Crear un pipeline de ML
Para construir el modelo de predicción, usaremos el conjunto de datos preprocesado en el ML Pipeline Builder. El paso inicial en el ML Pipeline Builder implica seleccionar la columna objetivo, que es la columna que estamos tratando de predecir.
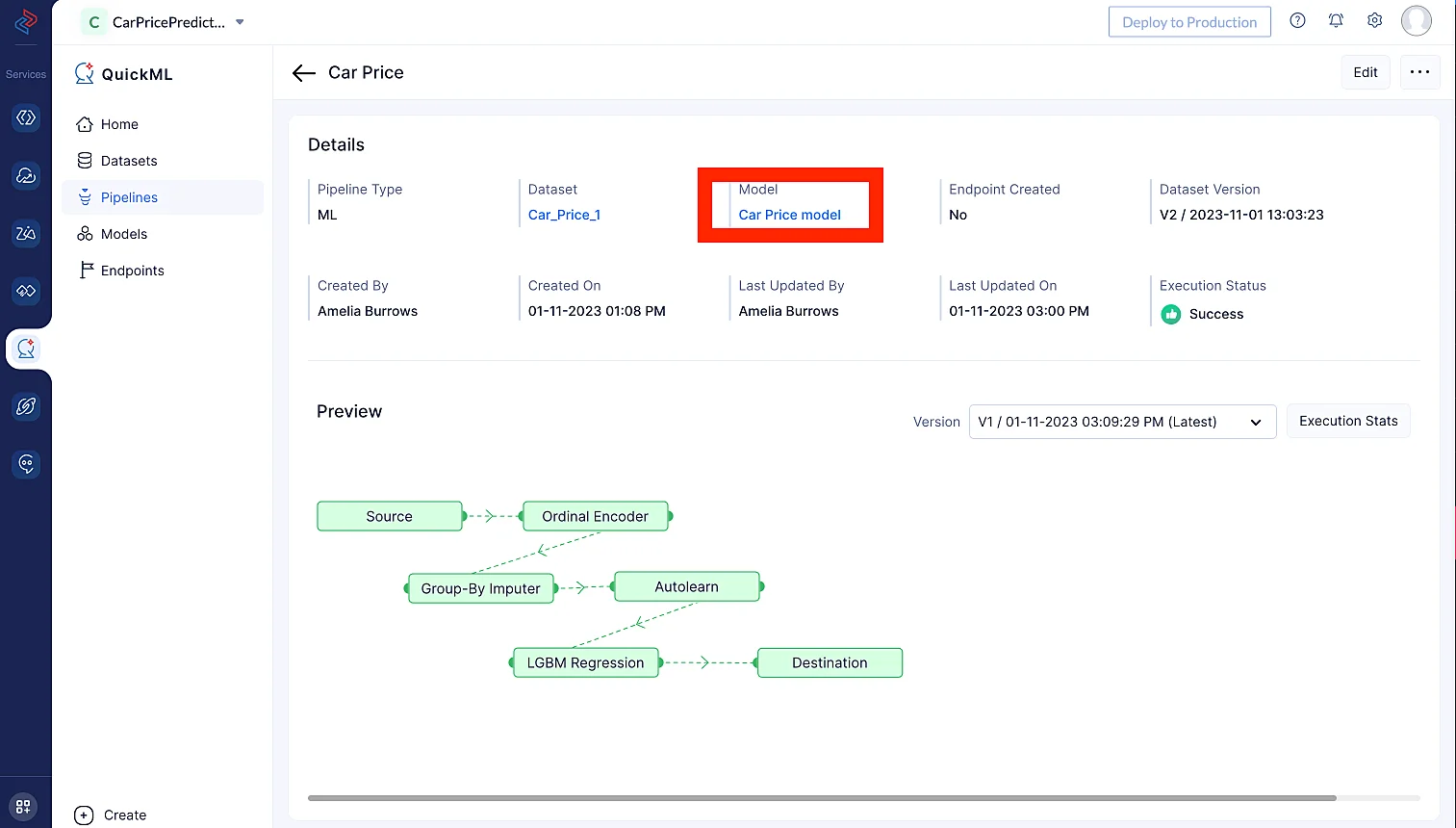
Para crear un pipeline de ML, primero navega a la sección Pipelines y haz clic en Create Pipeline.
En la ventana emergente que aparece, selecciona Prediction como tipo de pipeline y proporciona un nombre (aquí, usamos Car Price Model) para el pipeline y especifica el nombre del modelo. Luego, selecciona el conjunto de datos apropiado y el nombre de la columna objetivo. En este caso, nuestro objetivo es la columna llamada “money”.
