データパイプラインの作成
データセットのアップロードが完了したので、そのデータセットを使用してデータパイプラインの作成に進みます。
- 左メニューの Datasets コンポーネントに移動します。データパイプラインを作成するには2つの方法があります:
- データセットをクリックし、ページ右上の Create Pipeline をクリックします。
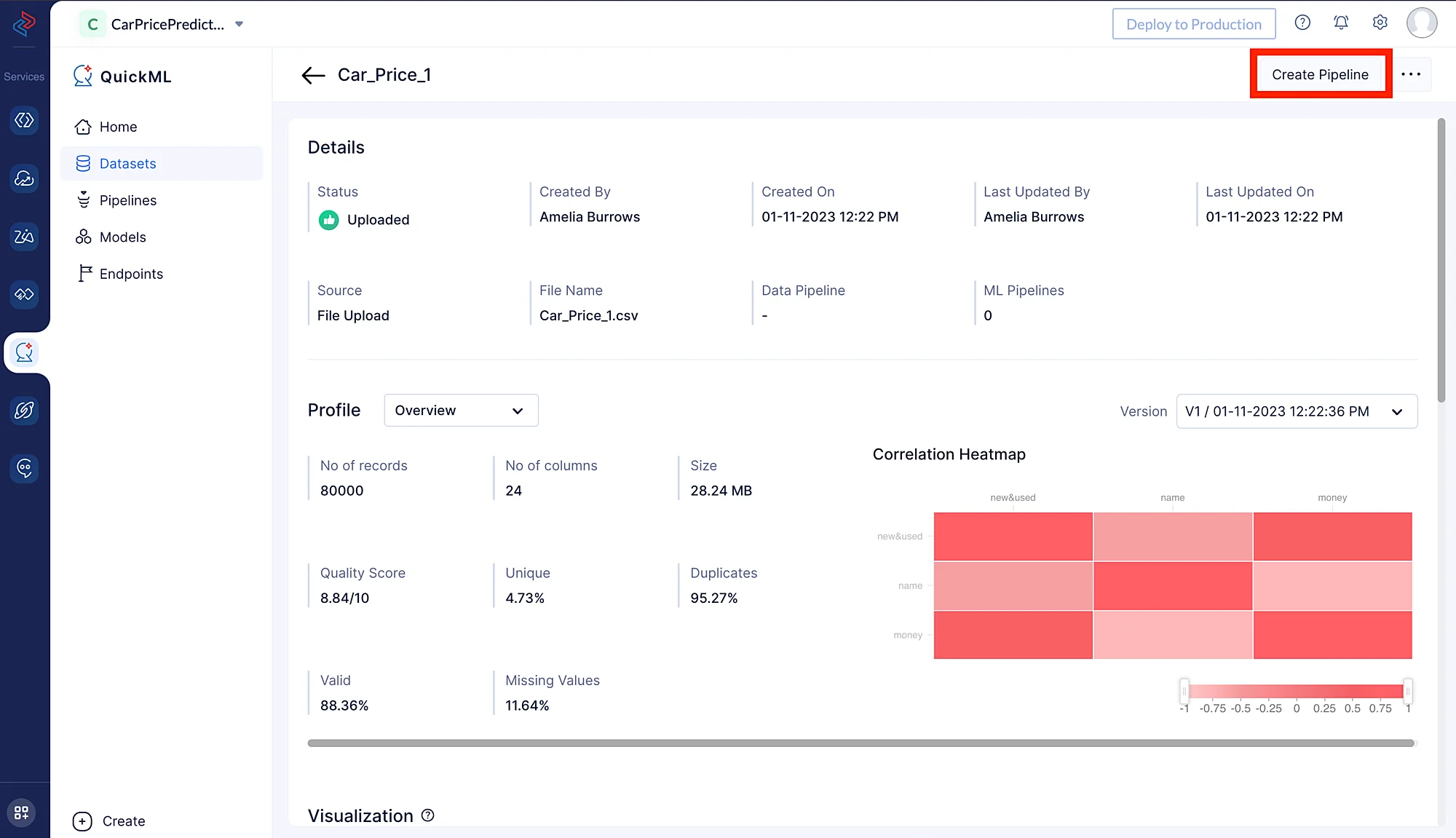
- 下の画像に示すように、データセット名の左側にあるペンアイコンをクリックします。
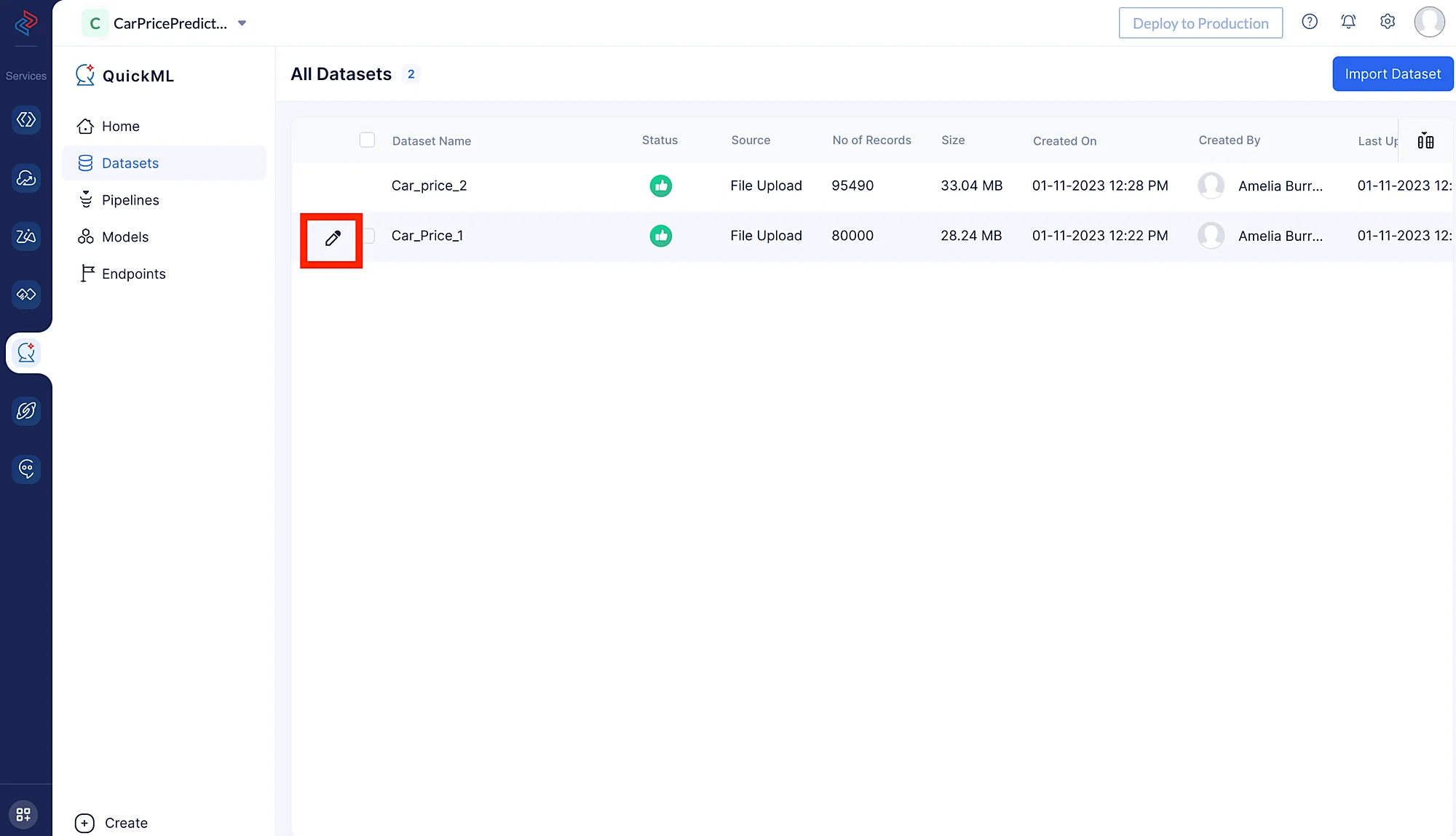
