データパイプラインの作成
データセットのアップロードが完了したので、次にデータセットを使用してデータパイプラインを作成します。
-
左メニューのDatasetsコンポーネントに移動し、Zoho_CRM_Deal_Prediction_Sampleデータセットをクリックします。
-
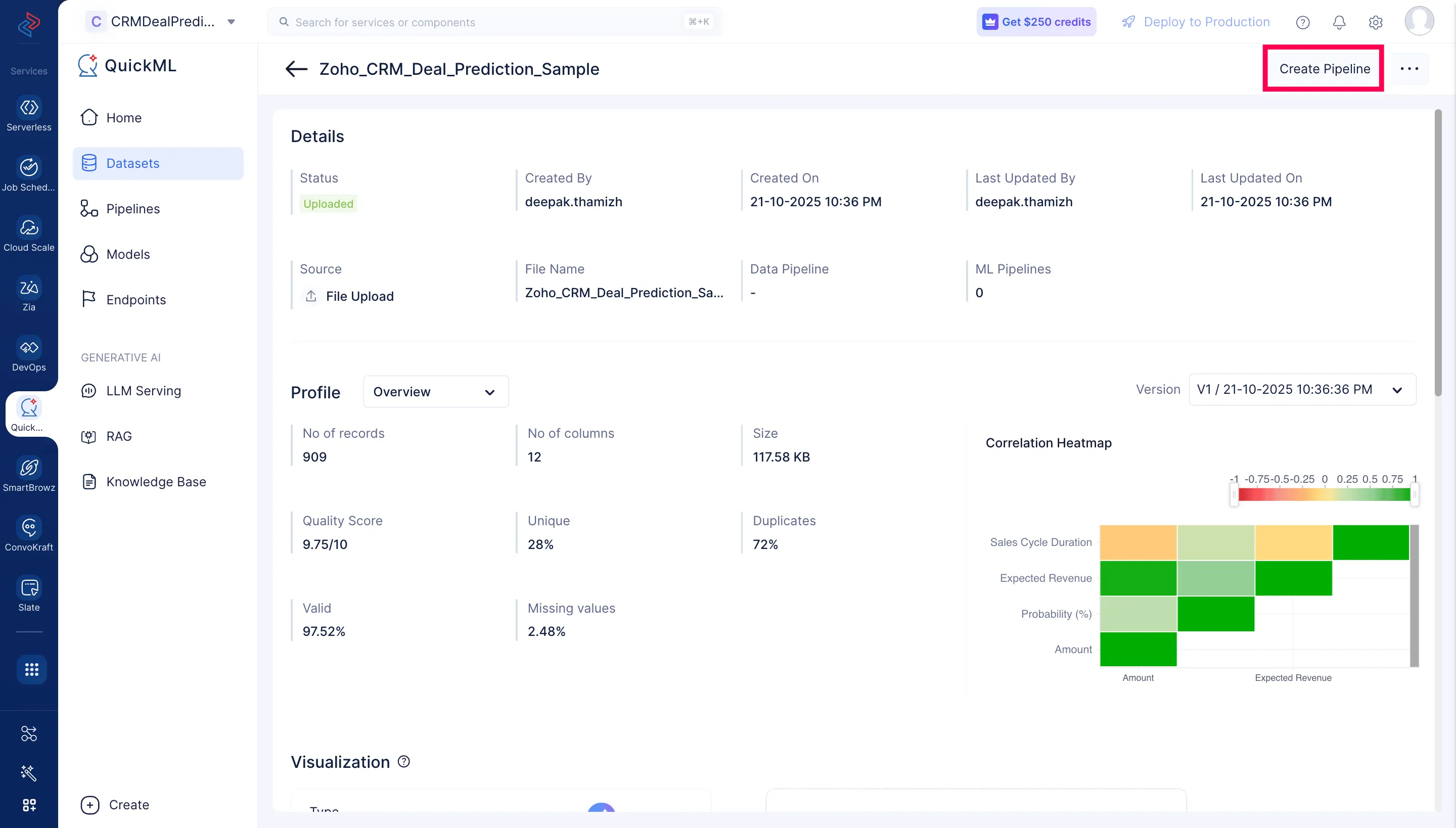
データセットのDetailsページが表示されます。ページの右上にあるCreate Pipelineをクリックします。
-
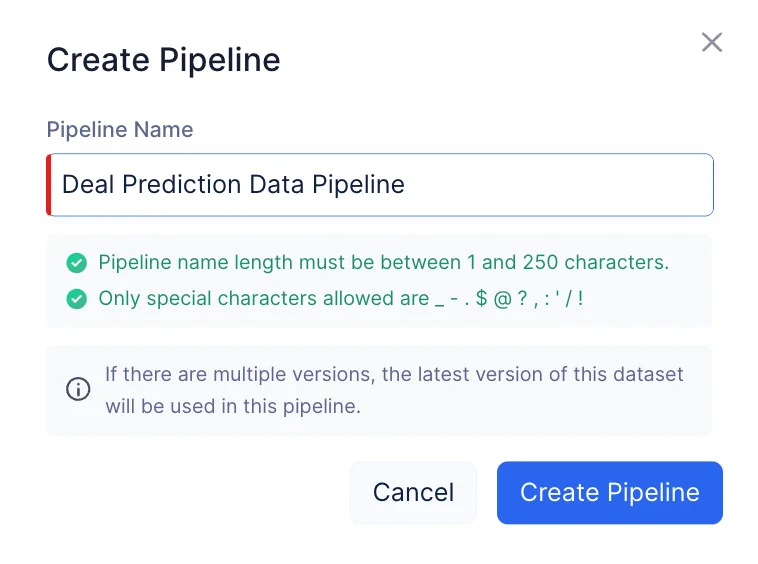
