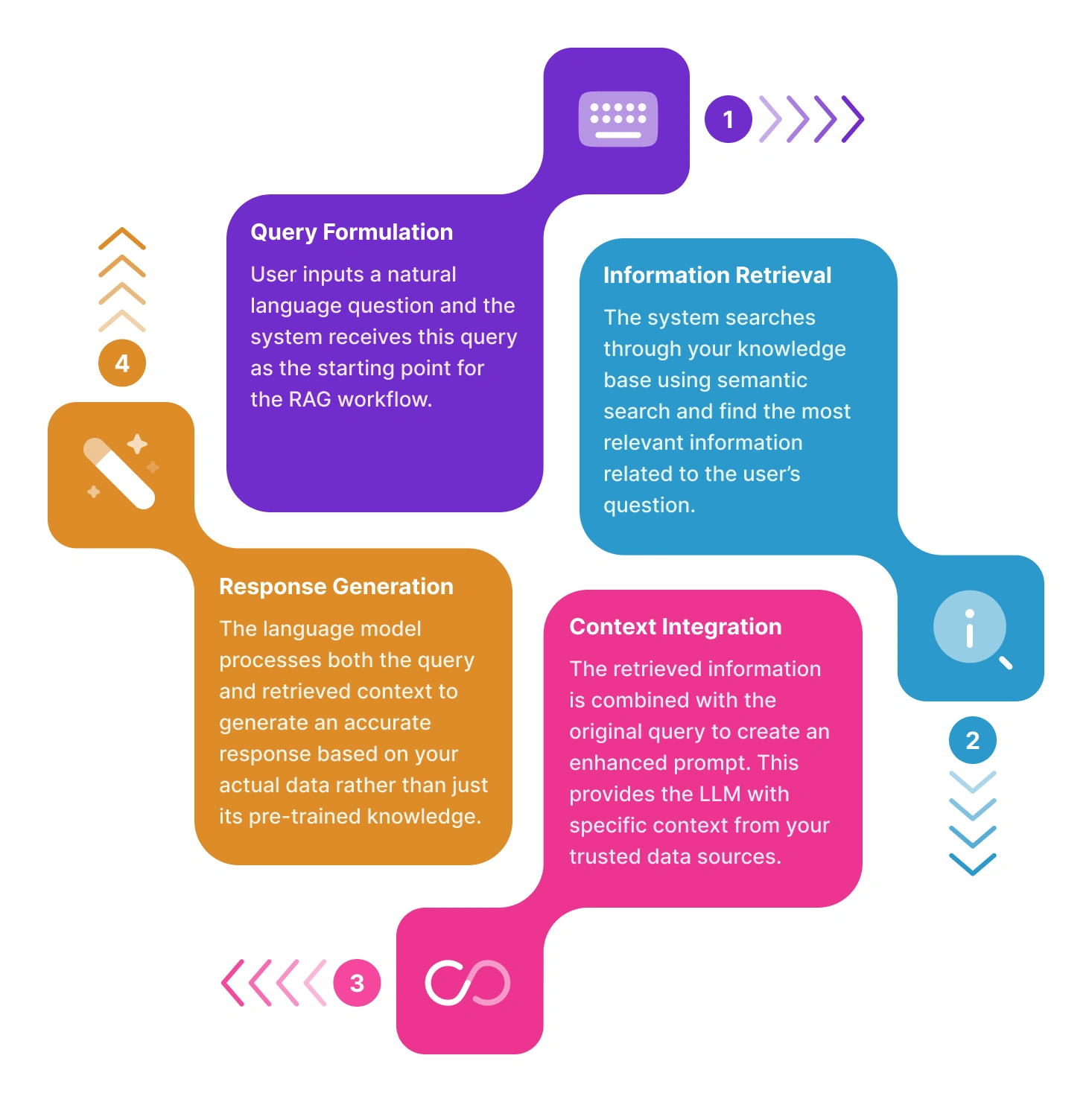
Without RAG, a large language model (LLM) generates responses solely based on its training data. With RAG, the process is enhanced by introducing an external information retrieval step, allowing the model to access fresh, relevant data at the time of the query. Here’s how it works in brief:
Ask a question
The user begins by entering a natural-language query, for example, “What’s our company’s return policy?” or “Summarize the latest updates in our product documentation.” This query acts as an initial input that triggers the RAG pipeline.
