Crear un pipeline de datos
Ahora que hemos subido el conjunto de datos, procederemos a crear un pipeline de datos con el conjunto de datos.
- Navega al componente Datasets en el menú izquierdo. Hay dos formas de crear un pipeline de datos:
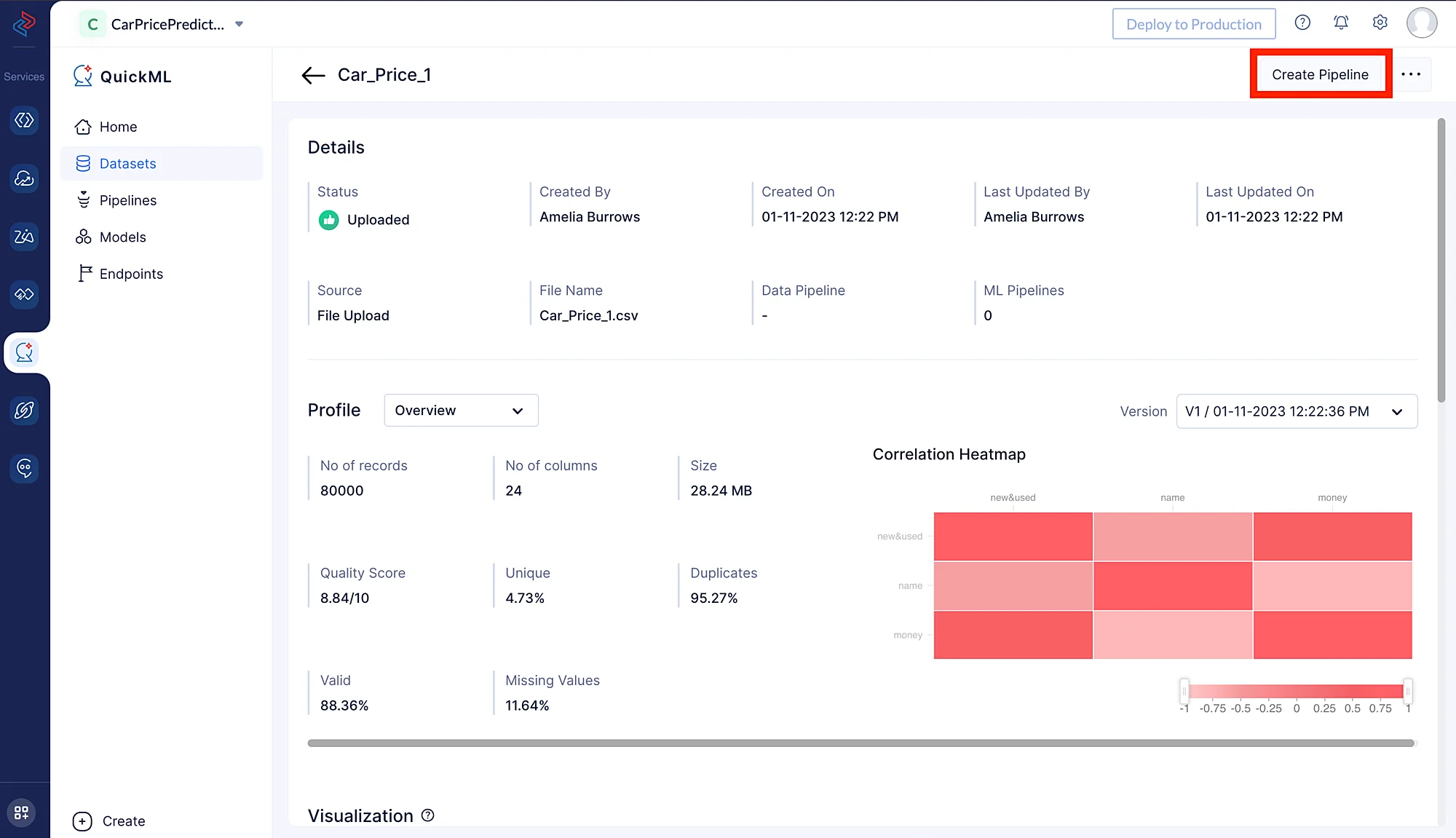
- Puedes hacer clic en el conjunto de datos y luego hacer clic en Create Pipeline en la esquina superior derecha de la página.
