Custom Code
Custom code operations
The Custom Code operations in the QuickML pipeline allow developers to insert their own logic into the model training process. By implementing Python classes provided in templates, users can customize how data is transformed, how features are processed, and even define the machine learning algorithm used.
This capability is divided into three distinct components:
- Custom Data Transformation
- Custom ML Transformation
- Custom Algorithm
Each component plays a unique role in the machine learning lifecycle and comes with predefined method signatures that must be implemented by the user.
Custom Data transformation
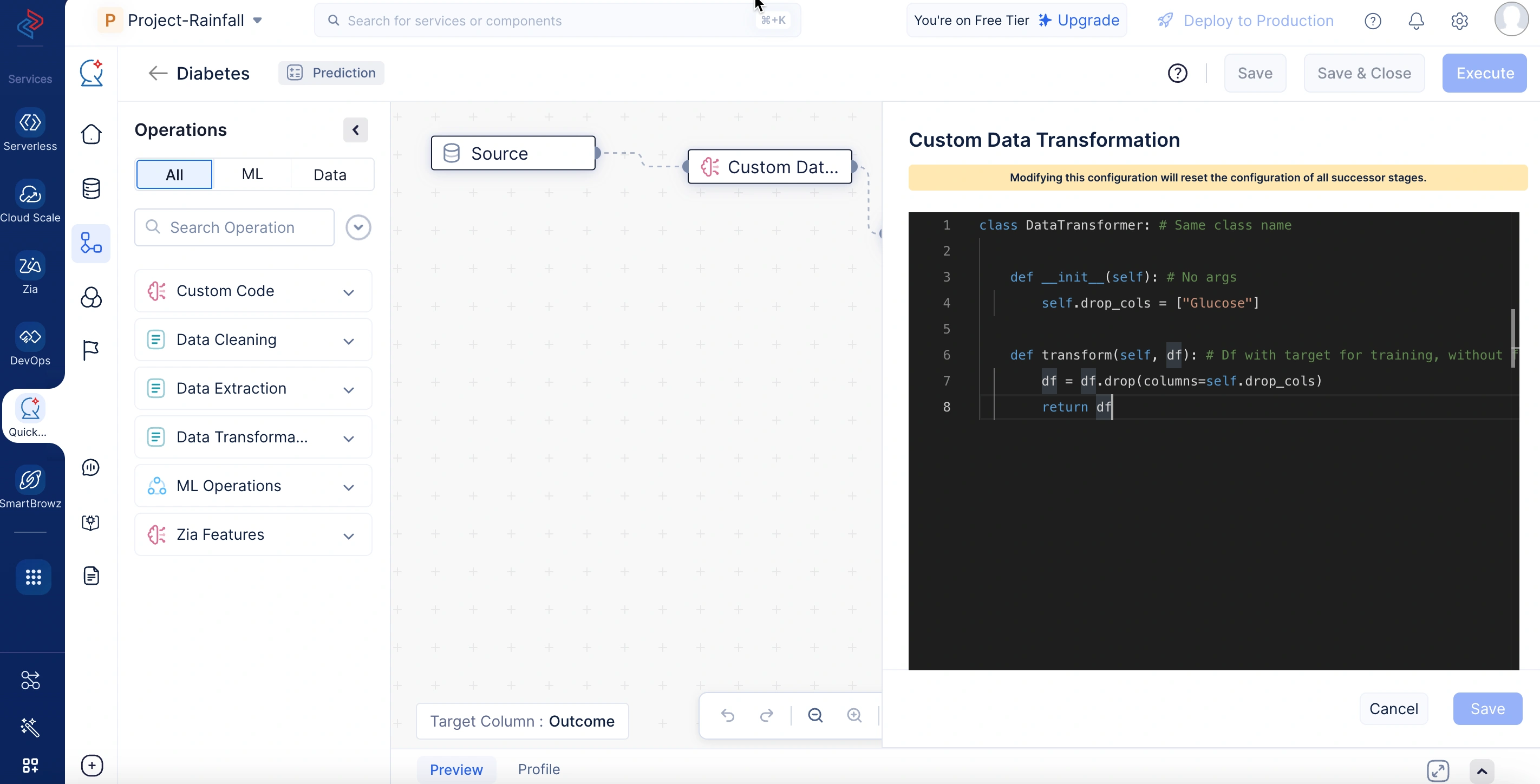
Custom data transformation is used in optimizing the data by performing operations such as data cleaning, transforming, and extraction of raw data using custom logic. It is particularly useful for preprocessing steps like column removal, format conversions, and scaling that must remain consistent across both model training and prediction stages. The customized code handles complex requirements during data pre-processing and is implemented in the transform() method, which accepts and returns a DataFrame object and is executed during both training and inference.
In the sample code below, the custom data transformation node preprocesses data before it’s used for model training or prediction. It removes the “Glucose” column from the dataset to ensure that irrelevant or potentially biased features do not influence the model’s learning or predictions.