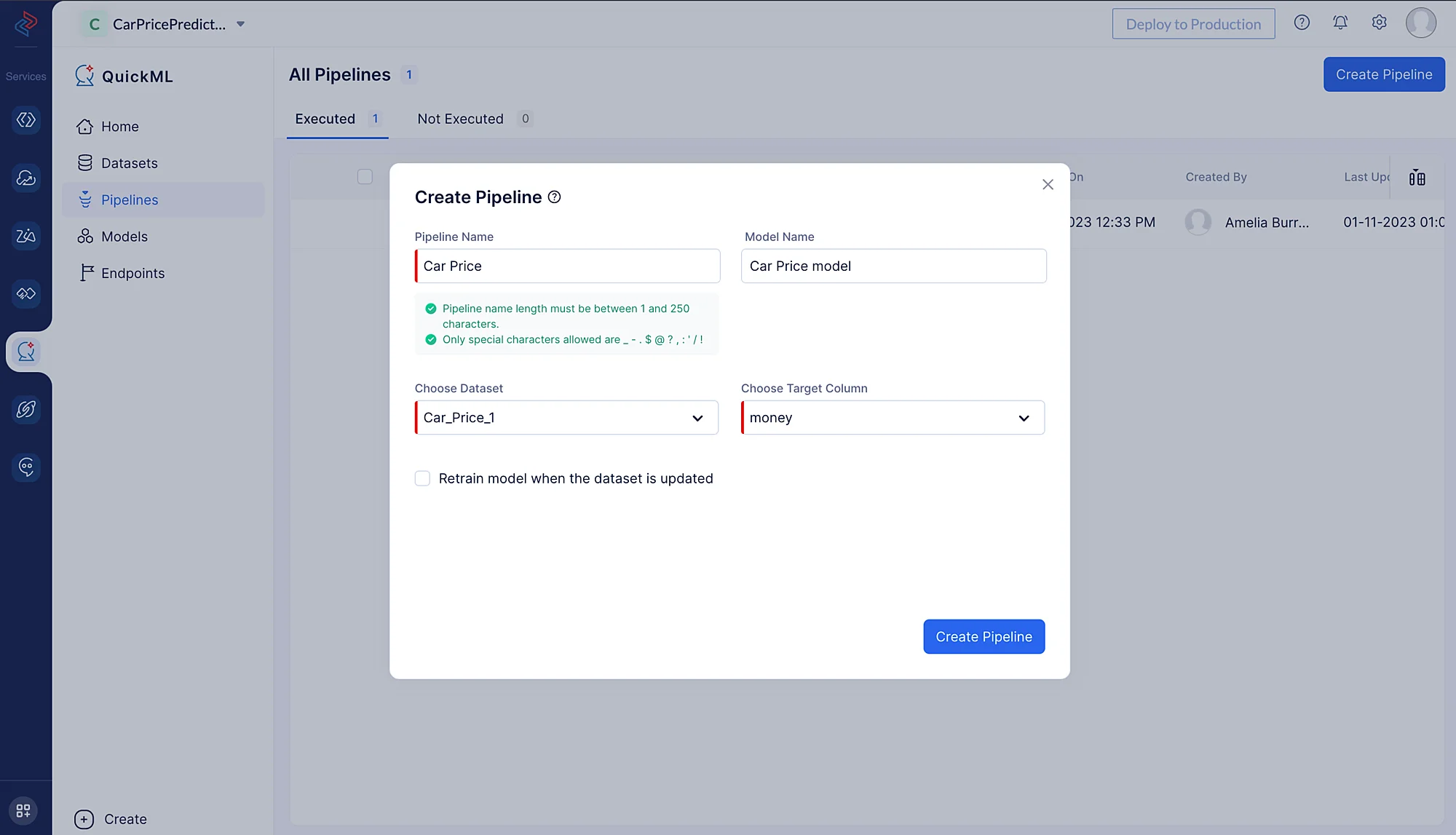
Al seleccionar el conjunto de datos, necesitamos seleccionar el conjunto de datos fuente que elegimos para construir el pipeline de datos, ya que los datos preprocesados se reflejan en el conjunto de datos fuente. En nuestro caso, importaremos el conjunto de datos Car_Price_1, ya que seleccionamos este conjunto de datos para preprocesar y limpiar los datos.
Codificación de columnas categóricas
Los codificadores se usan en varias tareas de preprocesamiento de datos y machine learning para convertir datos categóricos o no numéricos en un formato numérico con el que los algoritmos de machine learning puedan trabajar de forma efectiva.