パイプライン名を「Deal Prediction Data Pipeline」と入力し、Create Pipelineをクリックします。
以下のスクリーンショットのように、パイプラインビルダーインターフェースが開きます。
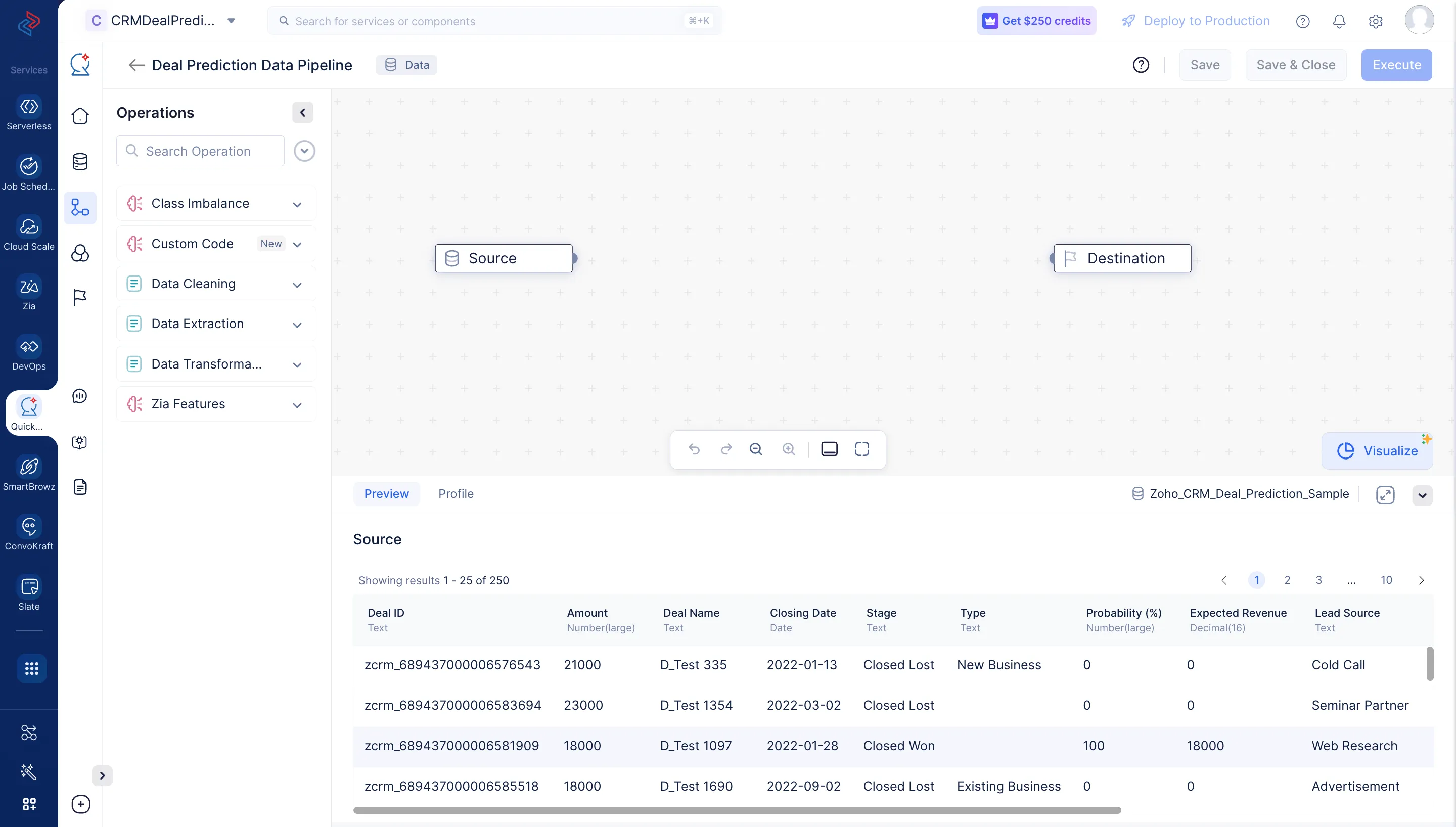
データセットのクリーニング、精製、変換を行い、データパイプラインを実行するために、以下の一連のデータ前処理操作を実施します。各操作は、パイプラインを構築するための個別のデータノードを使用します。