Custom ML transformation
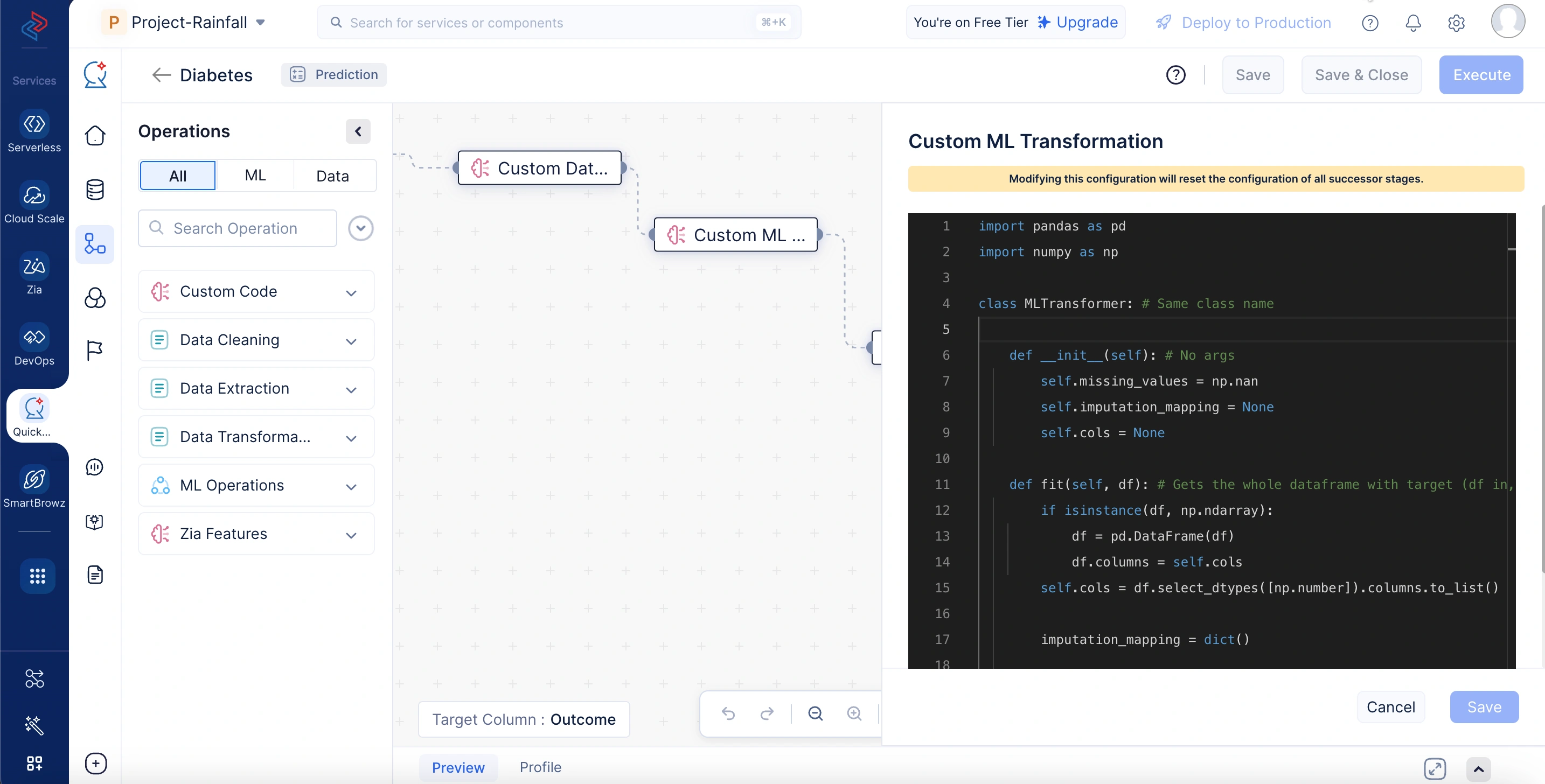
In the ML model development life cycle, custom ML transformation operations are used during the pre-processing step by performing feature engineering tasks specifically tailored to the use case using custom logic. These transformations are ideal for handling operations such as missing value imputation, feature encoding, and normalization—where the logic must learn from the training data and consistently apply the same transformation during prediction. This is accomplished through a fit() method, which learns the necessary parameters from the training data, and a transform() method, which applies those learned parameters to preprocess new data. Both methods accept and return a DataFrame object.
In the sample code below, the custom ML transformation node handles missing value imputation as part of the data pre-processing step. During training, it computes the mean of each numeric column and stores it. Later, during prediction or inference, it fills missing values in those columns using the stored mean values, ensuring consistency between training and prediction phases.
Custom algorithm
Allows you to plug in a custom ML model and define its training, prediction, and evaluation logic. This offers full control over which algorithm is used and how its performance is assessed. It has fit, predict, and get_evaluation_metrics functions. Fit is executed during model training, predict is executed during prediction, and get_evaluation_metrics is executed after model training to generate the evaluation metrics. The metrics returned from the get_evaluation_metrics() method will be displayed in the evaluation metrics section of the model details page.
