LLM Serving
Introduction to Large Language Model (LLM)
A Large Language Model (LLM) is an advanced AI system trained to generate human-like text based on patterns learned from vast amounts of data such as books, websites, and articles. It leverages deep learning techniques, particularly the Transformer neural network architecture, which processes entire sequences of input in parallel—unlike earlier models like Recurrent Neural Networks (RNNs), which handled inputs sequentially. This parallelism enables the use of GPUs for efficient training, significantly accelerating the process. This training typically involves unsupervised or self-supervised learning, where the model learns to predict the next word in a sentence by recognizing patterns, grammar, and context within the data.
Mechanism of LLM
A fundamental aspect of how Large Language Models (LLMs) operate lies in their approach to representing words. Earlier machine learning models relied on simple numerical tables to represent individual words, which made it difficult to capture the relationships between words—particularly those with similar meanings. This limitation was addressed with the introduction of multi-dimensional vectors, known as word embeddings. These embeddings map words into a vector space where semantically or contextually similar words are positioned close to each other.
With these embeddings, transformers convert text into numerical formats using the encoder, allowing the model to grasp context, meaning, and linguistic relationships—such as synonyms or grammatical roles. This processed understanding is then used by the decoder to generate meaningful and coherent text, enabling LLMs to produce responses that reflect the structure and flow of natural language.
Applications of LLM
LLM enables real-time AI-powered solutions across various industries. Here are key applications where LLMs are making a significant impact:
Chatbots and virtual assistants
LLMs power AI-driven chatbots and virtual assistants used in customer service, e-commerce, and enterprise support. These assistants can handle customer queries, provide automated responses, and assist with troubleshooting. Businesses use them to enhance user experience and reduce response time. Content generation and summarization
Organizations leverage LLMs to generate high-quality content, such as articles, reports, and product descriptions. Additionally, LLMs summarize lengthy documents or news articles into concise and easy-to-read formats, saving time and effort for users.
Code generation and debugging
Developers benefit from LLMs that assist with writing, optimizing, and debugging code in multiple programming languages. These models help streamline software development by providing instant code suggestions and explanations, reducing development time.
Language translation and localization
LLMs enhance translation services by providing real-time, context-aware translations for businesses and individuals. This is particularly useful in global communication, enabling seamless interaction between people speaking different languages. Image and text analysis (Multimodal AI) Advanced multimodal LLMs, such as Qwen 2.5 - 7B Vision Language, process both text and images. These models can describe images, recognize objects, and answer visual questions. Industries such as healthcare, accessibility, and digital content moderation use these capabilities for enhanced automation and decision-making. Advanced multimodal LLMs, such as Qwen 2.5 - 7B Vision Language, process both text and images. These models can describe images, recognize objects, and answer visual questions. Industries such as healthcare, accessibility, and digital content moderation use these capabilities for enhanced automation and decision-making.
Understanding LLM Serving
LLM Serving involves deploying and running large language models (LLMs) so they can handle real-time requests for predictions or responses. When an LLM is trained, it can be used to perform a variety of tasks, such as generating text, answering questions, translating languages, or even understanding and analyzing large datasets.
Purpose of LLM Serving
The primary purpose of LLM Serving is to bridge the gap between a trained model and its real-world usage. It enables organizations to:
-
Operationalize AI models in production environments
-
Ensure scalability and reliability for handling real-time, concurrent requests
-
Offer seamless integration into products, tools, and business processes
-
Transform LLMs from research tools into practical, usable systems that drive business outcomes
Architecture of LLM Serving
A well-structured architecture ensures that an LLM-serving system runs efficiently and responds quickly. It typically consists of the following layers:
-
Client layer: Receives requests from users or applications, such as questions or text inputs.
-
API layer: Converts the requests into a format the LLM can understand and sends them to the model.
-
Model layer: Runs the LLM, processes the request, and generates a response.
-
Data layer: Handles input and output data, ensuring smooth data flow between the model and users.
Unique features of LLM Serving in QuickML
QuickML makes it easy to use various large language models (LLMs) within a chat interface. Users can select different models based on their needs and get real-time responses.
Unlike many competing platforms that offer limited or rigid parameter tuning, QuickML empowers you with extensive customization options, ensuring greater flexibility and control. Here’s what sets QuickML apart:
-
Fine-tune responses effortlessly: Adjust creativity, coherence, and output length directly within the user-friendly interface.
-
Seamless model switching: Easily switch between multiple LLM models within a single chat interface to find the best fit for your needs.
-
Effortless integration: Deploy models into third-party applications using the provided endpoint URL for smooth and scalable implementation.
-
Optimized performance & cost control: Tailor responses to minimize unnecessary token usage, optimizing both speed and cost-efficiency.
-
Enhanced accessibility: No complex setup required; QuickML makes advanced AI capabilities accessible even for non-technical users.
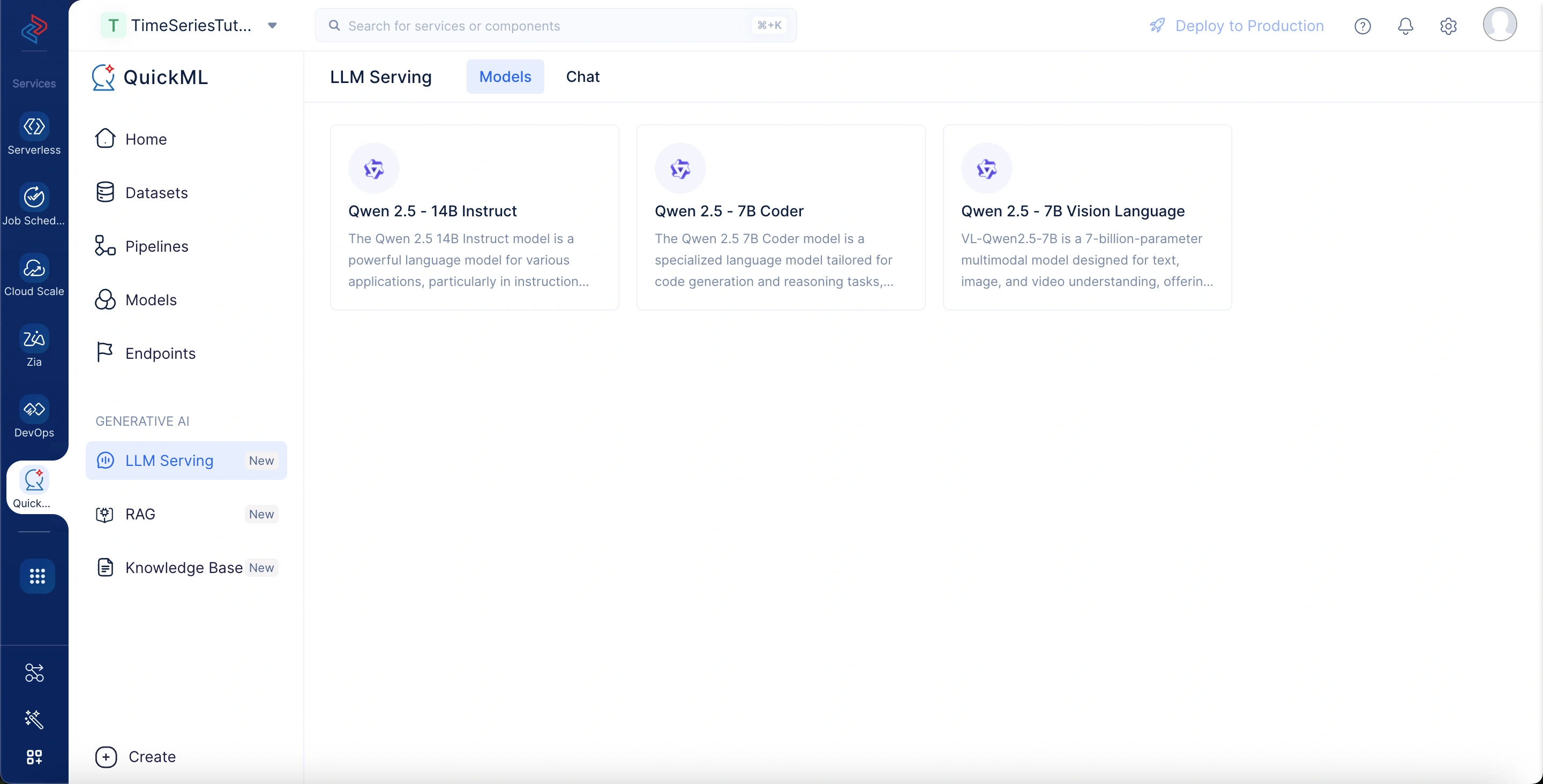
Available models in LLM serving
Below are some of the models available in QuickML, along with their capabilities and use cases.
Qwen 2.5 -14B Instruct
A lightweight yet efficient language model designed for general-purpose tasks, such as answering questions, summarizing text, and content generation.