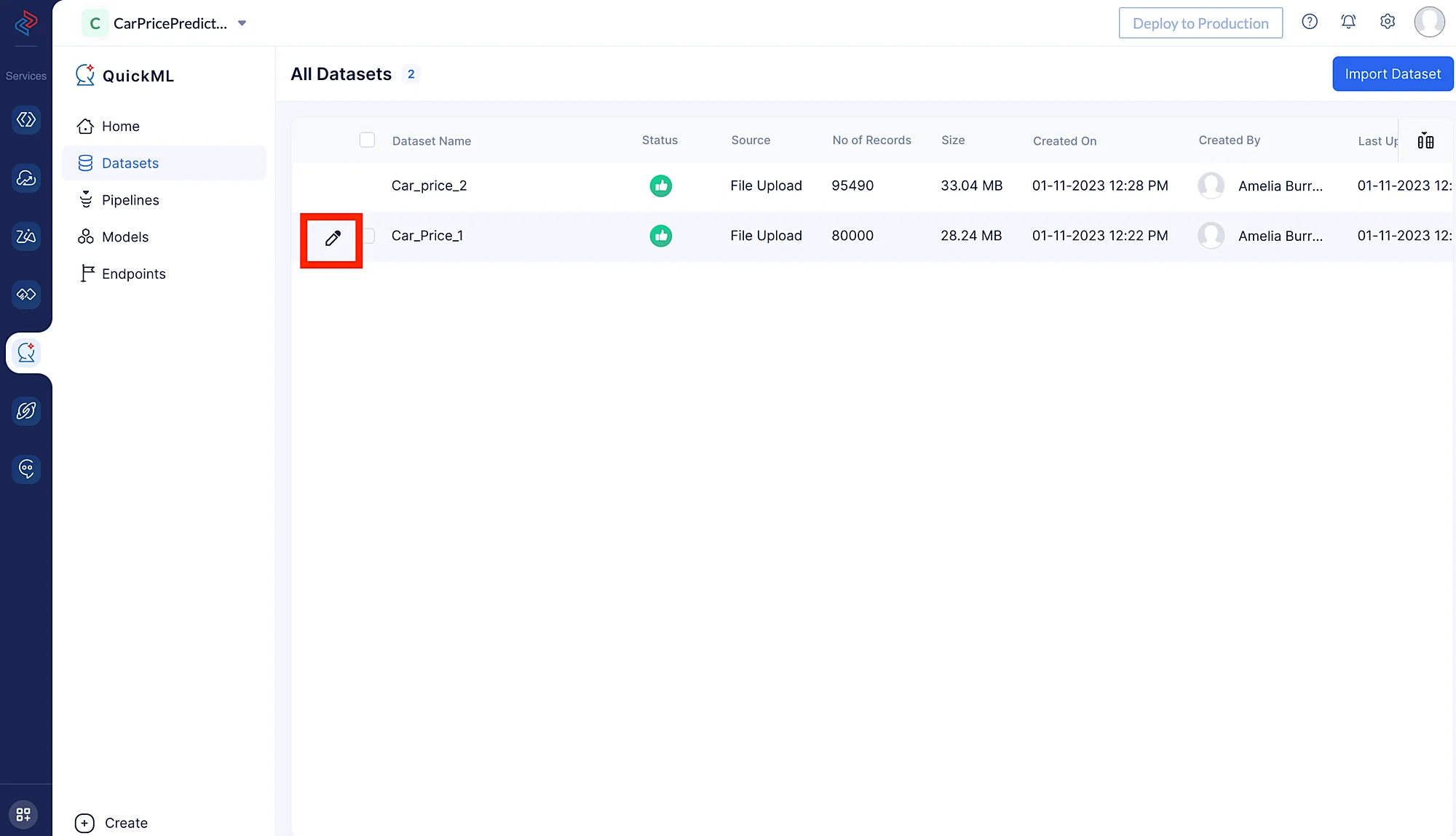
- Puedes hacer clic en el icono de lápiz ubicado a la izquierda del nombre del conjunto de datos, como se muestra en la imagen a continuación.
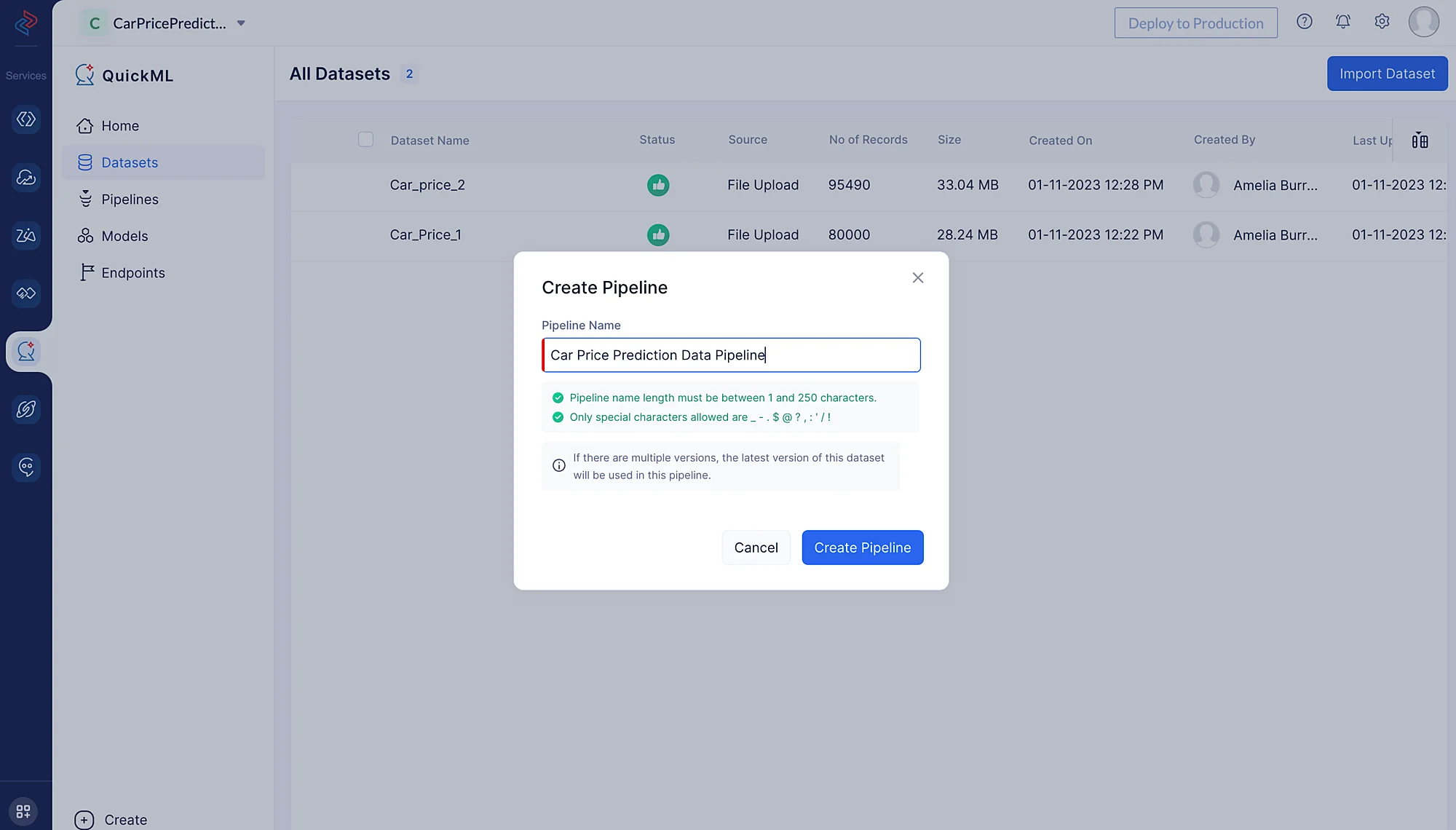
Aquí, estamos subiendo el conjunto de datos Car_price_1 para preprocesamiento. Car_Price_2 se agregará a este conjunto de datos en los próximos pasos de preprocesamiento.