ここでは、前処理のために Car_price_1 データセットをアップロードしています。Car_Price_2 は、これ以降の前処理ステップでこのデータセットに追加されます。
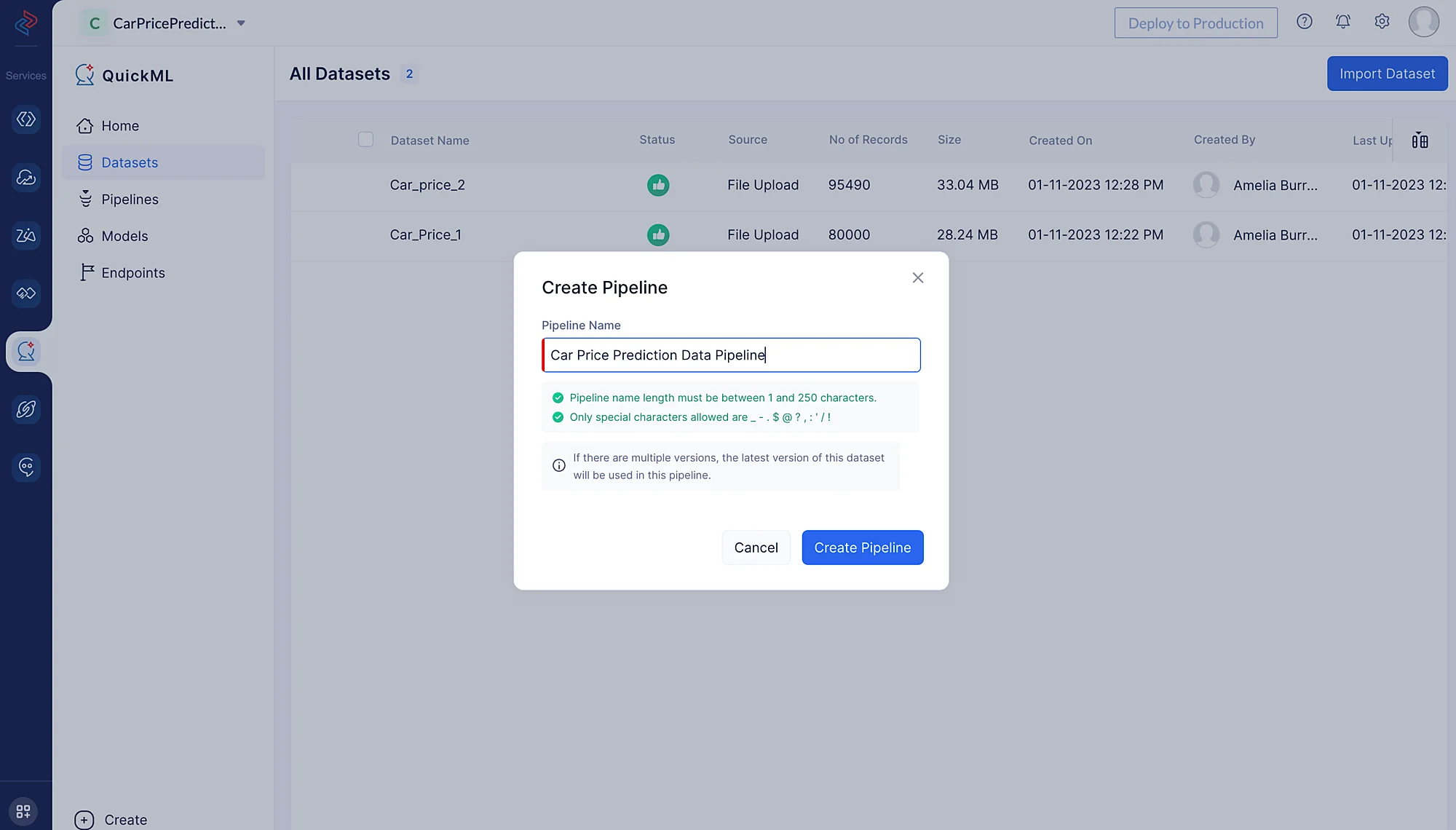
- パイプライン名を「Car Price Prediction Data Pipeline」と入力し、Create Pipeline をクリックします。
以下のスクリーンショットのように、パイプラインビルダーインターフェースが開きます。
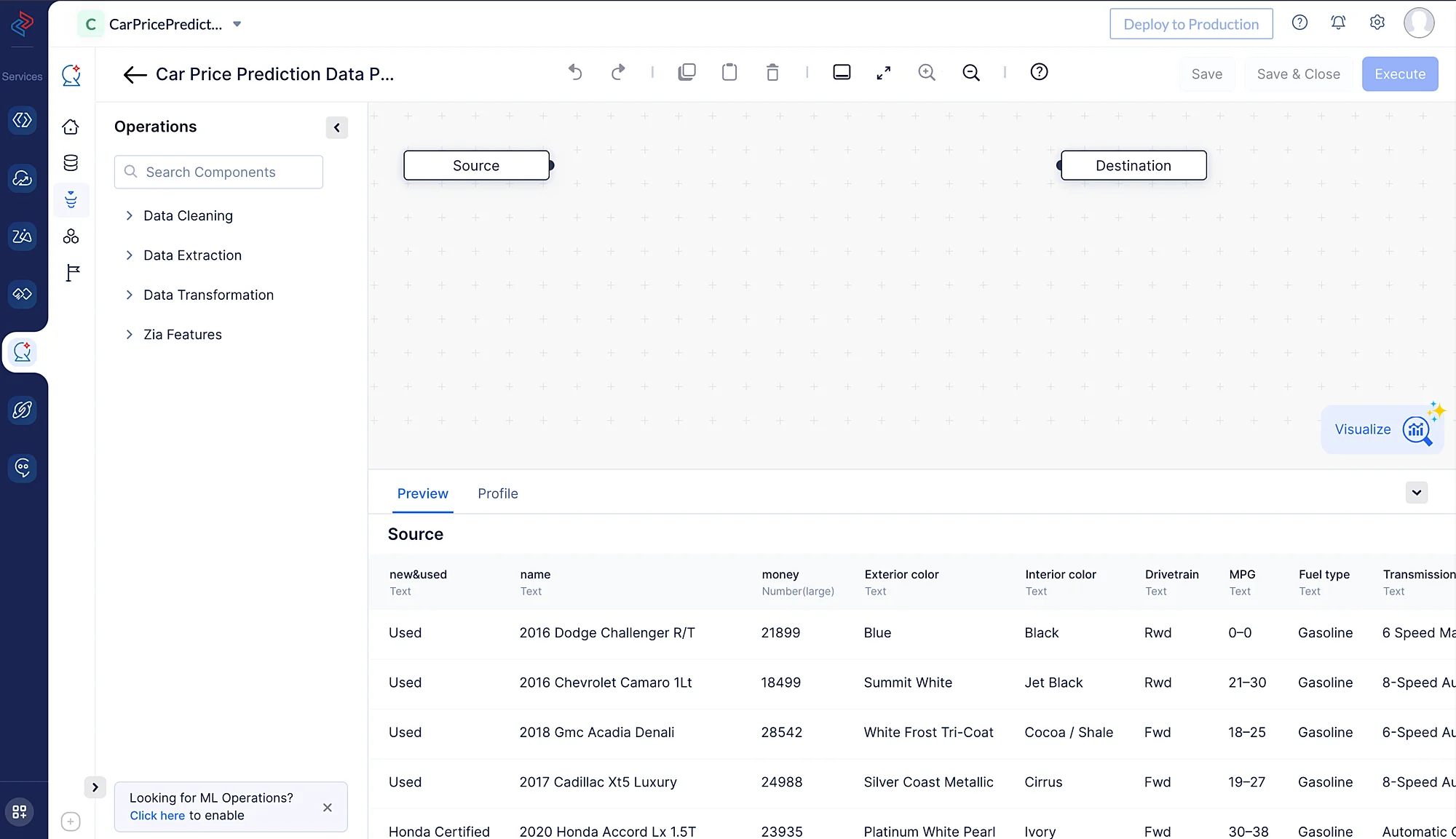