Retrieve relevant information from your documents
Instead of relying solely on the language model’s pre-trained knowledge, RAG connects to your knowledge base (like internal files, PDFs, etc.). Using advanced embedding and semantic search techniques, the system identifies and fetches the most relevant pieces of information based on the user’s question.
Refine results with re-ranking
Once relevant documents are retrieved, a re-ranking process is applied to better align the selected content with the user’s intent. This step evaluates multiple signals—such as semantic similarity and keyword presence—to reorder the results and surface the most contextually appropriate content for the query.
Pass it to the LLM
The retrieved content is then combined with the original query and sent as an augmented prompt to the LLM (Qwen 2.5-14B-Instruct). This step allows the LLM to read the context-specific information and use it to generate an informed response.
Generate context-aware answers
With both the user query and supporting data in hand, the LLM crafts a response that’s not only relevant but based on the actual source material. This approach helps ensure responses are based on verifiable information and aligned with the source material. It also allows users to trace answers back to original documents, which promotes transparency and builds confidence in the system.
Important notes
-
The RAG feature is available to users who have access to the QuickML platform.
-
Chats are user-specific, ensuring that one user cannot access any other user’s conversation. Currently, chat history is not supported. Conversations remain visible until the page is refreshed; once refreshed, all chats are cleared.
Accessing RAG in QuickML
RAG can be accessed within QuickML via these steps:
- Log in to your QuickML account.
- Under the Generative AI section, select RAG.
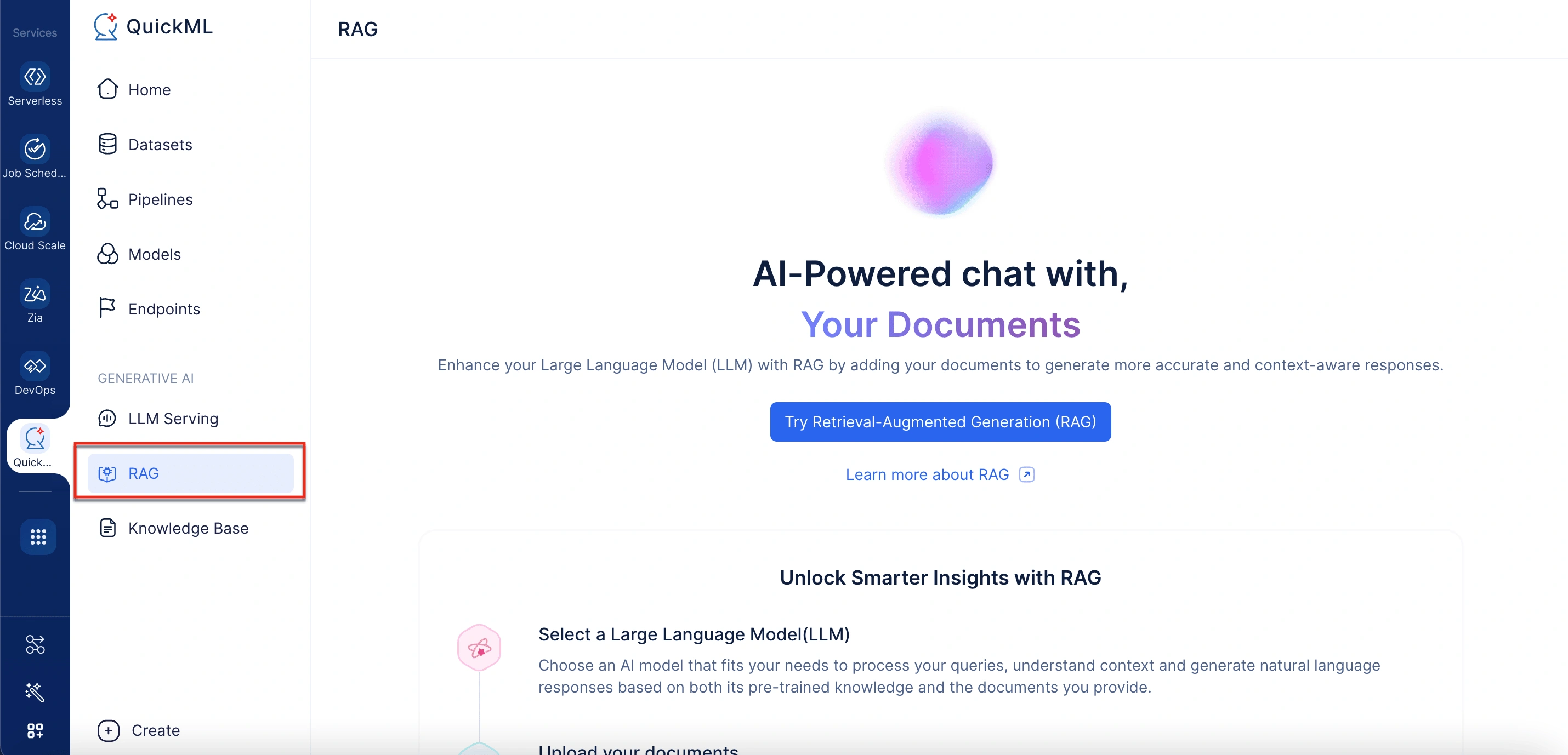
- Under Document Store in the right panel, click Add Documents. This will open a panel labeled Add Documents From Knowledge Base.
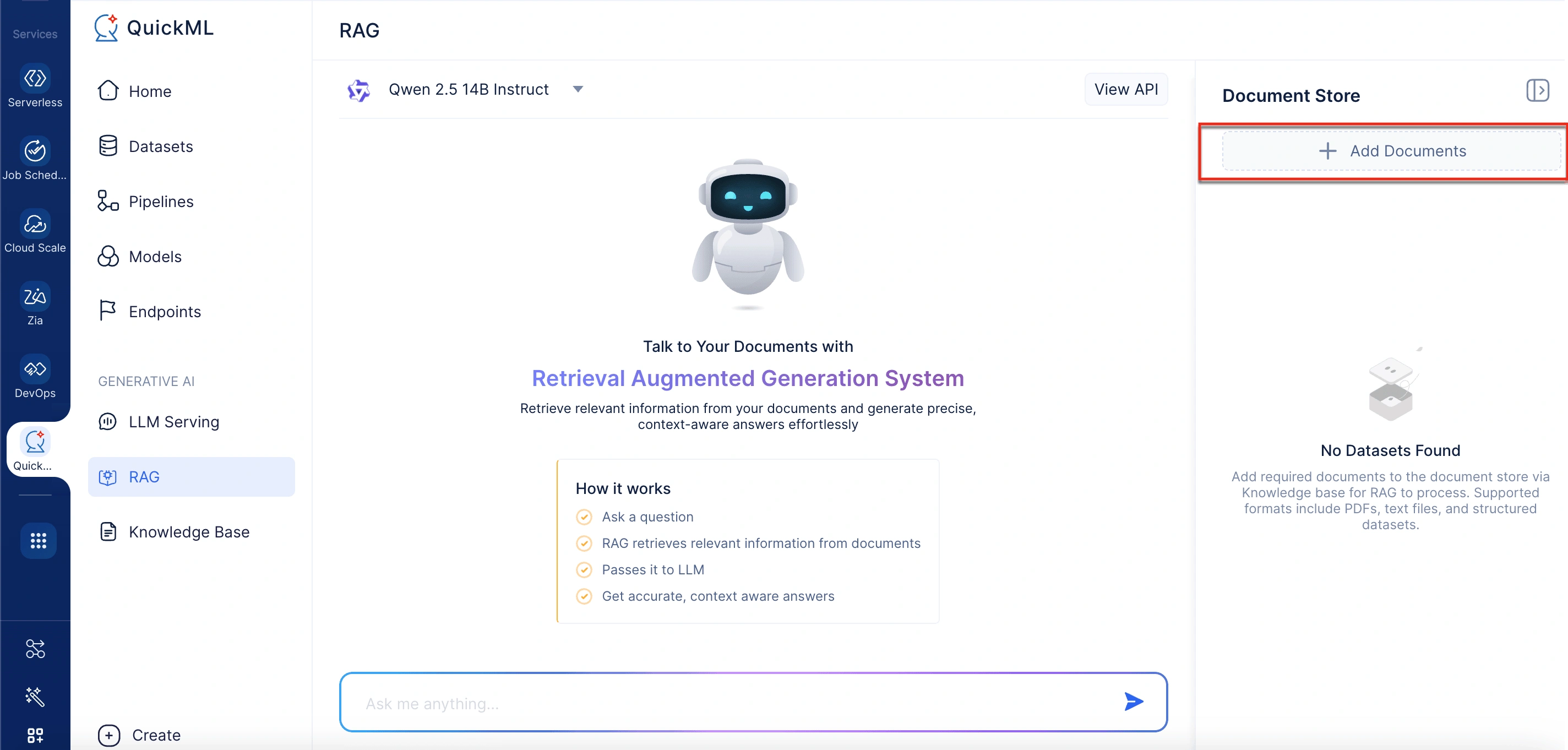
- In the Add Documents From Knowledge Base panel, select existing files or click New Document to upload from your desktop, WorkDrive, or Zoho Learn.
- Enter your queries in the chat interface.
The model will retrieve relevant information from the knowledge base and provide context-aware responses, including the detailed response breakdown.
Note: Responses are generated based on the documents stored in the knowledge base. You can add new documents as necessary to ensure the model has the required data to answer queries.