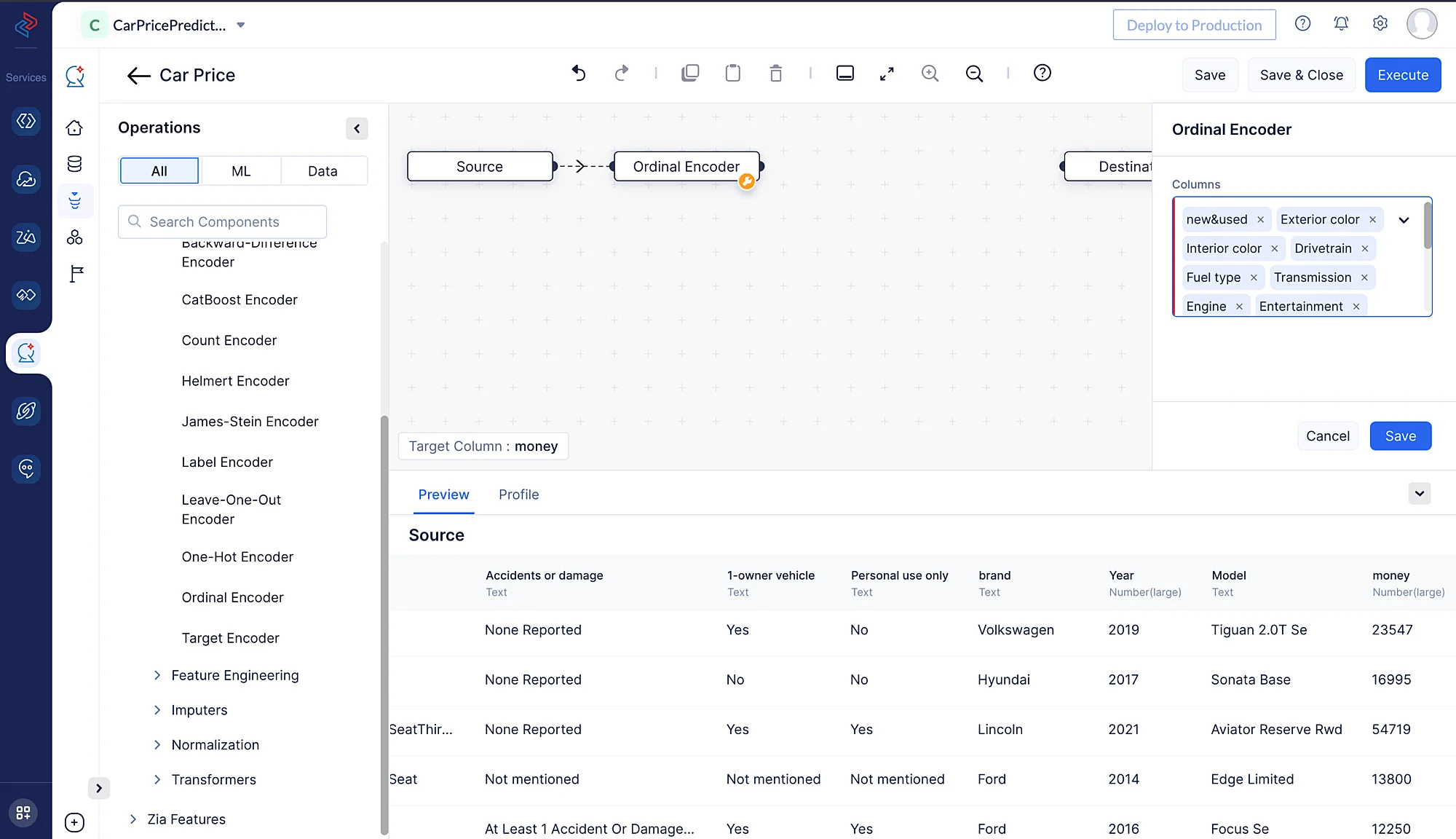
Aquí, estamos usando Ordinal Encoding para codificar todas las características categóricas. Asigna números enteros a las categorías basándose en su orden, lo que permite a los algoritmos de machine learning capturar la naturaleza ordinal de los datos.
Podemos usar el nodo Ordinal Encoder desde ML Operations > Encoding > Ordinal Encoder en QuickML para convertir las columnas categóricas en columnas numéricas. Aquí, estamos convirtiendo todas las columnas categóricas a formato numérico manteniendo el orden original y los datos de las columnas para el entrenamiento del modelo.