データ前処理用のフィールドを選択する
まず、データセット内の必要なフィールドを選択して、さらに変更を加えます。
-
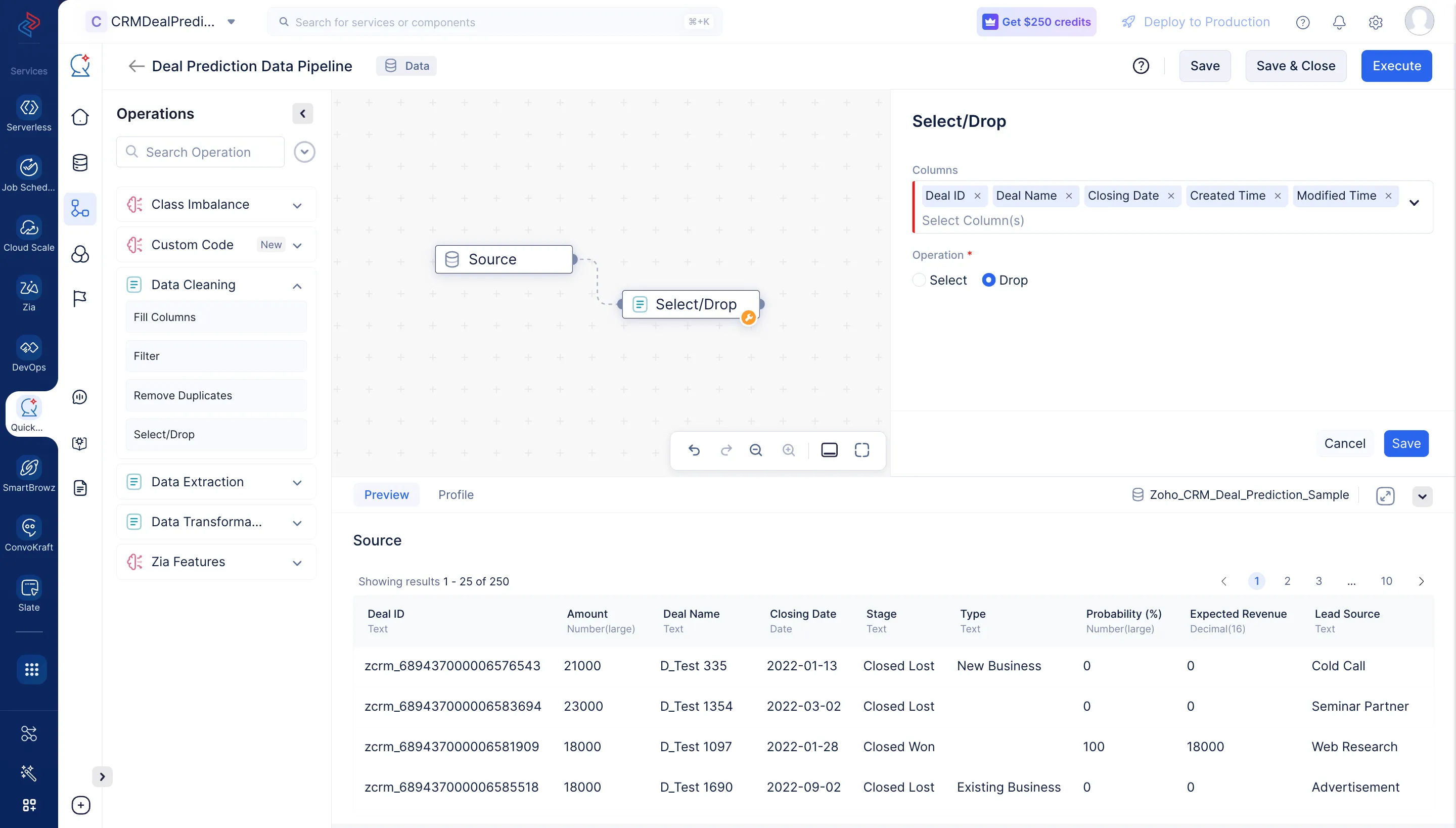
OperationsメニューのData Cleaningコンポーネントを展開します。Select/Drop ノードをパイプラインビルダーにドラッグ&ドロップし、Sourceノードと接続します。
-
右パネルのSelect/Dropセクションで、「Deal ID」「Deal Name」「Closing Date」「Created