- Nombra el pipeline “Car Price Prediction Data Pipeline” y haz clic en Create Pipeline.
Se abrirá la interfaz del pipeline builder como se muestra en la captura de pantalla a continuación.
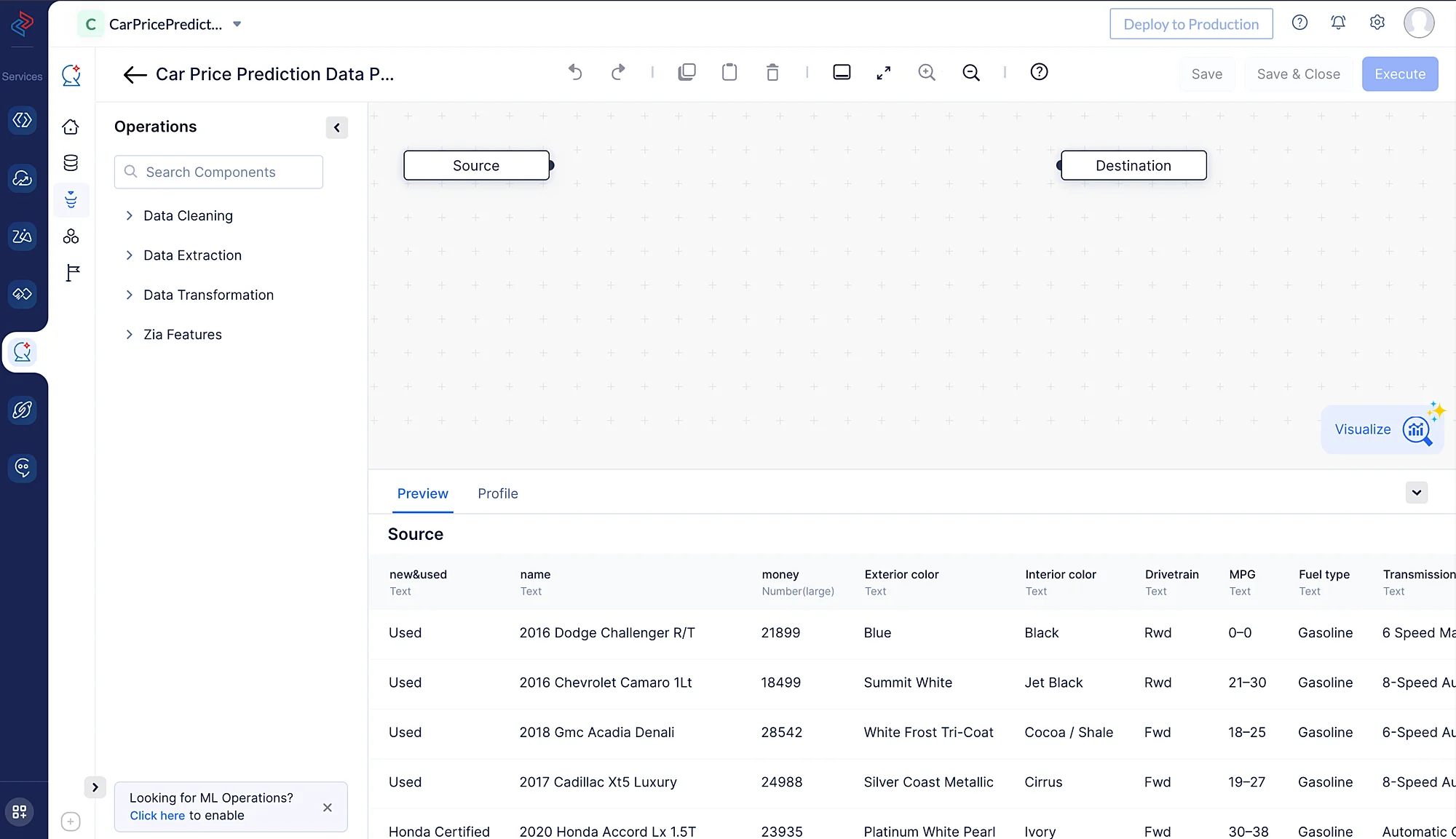
Realizaremos el siguiente conjunto de operaciones de preprocesamiento de datos para limpiar, refinar y transformar los conjuntos de datos, y luego ejecutaremos el pipeline de datos. Cada una de estas operaciones involucra nodos de datos individuales que se usan para construir el pipeline.
