MLパイプラインの作成
このセクションでは、前のセクションで前処理したデータセットを使用して、予測MLモデルを構築します。データセットはML Pipeline Builderへの入力となり、モデルのアーキテクチャを定義し、予測対象の列を選択できます。
MLパイプラインを作成するには:
-
左メニューのPipelinesコンポーネントに移動し、Create Pipelineをクリックします。
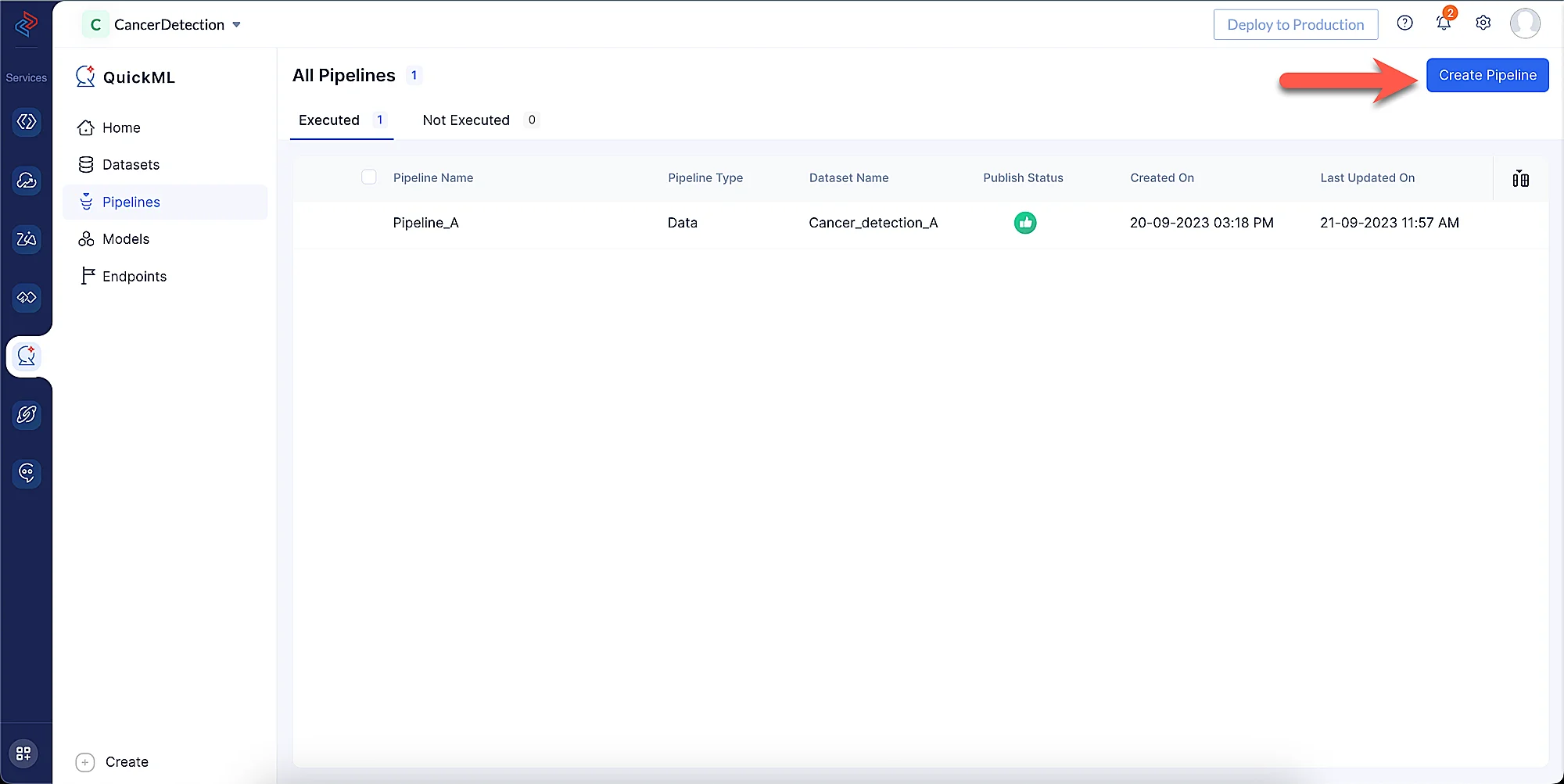