Time」「Modified Time」の列を選択し、操作として「Drop」を選択してデータセットから列を削除し、Saveをクリックします。ここでは、これらの列は汎用的で、今後の使用目的がないため削除します。
欠損値の処理
トレーニングに使用するデータの品質を向上させるために、Filter ノードを使用して、必要な列の空でないデータをフィルタリングします。このプロセスにより、無関係または不完全なデータが除外され、モデル開発に有用な情報のみが使用されます。
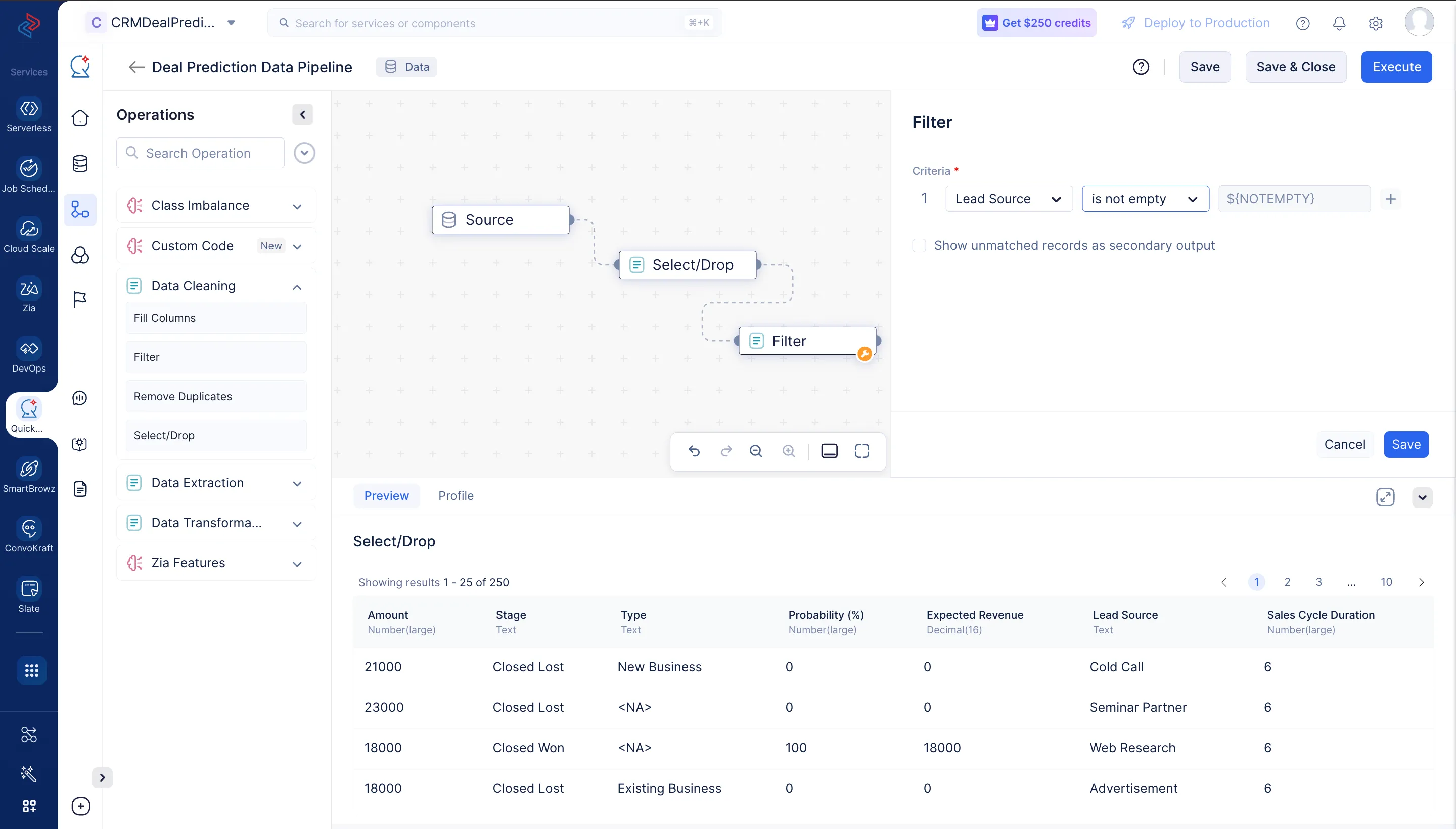