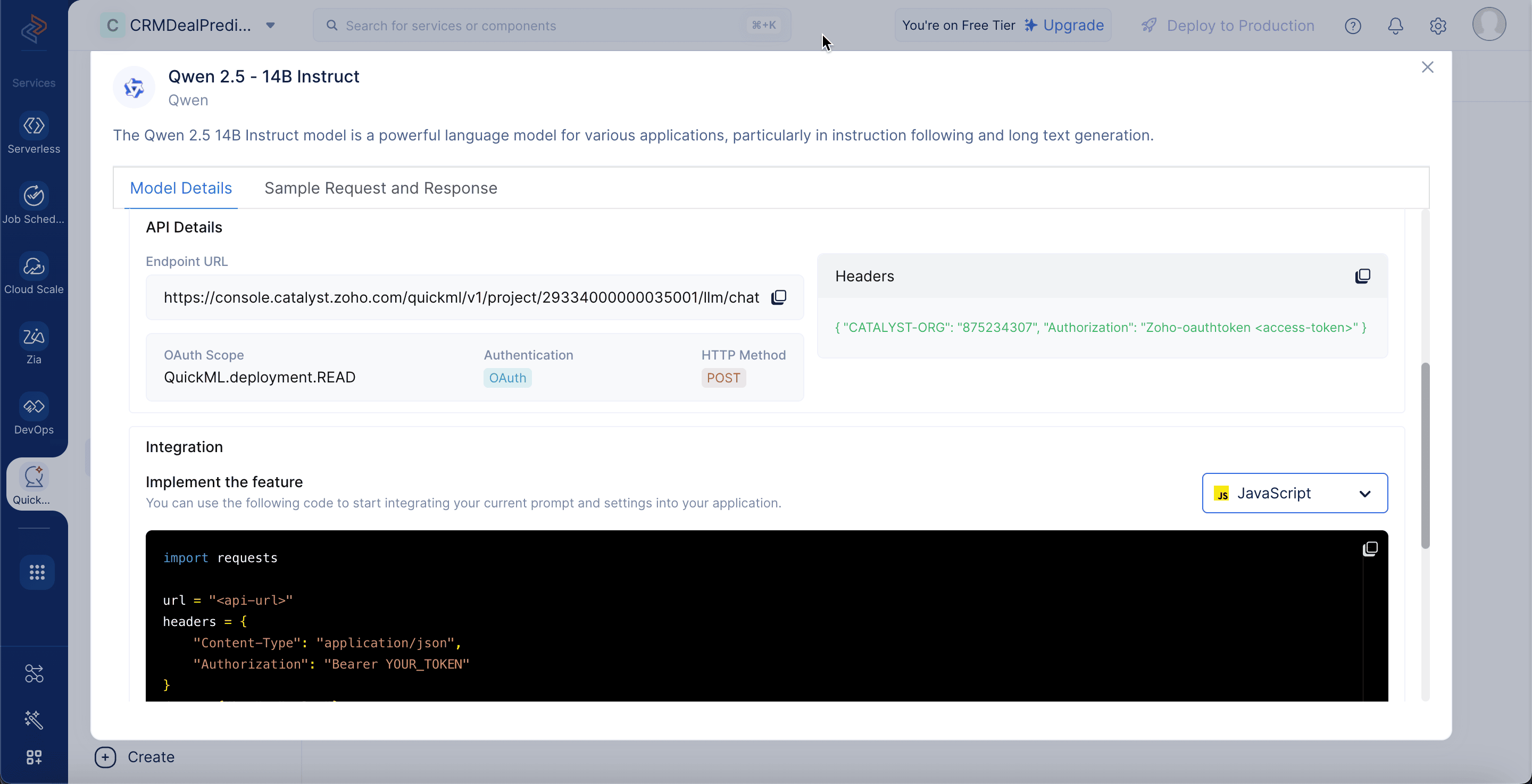
Qwen 2.5 - 14B Instruct model details
To view the model details, go to the LLM Serving tab, select Models, and choose the Qwen 2.5 - 14B Instruct model. The model details include:
-
Model Size: The model consists of 14 billion parameters, enabling high-level language understanding and generation.
-
Training Size: It has been trained on a massive 18 trillion tokens, providing broad knowledge coverage across diverse domains.
-
Parameters: The model uses 14 billion learnable weights to generate accurate and context-aware responses.
-
Input Token Limitations: Supports inputs up to 128,000 tokens, allowing for processing of very large contexts and documents.
-
Endpoint URL: The API address used to send prompts to the model.
-
OAuth Scope: The permission level required to access the model.
-
Authentication: Specifies OAuth as the method for verifying user identity.
-
HTTP Method: Indicates that API requests must be made using the POST method.
-
Headers: Requires metadata, including organization ID and OAuth token, for authorization.
-
Integration Section: Provides sample code to connect your application with the model.
-
Sample Request 1: A sample input JSON format showing how to send a prompt to the Qwen 2.5 - 14B Instruct model along with parameters like top_p, temperature, and max_tokens.
-
Sample Response 1: The output JSON format containing the model’s generated response based on the prompt.
-
Possible Error Responses: Lists common HTTP status errors like 400 (Bad Request) and 500 (Internal Server Error).
-
Sample Error Response: A structured error message that includes a code, message, and optional reason for debugging failed API calls.
You can refer to Integrate LLM into your application section for the steps to integrate the model into your application.
Qwen 2.5 - 7B Coder
A specialized model built for programming-related tasks, including code generation, debugging, and explanation.
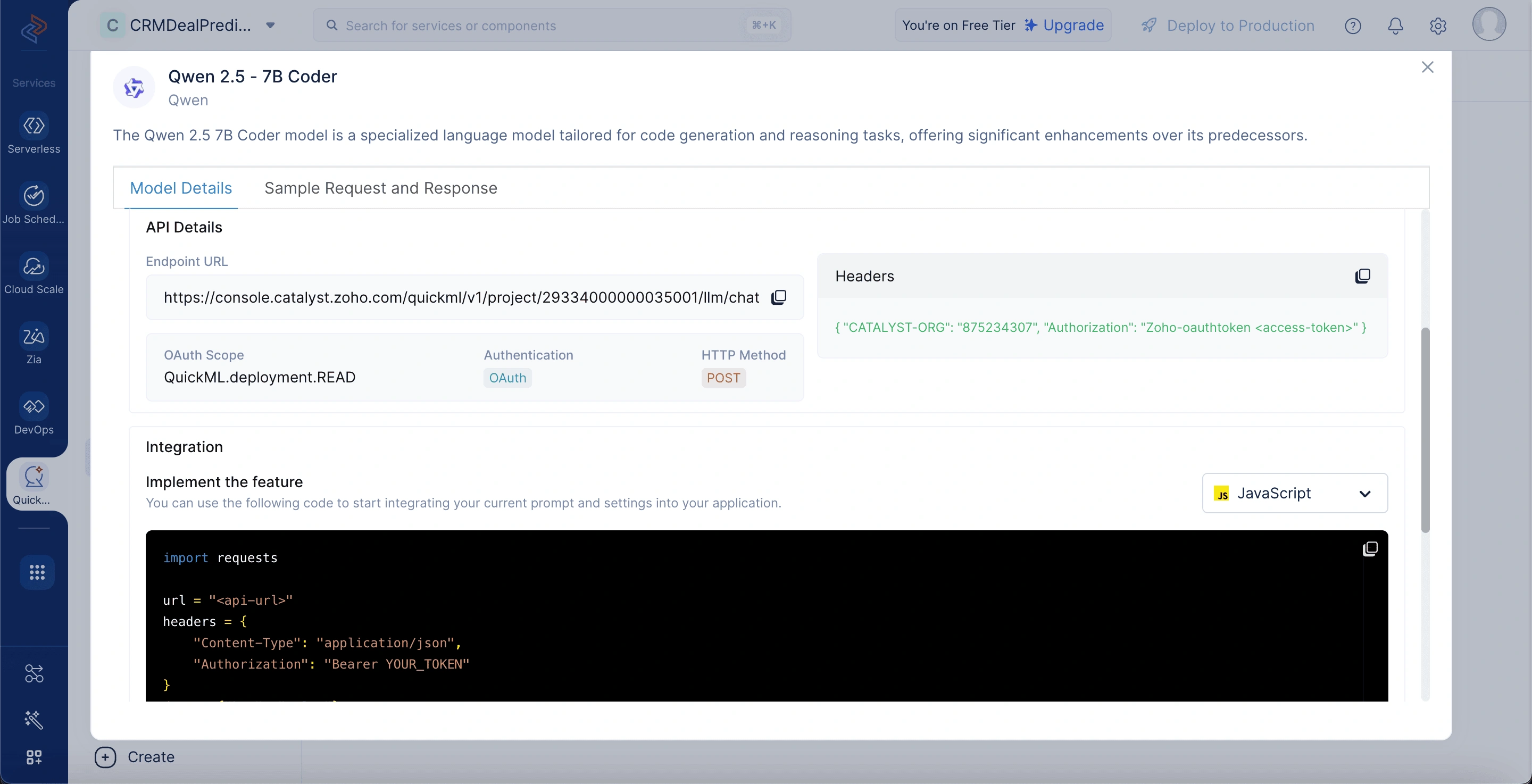
Qwen 2.5 - 7B model details
To view the model details, go to the LLM Serving tab, select Models, and choose the Qwen 7B model. The model details include:
-
Model Size: The model consists of 7 billion parameters, offering strong performance in natural language understanding and generation.