データセットのクリーニング、精製、変換を行い、データパイプラインを実行するために、以下の一連のデータ前処理操作を実施します。これらの各操作は、パイプラインを構成する個別のデータノードを使用します。
QuickML によるデータ前処理
-
2つのデータセットの結合
QuickML の Add Dataset ノードを使用して、新しいデータセットを追加できます(追加するデータセットは事前にアップロードしておく必要があります)。ここでは、既存のデータセットとマージするために Car_Price_2 データセットを追加します。
QuickML のドラッグ&ドロップインターフェースで Data Transformation > Union から Union ノードを使用して、Car_Price_1 と Car_Price_2 の2つのデータセットを1つに結合します。いずれかのデータセットに重複レコードがある場合は、操作時に「Drop Duplicate Records」のチェックボックスを必ずオンにしてください。これにより、両方のデータセットから重複レコードが削除されます。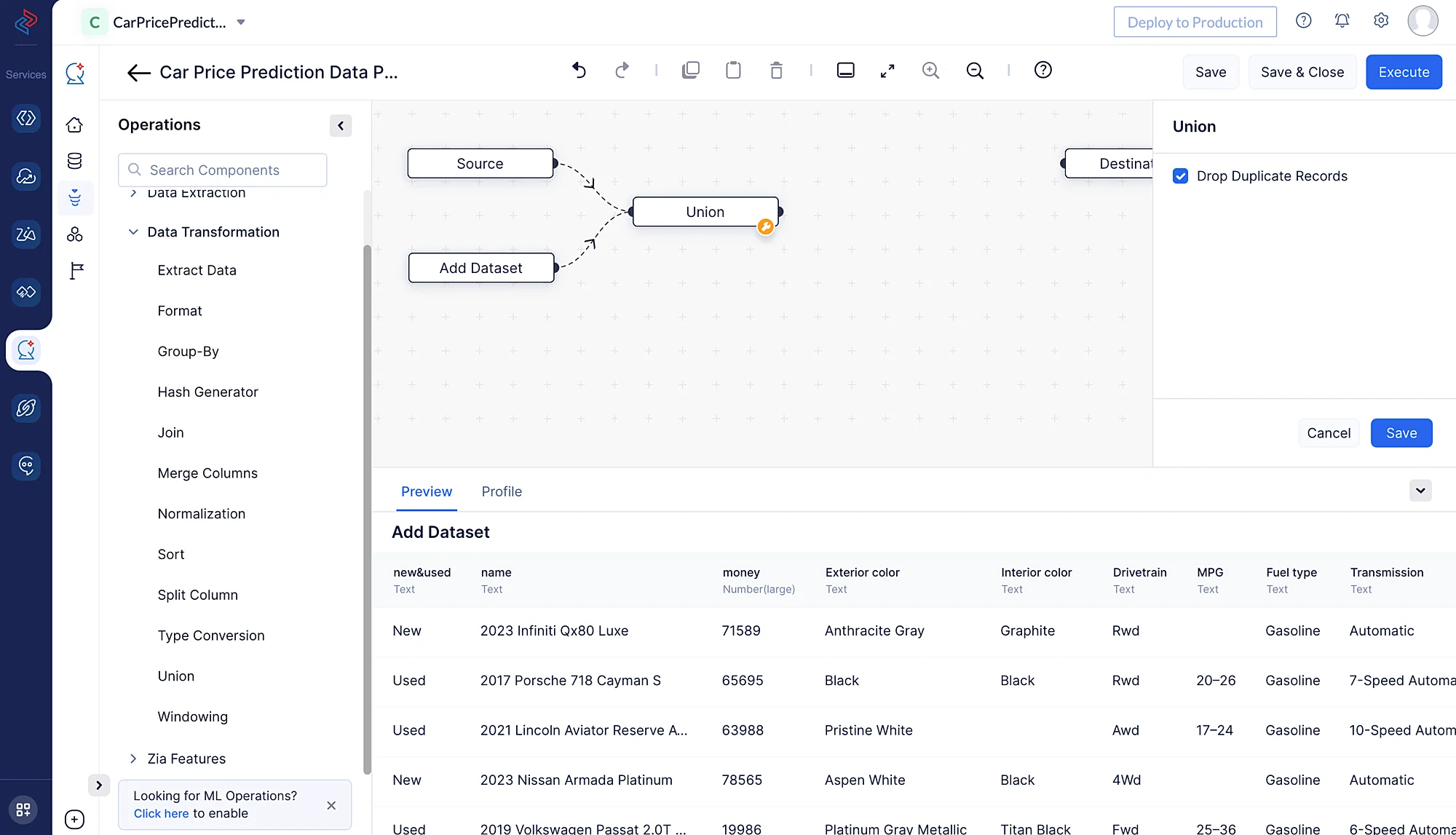
-
カラムの選択/削除
データセットからカラムを選択または削除することは、データ分析や機械学習における一般的なデータ前処理ステップです。カラムの選択や削除は、分析やモデリングの具体的な目的や要件に応じて決定します。 