Preprocesamiento de datos con QuickML
-
Combinar dos conjuntos de datos
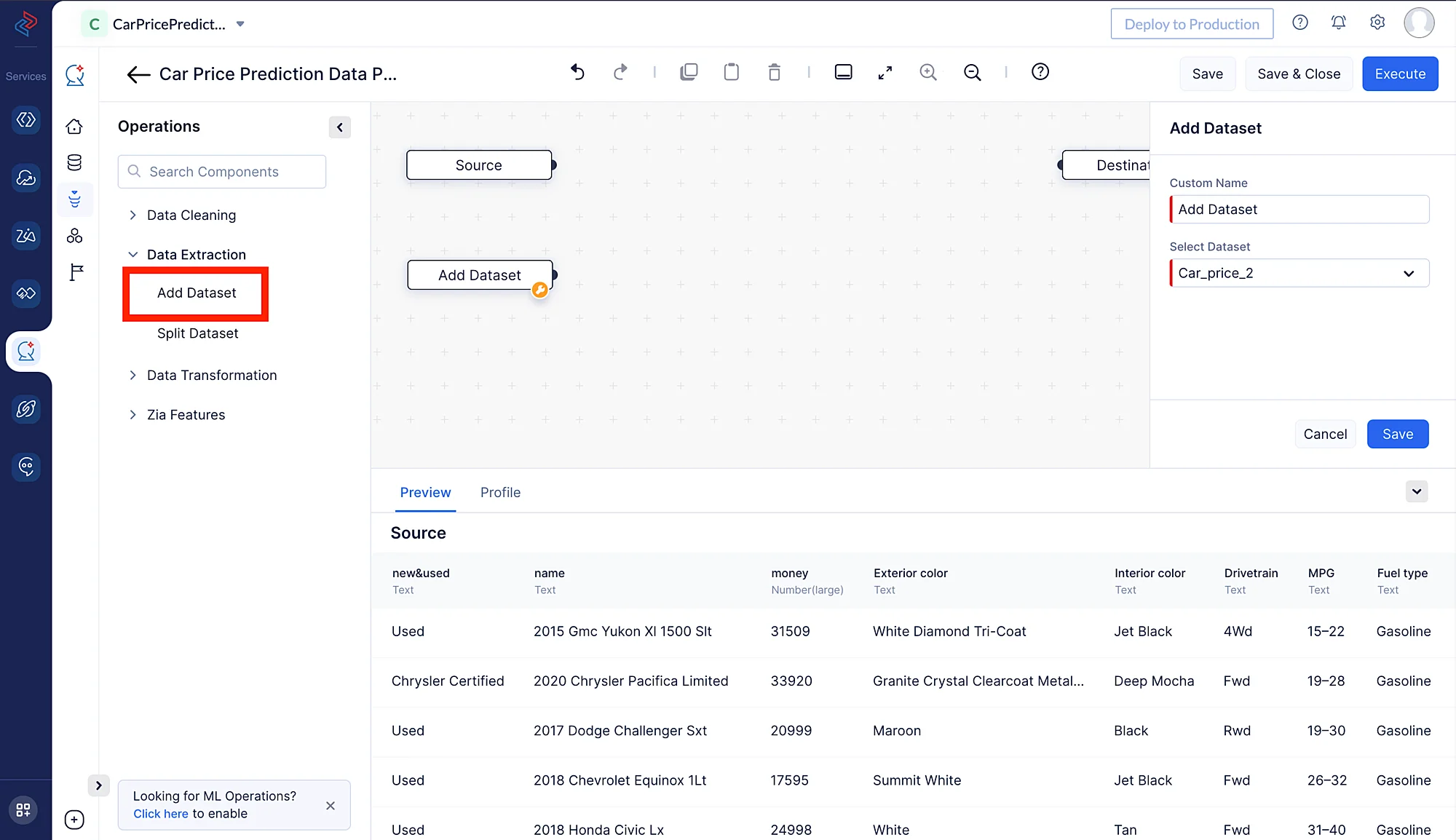
Con la ayuda del nodo Add Dataset en QuickML, podemos agregar un nuevo conjunto de datos (ten en cuenta que primero debes subir el conjunto de datos que deseas agregar). Aquí, estamos agregando el conjunto de datos Car_Price_2 para fusionarlo con el conjunto de datos existente.