Lead Sourceはモデルトレーニングの重要な列の1つであるため、空のセルを避けるためにこの列にフィルタを追加します。一致しないデータを処理する場合は、show unmatched records as a secondary outputを選択して、一致しないデータの別の出力を取得できます。
列の補完
データ前処理の一環として、データセットの列に欠損値がないか確認し、補完する必要があります。この操作にはFill Columns ノードを使用します。
-
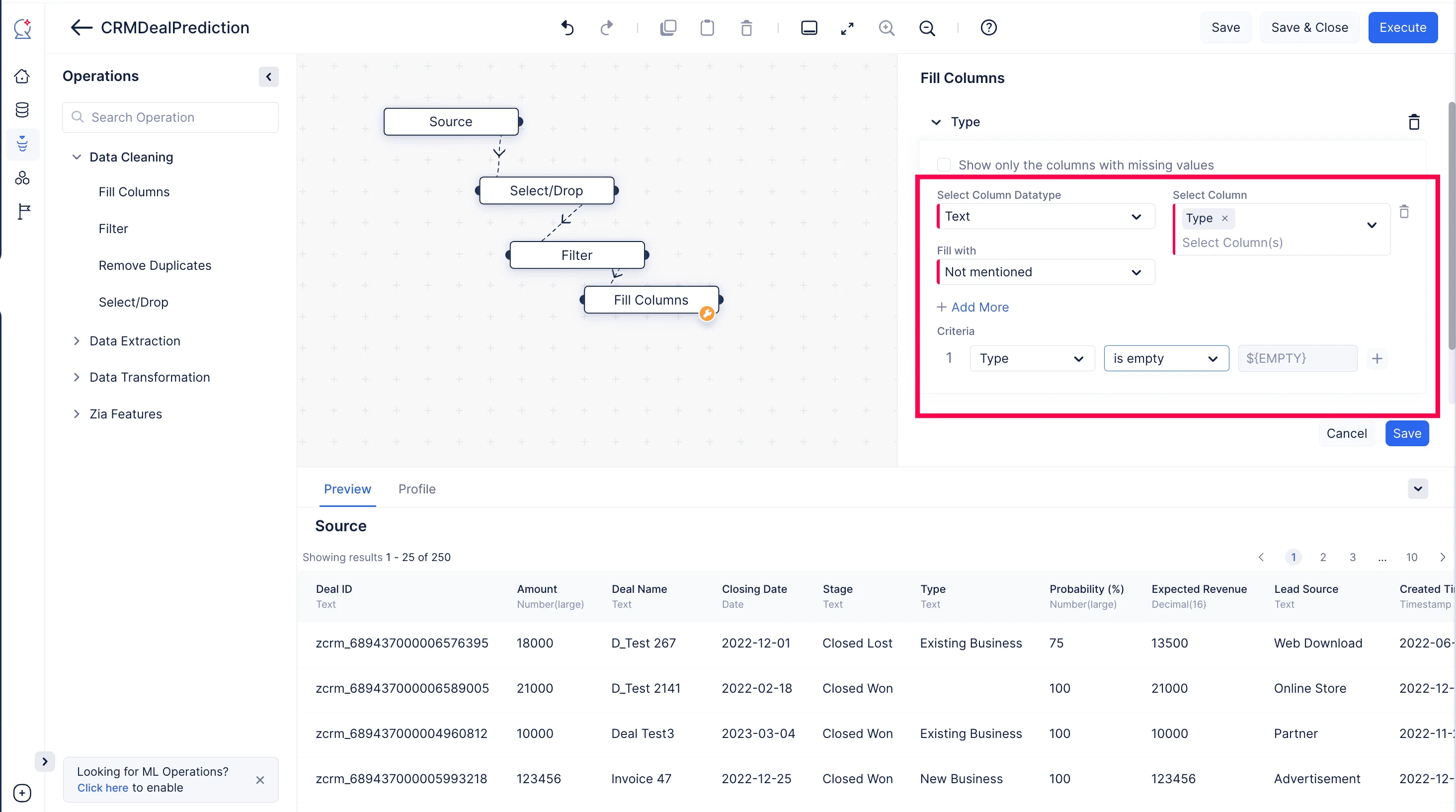