Imputadores
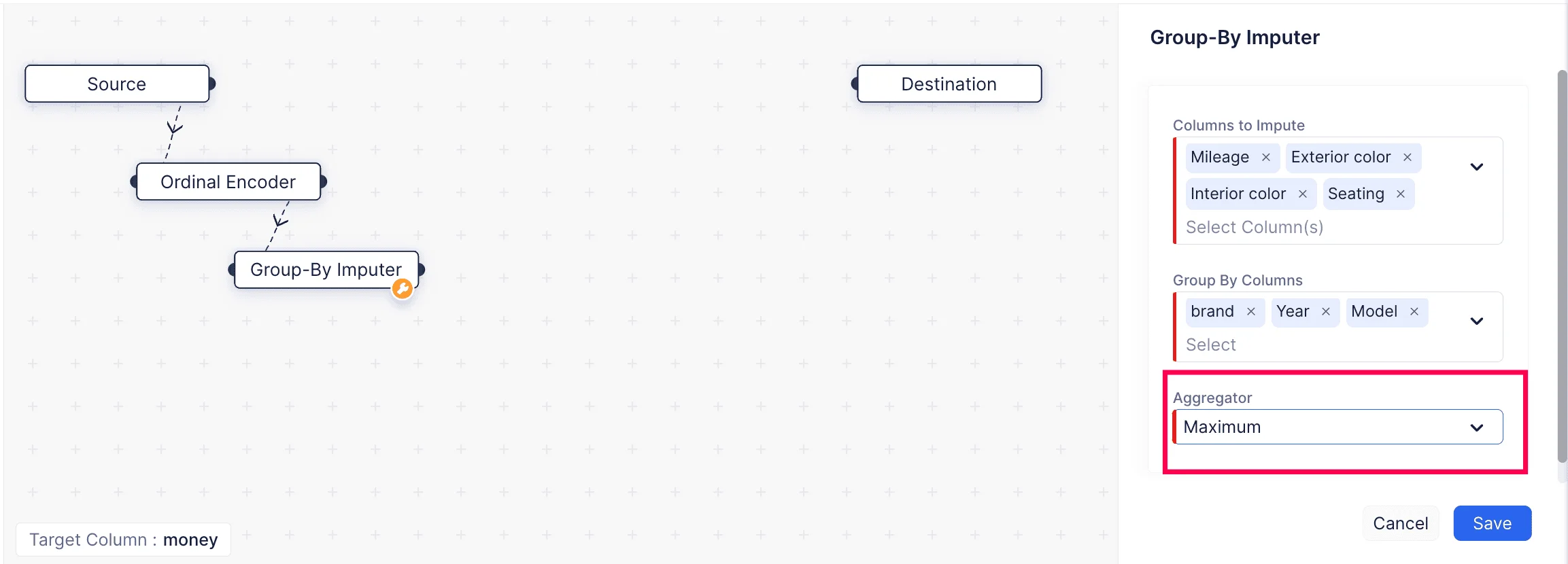
Los imputadores se usan en varios campos, como el análisis de datos, estadística y machine learning para manejar datos faltantes o incompletos. Aquí, estamos usando el imputador Group By desde ML operations > Imputers > Group-By Imputer para imputar los valores faltantes en el conjunto de datos.
La imputación Group By se refiere a una técnica de imputación de datos donde los valores faltantes se rellenan basándose en alguna agrupación o categorización de columnas seleccionadas. Si podemos decir que una columna particular puede ser imputada considerando otro conjunto de valores de columnas, podemos usar esta técnica de imputación.
Aquí, las columnas con valores faltantes son “Mileage”, “Exterior Color”, “Interior Color” y “Seating”. Hemos agrupado las columnas “brand”, “Year” y “Model” para rellenar los valores faltantes.
Ingeniería de Características