Let’s consider some sample use cases to understand how RAG can be used in a real-time business scenario.
Sample use case 1: Implementing RAG for employee policy assistance in an organization
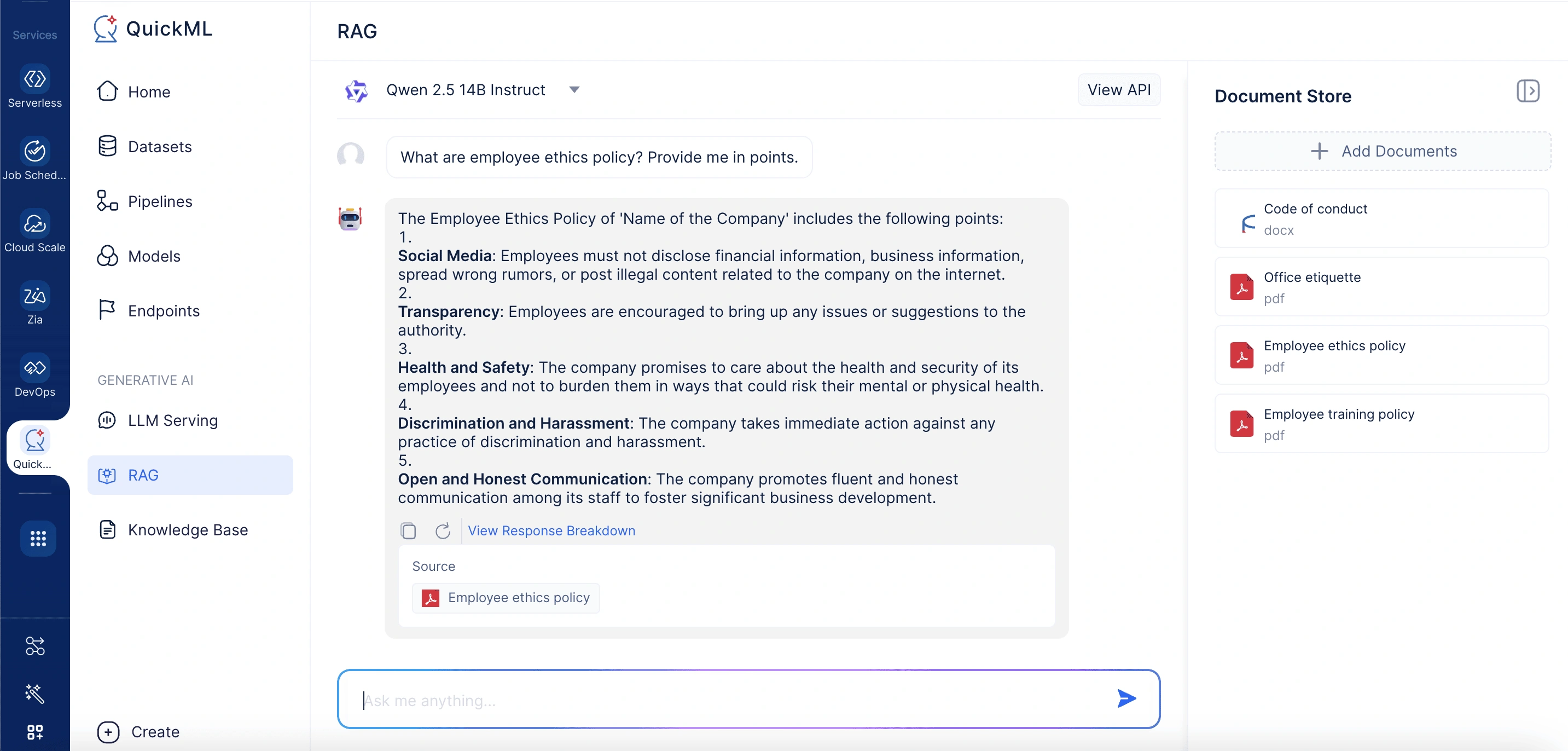
A company aiming to improve employee understanding of ethics and training policies begins by gathering all relevant documents—such as the Code of Conduct, Office Etiquette Policy, Anti-Harassment Policy, Workplace Behavior Guidelines, and Mandatory Training Manuals—and uploading them into QuickML’s RAG knowledge base. From the RAG chat interface, the administrator accesses the Add Documents From Knowledge Base panel to import or select existing files. Once uploaded, the documents form a centralized, structured repository that Qwen 2.5 14B Instruct can reference during user interactions.
When an employee asks a question like “What are the employee ethics policy?”, QuickML’s RAG system conducts a semantic search across the uploaded policies, retrieves the most relevant information, and combines it with the query. This context is then sent to Qwen 2.5 14B Instruct, which generates a concise and contextually accurate answer. The user can also view a detailed breakdown of which documents and specific sections were used to generate the response—ensuring transparency and trust in the information provided.
Sample use case 2: Enhancing customer support with RAG for a SaaS platform
A SaaS company aiming to improve its customer support experience leverages RAG to build an intelligent help assistant. The support team collects all relevant resources—product FAQs, user manuals, troubleshooting guides, release notes, and API documentation—and uploads them into the RAG knowledge base within QuickML. Through the RAG chat interface, the admin uses the Add Documents From Knowledge Base panel to populate the document store with this content, ensuring it stays up to date with each product release. Once set up, the RAG system becomes a central support repository.
When a user submits a query like “What are the possible error messages?”, the system semantically searches the document store for the most relevant information, retrieves matching content, and forwards both the query and supporting context to the language model. The model then generates an accurate, easy-to-follow solution, referencing the precise documentation sections. Users can view the source material behind the response for transparency and further reading, reducing ticket volume and improving self-service effectiveness.