提供されたデータセットにおいて、モデルのトレーニングに不要なカラムは「MPG,」「Convenience,」「Exterior,」「Clean title,」「Currency,」および「Name」です。QuickML の Data Cleaning セクションにある Select/Drop ノードを使用して、モデルトレーニングに必要なフィールドをデータセットからすばやく選択できます。

-
データセットのフィルタリング
データセットのフィルタリングとは、特定の基準や条件を満たす行のサブセットを DataFrame から選択することを意味します。ここでは、Data Cleaning セクションの Filter ノードを使用して、「Drivetrain」、「Fuel Type」、「Engine」、「Transmission」、および「Safety」カラムの空でない値をフィルタリングしています。
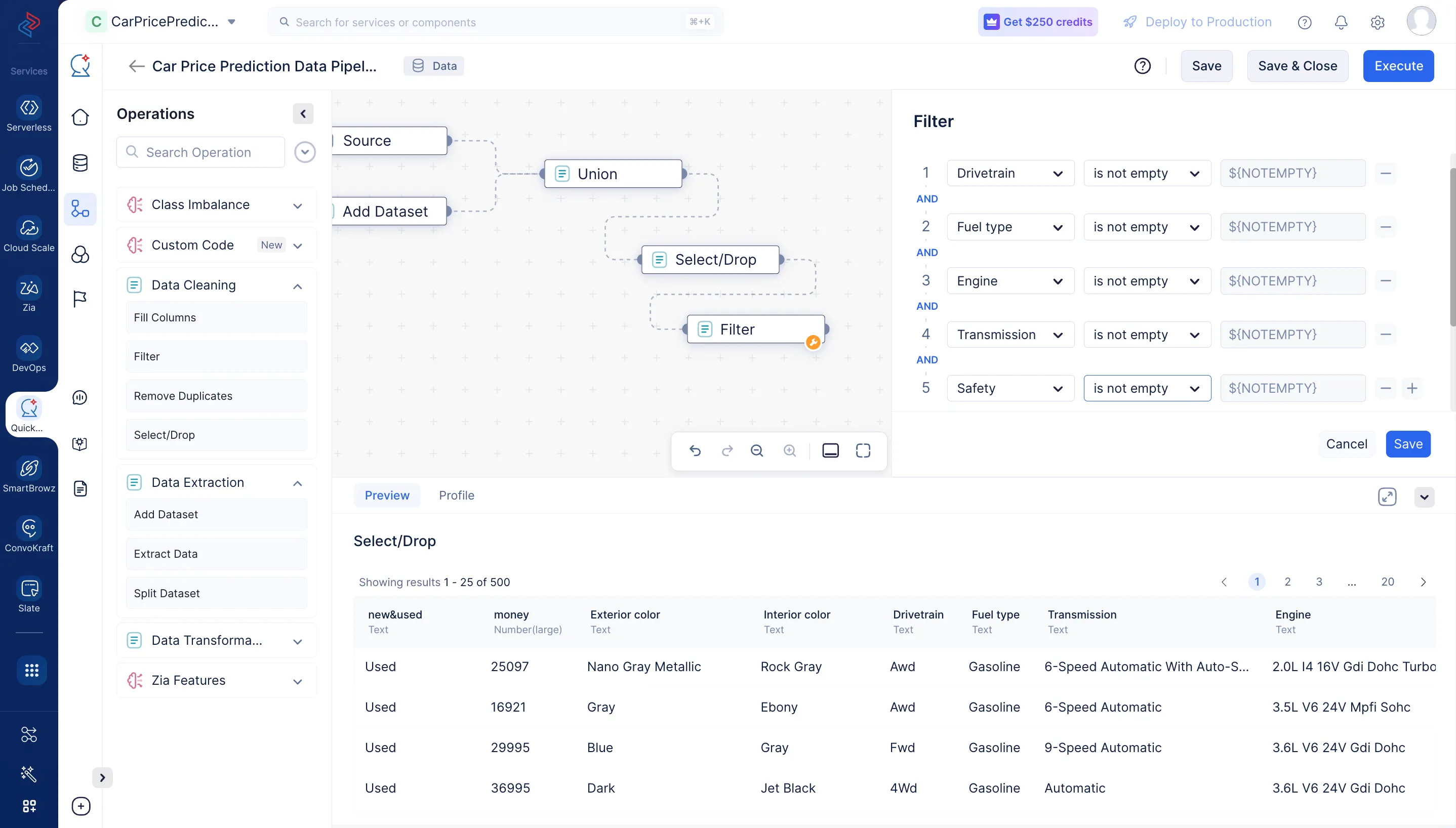
-
データセットのカラムに値を補充
QuickML の Fill Columns ノードを使用すると、特定の条件に基づいてカラムの値を簡単に補充できます。要件に応じて、null 値または非 null 値を補充できます。ここでは、「new&used」カラムにおいて「New」と表示されていないエントリに対して、カスタム値「Used」を補充しています。