Usa el nodo Union en la interfaz de arrastrar y soltar de QuickML desde Data Transformation > Union para combinar los dos conjuntos de datos proporcionados, Car_Price_1 y Car_Price_2, en un único conjunto de datos. Si existen registros duplicados en cualquiera de los conjuntos de datos, asegúrate de marcar la casilla etiquetada “Drop Duplicate Records” al realizar la operación. Esto eliminará los registros duplicados de ambos conjuntos de datos.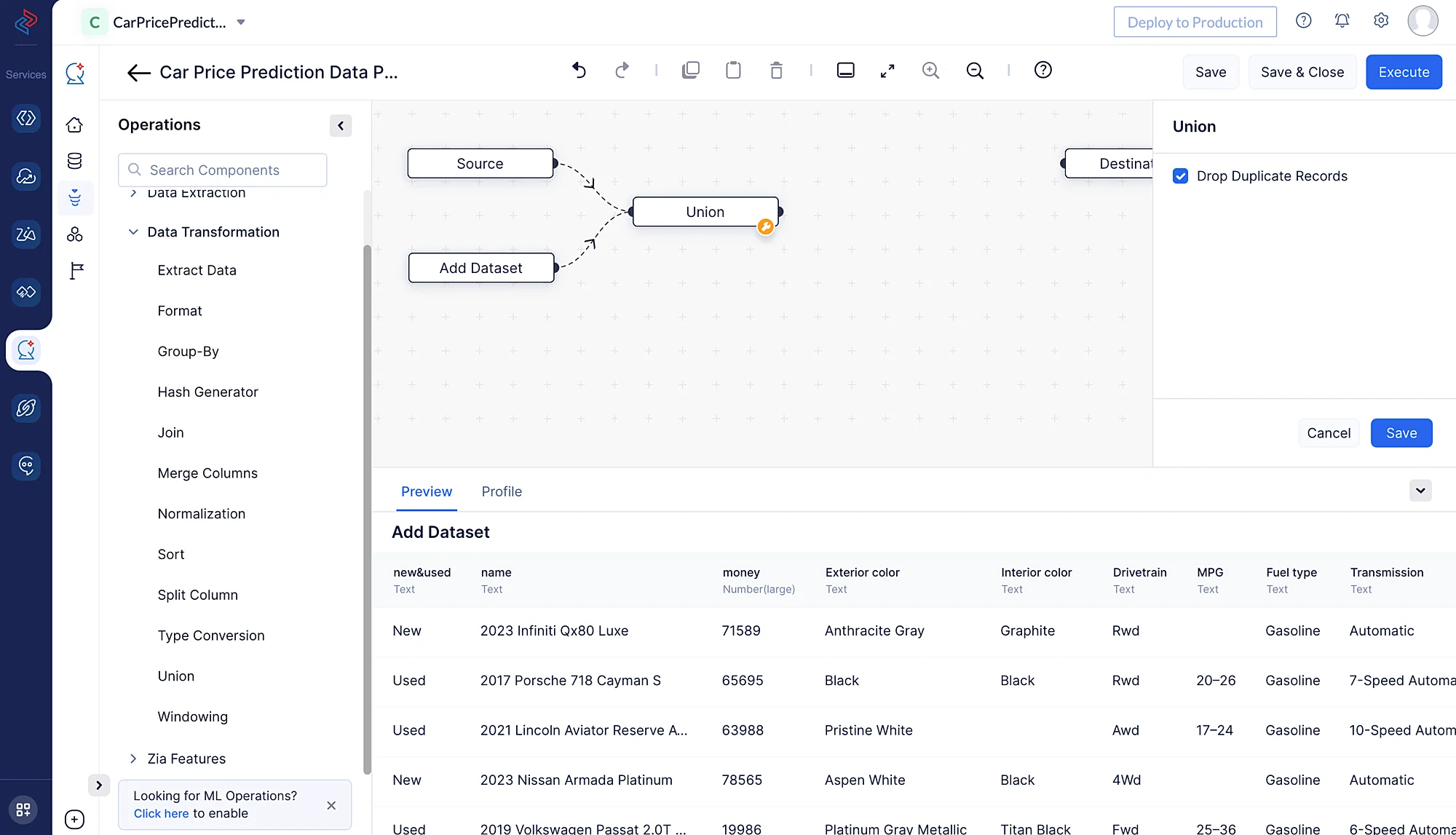
-
Seleccionar/eliminar columnas
Seleccionar o eliminar columnas de un conjunto de datos es un paso común de preprocesamiento de datos en análisis de datos y machine learning. La elección de seleccionar o eliminar columnas depende de los objetivos y requisitos específicos de tu tarea de análisis o modelado. Las columnas que no necesitamos para el entrenamiento de nuestro modelo son “MPG,” “Convenience,” “Exterior,” “Clean title,” “Currency,” y “Name” en los conjuntos de datos proporcionados. Usando QuickML, puedes seleccionar rápidamente los campos necesarios del conjunto de datos para el entrenamiento del modelo usando el nodo Select/Drop de la sección Data Cleaning.

-
Filtrar conjunto de datos
Filtrar un conjunto de datos generalmente implica seleccionar un subconjunto de filas de un DataFrame que cumplan ciertos criterios o condiciones. Aquí, estamos filtrando las columnas “Drivetrain”, “Fuel Type”, “Engine”, “Transmission” y “Safety” que tienen valores no vacíos usando el nodo Filter de la sección Data Cleaning.