-
Training Size: It has been trained on 5.5 trillion tokens, enabling broad domain knowledge and contextual comprehension.
-
Parameters: The model utilizes 7 billion learnable weights to generate intelligent, context-aware responses. Input Token Limitations: Supports inputs up to 128,000 tokens, making it suitable for handling lengthy code and complex instructions.
-
Additional Capabilities: Equipped with features like code generation, reasoning, and extended context understanding. Endpoint URL: The API endpoint used to send requests and prompts to the deployed model.
-
OAuth Scope: Defines the access level required to interact with the model (QuickML.deployment.READ).
-
Authentication: Uses OAuth to securely verify and authorize user access.
-
HTTP Method: Requires using the POST method to send data to the model.
-
Headers: Contains necessary metadata like organization ID and OAuth token for authentication.
-
Integration Section: Offers ready-to-use code snippets to help connect and use the model in your application.
-
Sample Request 1: Demonstrates how to structure a prompt and configure parameters such as model name, temperature, and max tokens.
-
Sample Response 1: Shows the structured output generated by the model in response to the sample request.
-
Possible Error Responses: Includes typical errors like 400 (Bad Request) and 500 (Internal Server Error) indicating failed requests.
-
Sample Error Response: Displays a JSON-formatted error message with fields like code, message, and reason for troubleshooting.
You can refer to Integrate LLM into your application section for the steps to integrate the model into your application.
Qwen 2.5 - 7B Vision Language
It is a 7-billion-parameter vision-language model that can understand both images and text. It’s designed for tasks like image captioning, visual question answering, and multimodal reasoning.
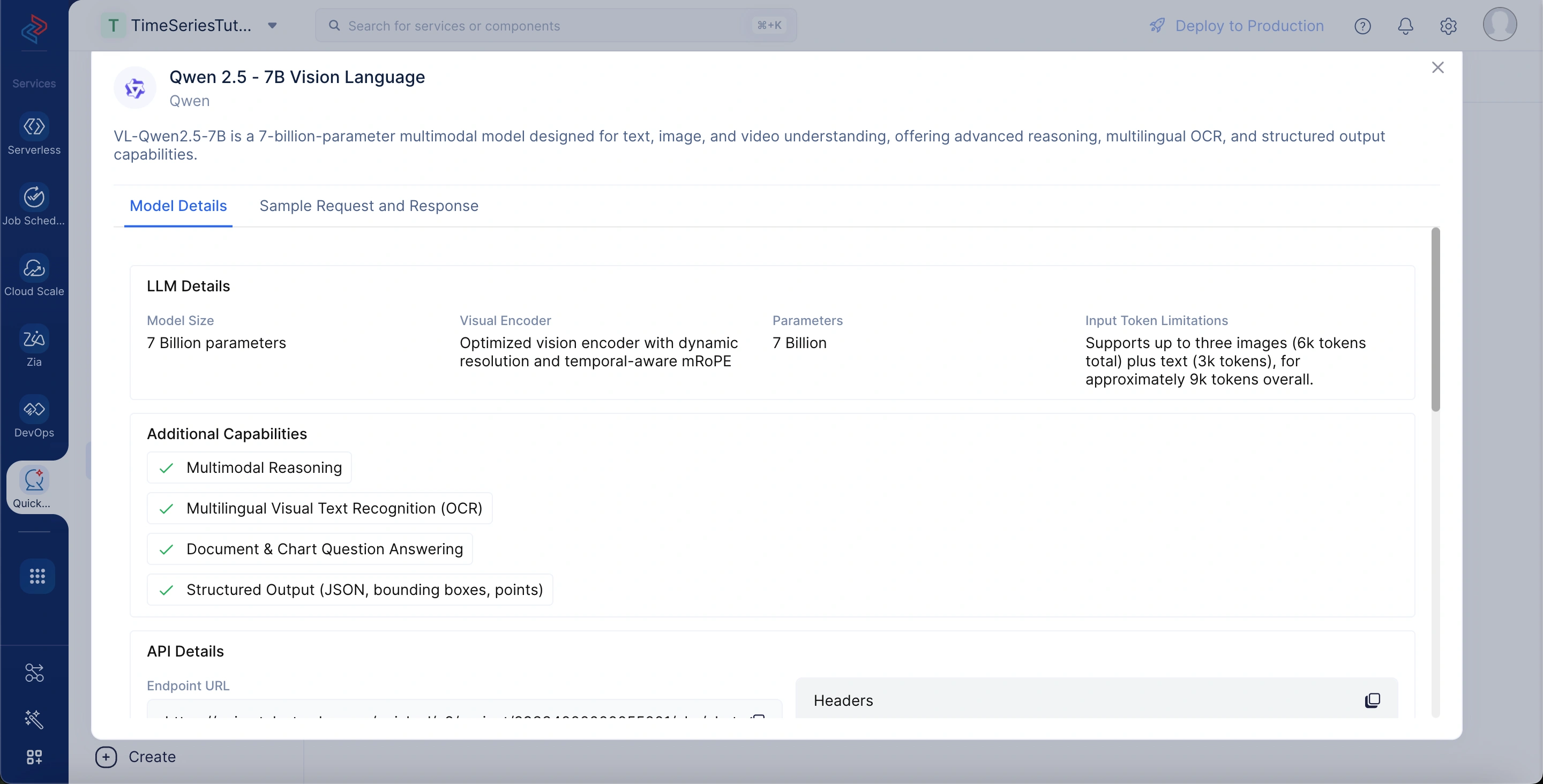
To view the model details, go to the LLM Serving tab, select Models, and choose the Qwen 2.5 - 7B Vision Language model. The model details include:
-
Model Size: The core language model consists of 7 billion parameters.
-
Visual Encoder: Uses an optimized vision encoder with dynamic resolution and temporal-aware mRoPE.
-
Parameters: A total of 7 billion trainable weights power the model.
-
Input Token Limitations: Supports up to three images (≈6k tokens) plus text (≈3k tokens), for a total of ~9k tokens.
-
Additional Capabilities: Provides multimodal reasoning, multilingual OCR, document & chart question answering, and structured outputs (JSON, bounding boxes, points).
-
Endpoint URL: The API endpoint used to send text and image prompts to the deployed vision-language model.
-
OAuth Scope: Requires QuickML.deployment.READ permission scope to interact with the model.
-
Authentication: Secured using OAuth authentication for authorized access.
-
HTTP Method: Uses the POST method to transmit prompt and media data to the model.
-
Headers: Includes mandatory metadata such as organization ID and access token for secure API requests.
-
Integration Section: Provides ready-to-use sample code in Python, JavaScript, and other languages for integration.
-
Integration Section: Provides ready-to-use sample code in Python, JavaScript, and other languages for integration.
-
Sample Request 1: Demonstrates multimodal input (text + base64-encoded images), with configurable parameters like system_prompt, top_k, top_p, temperature, and max_tokens.
-
Sample Response 1: Shows structured JSON output, extracting details like contact info, skills, education, and projects from the given document images.
-
Possible Error Responses: Includes standard errors such as 400 (Bad Request) and 500 (Internal Server Error).
-
Sample Error Response: Returns a JSON with code, message, and reason to help debug API issues.
You can refer to Integrate LLM into your application section for the steps to integrate the model into your application.
Breakdown of Chat Interface
Before looking into how to access the LLM Serving feature in QuickML, let’s have a brief look at how the chat interface is structured.
Model selection
Located at the top left under the “Chat” tab, this section allows you to choose from the available LLM models. It enables quick model switching within the same interface, making it easier to test different models for specific use cases without leaving the chat interface.