Custom algorithm operation refers to the application of custom algorithms tailored to specific business use cases. It allows users to plug in a custom ML model and define bespoke training, prediction, and evaluation logic. This approach offers full control over which algorithm is used and how its performance is assessed. It can be seen as an enhancement of standard pre-defined algorithms, enabling the solution of unique modeling problems using domain-specific rules.
The operation includes three key methods:
- fit() — executed during model training to learn from the data,
- predict() — executed during prediction to generate outputs, and
- get_evaluation_metrics() — executed post-training to compute and return evaluation metrics.
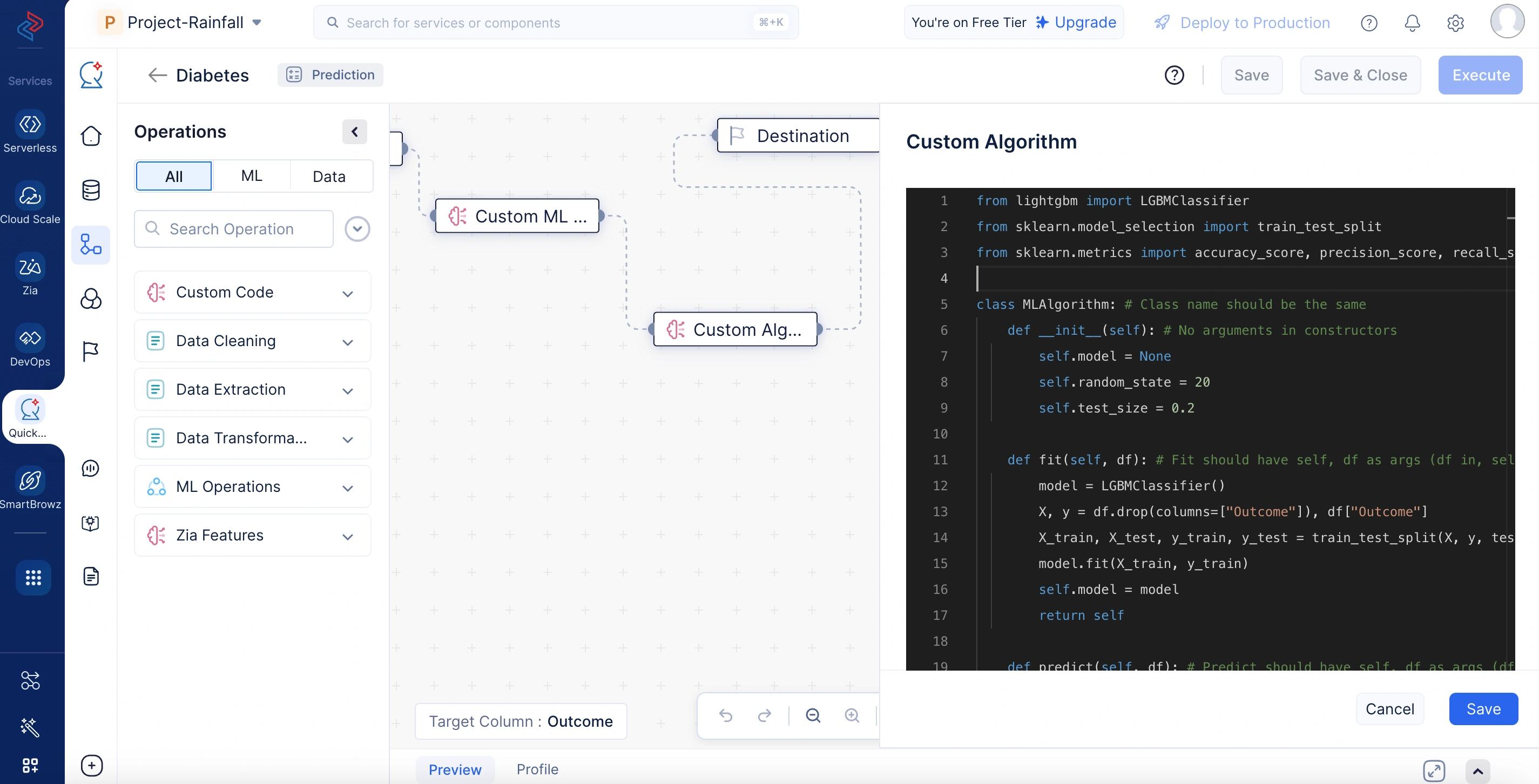
In the sample code below, the custom algorithm node builds an ML model using the LightGBM classifier. It splits the input dataset into training and testing sets, trains the model on the training data, and stores the trained model instance. During prediction, it uses the trained model to generate outputs for unseen data. After training, it evaluates the model using accuracy, precision, recall, and F1-score metrics, which are computed on the test data and returned as a dictionary for performance analysis.
List of py libraries form which import is supported:
numpy, scipy, pandas, xgboost, catboost, lightgbm, sklearn, tld, patsy, tensorflow, statsmodels, tldextract, huggingface_hub, sentence_transformers, imbalanced_learn, hyperopt, shap, lime, transformers, pmdarima, lightfm, LibRecommender, subseq
Last Updated 2025-10-24 19:35:40 +0530 IST
Yes
No
Send your feedback to us