OperationsメニューのData Cleaningコンポーネントを展開します。Fill Columns ノードをパイプラインビルダーにドラッグ&ドロップし、以下のスクリーンショットのように前のFilter ノードと接続します。
-
Select Columnドロップダウンから「Type」を選択します。Fill withフィールドで「Custom Value」を選択します。Valueフィールドを「Not mentioned」に更新し、条件として「Type」と「Is empty」をドロップダウンで選択し、Saveをクリックします。これにより、Type列の空の値が「Not mentioned」で補完されます。
ここまでで、データセットの準備が完了し、このチュートリアルに必要なノードの設定が完了しました。最後に、最後に設定したノードFill ColumnsとDestinationノードを接続します。
Executeをクリックします。
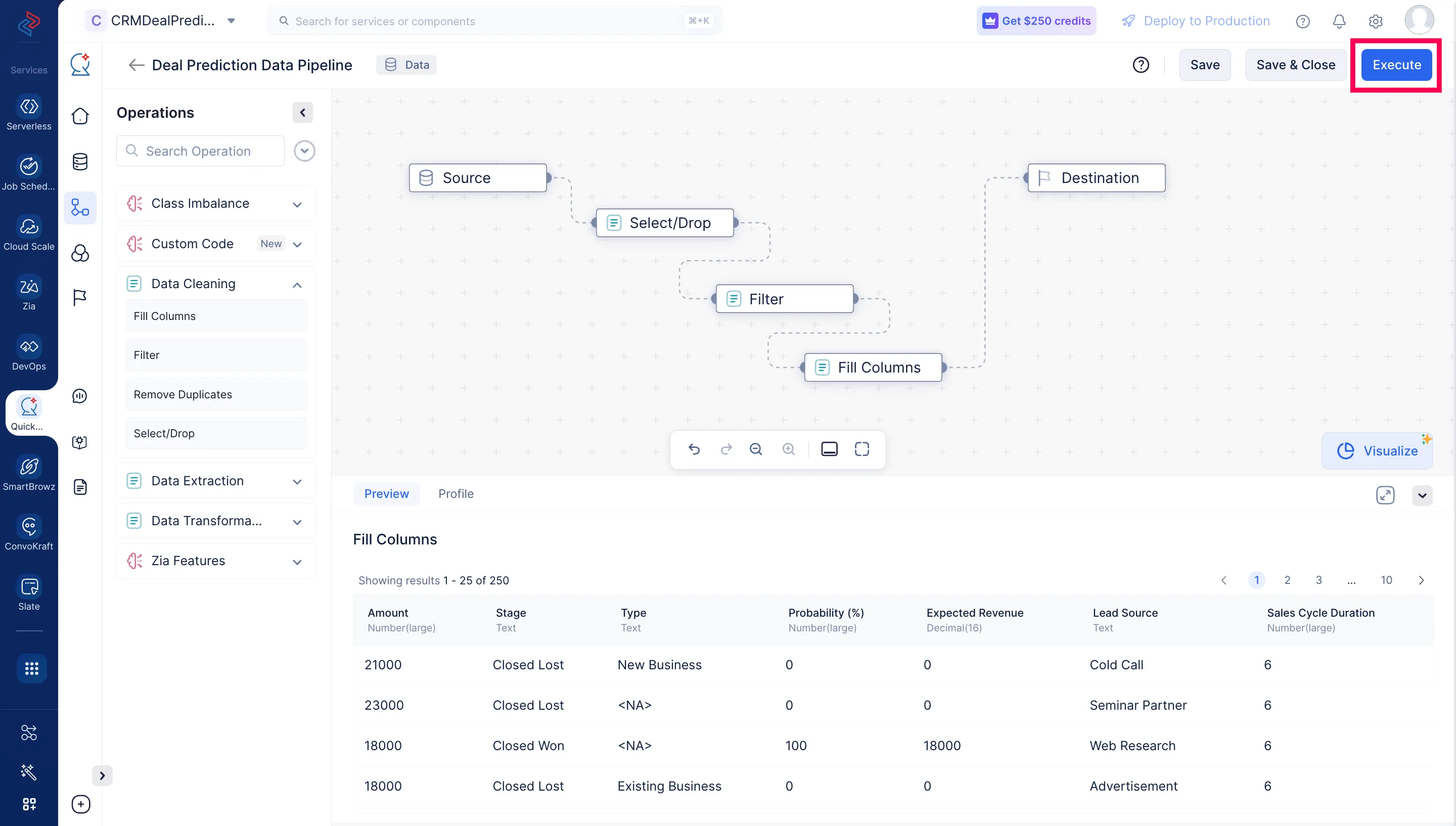
データパイプラインの実行が開始され、以下のスクリーンショットのようにパイプラインのDetailsページに実行ステータスが表示されます。パイプラインの実行が完了すると、実行ステータスに「Success」と表示されます。