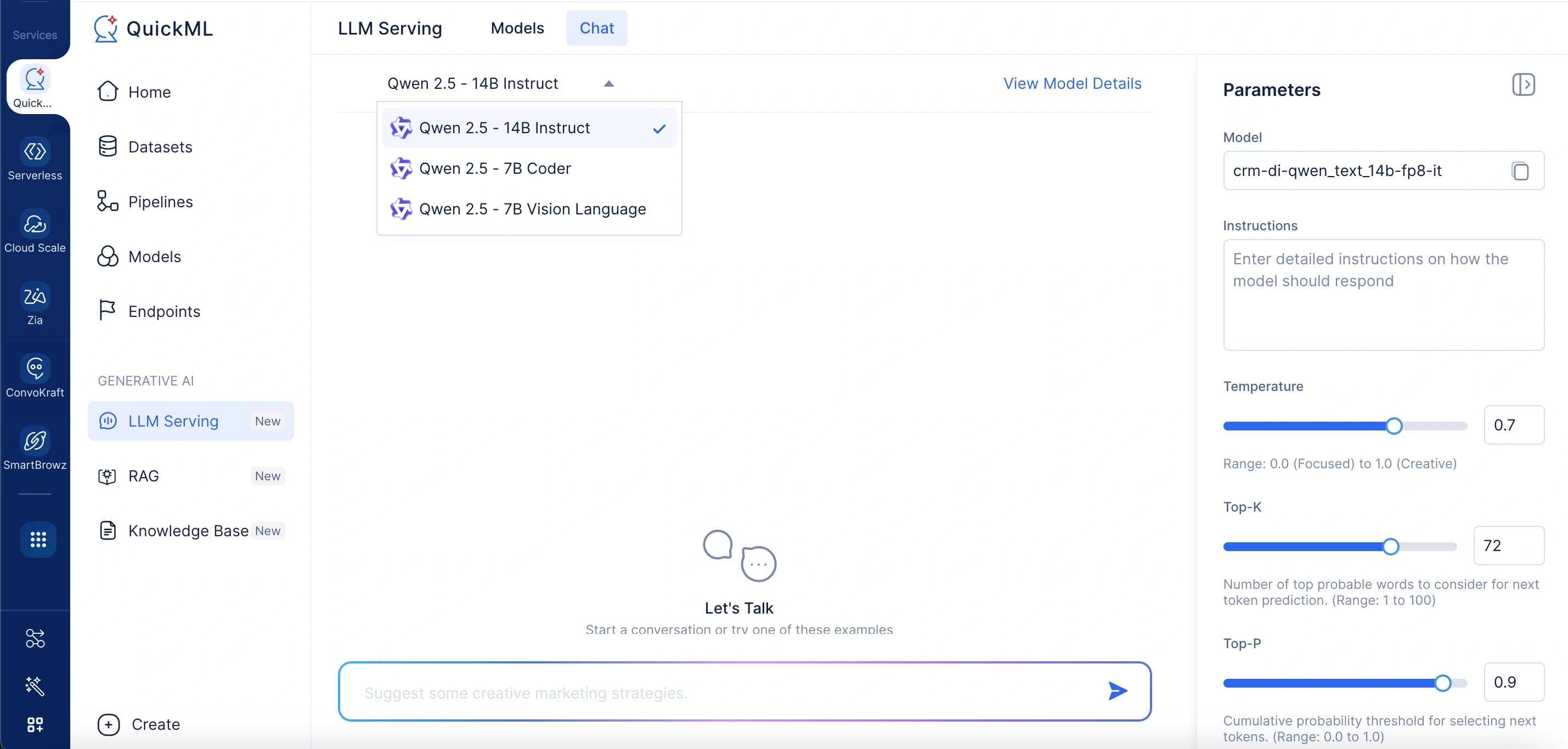
View model details
Next to the selected model name, the View Model Details option opens a pop-up window showing detailed information about the model. This includes aspects like model size, input token limits, training data, and integration options. It gives you deeper insights into what the model can do and how it can be used.
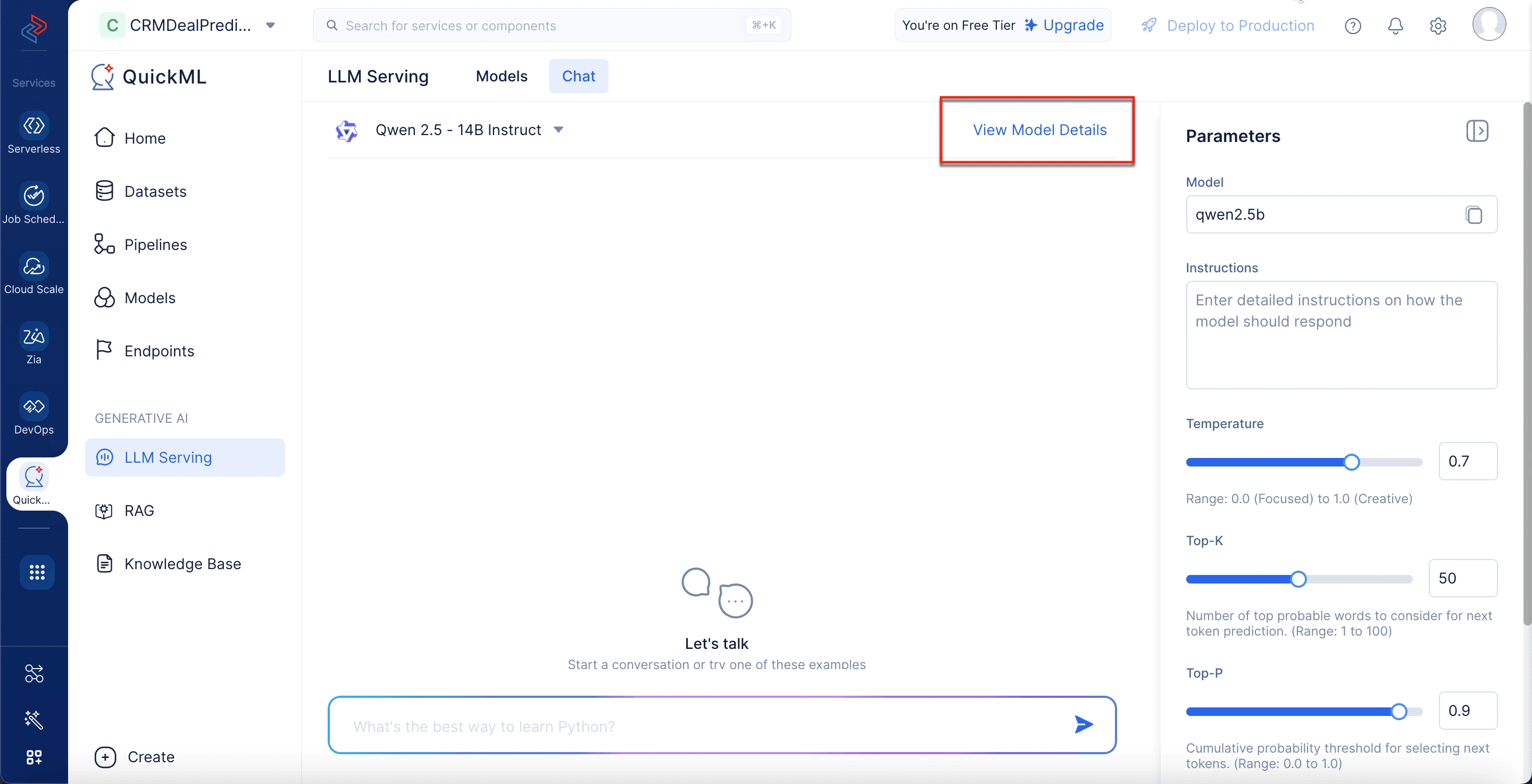
Chat interface (Conversation panel)
This central area is where all interactions take place. You can type prompts and view model-generated responses in a threaded format. Each response includes icons for actions like copying and regenerating individual responses.