「Accidents or damage」、「1-owner vehicle」、および「Personal use only」カラムについては、空の値をカスタム値「Not mentioned」で置き換えています。
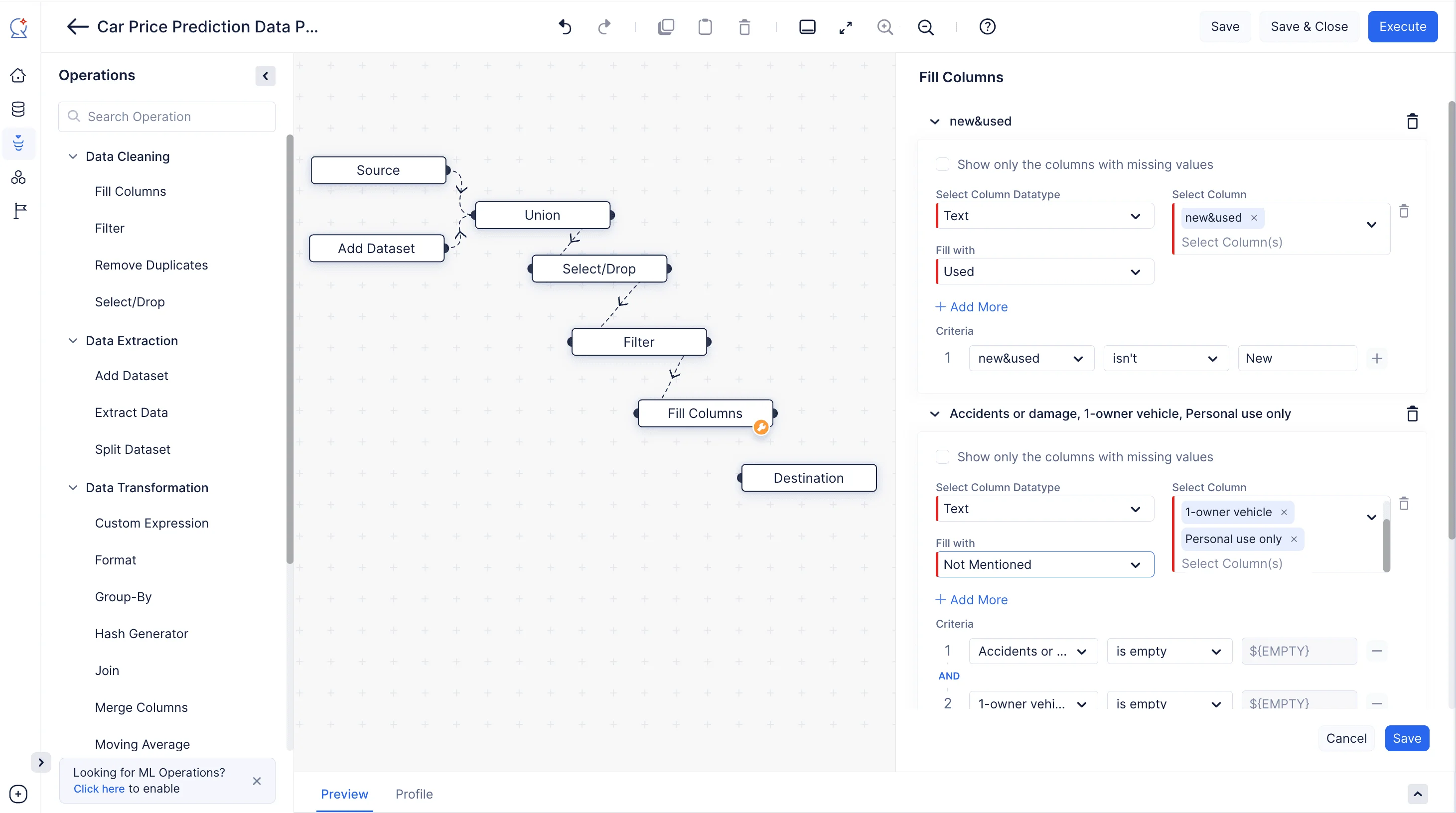
-
保存と実行
Fill Columns ノードを Destination ノードに接続します。すべてのノードが接続されたら、Save をクリックしてパイプラインを保存し、Execute をクリックしてパイプラインを実行します。
実行されたパイプラインと実行ステータスが表示されるページにリダイレクトされます。