-
表示されるポップアップで、パイプラインタイプとしてPredictionを選択し、パイプライン名に「Pipeline_B」と入力し、入力データセットとしてCancer_detection_Aを選択します。今回のケースでは、ターゲット列は「diagnosis」です。モデル名はパイプライン名に基づいて自動入力されます。Create Pipelineをクリックします。
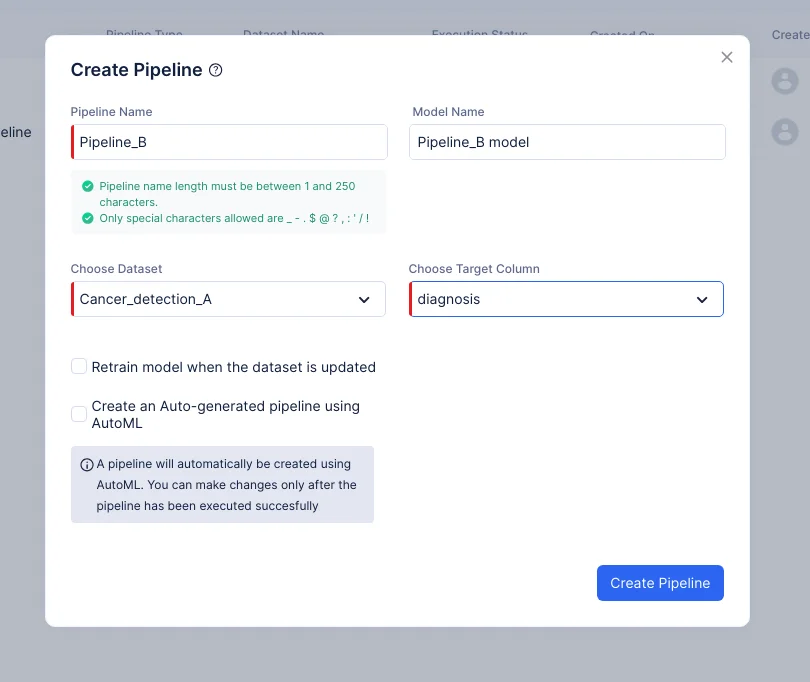
-