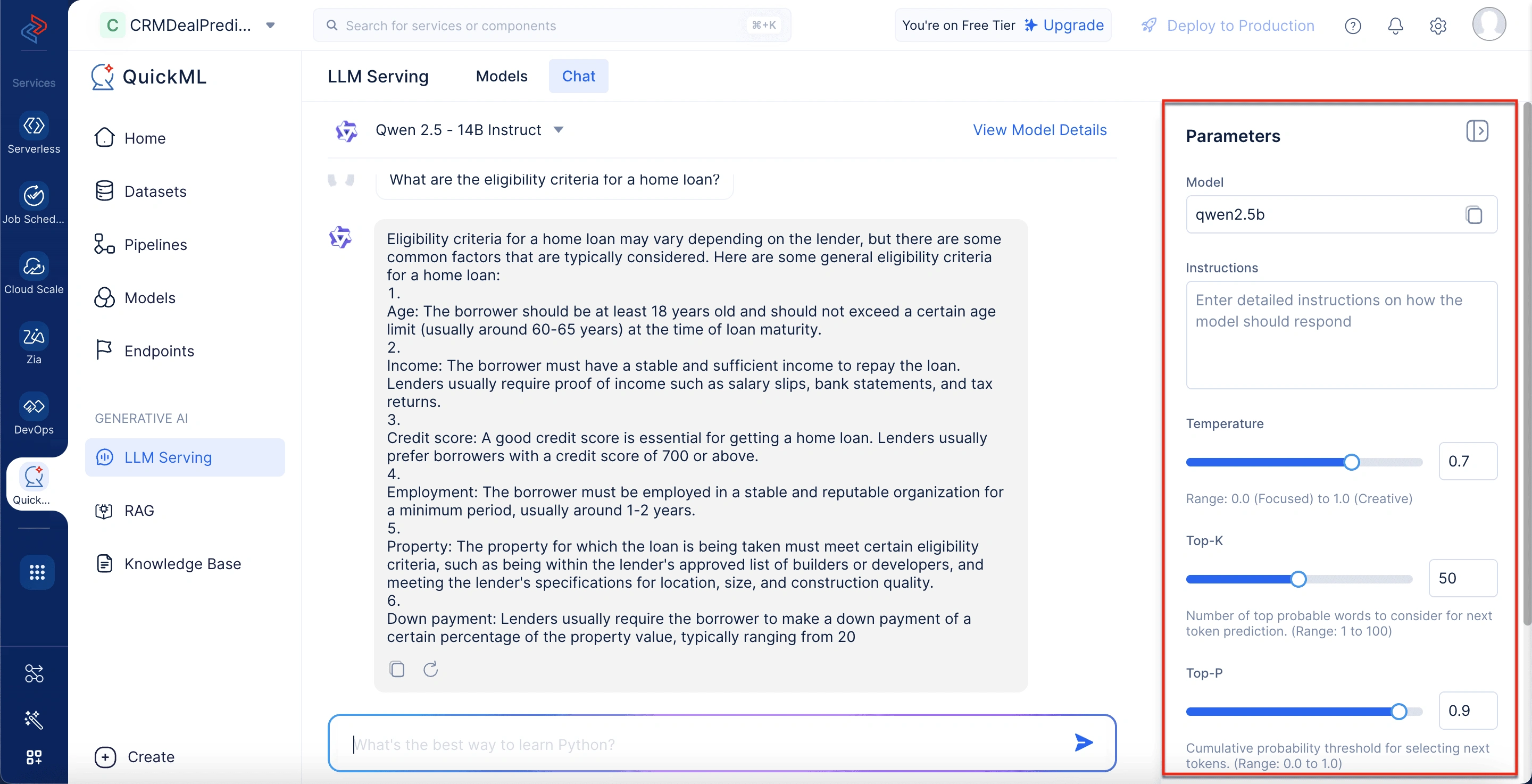
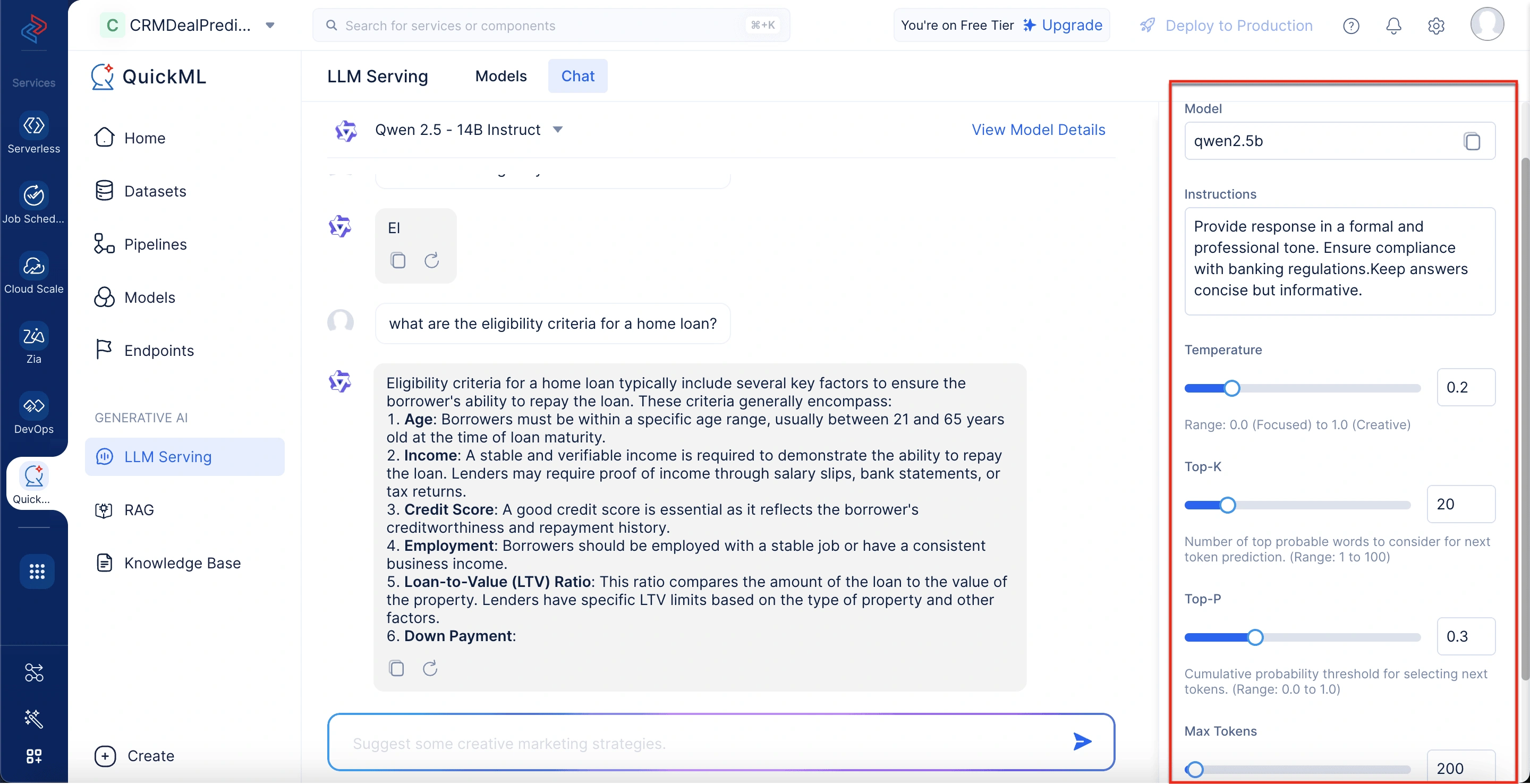
Parameters panel
Found on the right side, this panel lets you fine-tune model behavior by adjusting parameters such as Temperature, Top-K, Top-P, and Max Tokens. There’s also an instruction field to specify tone, format, or domain-specific requirements. These settings help align the output to enterprise or user-specific needs.
Chatbox
At the bottom of the screen lies the chat input box—the main area where you can type your prompts or questions to interact with the selected language model.
Parameters in LLM serving
QuickML provides a robust and flexible LLM (Large Language Model) serving environment, enabling developers and businesses to fine-tune AI model behavior through a variety of customizable parameters. These settings allow you to control how the model interprets inputs, generates responses, and aligns its output with your desired tone, structure, and purpose. Whether you’re building a legal advisor bot, a content creation tool, or a customer service assistant, QuickML’s parameter configuration options ensure your application delivers responses that are not only relevant, but also contextually tailored.
Unlike other platforms that restrict user control, QuickML prioritizes transparency and adaptability—allowing you to balance creativity with precision, determine the ideal response length, and guide the model to behave in ways that best serve your domain-specific needs.
Here’s a breakdown of the available parameters:
Model name
The model field allows you to copy the model name for easy reference and deployment.
Instructions
In the Instructions field box, you can input detailed instructions, guiding the model’s response style and content generation approach. This enhances output relevance and consistency for specific applications.
For example, a legal firm can enter instructions like “Provide responses in a formal legal tone with citations where applicable.”, ensuring AI-generated content aligns with compliance and professional standards.
Temperature
Controls the creativity level of the model’s responses:
- Lower values (e.g., 0.0 - 0.3): More deterministic and precise responses.
- Higher values (e.g., 0.7 - 1.0): Increases variability and creativity, making responses more diverse and engaging.
For example, a financial institution setting the Temperature to 0.2 would get precise responses like “The Federal Reserve increased interest rates by 0.25%.” while setting it to 0.8 might generate “The Federal Reserve’s recent rate hike of 0.25% aims to curb inflation, affecting mortgage and loan rates.”
Top-K
Determines the number of top probable words considered for the next token prediction:
- Lower values (e.g., 10 - 20): Produces more predictable and controlled responses.
- Higher values (e.g., 50 - 100): Enhances diversity and variation in generated text.
For example, a corporate HR chatbot with Top-K set to 10 may generate standard responses like “We value diversity in our hiring process.”, whereas 50 allows for richer, more engaging responses like “At [Company Name], diversity is at the core of our hiring process, fostering innovation and inclusivity.”
Top-P
Top-P sampling is also known as Nucleus sampling that generally ranges from 0.0 - 1.0. This parameter sets a cumulative probability threshold for the next token selection:
- Lower values (e.g., 0.1 - 0.3): Produces highly deterministic responses.
- Higher values (e.g., 0.8 - 0.9): Enables more diverse text generation while maintaining coherence.
For example, a customer support AI using a Top-P setting of 0.3 might generate straightforward responses like “Your order will arrive in 3 days.”, while 0.9 could lead to “Your order is expected to arrive within 3 days. You’ll receive a tracking update soon! Let us know if you need further assistance.”
Max tokens
Defines the maximum number of tokens (between 1 and 4096) that the model can generate in a response. QuickML allows precise control over response length, optimizing cost and latency.
For example, a compliance team setting Max Tokens to 50 ensures concise regulatory summaries, like “GDPR mandates data protection for EU citizens.”, while 500 could generate a comprehensive legal analysis detailing key provisions and compliance measures.
Working of LLM Serving in QuickML
-
When a user submits a request in QuickML’s LLM serving chat interface, the selected model (such as Qwen 2.5 - 14B Instruct) processes the input.
-
The model analyzes the context, intent, and meaning of the query to generate a relevant and coherent response.
-
The response is formulated based on the model’s training data, ensuring accuracy and contextual relevance.
-
Users can refine their queries or adjust model parameters to influence the response style, tone, and level of detail.