El acto de desarrollar nuevas características (variables) a partir de datos ya existentes se denomina Feature Generation. Estas características adicionales pueden utilizarse para mejorar la funcionalidad de un modelo de machine learning o para obtener más información sobre los datos subyacentes. Una parte crucial del pipeline de preprocesamiento de datos es la generación de características, que puede ayudar a transformar datos sin procesar en algo más adecuado para el modelado y extraer información útil de ellos.
Aquí, hemos usado la técnica de generación de características “Autolearn” para generar las características. Este método genera características a partir de las columnas existentes. Podemos seleccionar este nodo desde ML Operations > Feature Engineering > Feature Generation > Autolearn.
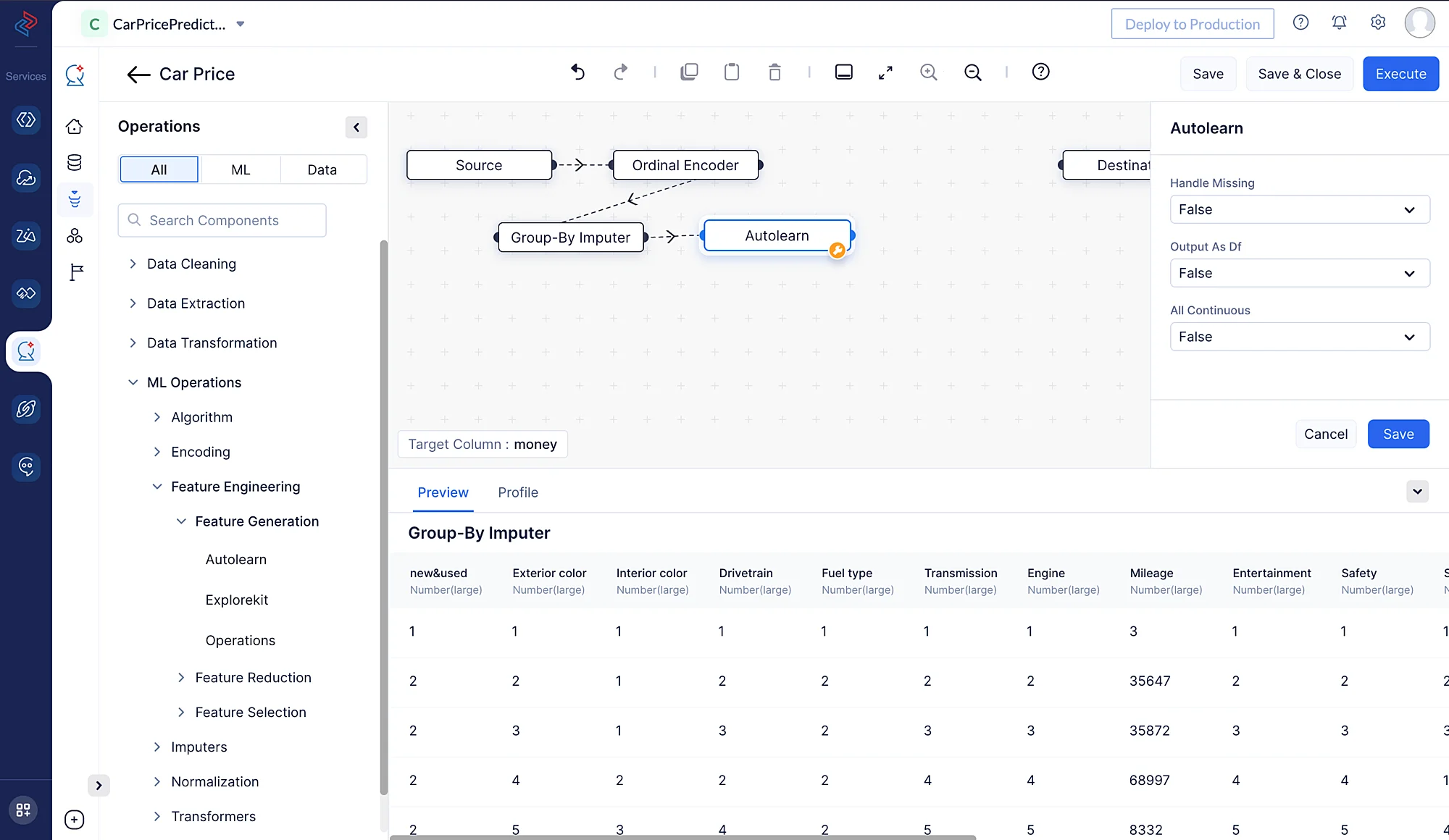
Selección de algoritmo y ajuste del modelo