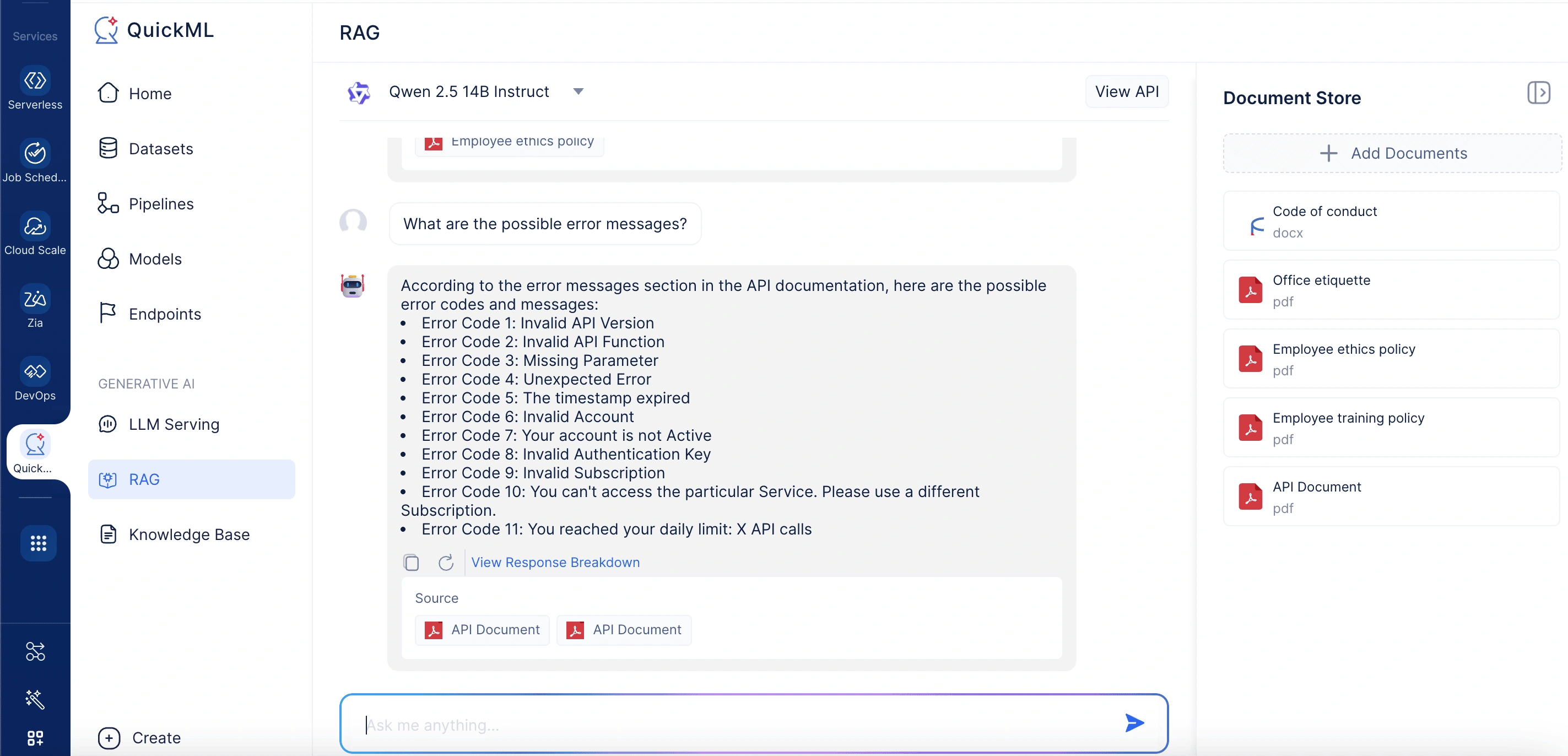
Integrating RAG into your applications
You can integrate QuickML’s RAG into your applications using the provided endpoint URL. This enables businesses to enhance customer support tools, internal chatbots, and document automation systems with context-rich AI capabilities.
To enable secure and efficient integration, QuickML supports OAuth-based authentication for access token generation. You can refer to this documentation for details on different types of OAuth applications and the steps required to generate and manage access tokens.