Key Points to be noted:
-
The LLM serving feature is available to users who have access to the QuickML platform.
-
You can seamlessly switch between multiple LLM models within the QuickML chat interface.
-
At present, you cannot erase the previous chat conversations or open a new chat window; all conversations remain within the same chat interface.
-
Chats are user-specific, ensuring that one user cannot access another user’s conversation.
-
You can upload images and type your query using the Qwen 2.5 - 7B Vision Language model for generating responses.
-
QuickML’s LLM serving does not use your data for model training. All responses are generated based on its pre-trained data.
Accessing LLM Serving in QuickML
LLM Serving can be accessed in QuickML by following the below steps,
- Log in to QuickML platform.
- Under the Generative AI section, select LLM Serving.
- Navigate to the Chat tab.
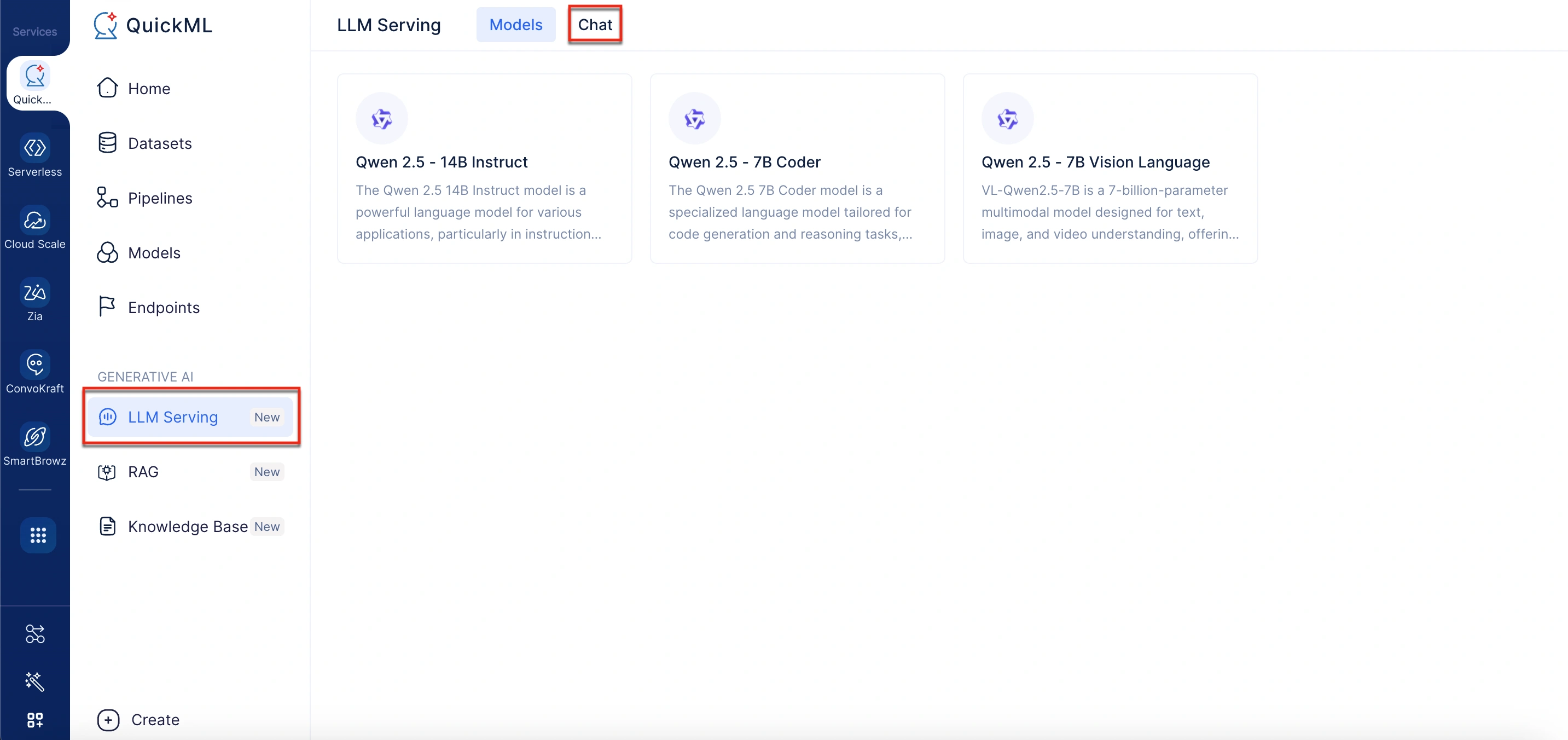
- Select the desired LLM model from the drop-down.
- You can select either Qwen 2.5 - 14B Instruct, Qwen 2.5 - 7B Coder, or Qwen 2.5 - 7B Vision Language
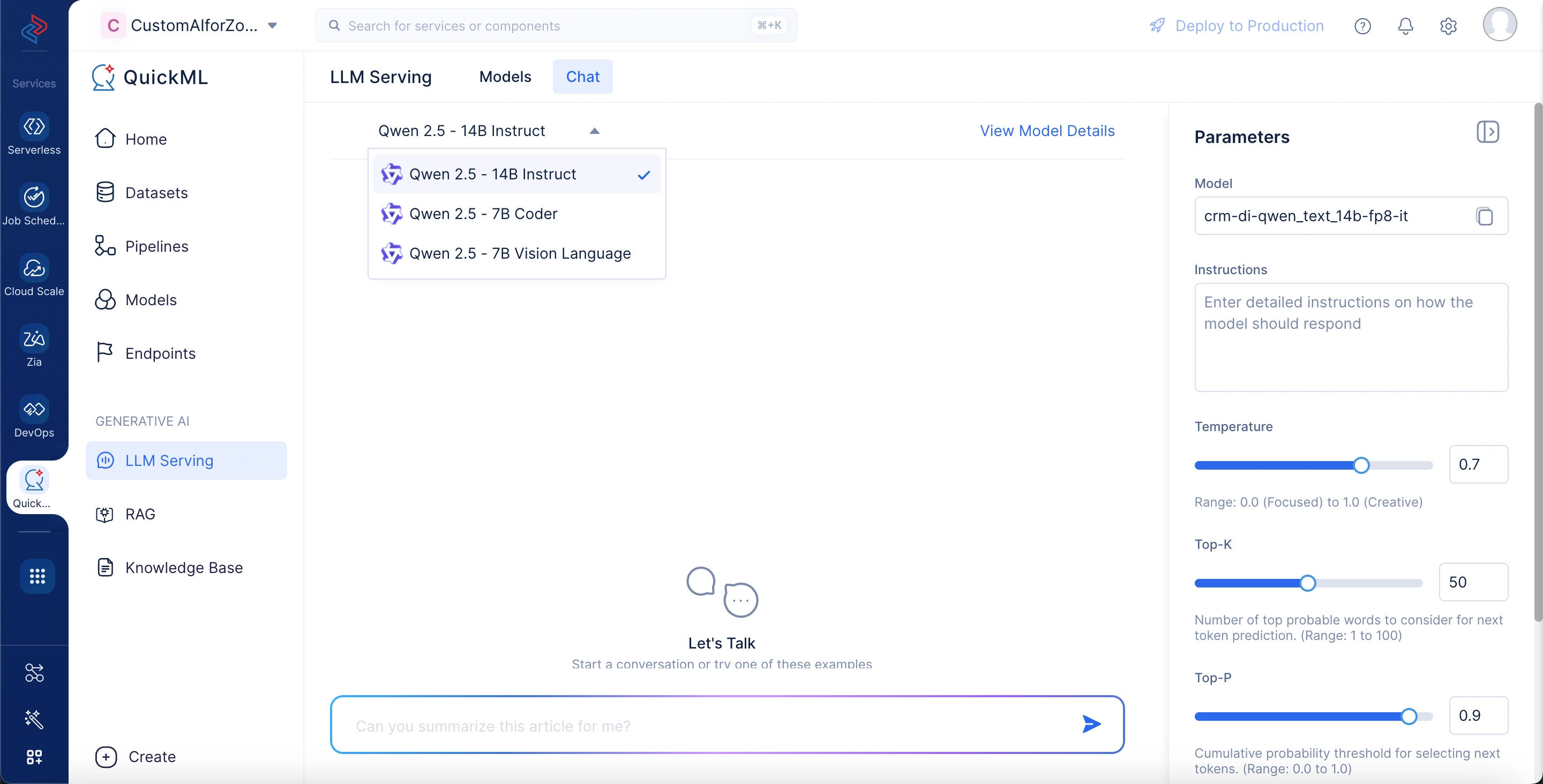
- Start entering your queries in the chat interface.
Note: The chat interface generates responses based on the default parameter configuration. However, you can adjust the settings as needed to suit your requirements.
To configure the parameters settings
- Under the Generative AI section, select LLM Serving tab.
- Navigate to the Chat tab.