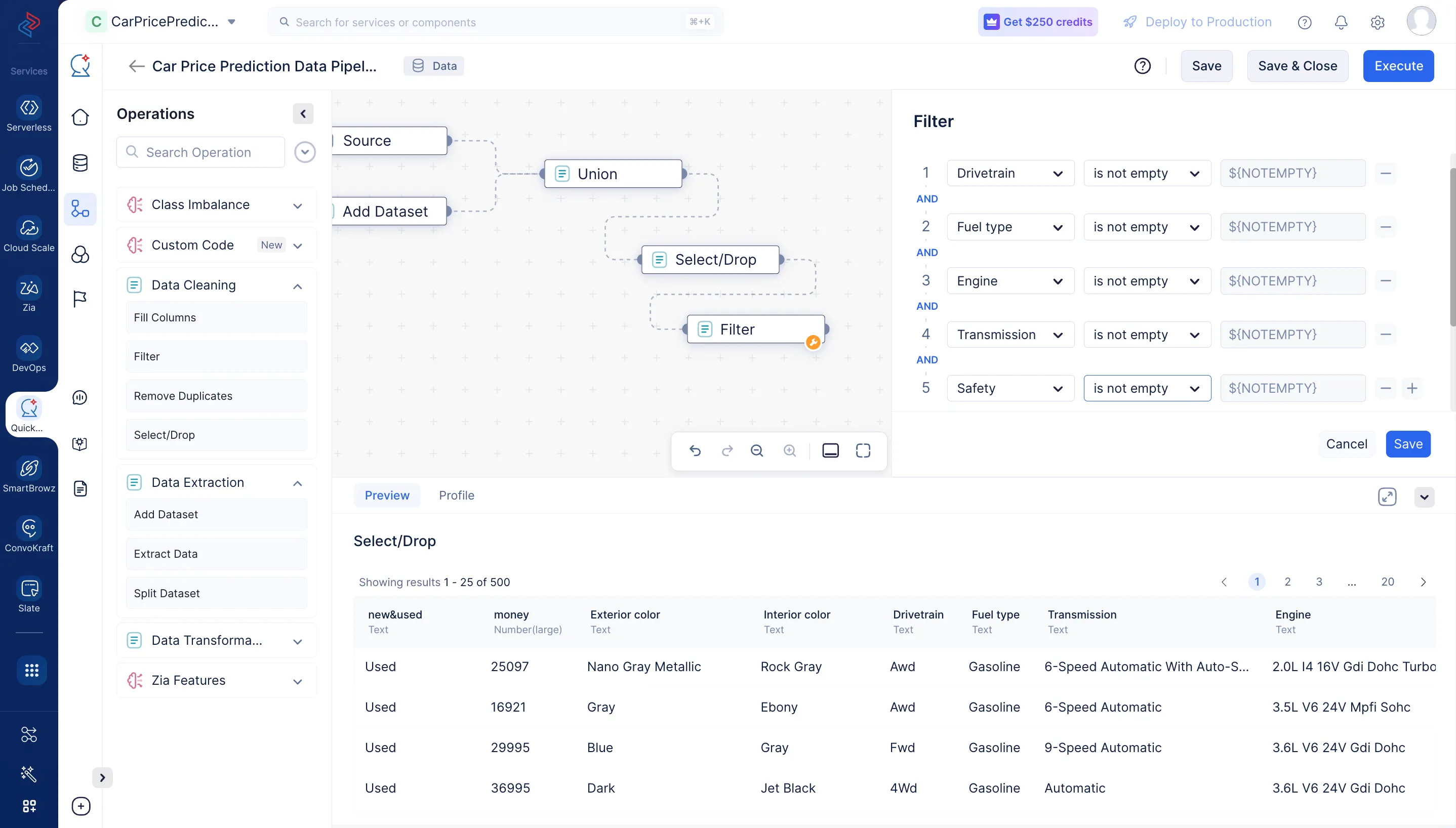
-
Rellenar columnas del conjunto de datos con valores
Usando el nodo Fill Columns en QuickML, podemos rellenar fácilmente los valores de las columnas basándose en cierta condición. Podemos rellenar los valores nulos o no nulos según nuestros requisitos. Aquí, estamos rellenando la columna “new&used” con el valor personalizado “Used” para cualquier entrada en la columna que no esté etiquetada como “New”. Para las columnas “Accidents or damage”, “1-owner vehicle” y “Personal use only”, estamos reemplazando los valores vacíos con un valor personalizado “Not mentioned”.