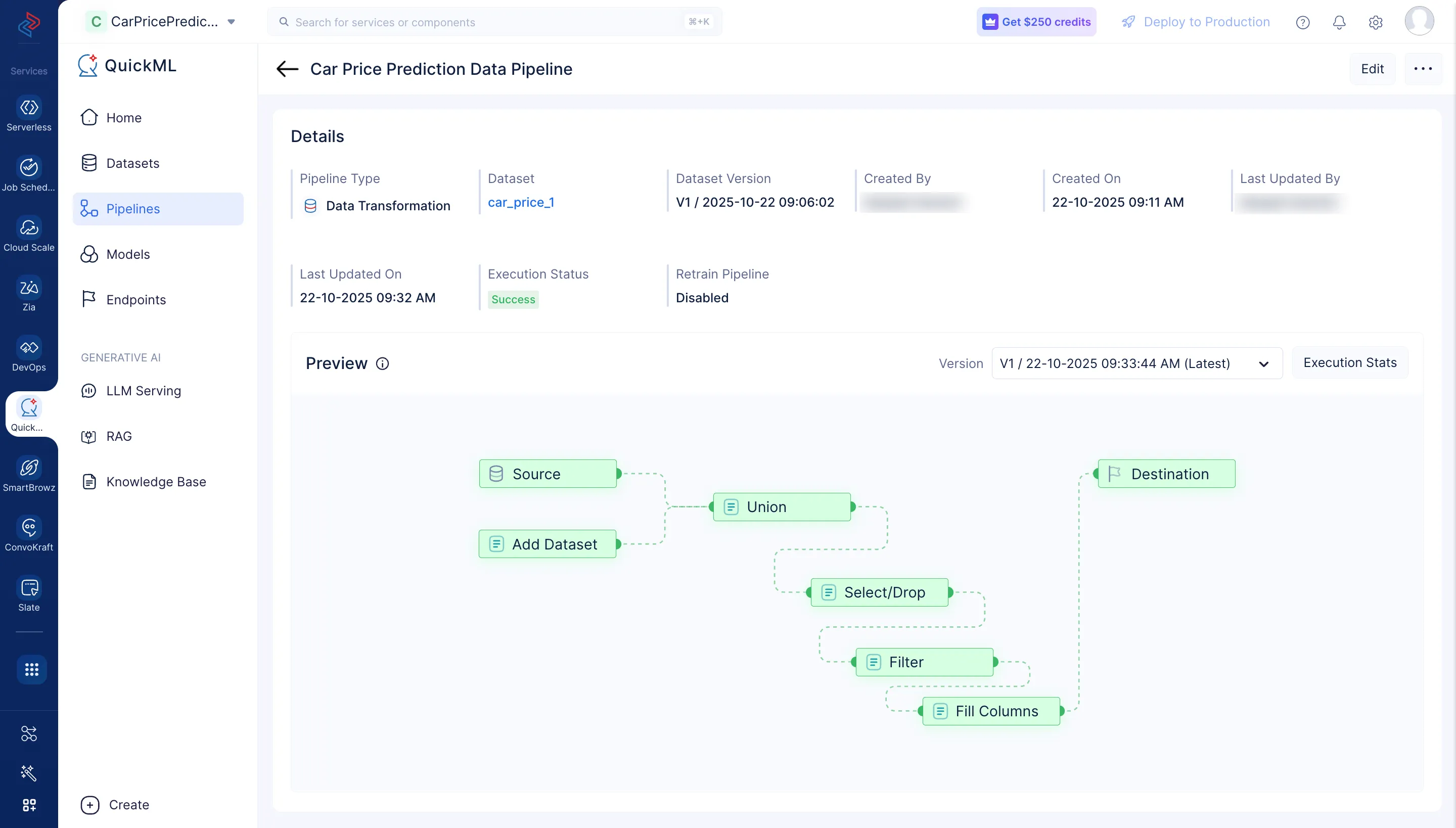
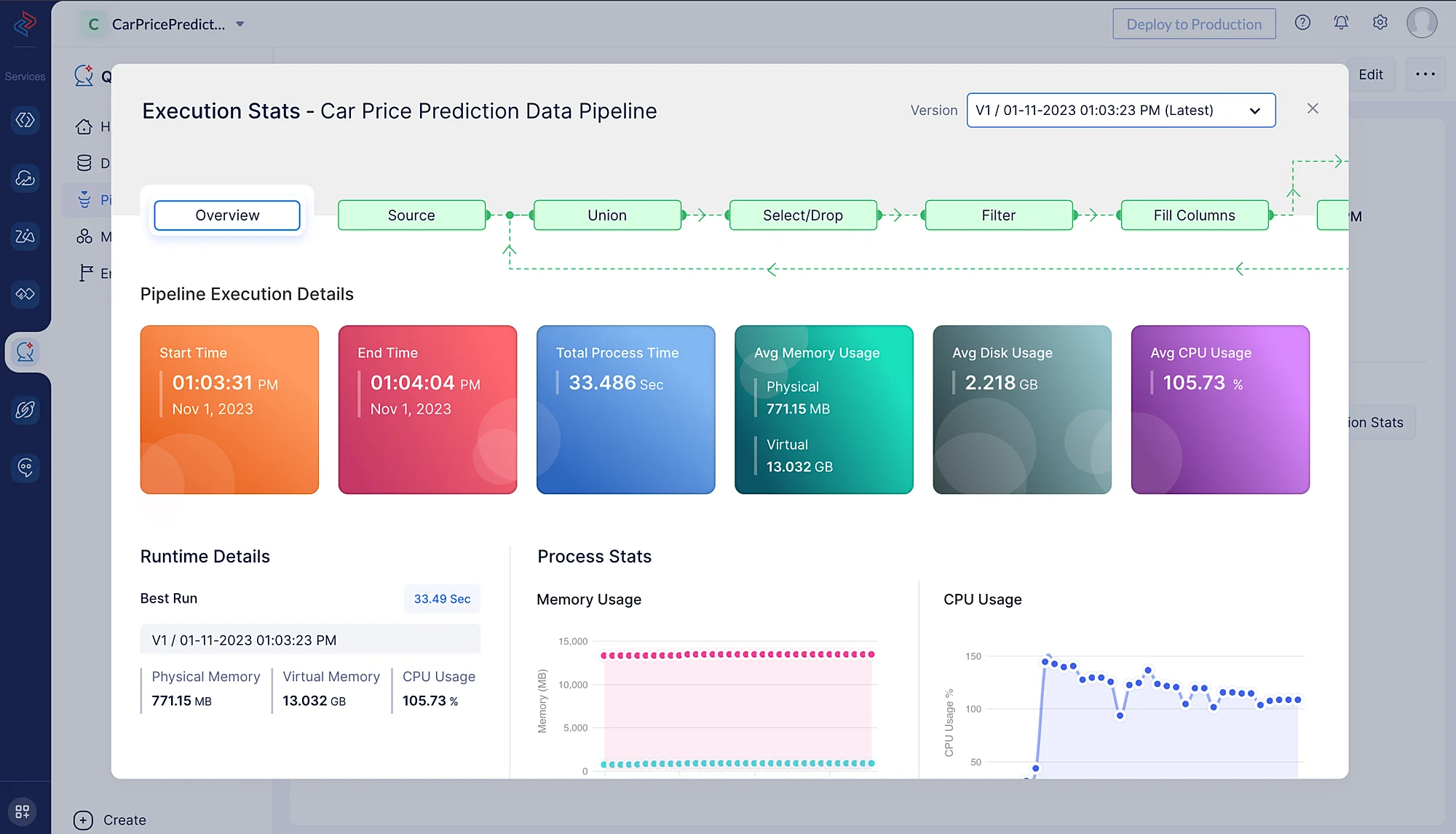
Execution Stats をクリックして、各実行ステージの詳細を確認します。
このパートでは、QuickML を使用したデータ処理の方法を確認し、機械学習モデルの作成に向けてデータを準備するためのさまざまな効果的な手法を紹介しました。このデータパイプラインは、Catalyst プロジェクト内のさまざまなユースケースに対して、複数の ML 実験を作成するために再利用できます。
最終更新日 2026-03-05 11:43:24 +0530 IST