以下のスクリーンショットに示すように、パイプライン詳細ページが表示されます。
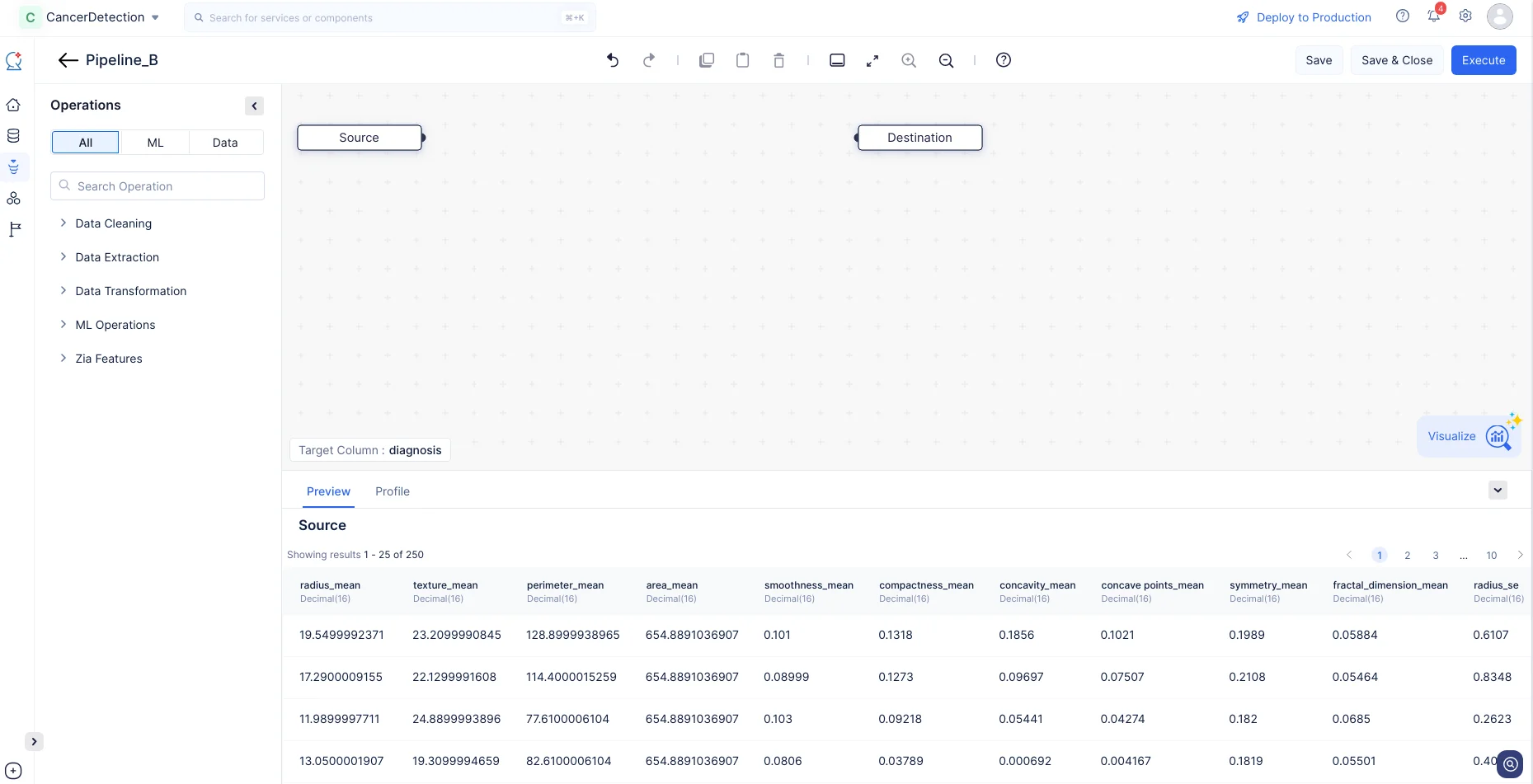
MLパイプラインが作成されたので、ML Pipeline Builderインターフェースでノードを定義してパイプラインの設定を行います。
データ型の変換
ターゲット列の「diagnosis」にはString型のカテゴリカルデータが含まれているため、MLトレーニングの標準に合わせてエンコードする必要があります。