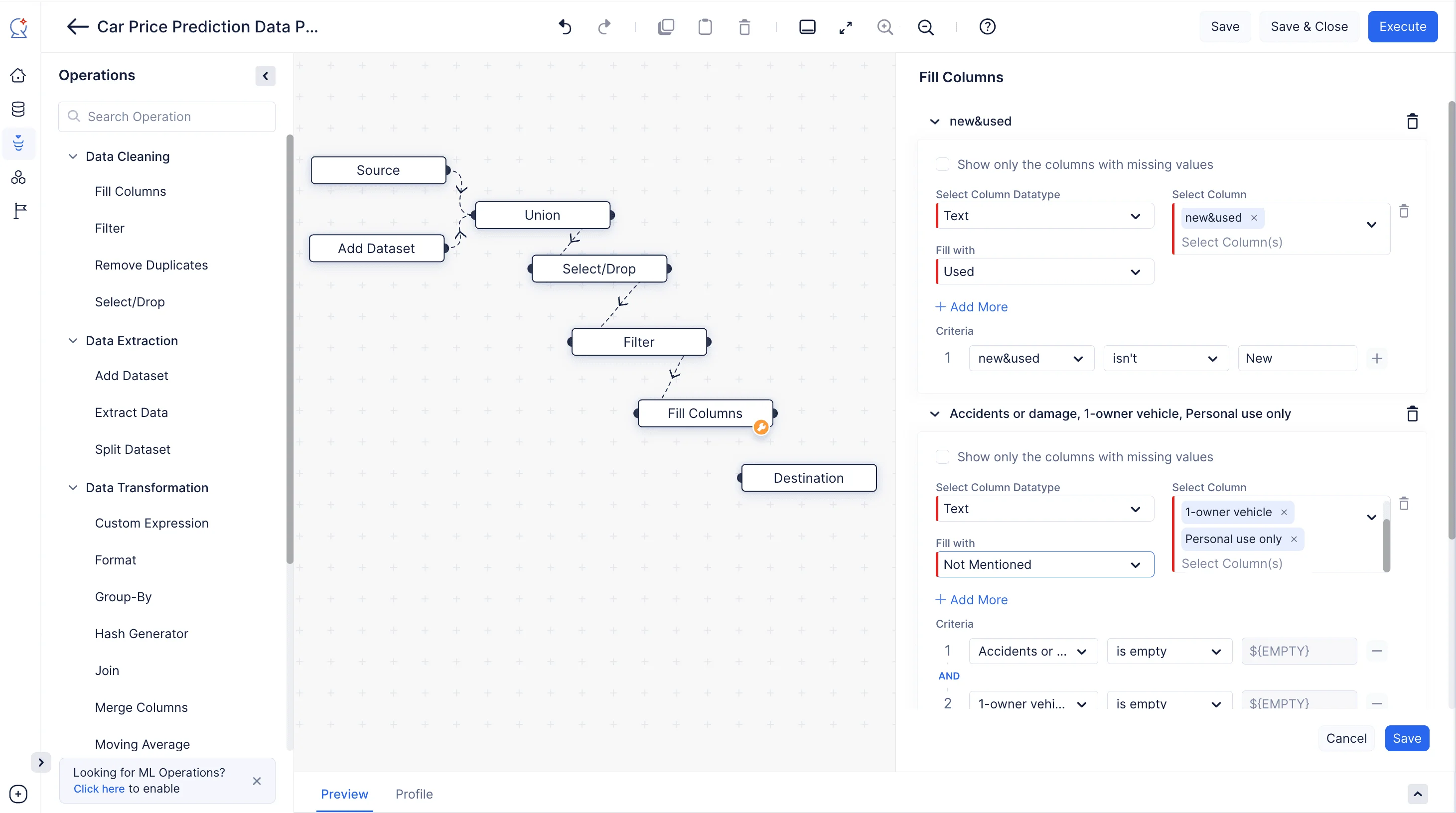
-
Guardar y ejecutar
Ahora conecta el nodo Fill Columns al nodo Destination. Una vez que todos los nodos estén conectados, haz clic en Save para guardar el pipeline y luego haz clic en Execute para ejecutar el pipeline.
Te redirigirá a una página que mostrará el pipeline ejecutado con el estado de ejecución.
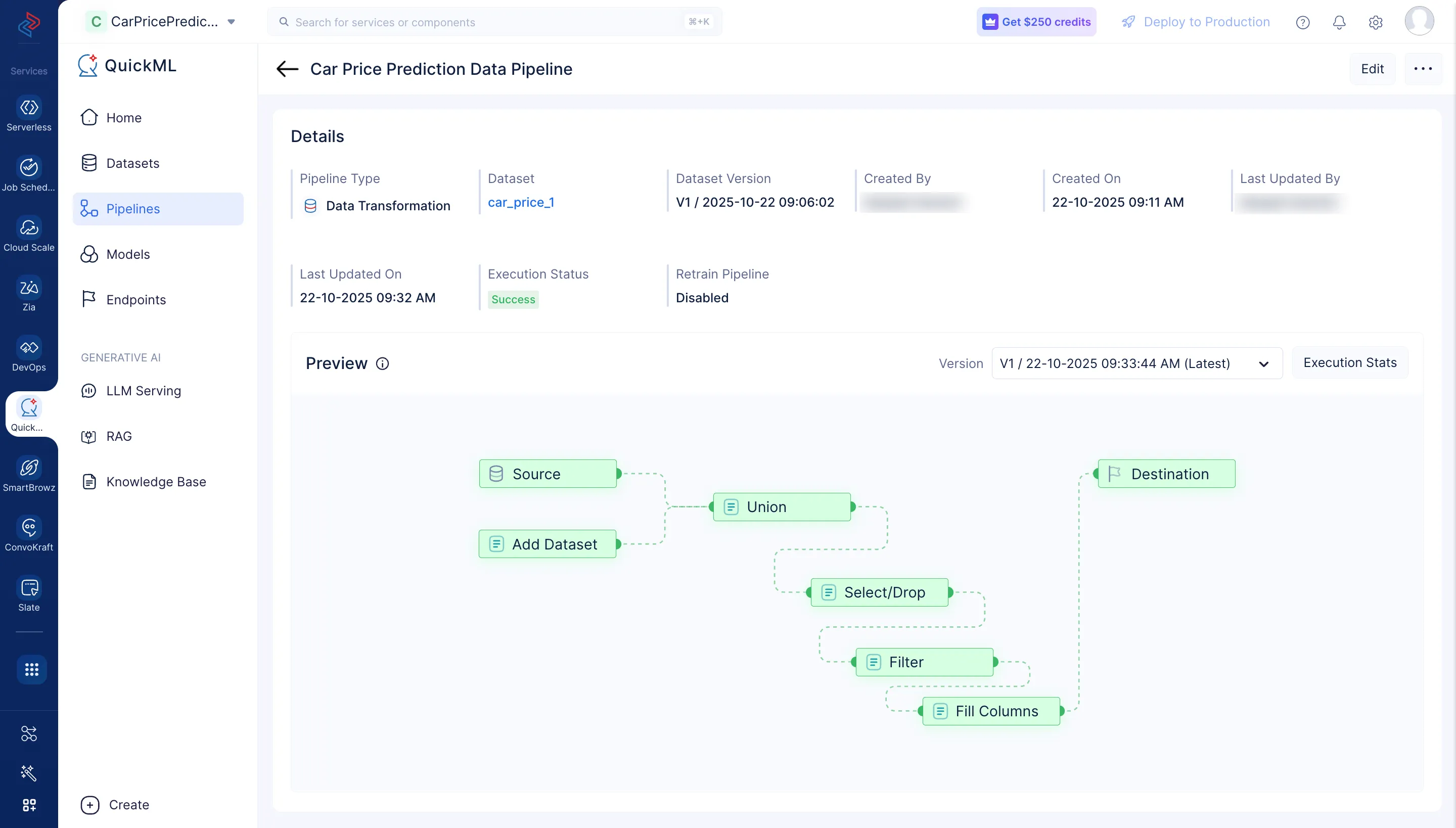
Haz clic en Execution Stats para ver más detalles sobre cada etapa de la ejecución en detalle.