El siguiente paso en la construcción del pipeline de ML es seleccionar el algoritmo apropiado para entrenar los datos preprocesados. Aquí, usaremos el algoritmo LightGBM Regressor para entrenar los datos.
LightGBM (Light Gradient Boosting Machine) es un framework popular de gradient boosting usado para varias tareas de machine learning, incluyendo problemas de regresión. Es conocido por su eficiencia y velocidad en el entrenamiento, lo que lo convierte en una opción popular para conjuntos de datos grandes.
Podemos construir rápidamente el método LightGBM Regression en el ML Pipeline Builder de QuickML arrastrando y soltando el nodo relevante LightGBM Regression desde ML Operations > Algorithm > Regression > LGBM Regression.
Para asegurarnos de que el modelo esté optimizado para nuestro conjunto de datos particular, también podemos ajustar los parámetros de ajuste. En nuestro caso, podemos simplemente mantener la configuración predeterminada. Cuando todo esté configurado, podemos guardar el pipeline para pruebas y despliegue posteriores.
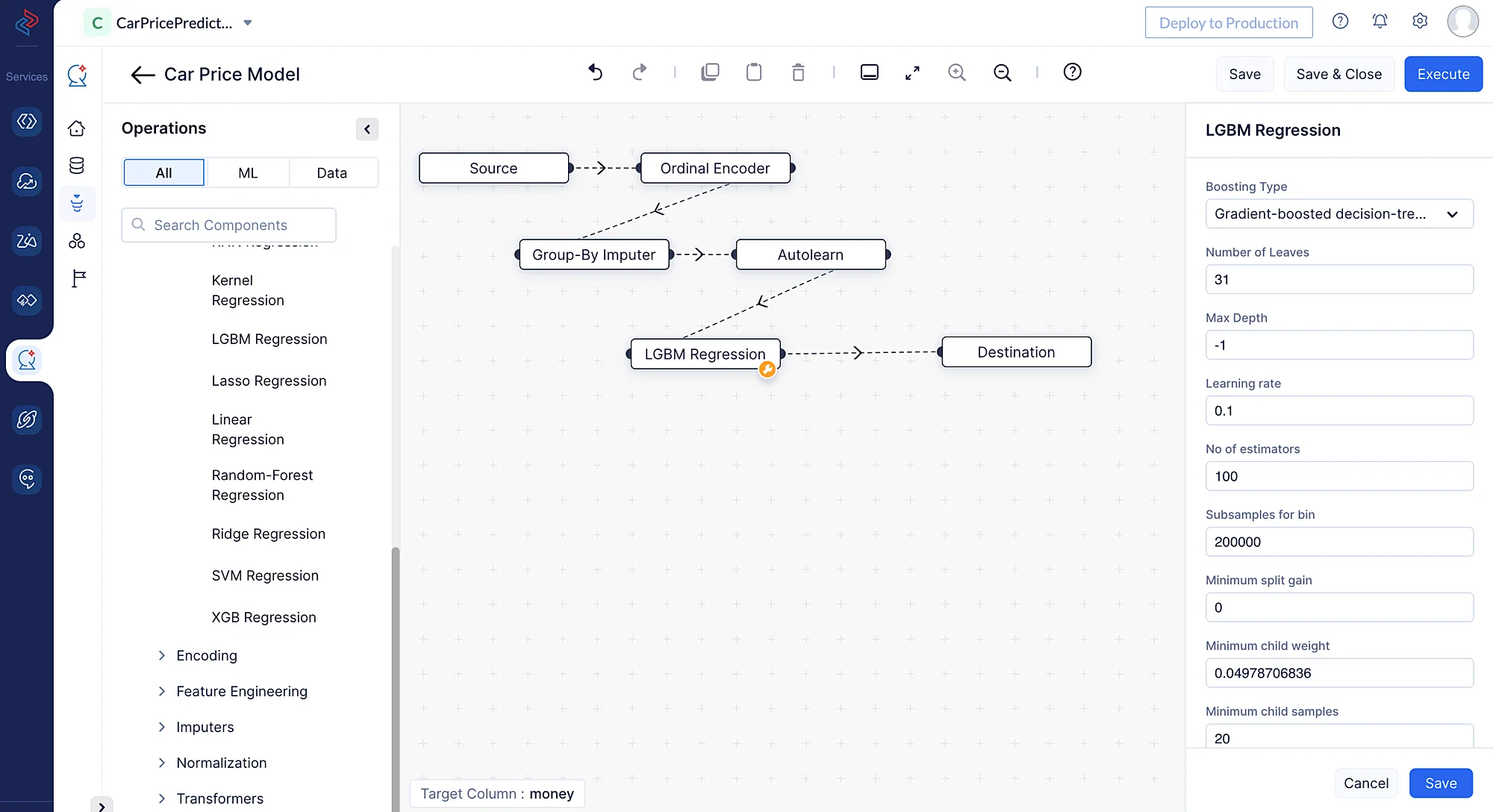
Una vez que arrastramos y soltamos el nodo del algoritmo, su nodo final se conectará automáticamente al nodo de destino. Una vez que el pipeline esté guardado, puedes ejecutar el pipeline haciendo clic en Execute en la esquina superior derecha de la página del pipeline.
Esto te redirigirá a la página de ejecución, donde podrás ver la ejecución del pipeline.
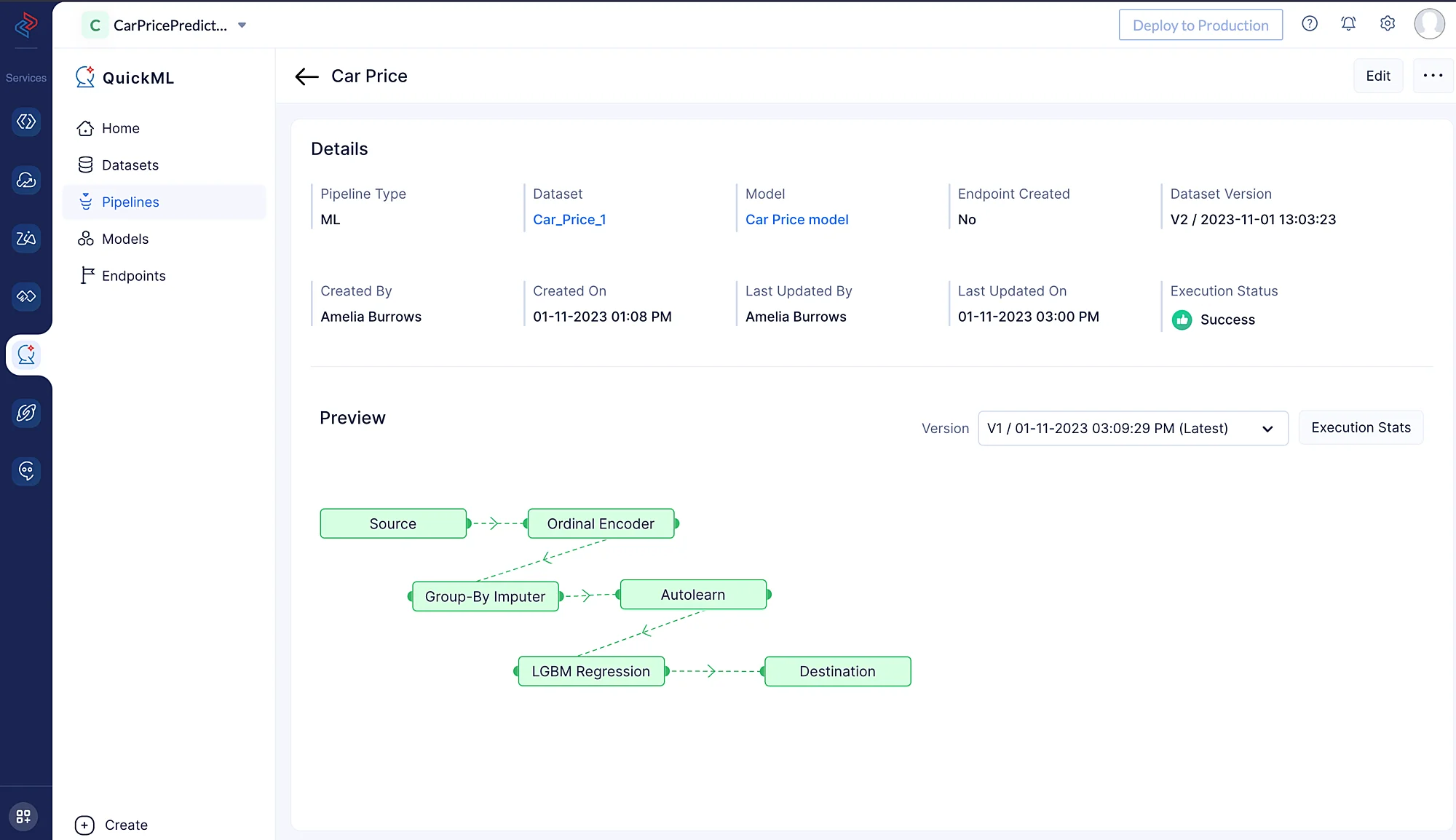
Haz clic en Execution Stats para ver más detalles sobre cada etapa de la ejecución del pipeline de ML en detalle.
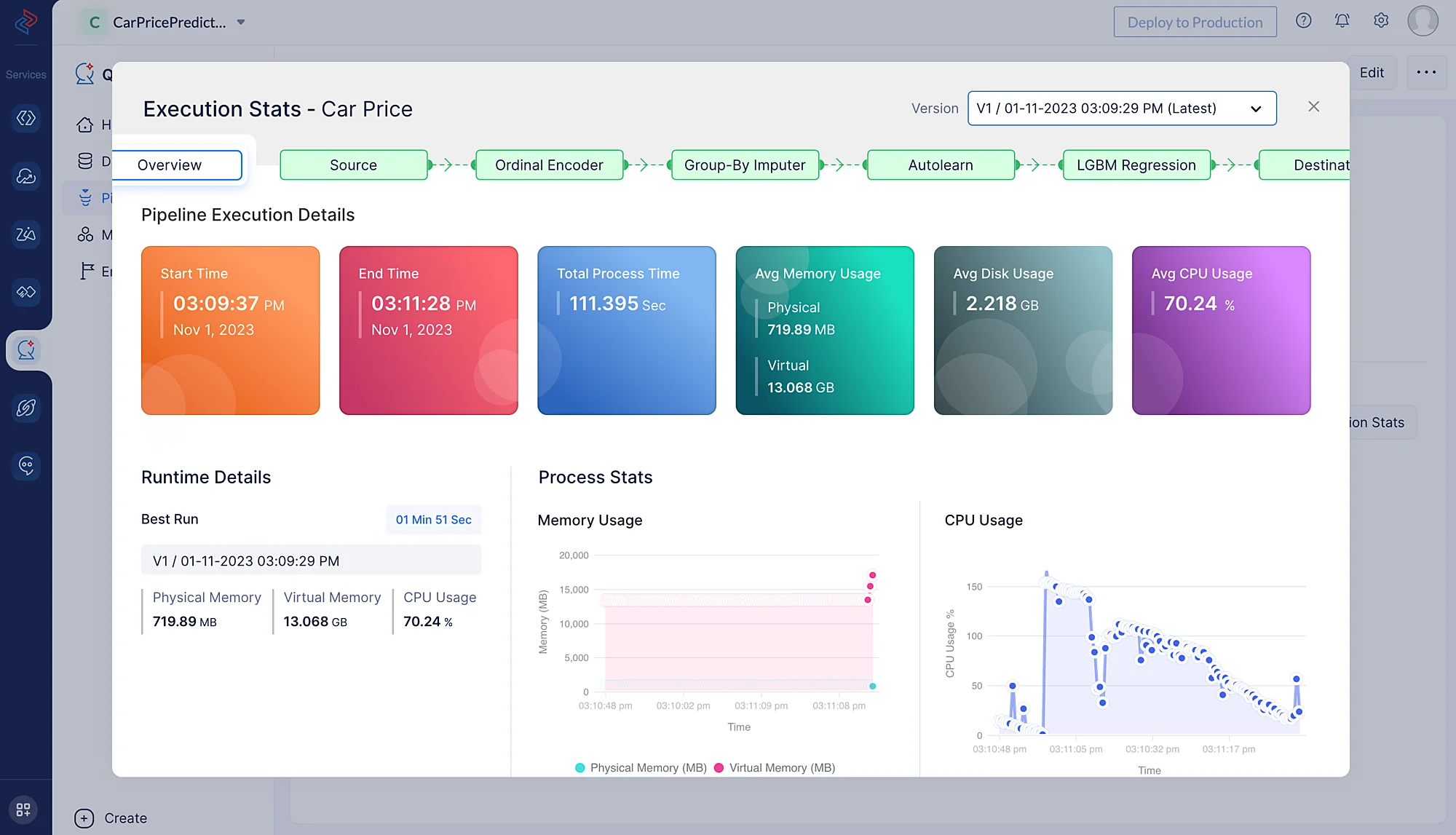
El modelo de predicción se crea y puede examinarse en la sección Model (haz clic en Car Price Model model) tras la ejecución exitosa del flujo de trabajo de ML.