- Operationsメニューで、ML operations->Encoding->Label Encoderに移動します。Label EncoderノードをML Pipeline Builderインターフェースにドラッグ&ドロップします。Label encodingはターゲット列にのみ適用できるため、自動的に実行されます。
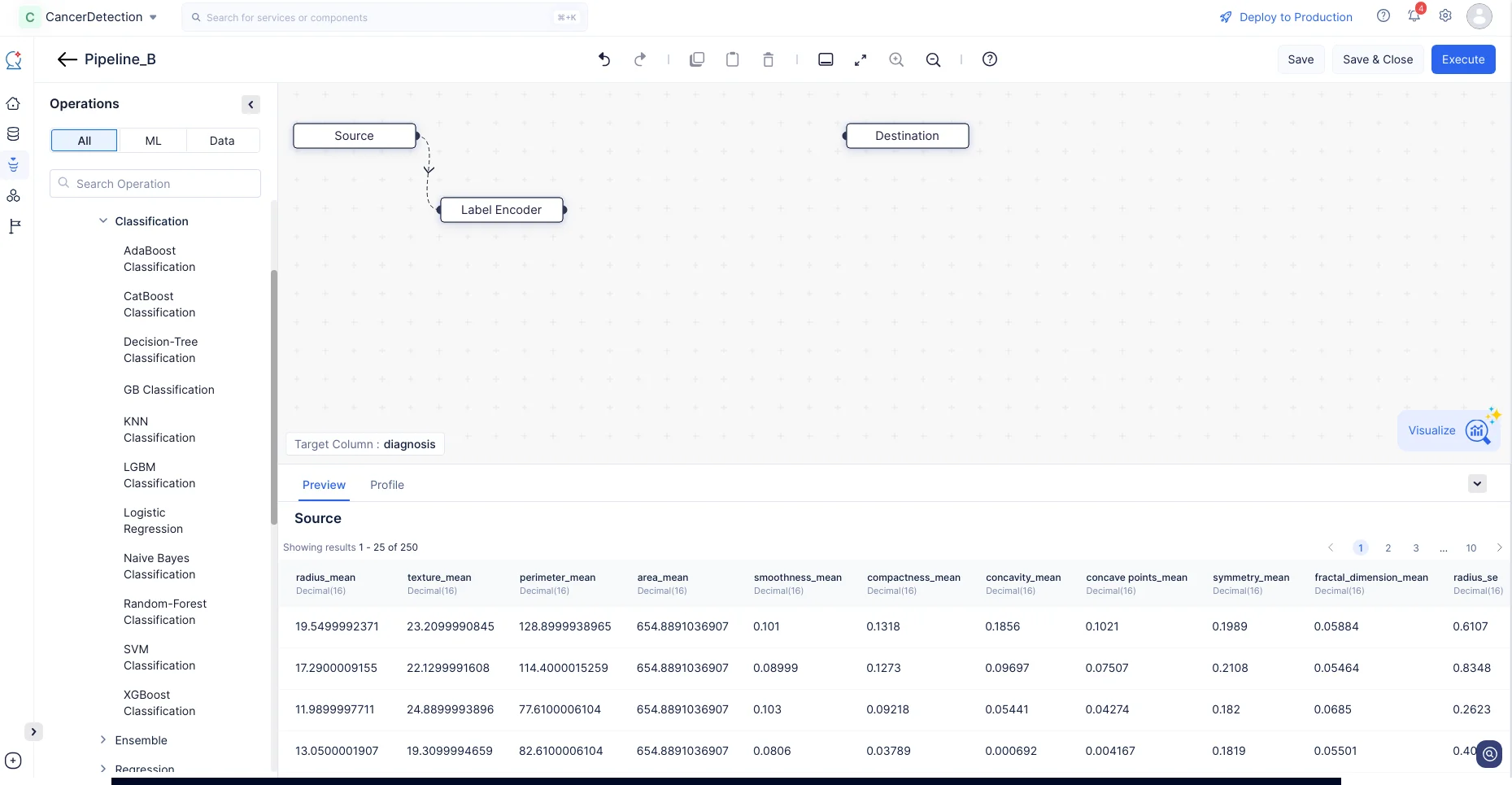
この操作により、列の値がString型からInteger型に変換され、順序が維持されデータの正確性が保たれます。