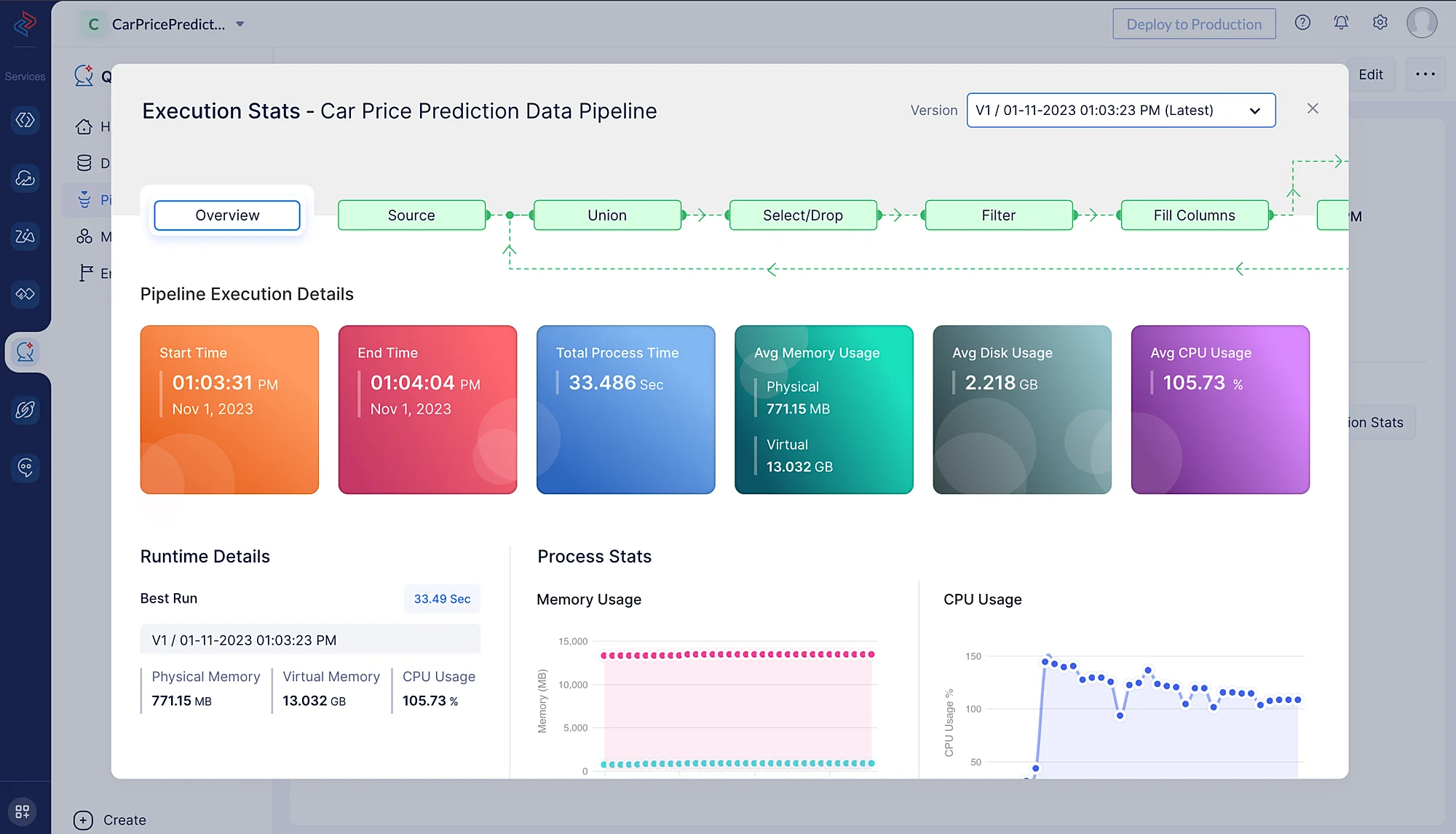
En esta parte, hemos visto cómo procesar datos usando QuickML, dándote una variedad de formas efectivas de preparar tus datos para la creación de modelos de machine learning. Este pipeline de datos puede reutilizarse para crear múltiples experimentos de ML para diversos casos de uso dentro de tu proyecto de Catalyst.
Última actualización 2026-03-20 21:51:56 +0530 IST