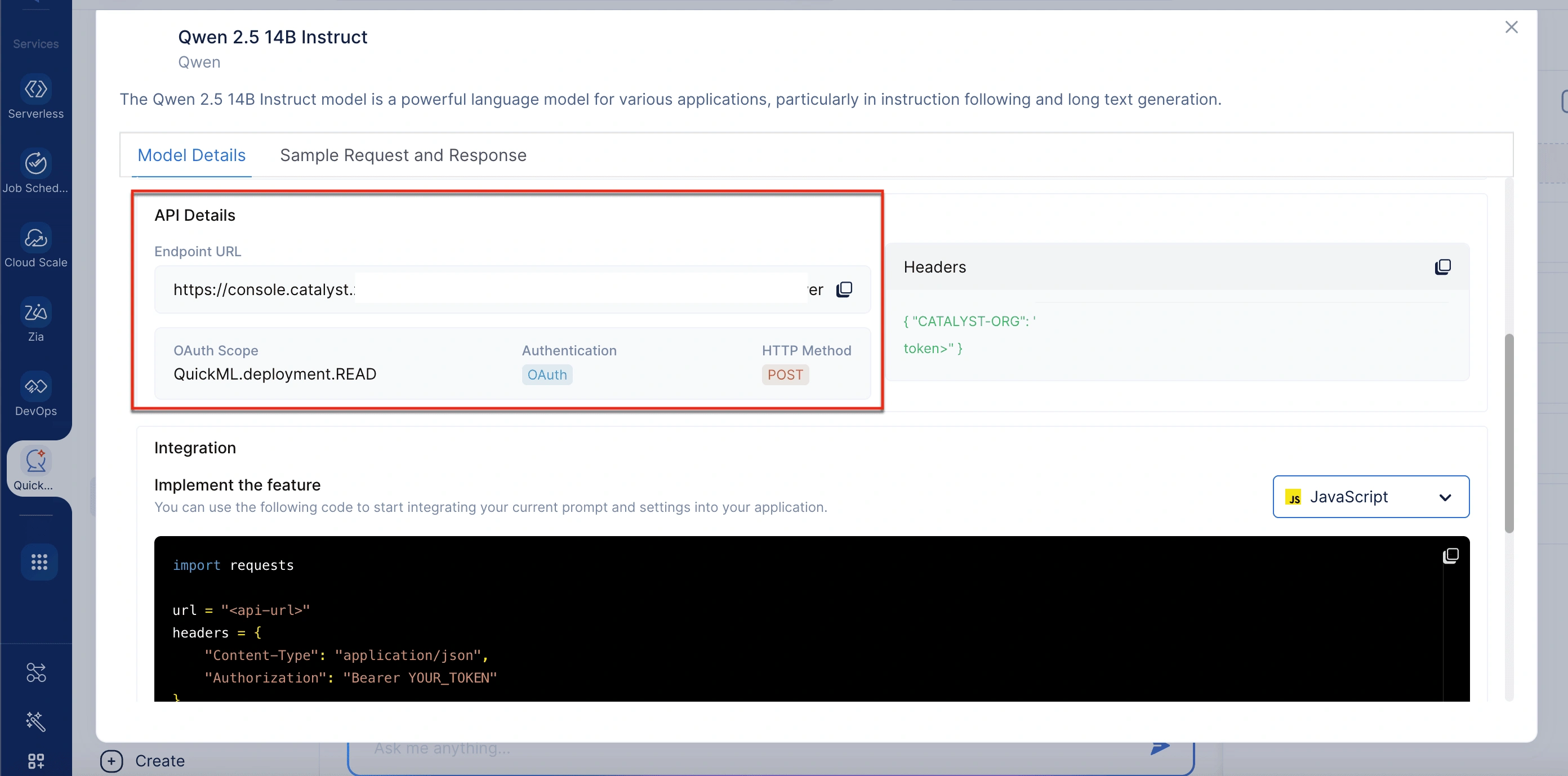
To get the endpoint URL
- Navigate to the Generative AI section in QuickML.
- Select the RAG tab.
- Click the View API option in the top right corner of the chat interface.
- In the Model Details pop-up window, scroll to the API Details section to get the endpoint URL.
Last Updated 2025-10-08 19:32:16 +0530 IST
Yes
No
Send your feedback to us