ハイパーパラメータチューニング
MLモデルでは、モデルがトレーニングされるためのMLアルゴリズムの実装が必須です。このチュートリアルでは、ロジスティック分類アルゴリズムを実装して、前処理済みデータセットに最適化されたMLモデルのチューニングパラメータを設定します。
-
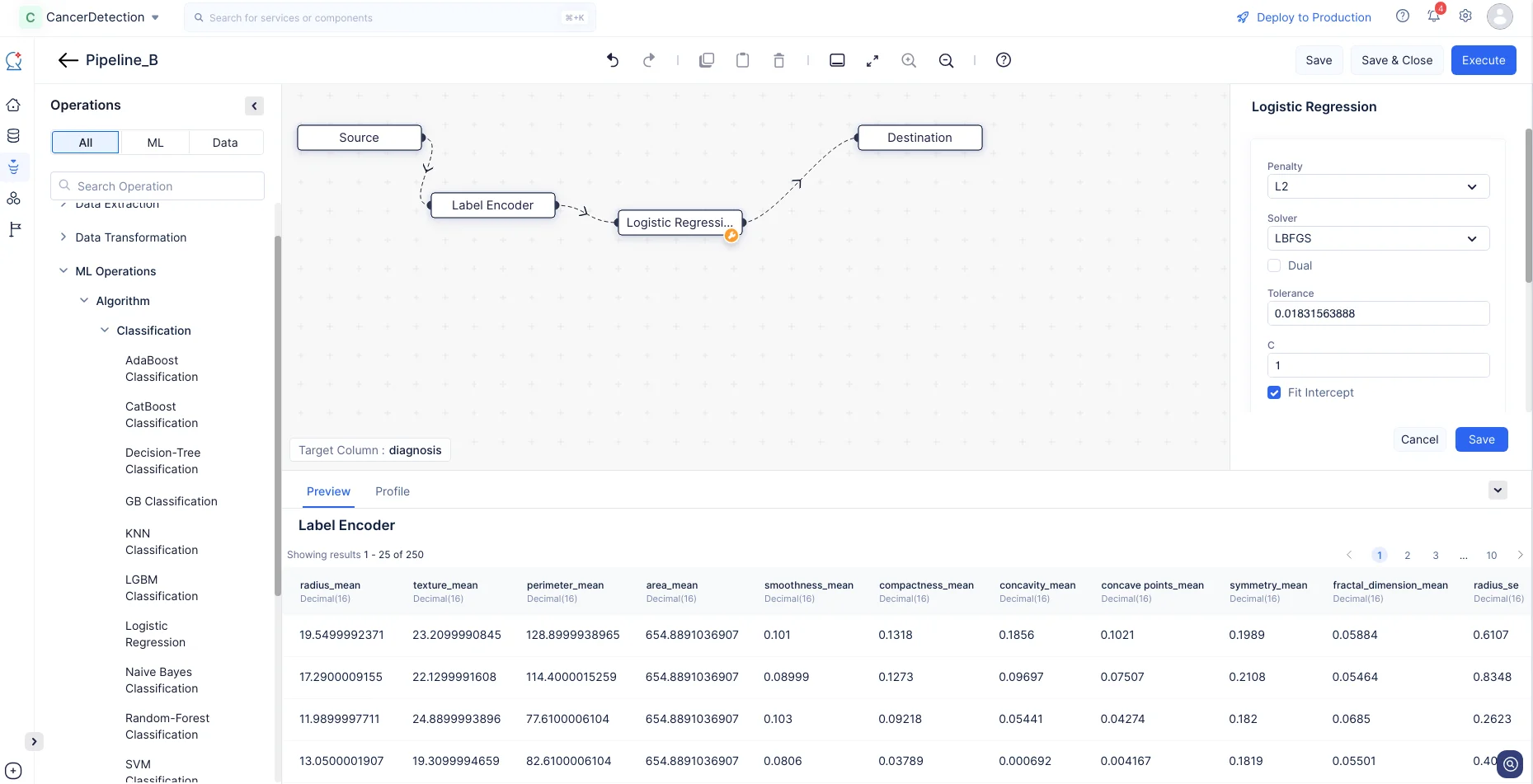
Operationsメニューで、ML operations->Algorithm->Classification->Logistic