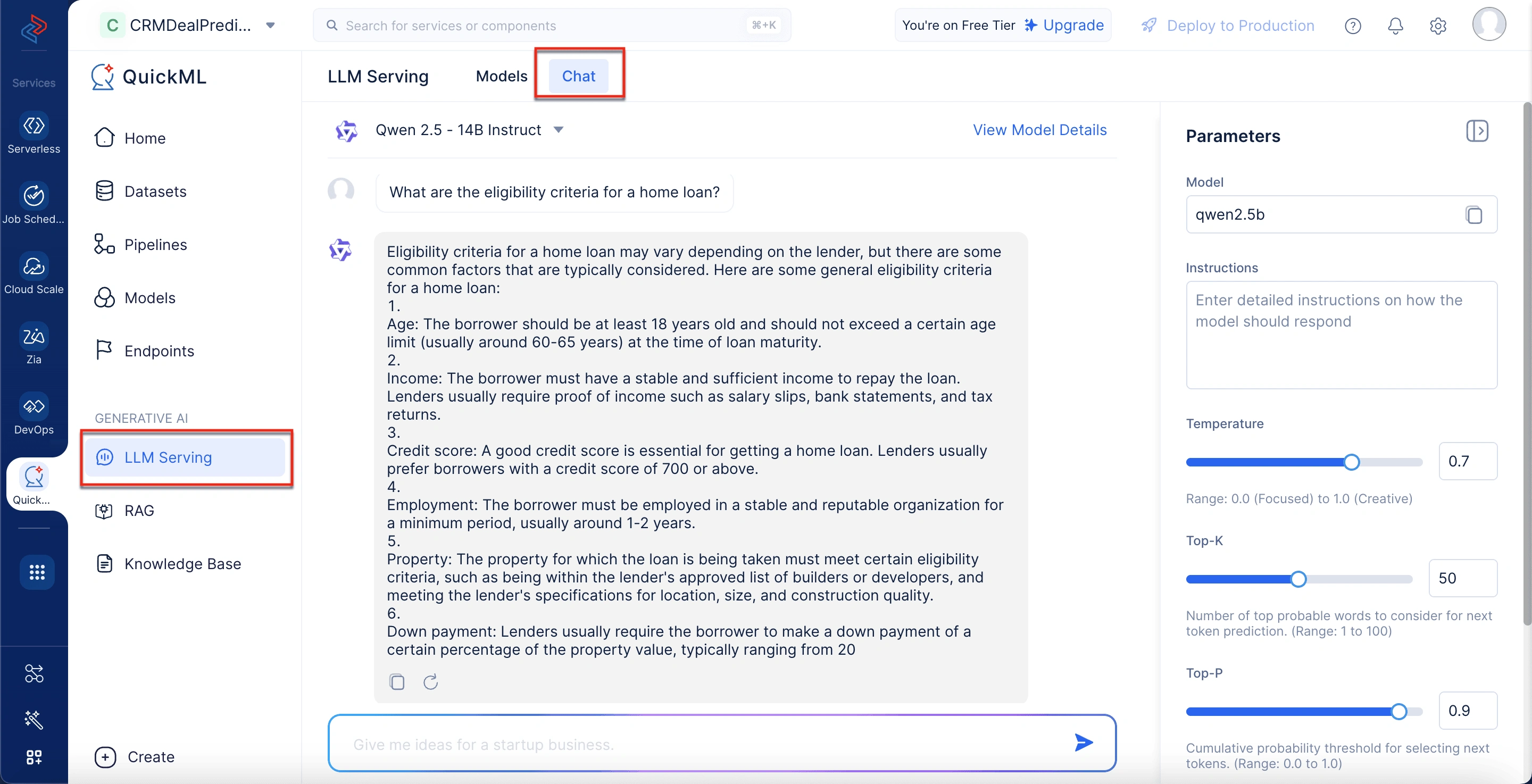
- Under Parameters in the right panel, configure the following:
- Enter the detailed instructions on how the model should perform.
- Control the creativity level of the model’s responses by adjusting the Temperature.
- Adjust the number of top probable words considered for the next token prediction in the Top-K field.
- Set the parameter for a cumulative probability threshold for the next token selection in the Top-P field.
- Define the maximum number of tokens the model generates per response in the Max Tokens field.
- Click Save.
Let’s consider a sample use case to understand how these parameters can be configured in a real-time business scenario.
Configuring parameters for a customer support chatbot in a financial institution
Usecase:
A bank wants to assist customers with general banking inquiries while ensuring responses are accurate, concise, and aligned with regulatory guidelines.
Step 1: Adjusting Parameters for Optimal Performance
| Parameter | Configuration | Reason |
|---|---|---|
| Model | Qwen 2.5 -14B Instruct | Selected for its balance of accuracy and efficiency. |
| Instructions | Provide responses in a formal and professional tone. Ensure compliance with banking regulations. Keep answers concise but informative. | Ensures consistency in customer interactions. |
| Temperature | 0.2 | Keeps responses factual and avoids unnecessary creativity. |
| Top-K | 20 | Limits word selection to the most relevant choices, reducing variability. |
| Top-P | 0.3 | Keeps responses focused and predictable, ensuring regulatory compliance. |
| Max Tokens | 200 | Prevents overly long responses while maintaining enough detail for clarity. |
Step 2: Engaging with the Chat Interface
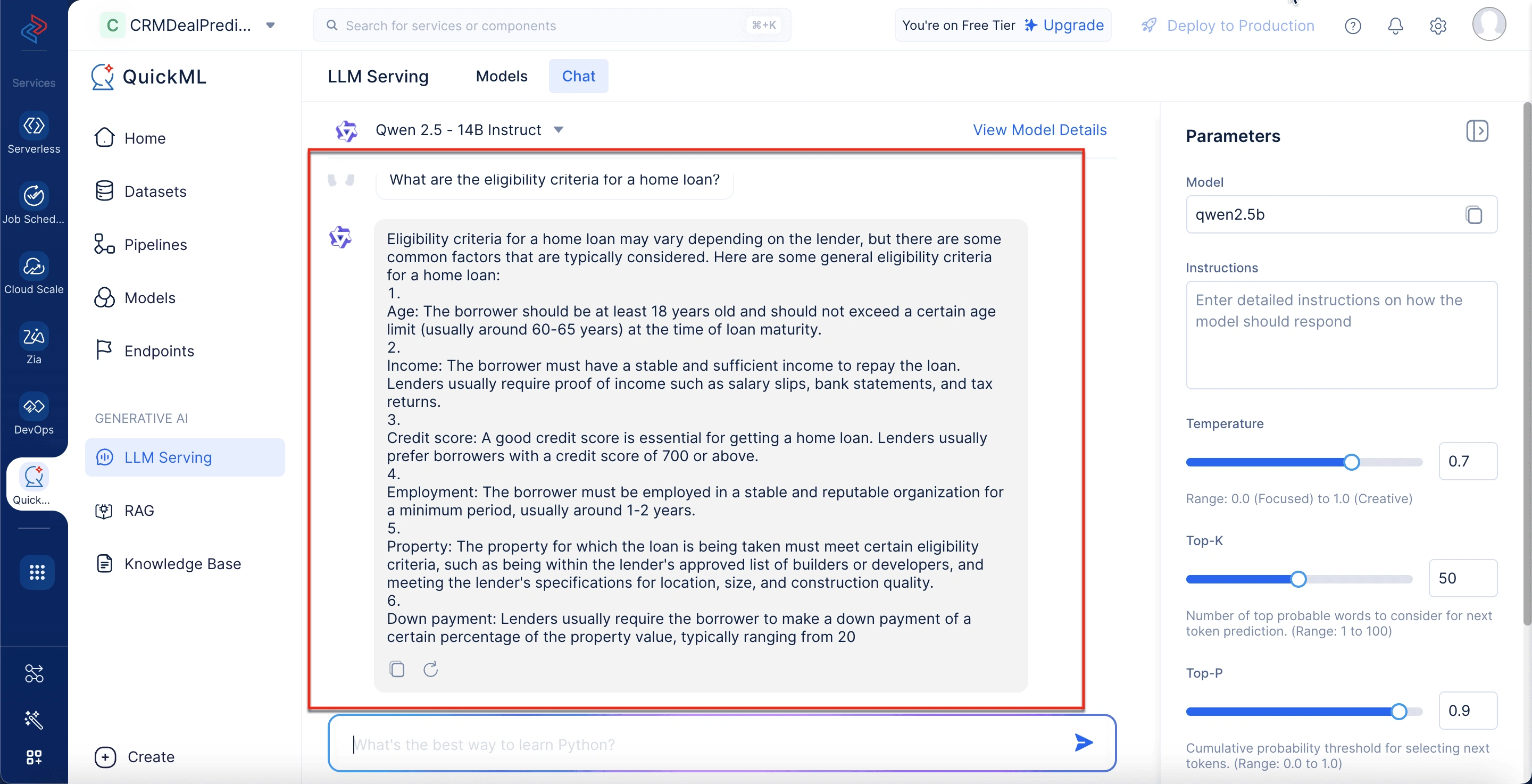
Once the parameters are set, the chatbot is ready for use. Here’s an example interaction:
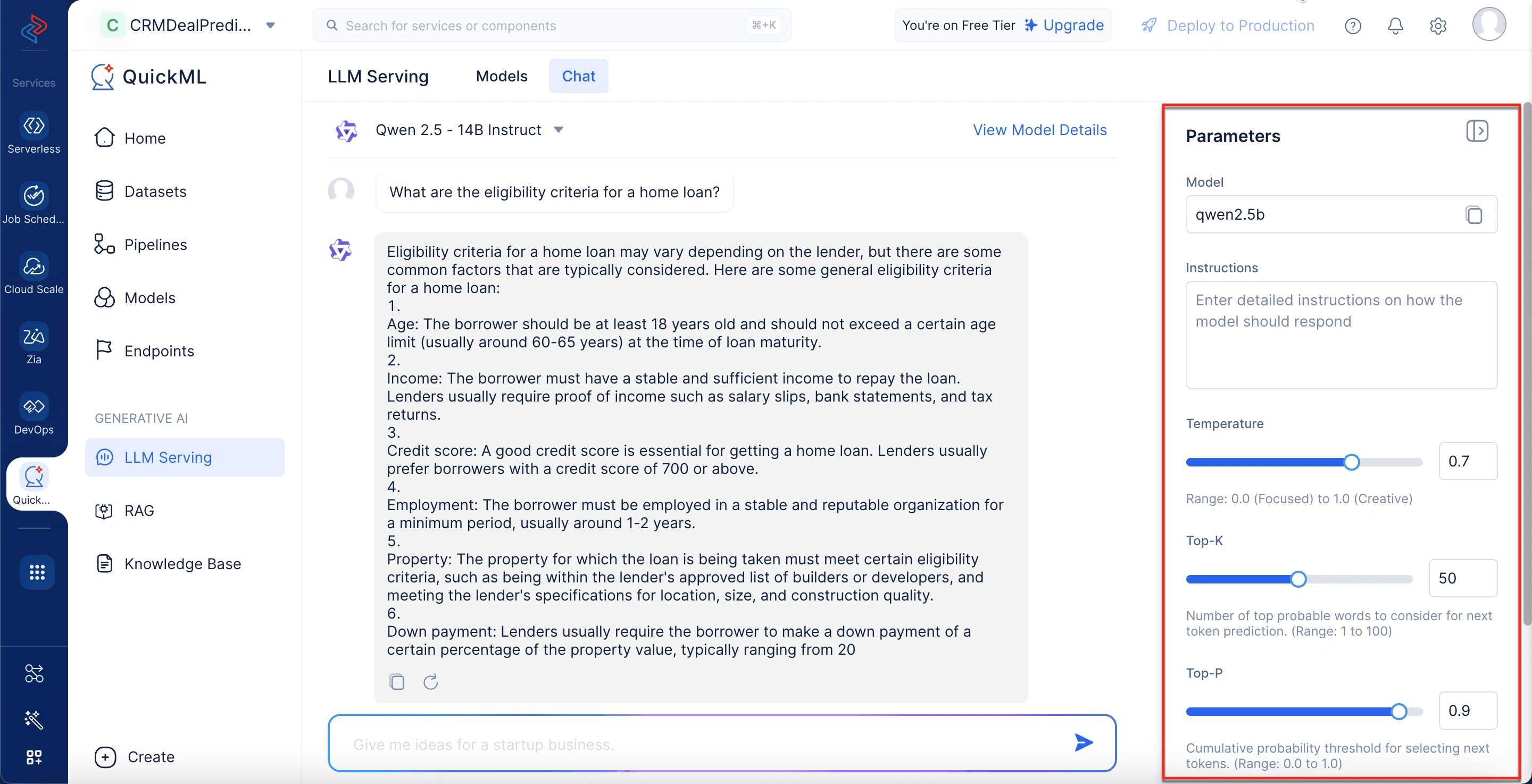
User:“What are the eligibility criteria for a home loan?”