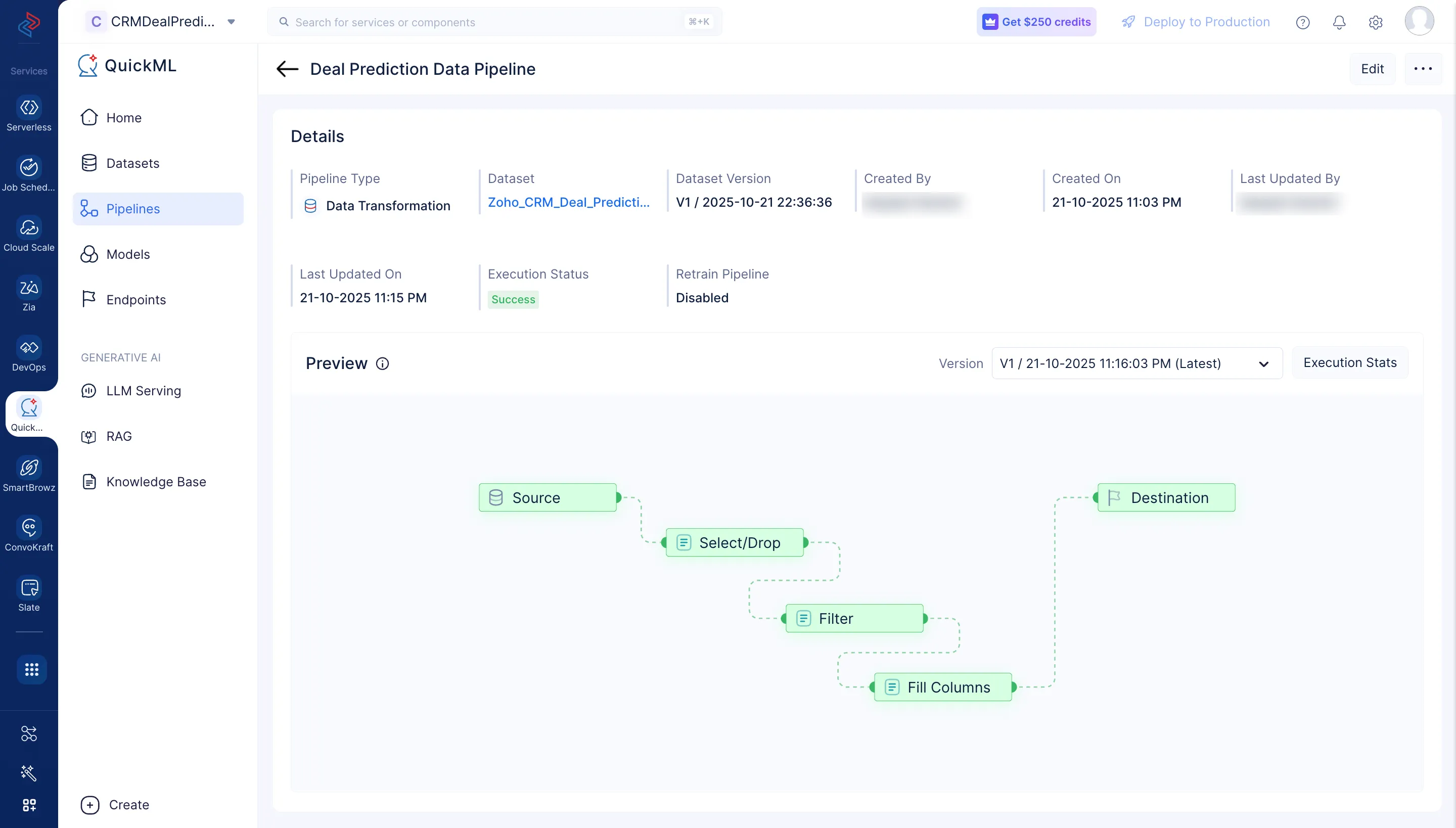
Execution Statsをクリックすると、実行の各ステージの詳細を確認できます。
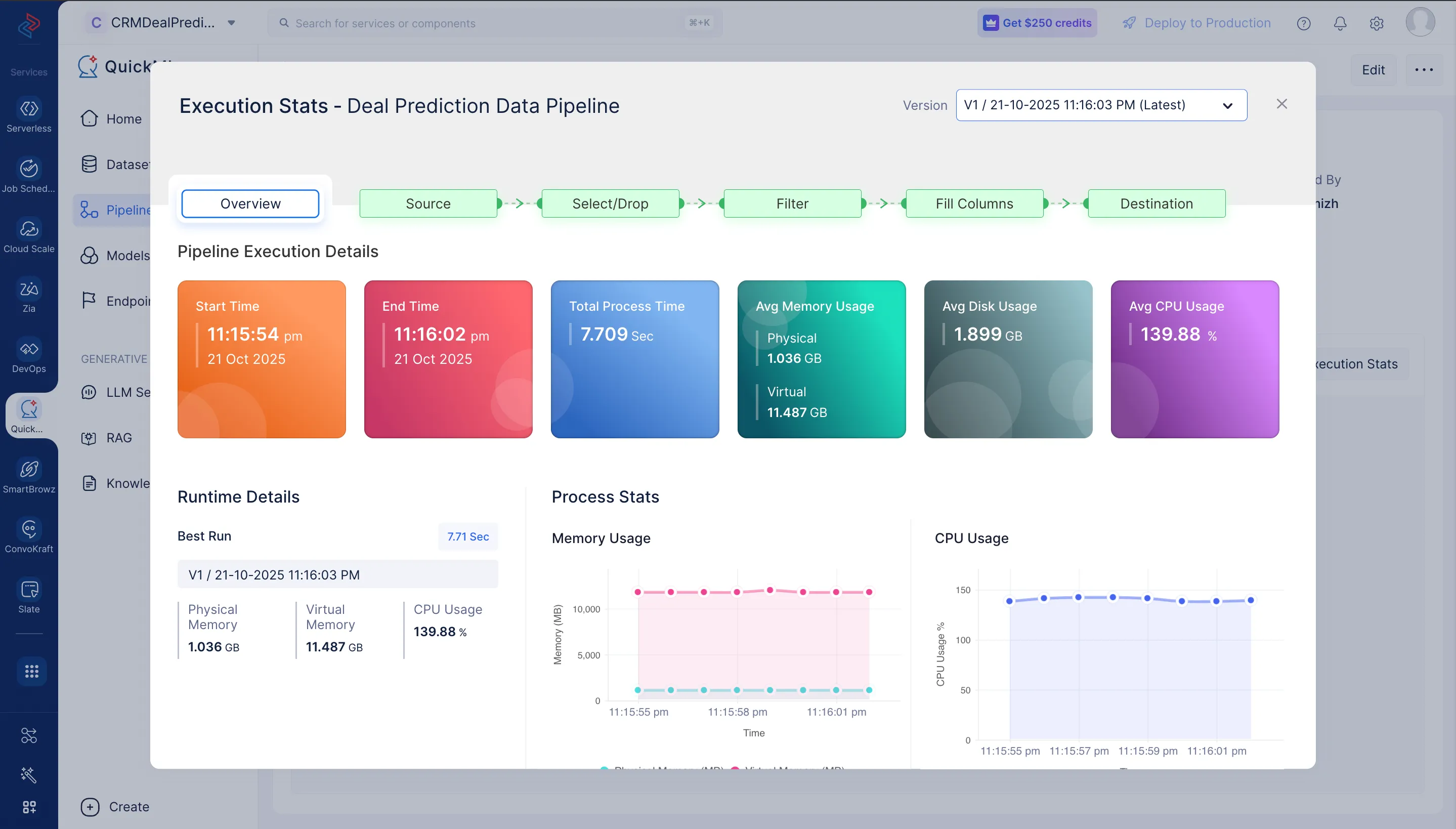
これで、MLモデルの開発に使用できるデータセットの準備が完了しました。次のセクションでは、MLパイプラインの作成について説明します。
最終更新日 2026-03-05 11:43:24 +0530 IST