Regressionを展開します。Logistic RegressionノードをPipeline Builderにドラッグ&ドロップします。ノードは自動的にDestinationノードに接続されます。Label EncoderとLogistic Regressionノードを接続します。
-
Logistic Regressionノードでは、デフォルト設定のままSaveをクリックします。
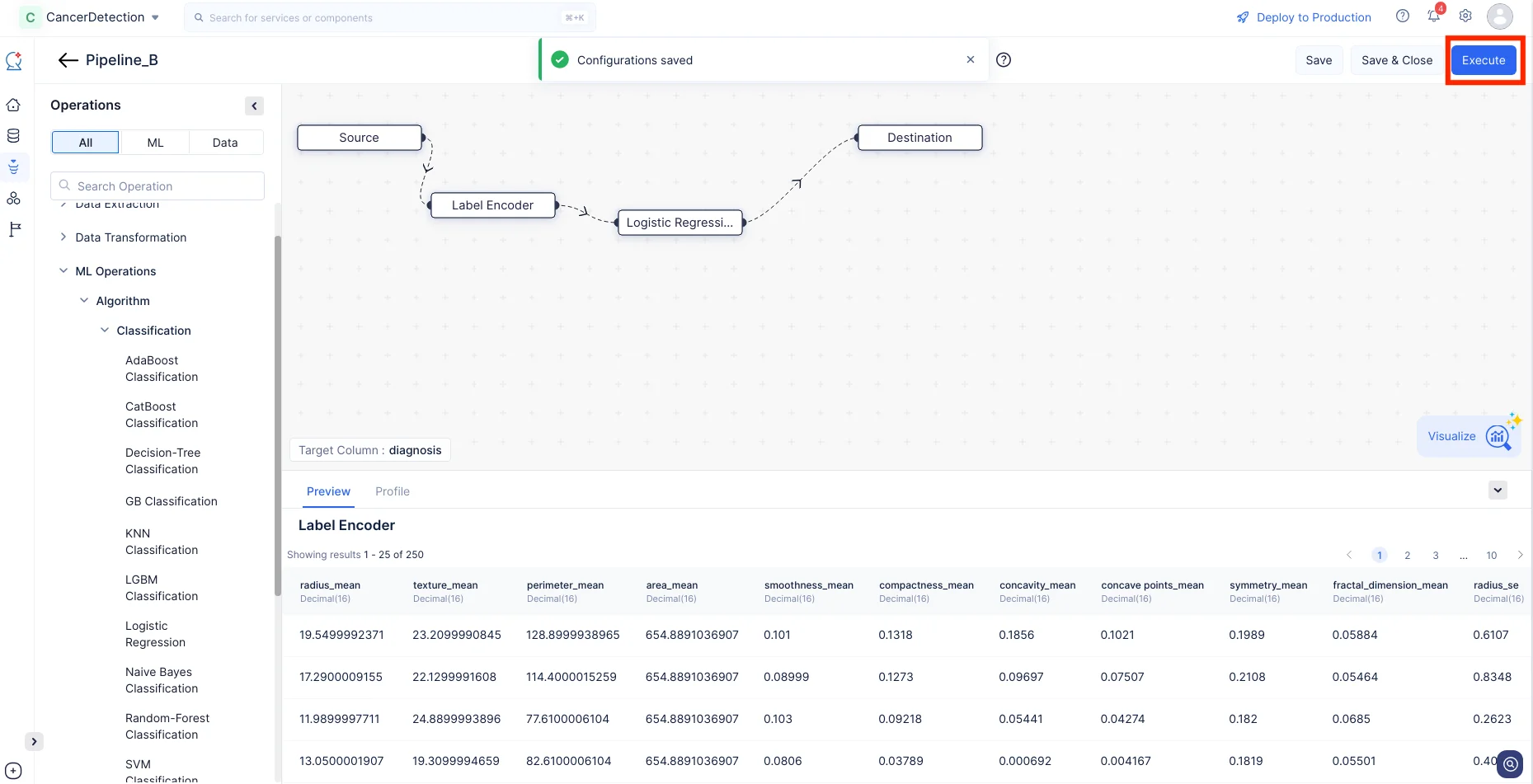
これで、必要なノードの接続と設定が完了しました。Executeをクリックしてパイプラインを実行し、評価とデプロイに進みます。
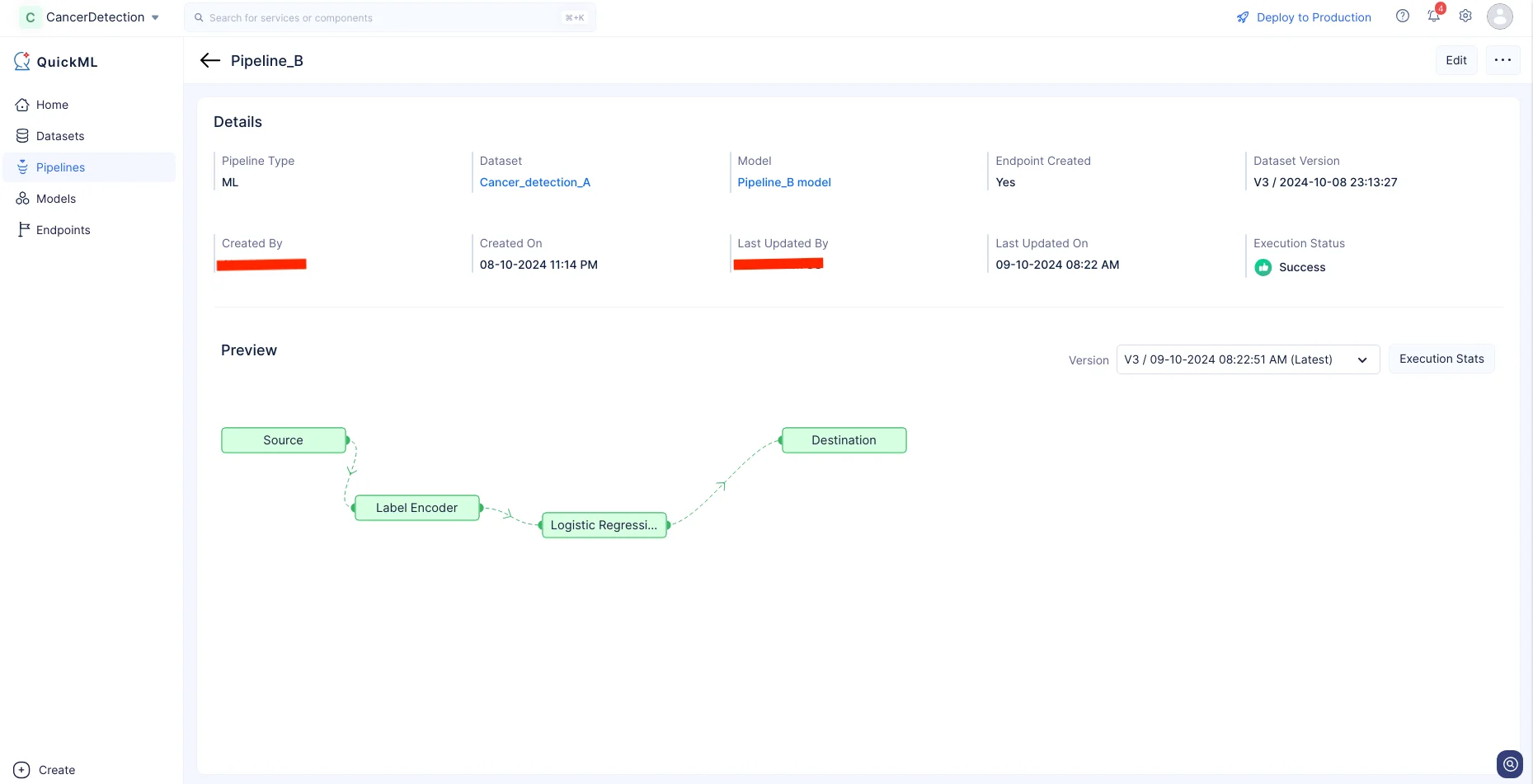
Execution Statsをクリックすると、各実行ステージの詳細を確認できます。
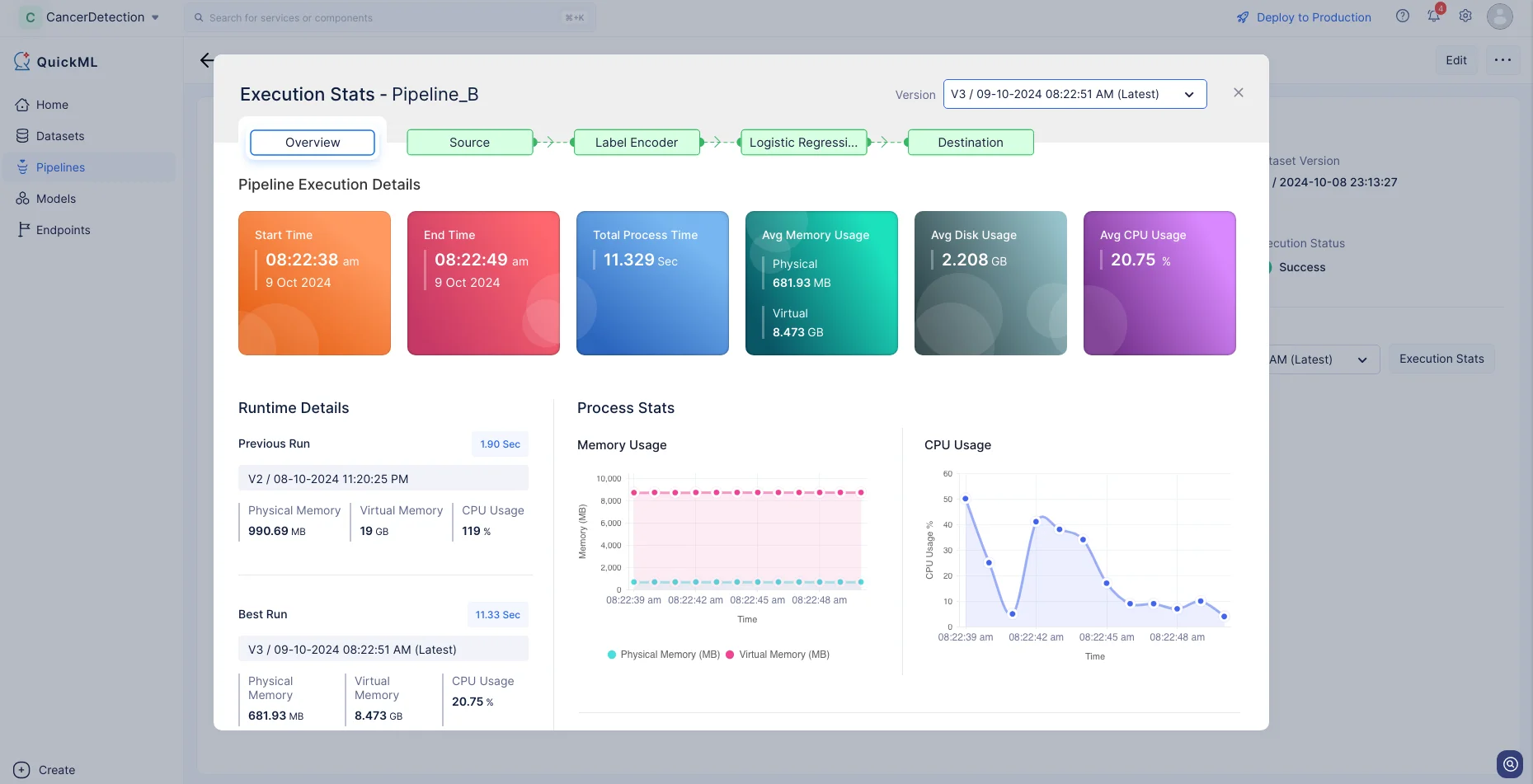
MLパイプラインの実行が成功すると、予測モデルが作成され、Modelsセクションに表示されます。