Chatbot Response (Qwen 2.5 - 14B Instruct, with adjusted parameters): Eligibility criteria for a home loan typically include several key factors to ensure the borrower’s ability to repay the loan. These criteria generally encompass:
- Age: Borrowers must be within a specific age range, usually between 21 and 65 years old at the time of loan maturity.
- Income: A stable and verifiable income is required to demonstrate the ability to repay the loan. Lenders may require proof of income through salary slips, bank statements, or tax returns.
- Credit Score: A good credit score is essential as it reflects the borrower’s creditworthiness and repayment history.
- Employment: Borrowers should be employed with a stable job or have a consistent business income. Loan-to-Value (LTV) Ratio: This ratio compares the amount of the loan to the value of the property. Lenders have specific LTV limits based on the type of property and other factors.
Integrate LLM into your Applications
Beyond utilizing LLM models within the QuickML platform, you can seamlessly integrate them into your own applications using the provided endpoint URL. This allows businesses to incorporate AI-powered responses into various business processes, such as customer support bots, content automation tools, and data analysis applications.
To enable secure and efficient integration, QuickML supports OAuth-based authentication for access token generation. You can refer to this documentation for details on different types of OAuth applications and the steps required to generate and manage access tokens.
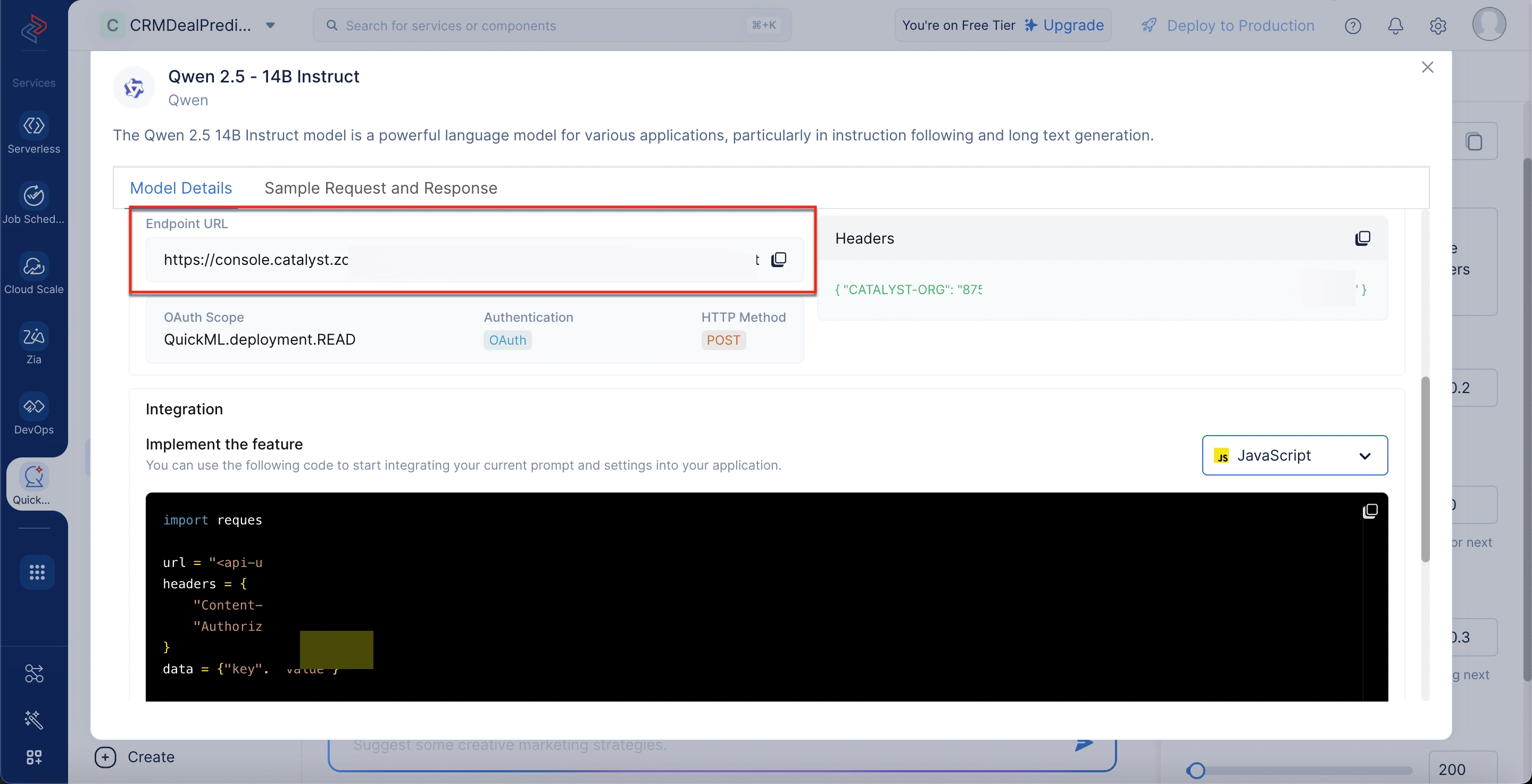
To get the endpoint URL
- Navigate to the Generative AI section within QuickML.
- Select the LLM Serving tab.
- In the Models tab, choose the desired model.
- In the Model Details pop-up window, scroll to the API Details section to get the endpoint URL.
Last Updated 2025-11-27 09:21:10 +0530 IST
Yes
No
Send your feedback to us