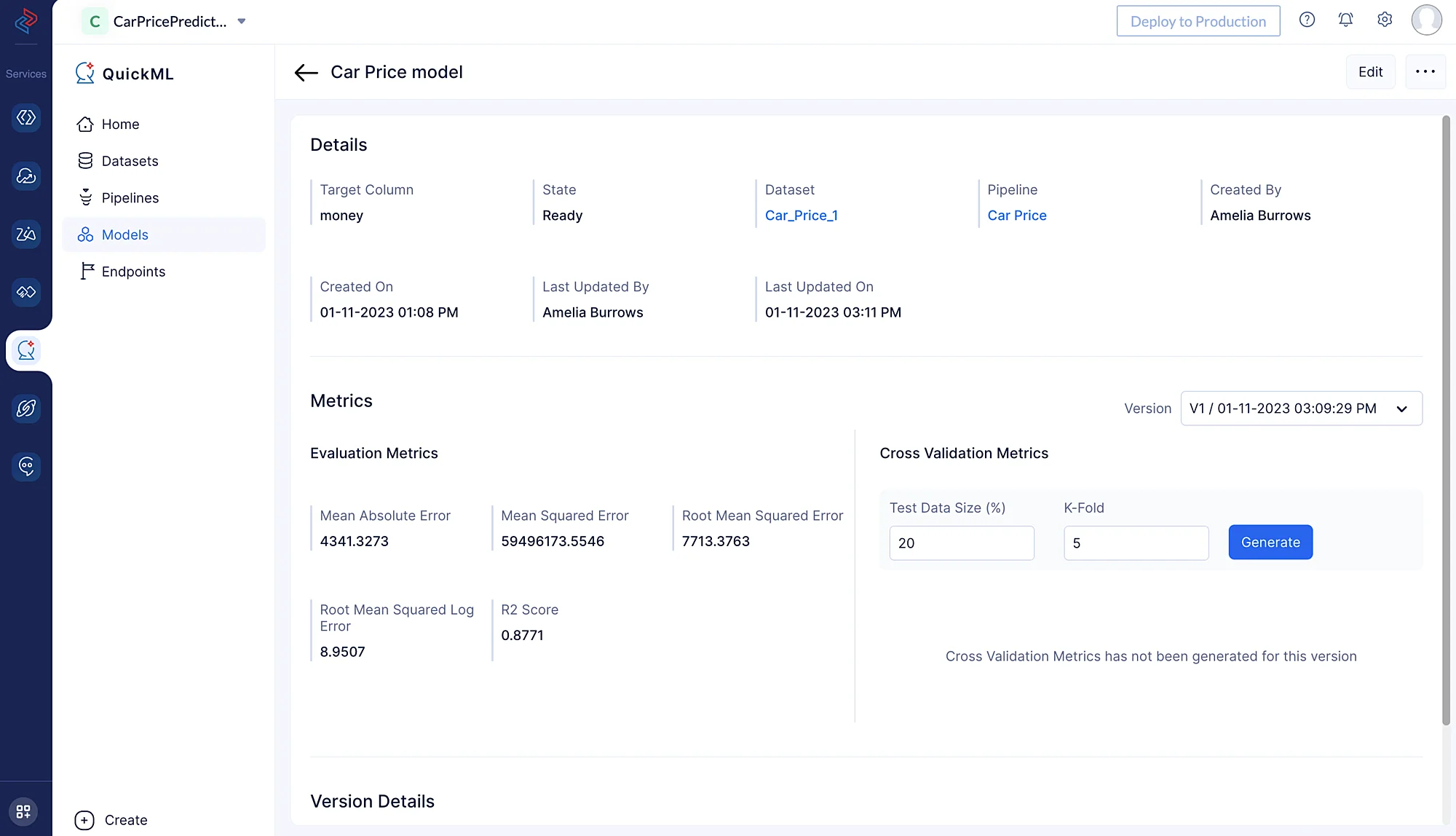
Las métricas a continuación ofrecen percepciones útiles sobre la eficiencia y el rendimiento del modelo al hacer predicciones basadas en los datos.
Última actualización 2026-03-20 21:51:56 +0530 IST