モデル名をクリックすると、Models詳細ページでモデルの詳細を確認できます。
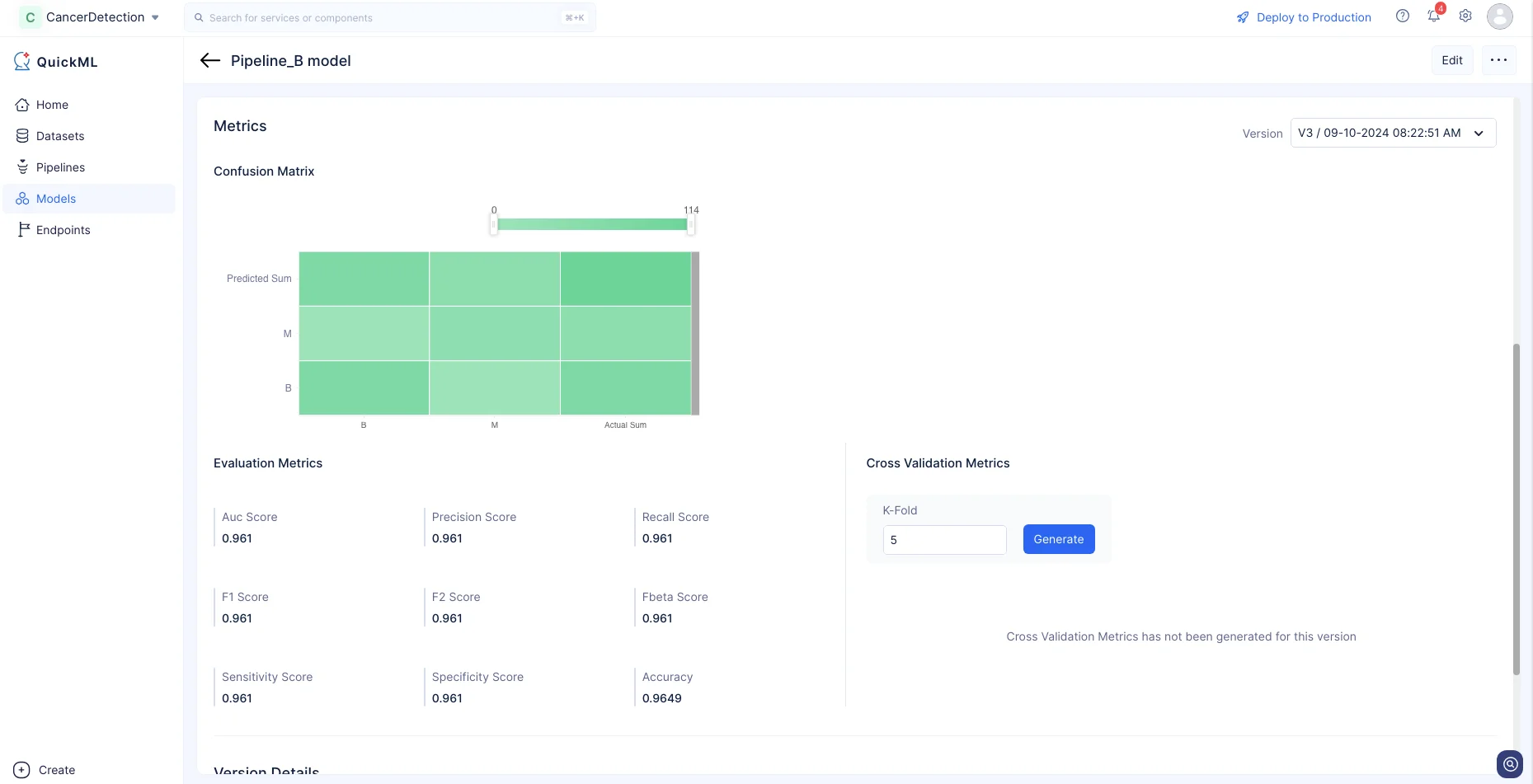
さらに、生成されたモデルの精度は、Models詳細ページのMetricsセクションで評価・確認できます。これにより、データに対するモデルの予測のパフォーマンスと有効性に関する貴重な洞察が得られます。
最終更新日 2026-02-23 18:09:41 +0530 IST